图像生成是一个较难建模的任务。为此,我们要用GAN、VAE、Diffusion等精巧的架构来建模图像生成。可是,在NLP中,文本生成却有一种非常简单的实现方法。NLP中有一种基础的概率模型——N元语言模型。N元语言模型可以根据句子的前几个字预测出下一个字的出现概率。比如看到「我爱吃苹……」这句话的前几个字,我们不难猜出下一个字大概率是「果」字。利用N元语言模型,我们可以轻松地实现一个文本生成算法:输入空句子,采样出第一个字;输入第一个字,采样出第二个字;输入前两个字,输出第三个字……以此类推。
既然如此,我们可不可以把相同的方法搬到图像生成里呢?当然可以。虽然图像是二维的数据,不像一维的文本一样有先后顺序,但是我们可以强行给图像的每个像素规定一个顺序。比如,我们可以从左到右,从上到下地给图像标上序号。这样,从逻辑上看,图像也是一个一维数据,可以用NLP中的方法来按照序号实现图像生成了。
PixelCNN就是一个使用这种方法生成图像的模型。可为什么PixelCNN的名气没有GAN、VAE那么大?为什么PixelCNN可以用CNN而不是RNN来处理一维化图像?为什么PixelCNN是一种「自回归模型」?别急,在这篇文章中,我们将认识PixelCNN及其改进模型Gated PixelCNN和PixelCNN++,并认真学习它们的实现代码。看完文章后,这些问题都会迎刃而解。
PixelCNN
如前所述,PixelCNN借用了NLP里的方法来生成图像。模型会根据前i - 1个像素输出第i个像素的概率分布。训练时,和多分类任务一样,要根据第i个像素的真值和预测的概率分布求交叉熵损失函数;采样时,直接从预测的概率分布里采样出第i个像素。根据这些线索,我们来尝试自己「发明」一遍PixelCNN。
这种模型最朴素的实现方法,是输入一幅图像的前i - 1个像素,输出第i个像素的概率分布,即第i个像素取某种颜色的概率的数组。为了方便讨论,我们先只考虑单通道图像,每个像素的颜色取值只有256种。因此,准确来说,模型的输出是256个经过softmax的概率。这样,我们得到了一个V1.0版本的模型。
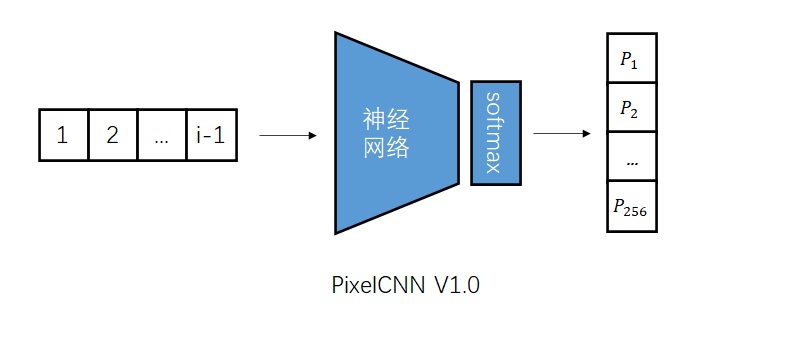
等等,模型不是叫「PixelCNN」吗?CNN跑哪去了?的确,对于图像数据,最好还是使用CNN,快捷又有效。因此,我们应该修改模型,令模型的输入为整幅图像和序号i。我们根据序号i,过滤掉i及i之后的像素,用CNN处理图像。输出部分还是保持一致。
V2.0并不是最终版本,我们可以暂时不用考虑实现细节,比如这里的「过滤」是怎么实现的。硬要做的话,这种过滤也可以暴力实现:把无效像素初始化为0,每次卷积后再把无效像素置0。
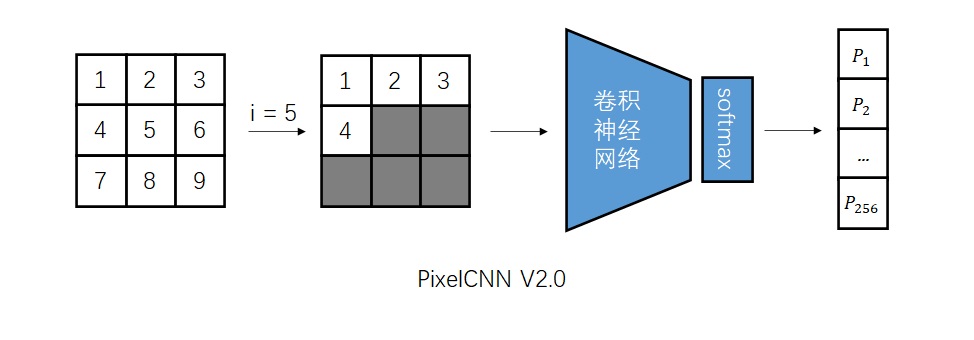
改进之后,V2.0版本的模型确实能快速计算第i个像素的概率分布了。可是,CNN是很擅长同时生成一个和原图像长宽相同的张量的,只算一个像素的概率分布还称不上高效。所以,我们可以让模型输入一幅图像,同时输出图像每一处的概率分布。
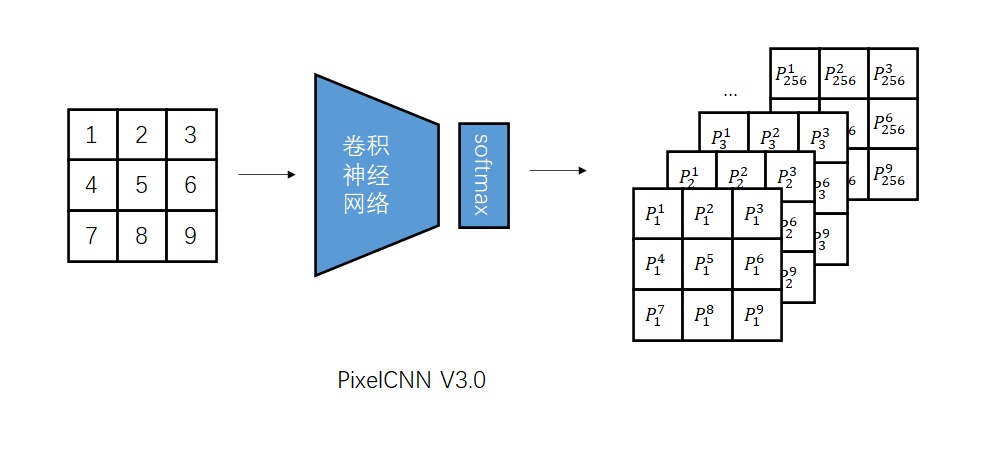
这次的改进并不能加速采样。但是,在训练时,由于整幅训练图像已知,我们可以在一次前向传播后得到图像每一处的概率分布。假设图像有N个像素,我们就等于是在并行地训练N个样本,训练速度快了N倍!
这种并行训练的想法和Transformer如出一辙。
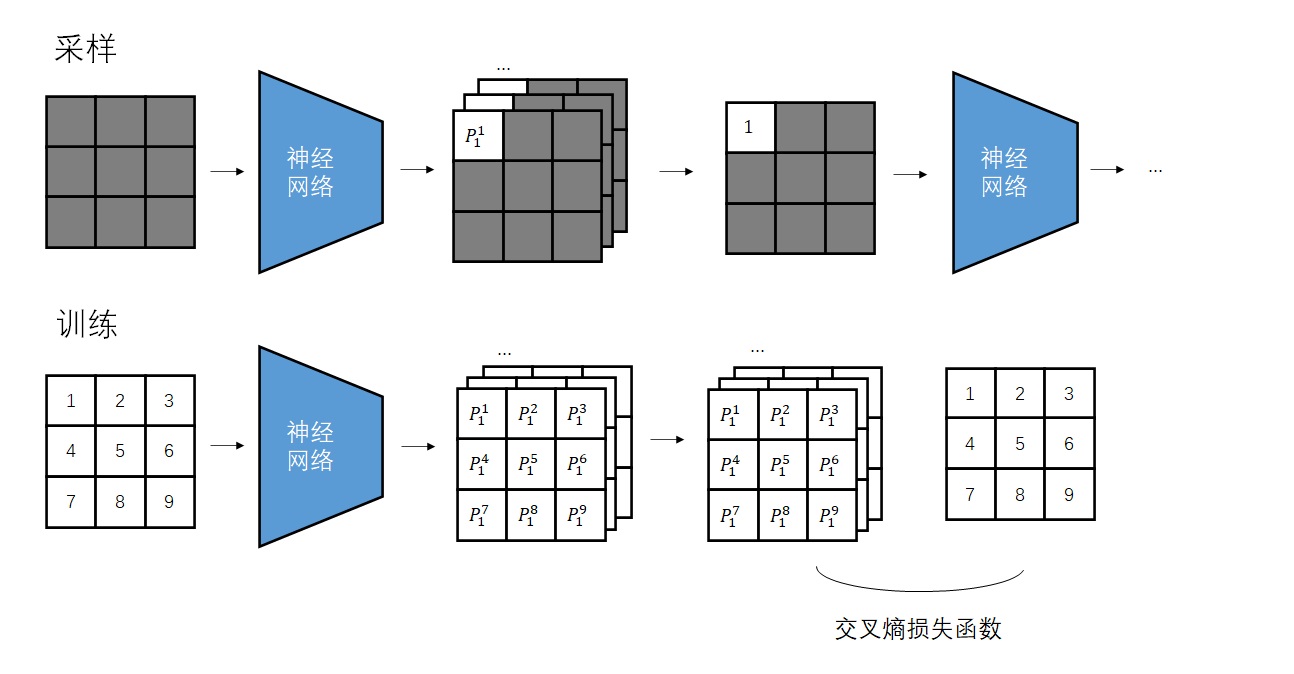
V3.0版本的PixelCNN已经和论文里的PixelCNN非常接近了,我们来探讨一下网络的实现细节。相比普通的CNN,PixelCNN有一个特别的约束:第i个像素只能看到前i-1个像素的信息,不能看到第i个像素及后续像素的信息。对于V2.0版本只要输出一个概率分布的PixelCNN,我们可以通过一些简单处理过滤掉第i个像素之后的信息。而对于并行输出所有概率分布的V3.0版本,让每个像素都忽略后续像素的信息的方法就不是那么显然了。
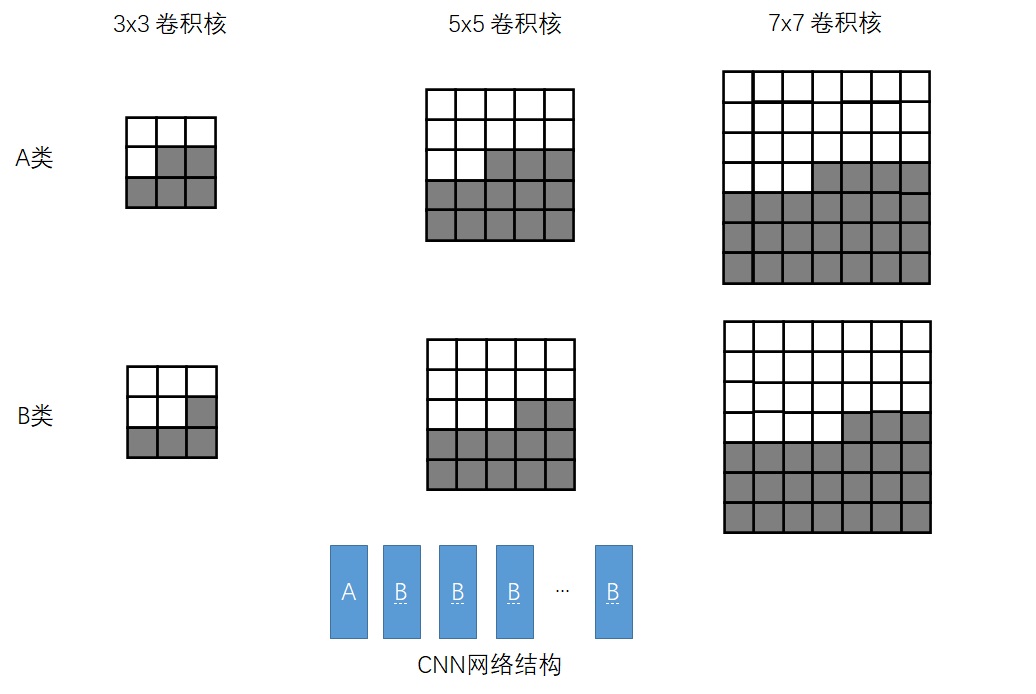
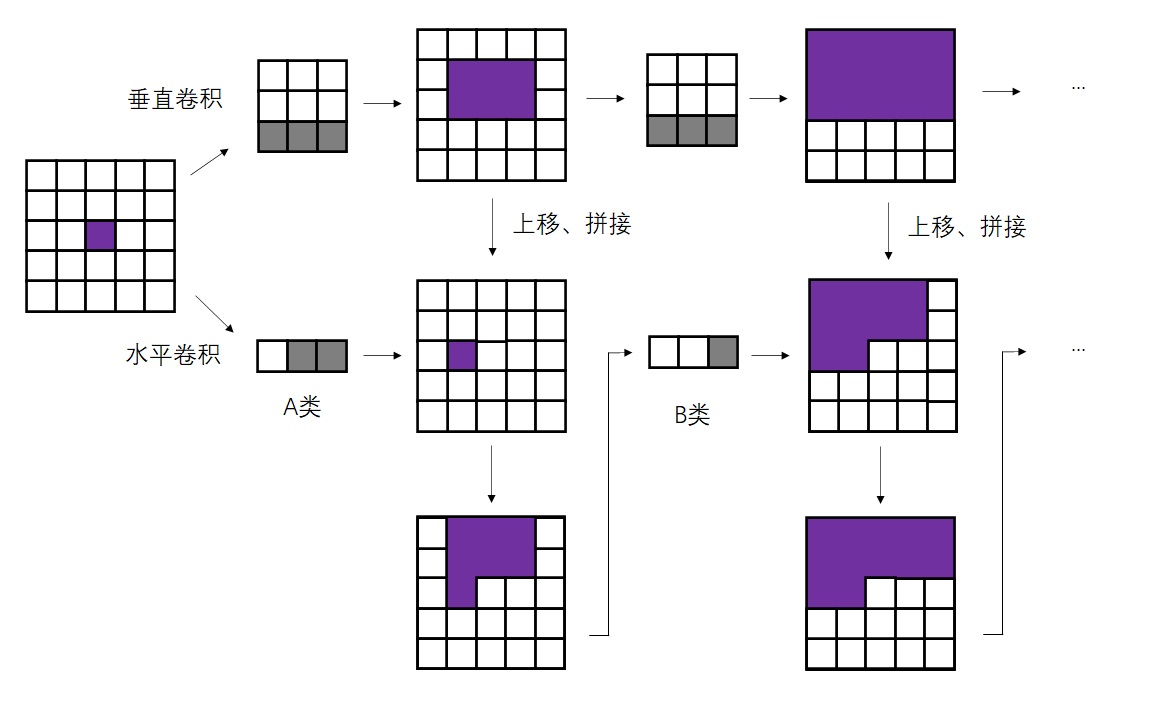
PixelCNN论文里提出了一种掩码卷积机制,这种机制可以巧妙地掩盖住每个像素右侧和下侧的信息。具体来说,PixelCNN使用了两类掩码卷积,我们把两类掩码卷积分别称为「A类」和「B类」。二者都是对卷积操作的卷积核做了掩码处理,使得卷积核的右下部分不产生贡献。A类和B类的唯一区别在于卷积核的中心像素是否产生贡献。CNN的第一个的卷积层使用A类掩码卷积,之后每一层的都使用B类掩码卷积。如下图所示。
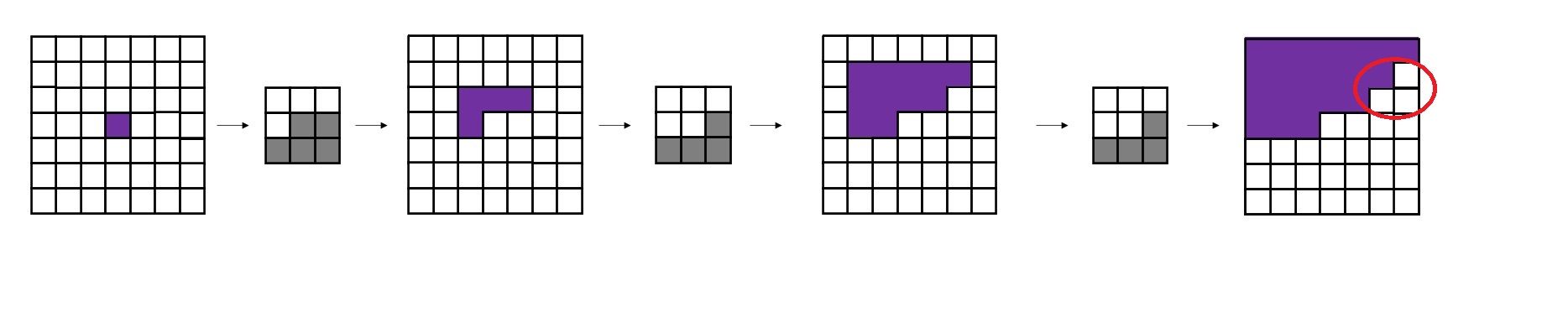
为什么要先用一次A类掩码卷积,再每次使用B类掩码卷积呢?我们不妨来做一个实验。对于一个7x7的图像,我们先用1次3x3 A类掩码卷积,再用若干次3x3 B类掩码卷积。我们观察图像中心处的像素在每次卷积后的感受野(即输入图像中哪些像素的信息能够传递到中心像素上)。
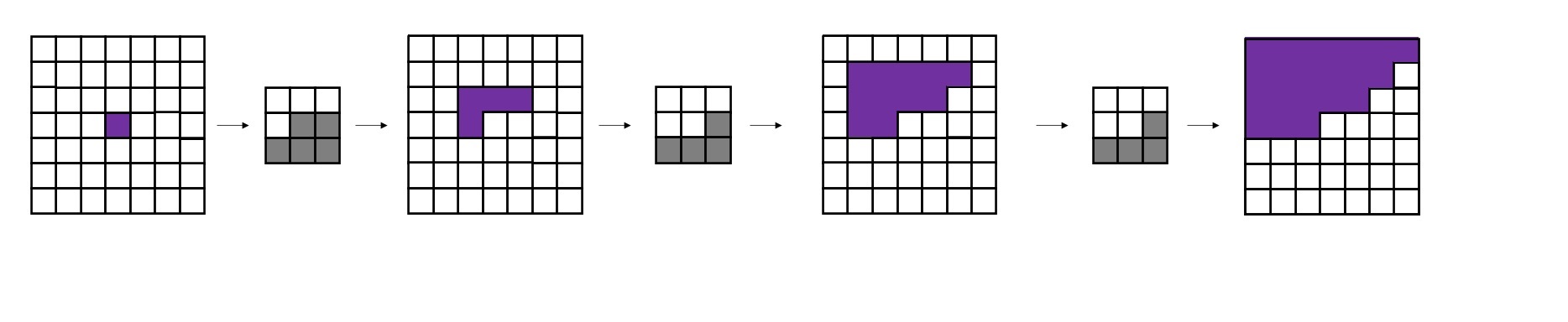
不难看出,经过了第一个A类掩码卷积后,每个像素就已经看不到自己位置上的输入信息了。再经过两次B类卷积,中心像素能够看到左上角大部分像素的信息。这满足PixelCNN的约束。
而如果一直使用A类卷积,每次卷积后中心像素都会看漏一些信息(不妨对比下面这张示意图和上面那张示意图)。多卷几层后,中心像素的值就会和输入图像毫无关系。
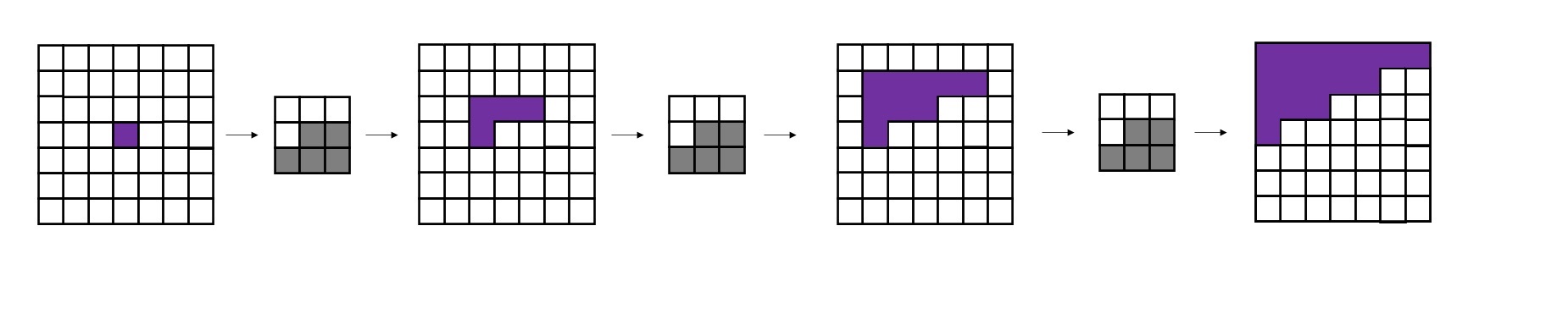
只是用B类卷积也是不行的。显然,如果第一层就使用B类卷积,中心像素还是能看到自己位置的输入信息。这打破了PixelCNN的约束。这下,我们能明白为什么只能先用一次A类卷积,再用若干次B类卷积了。
利用两类掩码卷积,PixelCNN满足了每个像素只能接受之前像素的信息这一约束。除此之外,PixelCNN就没有什么特别的地方了。我们可以用任意一种CNN架构来实现PixelCNN。PixelCNN论文使用了一种类似于ResNet的架构。其中,第一个7x7卷积层用了A类掩码卷积,之后所有3x3卷积都是B类掩码卷积。

到目前为止,我们已经成功搭建了处理单通道图像的PixelCNN。现在,我们来尝试把它推广到多通道图像上。相比于单通道图像,多通道图像只不过是一个像素由多个颜色分量组成。我们可以把一个像素的颜色分量看成是子像素。在定义约束关系时,我们规定一个子像素只由它之前的子像素决定。比如对于RGB图像,R子像素由它之前所有像素决定,G子像素由它的R子像素和之前所有像素决定,B子像素由它的R、G子像素和它之前所有像素决定。生成图像时,我们一个子像素一个子像素地生成。
