安装Tensorflow
前言
配编程环境考察的是利用搜索引擎的能力。在配环境时,应该多参考几篇文章。有英文阅读能力的应该去参考官方给的配置教程。出了问题把问题的出错信息放到搜索引擎上去查。一般多踩几次坑,多花点时间,环境总能配好。
本文只能给出一个大概率可行的指导,不能覆盖所有情况。如果在执行本文的安装步骤时出了问题,请灵活使用搜索引擎。
配置深度学习编程框架时,强烈推荐配置GPU版本。本文会介绍TensorFlow GPU版本的配置。如果只想用CPU版本的话,跳过“CUDA与cuDNN”一节即可。
本文会同时介绍Windows和Linux下的安装方法。二者操作有区别的地方本文会特别强调,若没有强调则默认二者处理方法一致。
CUDA与cuDNN
CUDA是NVIDIA显卡的GPU编程语言。cuDNN是基于CUDA编写的GPU深度学习编程库。在使用深度学习编程框架时,我们一般都要装好CUDA和cuDNN。
这个安装步骤主要分三步:
- 装显卡驱动
- 装CUDA
- 装cuDNN
其中,显卡驱动一般不需要手动安装,尤其是在自带了NVIDIA显卡的Windows电脑上。
显卡驱动
用nvidia-smi查看电脑的CUDA驱动最高支持版本。下图标出了命令运行成功后该信息所在位置:
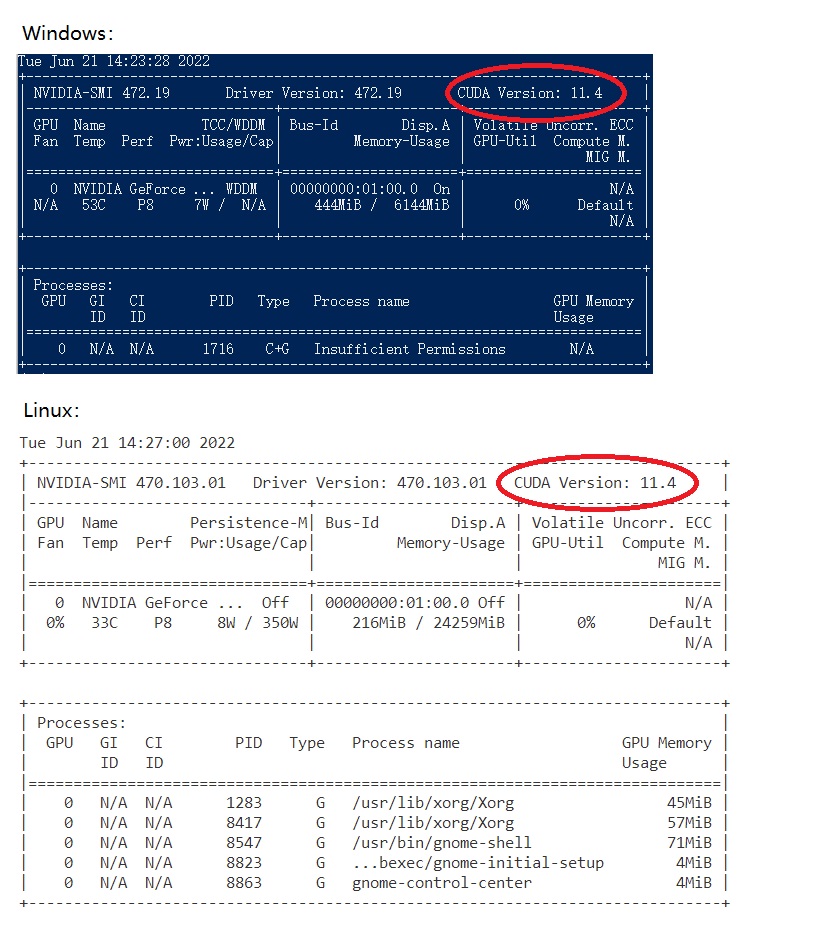
如果命令能成功运行,记住这个信息。
如果这个命令失败了,就说明电脑需要重新安装显卡驱动。现在(2022年)CUDA的主流版本都是11.x,如果你发现驱动支持的最高版本偏低,也可以按照下面的步骤重新安装显卡驱动。
访问NVIDIA驱动官网:https://www.nvidia.cn/geforce/drivers/ 。在网站上,输入显卡型号和操作系统等信息,即可找到对应的驱动安装程序。
对于Windows,下载的是一个有GUI的安装器;对于Linux,下载的是一个shell脚本。如果你用的是Linux服务器,没有图形接口,可以先复制好下载链接,之后用wget下载脚本。
之后,运行安装器,按照指引即可完成驱动的安装。
注意,如果是带图形界面的Linux系统,可能要关闭图像界面再安装驱动。比如对于Ubuntu,一般要关闭nouveau再重启。请参考 https://zhuanlan.zhihu.com/p/59618999 等专门介绍Ubuntu显卡驱动安装的文章。
能够执行nvidia-smi后,执行该命令,找到驱动支持的最高CUDA版本。
CUDA
首先,我们要定一个CUDA安装版本。
CUDA安装版本的第一个限制是,该版本不能大于刚刚在nvidia-smi中获取的最高CUDA版本。
第二个限制是,TensorFlow版本必须支持当前CUDA版本。在 https://www.tensorflow.org/install/source#gpu 中,可以找到TensorFlow与CUDA、cuDNN的版本对应表。这个表格仅表示了经过测试的CUDA版本,不代表其他CUDA版本就一定不行。
由于开发环境中可能会安装多个编程框架(TensorFlow,PyTorch),建议先安装一个比较常用、版本较高的CUDA,比如CUDA 11.1,11.2之类的。之后,让编程框架向CUDA版本妥协。
如果之后安装TensorFlow后发现CUDA版本不对应,可以尝试升级TensorFlow版本。如果TensorFlow实在是支持不了当前的CUDA版本,最后再考虑降级当前的CUDA版本。
选好了CUDA版本后,去 https://developer.nvidia.com/cuda-toolkit-archive 上下载CUDA安装器。同样,Windows和Linux分别会得到GUI安装器和shell脚本。
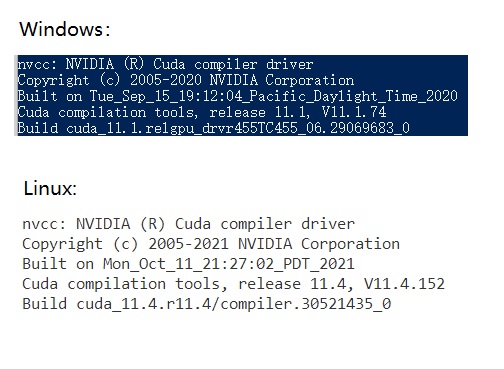
装完CUDA后,再控制台上输入nvcc -V。nvcc是CUDA专用的编译器,-V用于查询版本。如果这个命令能够运行,就说明CUDA已经装好了。以下是nvcc -V的输出:
