词嵌入简介
基础概念
之前,我们是用one-hot编码来表示单词的:假设一个单词在词汇表里的序号是$t$,词汇表大小是$T$,则这个单词的编码是一个长度为$T$的向量,向量只有第$t$维是1,其他维都是0。我们用$O_t$来表示这个单词的one-hot编码。如下图所示。
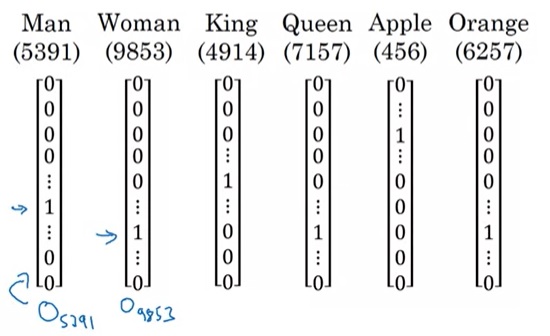
这种表示法能区分每个词,但是,它有一个缺陷:one-hot向量两两之间的乘积为0,不能通过向量的相似度推理出单词的相似度。因此,在NLP中,一个重要的任务就是找到一种合理的词表示方法,使得我们能够利用向量的某些性质来表示单词之间的某些性质。
我们来看一种新的词表示方法。假设有Man Woman King Queen Apple Orange这6个单词,我们从性别(Gender),皇家的(Royal),年龄(Age),是否是食物(Food)这几个角度来描述这几个单词,可以填写出这样一份表格:
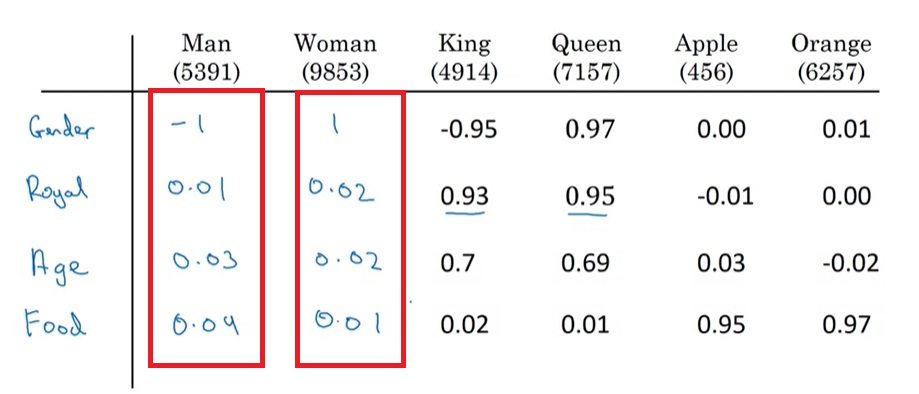
在这份表格里,每一列的数字可以看成属于某一单词的向量,这个向量就是一种词表示方法。我们用$e_t$表示词汇表里序号$t$的这种有意义的向量。比如$e_{5391}$就是Man的向量。观察每列的向量,我们能发现Woman和Man很相似,King Queen很相似,Apple和Orange很相似。这样,使用这种词表示,单词的相似度由向量的相似度表示了出来,符合我们对词表示的期望。
当然,使用算法生成的词表示中,向量的每一维不可能像这样可解释性这么强。
这种用向量描述单词的方法称为词嵌入(word embedding)。使用高维向量描述单词,就好像是把一个抽象的概念嵌进了一个向量一样。
词嵌入使用示例
看完了词嵌入的基础概念,我们来看看使用词嵌入有什么好处。
还是以命名实体识别任务为例。假设有这么一句话”Sally Johnson is an orange farmer”,我们能够推断出”Sally Johnson”是一个人名,这是因为我们看到了后面的”orange farmer”。橙子农民很可能与人名对应。
假设从刚刚那句话中,模型已经学会了橙子农民与人名之间的关系。现在,又有了一条新的训练样本”Robert Lin is an apple farmer”。使用了词嵌入的话,模型虽然不知道“苹果农民”是什么,但它知道”apple”和”orange”是很相似的东西,能够很快学会这句话的”Robert Lin”也是一个人名。
也就是说,通过使用词嵌入,模型能够利用单词之间的关系更快地完成学习。实际上,不仅是训练,使用了词嵌入后,哪怕出现了训练集中没出现过的单词,模型也能根据单词间的关系做出正确的推理。我们再来看一个例子。
假设又有一条测试样本”Robert Lin is a durian cultivator”。模型可能从来在训练集里没有见过”durian”和”cultivator”这两个单词。但是,通过词嵌入,模型知道”durian(榴莲)”是一种和”apple”相近的东西,”cultivator(培育者)”是一种和”farmer”类似的东西。通过这层关系,模型还是能够推理出”Robert Lin”是一个人名。
这就是词嵌入之所以那么重要的原因。词嵌入本质上是一种迁移学习,它隐含了在其他数据中学习到的单词之间的关系。利用这些知识,另一种任务能够在词嵌入的帮助下更快地完成学习。一般使用词嵌入的步骤如下:
- 用大量数据(千亿级)训练出词嵌入。
