At the beginning of this year, the multiscale autoregressive model VAR opened a new direction for image generation: by modeling image generation as next-scale prediction, and generating all pixels of the same scale at once per round, VAR achieves high-quality image generation at extremely fast speeds. Subsequently, many works have attempted to improve upon it. To compensate for the information loss introduced by the VQ (Vector Quantization) operation in VAR, HART (Hybrid Autoregressive Transformer) represents the lost information through a residual image and uses a lightweight diffusion model to generate this residual image. With these improvements, the authors used HART to accomplish text-to-image generation at a high resolution of $1024 \times 1024$. In this blog post, we will learn about the core methods of HART and analyze its experimental results on text-to-image tasks.
Paper link: https://arxiv.org/abs/2410.10812
Previous Work
All the autoregressive image generation methods involved in this paper originate from VQVAE and VQGAN. Before reading this paper, it is recommended that readers familiarize themselves with these two classic works.
HART is developed directly based on VAR (Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction), and some of its ideas are similar to MAR (Masked Autoregressive models, from the paper Autoregressive Image Generation without Vector Quantization). You are welcome to read my previous posts on these.
On top of the two-stage generation method in VQGAN, VAR makes the encoder output multiple scales of image tokens (instead of only the highest-scale tokens). During generation, VAR autoregressively generates token maps of different scales, and the token map at each scale is generated all at once in a single round of Transformer inference.
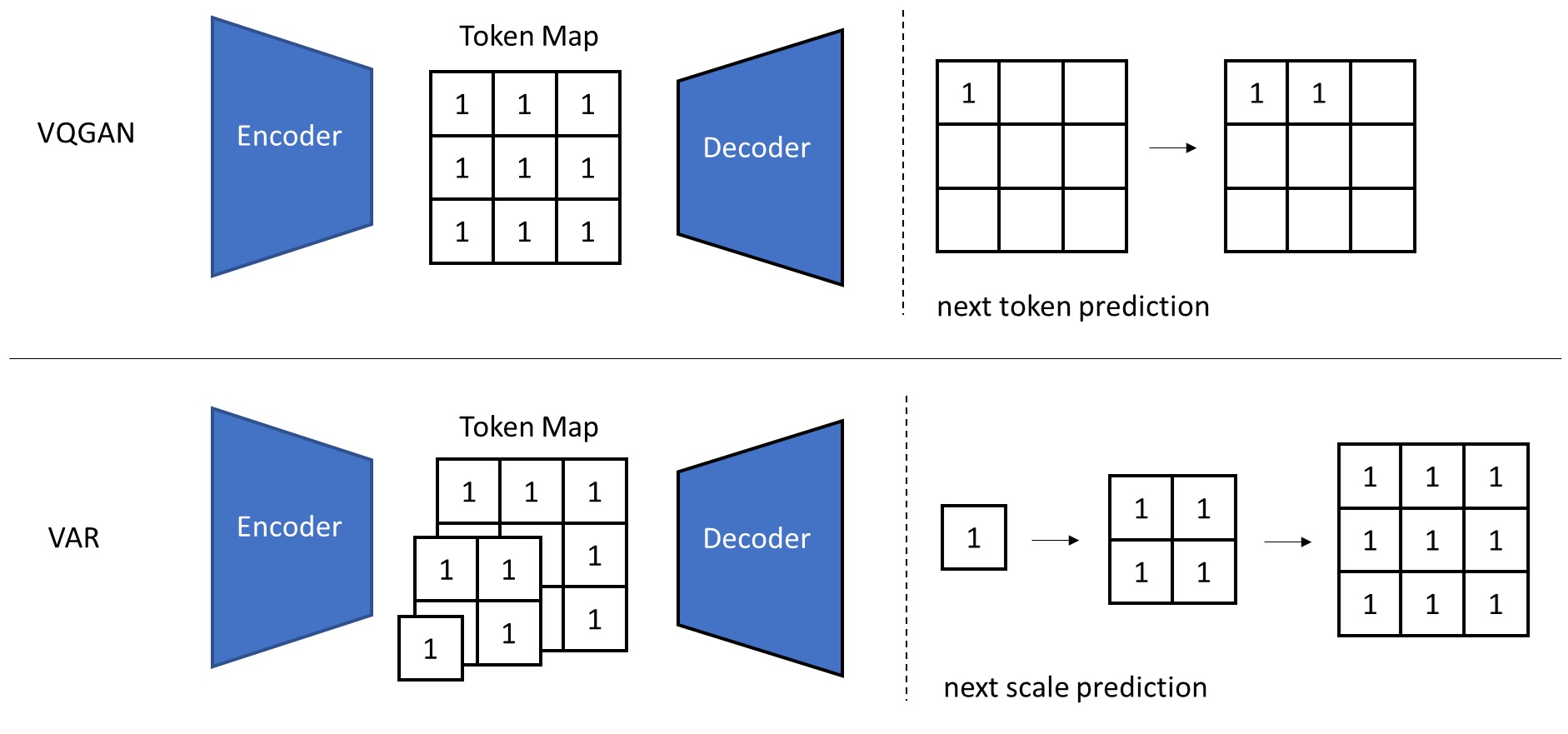
The VQ operation causes loss of information in the encoder output, so all image generation models using VQ-based autoencoders end up with slightly reduced quality. Methods like VAR and VQGAN have no choice but to use VQ because they model the distribution of tokens using a categorical distribution. To completely remove VQ, MAR replaces the categorical distribution with a diffusion model, allowing to use a more precise VAE for image compression.
