经过了之前的学习,我们学会了许多改进深度学习模型的方法,比如:
- 收集更多数据
- 收集更多样化的数据
- 延长训练时间
- 用高级梯度下降算法
- 缩小/扩大网络
- 使用正则化
- ……
这么多方法,如果只是一个一个试过去,开发效率就太低了。在未来的两周,我们会学习一些改进机器学习的策略。这些策略会给我们一些启发性的指导,让我们在改进模型时更明确下一步该做什么。
学习提示
这周课没有太多的新内容,主要是拓展了第二门课第一周有关偏差与方差分析的内容。学完了这周的课后,大家会进一步了解如何在一个全新的机器学习任务上设置目标,并通过误差分析等技术逐步靠近目标。
课堂笔记
正交化
如何从众多的改进方案中选择出优先级较高的呢?让我们先看看生活中一些其他事情的例子:
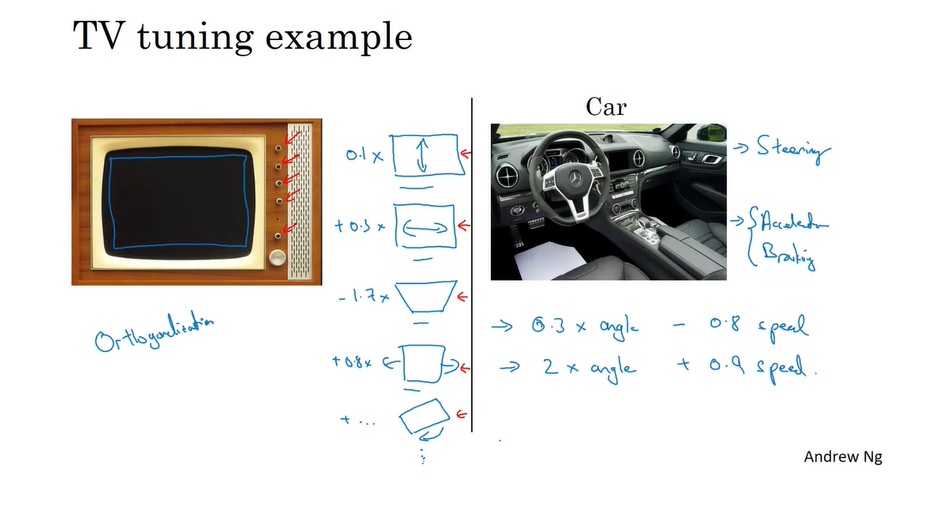
首先,是调整老式电视机的例子。老式电视机的画面不一定恰好能端端正正地填满屏幕,需要人为地调整画面的位置。一般这些电视机都有很多按钮,每个按钮各负责一项调整功能,比如调整上下位置、左右位置、缩放、旋转等。每个按钮之间的功能互不干扰。
另外,还有一个开汽车的例子。汽车最少有三种操作:转方向盘、加速、减速。只需要组合这三种操作,我们就能让汽车沿着某一路线跑起来。而如果汽车只有两个可以左右调整的按钮,一个按钮控制0.3倍的角度和-0.8倍的速度,另一个按钮控制2倍的角度和0.9倍的速度,那司机控制汽车时肯定会倍感吃力。
以上两个例子显示了正交化的好处。正交可以指数学里两条直线垂直,这里指的是两个调整方向互不干扰。通过调整正交的参数,我们可以把事物的“坐标分量”逐个调整到我们期待的“位置”。
类似地,在改进机器学习项目时,也可以使用正交化。

在机器学习项目中,大概有4个“坐标分量”需要调整:拟合训练集、拟合开发集、拟合测试集、提升实际应用中的表现。对于这每一项目标,我们都应该使用相互正交的策略去调整,比如:
- 拟合训练集 - 用更大的网络
- 拟合开发集 - 正则化
- 拟合测试集 - 用更大的开发集
- 提升实际应用中的表现 - 更换损失函数
值得一提的是,提前停止是一个即会影响训练误差,又会影响开发误差的方法。这个方法不满足正交化的要求,使用此方法时需要多多注意。
设置目标
单一指标
在分类任务中,一般有下面这两种评价指标:
- 精确率(precision, 又称查准率):所有识别为猫的图片中,究竟有多少确实是猫?
- 召回率(recall, 又称查全率):所有猫的图片中,有多少猫被正确识别了?
注意,我们之前代码实战中用的准确率(accuracy)和精确率(precision)不是一个指标。
现在,假设有两个模型,它们在开发集上的评估结果如下:
- 模型1:精确率95%,召回率90%。
- 模型2:精确率98%,召回率85%。
二者在精确率和召回率上各有优劣,该怎么从中选一个更好的模型出来呢?