- 把词嵌入迁移到新任务上,使用一个较小的数据集(比如,万级)。
- 可选:继续finetune词嵌入(仅当新任务的数据量足够多时)。
除了加速训练外,词嵌入还有一个好处:词嵌入的向量长度往往较少。比如一个长度为10000的字典训练出来的词嵌入可能长度只有300。
结束这节前,顺便提一下词嵌入与上门课讲到的人脸识别中的编码(encoding)之间的关系。不管是嵌入还是编码,其实都是指向量,两种描述不少时候可以通用。但是,人脸识别中的编码主要指对任何一张数据算出一个编码,而嵌入指把一个已知的单词集合的每一个单词嵌进一个向量空间里。二者的主要区别在于输入集合是否固定。
词嵌入的性质
掌握了词嵌入的基本应用,让我们在另一种任务里进一步认识词嵌入的性质。
NLP里有一种任务叫做类比推理。比如,Man和Woman的关系,相当于King和谁的关系?有了词嵌入,这一问题就很好回答了。
还是以刚刚那张人工构造出来的词嵌入表为例。这里我们用$e_{man}$来表示Man的词嵌入,以此类推。

单词间的关系不好描述,而向量间的关系却很容易算。我们可以用向量的差来表示向量直接的关系。计算一下,$e_{man}-e_{woman} \approx [2, 0, 0, 0]^T$, $e_{king}-e_{queen} \approx [2, 0, 0, 0]^T$。通过猜测,我们发现King和Queen的关系与Man和Woman的关系类似。进而可以得出,Man之于Woman,相当于King之于Queen。
准确来说,刚刚这个问题相当于求解一个单词$w$,其嵌入$e_w$满足
,移项,$w$的计算方法就是:
,其中$sim$表示某种相似度,比如cosine相似度。只要我们计算出了右边的$e_{king}-e_{man}+e_{woman}$,再用某种算法就可以求出最合适的$e_w$了。
通过这些观察,我们可以发现,词嵌入蕴含了语义信息。词嵌入间的差别很有可能就是语义上的差别。
词嵌入矩阵
假设词嵌入向量的长度是300,有10000个单词。词嵌入的过程,其实就算把一个长度为10000的向量映射成长度为300的向量的过程。这个过程可以用一个$300 \times 10000$的矩阵$E$表示,$E$就是词嵌入向量的数组。每一个词嵌入列向量$e_t$可以由one-hot编码$o_t$和$E$计算得到:$e_t=Eo_t$。
词嵌入的学习
认识了词嵌入的基本概念后,我们来看看如何用学习算法得到一个词嵌入矩阵。
学习词嵌入和学习神经网络的参数是一样的。只要我们是在根据词嵌入算一个损失函数,就可以使用梯度下降法优化词嵌入。因此,问题的关键在于如何建模一个使用到词嵌入的优化任务。
语言模型
早期的词嵌入是通过语言模型任务学习到的。回想上周课的内容,语言模型就是预测一句话在这种语言中出现的概率。比如 “I want a glass of orange ___ .”,我们会自然地觉得空格里的单词是”juice”,这是因为填juice后整句话的出现概率比填其他单词更高一点。
暂时抛开上周讲的RNN,我们可以用一个使用词嵌入的神经网络来学习语言模型,如下图所示:
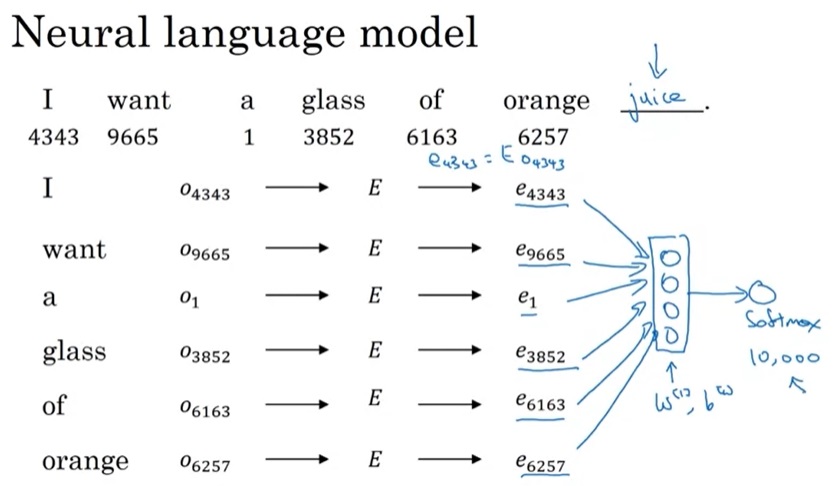
这个任务的输入是一句话中连续的6个单词,输出是第7个单词的预测。在用神经网络建模时,要先根据各个单词的one-hot编码$o_t$从词嵌入矩阵$E$中选出其嵌入$e_t$,再把各个单词的嵌入堆叠成一个向量,输入进标准神经网络里,最后用一个softmax预测下一个单词。
在这个模型中,可见的单词数是固定的。假设词嵌入的维度是300,那么根据6个单词进行预测的神经网络的输入向量长度就必须是1800。为了遍历整句话,可以拿一个长度为7(算上预测词)的滑动窗口在整句话上滑一遍。
可见前6个单词,其实算是网络的一个超参数。除了选取前6个单词外,还有其他的选取上下文的方式。常见的上下文选取方式如下:
- 前4个单词
- 前4个单词和后4个单词
- 前1个单词
- 往前数的第2个单词
经研究,如果只是要学习一个语言模型,使用前4个单词可能更好。而如果要学词嵌入的话,后几个方式也不错。
Word2Vec
Word2Vec是一种比语言模型更高效的词嵌入学习算法。与语言模型任务的思想类似,Word2Vec也要完成一个单词预测任务:给定一个上下文(context)单词,要求模型预测一个目标(target)单词。但是,这个目标单词不只是上下文单词的后一个单词,而是上下文单词前后10个单词中任意一个单词。比如在句子”I want a glass of orange juice to go along with my cereal”中,对于上下文单词glass,目标单词可以是juice, glass, my。
具体来说,每一条训练样本是一个上下文单词和目标单词的词对。比如(orange, juice), (orange, glass)。为了生成这些训练数据,我们要从语料库里每一个句子里采样出训练词对。在采样时,要先对上下文单词采样,再对目标单词采样。
假设有了上下文单词,对目标单词采样很简单,只需要从上下文单词的前后10个单词中均匀采样单词即可。而采样上下文单词就需要一些设计了。在英文中,大部分单词都是a, the, of这些没什么含义的词,如果在句子里均匀采样的话,大部分时候得到的都是这些词。因此,在Word2Vec论文中,有一些对上下文单词采样的设计,各单词的出现概率会更平均一点。
看完了训练数据的采样,再看一看Word2Vec的模型。Word2Vec模型非常简单,它是只有一个softmax层的神经网络,我们可以直接写出这个模型的公式:
$p(t|c)$即目标单词$t$在上下文单词$c$前后的出现概率。$e_c$是$c$的嵌入。$\theta$是softmax层的线性计算的参数,这里我们省略掉了bias。求和里的10000是整个词汇表的大小,也就是softmax输出向量的大小。
和其他多分类任务一样,这个任务的损失函数也是交叉熵函数。
Word2Vec的模型结构十分简单,因此,整个模型的计算量全部落在了softmax的分母求和上。假设词汇表有n个单词,整个模型的时间复杂度就是$O(n)$。在词汇表很大时,求和的开销也是很大的。
为了优化这个求和,Word2Vec使用了H-Softmax(Hierachical Softmax)这种优化方式。一个多分类任务,其实可以拆成多个二分类任务。比如有“猫、狗、树、草”这四种类别,我们可以先做是动物还是植物的二分类,再做一次更具体的二分类,最后把两次次二分类的概率乘起来。H-Softmax就是用这种思想优化了softmax的求和。
使用H-Softmax前,要先对所有单词建立一颗二叉树,比如对A, B, C, D四个单词,可以这样建树:”ABCD-(AB,CD)”, “AB-(A,B)”, “CD-(C,D)”。这样,把一个多分类问题拆成多个二分类问题,就等价于从树的根部开始,经过多个节点,达到单词所在的叶节点。使用H-Softmax时,只要把访问该单词的路径上所有节点的概率乘起来就行了。比如要求单词$x$是$C$的概率,可以先算$x$属于$CD$的概率$P(x \in CD)$,再算已知$x$属于$CD$时$x$是C的概率$P(x \in C | x \in CD)$,二者一乘就是我们要的$P(x \in C)$。
