前排提示:这周的课有很多知识点都在图中,一定要仔细地看一看图。
课堂笔记
计算机视觉
CV(Computer Vision, 计算机视觉)是计算机科学的一个研究领域。该领域研究如何让计算机“理解”图像,从而完成一些只有人类才能完成的高级任务。这些高级任务有:图像分类、目标检测、风格转换等。
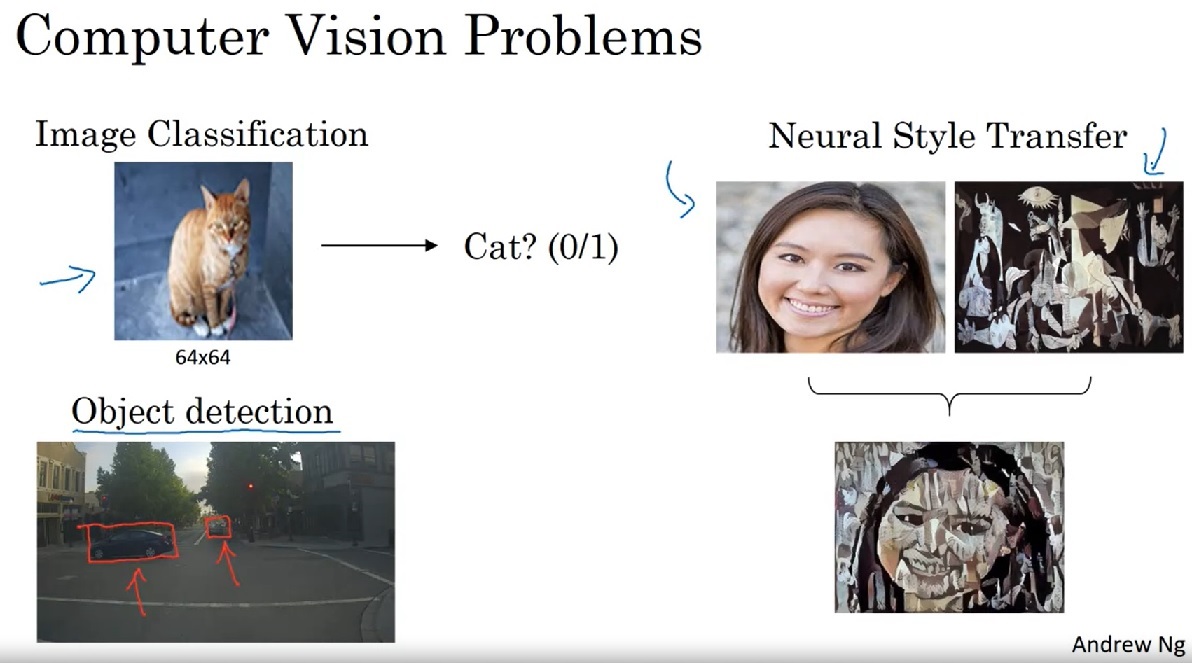
想具体了解有哪些计算机视觉任务,可以直接去访问OpenMMLab的GitHub主页:https://github.com/open-mmlab 。我随手整理了一下:图像分类、目标检测、语义分割、图像补全、光流、图像超分辨率、自动抠图、姿态识别、视频插帧、视频目标跟踪、文字识别与理解、图像生成、视频理解、3D目标检测与语义分割……
现在,大多数前沿CV算法是用深度学习实现的。
但是,在CV任务上使用我们之前学的经典神经网络,会碰到一个问题:神经网络输入层的通道数与输入图像尺寸正相关。对于一幅$64\times64\times3$的图像,输入的通道数是$12288$;而对于一幅$1000\times1000\times3$的图像,输入的通道数就高达$3\times 10^6$了。而网络第一层的参数量又与输入的通道数正相关。对于一个通道数高达$3\times 10^6$的输入,假设网络第一个隐藏层有$1000$个神经元,那么这一层的$W$将有$1000 \times 3\times 10^6=3\times 10^9$个参数。有这么多参数,除非有海量的数据,不然网络非常容易过拟合。现有的数据量和计算资源还是跑不动参数这么多的网络的。
因此,在CV中,我们一般不使用之前学的经典神经网络架构,而是使用一种新的网络架构——CNN(Convolutional Neural Network, 卷积神经网络)。
