在最后一课中,我们要学习Transformer模型。Transformer是深度学习发展史上的一次重大突破,它在多个领域中取得了傲人的成绩。Transformer最早用于解决NLP任务,它在CV任务上的潜力也在近几年里被挖掘出来。
RNN有一个致命的缺陷:计算必须按照时序执行,无法并行。为了改进这一点,Transformer借用了CNN的想法,并行地用注意力机制处理所有输入,抛弃了经典RNN的组件。
为了理解Transformer,我们将主要学习两个概念:自注意力和多头注意力。
- 自注意力:Transformer会为序列里的每一个元素用注意力生成一个新的表示,就和CNN里卷积层能为每个像素生成高维特征向量一样。这个表示和词嵌入不同,词嵌入只能表示一个单词本身的意义,而「自注意力」生成的表示是和句子里其他单词相关的。
- 多头注意力:「多头注意力」表示多次利用自注意力机制,生成多个表示,就和CNN里N个卷积核能生成N个特征一样。
这节课是《深度学习专项》新增的课程,内容比较简短。估计是因为Transformer太火了,不得不在教材里加上这些新内容。这节课讲得并不是很清楚,我会用更易懂的逻辑把这节课讲一遍。
Transformer
自注意力
词嵌入只能反映一个词本身的意思,而不能反映一个词在句子中的意思。比如我们要把”简访问非洲“翻译成英文,其中第三个字“问”有很多意思,比如询问、慰问等。自注意力的目的就是为每个词生成一个新的表示$A$,反映它在句子中的意思,比如我们为“问”字生成的表示$A^{< 3 >}$是“访问”这个具体的意思。
自注意力,顾名思义,就是对句子自己使用注意力机制。我们先回忆一下最初的注意力机制。
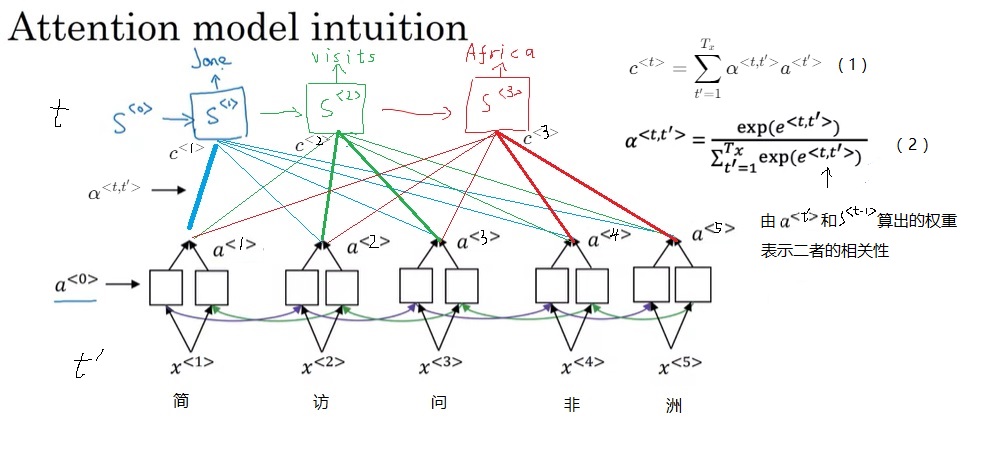
在翻译句子时,我们要算每个输出单词对每个输入单词的注意力$\alpha$,以这个注意力为权重,我们可以算所有输入状态$a$的加权平均数$c$(公式1)。这个$c$用于输出每一个单词。
注意力$\alpha$是权重$e$的归一化结果(如公式2所示,因为是求平均数,得保证权重$\alpha$的和为1),这里的$e^{< t, t’ >}$表示第$t’$个输入和第$t$个输出的相关量。由于$e^{< t, t’ >}$是用于计算$s^{< t >}$的,$s^{< t >}$还获取不了,我们只能用$s^{< t - 1 >}$来表示第$t$个输出。另外,我们用$a^{< t’ >}$表示第$t’$个输入。这样,$e^{< t, t’ >}$就应该由$s^{< t - 1 >}$和$a^{< t’ >}$决定。
Transformer用一种通用的公式表示了这种注意力的计算。
我们先不管这里的$q, K, V$是什么意思,暂且把它们当成标记。用它来表示最初的注意力机制的话,$q$就相当于输出状态$s$,$k$就相当于输入状态$a$,二者的相关关系$e$就是两个向量的内积$qk$。$v$也是输入状态$a$。