二分类的复杂度是$O(1)$,要做$O(logn)$次二分类。因此,经优化后,H-Softmax的复杂度$O(logn)$。实际上,这个算法还有一些优化空间。词汇表里的词汇是固定的,我们可以巧妙地修改建立二叉树的方法,进一步减少运算量。“给定各元素的访问概率(在这个问题里是单词在语言里的出现概率),对所有元素建立一颗二叉树,以最小化访问叶节点的路径长度的期望”是一个经典的问题,这个问题的解法叫做哈夫曼编码。这是离散数学的知识,和本课的关系就不大了。
H-Softmax的核心思想是把多分类拆成二分类,搞懂这个就行了。至于使用二叉树,怎么建立更好的二叉树,这是一个独立的子问题,理解它和理解H-Softmax无关。在学NLP时,可以先把这个子问题放一放,理解H-Softmax的用意就行。
Word2Vec的目标任务还有其他的形式。除了找上下文单词前后10个单词中的某个目标单词外,还可以用前后的1个单词预测中间的目标单词,这种方法叫做CBow。两种方法各有千秋。Word2Vec的主要思想是那个单层softmax模型,具体的任务倒不是最重要的。
负采样
通过前面几个小节的学习,我们能够总结词嵌入学习的一些经验:词嵌入的根本目的是学习词嵌入矩阵,使用词嵌入的任务倒没有那么重要。因此,我们可以放心大胆地去简化每轮任务的计算量,加快词嵌入的学习效率。
基于这种思想,我们可以进一步去优化Word2Vec里的多分类任务。实际上,一个N分类任务,可以“复杂化”成N个二分类任务——逐个判断输入是否是N个类别中的一种。顺着这个思路,我们不用去求给定上下文单词时目标单词的概率分布,只需要判断给定上下文单词和目标单词,判断二者是否相关即可。
这样,在每一轮任务中,我们不用去计算多分类的softmax,只要计算一个二分类的sigmoid就行了。这样一种算法叫做负采样(Negative Sampling)。
负采样使用的模型和Word2Vec一样简单:输入一个上下文单词的嵌入,经过一个sigmoid层,输出那个上下文单词和某个目标单词是否相关。
负采样算法中真正的难点是训练数据的生成。在看数据生成算法之前,我们先看一下训练样本的格式。负采样的每一条样本是一个三元组(context, word, target),分别表示上下文单词、目标单词、用01表示的两个单词是否相关。比如,我们可能会得到这样的正负样本:
| context | word | target |
|---|---|---|
| orange | juice | 1 |
| orange | king | 0 |
接下来,我们来看如何生成这些样本。使用Word2Vec的采样方法,我们会对语料库里的每一句话采样出一些词对。这样,每一个词对能构成一个正样本,它的target值为1。
正样本很好生成,可负样本就不是很好采样了。负采样算法使用了一种巧妙的采样方法(这也是其名称的由来):在生成一个正样本的同时,算法还会对同一个上下文单词context生成$k$个target为0的负样本。这些样本里的目标单词word是随机挑选的。
举个例子,设$k=4$,在”I want a glass of orange juice to go along with my cereal”这句话中,假如我们采样到了(orange, juice)这个词对,我们可能会随机选4个单词,得到下面这些训练样本:
