学完了CNN的基本构件,让我们用TensorFlow来搭建一个CNN,并用这个网络完成之前那个简单的猫狗分类任务。
项目网址:https://github.com/SingleZombie/DL-Demos/tree/master/dldemos/BasicCNN
获取数据集
和之前几次的代码实战任务一样,我们这次还用的是Kaggle上的猫狗数据集。我已经写好了数据预处理的函数。使用如下的接口即可获取数据集:
1 | train_X, train_Y, test_X, test_Y = get_cat_set( |
这次的数据格式和之前项目中的有一些区别。
在使用全连接网络时,每一个输入样本都是一个一维向量。在预处理数据集时,我就做了一个flatten操作,把图片的所有颜色值塞进了一维向量中。而在CNN中,对于卷积操作,每一个输入样本都是一个三维张量。在用OpenCV读取完图片后,不用对图片Resize,直接拿过来用就可以了。
另外,在用NumPy实现时,我们把数据集大小m当作了最后一个参数。而TensorFlow默认张量是”NHWC(数量-高度-宽度-通道数)”格式。在此项目中,我们是按照TensorFlow的格式预处理数据的。
初始化模型
根据课堂里讲的CNN构建思路,我搭了一个这样的网络。
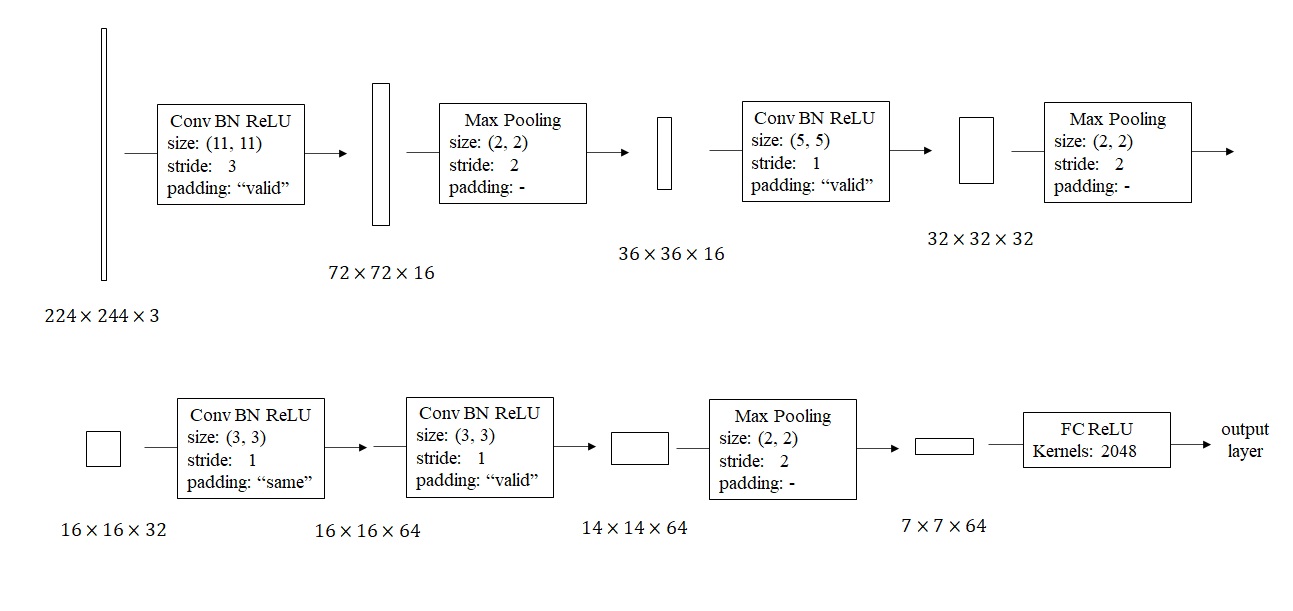
由于这个二分类任务比较简单,我在设计时尽可能让可训练参数更少。刚开始用一个大步幅、大卷积核的卷积快速缩小图片边长,之后逐步让图片边长减半、深度翻倍。
这样一个网络用TensorFlow实现如下:
1 | def init_model(input_shape=(224, 224, 3)): |
tf.keras.Sequential()用于创建一个串行的网络(前一个模块的输出就是后一个模块的输入)。网络各模块用到的初始化参数的介绍如下:
- Conv2D: 输出通道数、卷积核边长、步幅(要用一个数对表示)、填充方法。
- BatchNormalization: 做归一化的维度(全填3即可)。
- Dense(全连接层):输出通道数、激活函数。
根据之前的设计,把参数填入这些模块即可。
另外,TensorFlow维护的是静态图。一种比较简单的建图方法是在第一层里给出input_shape参数,让框架提前算好后续每一层中间结果的形状。
建图成功后,调用model.summary()可以查看网络各层的形状、参数量信息。
训练与推理
有了数据集和模型,用TensorFlow训练是一件很简单的事情。
1 | def main(): |
使用init_model初始化模型后,用compile填入模型的优化器、误差函数、评估指标信息。之后,只要用fit输入训练输入、训练标签、epoch数、batch size即可开始训练。训练结束后,用evaluate输入测试输入、测试标签即可在测试集上评估模型。
TensorFlow的这些函数确实非常方便,这里test_X, test_Y, train_X, train_Y其实都是NumPy里的ndarray,可以不用显式地把它们转换成TensorFlow里的张量。
实验结果
由于数据量较少,20个epoch后模型在训练集上的精度就快满了:
1 | Epoch 20/20 |
测试集上的精度就没那么高了:
1 | 13/13 [==============================] - 1s 30ms/step - loss: 1.0136 - accuracy: 0.7375 |
相比前几周用的全连接网络,CNN的效果出彩很多。相信加入更多训练数据的话,模型在测试集上的表现会更好。
另外,TensorFlow的高度封装的函数确实很好用,寥寥几行代码就完成了训练配置、训练、评估。相比用NumPy从零写代码,编程框架的开发效率会高上很多。
下篇文章里,我会介绍本项目的等价PyTorch实现。大家届时可以比较一下两个框架的区别。