PyTorch 自定义算子教程:两种方法实现加法算子(附LibTorch Windows环境配置教程)
我们都知道,PyTorch做卷积等底层运算时,都是用C++实现的。有时,我们再怎么去调用PyTorch定义好的算子,也无法满足我们的需求。这时,我们就要考虑用C++自定义一个PyTorch的算子了。
PyTorch提供了两种添加C++算子的方法:编译动态库并嵌入TorchScript[1]、用PyTorch的C++拓展接口[2]。前者适合导入独立的C++项目,后者需要用PyTorch的API设置编译信息,只适合小型C++项目,更适合于把新算子共享给他人的情况。由于我还没有用过torch的C++接口,这里先用第一种方法写一套独立的算子实现示例,跑通整个流程,再基于同一份代码,用第二种方法实现一次,以全方位地介绍PyTorch自定义算子的方法。
前置准备:
- 装好了CMake
- 装好了PyTorch
- 装好了OpenCV
- 看得懂C++、Python
知识点预览:
- 如何配置LibTorch
- 第一个Torch C++程序
- 如何自己写简单的CMake
- 如何用Visual Studio写CMake项目
- 如何编译使用简单的动态库
- 如何用两种方法实现PyTorch自定义算子
- 如何用setuptools自动编译C++源代码
(以上是我写这篇文章之前还不会的东西。)
- 如何用PyTest做单元测试
参考教程:
[1] 添加TorchScript拓展 https://pytorch.org/tutorials/advanced/torch_script_custom_ops.html
[2] PyTorch的C++拓展 https://pytorch.org/tutorials/advanced/cpp_extension.html
[3] 安装LibTorch https://pytorch.org/cppdocs/installing.html
[4] VS CMake https://docs.microsoft.com/zh-cn/cpp/build/cmake-projects-in-visual-studio?view=msvc-170&viewFallbackFrom=vs-2019
配置 LibTorch 开发环境
我们这个项目是使用CMake开发的,理论上任何平台都能使用。我是在Windows上测试的,理论上Windows上碰到的毛病会多一些,Linux上可能直接用就没问题了。
对于我们这个CMake项目来说,成功添加路径,使得find_package(Torch)(找到Torch的CMake配置)不报错就算配置环境成功。当然,貌似由于Torch依赖于OpenCV,找OpenCV包也得成功才行。
参考教程是[3],但对于像我一样什么都不懂的新手来说,由于CMake有些东西要配置,这篇官方教程还不太够用。
下载 LibTorch
想用PyTorch的C++相关内容的话,要先去下载LibTorch库。
在获取PyTorch的Python版本下载命令处,可以找到LibTorch的安装链接:
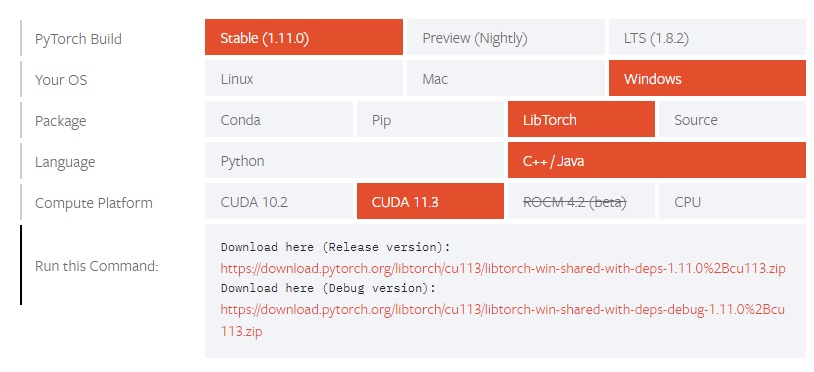
和装PyTorch Python版的时候类似,选好自己的版本,之后点击某个链接下载就行。第一个链接是Release版,第二个是Debug版。由于我是编程高手,不要调试,所以直接选择了Release版。建议大家去下Debug版方便随时调试。