Compensating for VQ’s Information Loss
To mitigate the quality degradation caused by VQ in VAR, HART uses a straightforward approach: since VQ inevitably causes information loss, we can treat that lost information as a residual image. After generating the image with the standard VAR, we use a diffusion model to generate the residual image. Adding the residual image to the original output yields a higher-quality final image.
Let’s get a direct feel for this idea from the figures in the paper. The first row shows reconstruction results from the VAR autoencoder and from HART’s hybrid autoencoder. Due to the VQ operation, the VQ autoencoder struggles to reconstruct the input image. The second row shows the original output from VAR and the residual image. We can see that after adding the residual image, the details become richer, no longer blurry as before.

In the next two sections, we will learn how HART respectively improves the token generation model of VAR and its autoencoder.
Generating Residual Image Using a Diffusion Model
To understand the entire method, we first need to see how HART’s “residual image” comes about. Therefore, let’s look at the modifications on the token generation model, then see the corresponding modifications in the autoencoder.
First, let’s review how VQ errors are introduced in VAR. VAR borrows the classic Laplacian pyramid idea to model token maps at multiple scales.

In other words, VAR does not split the full image into token maps at different resolutions but with the same content. Instead, it splits it into the lowest-resolution image plus the information lost at each scale. This “information loss” includes not only what comes from downsampling but also what results from VQ.
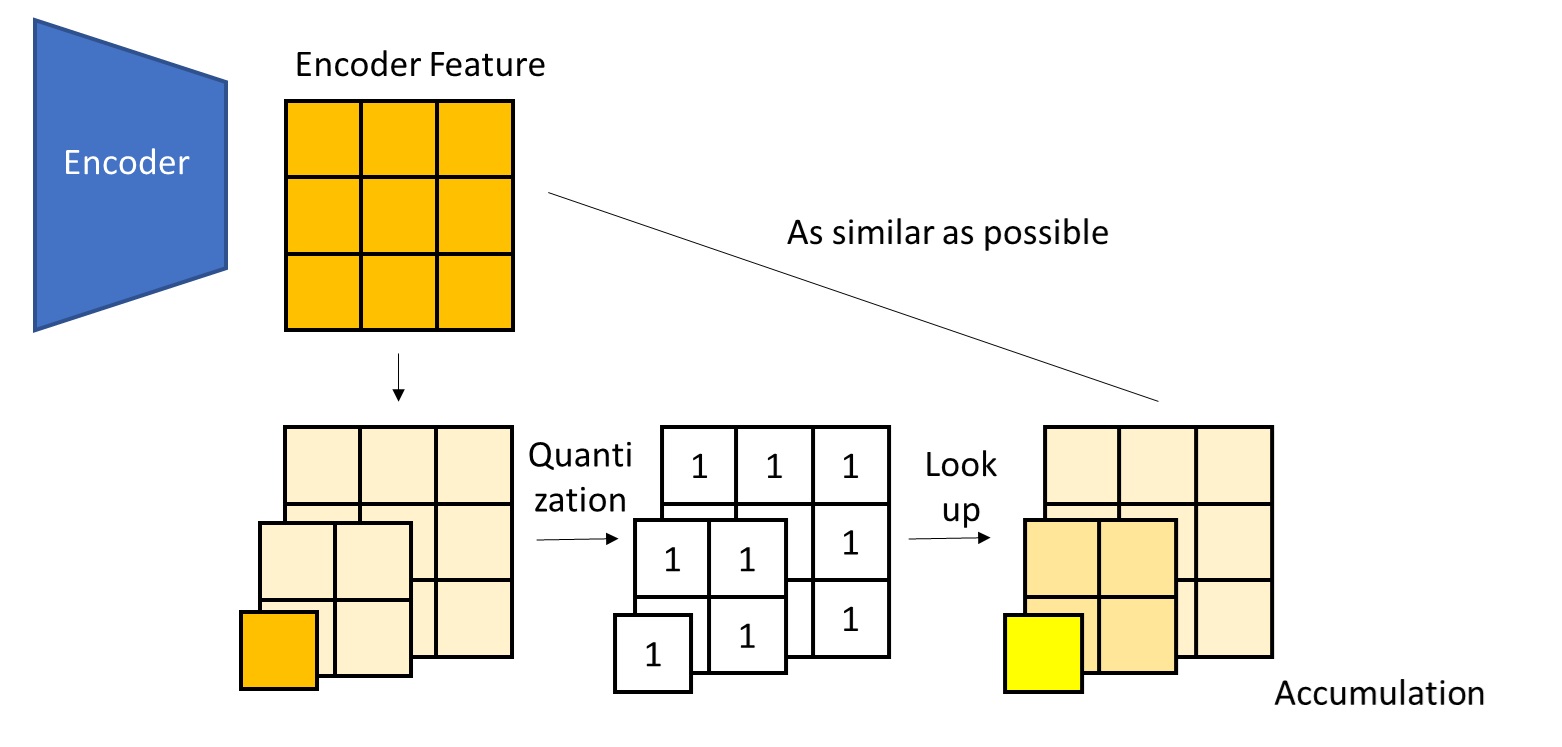
Even though the multiscale decomposition takes into account the information loss from VQ, the final reconstructed features (i.e., the decoder inputs, obtained by summing up the token lookups) still cannot perfectly match the encoder output features. The “residual image” HART wants to generate with a diffusion model is precisely the difference between the reconstructed features and the encoder output features shown in the figure above.