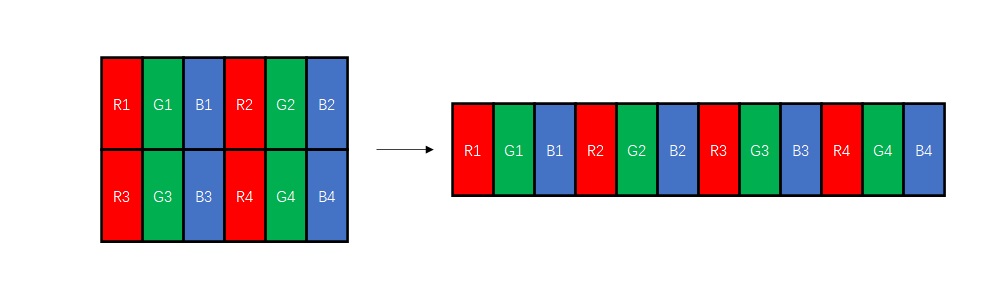
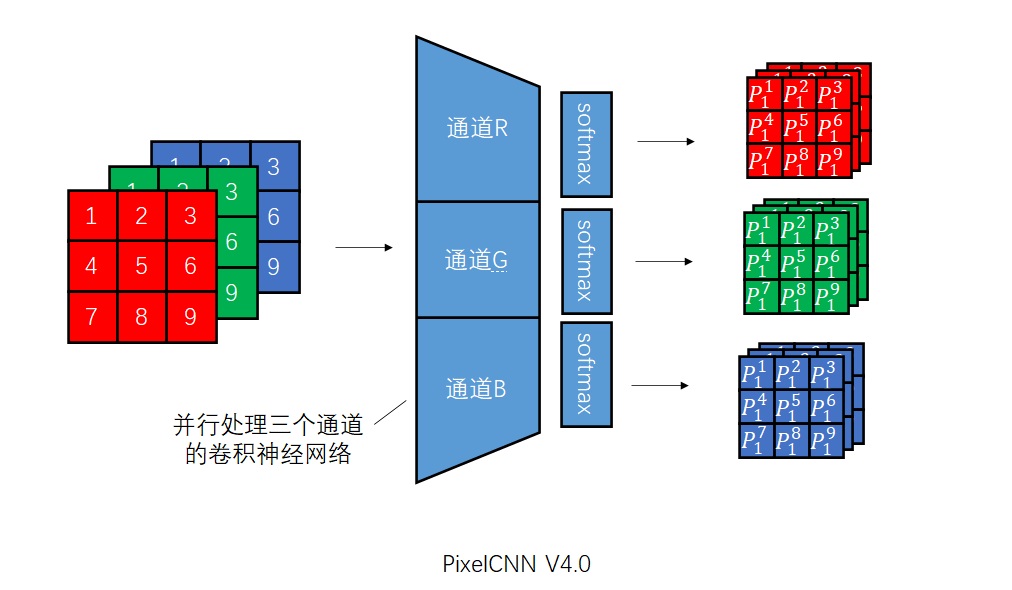
把我们的PixelCNN V3.0推广到RGB图像时,我们要做的第一件事就是修改网络的通道数量。由于现在要预测三个颜色通道,网络的输出应该是一个[256x3, H, W]形状的张量,即每个像素输出三个概率分布,分别表示R、G、B取某种颜色的概率。同时,本质上来讲,网络是在并行地为每个像素计算3组结果。因此,为了达到同样的性能,网络所有的特征图的通道数也要乘3。
这里说网络中间的通道数要乘3只是一种方便理解的说法。实际上,中间的通道数可以随意设置,是不是3的倍数都无所谓,只是所有通道在逻辑上被分成了3组。我们稍后会利用到「中间结果的通道数应该能被拆成3组」这一性质。
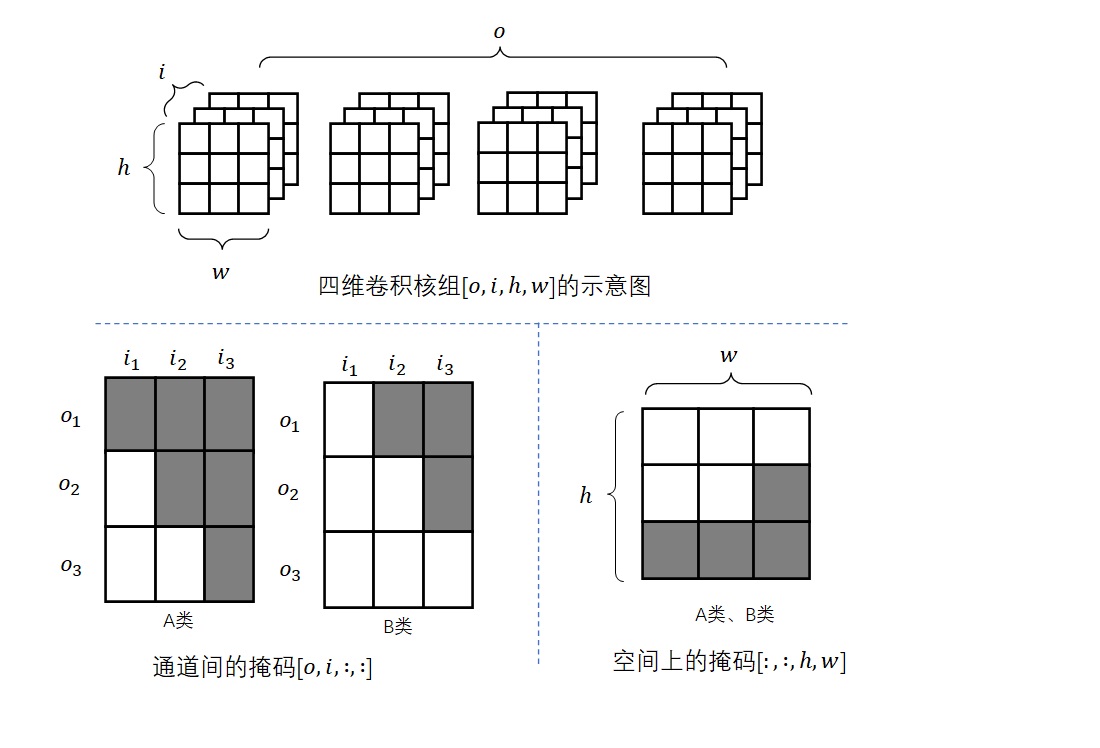
图像变为多通道后,A类卷积和B类卷积的定义也需要做出一些调整。我们不仅要考虑像素在空间上的约束,还要考虑一个像素内子像素间的约束。为此,我们要用不同的策略实现约束。为了方便描述,我们设卷积核组的形状为[o, i, h, w],其中o为输出通道数,i为输入通道数,h, w为卷积核的高和宽。
对于通道间的约束,我们要在
o, i两个维度上设置掩码。设输出通道可以被拆成三组o1, o2, o3,输入通道可以被拆成三组i1, i2, i3,即o1 = 0:o/3, o2 = o/3:o*2/3, o3 = o*2/3:o,i1 = 0:i/3, i2 = i/3:i*2/3, i3 = i*2/3:i。序号1, 2, 3分别表示这组通道是在维护R, G, B的计算。我们对输入通道组和输出通道组之间进行约束。对于A类卷积,我们令o1看不到i1, i2, i3,o2看不到i2, i3,o3看不到i3;对于B类卷积,我们取消每个通道看不到自己的限制,即在A类卷积的基础上令o1看到i1,o2看到i2,o3看到i3。对于空间上的约束,我们还是和之前一样,在
h, w两个维度上设置掩码。由于「是否看到自己」的处理已经在o, i两个维度里做好了,我们直接在空间上用原来的B类卷积就行。
就这样,修改了通道数,修改了卷积核的掩码后,我们成功实现了论文里的PixelCNN。让我们把这个过程总结一下。PixelCNN的核心思想是给图像的子像素定义一个先后顺序,之后让每个子像素的颜色取值分布由之前所有的子像素决定。实现PixelCNN时,可以用任意一种CNN架构,并注意两点:
- 网络的输出是一个经softmax的概率分布。
- 网络的所有卷积层要替换成带掩码的卷积层,第一个卷积层用A类掩码,后面的用B类掩码。
学完了PixelCNN,我们在闲暇之余来谈一谈PixelCNN和其他生成网络的对比情况。精通数学的人,会把图像生成问题看成学习一个图像的分布。每次生成一张图片,就是在图像分布里随机采样一个张量。学习一个分布,最便捷的方法是定义一个带参数$\theta$的概率模型$P_\theta$,最大化来自数据集的图像$\mathbf{x}$的概率$P_\theta(\mathbf{x})$。
可问题来了:一个又方便采样,又能计算概率的模型不好设计。VAE和Diffusion建模了把一个来自正态分布的向量$\mathbf{z}$变化成$\mathbf{x}$的过程,并使用了统计学里的变分推理,求出了$P_\theta(\mathbf{x})$的一个下界,再设法优化这个下界。GAN干脆放弃了概率模型,直接拿一个神经网络来评价生成的图像好不好。
PixelCNN则正面挑战了建立概率模型这一任务。它把$P_\theta(\mathbf{x})$定义为每个子像素出现概率的乘积,而每个子像素的概率仅由它之前的子像素决定。
由于我们可以轻松地用神经网络建模每个子像素的概率分布并完成采样,PixelCNN的采样也是很方便的。我们可以说PixelCNN是一个既方便采样,又能快速地求出图像概率的模型。
相比与其他生成模型,PixelCNN直接对$P_\theta(\mathbf{x})$建模,在和概率相关的指标上表现优秀。很可惜,能最大化数据集的图像的出现概率,并不代表图像的生成质量就很优秀。因此,一直以来,以PixelCNN为代表的对概率直接建模的生成模型没有受到过多的关注。可能只有少数必须要计算图像概率分布的任务才会用到PixelCNN。
除了能直接计算图像的概率外,PixelCNN还有一大特点:PixelCNN能输出离散的颜色值。VAE和GAN这些模型都是把图像的颜色看成一个连续的浮点数,模型的输入和输出的取值范围都位于-1到1之间(有些模型是0到1之间)。而PixelCNN则输出的是像素取某个颜色的概率分布,它能描述的颜色是有限而确定的。假如我们是在生成8位单通道图像,那网络就只输出256个离散的概率分布。能生成离散输出这一特性启发了后续很多生成模型。另外,这一特性也允许我们指定颜色的亮度级别。比如对于黑白手写数字数据集MNIST,我们完全可以用黑、白两种颜色来描述图像,而不是非得用256个灰度级来描述图像。减少亮度级别后,网络的训练速度能快上很多。
在后续的文献中,PixelCNN被归类为了自回归生成模型。这是因为PixelCNN在生成图像时,要先输入空图像,得到第一个像素;把第一个像素填入空图像,输入进模型,得到第二个像素……。也就是说,一个图像被不断扔进模型,不断把上一时刻的输出做为输入。这种用自己之前时刻的状态预测下一个状态的模型,在统计学里被称为自回归模型。如果你在其他图像生成文献中见到了「自回归模型」这个词,它大概率指的就是PixelCNN这种每次生成一个像素,该像素由之前所有像素决定的生成模型。
Gated PixelCNN
首篇提出PixelCNN的论文叫做Pixel Recurrent Neural Networks。没错!这篇文章的作者提出了一种叫做PixelRNN的架构,PixelCNN只是PixelRNN的一个变种。可能作者一开始也没指望PixelCNN有多强。后来,人们发现PixelCNN的想法还挺有趣的,但是原始的PixelCNN设计得太烂了,于是开始着手改进原始的PixelCNN。
PixelCNN的掩码卷积其实有一个重大漏洞:像素存在视野盲区。如下图所示,在我们刚刚的实验中,中心像素看不到右上角三个本应该能看到的像素。哪怕你对用B类卷积多卷几次,右上角的视野盲区都不会消失。
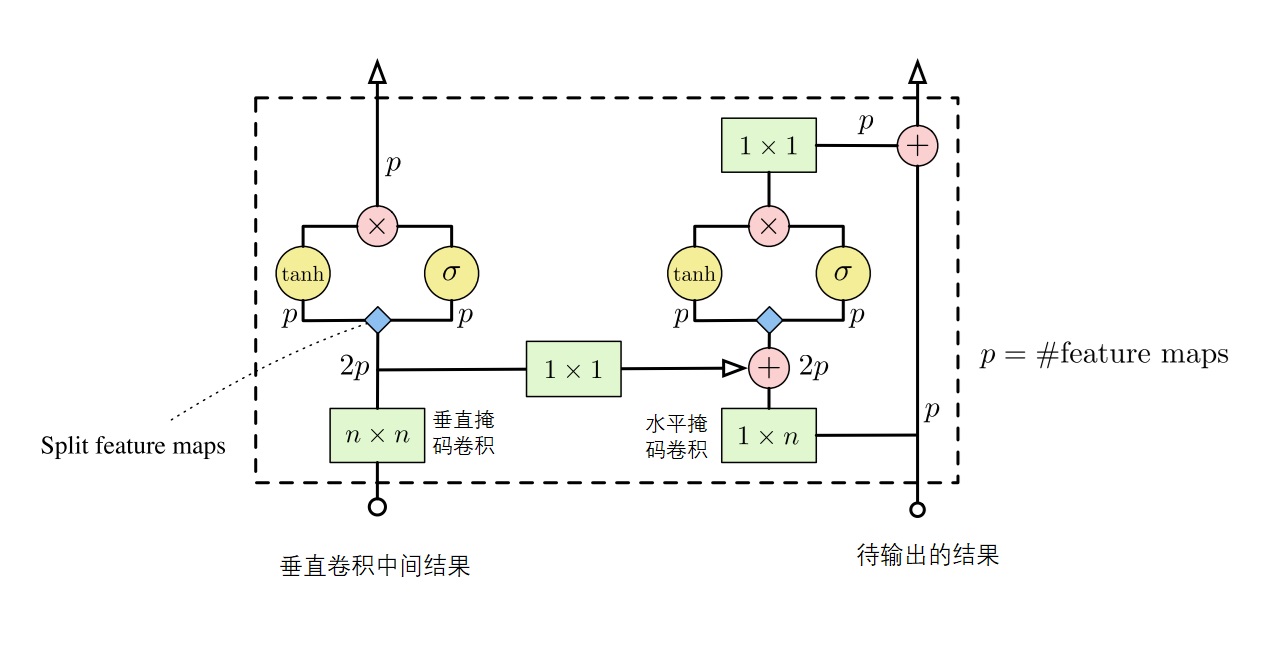