添加环境变量
下一步要把LibTorch的动态库所在目录加入环境变量中,以使程序运行时能够找得到依赖的动态库(编译是没问题的)。
把xxxxxxxx\libtorch\lib这个目录添加进环境变量即可。
如果是在Windows上,添加环境变量时有一个细节要注意:
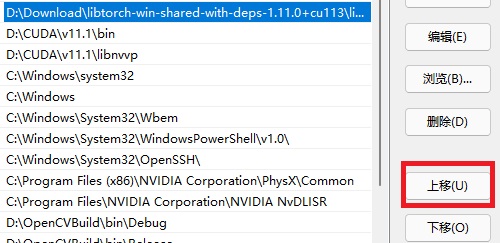
相信90%的人装PyTorch前都是把Cuda装好了的。在添加LibTorch的动态库目录时一定要注意,要把这个路径移到Cuda路径的上面。详细原因见FAQ。
Hello LibTorch
接下来我们要用一个能调试CMake程序的环境来完成第一个C++ LibTorch程序。
创建一个崭新的文件夹,在里面添加一个CMakeLists.txt:
1 | cmake_minimum_required(VERSION 3.1 FATAL_ERROR) |
里面的equi_conv可以换成你喜欢的项目名。我使用的项目名是equi_conv,这个名称会在后面多次出现。理论上我显示equi_conv的地方显示的应该是你自己的项目名。
注意! 一般情况下CMake是找不到Torch和OpenCV的,要手动设置CMake Configure附加命令中的Torch_DIR和OpenCV_DIR这两个参数,比如我的附加命令是
1 | -D Torch_DIR="D:/Download/libtorch-win-shared-with-deps-1.11.0+cu113/libtorch/share/cmake/Torch" -D OpenCV_DIR="D:/OpenCV/opencv/build" |
。Torch_DIR是"xxxxxxxx/libtorch/share/cmake/Torch,OpenCV_DIR大约是xxxxxxxx/opencv/build。每个人的具体路径可能不一样,只要记住,这两个路径里都得是包含了.cmake文件的。根据编程环境的不同,设置这两个CMake参数的位置也不同,详见后文。
官方教程[3]给了一种很骚的提供路径的方法:-DCMAKE_PREFIX_PATH="$(python -c 'import torch.utils; print(torch.utils.cmake_prefix_path)')"。这个命令是调用Python脚本以添加PyTorch默认的CMake搜索目录。但是这个命令有一些问题:1) 当前命令行环境里不一定能正确调用Python及访问torch库(比如PyTorch是用conda装的,而当前环境不是对应的conda环境);2) 我们下载的libtorch似乎难以对得上PyTorch包里默认的libtorch路径。这行命令似乎仅适用于处于正确Python环境下,把libtorch装到了/libtorch目录下的Linux系统。为了命令的兼容性,我们不用这么骚的操作,老老实实自己设置LibTorch目录和OpenCV目录。
再写一个叫op.cpp的C++源文件。
1 |
|
如果你是高手,可以不去配环境,直接手敲CMake命令。但为了方便,接下来我们还是准备调试运行这个程序。配置CMake调试环境有很多方法,这里先给一个Windows上Visual Studio的方案[4]:
准备好上面那个CMakeLists.txt后,用VS打开这个CMake文件(相信大家的VS都是2017版本以上的,旧版本是没有CMake的功能的~):