设置目标的一个原则是:只使用单一实数作为评价标准。因此,我们要想办法用一个指标把这两个指标都考虑进来。比如使用F1-score,它的公式如下:
再看一个例子。假如我们开发好了几个算法,我们要用来自不同国家的数据去测试它们。不同算法在不同国家的数据上表现较好。为了快速选取一个最好的算法,我们可以去计算每个算法的表现平均值。
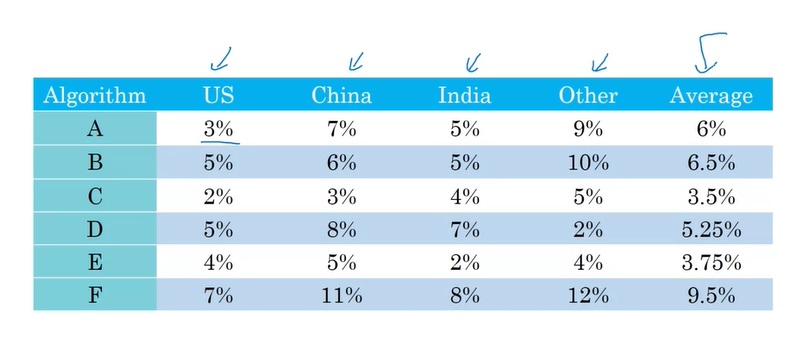
有了单一评价标准,我们就可以快速比较各个模型在开发集上的表现,并选择一个更好的模型。这样,我们开发的迭代速度也变快了。
满足指标与优化指标
在有多个评价指标时,不是总能挑选出一个最恰当的综合指标的。比如评价某算法时既要考虑到准确率,又要考虑到运行时间。用一个综合指标来组合它们显然不太现实。这时,我们可以把指标分成满足指标和优化指标。
比如说,我们有这样几个算法:
| 分类器 | 准确率 | 运行时间 |
|---|---|---|
| A | 90% | 80ms |
| B | 92% | 95ms |
| C | 95% | 1500ms |
算法C是挺好的,但是它相较A,B实在跑的太慢了。因此,我们可以设置以下的评价标准:
满足运行时间≤100ms的前提下,最大化准确率。
这个标准既保证了运行时间不会太长,又能选出准确率较高的算法。按照这个标准,B应该是最优的分类器。
在这个例子中,准确率就是优化指标,运行时间就是满足指标。
这种新的选取指标的方法应该和之前提到的单一指标原则结合起来。准确来说,应该只有一个优化指标,外加若干个满足指标。
训练/开发/测试的分布
开发集和评价指标,共同决定了我们的优化目标。因此,我们应该谨慎地选择各数据集的数据分布,防止优化目标跑偏。
举个例子,假如我们收集了来自不同地区的数据,有亚洲、欧洲……。假如我们令亚洲的数据为开发集,欧洲的数据为测试集,我们就可能会训练出一个在开发集上表现优秀,却在测试集上表现糟糕的模型。正确的做法是,我们把来自不同地区的数据打乱,把数据随机分成开发集和测试集。
还有一个改编自真实故事的例子。一个团队想开发根据某人的邮政编码预测他同意贷款的概率的算法。他们以中等收入地区的邮政编码为开发集,却以低收入地区的邮政编码为测试集。显然,在这两个地区的人同意贷款的概率会差很多。最后,这个团队花了3个月优化了算法在开发集上的表现,却发现模型在测试集上表现奇差,不得以推倒重来。
也就是说,我们应该让训练集和测试集能够反映我们将来实际应用时的数据,并且训练集和测试集都得来自同一个分布。设置开发集和评估指标,就像立了一个靶子一样。训练,就是让射出的箭更靠靶心。而测试集,应该反映我们期望箭射到的位置。我们既要知道箭应该射在哪里,还要把靶子摆对。
开发集和测试集的大小
这些知识在第二周已经学过了,这里再强调一次。
数据量小的时候(比如说数量级在万以下),我们可以按6:2:2的比例划分训练/开发/测试集。但数据量大的时候,就不用考虑比例了,按固定大小选择差不多大小的开发集和测试集即可。
那么,测试集要多大才够呢?从统计学的眼光来看,把测试集当成实际应用数据中的一个采样结果的话,我们应该保证测试集有很高的置信度能反映模型在实际应用中的综合表现。当然,对于简单的数据分布,我们可以用统计学知识严谨地算出置信度。而对于人工智能任务中用到的海量数据,数学工具就难以派上用场了。我们只能根据经验选择一个足够大的测试集。比如有百万级数据的话,一万个测试样本就够了。
何时更换开发/测试集与评价指标
在算法投入应用后,我们可能会发现新的评价角度。比如对于小猫分类模型,我们本来只期望它能正确识别小猫。可是,随着使用应用的人变多,我们发现有的用户会上传色情图片。这时,我们不仅希望模型能只找出小猫,还要能过滤掉色情图片。
这样,我们就引入了一个新的评价指标。这样,之前辨认小猫能力强的模型,可能会在辨认色情图片上较差。
为了考虑这个新的评价指标,我们可以修改误差函数,用更高的权重加大色情图片分类错误的惩罚。
总结来说,当我们发现使用当前指标得出来的最优模型,与考虑到某些新因素后得到的最优模型不同时,我们就应该更换开发/测试集与评价指标了。
与人类级表现比较
为什么是人类级表现
我们经常能看到AI与人类比较的新闻:什么AlphaGo在围棋上战胜人类了,什么在ImageNet上AI的分类准确率超过了人类啊,等等。除了博眼球的新闻外,业内同样也会时常将机器学习模型和人类比较。这是为什么呢?