为此,PixelCNN论文的作者们又打了一些补丁,发表了Conditional Image Generation with PixelCNN Decoders这篇论文。这篇论文提出了一种叫做Gated PixelCNN的改进架构。Gated PixelCNN使用了一种更好的掩码卷积机制,消除了原PixelCNN里的视野盲区。如下图所示,Gated PixelCNN使用了两种卷积——垂直卷积和水平卷积——来分别维护一个像素上侧的信息和左侧的信息。垂直卷积的结果只是一些临时量,而水平卷积的结果最终会被网络输出。可以看出,使用这种新的掩码卷积机制后,每个像素能正确地收到之前所有像素的信息了。
除此之外,Gated PixelCNN还把网络中的激活函数从ReLU换成了LSTM的门结构。Gated PixelCNN用下图的模块代替了原PixelCNN的普通残差模块。
模块的输入输出都是两个量,左边的量是垂直卷积中间结果,右边的量是最后用来计算输出的量。垂直卷积的结果会经过偏移和一个1x1卷积,再加到水平卷积的结果上。两条计算路线在输出前都会经过门激活单元。所谓门激活单元,就是输入两个形状相同的量,一个做tanh,一个做sigmoid,两个结果相乘再输出。此外,模块右侧那部分还有一个残差连接。
除了上面的两项改动,Gated PixelCNN还做出了其他的一些改动。比如,Gated PixelCNN支持带约束的图像生成,比如根据文字生成图片、根据类别生成图片。用于约束生成的向量$\mathbf{h}$会被输入进网络每一层的激活函数中。当然,这些改动不是为了提升原PixelCNN的性能。
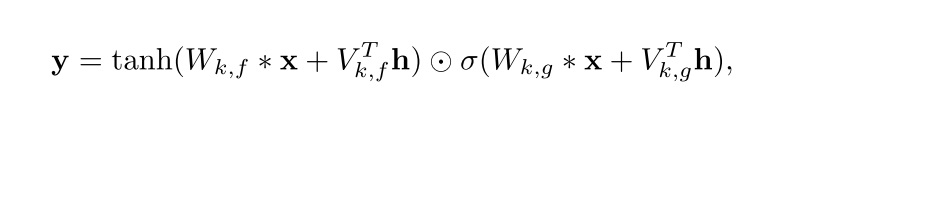
PixelCNN++
之后,VAE的作者也下场了,提出了一种改进版的PixelCNN,叫做PixelCNN++。这篇论文没有多余的废话,在摘要中就简明地指出了PixelCNN++的几项改动:
- 使用logistic分布代替256路softmax
- 简化RGB子像素之间的约束关系
- 使用U-Net架构
- 使用dropout正则化
这几项改动中,第一项改动是最具启发性的,这一技巧可以拓展到其他任务上。让我们主要学习一下第一项改动,并稍微浏览一下其他几项改动。
离散logistic混合似然
原PixelCNN使用256路softmax建模一个像素的颜色概率分布。这么做确实能让模型更加灵活,但有若干缺点。首先,计算这么多的概率值会占很多内存;其次,由于每次训练只有一个位置的标签为1,其他255个位置的标签都是0,模型可学习参数的梯度会很稀疏;最后,在这种概率分布方式下,256种颜色是分开考虑的,这导致模型并不知道相邻的颜色比较相似(比如颜色值128和127、129比较相似)这一事实。总之,用softmax独立地表示各种颜色有着诸多的不足。
作者把颜色的概率分布建模成了连续分布,一下子克服掉了上述所有难题。让我们来仔细看一下新概率分布的定义方法。
首先,新概率分布使用到的连续分布叫做logistic分布。它有两个参数:均值$\mu$和方差$s^2$。它的概率密度函数为:
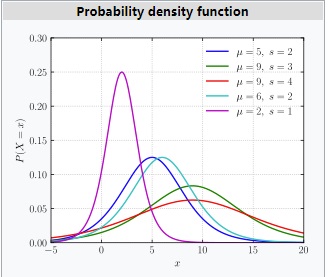
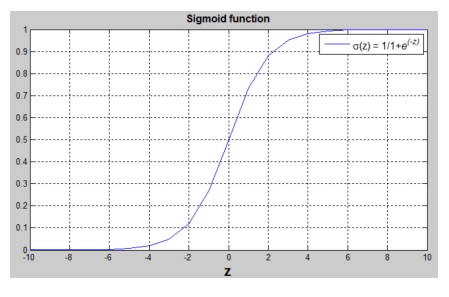
logistic分布的概率密度函数看起来比较复杂。但是,如果对这个函数积分,得到的累计分布函数就是logistic函数。如果令均值为0,方差为1,则logistic函数就是我们熟悉的sigmoid函数了。
接着,每个分布可能是$K$个参数不同的logistic分布中的某一个,选择某个logistic分布的概率由$\pi_i$表示。比如$K=2$,$\pi_1 = 0.3, \pi_2=0.7$,就说明有两个可选的logisti分布,每个分布有30%的概率会使用1号logistic分布,有70%的概率会使用2号logistic分布。 这里的$\pi_i$和原来256路softmax的输出的意义一样,都是选择某个东西的概率。当然,$K$会比256要小很多,不然这种改进就起不到减小计算量的作用了。设一个输出颜色为$v$,它的数学表达式为:
可logsitc分布是一个连续分布,而我们想得到256个颜色中某个颜色的概率,即得到一个离散的分布。因此,在最后一步,我们要从上面这个连续分布里得到一个离散的分布。我们先不管$K$和$\pi_i$,只考虑有一个logistic分布的情况。根据统计学知识可知,要从连续分布里得到一个离散分布,可以把定义域拆成若干个区间,对每个区间的概率求积分。在我们的例子里,我们可以把实数集拆成256个区间,令$(-\infty, 0.5]$为第1个区间,$(0.5, 1.5]$为第2个区间,……,$(253.5, 254.5]$为第255个区间, $(254.5, +\infty)$为第256个区间。
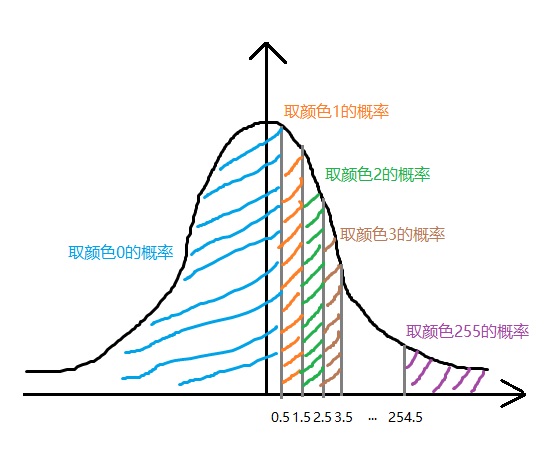
对概率密度函数求积分,就是在累积分布函数上做差。因此,对于某个离散颜色值$x\in[0, 255], x\in \mathbb{N}$,已知一个logistic分布$logistic(\mu, s)$,则这个颜色值的出现概率是:
其中,$\sigma()$是sigmoid函数。$\sigma((x-\mu)/s)$就是分布的累积分布函数。
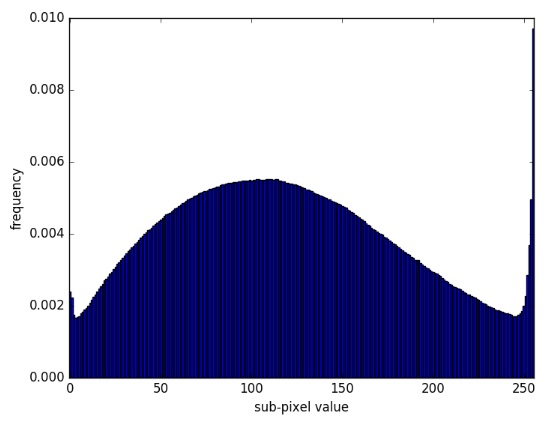
可以看出,使用这种区间划分方法,位于0处和位于255处的颜色的概率相对会高一点。这一特点符合作者统计出的CIFAR-10里的颜色分布规律。
当有$K$个logistic分布时,只要把各个分布的概率做一个加权和就行(公式省略掉了$x$位于边界处的情况)。
至此,我们已经知道了怎么用一个「离散logistic混合似然」来建模颜色的概率分布了。这个更高级的颜色分布以logistic分布为基础,以比例(概率)$\pi_i$混合了$K$个logstic分布,并用巧妙的方法把连续分布转换成了离散分布。
简化RGB子像素之间的约束关系
在原PixelCNN中,生成一个像素的RGB三个子像素时,为了保证子像素之间的约束,我们要把模型中所有特征图的通道分成三组,并用掩码来维持三组通道间的约束。这样做太麻烦了。因此,PixelCNN++对约束做了一定的简化:根据之前所有像素,网络一次性输出三个子像素的均值和方差,而不用掩码区分三个子像素的信息。当然,只是这样做是不够好的——G子像素缺少了R子像素的信息,B子像素缺少了R、G子像素的信息。为了弥补信息的缺失,PixelCNN会为每个像素额外输出三个参数$\alpha, \beta, \gamma$,$\alpha$描述R对G子像素的约束关系,$\beta$描述R对B的约束关系,$\gamma$描述G对B的约束关系。
让我们来用公式更清晰地描述这一过程。对于某个像素的第$i$个logistic分布,网络会输出10个参数:$\pi, \mu_r, \mu_g, \mu_b, s_r, s_g, s_b, \alpha, \beta, \gamma$。$\pi$就是之前见过的选择第$i$个分布的概率,$\mu_r, \mu_g, \mu_b$是网络输出的三个子像素的均值,$s_r, s_g, s_b$是网络输出的三个子像素的标准差,$\alpha, \beta, \gamma$描述子像素之间的约束。
由于缺少了其他子像素的信息,网络直接输出的$\mu_g, \mu_b$是不准的。我们假设子像素之间仅存在简单的线性关系。这样,可以用下面的公式更新$\mu_g$和$\mu_b$:
更新后的$\mu_g$和$\mu_b$才是训练和采样时使用的最终均值。
你会不会疑惑上面那个公式里的$r$和$g$是哪里来的?别忘了,虽然子像素之间的约束被简化了,但是三个子像素还是按先后顺序生成的。在训练时,我们是知道所有子像素的真值的,公式里的$r$和$g$来自真值;而在采样时,我们会先用神经网络生成三个子像素的均值和方差,再采样$r$,把采样的$r$套入公式采样出$g$,最后把采样的$r,g$套入公式采样出$b$.
使用U-Net架构
PixelCNN++的网络架构是一个三级U-Net,即网络先下采样两次再上采样两次,同级编码器(下采样部分)的输出会连到解码器(上采样部分)的输入上。这个U-Net和其他任务中的U-Net没什么太大的区别。
使用Dropout
过拟合会导致生成图像的观感不好。为此,PixelCNN++采用了Dropout正则化方法,在每个子模块的第一个卷积后面加了一个Dropout。
除了这些改动外,PixelCNN++还使用了类似于Gated PixelCNN里垂直卷积和水平卷积的设计,以消除原PixelCNN里的视野盲区。当然,这点不算做本文的主要贡献。
总结
PixelCNN把文本生成的想法套入了图像生成中,令子像素的生成有一个先后顺序。为了在维护先后顺序的同时执行并行训练,PixelCNN使用了掩码卷积。这种并行训练与掩码的设计和Transformer一模一样。如果你理解了Transformer,就能一眼看懂PixelCNN的原理。
相比与其他的图像生成模型,以PixelCNN为代表的自回归模型在生成效果上并不优秀。但是,PixelCNN有两个特点:能准确计算某图像在模型里的出现概率(准确来说在统计学里叫做「似然」)、能生成离散的颜色输出。这些特性为后续诸多工作铺平了道路。
原版的PixelCNN有很多缺陷,后续很多工作对其进行了改进。Gated PixelCNN主要消除了原PixelCNN里的视野盲区,而PixelCNN++提出了一种泛用性很强的用连续分布建模离散颜色值的方法,并用简单的线性约束代替了原先较为复杂的用神经网络表示的子像素之间的约束。
PixelCNN相关的知识难度不高,了解本文介绍的内容足矣。PixelCNN也不是很常见的架构,复现代码的优先级不高,有时间的话阅读一下本文附录中的代码即可。另外,PixelCNN的代码实现里有一个重要的知识点。这个知识点几乎不会在论文和网上的文章里看到,但它对实现是否成功有着重要的影响。如果你对新知识感兴趣,推荐去读一下附录中对其的介绍。
参考资料与学习提示
Pixel Recurrent Neural Networks 是提出了PixelCNN的文章。当然,这篇文章主要是在讲PixelRNN,只想学PixelCNN的话通读这篇文章的价值不大。
Conditional Image Generation with PixelCNN Decoders 是提出Gated PixelCNN的文章。可以主要阅读消除视野盲区和门激活函数的部分。
PixelCNN++: Improving the PixelCNN with Discretized Logistic Mixture Likelihood and Other Modifications 是提出PixelCNN++的文章。整篇文章非常简练,可以整体阅读一遍,并且着重阅读离散logistic混合似然的部分。不过,这篇文章有很多地方写得过于简单了,连公式里的字母都不好好交代清楚,我还是看代码才看懂他们想讲什么。建议搭配本文的讲解阅读。
这几篇文章都使用了NLL(负对数似然)这个评价指标。实际上,这个指标就是对所有数据在模型里的平均出现概率取了个对数,加了个负号。对于PixelCNN,其NLL就是交叉熵损失函数。其他生成模型不是直接对数据的概率分布建模,它们的NLL不好求得。比如diffusion模型只能计算NLL的一个上界。
网上还有几份PyTorch代码复现供参考:
PixelCNN:https://github.com/singh-hrituraj/PixelCNN-Pytorch
Gated PixelCNN:https://github.com/anordertoreclaim/PixelCNN
附录:代码学习
在附录中,我将给出PixelCNN和Gated PixelCNN的PyTorch实现,并讲解PixelCNN++开源代码的实现细节。
PixelCNN 与 GatedPixelCNN
为了简化实现,我们来实现MNIST上的PixelCNN和Gated PixelCNN。MNIST是单通道数据集,我们不用考虑颜色通道之间复杂的约束。代码仓库:https://github.com/SingleZombie/DL-Demos/tree/master/dldemos/pixelcnn。
我们先准备好数据集。PyTorch的torchvision提供了获取了MNIST的接口,我们只需要用下面的函数就可以生成MNIST的Dataset实例。参数中,root为数据集的下载路径,download为是否自动下载数据集。令download=True的话,第一次调用该函数时会自动下载数据集,而第二次之后就不用下载了,函数会读取存储在root里的数据。
1 | mnist = torchvision.datasets.MNIST(root='./data/mnist', download=True) |
我们可以用下面的代码来下载MNIST并输出该数据集的一些信息:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23import torchvision
from torchvision.transforms import ToTensor
def download_dataset():
mnist = torchvision.datasets.MNIST(root='./data/mnist', download=True)
print('length of MNIST', len(mnist))
id = 4
img, label = mnist[id]
print(img)
print(label)
# On computer with monitor
# img.show()
img.save('work_dirs/tmp.jpg')
tensor = ToTensor()(img)
print(tensor.shape)
print(tensor.max())
print(tensor.min())
if __name__ == '__main__':
import os
os.makedirs('work_dirs', exist_ok=True)
download_dataset()
执行这段代码,输出大致为:
1 | length of MNIST 60000 |
第一行输出表明,MNIST数据集里有60000张图片。而从第二行和第三行输出中,我们发现每一项数据由图片和标签组成,图片是大小为28x28的PIL格式的图片,标签表明该图片是哪个数字。我们可以用torchvision里的ToTensor()把PIL图片转成PyTorch张量,进一步查看图片的信息。最后三行输出表明,每一张图片都是单通道图片(灰度图),颜色值的取值范围是0~1。
我们可以查看一下每张图片的样子。如果你是在用带显示器的电脑,可以去掉img.show那一行的注释,直接查看图片;如果你是在用服务器,可以去img.save的路径里查看图片。该图片的应该长这个样子:

我们可以用下面的代码预处理数据并创建DataLoader。PixelCNN对输入图片的颜色取值没有特别的要求,我们可以不对图片的颜色取值做处理,保持取值范围在0~1即可。
1 | from torch.utils.data import DataLoader |
准备好数据后,我们来实现PixelCNN和Gated PixelCNN。先从PixelCNN开始。
实现PixelCNN,最重要的是实现掩码卷积。其代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23import torch
import torch.nn as nn
import torch.nn.functional as F
class MaskConv2d(nn.Module):
def __init__(self, conv_type, *args, **kwags):
super().__init__()
assert conv_type in ('A', 'B')
self.conv = nn.Conv2d(*args, **kwags)
H, W = self.conv.weight.shape[-2:]
mask = torch.zeros((H, W), dtype=torch.float32)
mask[0:H // 2] = 1
mask[H // 2, 0:W // 2] = 1
if conv_type == 'B':
mask[H // 2, W // 2] = 1
mask = mask.reshape((1, 1, H, W))
self.register_buffer('mask', mask, False)
def forward(self, x):
self.conv.weight.data *= self.mask
conv_res = self.conv(x)
return conv_res
掩码卷积的实现思路就是在卷积核组上设置一个mask。在前向传播的时候,先让卷积核组乘mask,再做普通的卷积。因此,掩码卷积类里需要实现一个普通卷积的操作。实现普通卷积,既可以写成继承nn.Conv2d,也可以把nn.Conv2d的实例当成成员变量。这份代码使用了后一种实现方法。在__init__里把其他参数原封不动地传给self.conv,并在forward中直接调用self.conv(x)。
1 | class MaskConv2d(nn.Module): |
准备好卷积对象后,我们来维护掩码张量。由于输入输出都是单通道图像,按照正文中关于PixelCNN的描述,我们只需要在卷积核的h, w两个维度设置掩码。我们可以用下面的代码生成一个形状为(H, W)的掩码并根据卷积类型对掩码赋值:
1 | def __init__(self, conv_type, *args, **kwags): |
然后,为了保证掩码能正确广播到4维的卷积核组上,我们做一个reshape操作。1
mask = mask.reshape((1, 1, H, W))
在初始化函数的最后,我们把用PyTorch API把mask注册成名为'mask'的成员变量。register_buffer可以把一个变量加入成员变量的同时,记录到PyTorch的Module中。这样做的好处时,每当执行model.to(device)把模型中所有参数转到某个设备上时,被注册的变量会跟着转。否则的话我们要手动model.mask = model.mask.to(device)转设备。register_buffer的第三个参数表示被注册的变量是否要加入state_dict中以保存下来。由于这里mask每次都会自动生成,我们不需要把它存下来,可以令第三个参数为False。
1 | self.register_buffer('mask', mask, False) |
在前向传播时,只需要先让卷积核乘掩码,再做普通的卷积。
1 | def forward(self, x): |
有了最核心的掩码卷积,我们来根据论文中的模型结构图把模型搭起来。
我们先照着论文实现残差块ResidualBlock。原论文并没有使用归一化,但我发现使用归一化后效果会好一点,于是往模块里加了BatchNorm。
1 | class ResidualBlock(nn.Module): |
有了所有这些基础模块后,我们就可以拼出最终的PixelCNN了。注意,我们可以自己决定颜色有几个亮度级别。要修改亮度级别的数量,只需要修改softmax输出的通道数。
1 | class PixelCNN(nn.Module): |
PixelCNN实现完毕,我们来按照同样的流程实现Gated PixelCNN。首先,我们要实现其中的垂直掩码卷积和水平掩码卷积,二者的实现和PixelCNN里的掩码卷积差不多,只是mask的内容不太一样。
1 | class VerticalMaskConv2d(nn.Module): |