如果文件没写错VS会自动配置(Configure)CMake。在工具栏中可以手动中断或开始CMake的配置。
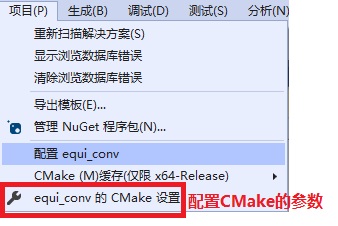
还可以点击上面的“{PROJECT_NAME}的CMake设置”来设置CMake命令中要用的参数(比如-D参数)
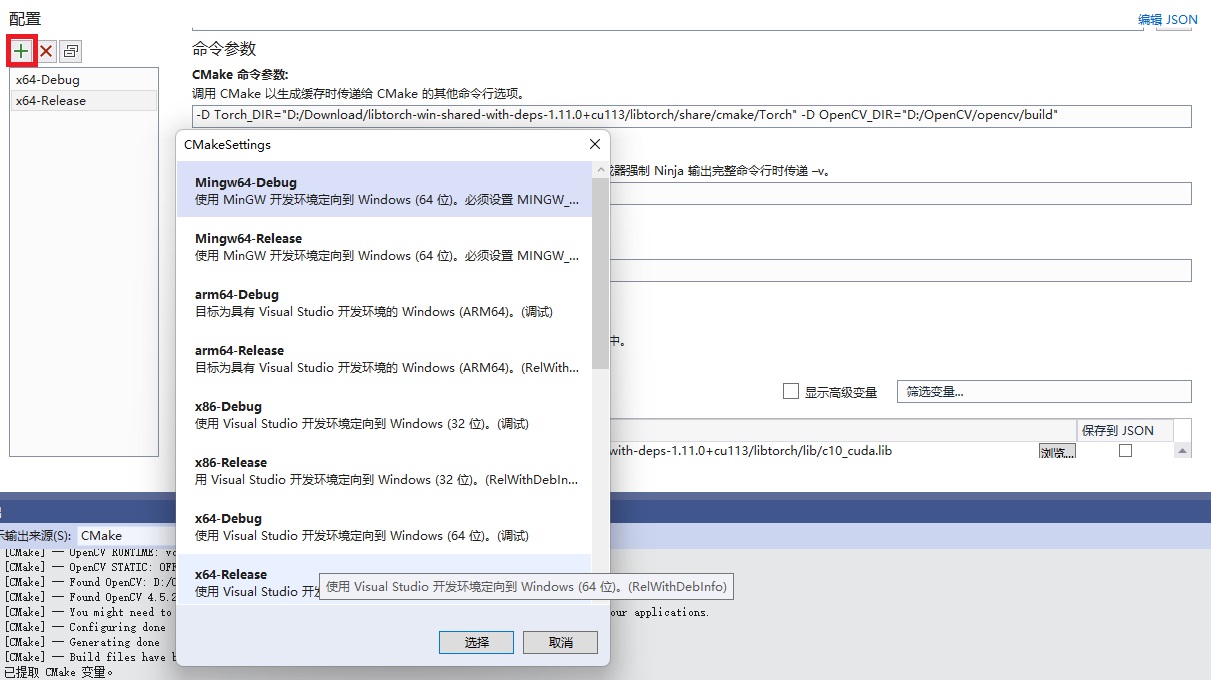
注意,一开始CMake只有Debug版的配置,可以点左上角的加号手动加一个Release版的配置。
同时,如图中所示,xxx_DIR应该卸载CMake命令参数里面。
配置好后去上面的工具栏点击”生成-全部生成”就可以把程序编译好了。接下来按熟悉的F5就可以运行程序了。
再介绍一个VSCode的CMake编程环境,这个基本上是全平台通用的。不过同样,我还是在Windows上测试的,以Windows上的配置为主。
通过搜索”Windows CMake VSCode cl 配置”等关键词,我搜索到了一篇很好的教程,我是照着这篇教程配的环境。如果是Linux的话,换一下编译器应该就能拿过来用了。
为了添加-D等配置参数,可以用ctrl+,打开设置,修改工作区设置里的CMake Configure命令:

如果一切正常,程序会输出随机张量的内容。
LibTorch A+B
C++ 侧
修改op.cpp:
1 |
|
我们要实现一个新PyTorch算子my_add,该实现函数先把两个PyTorch Tensor转换成OpenCV Mat,用Mat做加法,再把Mat转回Tensor。整个代码非常易懂,哪怕对LibTorch和OpenCV的语法不熟,也基本猜得出每行代码的作用。
1 |
一开始,先包含LibTorch、OpenCV的头文件。
1 | torch::Tensor my_add(torch::Tensor t1, torch::Tensor t2) |
我们要实现的是一个PyTorch的加法,因此实现函数中所有的张量类型都是torch::Tensor。加法输入是两个量,输出是一个量,因此最后的函数头要这样写。
1 | assert(t1.size(0) == t2.size(0)); |
做为严谨的程序员,我们要对输入的Tensor做一定的检查(实际上这两个检查还不够,由于我们默认输入图像的通道是3,还应该检查一下通道数。但这样检查下去可能会没完没了了,这里仅仅是提醒大家要养成良好的编程习惯)(其实是我写了两行就懒得写下去了)。
1 | cv::Mat m1(t1.size(0), t1.size(1), CV_32FC3, t1.data_ptr<float>()); |
这两行是用Tensor构造Mat。从这两行代码中,可以学到两点:1)可以通过tensor.data_ptr<float>来获取Tensor存储数据的指针;2)不同框架下的数据结构互转时一般是传指针,再传shape。
OpenCV这里有一点点特殊。OpenCV的Mat是二维的,要维护一个H-W-C(高-宽-通道)的数据,需要传一个基础数据类型CV_32FC3,即3通道浮点数。
从代码中可以猜出来,tensor.size(i)可以获取Tensor第i维的长度。
1 | cv::Mat res = m1 + m2; |
不用猜都知道这是调用了Mat的加法。
1 | torch::Tensor output = torch::from_blob(res.ptr<float>(), { t1.size(0), t1.size(1), 3}); |
