我在学习今年的一篇和人脸生成相关的论文时,看到了一个约束人脸相似度的 loss。这个 loss 基于经典的 ArcFace 人脸识别网络。ArcFace 是 2019年发表的,这么久了还有人用,说明这是一篇适用性很强的工作。于是,我顺手学了一下 ArcFace 的相关背景。在这篇文章中,我将简要分享 ArcFace 人脸识别网络的发展历程,并介绍如何快速利用它的开源 PyTorch 项目计算任意两幅人脸的相似度。
人脸识别与 ArcFace
人脸识别是在深度学习时代取得较大突破的一项任务:给定一个登记了 N 个人的人脸数据库,再输入一幅人脸,输出这个人是否是 N 个人中的某一个。
多数深度学习算法会用一个 CNN 来提取所有人脸图片的特征,如果输入的图片特征和数据库里的某个特征的向量相似度大于某个阈值,就说明识别成功。也就是说,人脸识别的关键在于如何用 CNN 生成一个「好」的特征。特征的「好」体现在两点上:1) 同一个人的人脸特征要尽可能相似;2) 不同人的人脸之间的特征要尽可能不同。
为了达成这个目的,研究者提出了不同的学习特征的方法。最直观的方式是像学习词嵌入一样,用一个具体的任务来学习特征提取。恰好,人脸识别可以天然地被当成一个多分类任务:对于一个有 N 个人的人脸训练集,人脸识别就是一个 N 分类任务。只要在特征提取后面加一个线性层和一个 softmax 就可以做多分类了。训练好多分类器后,扔掉线性层和 softmax 层,就得到了一个特征提取器。
这种基于 softmax 分类器的学习方法确实能够区分训练集中的人脸,但在辨别开放人脸数据集时表现不佳。这是因为 softmax 的学习目标仅仅是区分不同类别的人脸,而没有要求这种区分有多么分明。后续的多篇工作,包括 ArcFace,都是在改进训练目标 softmax,使得每类对象之间有一个较大的间隔。
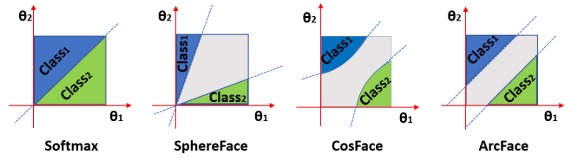
为了让不同的类别之间存在间隔,研究者们详细分析了 softmax 函数。假设$x \in \mathbb{R}^d$是人脸图片提取出的维度为$d$的特征向量,它属于$N$类里的第$y$类。softmax 前的线性层的参数是$W\in \mathbb{R}^{d\times N}, b\in \mathbb{R}^N$。则基于 softmax 的多分类误差可以写成:
其中,向量内积$W^T_jx$可以展开为:$W^T_jx=||W^T_j|| ||x|| cos \theta_j$,其中$\theta_j$是两个向量的夹角。如果对向量$W^T_j$和$x$都做归一化的话,再令$b=0$,则新的误差可以写成:
也就是说,对于这种归一化的多分类误差,对误差产生贡献的只有特征向量和$W$的列向量的夹角。那么,我们就可以换一个视角来看待这个误差:$W$其实是$N$个维度为$d$的向量的数组,它们表示了$N$个人脸类别的中心特征向量。误差要求每个特征和它对应的中心向量的夹角更小。
为了让不同的类别之间有更大的间隔,相同类别内部更加聚拢,ArcFace 在误差的$cos$中加了一个常数项。
直观上来看,加这一项就是把角度远离类别中心的惩罚扩大,使得各个类别的数据都更加靠近中心。这一优化是有效的。作者做了一个简单的实验,用8类人脸的训练集训练了一个维度为2的特征。其可视化结果如下(线是各个类别中心的方向向量,点是样本的特征向量):
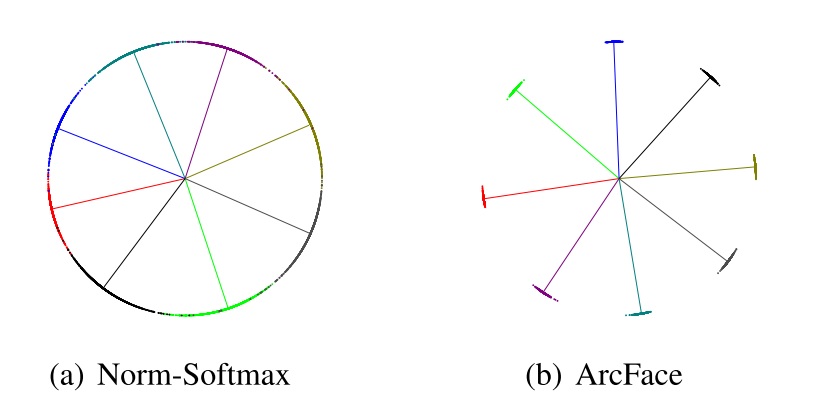
ArcFace 的核心思想就是其 loss 的设计。ArcFace 的网络架构没有特别的要求,一般使用 ResNet 就行。
使用 ArcFace 开源项目
其实用这个库的时候可以完全不懂 ArcFace 的原理。