Unlike the discrete token maps, the residual image is continuous. To generate this continuous image, HART refers to MAR, employing an image-conditioned diffusion model. The goal of this diffusion model can be interpreted as: given the decoded image from the discrete token map, how do we use a diffusion model to generate additional details to improve image quality?
A schematic of HART’s generation model is shown below. The generation process before the last step is exactly the same as VAR. In the final step, the intermediate hidden state of the Transformer is fed into an MLP diffusion model. The diffusion model predicts a residual value independently for each token. In other words, this is not an image diffusion model but rather a per-token pixel diffusion model. Tokens are sampled independently from each other. Thanks to this independence assumption, HART can use a lightweight diffusion model to generate the residual image, adding almost no extra time to the overall generation process.

HART also changes VAR’s class conditioning to text conditioning. We will discuss this later in the experiments section.
AE + VQVAE Hybrid Autoencoder
Now that we know where HART’s residual image comes from, we can go back and look at the corresponding modifications in the autoencoder. Currently, the autoencoder decoder has two types of inputs: (1) the approximate reconstructed features formed by summing up the discrete tokens from VAR, and (2) the precise reconstructed features (equal to the encoder output features) when the residual image from HART is added. To handle both types of input simultaneously, the decoder is trained such that half of the time it takes the encoder’s output, and the other half it takes the reconstructed features from the discrete tokens. Of course, during generation, since the residual image is added, the decoder’s input can be considered the same as the encoder output.
The figure below uses “token” terminology differently from VAR. VAR calls both the encoder outputs and decoder inputs “feature maps,” and calls the index map after the VQ operation the “token map.” HART, however, calls the encoder outputs “continuous tokens” and the reconstructed features “discrete tokens”. In this blog post, we follow VAR’s naming. Likewise, what HART calls “residual token” is referred to here as the “residual image.”