这一行是Mat转Tensor,同样是传了数据指针和张量形状。
这里第二个参数是个叫at::IntArrayRef的类型的。这个类型会用在Tensor的shape上。该类型的最简单的初始化方式就是用大括号把值框进去,就像Python里用方括号或圆括号传List和Set一样。
相比生成OpenCV Mat,这里没有传数据类型。原因如前文所述,应该是由于OpenCV的数据类型里包含了维度信息,所以OpenCV的Mat构造时要额外传这个信息。
1 | return output.clone(); |
最后返回的是tensor.clone()。官方教程里说,用指针创建Tensor时会复用原来的指针,而不会新申请内存。函数结束后,Mat里的资源会释放,等于说这个用Mat创建出的Tensor也失效了。因此要clone()一下,让数据在函数结束后依然存在。
1 | TORCH_LIBRARY(my_ops, m) |
最后调用API把C++函数绑定到Python上,现在可以不用追究这些代码的具体原理,只要知道这样写Python就可以访问到my_add了。
这里可以改动的内容其实有两处:算子的域my_ops,算子名/函数名my_add。前面那个my_ops在PyTorch的某些地方会用到,这里我们先不管,随便取一个名字即可。
现在我们要编译的是一个包含一个函数的动态库,而不是一个包含main的应用程序了。因此,我们要修改一下CMakeLists.txt中的编译选项:
1 | cmake_minimum_required(VERSION 3.1 FATAL_ERROR) |
其实就改了一行:add_library(equi_conv SHARED op.cpp),这样可以把编译目标变成一个动态库。
代码没错的话,重新Configure和Generate后动态库就编译好了。
Python 侧
我们写一个单元测试Python脚本来测试一下我们的算子能否在PyTorch里成功运行:
1 | import torch |
再一次,为了体现我们编程时的严谨性,我们使用pytest来测试这个脚本。pip install pytest就可以轻松安装好这个Python单元测试工具。但如果你实在太懒了,不想下pytest,就得在后面补一行test_add()手动调用一下这个函数。
1 | lib_path = r"D:\Repo\equi_conv\EquiConv\out\build\x64-Release\equi_conv.dll" |
import torch就不说了。这两行代码是调用PyTorch的API来读取我们刚刚编译出来的动态库。我们这里只需要把动态库路径改成自己的就好,别的都不用改。
1 | def test_add(): |
后面这些代码就是实际单元测试的代码里,代码非常简单:生成两个随机tensor,比较一下我们的加法和PyTorch自己的加法是否结果一致。
值得注意的是,用torch.ops.my_ops.my_add可以调用我们刚刚那个C++函数。前面的torch.ops都是写死的,后面的my_add是我们自己定义的函数名。而my_ops,则是我们刚刚调API时填的“算子域”了。算子域在注册Python符号表的时候还会用到,这里不用管那么多,把算子域理解成一个命名空间,一个防止算子命名冲突的东西即可。
torch.allclose可以简单地理解为一个要求两个Tensor所有值都几乎相等的比较函数。
