Video diffusion models generally have the problem that video quality decreases with the increase of video length. Therefore, the authors of Diffusion Forcing propose a new sequence generation paradigm: Noise of different levels is independently added to each element in the sequence when training sequence diffusion models. The effectiveness of this paradigm is verified by simple video generation and decision-making tasks. I will introduce this work mainly from the perspective of video generation.
Paper arxiv: https://arxiv.org/abs/2407.01392
Previous work
As we will see later, Diffusion Forcing is closely related to the two previous mainstream sequence generation paradigms: autoregressive generation (AR) and full-sequence diffusion models.
In autoregressive sequence generation, the model continually predicts the next (n-th) element based on the first n-1 elements of the sequence. AR is the most common in NLP and is used by both RNN and Transformer.
The diffusion models can directly generate data of any shape. If we treat video not as a sequence of images, but as a “3D image”, we can directly extend a 2D image diffusion model to a 3D video diffusion model. This approach is referred to in this paper as the “full-sequence diffusion model”. Early works using this approach included Video Diffusion Models by the authors of DDPM. The authors of Stable Diffusion also proposed a similar work, Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models (Video LDM), based on the LDM.
The full-sequence diffusion models can only generate fixed-length video. In order to extend it to long video generation, it has to be combined with AR. However, the quality of frames generated in this method does not match the training set, causing continuous quality degradation in the autoregressive process. Inspired by Cascaded Diffusion Models, Stable Video Diffusion and other works try to mitigate this problem by adding noise to constrained image/video frames.
AR-Diffusion: Auto-Regressive Diffusion Model for Text Generation further explores the combination of AR and full-sequence diffusion models: when generating text with diffusion models, the noise for each token varies, and the earlier the token, the less the noise. Coincidentally, FIFO-Diffusion: Generating Infinite Videos from Text without Training shows how different video frames can be generated with different levels of noise on a pre-trained video diffusion model. Perhaps inspired by these works, Diffusion Forcing systematically explores how to independently add noise to sequence elements during training.
Research Motivation
The author of this paper finds the shortcomings of the AR and full-sequence diffusion models and considers that the two generative paradigms are complementary:
- AR cannot add new optimization objectives in inference time, and there is a quality degradation problem caused by the mismatch of training and inference samples.
- Full-sequence diffusion models cannot generate sequences of varying lengths.
Conversely,
- Full-sequence diffusion models can add Classifier-guidance in inference time and there is only a little degradation within training sequence length.
- AR can generate sequences of varying lengths.
Then, is it possible to combine the two? During sampling, we want the sequence to be generated autoregressively. Meanwhile, from the aspect of noise levels, we hope that each element can be gradually generated from full noise to full clarity. Here is what Diffusion Forcing does: When generating a sequence, the earlier elements have less noise, while the newer elements have more noise. All the elements of different noise levels are denoised at the same time in diffusion models. For example, if the sampling requires 3 DDIM steps and we want to generate 3 frames, a denoising step would make $[x_1^{1/3\cdot T}, x_2^{2/3\cdot T}, x_3^{T}]$ to $[x_1^0, x_2^{1/3\cdot T}, x_3^{2/3\cdot T}]$.
To implement this kind of sampling, we must modify the training approach of diffusion models so that the model can correctly denoise even if the noise levels of inputs are not uniform. Unlike previous works, the authors find that we do not have to fix the noise levels of each element in training as we do in sampling, but can independently sample the noise levels of each frame.
Simple Video Generation Models
The idea of this paper is very concise. Based on the video DDPM, it just changes the noise levels of each frame in training and sampling. To further understand the method of this work, let’s look at the method and experiment of video generation in this paper.
Overall, the training method is the same as the DDPM epsilon-prediction, but with different frame noise levels.