水平卷积其实只要用一个1x3的卷积就可以实现了。但出于偷懒(也为了方便理解),我还是在3x3卷积的基础上添加的mask。
之后我们来用两种卷积搭建论文中的Gated Block。
Gated Block搭起来稍有难度。如上面的结构图所示,我们主要要维护两个v, h两个变量,分别表示垂直卷积部分的结果和水平卷积部分的结果。v会经过一个垂直掩码卷积和一个门激活函数。h会经过一个类似于残差块的结构,只不过第一个卷积是水平掩码卷积、激活函数是门激活函数、进入激活函数之前会和垂直卷积的信息融合。
1 | class GatedBlock(nn.Module): |
代码中的其他地方都比较常规,唯一要注意的是v和h的合成部分。这一部分的实现初看下来比较难懂。为了把v的信息贴到h上,我们并不是像前面的示意图所写的令v上移一个单位,而是用下面的代码令v下移了一个单位(下移即去掉最下面一行,往最上面一行填0)。1
2v_to_h = v[:, :, 0:-1]
v_to_h = F.pad(v_to_h, (0, 0, 1, 0))
为什么实际上是要对特征图v下移一个单位呢?实际上,在拼接v和h时,我们是想做下面这个计算:1
2
3for i in range(H):
for j in range(W):
h[:, :, i, j] += v[:, :, i - 1, j]
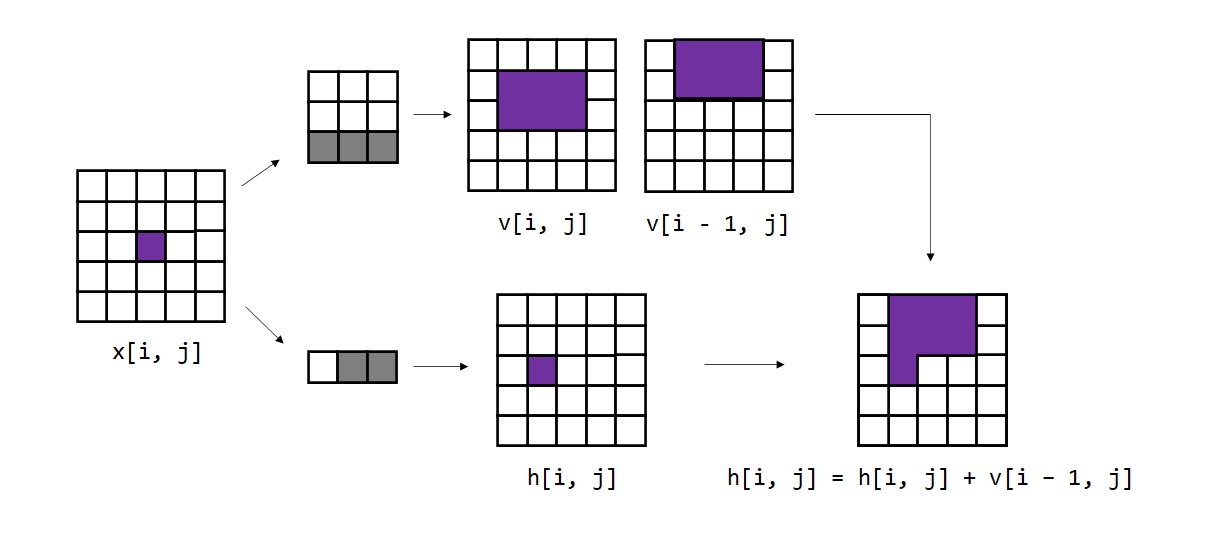
但是,写成循环就太慢了,我们最好是能做向量化计算。注意到,v和i相加的位置只差了一个单位。为了把相加的位置对齐,我们要把v往下移一个单位,把原来在i-1处的信息移到i上。这样,移动过后的v_to_h就能和h直接用向量加法并行地加到一起了。
除了v和h的合成有点麻烦外,GatedBlock还有一个细节值得注意。h的计算通路中有一个残差连接,但是,在网络的第一层,每个数据是不能看到自己的。所以,当GatedBlock发现卷积类型为A类时,不应该对h做残差连接。
最后,我们来用GatedBlock搭出Gated PixelCNN。Gated PixelCNN和原版PixelCNN的结构非常相似,只是把ResidualBlock替换成了GatedBlock而已。
1 | class GatedPixelCNN(nn.Module): |
准备好了模型代码,我们可以编写训练和采样的脚本了。我们先用超参数初始化好两个模型。根据论文的描述,PixelCNN有15个残差块,中间特征的通道数为128,输出前线性层的通道数为32。
1 | from dldemos.pixelcnn.dataset import get_dataloader, get_img_shape |
之后是训练部分。
1 | def train(model, device, model_path): |
这部分代码十分常规,和普通的多分类任务十分类似。代码中值得一看的是下面几行:
1 | y = torch.ceil(x * (color_level - 1)).long() |
这几行代码根据输入x得到了标签y,再做前向传播,最后用预测的predict_y和y求交叉熵损失函数。这里第一个要注意的地方是y = y.squeeze(1)这一行。在PyTorch中用交叉熵函数时,标签的形状应该为[N, A, B, ...],预测值的形状应为[N, num_class, A, B, ...]。其中,A,B, ...表示数据的形状。在我们的任务中,数据是二维的,因此标签的形状应为[N, H, W],预测值的形状应为[N, num_class, H, W]。而我们在DataLoader中获得的数据的形状是[N, 1, H, W]。我们要对数据y的形状做一个变换,使之满足PyTorch的要求。这里由于输入是单通道,我们可以随便用squeeze()把y长度为1的通道去掉。如果图像是多通道的话,我们则不应该修改y,而是要对预测张量y_predict做一个reshape,改成[N, num_class, C, H, W]。
第二个要注意的是y = torch.ceil(x * (color_level - 1)).long()这一行。为什么需要写一个这么复杂的浮点数转整数呢?这个地方的实现需要多解释几句。在我们的代码中,PixelCNN的输入可能来自两个地方:
- 训练时,PixelCNN的输入来自数据集。数据集里的颜色值是0~1的浮点数。
- 采样时,PixelCNN的输入来自PixelCNN的输出。PixelCNN的输出是整型(别忘了,PixelCNN只能产生离散的输出)。
两种输入,一个是0~1的浮点数,一个是0~color_level-1的整数。为了统一两个输入的形式,最简单的做法是对整型颜色输入做个除法,映射到0~1里,把它统一到浮点数上。
此外,还有一个地方需要类型转换。在训练时,我们需要得到每个像素的标签,即得到每个像素颜色的真值。由于PixelCNN的输出是离散的,这个标签也得是一个离散的颜色。而标签来自训练数据,训练数据又是0~1的浮点数。因此,在计算标签时,需要做一次浮点到整型的转换。这样,整个项目里就有两个重要的类型转换:一个是在获取标签时把浮点转整型,一个是在采样时把整型转浮点。这两个类型转换应该恰好「互逆」,不然就会出现转过去转不回来的问题。
在项目中,我使用了下图所示的浮点数映射到整数的方法。0.0映射到0,(0, 1/255]映射到1,……(254/255, 1]映射到255。即浮点转整型时使用ceil(x*255),整型转浮点的时候使用x/255。这种简单的转换方法保证一个区间里的离散颜色值只会映射到一个整数上,同时把整数映射回浮点数时该浮点数也会落在区间里。如果你随手把浮点转整型写成了int(x*255),则会出现浮点转整数和整数转浮点对应不上的问题,到时候采样的结果会很不好。
由于一个整型只能映射到一个浮点数,而多个浮点数会映射到一个整数,严格来说,大部分浮点数转成整数再转回来是变不回原来的浮点数的。这两个转换过程从数学上来说不是严格的互逆。但是,如果我们马虎一点,把位于同一个区间的浮点数看成等价的,那么浮点数和整数之间的映射就是一个双射,来回转换不会有任何信息损失。
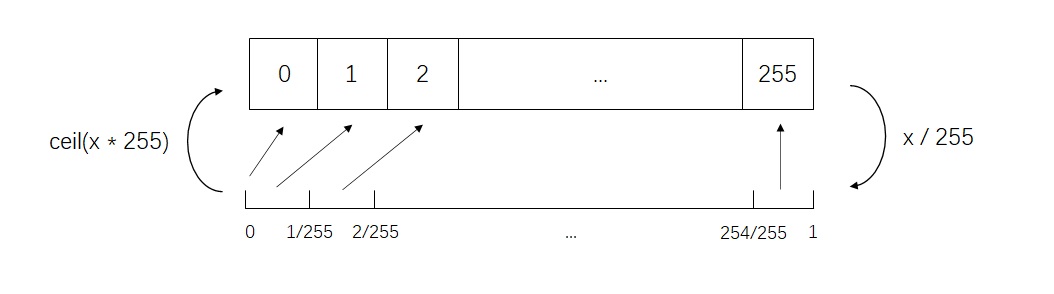
刚才代码中y = torch.ceil(x * (color_level - 1)).long()这一行实际上就是在描述怎样把训练集的浮点颜色值转换成0~color_level-1之间的整型标签的。
再来看看采样部分的代码。和正文里的描述一样,在采样时,我们把x初始化成一个0张量。之后,循环遍历每一个像素,输入x,把预测出的下一个像素填入x.