现在,我们来看看如何用这个公式计算自注意力。我们将以第三个输入$x ^ {< 3 >}$的注意力表示$A^{< 3 >}$为例。
假设我们为每个输入单词都已经维护好了3个变量$q^{< t >}, k^{< t >}, v^{< t >}$。q, k, v是英文query, key, value的缩写,这一概念来自于数据库。假如数据库里存了学生的年龄,第一条记录的key-value是("张三", 18),第二条记录的key-value是("李四", 19)。现在,有一条query,询问"张三"的年龄。我们把这一条query和所有key比对,发现第一条记录是我们需要的。因此,我们取出第一个value,即18。
每个单词的$q, k, v$也可以有类似的解释。比如第三个字“问”的query $q^{< 3 >}$是:哪个字和“问”字组词了?当然,在这个句子里,我们人类可以很轻松地知道答案,“问”和“访”组成了“访问”这个词。每个字的key可以认为是字的固有属性,比如是名词还是动词。每个字的value就可以认为是这个字的词嵌入。

让计算机去查询$q^{< 3 >}$的话,我们要用这个query去句子的其他字里查出我们要的答案。和数据库的查询一样,我们也要把这个query和所有字的key进行比对。根据注意力的公式,我们用$q^{< 3 >}$和所有$k$相乘再做softmax,得到注意力权重。再用这个权重乘上每个$v$,加起来,得到所有$v$的加权平均数。既然是查询“问”字和谁组词了,那么这个要找的字肯定是一个动词。因此,计算机会发现$q^{< 3 >}, k^{< 2 >}$比较相关,即这两个向量的内积比较大。一切顺利的话,这个$A^{< 3 >}$应该和$v^{< 2 >}$很接近,即问题“哪个字和‘问’字组词了?”的答案是第二个字“访”。
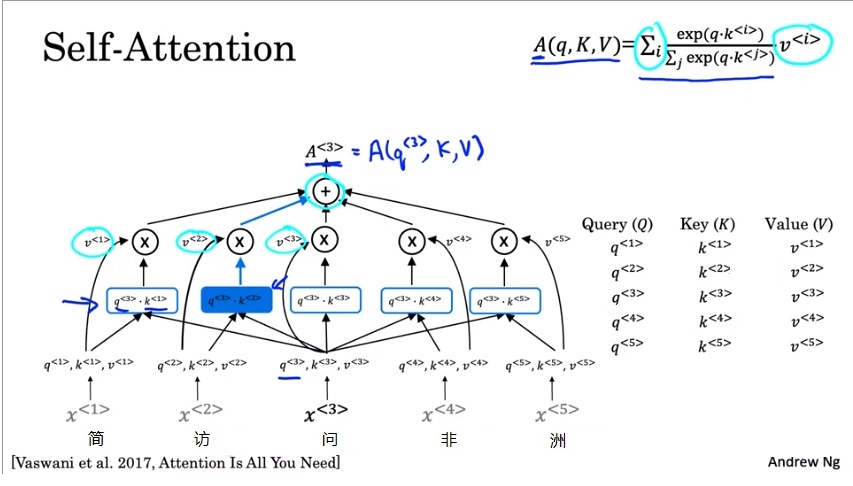
这是$A^{< 3 >}$的计算过程。准确来说,$A^{< 3 >}=A(q^{< 3 >}, K, V)$。类似地,$A^{< 1 >}-A^{< 5 >}$都是用这个公式来计算。把所有$A$的计算合起来,把$q$合起来,得到的就是下面这个公式。
其中,$d_k$是一个常量,$\sqrt{d_k}$这一项是用来防止点乘结果的数值过大的。它属于实现细节,对整个式子的意义不影响。抛去这一项的话,上式不过是之前那个公式的矩阵版本。这个公式在原论文里叫做Scaled Dot-Product Attention。
现在,我们已经理解了注意力的公式。自注意力,其实就是令$Q=K=V=E$,对$E$这个向量自己做注意力。但是,我们还有一个重要的问题没有解决:$Q, K, V$在Transformer里是怎么获得的?别急,后几节我们会把所有的概念串起来,学习Transformer的结构。现在,让我们再看一看Transformer里的另一个概念——多头注意力。