cuDNN
打开下载网站 https://developer.nvidia.com/rdp/cudnn-download (最新版本) 或 https://developer.nvidia.com/rdp/cudnn-archive (历史版本)。注册账号并登录。
根据CUDA版本,找到合适版本的cuDNN。https://docs.nvidia.com/deeplearning/cudnn/archives/index.html 这个网站列出了每个cuDNN版本支持的CUDA版本(Support Matrix)。一般来说,可以去找最新的cuDNN,看它是否兼容当前的CUDA版本。如果不行,再考虑降级cuDNN。一般来说,CUDA 11.x 的兼容性都很好。
选好了cuDNN版本后,去上面的下载网站上下载最新或某个历史版本的cuDNN。注意,应该下载一个压缩文件,而不应该下载一个可执行文件。比如对于所有的Linux系统,都应该下载”xxx for Linux x86_64 (Tar)”
装CUDA和cuDNN,主要的目的是把它们的动态库放进环境变量里,把头文件放到系统头文件目录变量里。因此,下一步,我们要把cuDNN的文件放到系统能够找到的地方。由于CUDA的库目录、包含目录都会在安装时自动设置好,一种简单的配置方法是把cuDNN的文件放到CUDA的对应目录里。
对于Windows,我们要找到CUDA的安装目录,比如C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2。再找到刚刚cuDNN解压后的目录,比如D:\Download\cudnn-11.1-windows-x64-v8.0.4.30\cuda。把cuDNN目录下bin、include、lib里的文件分别复制到CUDA目录的对应文件夹中。
对于Linux,CUDA的安装目录一般是/usr/local/cuda。再找到cuDNN的解压目录,比如~/Downloads/cudnn-linux-x86_64-8.4.0.27_cuda11.6-archive。切换到cuDNN的根目录下,输入类似下面的命令:
1 | sudo cp include/* /usr/local/cuda/include |
该命令用于把所有cuDNN的相关文件暴力复制到cuda的对应目录下,并修改它们的访问权限。一定要注意一下该命令中的路径,如果路径不对应的话要修改上述命令,比如有些cuDNN的库目录不叫lib而叫lib64。
如果大家对操作系统熟悉的话,可以灵活地把复制改为剪切或者软链接。
Anaconda
Anaconda可以让用户更好地管理Python包。反正大家都在用,我也一直在用。
无论是什么操作系统,都可以在这里下Anaconda:
https://www.anaconda.com/products/individual#Downloads
同样,Windows和Linux分别会得到GUI安装器和shell脚本。
下好了安装器后,按照默认配置安装即可。
安装完成后,下一步是打开有Anaconda环境的控制台。
在Windows下,点击任务栏中的搜索框,搜索Anaconda,打开Anaconda Powershell Prompt (Anaconda)或者Anaconda Prompt (Anaconda)。
在Linux下,新建一个命令行即可。
如果在命令行里看到了(base),就说明安装成功了。
之后,要创建某个Python版本的虚拟环境,专门放我们用来做深度学习的Python库。该命令如下:
1 | conda create --name {env_name} python={version} |
比如我要创建一个名字叫pt,Python版本3.7的虚拟环境:
1 | conda create --name pt python=3.7 |
创建完成后,使用下面的命令进入虚拟环境:1