可能是由于「ArcFace」这个名字和其他项目撞车了,ArcFace 的官方 GitHub 仓库叫做 insightface。其 PyTorch 实现的网址是 https://github.com/deepinsight/insightface/tree/master/recognition/arcface_torch。
早期该论文没有官方的 PyTorch 实现。有人用 PyTorch 复现了该论文(https://github.com/TreB1eN/InsightFace_Pytorch )。我使用的项目是这个复现版,它更完整一点,包含了人脸预处理代码。
人脸识别任务最简单的例子是输出两幅人脸的相似度。接下来我将介绍如何安装这个项目,并用它来编写一个简单的计算人脸相似度的 demo。
安装这个库很方便,只要一键 git clone 就行。这个项目基本不依赖什么第三方库,环境里有 PyTorch,NumPy 等常见库就行了。
1 | git clone git@github.com:TreB1eN/InsightFace_Pytorch.git |
获取仓库后,在 README 的链接里下载 IR-SE50 模型 model_ir_se50.pth。随便放在哪个目录里。比如下载 IR-SE50 @ Onedrive 。
最后,还要准备一下测试图片。我很机智地使用了吴恩达《深度学习专项》里讲人脸识别时用到的图片,分别命名为face1.jpg, face2.jpg, face3.jpg。

准备就绪后,就可以编写 demo 了。在做一个人脸相关的项目时,一般会先对人脸做预处理,让所有的人脸图片都有相同的分辨率,且五官的位置对齐。我们的 demo 也是先利用了项目中的人脸预处理库对齐人脸,再调用模型计算相似度。这三张图片的对齐结果如下:

这个demo会输出第一张人脸和第二、第三张人脸之间的相似度。完整的 demo 代码如下(注意修改其中的路径):
1 | from model import Backbone |
可能是 NumPy 更新的原因,代码在读取.npy时少了allow_pickle=True,会报错。要在mtcnn_pytorch/src/get_nets.py的几个np.load的地方加上allow_pickle=True。不知道在哪加也没关系,报错了再补上即可。
1 | # mtcnn_pytorch/src/get_nets.py |
修改完毕后,直接运行脚本就行了。其输出大致为:
1 | torch.Size([1, 3, 112, 112]) |
第一个输出是模型输入张量的形状。第二个输出是模型输出的特征的性质。了解这两个形状信息有助于我们调用此库。
第三个输出是第一、第二张人脸的cos相似度,第四个输出是第二、第三张人脸的cos相似度。我们已经事先知道了,第一和第二张人脸图片是同一个人,第一和第三张人脸图片是两个人。所以说,这个输出结果非常正确。
在我们自己的人脸项目中,一般都会准备好人脸预处理的代码。因此,在调用这个库时,可以只把 model.Backbone 里的代码复制过去,只使用该项目的模型即可。使用时注意输入输出的形状要求。
参考资料
ArcFace 论文:ArcFace: Additive Angular Margin Loss for Deep Face Recognition
官方仓库:https://github.com/deepinsight/insightface
PyTorch 复现仓库:https://github.com/TreB1eN/InsightFace_Pytorch
《人脸识别的 loss》:https://zhuanlan.zhihu.com/p/34404607 https://zhuanlan.zhihu.com/p/34436551