教材这一段的引入新知识组织得非常棒,从参数量的角度自然而然地从全连接网络过度到卷积神经网络。
让我们从卷积神经网络最简单的构件——卷积学起,一步一步认识卷积神经网络。
边缘检测
卷积是一种定义在图像上的操作。在深度学习时代之前,它最常用于图像处理。让我们来看看卷积在图像处理中的一个经典应用——边缘检测,通过这个应用来学习卷积。
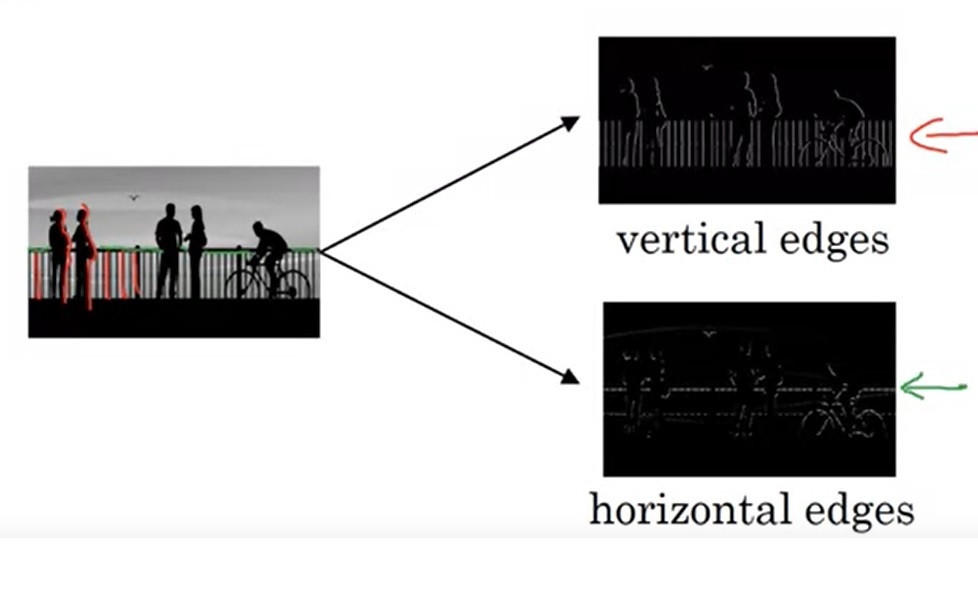
边缘检测的示意图如上所示。输入一张图片,我们希望计算机能够检测出图像纵向和横向的边缘,把有边缘的地方标成白色,没有边缘的地方标成黑色。
我们可以用卷积实现边缘检测。让我们来看看卷积运算是怎么样对数据进行操作的。
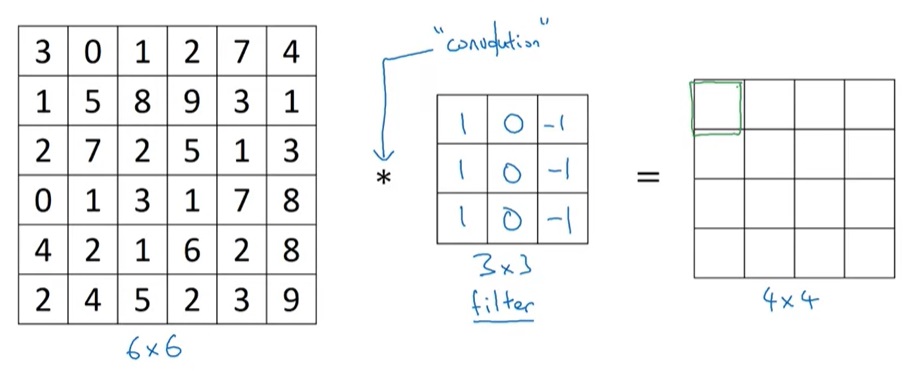
卷积有两个输入:一幅图像和一个卷积核(英文是kernel,也叫做filter滤波器),其中卷积核是一个二维矩阵。我们这里假设图像是一幅单通道$6 \times 6$的矩阵,卷积核是一个$3 \times 3$的矩阵。经过卷积后,我们会得到一个$4 \times 4$的单通道图像(稍后会介绍$4 \times 4$是怎么算出来的)。
卷积操作会依次算出输出图像中每一个格子的值。对于输出左上角第一个格子,它的计算方法如下:
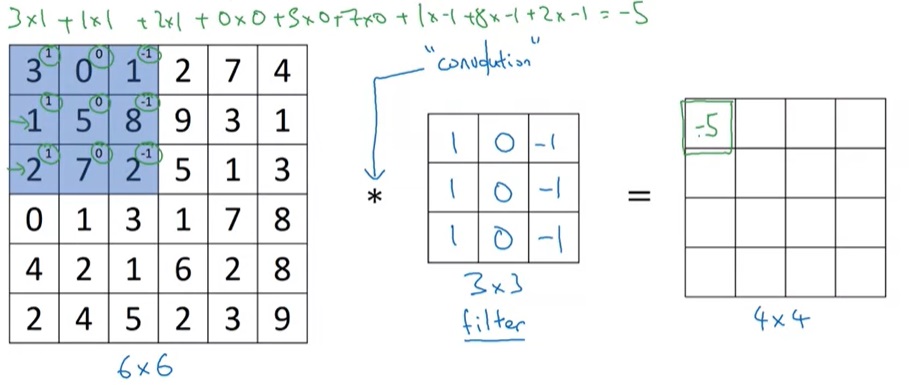
首先,我们把$3 \times 3$的卷积核“套”在输入图像的左上角。之后,我们把同一个位置的两个数字乘起来。比如图像左上角第一行是$3 0 1$,卷积核第一行是$1 0 1$,做完乘法运算后应该得到$3 0 -1$。最后,把所有乘法结果加起来,这个和就是输出中第一个格子的值。通过计算,这个值是$-5$,我们把它填入到输出图像中。
