在前两周的课中,我们分别学习了RNN的基础结构、词嵌入的知识。学完这些东西后,我们已经能够开发大多数NLP应用了。
正如我们第一周所学,序列任务的本质区别是输入和输出的映射关系不同。我们曾经把任务按映射关系分成一对一、一对多、多对一、等长多对多、不等长多对多。其中,不等长的多对多任务是最常见、最通用的。这周,我们就要以机器翻译任务为例,学习解决多对多问题的更多技巧。同时,我们也会学习机器翻译任务中比较出名的一种模型架构——注意力模型。
学完了机器翻译任务的一些常见架构后,我们还会把这些方法拓展到语音识别问题上,了解一些语音识别中的常见任务。
序列到序列模型
基础模型
有一些问题,它们的输入和输出都是一个序列。比如说机器翻译,输入是某种语言的一句话,输出是另一种语言的一句话。这种序列到序列的问题可以简单地套用RNN解决。
如我们第一周所学,不等长的序列到序列问题可以用如下的RNN模型解决。前面只有输入的部分叫做编码器(encoder),后面输出的部分叫做解码器(decoder)。
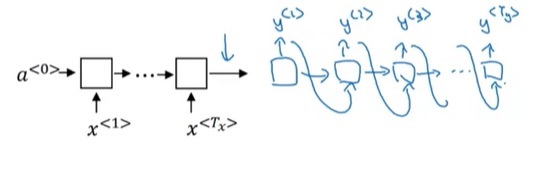
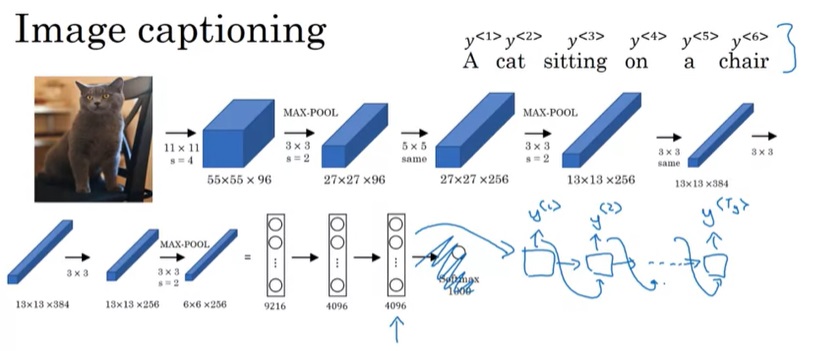
再举另一个任务——看图说话的例子。看图说话,就是输入一幅图片,输出该图片的文字描述。比如给定下图的图片,我们可以说“小猫在椅子上”。这个任务的输入看上去并不是一个序列,但我们可以用某种CNN架构把图片转换成一个向量。这个向量就可以看成图片的编码,和刚刚那个RNN编码器的输出一样。利用这个编码,我们可以用RNN解码器生成一句话。
挑选最好的句子
但是,这种基础的架构类似于我们第一周学的语言模型。它可能生成多个新句子,而不能保证生成最好的句子。为了按要求生成最好的句子,我们要使用一些其他的方法。
比如把“Jane九月要访问非洲”翻译成英文,可以翻译成”Jane is visiting Africa in September.”,也可以翻译成”Jane is going to be visiting Africa in September.”。上节提到的那个类似于语言模型的RNN架构可以生成出这两个句子中的任何一个。
从语言的角度,”Jane is visiting Africa in September.”这个翻译比”Jane is going to be visiting Africa in September.”更好。或者说,前面那个句子的概率更高一点。用数学公式来表达,给定被翻译的句子$x$, 我们希望求一个使$P(y^{< 1 >}, y^{< 2 >}, …y^{< T_y >},|x)$最大的序列$y$。
求解这个最优化问题时,我们可能会想到贪心算法。由于RNN解码器每步的softmax可以输出下一个词的概率(还是和语言模型一样的道理),我们可以求出$argmax_{y^{< 1 >}}P(y^{< 1 >}|x)$, $argmax_{y^{< 2 >}}P(y^{< 2 >}|y^{< 1 >}, x)$, …,即用贪心算法每次求出一个概率最大的单词。
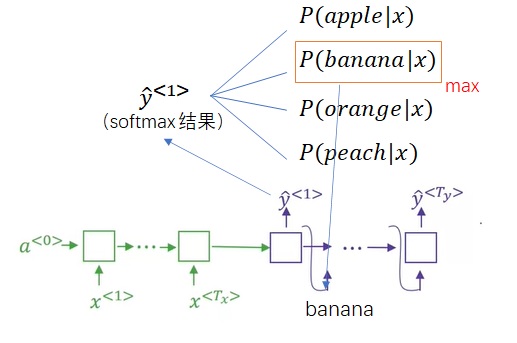