在该文件夹下运行命令pytest,屏幕上显示绿色的1 passed xxxxxxxxxx即说明单元测试成功运行。
至此,我们算是成功在Python里调用了一个C++写的算子。只需要写上torch.ops.my_ops.my_add`,我们就能够在任何地方(比如模型的forward函数)调用我们的算子。聪明的人看到这里,已经学会随心所欲地在PyTorch里嵌入自己的高效率的C++算子了。
配好环境,搭好框架后,我们自己实现算子倒是非常舒服。问题是,如果我们要把这些算子给别人使用的话,要么是给别人源代码,让别人自己配置LibTorch编译环境;要么是把所有Torch版本数 * Cuda版本数 * 操作系统数这么多个动态库给预编译出来。
要是能抛掉LibTorch,让有PyTorch和Cuda环境的用户自己编译源代码,似乎一个平衡开发者体验和用户体验的选择。所以,这里再介绍之前讲过的第二种添加算子的方法:直接在PyTorch里添加C++拓展。
PyTorch Extension A+B
用Python的setuptools也可以编译一些C++项目但,由于其头文件目录、依赖的库目录这些编译选项需要手动设置,setuptools仅适用于编译比较简单的C++项目。
在同文件夹中,编写以下的setup.py文件:
1 | from setuptools import setup |
在这个源文件中,要改的就是以下三个路径(代码块中显示的是我的路径):
1 | include_dirs = [r'D:\OpenCV\opencv\build\include'] |
这三个路径用于配置OpenCV的编译选项,分别表示OpenCV的包含目录(头文件目录)、静态库目录、静态库名。用Visual Studio导入过第三方库的,肯定对这三个选项不陌生。
如果是在 Linux 上,前两个路径大概是”/usr/local/include/opencv2”, “/usr/local/lib” 。最后的库名填写
opencv_core即可。
至于PyTorch相关的编译选项,我们不需要手动设置。这是因为我们用了PyTorch封装的添加C++拓展接口,PyTorch有关的路径已经被填好了。
1 | setup(name='my_add', |
在调用setup时,name是整个项目的名字,可以随便取。my_ops和刚刚一样,是命名空间的名字,我们还是保持my_ops这个名字。op2.cpp就是要编译的源文件了,这里我们待会再讨论。剩下的参数这些传进去就行了。
我们再在op.cpp的基础上新建一个新的C++源文件op2.cpp:
1 |
|
其实修改的就是这一行TORCH_LIBRARY(my_ops, m)->PYBIND11_MODULE(my_ops, m),没有调用TorchScript的绑定接口,而是直接用Pybind绑定了C++函数。
接下来,在当前文件夹下运行命令python setup.py install即可编译刚刚的C++源文件了。成功的话大概会有Finished processing dependencies for my-add==0.0.0这样的提示。
编译结束后,我们在原来test_add.py的基础上添加一些单元测试,看看用这种新方法编译完C++拓展后怎么调用C++函数。
1 | def test_add2(): |
由于我们刚刚编译了一个命名空间为my_ops的包,我们可以用import my_ops导入这个刚刚编译好的库了。现在调用C++函数的方法变成了my_ops.my_add,其他地方都没有变化。
