今天,一则重磅消息席卷了 AI 圈:OpenAI 发布了视频模型 Sora,能根据文本生成长达一分钟的高质量 1920x1080 视频,生成能力远超此前只能生成 25 帧 576x1024 图像的顶尖视频生成模型 Stable Video Diffusion。
同时,OpenAI 也公布了一篇非常简短的技术报告。报告仅大致介绍了 Sora 的架构及应用场景,并未对模型的原理详加介绍。让我们来快速浏览一下这份报告,看看科研人员从这份报告中能学到什么。
技术报告链接:https://openai.com/research/video-generation-models-as-world-simulators
这篇文章没怎么贴视频,感兴趣的话可以对照着原报告中的视频阅读。
LDM 与 DiT 的结合
简单来说,Sora 就是 Latent Diffusion Model (LDM) [1] 加上 Diffusion Transformer (DiT) [2]。我们先简要回顾一下这两种模型架构。
LDM 就是 Stable Diffusion 使用的模型架构。扩散模型的一大问题是计算需求大,难以拟合高分辨率图像。为了解决这一问题,实现 LDM时,会先训练一个几乎能无损压缩图像的自编码器,能把 512x512 的真实图像压缩成 64x64 的压缩图像并还原。接着,再训练一个扩散模型去拟合分辨率更低的压缩图像。这样,仅需少量计算资源就能训练出高分辨率的图像生成模型。
LDM 的扩散模型使用的模型是 U-Net。而根据其他深度学习任务中的经验,相比 U-Net,Transformer 架构的参数可拓展性强,即随着参数量的增加,Transformer 架构的性能提升会更加明显。这也是为什么大模型普遍都采用了 Transformer 架构。从这一动机出发,DiT 应运而生。DiT 在 LDM 的基础上,把 U-Net 换成了 Transformer。
顺带一提,Transformer 本来是用于文本任务的,它只能处理一维的序列数据。为了让 Transformer 处理二维图像,通常会把输入图像先切成边长为 $p$ 的图块,再把每个图块处理成一项数据。也就是说,原来边长为 $I$ 的正方形图片,经图块化后,变成了长度为 $(I/p)^2$ 的一维序列数据。
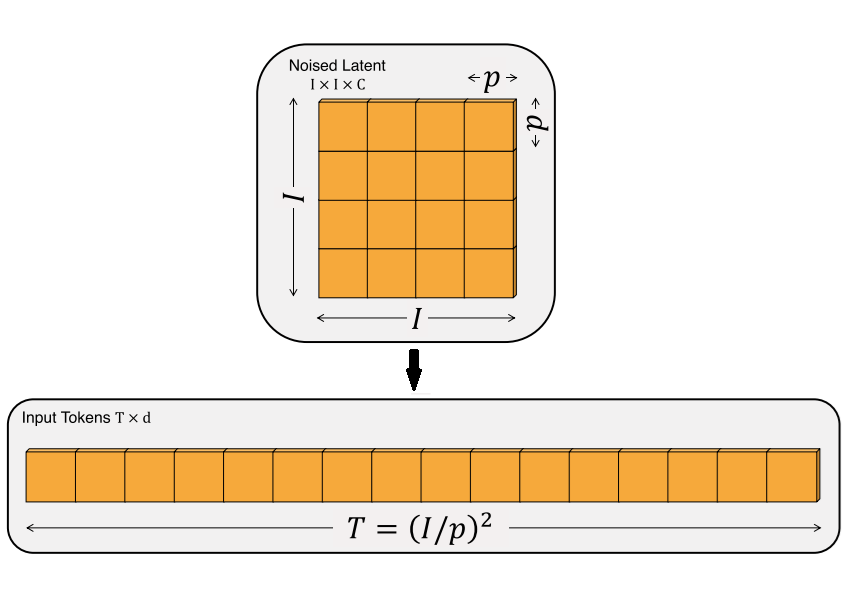
Transformer 是一种和顺序无关的计算。比如对于输入”abc”和”bca”,Transformer 会输出一模一样的值。为了描述数据的先后顺序,使用 Transformer 时,一般会给数据加一个位置编码。
Sora 是一个视频版的 DiT 模型。让我们看一下 Sora 在 DiT 上做了哪些改进。
时空自编码器
在此之前,许多工作都尝试把预训练 Stable Diffusion 拓展成视频生成模型。在拓展时,视频的每一帧都会单独输入进 Stable Diffusion 的自编码器,再重新构成一个压缩过的图像序列。而 VideoLDM[3] 工作发现,直接对视频使用之前的图像自编码器,会令输出视频出现闪烁的现象。为此,该工作对自编码器的解码器进行了微调,加入了一些能够处理时间维度的模块,使之能一次性处理整段压缩视频,并输出连贯的真实视频。
Sora 则是从头训练了一套能直接压缩视频的自编码器。相比之前的工作,Sora 的自编码器不仅能在空间上压缩图像,还能在时间上压缩视频长度。这估计是为什么 Sora 能生成长达一分钟的视频。
报告中提到,Sora 也能处理图像,即长度为1的视频。那么,自编码器怎么在时间上压缩长度为1的视频呢?报告中并没有给出细节。我猜测该自编码器在时间维度做了填充(比如时间被压缩成原来的 1/2,那么就对输入视频填充空数据直至视频长度为偶数),也可能是输入了视频长度这一额外约束信息。
时空压缩图块
输入视频经过自编码器后,会被转换成一段空间和时间维度上都变小的压缩视频。这段压缩视频就是 Sora 的 DiT 的拟合对象。在处理视频数据时,DiT 较 U-Net 又有一些优势。