1 | def sample(model, device, model_path, output_path, n_sample=81): |
整个采样代码的核心部分是下面这几行。我们先获取模型的输出,再用softmax转换成概率分布,再用torch.multinomial(prob_dist,
1)从概率分布里采样出一个0~(color_level-1)的离散颜色值,再除以(color_level - 1)把离散颜色转换成浮点颜色(因为网络是输入是浮点颜色),最后把新像素填入生成图像。1
2
3
4
5output = model(x)
prob_dist = F.softmax(output[:, :, i, j], -1)
pixel = torch.multinomial(prob_dist,
1).float() / (color_level - 1)
x[:, :, i, j] = pixel
上面的代码中,如前所述,/ (color_level - 1)与前面的torch.ceil(x * (color_level - 1)).long()必须是对应起来的。两个操作必须「互逆」,不然就会出问题。
当然,最后得到的图像x是一个用0~1浮点数表示的图像,可以直接把它乘255变成一个用8位字节表示的图像,这一步浮点到整型的转换是为了让图像输出,和其他图像任务的后处理是一样的,和PixelCNN对于离散颜色和连续颜色的建模不是同一个意思,不是非得取一次ceil()。
PixelCNN训练起来很慢。在代码中,我默认训练40个epoch。原版PixelCNN要花一小时左右训完,Gated PixelCNN就更慢了。
以下是我得到的一些采样结果。首先是只有8个颜色级别的PixelCNN和Gated PixelCNN。
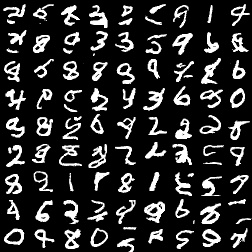

可以看出,PixelCNN经常会生成一些没有意义的「数字」,而Gated PixelCNN生成的大部分数字都是正常的。但由于颜色级别只有8,模型偶尔会生成较粗的色块。这个在Gated PixelCNN的输出里比较明显。
之后看一下正常的256个颜色级别的PixelCNN和Gated PixelCNN采样结果。
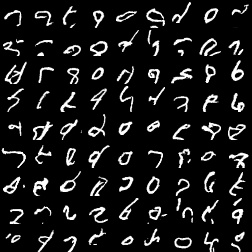
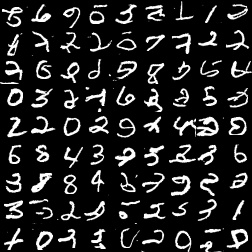
由于颜色级别增大,任务难度变大,这两个模型的生成效果就不是那么好了。当然,Gated PixelCNN还是略好一些。训练效果差,与MNIST的特性(大部分像素都是0和255)以及PixelCNN对于离散颜色的建模有关。PixelCNN的这一缺陷已经在PixelCNN++论文里分析过了。
PixelCNN++ 源码阅读
PixelCNN++在实现上细节颇多,复现起来难度较大。而且它的官方实现是拿TensorFlow写的,对于只会PyTorch的选手来说不够友好。还好,PixelCNN++的官方实现非常简练,核心代码只有两个文件,没有过度封装,也没有过度使用API,哪怕不懂TensorFlow也不会有障碍(但由于代码中有很多科学计算,阅读起来没有障碍,却难度不小)。让我们来通过阅读官方源码来学习PixelCNN++的实现。
官方代码的地址在 https://github.com/openai/pixel-cnn 。源码有两个核心文件:nn.py实现了网络模块及一些重要的训练和采样函数,model.py定义了网络的结构。让我们自顶向下地学习,先看model.py,看到函数调用后再跑到nn.py里查看实现细节。
model.py里就只有一个函数model_spec,它定义了神经网络的结构。
它的参数为:
1 | def model_spec(x, |
各参数的意义为:
x: 形状为[N, H, W, D1]的输入张量。其中,D1表示输入通道数。对于RGB图像,D1=3。h: 形状为[N, K]的约束条件,即对于每个batch来说,约束条件是一个长度K的向量。这里的约束条件和Gatd PixelCNN中提出的一样,可以是文字,也可以是类别,只要约束条件最终被转换成一个向量就行。init: 是否执行初始化。这和TensorFlow的实现有关,可以不管。ema: 对参数使用指数移动平均,一种训练优化技巧,和论文无关,可以不管。dropout_p: dropout的概率。nr_resnet: U-Net每一块里有几个ResNet层(U-Net一共有6块,编码器3块解码器3块)。nr_filters: 每个卷积层的卷积核个数,即所有中间特征图的通道数。nr_logistic_mix: 论文里的$K$,表示用几个logistic分布混合起来描述一个颜色分布。resnet_nonlinearity: 激活函数的类别。energy_distance:是否使用论文里没提过的一种算损失函数的办法,可以不管。
之后来看函数体。20行with arg_scope ([nn.conv2d, ...], counters=counters, ...)大概是说进入了TensorFlow里的arg_scope这个上下文。只要在上下文里,后面counters等参数就会被自动传入nn.conv2d等函数,而不需要在函数里显式传参。这样写会让后面的函数调用更简短一点。
22行至30行在选择激活函数,可以直接跳过。1
2
3
4
5
6
7
8
9# parse resnet nonlinearity argument
if resnet_nonlinearity == 'concat_elu':
resnet_nonlinearity = nn.concat_elu
elif resnet_nonlinearity == 'elu':
resnet_nonlinearity = tf.nn.elu
elif resnet_nonlinearity == 'relu':
resnet_nonlinearity = tf.nn.relu
else:
raise('resnet nonlinearity ' + resnet_nonlinearity + ' is not supported')
从35行开始,函数正式开始定义网络结构。一开始,代码里有一个匪夷所思的操作:先是取出输入张量的形状xs,再根据这个形状给x填充了一个全是1的通道。
1 | xs = nn.int_shape(x) |
虽然作者加了注释,说这个x_pad后面会用到。但我翻遍了代码,楞是没找到这个多出来的通道发挥了什么作用。GitHub issue里也有人提问,问这个x_pad在做什么。有其他用户给了回复,说他尝试了去掉填充,结果不变。可见这一行代码确实是毫无贡献,还增加了不必要的计算量。大概是作者没删干净过时的实现代码。
之后的几行是在初始化上卷积和左上卷积的中间结果(上卷积和Gated PixelCNN里的垂直卷积类似,左上卷积和Gated PixelCNN里的水平卷积类似)。u_list会保存所有上卷积在编码器里的结果,ul_list会保存所有左上卷积在编码器里的结果。这些结果会供解码器使用。1
2
3
4
5
6
7
8
9
10
11
12 u_list = [nn.down_shift(
nn.down_shifted_conv2d(x_pad,
num_filters=nr_filters,
filter_size=[2, 3])
)] # stream for pixels above
ul_list = [nn.down_shift(
nn.down_shifted_conv2d(x_pad,
num_filters=nr_filters,
filter_size=[1,3])
) + nn.right_shift(
nn.down_right_shifted_conv2d(x_pad, num_filters=nr_filters, filter_size=[2,1])
)] # stream for up and to the left
作者没有使用带掩码的卷积,而是通过普通卷积加偏移等效实现了掩码卷积。这一实现非常巧妙,效率更高。我们来看看这几个卷积的实现方法。
首先看上卷积down_shifted_conv2d,它表示实现一个卷积中心在卷积核正下方的卷积。作者使用了[2,3]的卷积核,并手动给卷积填充(注意,卷积的类型是'valid'不是'same')。这种卷积等价于我们做普通的3x3卷积再给上面6个像素打上掩码。
1 | def down_shifted_conv2d(x, num_filters, filter_size=[2,3], stride=[1,1], **kwargs): |
作者在down_shifted_conv2d之后跟了一个down_shift。这个操作和我们实现Gated PixelCNN时移动v_to_h张量的做法一样,去掉张量最下面一行,在最上面一行填0,也就是让张量往下移了一格。
1 | def down_shift(x): |
类似地,在做第一次左上卷积时,作者把一个下移过的1x3卷积结果和一个右移过的2x1卷积结果拼到了一起。其中,down_right_shifted_conv2d就是实现一个卷积中心在卷积核右下角的卷积。
1 | ul_list = [nn.down_shift( |
初始化完毕后,数据就正式进入了U-Net。让我们先略过函数的细节,看一看模型的整体架构。在下采样部分,三级U-Net在每一级都是先经过若干个gated_resnet模块,再下采样。
1 | for rep in range(nr_resnet): |
之后是上采样。类似地,数据先经过若干个gated_resnet模块,再上采样。与前半部分不同的是,前半部分的输出会从u_list和ul_list中逐个取出(实际上这两个list起到了一个栈的作用),接入到gated_resnet的输入里。
1 | u = u_list.pop() |
模型U-Net的部分到此为止。整个网络的结构并不复杂,我们只要看懂了nn.gated_resnet的实现,就算理解了整个模型的实现。让我们来详细看一下这个模块是怎么实现的。以下是整个模块的实现代码。
1 | def gated_resnet(x, a=None, h=None, nonlinearity=concat_elu, conv=conv2d, init=False, counters={}, ema=None, dropout_p=0., **kwargs): |
照例,我们来先看一下函数的每个参数的意义。
1 | def gated_resnet(x, a=None, h=None, nonlinearity=concat_elu, conv=conv2d, init=False, counters={}, ema=None, dropout_p=0., **kwargs) |
x: 模块的输入。a: 模块的附加输入。附加输入有两个来源:上方u_list的信息传递给左上方ul_list的信息、编码器把信息传递给解码器。h: 形状为[N, K]的约束条件。从模型的参数里传递而来。nonlinearity: 激活函数。从模型的参数里传递而来。conv:卷积操作的函数。可能是上卷积或者左上卷积。init: 是否执行初始化。这和TensorFlow的实现有关,可以不管。counters: 作者写的一个用于方便地给模块的命名的字典,可以不管。ema: 对参数使用指数移动平均。从模型的参数里传递而来。dropout_p: dropout的概率。从模型的参数里传递而来。
模块主要是做了下面这些卷积操作。一开始,先对输入x做卷积,得到c1。如果有额外输入a,则对a做一个1x1卷积(作者自己实现了1x1卷积,把函数命名为nin),加到c1上。做完第一个卷积后,过一个dropout层。最后再卷积一次,得到2*num_filters通道数的张量。
1 | c1 = conv(nonlinearity(x), num_filters) |