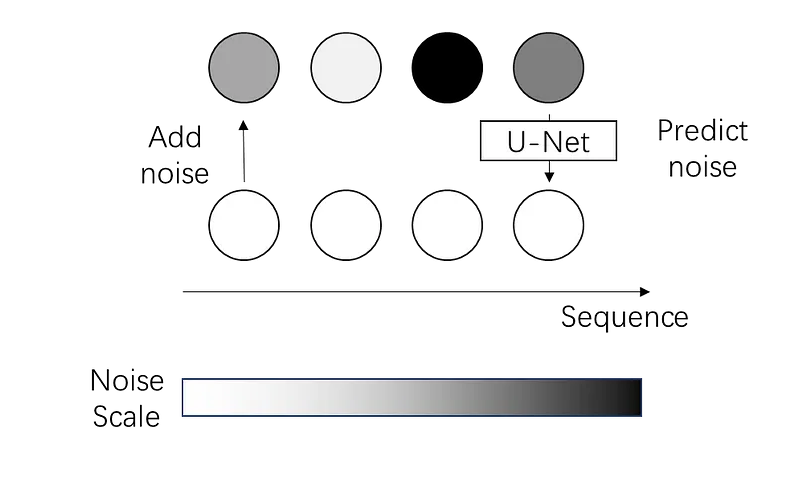
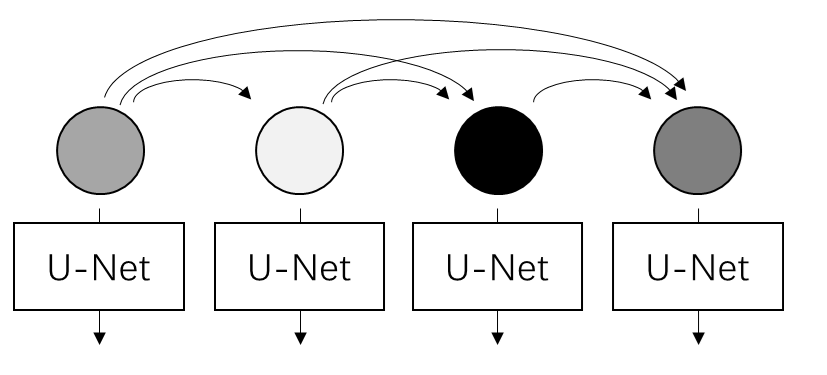
In terms of inter-frame relationships, Diffusion Forcing models causal relationships, meaning that the current frame can only see information from previous frames.
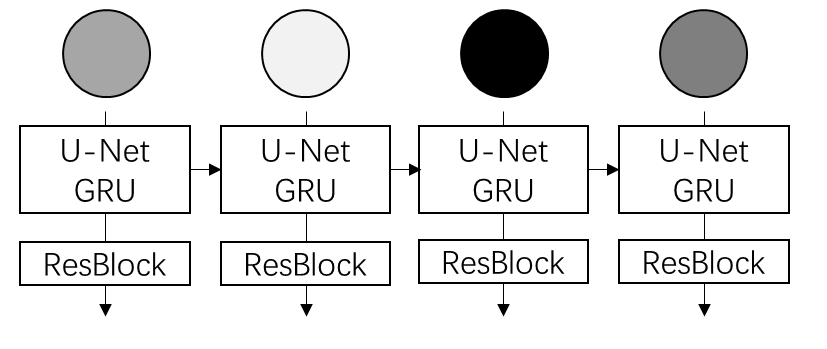
Specifically, this work uses the hidden variables of RNN (exactly GRU) to model the information passed from previous frames. After introducing RNN, the paper complicates the simple formulas of DDPM. I do not recommend readers delve into the contents of the RNN part.
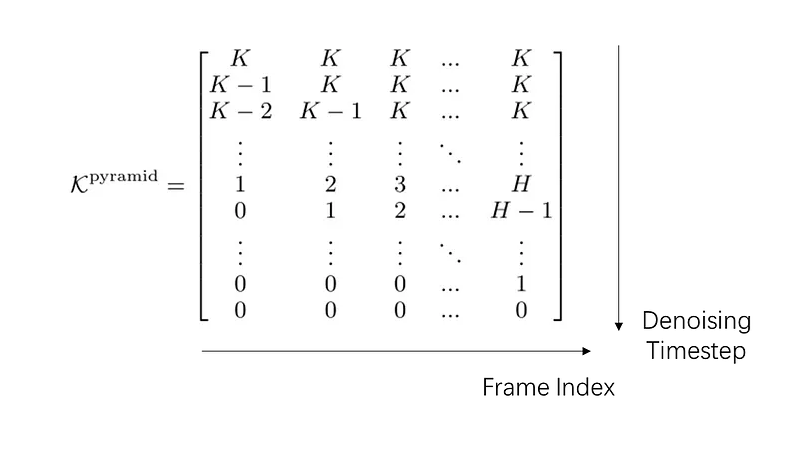
Because of the different noise levels in different frames, we now need to define a two-dimensional noise schedule table for different frames and denoising steps. To create different noise levels at the beginning, the denoising timestep of newer frames will stay in place. The details of the simultaneous denoising algorithm are introduced in the appendix of the paper.