之前基于 U-Net 的去噪模型在处理视频数据时(如 [3]),都需要额外加入一些和时间维度有关的操作,比如时间维度上的卷积、自注意力。而 Sora 的 DiT 是一种完全基于图块的 Transformer 架构。要用 DiT 处理视频数据,不需要这种设计,只要把视频看成一个 3D 物体,再把 3D 物体分割成「图块」,并重组成一维数据输入进 DiT 即可。和原本图像 DiT 一样,假设视频边长为 $I$,时长也为 $I$,要切成边长为 $p$ 的图块,最后会得到 $(I/p)^3$ 个数据。
报告没有给出视频图块化的细节。
处理任意分辨率、时长的视频
报告中反复提及,Sora 在训练和生成时使用的视频可以是任何分辨率(在 1920x1080 以内)、任何长宽比、任何时长的。这意味着视频训练数据不需要做缩放、裁剪等预处理。这些特性是绝大多数其他视频生成模型做不到的,让我们来着重分析一下这一特性的原理。
Sora 的这种性质还是得益于 Transformer 架构。前文提到,Transformer 的计算与输入顺序无关,必须用位置编码来指明每个数据的位置。尽管报告没有提及,我觉得 Sora 的 DiT 使用了类似于 $(x, y, t)$ 的位置编码来表示一个图块的时空位置。这样,不管输入的视频的大小如何,长度如何,只要给每个图块都分配一个位置编码,DiT 就能分清图块间的相对关系了。
相比以前的工作,Sora 的这种设计是十分新颖的。之前基于 U-Net 的 Stable Diffusion 为了保证所有训练数据可以统一被处理,输入图像都会被缩放与裁剪至同一大小。由于训练数据中有被裁剪的图像,模型偶尔也会生成被裁剪的图像。生成训练分辨率以外的图像时,模型的表现有时也会不太好。SDXL [4] 的解决方式是把裁剪的长宽做为额外信息输入进 U-Net。为了生成没有裁剪的图像,只要令输入的裁剪长宽为 0 即可。类似地,SDXL 也把图像分辨率做为额外输入,使得 U-Net 学习不同分辨率、长宽比的图像。相比 SDXL,Sora 的做法就简洁多了。
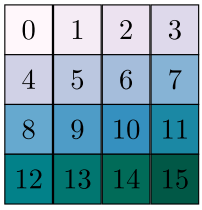
之前基于 DiT 的模型 (比如华为的 PixArt [5])似乎都没有利用到 Transformer 可以随意设置位置编码这一性质。DiT 在处理输入图块时,会先把图块变形成一维数据,再从左到右编号,即从从左到右,从上到下地给二维图块组编号。这种位置编码并没有保留图像的二维空间信息,因此,在这种编码下,模型的输入分辨率必须固定。比如对于下面这个$4\times4$的图块组,如果是从左到右、从上到下编码,模型等于是强行学习到了「1号在0号右边、4号在0号下面」这样的位置信息。如果输入的图块形状为 $4 \times 5$,那么图块间的相对关系就完全对不上了。而如果像 Sora 这样以视频图块的 $(x, y, t)$ 来生成位置编码的话,就没有这种问题了,输入视频可以是任何分辨率、任何长度。
Transformer 在视频生成的可拓展性
前文提过,Transformer 的特点就是可拓展性强,即模型越大,训练越久,效果越好。报告中展示了1倍、4倍、16倍某单位训练时间下的生成结果,可以看出模型确实一直有进步。

语言理解能力
之前大部分文生图扩散模型都是在人工标注的图片-文字数据集上训练的。后来大家发现,人工标注的图片描述质量较低,纷纷提出了各种提升标注质量的方法。Sora 复用了自家 DALL·E 3 的重标注技术,用一个训练的能生成详细描述的标注器来重新为训练视频生成标注。这种做法不仅解决了视频缺乏标注的问题,且相比人工标注质量更高。Sora 的部分结果展示了其强大了抽象理解能力(如理解人和猫之间的交互),这多半是因为视频标注模型足够强大,视频生成模型学到了视频标注模型的知识。但同样,视频标注模型的相关细节完全没有公开。
其他生成功能
- 基于已有图像和视频进行生成:除了约束文本外,Sora 还支持在一个视频前后补充内容(如果是在一张图片后面补充内容,就是图生视频)。报告没有给出实现细节,我猜测是直接做了反演(inversion)再把反演得到的隐变量替换到随机初始隐变量中。
- 视频编辑:报告明确写出,只用简单的 SDEdit (即目前 Stable Diffusion 中的图生图)即可实现视频编辑。
- 视频内容融合:可能是对两个视频的初始隐变量做了插值。