然而,每次选一个概率最大的单词,不能保证整句话概率最大。比如,模型可能有”Jane is visiting Africa in September.”和”Jane is going to be visiting Africa in September.”这两个潜在的候选翻译结果。选第三个单词时,”going”的概率可能比”visiting”要高,按贪心算法,我们最后会生成出第二个句子。可是,从翻译质量来看,第一个句子显然更好,它的概率更高。
为了求出概率最大的输出序列,我们要使用一种较好的搜索算法。
Beam Search
贪心算法每次只求出能令当前句子概率最大的下一个单词。这种算法太容易遗漏更优的输出了。而如果真的想求出最优的句子,即求出$argmax_{y}P(y|x)$,需要遍历所有可能的$y$。假如每个单词有$N$种选择,句子长度$T_y$,则搜索算法的复杂度是$O(N^{T_y})$。这个指数增长的复杂度是不能接受的。
Beam Search是这样一种折中的启发式搜算算法。它不能保证求出最优解,却能比贪心算法找出更多更优的解。
Beam Search的核心思想可以用一句话概括:相比于只维护一个概率最优句子的贪心算法,Beam Search每次维护$B$个概率最优的句子。
还是拿开始那句话的翻译为例,并假设$B=3$,词汇表大小为10000。生成第一个单词时,概率最高的三个单词可能是in, Jane, September。生成第二个单词时,我们要遍历第一个单词是in, Jane, September时的所有30000种两个单词组合的可能。最终,我们可能发现in September, Jane is, Jane visits这三个句子的概率最高。依次类推,我们继续遍历下去,直到生成句子里的所有单词。

这个算法用伪代码表示如下:
这份伪代码不是用来是解读的,而是用来对齐想法的。看懂了算法的流程后,读者应该能够用自己的伪代码把这个算法写出来。如果读者自己能写出伪代码,就也能顺着思路读懂我的这份伪代码。
1 | Input x, B |
Beam Search 还有一些优化的手段。
在Beam Search中,我们用了语言模型中求句子的概率的方法,即:
这个概率是我们的优化目标。但是,使用累乘会碰到计算机硬件精度不够的问题。为此,我们可以把优化目标由累乘取log变成累加:
此外,大多情况下,输出的句子越短,句子可能越不准确。因此,我们可以给优化目标添加一个和长度有关的归一化项:
这里的$\alpha(\alpha< 1)$是一个超参数,它用于让长度惩罚更平滑一点,即模型更容易生成长句子。一般$\alpha=0.7$。
为了生成不同长度的句子,在让decoder输出句子时,我们可以记录下$T_y=1, 2…$时概率最大的句子。得到了这些不同长度的候选句子后,把它们的概率乘上归一化项,找出整体概率最大的句子。
Beam Search是一种启发式算法,它的效果取决于超参数B。一般情况下,为了保证速度,B取10就挺不错了。只有在某些不考虑速度的应用或研究中才会令B=100或更高。
加入Beam Search会让我们调试机器翻译算法时更加困难。还是对于开始那个翻译示例,假如人类给出了翻译$y^{\ast}$:Jane visits Africa in September,算法给出了翻译$\hat{y}$:Jane visited Africa last September。这个算法的翻译不够好,我们想利用第三门课学的错误分析方法来分析错误的来源。这究竟是Beam Search出了问题,还是RNN神经网络出了问题呢?