运行pytest test_add.py::test_add2可以单独测试这一个函数。当然懒的话直接pytest可以把刚刚那个测试和这个测试一起做一遍。单元测试通过就说明我们成功运行了C++拓展。
事实上,这种安装方式还是不够友好。由于我们用到了OpenCV,OpenCV的库路径还是要手动设置。这种安装方式只有在除PyTorch本身外不需要任何第三方库时比较友好。不然的话要么让用户自己手动设置路径,要么在代码库里引用别的开源库,再一个一个重写路径。大型项目还是用CMake等编译系统来编译比较友好。
总结
在这篇文章中,我介绍了两种在PyTorch里调用C++新算子的方法。只要看懂了这篇文章,就算是彻底打通了PyTorch与C++的桥梁,以后写代码可以专注于C++算子的实现及PyTorch对算子的封装,剩下的绑定算子的内容直接套这个模板就行。
两种算子实现方法的区别主要在于编译选项的设置上和用户在编译算子的体验上。应根据项目的实际情况选择一种方案。
这篇文章强行调用OpenCV实现了Tensor加法,看上去是多此一举,实际上这是为了展示如何在添加自定义算子时使用第三方库。但为了简化他人编译的过程,实际实现算子时最好只用原本的PyTorch API。
FAQ
运行LibTorch的示例程序,无法定位程序输入点 xxxxx 于动态链接库 xxxxx
这个问题找了我老半天,就找到2~3个相关的答案,全是治标不治本的方法。
有人说,是动态库路径的问题。我测试了一下,直接运行编译好的程序会报错,但是把程序放到LibTorch的动态库目录下就不会报错。我已经隐隐约约地感觉到,不是动态库找不到,而是动态库路径的优先顺序出了问题。
果不其然,最后我在这篇文章里找到了问题的真正原因:Cuda的动态库和LibTorch的冲突了(PyTorch和Cuda要背大锅)。那篇文章中暴力删掉了Cuda的动态库,但是温柔的我们绝对不要这样做。按照前面章节的内容,调整LibTorch与Cuda的路径优先级即可。

貌似官方教程提到了类似的错误。这里再提供一种可能的解决问题的思路(反正我没试)。
[WinError 126] 找不到指定的模块
这个问题说明Python的PyTorch库版本和下载的LibTorch C++版本不一致。用pip show torch查看当前的PyTorch版本,去重新下载对应的LibTorch即可。
OSError: xxx Undefined symbol (Linux)
要把 LibTorch 的动态库加入 LD_LIBRARY_PATH 里。
有关博客“学习”分类下子类别的说明
貌似之前说明过一次,这里再整理一遍。
- 工具用法指南:几乎没有技术含量的,把下载安装过程的踩坑过程原封不动地讲一遍。
- 知识记录:对现有成体系知识的描述,尤其会写教科书、公开课上的知识,较少我个人的见解。
- 知识整理:对某一工具、知识、技术的说明,主要以我个人的见解、整理为主。
另外,“学习”类别和“记录”类别挺容易混淆的。这里我再做个规定:“记录”以具体的任务为导向,比如先有要写的作业、要看的论文、要做的项目、规划好的旅游计划,再对这些事情进行描述。而“学习”中包含的文章,更多是一种主观的,以学到东西为目的而写的文章。如果我看了一篇论文,只写论文的内容的话,会分到“记录”里;如果我想调研一个主题的文章,会把调研结果放到“学习-笔记”里;如果我看了很多论文,有了原创性非常强的一篇描述知识的文章,会放到“知识分享”(未来的“创作-知识”)里。