在许多任务中,人类的表现都非常出色。当AI超过了人类后,往往也达到了这类问题的最优精度。在机器学习模型超过人类前,与人类比较有以下好处:
- 获取人类标注的数据。
- 从手动误差分析中获得启发:为什么人就能做对?
- 更好地分析偏差与方差。
其中,第1条是显然的,第2条会在下周介绍。接下来,我们看看第3条是怎么回事。
可规避偏差
这个知识之前也学过了一点。
如果一个模型的训练误差是8%,开发误差是10%,我们不一定说模型就存在这个偏差问题。有可能模型在训练集上已经几乎达到了最优的表现;
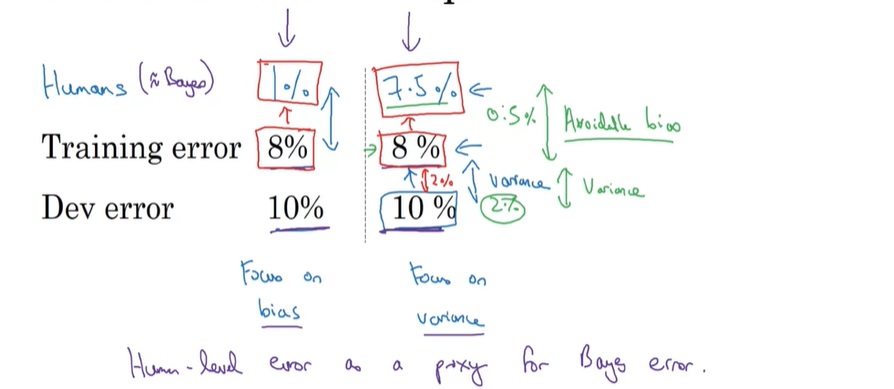
在判断一件事时,有可能因为信息的缺乏,最优的准确率也达不到100%,总会存在一些误差。这样的最小的误差叫做贝叶斯误差。人类的表现,通常可以用作贝叶斯误差的一个估计。
在刚才那个例子中,如果人类误差是1%,那么模型的训练误差还有7%的提升空间;而如果人类误差是7.5%,那说不定模型的训练误差只有0.5%的提升空间了。对于前者,我们应该关注偏差;关于后者,我们应该关注方差。这里讲到的7%, 0.5%的提升空间,可以称作可规避偏差。
理解人类级表现
假如让人类来完成医学图片分类任务,人们得到了以下的分类误差:

从一个普通人,到一群有经验的医生,误差逐渐降低。那么,哪个误差算是人类级表现呢?
回顾上一节的内容,人类误差是贝叶斯误差的一个估计。因此,人类最优的表现,才应该被视作是人类误差。
当然,获取人类级表现的目的还是为了做偏差和方差分析。如果当前的训练误差是5%,那不管人类误差是1%,0.7%,还是5%,都差不多。而如果训练误差到了1%,甚至更低,那就要仔细地获取人类误差了。
提升模型表现
最后,再一次回顾一下如何减少偏差和方差。
机器学习有两大假设:模型能够很好地拟合训练集、模型能够泛化到开发/测试集上。它们分别对应偏差问题和方差问题。
训练误差和人类级表现之间的差是可规避偏差,开发集和训练集之间的差是方差。
训练更大的模型、训练更久/用更好的优化算法能够解决偏差问题。
使用更多数据、正则化能解决方差问题。
用更好的架构、超参数能同时解决这两个问题。
总结
这节课涉及的新知识很少,大家就权当是复习了一下之前的知识。这节课大概学了这些东西:
- 正交化
- 目标
- 单一指标
- 满足指标与优化指标
- 开发集与测试集
- 分布
- 大小
- 人类级表现
- 贝叶斯误差
- 可规避偏差
- 提升模型表现的思路