多头注意力
在CNN中,我们会在一个卷积层里使用多个卷积核,以提取出不同的特征。比如第一个卷积核提取出图像水平方向的边缘,第二个卷积核提取出图像垂直方向的边缘。类似地,一次自注意力也只能得到部分的信息,我们可以多次使用自注意力得到多个信息。
上一节的$A^{< 3 >}$是问题“哪个字和‘问’字组词了?”的答案。我们可以多问几个问题,得到有关“问”字的更多信息,比如“‘问’的主语是谁?”、“‘问’的宾语是谁?”。为了描述这些不同的问题,我们要准备一些可学习的矩阵$W^Q_i, W^K_i, W^V_i$。$Attention(W^Q_1Q, W^K_1K, W^V_1V)$就是第一组注意力结果,$Attention(W^Q_2Q, W^K_2K, W^V_2V)$就是第二组注意力结果,以此类推。这种机制叫做多头注意力。
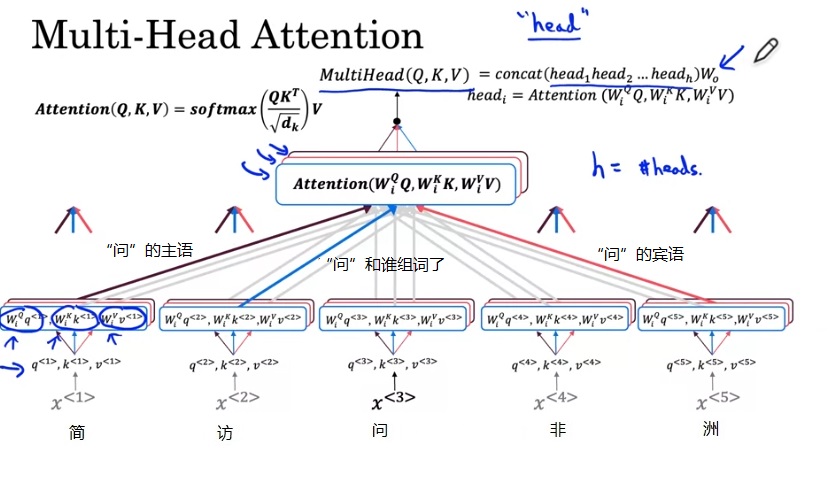
每次Attention的结果是一个向量,所有Attention的结果concat起来就是多头注意力的结果。
Transformer 网络结构
搞懂了自注意力、多头注意力这两个核心机制后,我们就能够看懂Transformer的整体结构了。
让我们看看Transformer是怎么翻译一句话的。给定一个单词序列(为了方便,我们认为输入句子已经被token化,且输入的是每个token的嵌入),我们要先用encoder提取特征,再用decoder逐个输出翻译出来的token。
在encoder中,输入会经过一个多头注意力层。这一层的Q, K, V都是输入的词嵌入。多头注意力层会接到一个前馈神经网络上,这个网络就是一个简单的全连接网络。
别忘了,多头注意力层的可学习参数是$W^Q_i, W^K_i, W^V_i$,Q, K, V可以是预训练好的词嵌入。
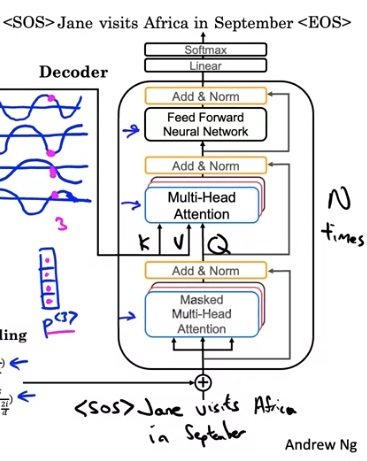
再看decoder。先看一下decoder的输出流程。第一轮,decoder的输入是<SOS>,输出Jane;第二轮,decoder的输入是<SOS> Jane,输出是visits。也就是说,decoder的输入是现有的翻译序列,输出是下一个翻译出来的单词。
在decoder中,输入同样要经过一个多头注意力层。这一层的Q, K, V全是输入的词嵌入。之后,数据会经过另一个多头注意力层,它的Q是上一层的输出,K, V来自于Encoder。为什么这一层有这样的设计呢?大家不妨翻回到前几节,回顾一下经典注意力模型中注意力是怎么计算的。其实,经典注意力模型就是以decoder的隐状态为Q,以encoder的隐状态为K, V的注意力。Transformer不过是用一套全新的公式把之前的机制搬过来了而已。做完这次多头注意力后,数据也是会经过一个全连接网络,输出结果。