| context | word | target |
|---|---|---|
| orange | juice | 1 |
| orange | king | 0 |
| orange | book | 0 |
| orange | the | 0 |
| orange | of | 0 |
注意,每$k$个负样本是针对一条正样本而言的。尽管orange, of都出现在了这句话里,但我们在考虑(orange, juice)这个正样本词对时,会把其他所有词对都当做负样本。
刚刚讲到,负样本里的word是随机挑选的。其实,这种“随机”有一些讲究。如果对所有单词均匀采样,那么不常用的词会被过度学习;如果按照单词的出现频率采样,of, the这些助词又会被过度学习。因此,在采样负样本时,这个负采样算法的论文使用了这样一种折中的方法:
这里$p(w_i)$表示第$i$个单词$w_i$被采样到的概率,$f(w_i)$是单词在这个语言中的出现频率。公式里的$\frac{3}{4}$是根据经验试出来的。
GloVe
GloVe(global vectors for word representation)是一种更加简单的求词嵌入的算法。刚才学习的几种方法都需要进行复杂的采样,而GloVe使用了一种更简洁的学习目标$x_{ij}$,以代替多分类任务或者二分类任务。
$x_{ij}$为给定上下文单词$i$时单词$j$出现的次数。和前面一样,这里的“上下文”可以有多种定义。比如,如果上下文的定义是“前后5个单词”,那么这就是一个对称的上下文定义,$x_{ij}=x_{ji}$;如果上下文的定义是“后1个单词”,则$x_{ij}\neq x_{ji}$。我们可以简单地把$x_{ij}$理解成$j$出现在$i$附近的次数。
比如我们把上下文定义为前后2个单词。在句子”a b c b d e”中,$x_{ca}=1, x_{cb}=2, x_{cd}=1, x_{ce}=0$。
有了$x_{ij}$,我们就能直接知道给定上下文$i$时各个单词$j$的出现频率,而不需要再构建一个分类任务去学习单词$j$出现的条件概率。这样一个新的误差函数是:
视频里的公式把i, j写反了。
和之前几个任务一样,$e_i$是上下文单词的词嵌入,$\theta$是线性计算的参数。$\theta^{T}_je_i$其实再就是拟合某单词$j$和上下文单词$i$的相关程度。而$logx_{ij}$恰好能反映某单词$j$和上下文单词$i$的相关程度。
刚刚那个误差函数有几个需要改进的地方:
- log 里面可能出现0。对于$x_{ij}=0$的地方,我们要想办法让$logx_{ij}=0$。
- 不同单词的出现频率不同。对于出现频率较少的单词,我们可以限制它对优化目标的影响。
- 可以像普通的线性层一样,加入偏差项bias。
因此,最终的损失函数为(假设词汇表大小10000):
其中,$f$是权重项,既用于防止$x_{ij}=0$($f(0)=0$),也用于调节低频率单词的影响。$b_i, b’_j$分别是上下文单词和目标单词的偏差项。
有趣的是,当$x_{ij}$是对称矩阵的时候,$\theta, e$也是对称的,它们在式子里的作用是等价的。我们可以让最终的词嵌入为$\theta, e$的平均值。
在结束词嵌入的学习前,我们还要补充学习一下词嵌入的一些性质。