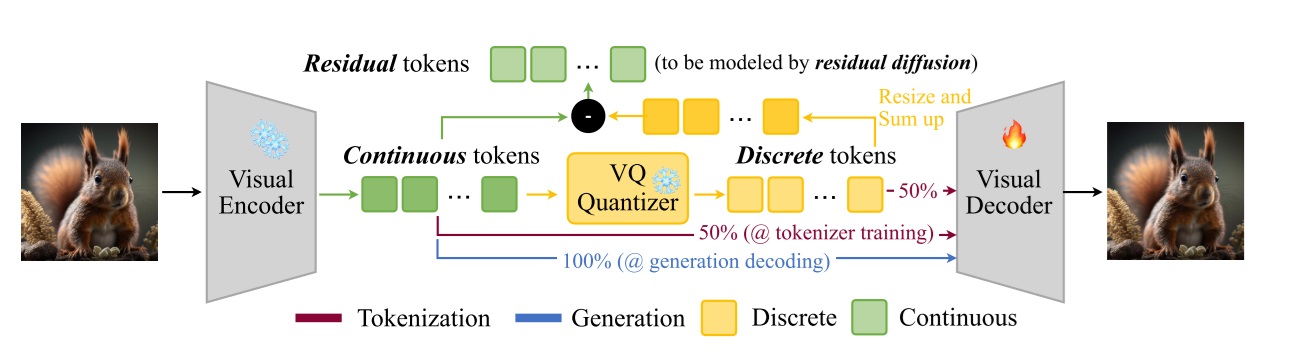
In this sense, HART’s hybrid autoencoder is like a VAE without KL loss (i.e., an ordinary autoencoder) and also like a VQVAE.
High-Resolution Text-to-Image Implementation Details
Let’s briefly see how HART extends the class-conditioned ImageNet $256 \times 256$ VAR to a $1024 \times 1024$ text-to-image model.
- Text conditioning: Instead of using cross-attention to incorporate text condition, as in many T2I models, HART follows VAR’s approach to class embeddings, adding the text embedding as the input to the first scale and as input to the AdaLN layers.
- Positional encoding: For the scale and image position indices, VAR uses learnable absolute position embeddings. HART, however, uses sinusoidal encoding for scale and 2D RoPE (rotary position encoding) for the image coordinates.
- Larger scales: In the original VAR, the largest token map side length is
16, HART appends additional side lengths21,27,36,48,64. - Lightweight diffusion model: Since the diffusion model only needs to model the distribution of single tokens, it has only 37M parameters and needs just 8 steps to achieve high-quality sampling.
Quantitative Results
- Let’s first look at the most popular “benchmark” metric—ImageNet $256 \times 256$ class-conditioned generation. The authors did not include results for the best MAR model, so I’ve added them here.
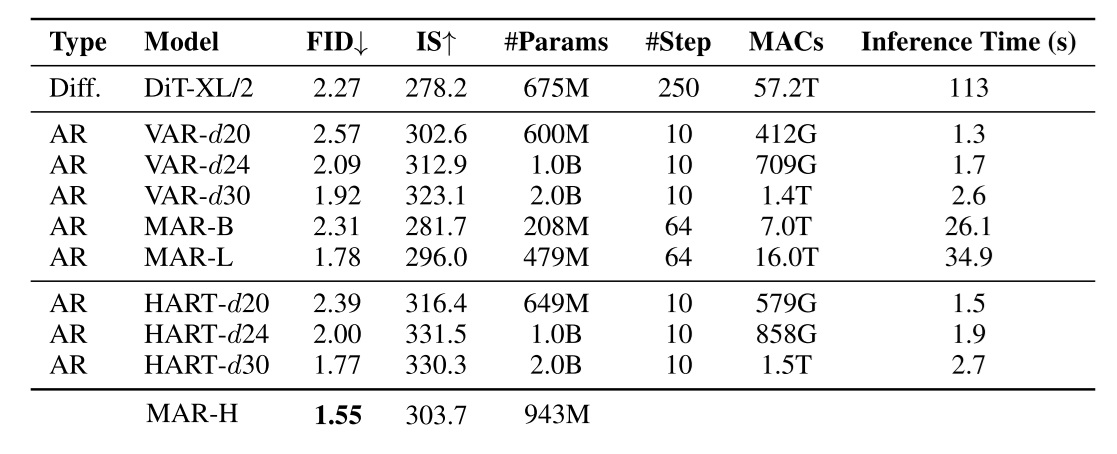
In this task, the main difference between HART and VAR is whether or not a diffusion model is used to produce the residual image. As we can see, the residual diffusion model hardly increases the inference time, yet it significantly improves the FID metric (considering the lower the value, the harder it is to improve). Moreover, comparing the speeds of different models, we see that the greatest advantage of VAR-like models lies in their fast inference.