按同样的道理,我们可以填完第一行剩下的格子:
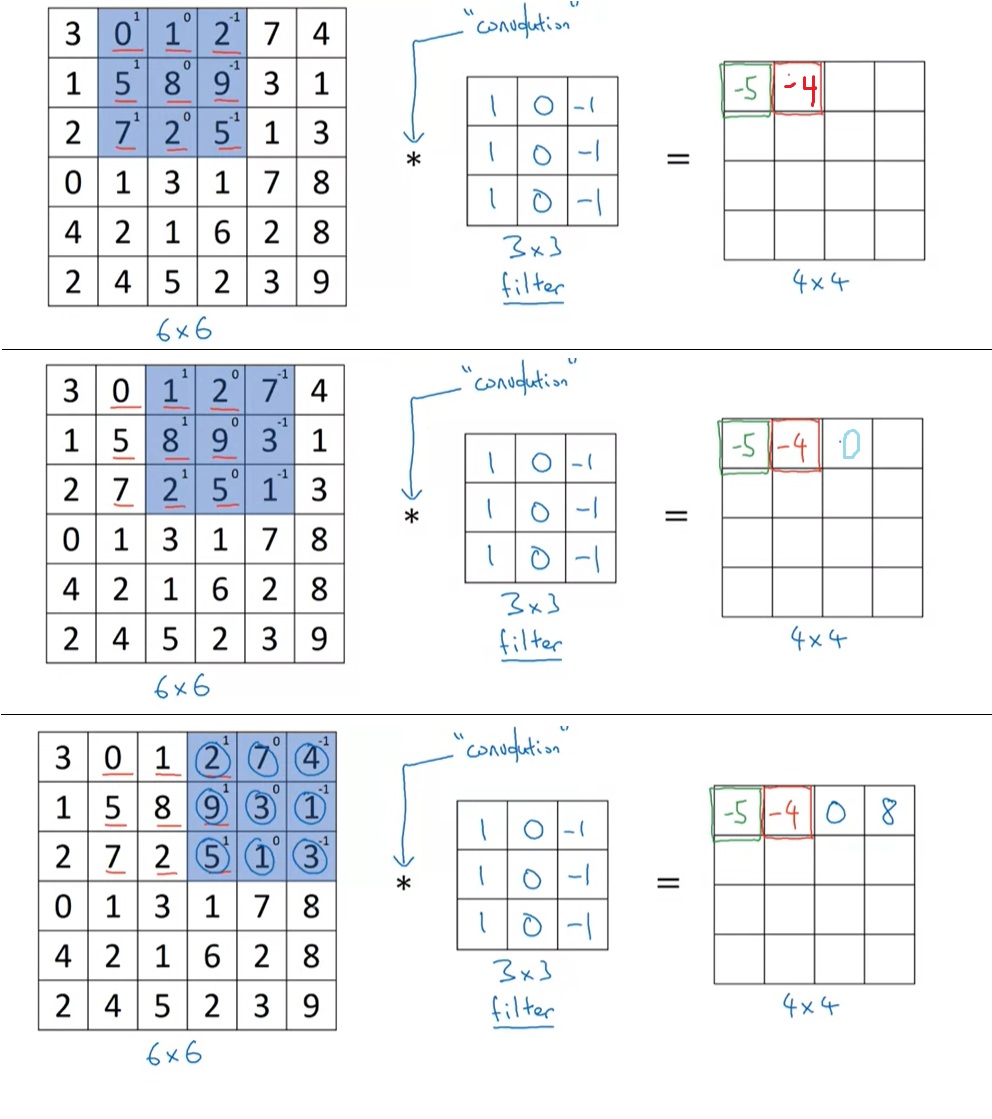
从第二行开始,卷积核要往下移一格。
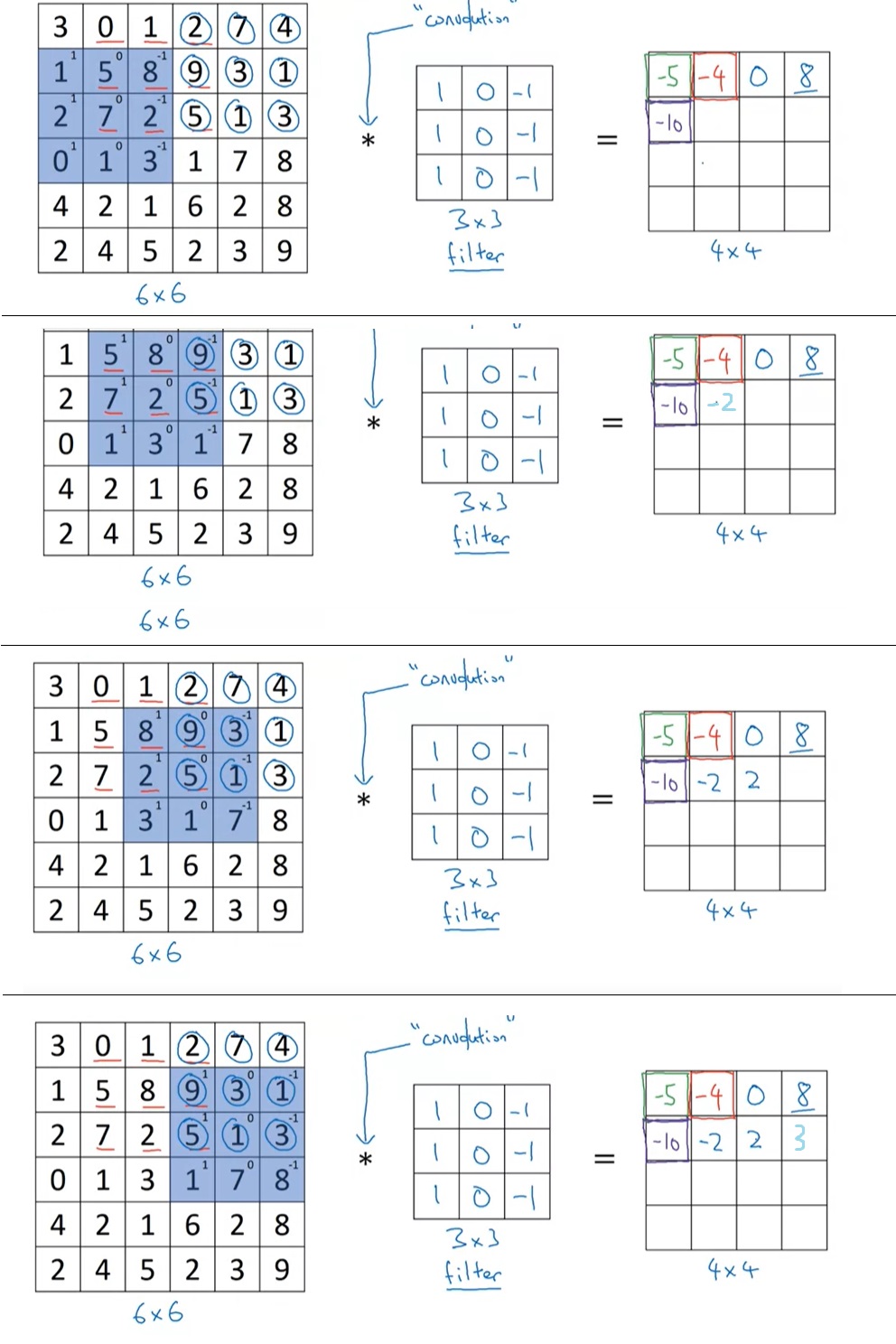
以此类推,我们可以填完所有格子。大家明白了为什么输出是$4 \times 4$的图像吗?没错,把$3 \times 3$的卷积核放到$6 \times 6$的图像上,只有$4 \times 4$个位置能放得下。
学会了卷积,该怎么用卷积完成边缘检测呢?我们可以看下面这个例子:
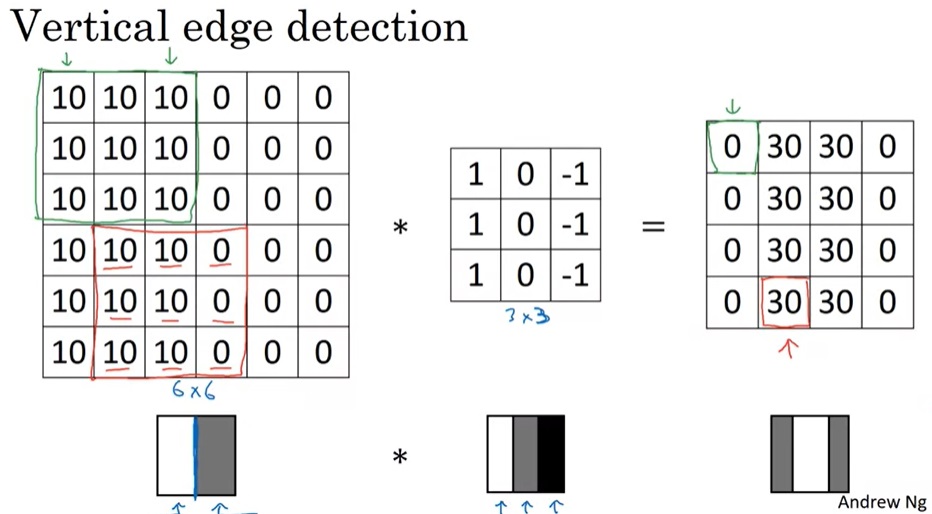
来看左边那幅图像,它左侧是白的,右侧是灰的。很明显,中间有一条纵向的边缘。当我们用图中那个卷积核对图像做卷积操作后,输出的图像中间是白色的(非0值),两侧是黑色的。输出图像用白色标出了原图像的纵向边缘,达到了边缘检测的目的。
刚刚那个卷积核只能检测纵向的边缘。大家应该能猜出,如果我们把卷积核转一下,就能检测横向的边缘了。

实际上,不仅是横向和纵向,我们还可以通过改变卷积核,检测出图像45°,30°的边缘。同时,卷积核里面的数值也不一定是1和-1,还有各种各样的取值方法。如果大家感兴趣,可以参考数字图像处理中有关边缘检测的介绍。
卷积与交叉相关
其实,现在我们在课堂上学的和编程框架里用的卷积,在数学上叫做“交叉相关(cross-correlation)”。数学中真正的那个卷积,要先对卷积核做一个旋转180°的操作,再做我们现在的那个卷积的操作。相比交叉相关,数学中的那个卷积能够满足交换律、结合律等一些实用的性质。
但是,在图像处理中,我们是从工程的角度而不是理科的角度使用卷积。要实现多次卷积的操作,只要拿图像多卷几次就好了,不用考虑结合律等复杂的性质。对于计算机来说,旋转卷积核180°是一个费时而多余的操作。因此,我们现在说到的卷积,实际上是一个简化版的卷积,即交叉相关。
如果大家对这方面的知识感兴趣,欢迎阅读网上的这篇文章:https://zhuanlan.zhihu.com/p/33194385
填充
卷积后,图像的边长会变小。比如刚刚那个$6 \times 6$的图像经$3 \times 3$卷积后,会得到一个$4 \times 4$的图像。这是因为原图像中只有$4 \times 4$个位置放得下卷积核。
更一般地,如果原图像大小为$n \times n$,卷积核大小$f \times f$,则卷积后的图像为$(n-f+1) \times (n-f+1)$。
卷积操作导致的这种“缩水”现象有两个缺点:1)图像的分辨率会越来越小。最坏的情况下,图像变成了$1 \times 1$的大小,再也无法进行卷积操作了。2)图像中间的数据会被算到多次,而边缘处数据被算的次数较少。
填充(padding) 操作可以解决这些的问题:在做卷积操作之前,我们可以往图像四周填充一些像素,使得卷积操作后的图像大小不变。比如$6 \times 6$的图像做$3 \times 3$卷积时,可以先把图像填充成$8 \times 8$。这样,卷积后的图像还能保持$6 \times 6$的大小。
填充操作有两个参数:填充的数据和向四周填充的宽度。对于填充的数据,一般情况下,全部填0即可。而对于填充宽度,其取决于卷积核的大小。为了让图像大小不变,我们应该让填充宽度$p$满足$n+2p-f+1=n$,解得$p=\frac{f-1}{2}$。为了让$p$是整数,卷积核边长最好是奇数。
解释一下$n+2p-f+1=n$这个方程的左侧是怎么得来的。由于填充是上下、左右都填,填充后的图像边长是$n+2p$。根据开始的卷积后图像边长公式$n-f+1$,我们可以得到填充+卷积后边长公式$n+2p-f+1。$
加入了填充操作后,我们可以把卷积分成两类:有效卷积和等长卷积。前者不做填充操作,只对图像的有效区域做卷积。而后者会在卷积前做一次填充,保证整个操作的前后图像大小不变。
跨步卷积
跨步卷积的英文是strided convolution。strided来源于动词stride,表示“大步走”。我没有在网上找到一个合适的对这里的strided的翻译。我觉得直接翻译成“跨步卷积”就挺好。
还有一个翻译的小细节:做名词时,stride应翻译成“步幅”,而“步长”的英文应该是step。二者在描述人类行走时略有区别。
之前,每做完一次卷积后,我们都会让卷积核往右移1格;每做完一行卷积后,我们都会让卷积核往下移1格。但实际上,我们可以让卷积核移动得更快一点。卷积核每次移动的长度$s$称为步幅(stride).
跨步卷积的部分计算示意图(第1, 2, 4次计算)如下:
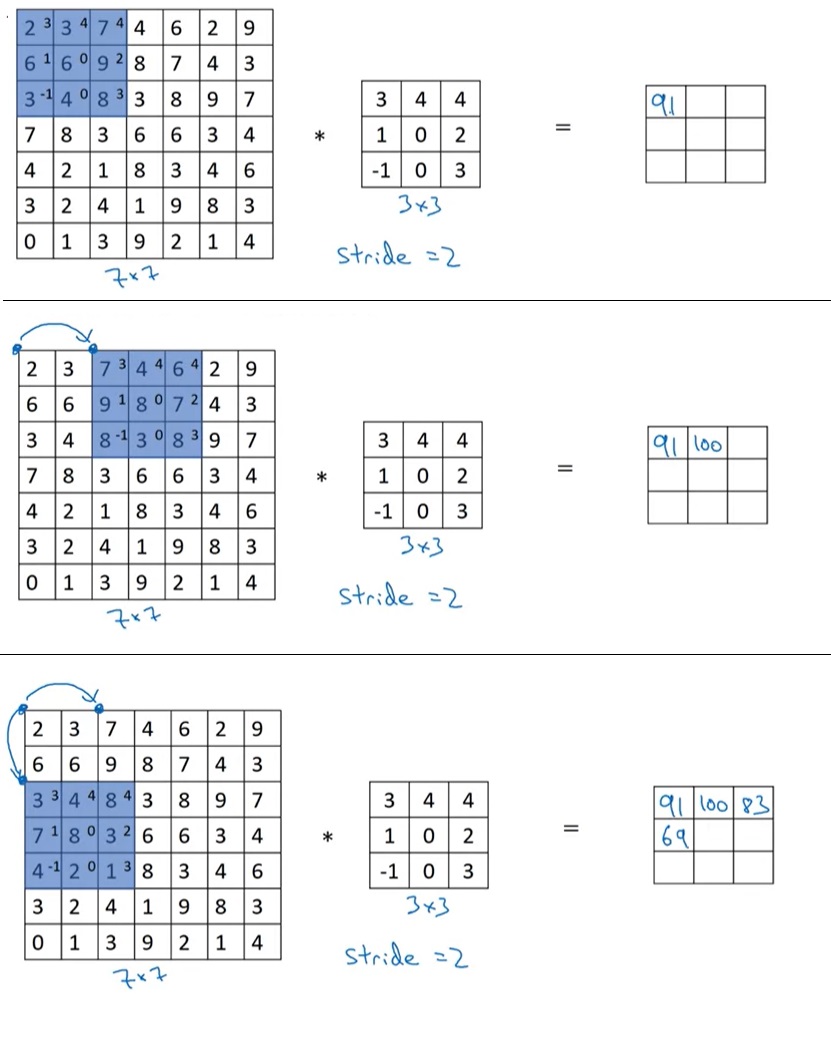
可以看到,步幅改变后,输出图像的边长也改变了。一般地,卷积后图像边长满足下面这个公式,大家可以自行推导验证一下:
其中$\lfloor x \rfloor$表示去掉$x$的小数部分,只保留其整数部分,即向下取整。
在3D数据体上卷积
之前我们学的卷积都是定义在一个二维单通道图像上的。在一个三通道的图像上,应该怎么进行卷积呢?
其实,对3D数据体的卷积是类似的。对于一个有3个通道的图像,卷积核也应该有3个通道。这样,图像和卷积核就从面变成了体。和2D时一样,我们把两个数据体对应位置的元素相乘,最后再把乘法的结果加起来,放到输出图像对应的格子中。
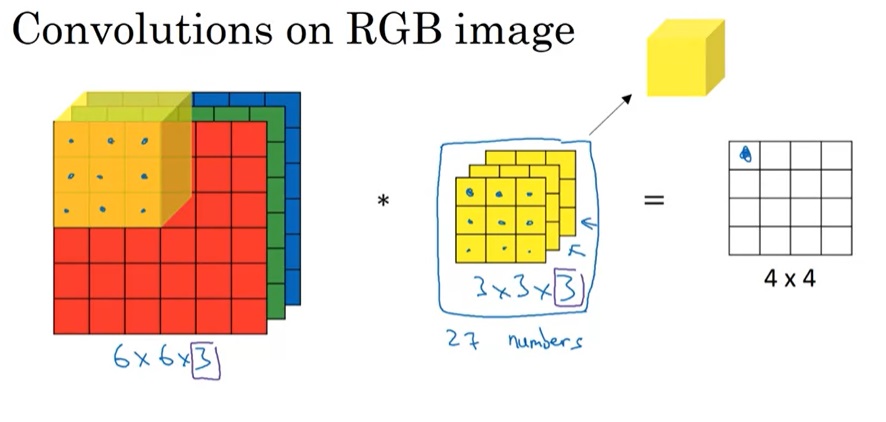
我认为,把三通道的图像表示成$3 \times 6 \times 6$更好理解一些。这样,输入图像的其实是一个二维图像的数组,$3 \times 3 \times 3$的卷积核其实也是一个$3 \times 3$卷积核的数组。我们把数组中下标一样的图像和卷积核做卷积,最后把所有数组的结果加到一起。
图像是用CHW(通道-高-宽)还是HWC表示,这件事并没有一个定论。似乎TensorFlow是用HWC,PyTorch是用CHW。这门课默认使用的是HWC。
既然输入都可以是多通道图像了,输出图像是不是也可以有多个通道呢?是的,我们只要用多个卷积核来卷图像,就可以得到一个多通道的图像了。
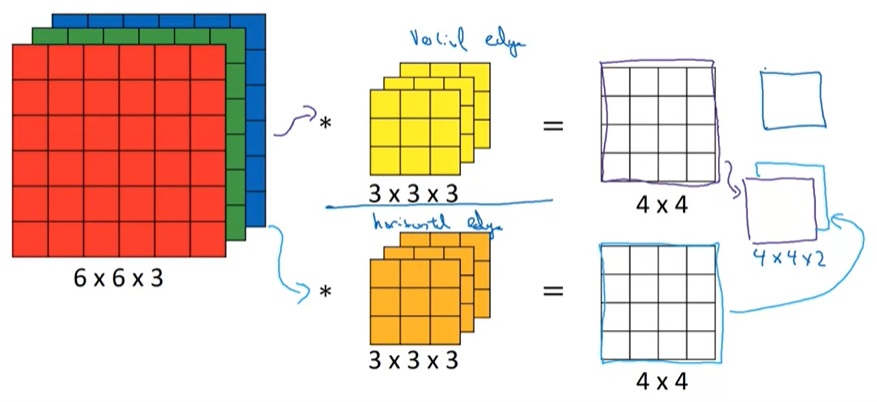
总结一下,假如输入图像的形状是$n \times n \times n_c$,卷积核的形状则是$f \times f \times n_c$。注意这个$n_c$必须是同一个数。假如有$n_c’$个卷积核,则输出图像的形状是$(n - f + 1) \times (n - f + 1) \times (n_c’)$。
在某些框架中,卷积核数量会也会当成卷积核的一个维度,比如可以用$n_c’ \times f \times f \times n_c$来表示一个卷积核组。
卷积神经网络中的卷积层
现在,我们已经掌握了卷积的基本知识,让我们来看看卷积神经网络中的卷积层长什么样。
卷积在卷积层中的地位,就和乘法操作在传统神经网络隐藏层中的地位一样。因此,在卷积层中,除了基础的卷积操作外,还有添加偏移量、使用激活函数这两步。注意,每有一个输出通道,就有一个$b$。
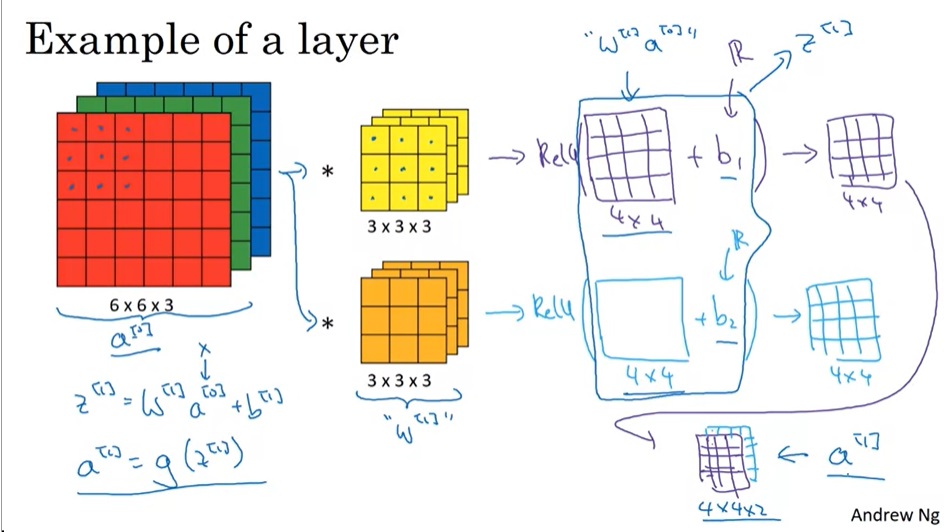
现在,我们可以总结一下一个卷积层中涉及的所有中间变量以及它们的形状了。

池化层与全连接层
池化层执行的池化操作和卷积类似,都是拿一个小矩阵盖在图像上,根据被小矩阵盖住的元素来算一个结果。因此,池化也有池化边长$f$和池化步幅$s$这两个参数。而与卷积不同的是,池化是一个没有可学习参数的操作,它的结果完全取决于输入。比如对于最大池化,每一步计算都会算出被覆盖区域的最大值。
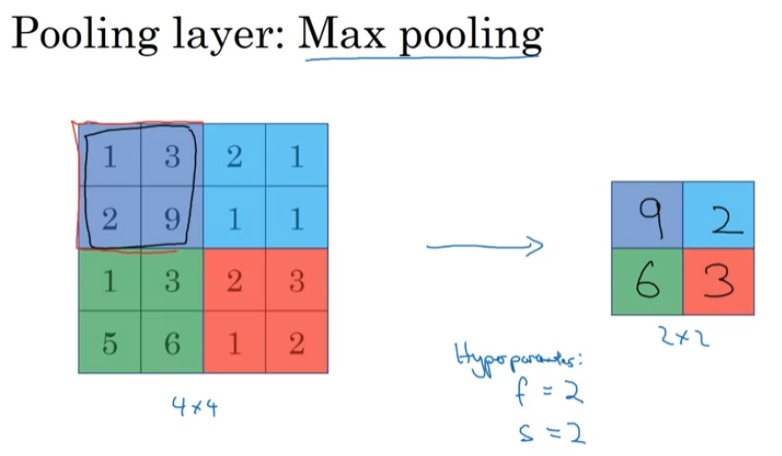
比如上图中,我们令池化边长为2,步幅为2。这样,就等于把一个$4 \times 4$的图像分成了$2 \times 2$个等大的区域。对于每一个区域,我们算一个最大值。
一般情况下,最常用的池化就是这种边长为2,步幅为2的池化。做完该操作后,图像的边长会缩小至原来的$\frac{1}{2}$。
除了最大池化,还有计算区域内所有数平均值的平均池化。但现在几乎只用最大池化,不用平均池化了。
没有人知道池化层究竟为什么这么有用。一种可能的解释是:池化层忽略了细节,保留了关键信息,使后续网络能够只关注之前输出的最值/平均值。
全连接层其实就是我们之前学的经典神经网络中的层。前一层的每一个神经元和后一层的每一个神经元直接都有连接。当然,在把图像喂入全连接层之前,一定别忘了做flatten操作,把图像中所有数据平铺成一个一维向量。
CNN示例
学完了CNN所有的基础构件,我们或许会感到疑惑:每个卷积层、池化层、全连接层都有那么多超参数,而且层与层之间可以随意地排列组合。该怎么搭建一个CNN呢?不急,让我们来看一个CNN的实例:
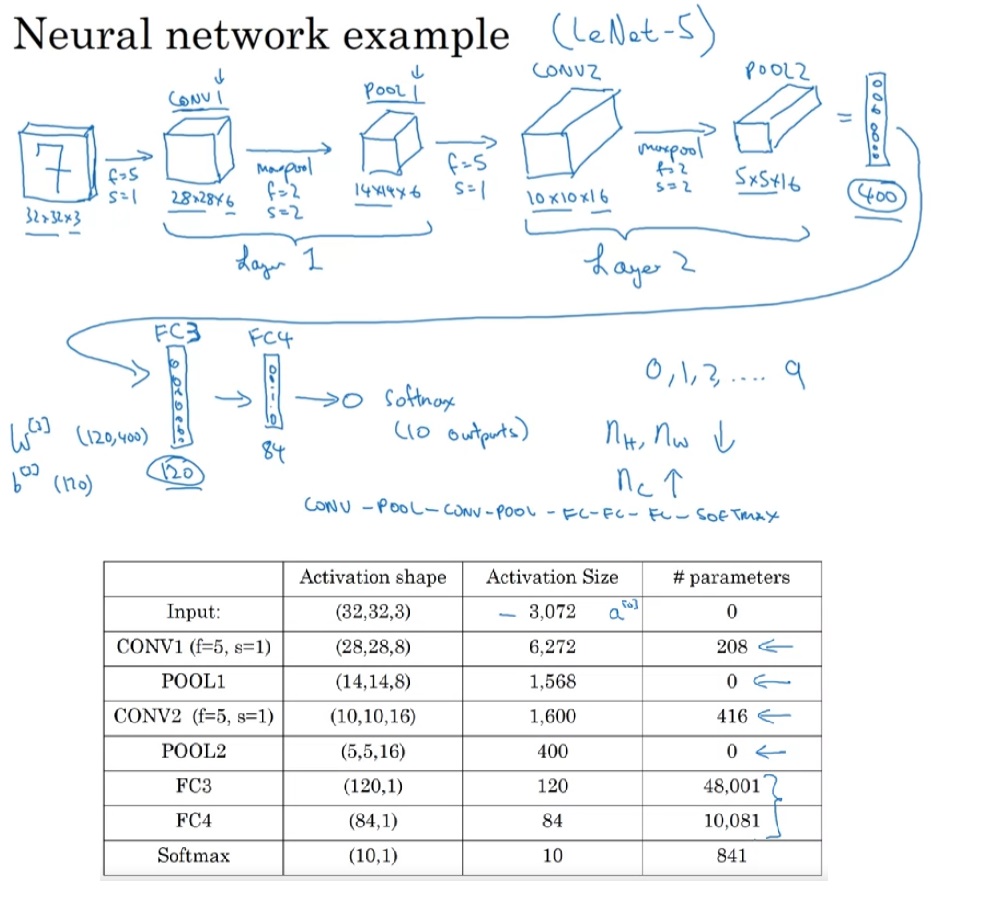
这个网络是经典网络LeNet-5的改进版,它被用于一个10-分类任务。我们会在下周正式学习这个网络。现在,让我们通过概览这个网络来找出一些搭建CNN的规律。
网络按照“卷积-池化-卷积-池化-全连接-全连接-softmax”的顺序执行。通常情况下,CNN都是执行若干次卷积,后面跟一次池化。等所有卷积核池化做完,才会做全连接操作。全连接之后就是由softmax激活的输出层。
另外,图像的形状也有一些规律。在卷积核池化的过程中,图像的边长不断变小,而通道数会不断变大。
下周,我们会继续认识一些经典的CNN架构,这些经典架构能够启发我们,帮助我们更好地搭建自己的CNN。
为什么用卷积?
这周,我们一直都在讲卷积。而卷积具体有哪些优点呢?
首先,卷积最大的优势就是需要的参数量少。回想这周开头讲的参数量问题。对于图像数据,如果用全连接网络的话,网络的参数会非常多。而卷积的两个性质,使得需要的参数量大大降低。这两个性质是权重共享与稀疏连接。
权重共享:对于输入图像的所有位置来说,卷积核的参数是共享的。这种设计是十分合理的。比如在边缘检测中,只要我们用同样一个[[1, 0, -1], [1, 0, -1], [1, 0, -1]]的卷积核卷网络,就能检测出垂直方向的边缘。这样,卷积操作的参数量就只由卷积核参数决定,而与图像大小无关。
稀疏连接:卷积核的大小通常很小,也就是卷积操作的一个输出只会由少部分的输入决定。这样,相比一个输出要由所有输入决定的全连接网络,参数量得到进一步的减少。
除了减少参数量外,这两个特性还让网络更加不容易过拟合。回想之前学过的dropout,卷积的这些特性就和扔掉了部分激活输出一样。
另外,卷积操作还适合捕捉平移不变性(translation invariance)。这个词的意思是说,如果一张图里画了一个小猫,如果你把图片往右移动几格,那么图片里还是一个小猫。由于同样的卷积操作会用在所有像素上,这种平移后不变的特性非常容易被CNN捕捉。
总结
在这堂课中,我们认识了CNN的三大基础构件:卷积、池化、全连接。其中,卷积和池化是新学的知识。这堂课的内容非常多,也非常重要,让我们来回顾一下。
- CNN 的优点
- CNN 与全连接网络的参数比较
- 权重共享、稀疏连接
- 卷积操作
- 基本运算流程
- 填充
- 步幅
- 示例:边缘检测
- 卷积层
- 对多通道图像卷积
- 输出多通道图像
- 加上bias,送入激活函数
- 池化层
- 运算流程
- 最大池化与平均池化
- CNN 示例
- 如何组合不同类别的层:卷积接池化,最后全连接。
- 图像边长变小,通道数变大。
由于深度学习编程框架通常会帮我们实现好卷积,卷积的实现细节倒没有那么重要。在这周的课里,最重要的是一些宏观的知识。我们要知道卷积有哪些参数、哪些超参数,了解卷积的优点。同时,还要知道卷积和其他构件是如何组成一个CNN的。
在这周的编程实战里,我们会用框架(TensorFlow和PyTorch)实现一个简单的CNN,完成图像分类任务。有时间多的话,我还会介绍一下如何用NumPy实现卷积的正向和反向传播。