conda activate {env_name}
我的命令是:1
conda activate pt
如果在命令行前面看到了({env_name}),就算是成功了:

完成上述步骤后,在VSCode里用
ctrl+shift+p打开命令面板,输入select interpreter,找到Python: Select Interpreter这个选项,选择刚刚新建好的虚拟环境中的Python解释器。这样,新建VSCode的控制台时,控制台就能自动进入到conda虚拟环境里了。
TensorFlow
无论是GPU版还是CPU版,只需要在对应的虚拟环境中输入下面的命令即可:
1 | pip install tensorflow |
如果下载速度较慢,请更换conda和pip的下载源。可参考的教程很多,比如 https://blog.csdn.net/u011935830/article/details/10307 95。
如果显卡驱动和conda都装好了,执行完上面的命令后,GPU版TensorFlow也就装好了。打开Python,执行下面的命令(或者写一个.py文件再运行),即可验证GPU版安装是否成功。
1 | import tensorflow as tf |
如果最后输出了一大堆信息,最后一行是
1 | [PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')] |
,那么就说明GPU版的TensorFlow安装成功了。
VSCode代码补全
TensorFlow.keras在VSCode中无法生成代码补全,编程体验极差,不知道维护者在干什么东西。有人在issue中提出了解决方法。
打开tensorflow/__init__.py,添加以下内容:1
2
3
4
5
6
7if _typing.TYPE_CHECKING:
from tensorflow_estimator.python.estimator.api._v2 import estimator as estimator
from keras.api._v2 import keras
from keras.api._v2.keras import losses
from keras.api._v2.keras import metrics
from keras.api._v2.keras import optimizers
from keras.api._v2.keras import initializers
用TensorFlow实现多分类任务
每当学习一门新的编程技术时,程序员们都会完成一个”Hello World”项目。让我们完成一个简单的点集多分类任务,作为TensorFlow的入门项目。这个项目只会用到比较底层的函数,而不会使用框架的高级特性,可以轻松地翻译成纯NumPy或者其他框架的实现。
在这个项目中,我们会学到以下和TensorFlow有关的知识:
- TensorFlow与NumPy的相互转换
- TensorFlow的常量与变量
- TensorFlow的常见运算(矩阵乘法、激活函数、误差)
- TensorFlow的初始化器
- TensorFlow的优化器
- TensorFlow保存梯度中间结果的方法
- one-hot与标签的相互转换
我们将按照程序运行的逻辑顺序,看看这个多分类器是怎么实现的。
如果你看过我前几周的代码实战文章,欢迎比较一下这周和之前的代码,看看相比NumPy,TensorFlow节约了多少代码。
欢迎在GitHub上面访问本项目。
数据集
这周,我们要用到一个平面点数据集。在平面上,有三种颜色不同的点。我们希望用TensorFlow编写的神经网络能够区分这三种点。
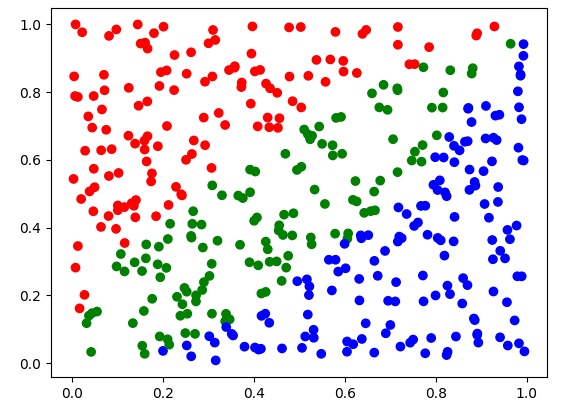