encoder和decoder的大模块一共重复了N次,原论文中N=6。
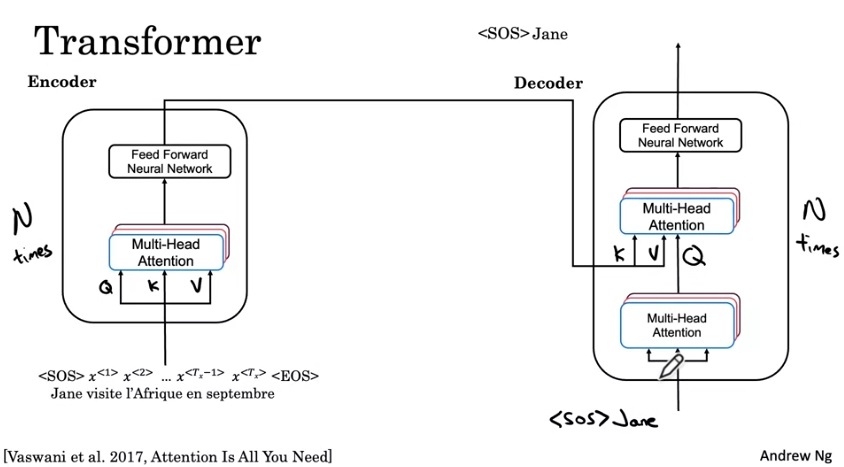
总结一下注意力在Transformer里的使用。多头注意力其实有两个版本:第一个版本是自注意力,用于进一步提取输入的特征;第二个版本和经典注意力模型一样,把输出序列和输入序列关联了起来。
刚才我们学习的是Transformer的主要结构。实际上,Transformer的结构里还有很多细节。
- Positional Encoding (位置编码): 和RNN不同,Transformer的多头注意力无法区分每一个输入的顺序。为了告诉模型每一个token的先后顺序,词嵌入在输入模型之前还要加上一个Positional Encoding。这个编码会给每一个词嵌入的每一维加上一个三角函数值。三角函数之间的差具有周期性,模型能够从这个值里认识到输入序列的顺序信息。
我会在之后的文章详细介绍位置编码,这里只需要明白位置编码的意义即可。
Add & Norm 层:参考深度CNN的结构,Transformer给每个模块的输出都做了一次归一化,并且使用了残差连接。
输出前的线性层和Softmax:为了输出一个单词,我们肯定要做一个softmax。这些层是输出单词的常规操作,和RNN结构里的相同。
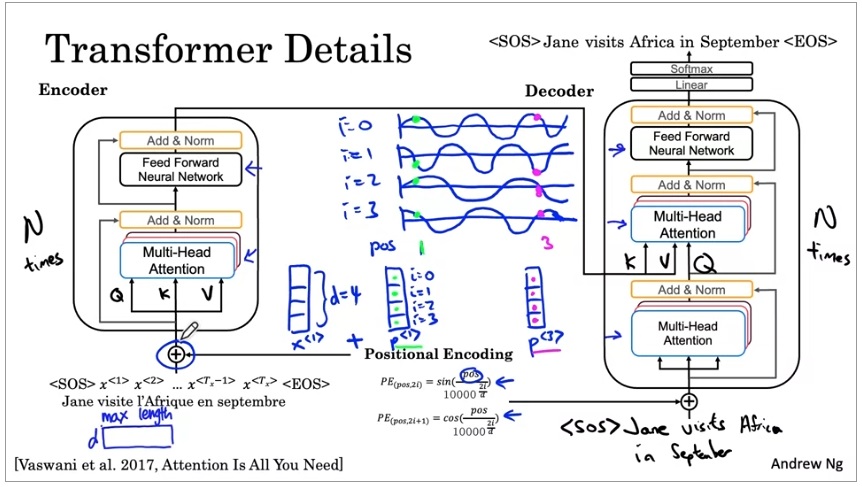
最后,在训练Tranformer时,还有一个重要的模块:Masked Multi-head Attention。刚刚我们学到,在输出翻译的句子时,我们要输出一个单词,更新一次decoder的输入;输出一个单词,更新一次decoder的输入。然而,在训练时,我们实际上已经有了正确的输出。因此,我们可以同时给decoder看前1个单词,看前2个单词……,并行地训练所有的这些情况。为了只让decoder看到前几个单词,我们可以给输入加一个mask,把后面那些不应该看到的单词“蒙上”。
Masked Multi-head Attention 其实只是一个实现上的小技巧,不能算作一个新模块。具体的实现方式其实有很多,我们只要重点理解这一设计的原因即可。总之,这种设计让Transformer能够并行地训练翻译进度不同的句子。因此,Transfomer的训练效率会比RNN快很多。
总结
这节课我们主要学习了Transformer模型。在学习时,我们主要应该关注两个核心机制:自注意力、多头注意力。搞懂Transformer的注意力机制后,我们基本就理解了Transformer的原理了。剩下的一些细节知识可以去看原论文,这些细节不干扰论文主体思想的理解。
《深度学习专项》的课就到此结束了。不过,之后我还会围绕这门课发两篇文章。第一篇文章会详细地解读“Attention Is All You Need”这篇论文,第二篇文章会详细介绍Transformer的复现过程,作为这节课的大作业。