Next, let’s look at the text-to-image generation metrics, which are the main focus of this paper. In addition to the commonly used GenEval (mainly measuring text-image alignment), the authors also show two metrics introduced this year: metrics on the MJHQ-30K dataset and DPG-Bench.
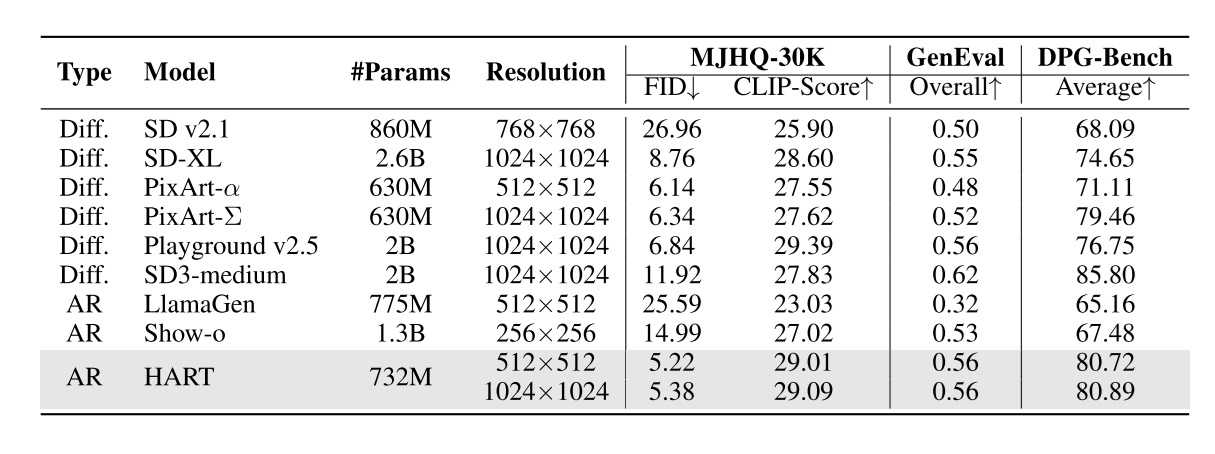
These metrics may not be very convincing. According to user-voted rankings at https://imgsys.org/rankings, Playground v2.5 is the best, while SD3 and PixelArt-Σ are about the same. However, the MJHQ FID and DPG-Bench metrics do not reflect that ranking. In particular, since the FID uses the Inception V3 network trained on ImageNet $299 \times 299$, FID does not accurately capture high-resolution image similarity, nor does it capture similarity in more complex images.
In summary, HART’s performance on high-resolution text-to-image tasks cannot yet be reflected by the experimental results. According to some community feedback (https://www.reddit.com/r/StableDiffusion/comments/1glig4u/mits_hart_fast_texttoimage_model_you_need_to_see/), HART has issues in generating high-frequency details. Looking back at HART’s method, we can infer that this might be caused by the suboptimal design of the residual diffusion model.
Summary
To mitigate the information loss caused by the VQ operation in VQ-based autoencoders, HART treats the lost information as a residual image and uses a lightweight pixel diffusion model to independently generate each pixel of that residual image. HART applies this improvement directly to VAR and boosts the ImageNet FID metric. However, HART still cannot compete with diffusion models in high-resolution text-to-image tasks, and since diffusion models have various acceleration tricks, HART does not have an advantage in generation speed either.
VQ operations transform complex images into image tokens. This makes the distrbution of image tokens easy to learn, but sacrifice autoencoder reconstruction quality. Many works have tried to improve the original nearest-neighbor VQ operation in VQVAE. Regardless, the error introduced by VQ is inevitably present. From another aspect, HART alleviates VQ reconstruction errors by generating a residual image with a separate model. This design idea is promising—it may be possible to eliminate VQ errors entirely. But there’s no free lunch: improving generation quality typically means increasing training and inference time. Although HART’s approach of using a lightweight pixel diffusion model to generate the residual image does not slow down the model, its effectiveness is still not sufficient. Perhaps replacing it with a diffusion model with larger receptive field could improve the quality of the residual image without significantly increasing generation time.