在项目中,我已经写好了生成数据集的函数。generate_points能根据数据集大小生成一个平面点数据集。generate_plot_set能生成最终测试平面上每一个“像素”的测试集。使用这两个函数,得到的X的形状为[2, m](因为是平面点,所以只有两个通道),Y的形状为[1, m]。Y的元素是0-2的标签,分别表示红、绿、蓝三种颜色的点。
1 | train_X, train_Y = generate_points(400) |
数据预处理与TensorFlow转换
我们刚刚得到的X, Y都是NumPy数组,我们要把它们转换成TensorFlow认识的数据结构。
TensorFlow用起来和C++很像,我们要决定一个数据是变量还是常量。由于X是不可变的训练数据,它应该属于常量。因此,我们用下面的语句把它转换成TensorFlow的常量。
1 | train_X_tf = tf.constant(train_X, dtype=tf.float32) |
TensorFlow常量的类型名叫做tf.Tensor,也就是说train_X_tf是一个tf.Tensor。
而在使用Y时,我们要加一步转换到one-hot编码的步骤。回忆本周笔记中有关多分类loss的知识,这里的Y是一个整型数组,表示每个数据的类别。而在loss的计算中,我们需要把每个整数转换成一个one-hot向量,得到一个one-hot向量的向量。
因此,我们可以用下面的代码把Y预处理并转换成TensorFlow的数据结构:
1 | train_Y_tf = tf.transpose(tf.one_hot(train_Y.squeeze(0), 3)) |
tf.one_hot()用于生成one-hot编码,其第二个参数为总类别数。我们的数据集有3种点,因此取3。tf.one_hot()的输出是一个[m, 3]形状的张量,我们要把它tf.transpose转置一下,得到与其他代码相匹配的[3, m]张量。
顺带一提,由于tf.one_hot是一个TensorFlow的运算,如果输入是一个numpy数组,输出会被自动转换成一个TensorFlow的常量tf.Tensor。所以,Y的类型也是tf.Tensor。
经过上述操作,X, Y再被送入TensorFlow模型之前的形状是:
1 | # X: [2, m] |
TensorFlow多分类模型
处理完了数据,接下来,我们就要定义神经网络了。在神经网络中,我们要实现初始化、正向传播、误差、评估这四个方法。
初始化
1 | class MulticlassClassificationNet(): |
和之前一样,我们通过neuron_cnt指定神经网络包含输出层在内每一层的神经元数。之后,根据每一层的神经元数,我们就可以初始化参数W和b了。
使用TensorFlow,我们可以方便地完成一些高级初始化操作。比如我们要使用He Initialization,我们可以用tf.keras.initializers.HeNormal(seed=1)生成一个初始化器initializer,再用这个工具生成每一个初始化后的变量。
使用initializer(*shape)即可生成某形状的参数。由于参数是需要被优化更新的,我们需要用tf.Variable来把参数转换成可以优化的变量。
最后,我们用self.trainable_vars = self.W + self.b记录一下所有待优化变量,为之后的优化算法做准备。
正向传播
正向传播的写法很简单,只要在每层算一个矩阵乘法和一次加法,再经过激活函数即可(在这个神经网络中,隐藏层的激活函数默认使用ReLU):1
2
3
4
5
6
7
8def forward(self, X):
A = X
for i in range(self.num_layer):
Z = tf.matmul(self.W[i], A) + self.b[i]
if i == self.num_layer - 1:
A = tf.keras.activations.softmax(Z)
else:
A = tf.keras.activations.relu(Z)