对此,我们可以把训练好的RNN当成一个语言模型,输入$y^{\ast}$和$\hat{y}$,求出这两个句子的概率。如果$y^{\ast} \gt \hat{y}$,那说明RNN的判断是准确的,是Beam Search漏搜了;如果$y^{\ast} \leq \hat{y}$,那说明RNN判断得不准,是RNN出了问题。
Bleu Score
在图像分类中,我们可以用识别准确率来轻松地评价一个模型。但是,在机器翻译任务中,最优的翻译可能不只一个。比如把“小猫在垫子上”翻译成英文,既可以说”The cat is on the mat”,也可以说”There is a cat on the mat”。我们不太好去评价每句话的翻译质量。Bleu Score就是一种衡量翻译质量的指标。
为了评价一句话的翻译质量,我们还是需要专业翻译者给出的参考翻译。比如把刚刚那两句英文翻译作为参考译句:
- The cat is on the mat
- There is a cat on the mat
我们可以把机器的翻译结果和这两句参考结果做对比。对比的第一想法是看看机器翻译的句子里的单词有多少个在参考句子里出现过。但是,这种比较方法有问题。假如机器输出了”the the the the the the the”,the在参考句子里出现过,输出的7个单词全部都出现过。因此,翻译准确率是$\frac{7}{7}$。这显然不是一个好的评价指标。
一种更公平的比较方法是,每个单词重复计分的次数是原句中该单词出现的最大次数。比如,the在第一个参考句子里出现2次,在第二个参考句子里出现1次。因此,我们认为the最多计分两次。这样,这句话的翻译准确率就是$\frac{2}{7}$。这个评价结果好多了。
我们不仅可以对单个单词计分,还可以对相邻两个单词构成的单词对计分。比如机器翻译输出了句子The cat the cat on the cat。我们统计每一个词对在输出里出现的次数和计分的次数。
| count | score | |
|---|---|---|
| the cat | 2 | 1 |
| cat the | 1 | 0 |
| cat on | 1 | 1 |
| on the | 1 | 1 |
| the mat | 1 | 1 |
这样,这个句子的准确率是$\frac{4}{6}$。
这种打分方式就叫做bleu score。刚刚我们只讨论了考虑一个单词、两个单词时的打分结果。实际上,我们可以用$p_n$表示连续考虑$n$个单词的bleu score。最终评价一个翻译出来的句子时,我们会考虑到$n$取不同值的情况,比如考虑$n=1, 2, 3, 4$的情况。最终使用的这种指标叫做组合bleu score,它的计算公式为:
其中,BP的全称是brevity penalty(简短惩罚)。这是一个系数,用于防止输出的句子过短。它的计算公式是:
其中,$L_o$是输出句子的长度,$L_r$是参考句子的长度。
bleu score是一个能十分合理地评价机器翻译句子的指标。在评估机器翻译模型时,我们只要使用这一种指标就行了,这符合我们在第三门课中学习的单一优化目标原则。bleu score最早是在机器翻译任务中提出的,后续很多和句子生成相关的任务都使用了此评估指标。
注意力模型
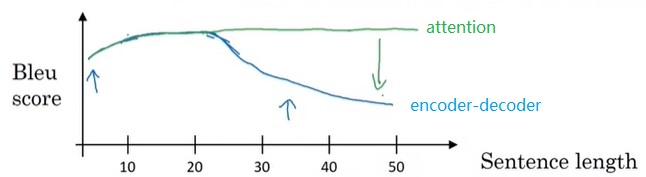
我们刚刚学习的这种“编码器-解码器”架构的RNN确实能在机器翻译上取得不错的效果。但是,这种架构存在一定的限制:模型的编码(输入)和解码(输出)这两步都是一步完成的,模型一次性输入所有的句子,一次性输出所有的句子。这种做法在句子较短的时候还比较可行,但输入句子较长时,模型就“记不住”之前的信息了。而我们这一节学习的注意力模型能够很好地处理任意长度的句子。
让我们看看人类在翻译长句的时候是怎么做的。比如把“简访问非洲”翻译成”Jane visits Africa”时,我们一般不会把整句话一次性翻译,而是会对单词(或文字)逐个翻译。我们会把“简”翻译成”Jane”,“访问”翻译成”visits”,“非洲”翻译成”Africa”。在输出每一个单词时,我们往往只需要关心输入里的某几个单词就行了,而不需要关注所有单词。
注意力模型就使用了类似的原理。在注意力模型中,我们先把输入喂给一个BRNN(双向RNN)。这个BRNN不用来输出句子,而是用于提取每一个输入单词的特征。我们会用另一个单向RNN来输出句子。每一个输出单词的RNN会去查看输入特征,看看它需要“关注”哪些输入。比如,”Jane”的RNN会关注“简”的特征,”visits”的RNN会关注“访”和“问”的特征。这一过程如下图所示(线条表示输出对输入的关注,线条越粗关注度越高)。
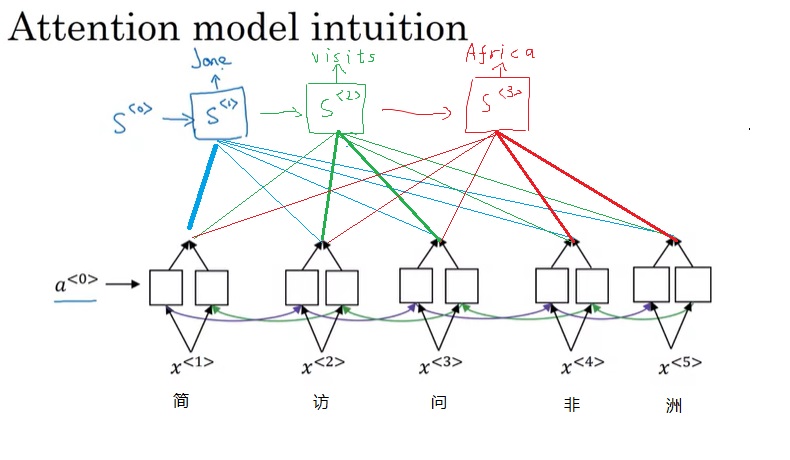
这样,不管输入的序列有多长,每一个输出都能找到它需要关注的部分单词,仅根据这些输入来完成翻译,就和我们人类的做法一样。这就是注意力模型的思想。
让我们看一下具体的计算过程。为了区分上下两个RNN,我们用$a$表示编码RNN的状态,$t’$表示输入序号;$s$表示解码RNN的状态,$t$表示输出序号。刚才提到的那种关注每个输入单词的注意力机制会给每个输出一个上下文向量$c^{< t >}$。这个向量和上一轮输出$\hat{y}^{< t-1 >}$拼在一起作为这轮解码RNN的输入。
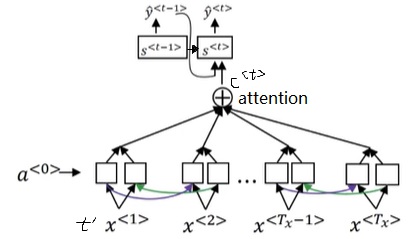
注意,从逻辑上来讲,解码RNN有两个输入。第一个输入和我们之前见过的解码RNN一样,是上一轮的输出$\hat{y}^{< t-1 >}$。第二个输入是注意力上下文$c^{< t >}$。这两个输入通过拼接(concatenate)的方式一起输入解码RNN。我在学到这里的时候一直很疑惑,两个输入该怎么输入进RNN。原视频并没有强调两个输入是拼接在一起的。
如果输出的单词不是很依赖于上一个单词,解码RNN也可以不输入上一个单词,只输入注意力上下文。这门课的编程作业就采用了这种只有一个输入的更为简单的结构。
接下来,我们来详细看看注意力机制是怎么工作的。如前文所述,注意力机制就是要算一个对每个输入的关注度,根据这个关注度以不同的权重去输入里取值。这个过程的表示如下。
设输入状态$a^{< t’ >}=(\overrightarrow{a}^{< t’ >}, \overleftarrow{a}^{< t’ >})$(把BRNN前后的状态拼接到一起)。假如我们得到了权重$\alpha^{< t, t’ >}$,它表示第$t$个输出对第$t’$个输入的关注度,则注意力上下文$c^{< t >}$的计算方法为:
对于每一个$t$, 所有$t’$的$\alpha^{< t, t’ >}$和为1。也就是说,上式其实就是一个加权平均数,其中$\alpha^{< t, t’ >}$是权重。“注意力”这个名词看上去很高端,其实就是一个中学生都会的概念而已。
现在,我们还不知道关注度$\alpha^{< t, t’ >}$是怎么算的。让我们思考一下,第$t$个输出单词和第$t’$个输入单词的关注度取决于谁的信息呢?答案很简单,取决于第$t$个输出单词的信息和第$t’$个输入单词的信息。第$t$个输出单词的信息,可以用其上一层的状态$s^{< t-1 >}$表达;第$t’$个输入单词的信息,可以用$a^{< t’ >}$表达。怎么用它们算一个关注度出来呢?谁也给不出一个具体的公式,干脆就用一个神经网络来拟合就好了。
具体的计算过程如下图所示:
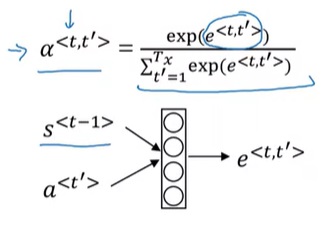
我们用一个小全连接网络算出一个输出$e^{< t, t’ >}$。由于$\alpha^{< t, t’ >}$最后的和要为1,我们用对$e^{< t, t’ >}$做一个softmax,得到归一化的$\alpha^{< t, t’ >}$。
整理一下,注意力模型的计算步骤如下:
- 用一个编码RNN(比如Bi-LSTM)算出输入的特征$a^{< t’ >}$。
- 用一个解码RNN(比如LSTM)的状态$s^{< t-1 >}$和所有$a^{< t’ >}$算一个对每个输入的关注度$\alpha^{< t, t’ >}$ 。
- 以关注度为权重,以$a^{< t’ >}$为值,算一个加权平均数$c^{< t >}$作为第$t$个输出的注意力上下文。
- 以上一轮输出$y^{< t-1 >}$和$c^{< t >}$为输入,以$s^{< t-1 >}$为上一轮状态,计算解码RNN这一轮的输出$y^{< t >}$。
注意力模型的效果不错,但它的计算复杂度是平方级别的(输入长度乘输出长度)。不过,机器翻译任务的输入输出都不会太大,这一性能弊端没有那么明显。
语音任务
语音识别
到目前为止,我们主要用序列模型完成NLP任务。其实序列模型也很适合用在语音数据上。让我们来快速认识一下语音识别任务的解决方法。
语音数据是一维数据,表示每一时刻的声音强度。而我们人脑在在接受声音时,会自动对声音处理,感知到声音的音调(频率)和响度。