上图是我们在这节课的开头学习到的“人造词嵌入”。在这个词嵌入中,向量的每一个维度都有一个意义。而在实际情况中,算法学习出来的词嵌入不能保证每个维度都只有一个意义。根据线性代数的知识,要表示同一个空间,有无数组选择坐标轴的方法。很可能0.3x+0.7y这个方向表示一个意思,0.4y+0.6z这个方向又表示一个意思,而不是每个坐标轴的方向恰好表示一个意思。当然,不管怎么选取坐标轴,两个向量的相对关系不会变,对词嵌入做减法以判断两个单词的关系的做法依然适用。
词嵌入的应用
情感分析
词嵌入可以应用于情感分析(Sentiment Classification)任务。在情感分析任务中,算法的输入是一段文字(比如影评),输出是用户表达出来的喜恶程度(比如1-5星)。

有了词嵌入,我们可以轻松地构筑一个简单的模型。
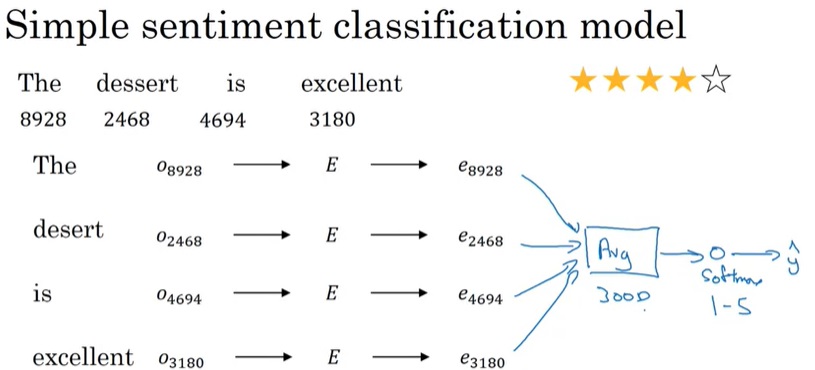
如上图所示,只要简单地对所有输入单词的词嵌入取平均值,放入softmax即可。
这种算法确实能够生效。但是,它只考虑了每个单词的含义,而忽略了整体的意思。如果句子里有”not”这种否定词,这个模型就不太有效了。为此,我们可以构建更精巧的RNN模型。
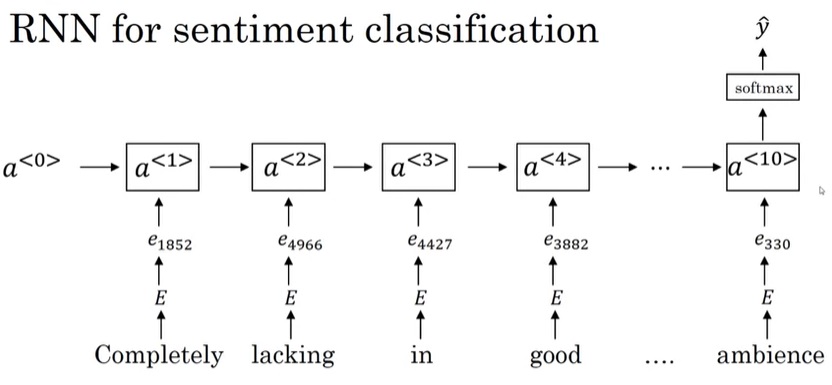
如第一周所学,RNN是一个“多对一”任务。我们可以让RNN最后一轮输出一个分类结果。只不过,这次输入RNN的不是one-hot向量,而是更有意义的词嵌入。
消除歧视
词嵌入会自动从大量的本文中学习知识。但是,数据中的知识可能本身带有偏见。比如,在自动学到的词嵌入看来,男人之于程序员,就像女人之于家庭主妇;父亲之于医生,就像母亲之于护士。类似的歧视不仅存在于性别这一维度,还存在于种族、年龄、贫富等维度。我们希望消除词嵌入里面的这些歧视。
本节仅对消除歧视的方法做一个简介,很多实现细节都被省略了。详情请见原论文。
词嵌入本身是向量,歧视其实就是某些本应该对称的向量不太对称了。我们的目的就是在带有偏见的维度上令向量对称。
第一步,我们要找到带有偏见的维度。比如,对于性别维度,我们可以算$e_{he}-e_{she}, e_{male}-e_{female}$,对这些表示同一意义的方向取一个平均向量,得到偏见的方向。得到方向后,我们可以用一个平面图来可视化和偏见相关的向量。假设词嵌入的长度是300,那么x轴表示带有偏见的那个维度,y轴表示剩余的299个维度。
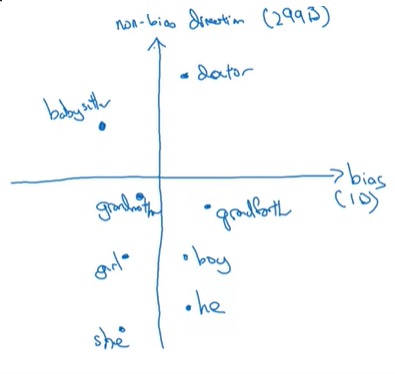
所有的单词可以分成两类:和性别相关的明确(definitional)单词和剩余不明确的单词(明确单词需要手动找出来)。第二步,我们要让所有不明确单词都恰好回到y轴上。这样,任何其他单词都不会偏向某一性别了。
最后,有些和性别相关还不够对称。我们要想办法让每对和性别相关的词恰好按y轴对称。
总结
在这堂课中,我们系统地学习了词嵌入这个概念,并大致了解了如何在NLP任务中使用词嵌入。相关的知识有:
- 词嵌入简介
- 从one-hot到词嵌入
- 词嵌入向量的意义
- 词嵌入学习算法
- 语音模型
- Word2Vec
- 负采样
- GloVe
- 如何应用词嵌入
词嵌入是专属于NLP的概念,且是NLP任务的基石。如果要开展NLP相关研究,词嵌入是一个绕不过去的知识;反过来说,如果不搞NLP,只是想广泛地学习深度学习,那么词嵌入本身可能不是那么重要,对词嵌入问题的建模方法会更重要一点。
只从实用的角度来看的话,这堂课介绍的知识并没有那么重要,网上能够轻松找到别人预训练好的词嵌入权重。真正重要的是词嵌入在框架中的使用方法,以及如何在一般任务中使用词嵌入。在这周的代码实战中,我会分享一下如何用预训练的词嵌入完成某些NLP任务。