The authors find that Diffusion Forcing can be extended to video generation with infinite length: when generating the next segment, the RNN’s initial hidden state is set to the output of the RNN of the previous segment without a sliding window.
The authors train two baseline models with the same RNN architecture: an autoregressive model and a full-sequence causal diffusion model. The qualitative results show that the results of Diffusion Forcing are better than those of the baseline methods, whether within the training video length or beyond the length. The results can be viewed on the official project website:
https://boyuan.space/diffusion-forcing/
Critical Analysis
At the beginning of the paper, it says that AR lacks the capacity to add conditions in inference. But this is not fatal for video generation, because you can usually add conditions in training and use Classifier-free Guidance in inference.
The authors say they implemented Diffusion Forcing with RNN for simplicity. But it is clear that 3D U-Net should be the easiest and most intuitive way to do this. After all, the earliest video diffusion model was done with 3D U-Net. In the official warehouse, an undergraduate student helped them implement a 3D U-Net with temporal attention that works better than the original video model.
I think the video generation baselines in the paper are not powerful enough. Most autoregressive video generation / image-to-video generation models employ a noise augmentation method proposed in Cascaded Diffusion, which adds noise to the condition image and inputs this noise scale as an additional condition to the denoising model. This design is similar to the Diffusion Forcing’s principle. To illustrate the benefits of the new approach, it is necessary to compare Diffusion Forcing with these more powerful baseline AR models.
The design of the full-sequence video diffusion model looks strange. The motivation of this type of video diffusion model is to treat the video as a 3D image, allowing the exchange of information between frames, and only ensuring the coherence of the video within the training length. The authors now implement a casual version of the full-sequence video model using RNN, which is certainly not as good as the non-casual version. Although the authors say that Diffusion Forcing is always more coherent than the full-sequence diffusion models, I doubt whether Diffusion Forcing can beat non-casual full-sequence diffusion models.
The main benefit of Diffusion Forcing in video generation should be long video generation beyond training length. Therefore, it doesn’t matter if the full-sequence diffusion models perform better within the training length. The author should compare the method that directly combines autoregressive and full-sequence diffusion models to show the superiority of Diffusion Forcing in long video generation.
To sum up, I think the author’s experiment on the video generation task is not sufficient. Indeed, half the paper focuses on decision-making tasks, not just video generation tasks. I believe Diffusion Forcing will mitigate the degradation in long video generation. We may see better long video diffusion models using Diffusion Forcing by large companies. But the fundamental problem with long video generation is the loss of memory, an essential issue that Diffusion Forcing cannot solve.
My biggest inspiration from this work is that we always treat videos as complete 3D data, but forget that video can be treated as an image sequence. If the video is treated as 3D data, different frames can only see the information of other frames at the current denoising time through temporal attention. But for sequential data, we can do more design on the dependence of different frames, such as using different denoising levels like this work. I’ve long been thinking of a sequence-generation paradigm that has a stronger sequence dependency: Can we condition the current element with all information (including intermediate denoising outputs and intermediate variables of the denoising network) from all other elements in all denoising steps? This kind of strongly conditioned sequence model may be helpful to the consistency of multi-view generation and video segment generation. Since the generation is conditioned on another denoising process, any edits we make to this denoising process can naturally propagate to the current element. For example, in video generation, if the entire video is conditioned on the denoising process of the first frame, we can edit the first frame by any image editing method based on the diffusion model and propagate the changes to the whole video. Of course, I just provide a general idea, temporarily without considering the details, you are welcome to think in this direction.
One might also wonder if Diffusion Forcing could be extended to model pixel relationships. I don’t think there’s a problem with training at all. The problem is with inference: Diffusion Forcing needs to predefine the denoising schedule table for different elements and timesteps. For sequential data such as video, it is natural that the earlier the frame, the lower the noise level. However, how to define the denoising schedule of different pixels is not trivial.