在这份代码中,tf.matmul用于执行矩阵乘法,等价于np.dot。和NumPy里的张量一样,TensorFlow里的张量也可以直接用运算符+来完成加法。
做完了线性层的运算后,我们可以方便地调用tf.keras.activations里的激活函数完成激活操作。
值得一提的是,TensorFlow会自动帮我们计算导数。因此,之前我们在正向传播里保存中间运算结果的代码全都可以删掉。我们也不用再编写反向传播函数了。
损失函数
使用下面的代码可以在一行内算完损失函数:1
2
3
4def loss(self, Y, Y_hat):
return tf.reduce_mean(
tf.keras.losses.categorical_crossentropy(
tf.transpose(Y),tf.transpose(Y_hat)))tf.keras.losses.categorical_crossentropy就是多分类使用的交叉熵误差。由于这个函数要求输入的形状为[num_samples, num_classes],和我们的定义相反,我们要把两个输入都转置一下。算完误差后,我们用tf.reduce_mean算误差的平均数以得到最终的损失函数。这个函数等价于NumPy里用mean时令keepdims=False。
评估
为了监控网络的运行结果,我们可以手写一个评估网络正确率和误差的函数:
1 | def evaluate(self, X, Y, return_loss=False): |
首先,我们使用Y_hat = self.forward(X),根据X算出估计值Y_hat。之后我们就要对Y和Y_hat进行比较了。
Y和Y_hat都不是整数标签,而是用向量代表了标签。为了方便比较,我们要把它们转换回用整数表示的标签。这个转换函数是tf.argmax。
和数学里的定义一样,tf.argmax返回令函数最大的参数值。而对于数组来说,就是返回数组里值最大的下标值。tf.argmax的第一个参数是参与运算的张量,第二个参数是参与运算的维度。Y和Y_hat的形状是[3, m],我们要把长度为3的向量转换回标签向量,因此应该对第一维进行运算(即维度0)。
得到了Y_predict, Y_hat_predict后,我们要比对它们以计算准确率。这时,我们可以用res = Y_predict == Y_hat_predict得到一个bool值的比对结果。TensorFlow的类型非常严格,bool值是无法参与普通运算的,我们要用tf.cast强制类型转换。由于最终的准确率是一个浮点数,我们要转换成tf.float32浮点类型。
最后,用accuracy = tf.reduce_mean(res)就可以得到准确率了。
由于我们前面写好了loss方法,计算loss时直接调用方法就行了。
模型训练
写完了模型,该训练模型了。下面是模型训练的主要代码:
1 | def train(model: MulticlassClassificationNet, |
TensorFlow使用一系列的优化器来维护梯度下降的过程。我们只需要用tf.keras.optimizers.Adam(learning_rate)即可获取一个Adam优化器。
接下来,我们看for s in range(step):里每一步更新参数的过程。
在TensorFlow里,为了计算梯度,我们要使用一个上下文with tf.GradientTape() as tape:。在这个上下文中,执行完运算后,所有Variable的求导中间结果都会被记录下来。因此,我们应该调用网络的前向传播和损失函数,完成整套的计算过程。
计算出损失函数后,我们用grads = tape.gradient(cost, model.trainable_vars)算出最终的梯度,并调用optimizer.apply_gradients(zip(grads, model.trainable_vars))更新参数。