之后,作者也使用了一种门结构作为整个模块的激活函数。但是和Gated PixelCNN相比,PixelCNN++的门结构简单一点。详见下面的代码。
1 | a, b = tf.split(c2, 2, 3) |
最后输出时,c3和输入x之间有一个残差连接。1
return x + c3
看完gated_resnet的实现,我们可以跳回去继续看模型结构了。经过了U-Net的主体结构后,只需要经过一个输出层就可以得到最终的输出了。输出层里,作者用1x1卷积修改了输出通道数,令最后的通道数为10*nr_logistic_mix。
1 | if energy_distance: |
大家还记得这个10是从哪里来的吗?在正文中,我们曾经学过,对于某个像素的第$i$个logistic分布,网络会输出10个参数:$\pi, \mu_r, \mu_g, \mu_b, s_r, s_g, s_b, \alpha, \beta, \gamma$。这个10就是10个参数的意思。
光知道一共有10个参数还不够。接下来就是PixelCNN++比较难懂的部分——怎么用这些参数构成一共logistic分布,并从连续分布中得到离散的概率分布。这些逻辑被作者写在了损失函数nn.discretized_mix_logistic_loss里面。
1 | def discretized_mix_logistic_loss(x,l,sum_all=True): |
这个函数很长,很难读。它实际上可以被拆成四个部分:取参数、求均值、求离散概率、求和。让我们一部分一部分看过来。
首先是取参数部分,这部分代码如下所示。模型一共输出了10*nr_mix个参数,即输出了nr_mix组参数,每组有10个参数。如前所述,第一个参数是选择该分布的未经过softmax的概率logit_probs,之后的6个参数是三个通道的均值及三个通道的标准差取log,最后3个参数是描述通道间依赖关系的$\alpha, \beta, \gamma$。不用去认真阅读这段代码,只需要知道这些代码可以把数据取出来即可。
1 | xs = int_shape(x) # true image (i.e. labels) to regress to, e.g. (B,32,32,3) |
之后是求均值部分。在第一行,作者用了一种曲折的方式实现了repeat操作,把x在最后一维重复了nr_mix次,方便后续处理。在第二第三行,作者根据论文里的公式,调整了G通道和B通道的均值。在最后第四行,作者把所有均值张量拼到了一起。
1 | x = tf.reshape(x, xs + [1]) + tf.zeros(xs + [nr_mix]) # here and below: getting the means and adjusting them based on preceding sub-pixels |
再来是求离散概率部分。作者根据论文里的公式,算出了当前离散分布的积分上限和积分下限(通过从累计分布密度函数里取值),再做差,得到了离散分布的概率。由于最终的概率值要求log,作者没有按照公式的顺序先算累计分布概率函数的值,再取log,而是把所有计算放到一起并化简。这样代码虽然难读了一点,但减少了不必要的计算,也减少了精度损失。
1 | centered_x = x - means |
作者还算了积分区间中心的概率,以处理某些边界情况。实际上这个值没有在代码中使用。1
2
3mid_in = inv_stdv * centered_x
log_pdf_mid = mid_in - log_scales - 2.*tf.nn.softplus(mid_in)
# log probability in the center of the bin, to be used in extreme cases (not actually used in our code)
光做差还不够。为了处理颜色值在0和255的边界情况,作者还给代码加入了一些边界上的特判,才得到了最终的概率log_probs。1
2
3
4
5log_probs = tf.where(x < -0.999, log_cdf_plus,
tf.where(x > 0.999, log_one_minus_cdf_min,
tf.where(cdf_delta > 1e-5,
tf.log(tf.maximum(cdf_delta, 1e-12)),
log_pdf_mid - np.log(127.5))))
最后是loss求和部分。除了要把离散概率的对数求和外,还要加上选择这个分布的概率的对数。log_prob_from_logits就是做一个softmax再求一个log。算上了选择分布的概率后,再对loss求一次和,就得到了最终的loss。
1 | log_probs = tf.reduce_sum(log_probs,3) + log_prob_from_logits(logit_probs) |
至此,我们就看完了训练部分的关键代码。我们再来看一看采样部分最关键的代码,怎么从logisitc分布里采样。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21def sample_from_discretized_mix_logistic(l,nr_mix):
ls = int_shape(l)
xs = ls[:-1] + [3]
# unpack parameters
logit_probs = l[:, :, :, :nr_mix]
l = tf.reshape(l[:, :, :, nr_mix:], xs + [nr_mix*3])
# sample mixture indicator from softmax
sel = tf.one_hot(tf.argmax(logit_probs - tf.log(-tf.log(tf.random_uniform(logit_probs.get_shape(), minval=1e-5, maxval=1. - 1e-5))), 3), depth=nr_mix, dtype=tf.float32)
sel = tf.reshape(sel, xs[:-1] + [1,nr_mix])
# select logistic parameters
means = tf.reduce_sum(l[:,:,:,:,:nr_mix]*sel,4)
log_scales = tf.maximum(tf.reduce_sum(l[:,:,:,:,nr_mix:2*nr_mix]*sel,4), -7.)
coeffs = tf.reduce_sum(tf.nn.tanh(l[:,:,:,:,2*nr_mix:3*nr_mix])*sel,4)
# sample from logistic & clip to interval
# we don't actually round to the nearest 8bit value when sampling
u = tf.random_uniform(means.get_shape(), minval=1e-5, maxval=1. - 1e-5)
x = means + tf.exp(log_scales)*(tf.log(u) - tf.log(1. - u))
x0 = tf.minimum(tf.maximum(x[:,:,:,0], -1.), 1.)
x1 = tf.minimum(tf.maximum(x[:,:,:,1] + coeffs[:,:,:,0]*x0, -1.), 1.)
x2 = tf.minimum(tf.maximum(x[:,:,:,2] + coeffs[:,:,:,1]*x0 + coeffs[:,:,:,2]*x1, -1.), 1.)
return tf.concat([tf.reshape(x0,xs[:-1]+[1]), tf.reshape(x1,xs[:-1]+[1]), tf.reshape(x2,xs[:-1]+[1])],3)
一开始,还是和刚刚的求loss一样,作者把参数从网络输出l里拆出来。logit_probs是选择某分布的未经softmax的概率,其余的参数是均值、标准差、通道间依赖参数。
1 | def sample_from_discretized_mix_logistic(l,nr_mix): |
之后,作者对logit_probs做了一个softmax,得到选择各分布的概率。之后,作者根据这个概率分布采样,从nr_mix个logistic分布里选了一个做为这次生成使用的分布。作者没有使用下标来选择数据,而是把选中的序号编码成one-hot向量sel,通过乘one-hot向量来实现从某数据组里取数。
1 | sel = tf.one_hot(tf.argmax(logit_probs - tf.log(-tf.log(tf.random_uniform(logit_probs.get_shape(), minval=1e-5, maxval=1. - 1e-5))), 3), depth=nr_mix, dtype=tf.float32) |
接着,作者根据sel,取出nr_mix个logistic分布中某一个分布的均值、标准差、依赖系数。1
2
3
4# select logistic parameters
means = tf.reduce_sum(l[:,:,:,:,:nr_mix]*sel,4)
log_scales = tf.maximum(tf.reduce_sum(l[:,:,:,:,nr_mix:2*nr_mix]*sel,4), -7.)
coeffs = tf.reduce_sum(tf.nn.tanh(l[:,:,:,:,2*nr_mix:3*nr_mix])*sel,4)
再然后,作者用下面两行代码完成了从logistic分布的采样。从一个连续概率分布里采样是一个基础的数学问题。其做法是先求概率分布的累计分布函数。由于累计分布函数可以把自变量一一映射到0~1之间的概率,我们就得到了一个0~1之间的数到自变量的映射,即累积分布函数的反函数。通过对0~1均匀采样,再套入累积分布函数的反函数,就完成了采样。下面第二行计算其实就是在算logisitc分布的累积分布函数的反函数的一个值。
1 | u = tf.random_uniform(means.get_shape(), minval=1e-5, maxval=1. - 1e-5) |
只从分布里采样还不够,我们还得算上依赖系数。把依赖系数的贡献算完后,整个采样就结束了,我们得到了RGB三个颜色值。
1 | x0 = tf.minimum(tf.maximum(x[:,:,:,0], -1.), 1.) |
至此,PixelCNN++中最具有学习价值的代码就看完了。让我再次总结一下PixelCNN++中的重要代码,并介绍一下学习它们需要什么前置知识。
PixelCNN++中第一个比较重要的地方是掩码卷积的实现。它没有真的使用到掩码,而是使用了卷积中心在卷积核下方和右下角的卷积来等价实现。要读懂这些代码,你需要先看懂PixelCNN和Gated PixelCNN里面对于掩码卷积的定义,知道PixelCNN++为什么要做两种卷积。之后,你还需要对卷积操作有一点基础的认识,知道卷积操作的填充方式其实是在改变卷积中心在卷积核中的位置。你不需要懂太多TensorFlow的知识,毕竟卷积的API就那么几个参数,每个框架都差不多。
PixelCNN++的另一个比较重要的地方是logistic分布的离散概率计算与采样。为了学懂这些,你需要一点比较基础的统计学知识,知道概率密度函数与累积分布函数的关系,知道怎么用计算机从一个连续分布里采样。之后,你要读懂PixelCNN++是怎么用logistic分布对离散概率建模的,知道logistic分布的累计分布函数就是sigmoid函数。懂了这些,你看代码就不会有太多问题,代码基本上就是对论文内容的翻译。反倒是如果读论文没读懂,可以去看代码里的实现细节。