语音识别任务的输入是语音数据,输出是一个句子。我们可以直接用注意力模型解决这个问题(令输出元素为字母而不是单词),也可以用一种叫做CTC(connectionist temporal classification)的算法解决。
CTC算法用于把语音识别的输入输出长度对齐。这样,我们用一个简单的等长多对多RNN就可以了。在语音识别中,输入的长度远大于输出的长度,我们可以想办法扩大输出长度。这种扩充方式如下:
比如,对于句子”the quick brown fox”,我们可以把”the q”它扩充成ttt_h_eee____< space >____qqq__。这个和输入等长的序列表示每一个时刻发音者正在说哪个字母。序列中有一些特殊标记,下划线表示没有识别出任何东西,空格< space >表示英语里的空格。
通过这种方法,我们可以把所有训练数据的标签预处理成和输入等长的序列,进而用普通RNN解决语音识别问题。
触发词检测
触发词检测也是一类常见的语音问题,我们可以用序列模型轻松解决它。
触发词检测在生活中比较常见,比如苹果设备的”Hey Siri”就可以唤醒苹果语音助手。我们的任务,就是给定一段语音序列,输出何时有人说出了某个触发词。
我们可以用一张图快速地学会如何解决这个问题。如下图所示,对于每一个输入,我们可以构造一个等长的输出,表示每一时刻是否说完了触发词。每当一个触发词说完,我们就往它后面几个时刻标上1。用一个普通RNN就可以解决这个问题了。
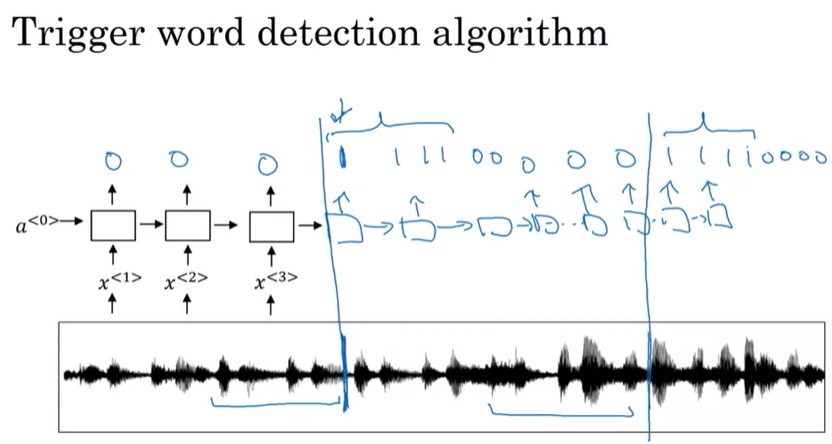
从这两个示例中,我们能看出,学会了序列模型后,我们掌握了很多武器。而在解决实际问题时,关键在于如何建模,把问题的输入输出对应到RNN的输入输出上,把我们的武器用出去。
总结
这堂课以机器翻译任务为例,介绍了序列到序列问题的一些解决方法。特别地,这堂课介绍了注意力模型。注意力模型在序列到序列问题上有着极佳的表现,并催生了后续纯粹由注意力机制构成的更加强大的Transformer模型。利用这些学到的知识,我们可以轻松地解决大多数序列到序列问题,比如和语音相关的语音识别与触发词检测问题。
这堂课的知识点有:
- Beam Search
- 序列到序列问题的建模方法:解码器与生成器,生成一个概率尽可能大的输出序列
- 为什么需要搜索算法,为什么贪心算法不好
- Beam Search 的过程
- Bleu Score 的计算思想:公平地根据参考序列评价生成序列的质量
- 注意力模型
- 新的编码器-解码器架构
- 注意力机制的动机
- 解码器怎么利用注意力权重
- 注意力权重怎么生成
- 语音问题
- 建模思想:对齐输入输出序列,用简单的RNN解决问题
- 语音识别CTC算法:输出每一时刻正在发音的字符
- 触发词检测:用01表示是否有触发词
本来,深度学习专项的课程就到此为止了。但是,后来Transformer太火了,课程专门加了一节介绍Transformer的内容。让我们在下周详细学习一下Transformer这一功能强大的模型架构。