可以看出,相比完全用NumPy实现,TensorFlow用起来十分方便。只要我们用心定义好了前向传播函数和损失函数,维护梯度和优化参数都可以交给编程框架来完成。
实验
做完了所有准备后,我们用下面的代码初始化模型并调用训练函数1
2
3
4n_x = 2
neuron_list = [n_x, 10, 10, 3]
model = MulticlassClassificationNet(neuron_list)
train(model, train_X_tf, train_Y_tf, 5000, 0.001, 1000)
这里要注意一下,由于数据有三种类别,神经网络最后一层必须是3个神经元。
网络训练完成后,我们用下面的代码把网络推理结果转换成可视化要用的NumPy结果:
1 | plot_result = model.forward(plot_X) |
运行完plot_result = model.forward(plot_X)后,我们得到的是一个[3, m]的概率t矩阵。我们要用tf.argmax(plot_result, 0)把它转换回整型标签。
之后,我们对TensorFlow的张量调用.numpy(),即可使用我们熟悉的NumPy张量了。为了对齐可视化API的格式,我用expand_dims把最终的标签转换成了[1, m]的形状。
完成了转换,只需调用我写的可视化函数即可看出模型是怎样对二维平面分类的:
1 | visualize(train_X, train_Y, plot_result) |
我的一个运行结果如下:
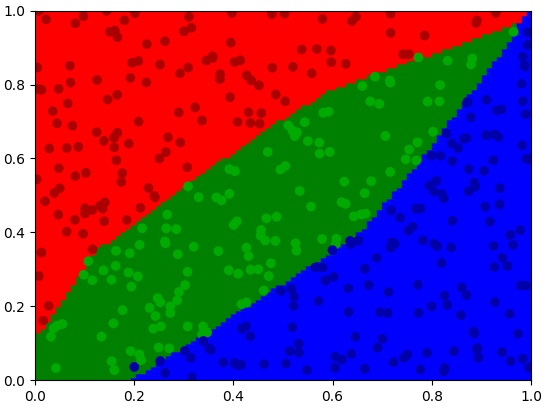
只能说,神经网络实在太强啦。
附录:TensorFlow的GPU版本
在使用TensorFlow时,我唯一发现它比PyTorch更便捷的地方,就是TensorFlow能够自动选择运算时的设备。如果电脑按上面的流程装好了驱动、CUDA和cuDNN,TensorFlow就会很主动地把张量放到GPU上运算。而如果没有检测到GPU,TensorFlow也会用CPU计算。
如果想要手动管理张量的运算设备,可以参考下面的代码。当我想在CPU上初始化张量时:1
2
3with tf.device('/CPU:0'):
a = tf.constant([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])
b = tf.constant([[1.0, 2.0], [3.0, 4.0], [5.0, 6.0]])
想初始化多个GPU中的某个GPU上的张量:1
2
3with tf.device('/device:GPU:2'):
a = tf.constant([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])
b = tf.constant([[1.0, 2.0], [3.0, 4.0], [5.0, 6.0]])
这里GPU的名称可以用我们之前见过的tf.config.list_physical_devices('GPU')来查找:
1 | >> tf.config.list_physical_devices('GPU') |
有趣的是,这个项目的代码用TensorFlow在GPU上运行,比我之前的NumPy项目用CPU运行还慢。感觉是这个项目的计算过于简单,GPU无法发挥性能上的优势。GPU计算的一些其他开销盖过了运算时间的减少。
总结
在这篇笔记中,我介绍了TensorFlow在Windows/Linux下的从零安装方法,并且介绍了一个简单的TensorFlow多分类项目。希望大家能通过这篇笔记,成功上手TensorFlow。
项目链接:https://github.com/SingleZombie/DL-Demos/tree/master/dldemos/MulticlassClassification