- 图像生成:当然,Sora 也可以生成图像。报告表明,Sora 可以生成最大 2048x2048 的图像。
涌现出的能力
通过学习大量数据,Sora 还涌现出一些意想不到的能力。
- 3D 一致性:视频中包含自然的相机视角变换。之前的 Stable Video Diffusion 也有类似发现。
- 长距离连贯性:AI 生成出来的视频往往有物体在中途突然消失的情况。而 Sora 有时候能克服这一问题。
- 与世界的交互:比如在描述画画的视频中,画纸上的内容随画笔生成。
- 模拟数字世界:报告展示了在输入文本有”Minecraft”时,模型能生成非常真实的 Minecraft 游戏视频。这大概只能说明模型的拟合能力太强了,以至于学会了生成 Minecraft 这一种特定风格的视频。
局限性
报告结尾还是给出了一些失败的生成示例,比如玻璃杯在桌子上没有摔碎。这表明模型还不能完全学会某些物理性质。然而,我觉得现阶段 Sora 已经展示了足够强大的学习能力。想模拟现有视频中已经包含的物理现象,只需要增加数据就行了。
总结
Sora 是一个惊艳的视频生成模型,它以卓越的生成能力(高分辨率、长时间)与生成质量令一众同期的视频生成模型黯然失色。Sora 的技术报告非常简短,不过我们从中还是可以学到一些东西。从技术贡献上来看,Sora 的创新主要有两点:
- 让 LDM 的自编码器也在视频时间维度上压缩。
- 使用了一种不限制输入形状的 DiT
其中,第二点贡献是非常有启发性的。DiT 能支持不同形状的输入,大概率是因为它以视频的3D位置生成位置编码,打破了一维编码的分辨率限制。后续大家或许会逐渐从 U-Net 转向 DiT 来建模扩散模型的去噪模型。
我认为 Sora 的成功有三个原因。前两个原因对应两项创新。第一,由于在时间维度上也进行了压缩,Sora 最终能生成长达一分钟的视频;第二,使用 DiT 不仅去除了视频空间、时间长度上的限制,还充分利用了 Transformer 本身的可拓展性,使训练一个视频生成大模型变得可能。第三个原因来自于视频标注模型。之前 Stable Diffusion 能够成功,很大程度上是因为有一个能够关联图像与文本的 CLIP 模型,且有足够多的带标注图片。相比图像,视频训练本来就少,带标注的视频就更难获得了。一个能够理解视频内容,生成详细视频标注的标注器,一定是让视频生成模型理解复杂文本描述的关键。除了这几点原因外,剩下的就是砸钱、扩大模型、加数据了。
Sora 显然会对 AIGC 社区产生一定影响。对于 AIGC 爱好者而言,他们或许会多了一些生成创意视频的方法,比如给部分帧让 Sora 来根据文本补全剩余帧。当然,目前 Sora 依然不能取代视频创作者,长视频的质量依然有待观察。对于正在开发相似应用的公司,我觉得他们应该要连夜撤销之前的方案,转换为这套没有分辨率限制的 DiT 的方案。他们的压力应该会很大。对于相关科研人员而言,除了学习这种较为新颖的 DiT 用法外,也没有太多收获了。这份技术报告透露出一股「我绝对不会开源」的意思。没有开源模型,普通的研究者也就什么都做不了。新技术的诞生绝对不可能靠一家公司,一个模型就搞定。像之前的 Stable Diffusion,也是先开源了一个基础模型,科研者和爱好者再补充了各种丰富的应用。我呼吁各大公司尽快训练并开源一个这种不限分辨率的 DiT,这样科研界或许会抛开 U-Net,基于 DiT 开发出新的扩散模型应用。
参考论文
- Latent Diffusion Model, Stable Difusion: High-Resolution Image Synthesis with Latent Diffusion Models
- DiT: Scalable Diffusion Models with Transformers
- VideoLDM: Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models
- SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
- PixArt-α: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis