ResNet是CV中的经典网络。在这篇文章中,我将按照阅读论文的通用方法由粗至精地解读这篇文章。如果你对ResNet不熟,最好对着原论文阅读本文。如果你已经很熟悉ResNet了,也可以通过这篇文章查缺补漏。
粗读
摘要
摘要的前三句话开门见山地介绍本文要解决的问题以及解决的方法。
- 问题:较深的神经网络很难训练。
- 本文的工作:提出了一种能够轻松训练比以往的网络要深得多的残差学习框架。
- 本文方法的进一步解释:神经网络的层将拟合一个基于输入的残差函数,而不是一个没有参考的函数。
随后,摘要展示了这种方法取得的成就:
- 经实验而非理论证明,增加深度后,模型的训练效果和测试效果都得到了提升。
- 精度打败了当时所有的分类模型。
- 深度高达152,大幅超过了当时较火的19层的VGG,同时并没有增加多少计算量。
- 精度打败了当时所有的检测、分割等任务的模型。这证明这种方法的泛化性强。
这篇摘要没有罗列贡献,而是在提出问题后轻轻一点,介绍了本文的方法及其作用。随后,所有的篇幅都在秀这种方法的成效。看完这段话,我们可能还不知道“残差”是怎么算的,但我们知道了这种方法很厉害,测试精度、训练难易度、泛化性都十分优秀,成功解决了较深的模型难以训练的问题。
在这轮粗读中,我们可以带着以下问题去概览论文:
- 文章要解决的具体是一个怎样的问题?为什么较深的神经网络很难训练?
- 文章提出的“残差”是什么?它为什么能解决深模型难训练的问题?
- 凭什么说深模型难训练的问题被解决了?实验是怎么做的?
- 这篇文章提出的模型比其他模型好在哪?
引言
引言用十分清晰的逻辑阐明了本文的核心思想——深度残差学习框架。引言先介绍“训练更深的神经网络”这一问题的由来,再抽丝剥茧地讨论该问题的解决方法,最后自然过渡到了本文的核心思想上。看完引言,我们就应该看懂这篇文章。
深度卷积神经网络的有效性,得益于它的“深度”。那么,是不是层数更深的网络就更好呢?过去的实验显示:不是的。
更深的网络面临的第一个问题是梯度弥散/爆炸,这些问题会令网络难以收敛。但是,通过参数归一初始化和归一化层,这一问题以及得到了有效缓解。证据就是,较深的网络能够收敛。
这时,较深网络又暴露出了第二个问题——退化:增加网络的深度,反而会降低网络的精度。这种退化和过拟合还不同,因为退化不仅导致精度降低,还提升了模型的训练误差。
这种退化,是不是说明较深的网络本质上就比不过较浅的网络呢?其实并不是,退化只是因为较深的网络不是那么容易优化。考虑一个较浅的网络,我们往它的后面增加几层全等映射(y=x)。这个变深的网络与原来的网络完全等价。从这个角度看,更深的网络最少不会比更浅的网络更差才对。因此,我们要想办法让学习算法能够更好地优化更深的网络,最起码优化出一个不比较浅网络更差的网络。也就是说,我们要想办法让学习算法能够轻松学会恒等映射。
文章提出了一种深度残差学习框架。假设一层网络表示的映射是$H(x)$,则该层的非线性层要拟合另一个表示残差的映射$F(x) := H(x) - x$。换个角度看,就是一层网络的输出由原来的$F(x)$变成了$F(x)+x$,多加上了一个$x$。这样,只要令$F(x)=0$,网络就能轻松描述恒等映射,较深的网络最起码不比较浅的网络更差了。
多个数据集上的实验表明,这种方法不仅容易训练,还能得到更高的精度。在多项任务的CV竞赛中,这种方法都独占鳌头。
看完了引言,我们基本能知道文章在解决怎样的问题,也大致明白了残差学习的原理。接下来,我们来过一过这篇文章的实验,看看这种方法的效果究竟如何。
实验
我们主要看几组ImageNet上的实验。为了方便称呼,作者把不使用残差连接的普通网络叫做“平坦(plain)”网络。第一组实验对比了不同深度的平坦网络的训练误差(细线)和验证误差(粗线)。
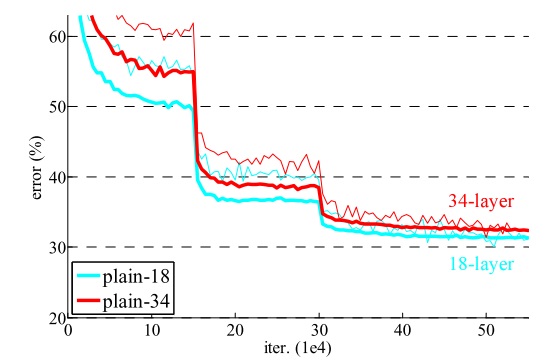
可以看出,更深的网络有更高的训练误差和验证误差。作者排除了梯度问题的影响。这些网络在训练时使用了Batch Normalization (BN),经调试,它们的梯度值也一切正常。因此,这种问题不是梯度消失导致的。引言中对于退化问题的描述得到了验证。
第二组实验是对残差网络ResNet的实验。我们可以把它的结果和平坦网络的放在一起对比。
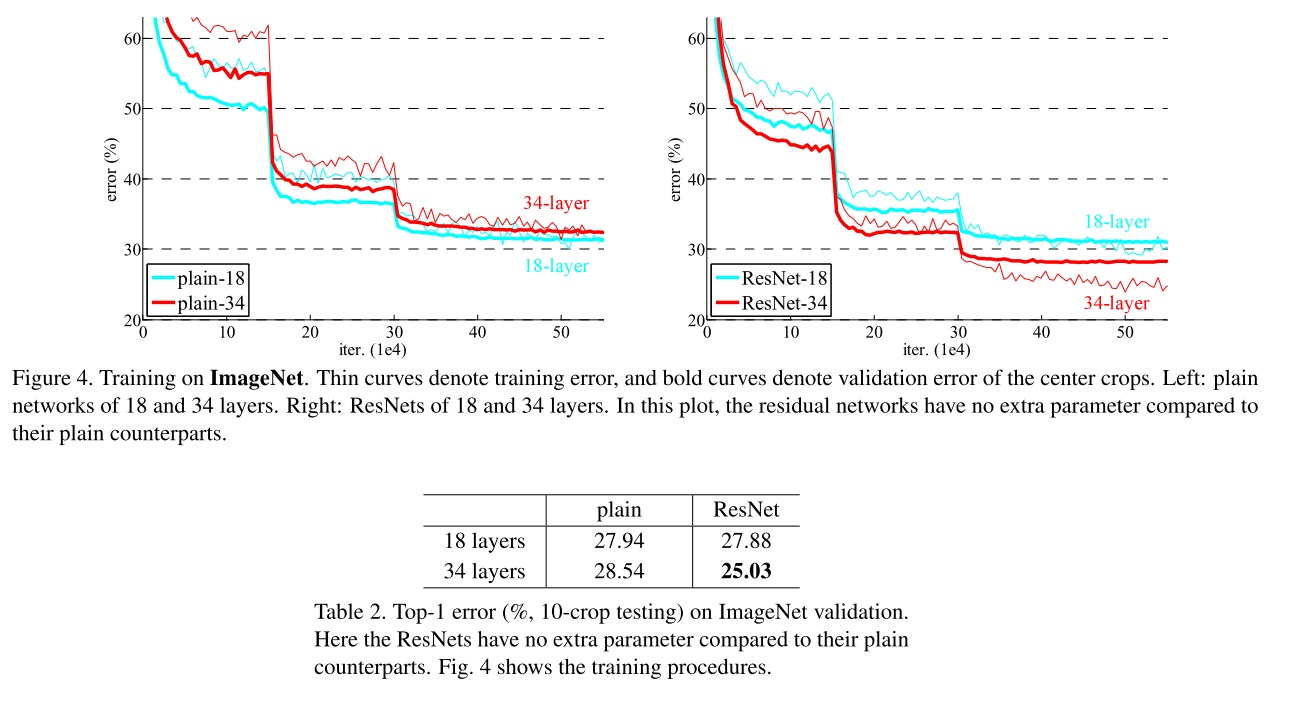
从图中可以看出,使用残差学习后,更深的网络果然有了更低的训练误差和验证误差。同时,从表中可以看出,残差网络的测试误差也降低了一大截。这说明残差学习很好地解决了前文提到的退化问题,且这种有效性在测试数据上依然能保持。
由于这轮粗读我们没读方法部分,和方法有关的实验结果得跳过。可以直接翻页到和其他模型的对比表格处:
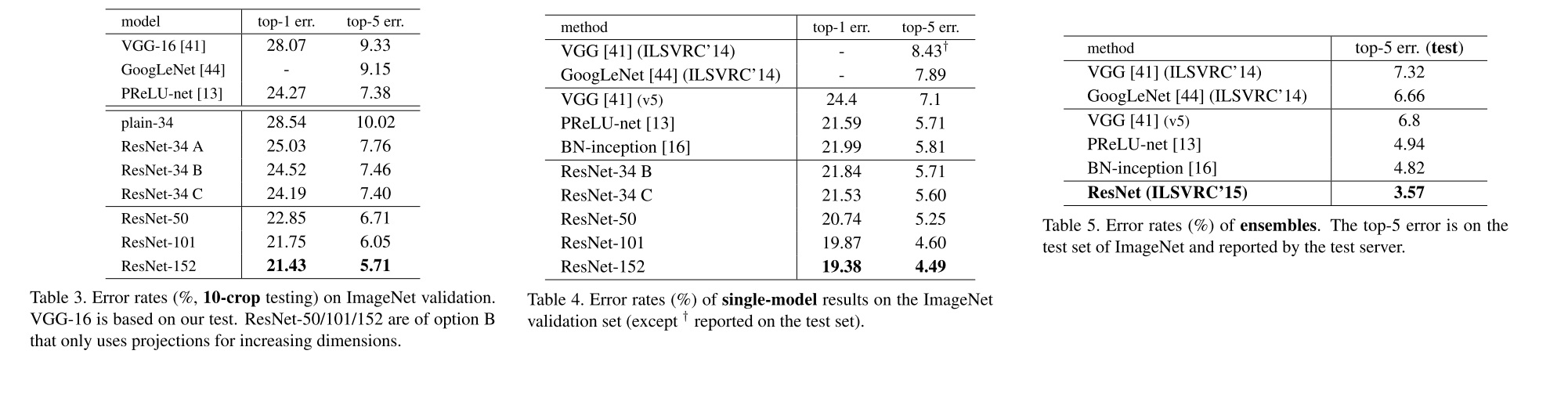
ResNet 在各个评价指标上打败了当时的其他网络,确实很厉害。
后面的表格显示,不仅是图像分类,ResNet在检测和分割等任务中也取得了第一名。
一般看到这里,一轮粗读就差不多完成了。从这轮粗读中,我们看懂了残差学习的核心思想,基本上理解了本文的核心创新点。当然,粗读深度学习相关的论文时,还可以扫一眼网络的核心模块和模型结构。精读的时候,我们再仔细理解文章的方法。
精读
残差公式
设多个层构成的模块在拟合一个映射$H(x)$,其中第一层的输入是$x$,则我们希望网络的非线性层去拟合另一个残差函数$F(x) := H(x) - x$,或者说整个模块在拟合$F(x) + x$。由于神经网络的多个非线性层能拟合任意复杂的映射,拟合一个残差函数$H(x)-x$也是可以实现的。
残差块
有了整体的思路,我们来具体看看每一个带残差的模块是怎么搭建的。具体而言,一个模块可以由输入$x$和参数集合${W_i}$计算得到(为了简化表达,bias被省略了):
我们主要关心$F(x, {W_i})$是怎么搭建的。文章中给出了一种简单的双层残差块示例,其中,$x$是以短路的形式连接到输出上的:
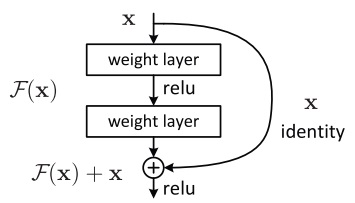
注意这里的$y = W_2\sigma(W_1x)$是一个未经激活的结果。整个模块送入下一层的输出是$\sigma(y)$,还要加上激活函数。
残差学习是一个框架,每个残差块可以有更多层。比如本文在实验部分还测试了另一种三层残差块(下图是一个示例,实际上通道数可以任意改变)。
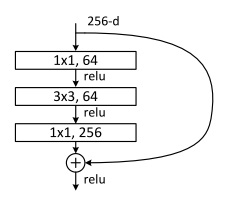
多层的残差块都是可行的。但是,单层的残差块$y = W_1x + x$和线性层几乎一样,不能提升网络的有效性。
上述的输入$x$是直接加到激活前的输出上的。这个加法操作有一个前提:模块的输入输出通道数是一样的。在输入输出通道数不同时,可以在短路连接上加一个变换维度的线性运算$W_sx$。原来直接做加法的操作叫做全等映射,这里加上一个线性运算再做加法的操作叫做投影映射。
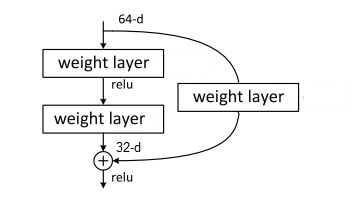
这里的符号标记都是基于全连接层的。这些计算对卷积层来说也一样,把矩阵乘法替换成卷积即可。
网络架构
本文先借鉴VGG的思路,先搭建了一个图像大小逐渐减半,深度逐渐翻倍的平坦网络。之后,在平坦网络连续的3x3卷积层上添加残差连接。下图中的实线代表普通的短路连接,虚线表示需要变换张量形状的短路连接。
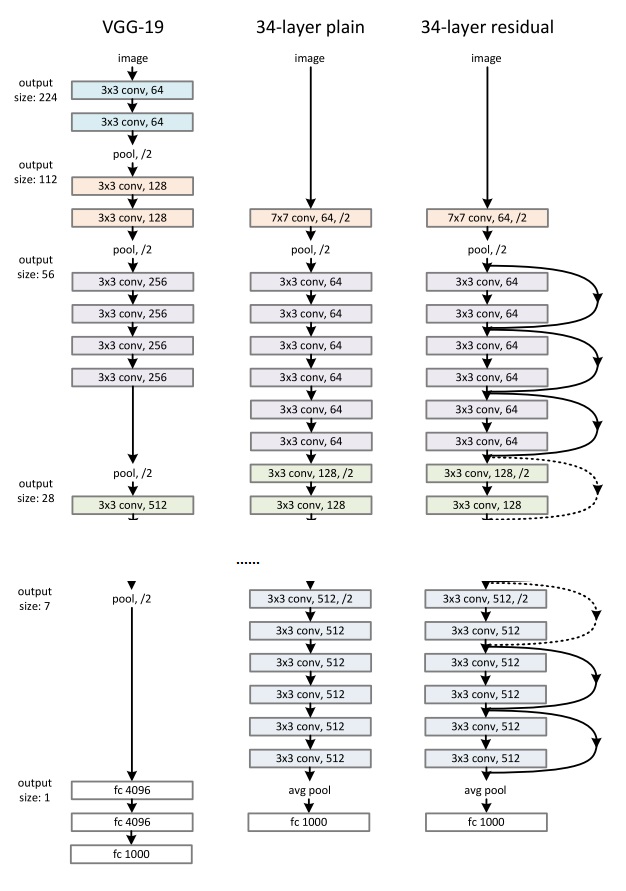
在虚线表示的残差连接中,图像的大小和深度都发生了改变。对于深度的增加,即可以使用上一节提到的投影映射,也可以直接往多出来的通道数里填0(全等映射)。对于大小的减半,无论是用怎样的深度变化方法,都可以使用步幅为2的操作来实现大小减半。
在投影时,要进行卷积操作,卷积的步幅为2很好理解。但是,文章没有详细介绍步幅为2的全等映射是怎么做的。直观上理解,就是以步幅2跳着去输入张量里取值。
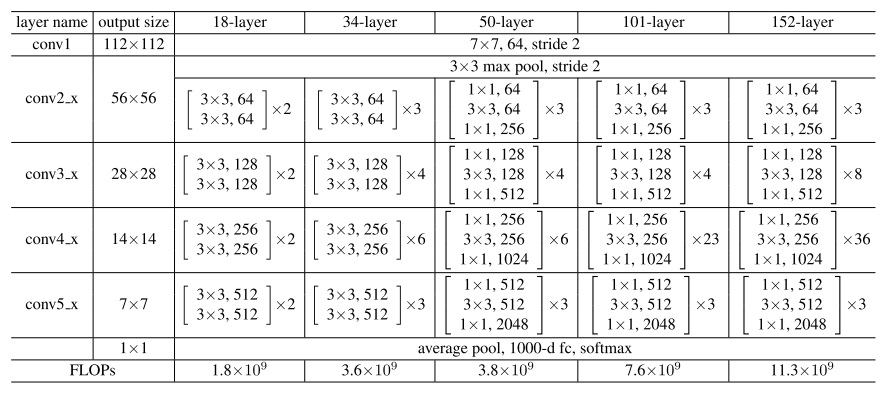
文章还提出了层数不同的ResNet架构。对于较深的网络,文章使用了3层残差块。
训练细节
训练的大部分配置都借鉴自AlexNet。如果你是刚入门图像识别且以后要从事这方面的研究,可以多关注这些细节。
数据处理:
- 随机缩放图像短边至 [256, 480] 中的均匀随机值
- 随机翻转
- 裁剪成 224x224
- 像素归一化(同AlexNet)
- 标准颜色增强(同AlexNet)
归一化
- 激活前使用BN
- 参数初始化使用 He Initialization
优化配置
- batch size 256 的 mini-batch 梯度下降
- 学习率初始化为0.1,发现误差不动了就除以10
- 迭代$60 \times 10^4$轮
- weight decay=0.0001, momentum=0.9
- 没有dropout
此外,为了提高比赛中的精度,在测试时使用了10-crop(对图像裁剪10次,把输入分别输入网络,取结果的平均值)。同时,图像以不同的尺寸输入进了网络,结果取所有运算的平均值。
实验
读懂了方法,我们再来详细读一遍实验部分。
再看一次平坦网络和残差网络的对比。
在这份对比实验中,残差网络相对平坦网络没有添加任何参数。当通道数改变时,残差网络用的是0填充的全等映射。这样,平坦网络和残差网络的唯一区别就是是否有短路连接,整个对比实验非常公平。实验的结果证明了残差连接的有效性。
这篇工作还做了另一个比较平坦网络的实验:在CIFAR-10数据集上统计了平坦网络和残差网络的3x3卷积输出的标准差。标准差大,能说明输出的数值较大。
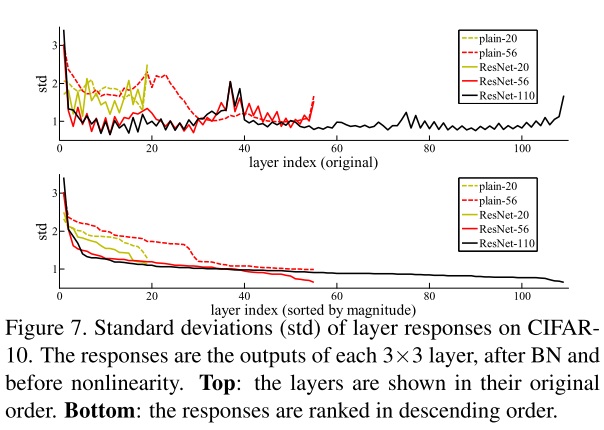
从这份对比结果中,我们能看出残差网络的输出标准差小于平坦网络。这符合残差学习的设计初衷:残差块至少是一个不会使性能变差的全等映射,其效果能够在全等映射的基础上优化。也因此,残差网络的输出大小会比平坦网络更靠近0。
看完了和平坦网络的对比,再看一看不同配置的ResNet直接的对比。文章先比较了全等映射和投影映射的短路连接。本文探讨了短路连接的3种配置:A) 全部使用全等连接 B) 有通道数变动的地方才使用投影连接 C) 全部使用投影连接。它们的表现如下:
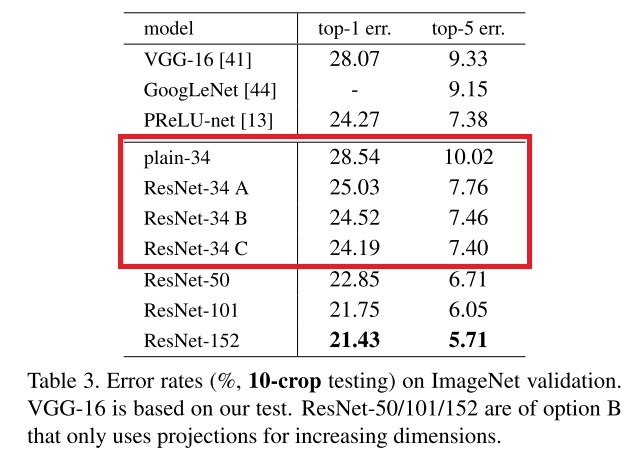
可以看出,投影用得越多,效果越好。作者认为,B相对A更好,是因为通道数变化时0填充的部分没有残差学习(也就是没有做$+x$的操作);C相对B更好,是因为参数更多了。这些实验结果说明,投影连接并不能解决退化问题,出于性能的考虑,本文没有在其他实验中使用C。
后来,B是公认的ResNet标配。
文章还讨论了构筑更深网络的bottleneck结构。如前文所述,50层以上的ResNet在每个残差块里使用了3个1x1, 3x3, 1x3的卷积。这种设计主要是为了缩短训练时间。ResNet-50和ResNet-34有着同样的时间复杂度,却因为深度更大,精度更高。
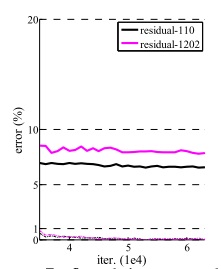
这篇论文的主要实验就是这些。论文后面还展示了一个比较有趣的实验:在CIFAR-10数据集上训练超过1000层的ResNet。实验结果显示,1000多层的ResNet仍能成功被优化,训练误差也降到了很低,但是测试误差没有110层的网络好。作者认为,这是因为训练数据太少,网络过拟合了。
总结
ResNet是基于深度学习的计算机视觉中里程碑式的工作。通过阅读这篇论文,我们发现,ResNet使用的残差结构本身并不十分复杂。这篇工作真正出彩之处,是发现了深度神经网络的一个普遍存在的问题,并用精彩的推理设计出了一套能够解决此问题的方案。这种方案确实很有效,基于残差学习的ResNet击败了同时代的所有网络。残差连接被用在了后续几乎所有网络架构中,使用ResNet为backbone也成了其他CV任务较为常用的初始配置。