近期,各个科技公司纷纷展示了自己在视频生成模型上的最新成果。虽然不少模型的演示效果都非常惊艳,但其中可供学术界研究的开源模型却少之又少。Stable Video Diffusion (SVD) 算得上是目前开源视频生成模型中的佼佼者,有认真一学的价值。在这篇文章中,我将面向之前已经熟悉 Stable Diffusion (SD) 的读者,简要解读 SVD 的论文。由于 SVD 的部分结构复用了之前的工作,并没有在论文正文中做详细介绍,所以我还会补充介绍一下 SVD 的模型结构、调度器。后续我还会在其他文章中详细介绍 SVD 的代码实现及使用方法。

背景
Stable Video Diffusion 是 Stability 公司于 2023 年 11 月 21 日公布并开源的一套用扩散模型实现的视频生成模型。由于该模型是从 Stability 公司此前发布的著名文生图模型 Stable Diffusion 2.1 微调而成的,因而得名 Stable Video Diffusion。SVD 的技术报告论文与模型同日发布,它对 SVD 的训练过程做了一个详细的分享。由于该论文过分偏向实践,这里我们仅对它的开头及中间模型设计的几处关键部分做解读。
摘要
最近,有许多视频生成模型都是在图像生成模型 SD 的基础上,添加和视频时序相关的模块,并在小规模高质量视频数据集上微调新模型。而 SVD 作者认为,该领域在训练方法及精制数据集的策略上并未达成统一。这篇文章的主要贡献,也正是提出了一套训练方法与精制数据集的方法。具体而言,SVD 的训练由三个阶段组成:文生图预训练、视频预训练、高质量视频微调。同时,SVD 提出了一种系统性的数据精制流程,包含数据的标注与过滤这两部分的策略。论文会分享诸多的实验成果,包括验证精心构建的数据集对生成高质量视频的必要性、探究视频预训练与微调这两步的重要性、展示基础模型如何为图生视频等下游任务提供强大的运动表示、演示模型如何提供多视角三维先验并可以作为微调多视角扩散模型的基础模型在一轮神经网络推理中同时生成多视角的图片。
「构建」一个数据集在论文中通常用动词 curate 及名词 curation 指代。curate 原指展出画作时,选择、组织和呈现艺术品的过程。而现代将这个词用在数据集上时,则转变为表示精心选择、组织和管理数据的过程。中文中并没有完全对应的翻译,我暂时将这个词翻译为「精制」,以区别于随便收集一些数据来构成一个数据集。
总结一下,SVD 并没有强调在模型设计或者采样算法上的创新,而主要宣传了该工作在数据集精制及训练策略上的创新。对于大部分普通研究人员来说,由于没有训练大视频模型的需求,该文章的很多内容都价值不大。我们就只是来大致过一遍这篇文章的主要内容。
SVD 模型架构回顾
Video-LDM 与 SVD
在阅读正文之前,我们先来回顾一下此前视频生成模型的开发历程,并重点探究 SVD 的模型架构——Video LDM 的具体组成。绝大多数工作在训练一个基于扩散模型的视频生成模型时,都是在预训练的 SD 上加入时序模块,如 3D 卷积,并通过微调把一个图像生成模型转换成视频生成模型。由于 SD 是一种 LDM (Latent Diffusion Model),所以这些视频模型都可以归类为 Video-LDM。所谓 LDM,就是一种先生成压缩图像,再用解码模型把压缩图像还原成真实图像的模型。而对于视频,Video-LDM 则会先生成边长压缩过的视频,再把压缩视频还原。
虽然 Video-LDM 严格上来说是一个视频扩散模型的种类,但大家一般会用Video LDM (没有横杠) 来指代 Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models 这篇工作。这篇论文已在 CVPR 2023 上发布,两个主要作者正是前一年在 CVPR 上发表 SD 论文的主要作者,也是现在这篇 SVD 论文的主要作者。从署名上来看,似乎两个作者在毕业后就加入了 Stability 公司,并将 Video LDM 拓展成了 SVD。论文中也讲到,SVD 完全复用了 Video LDM 的结构。为了了解 SVD 的模型结构,我们再来回顾一下 Video LDM 的结构。
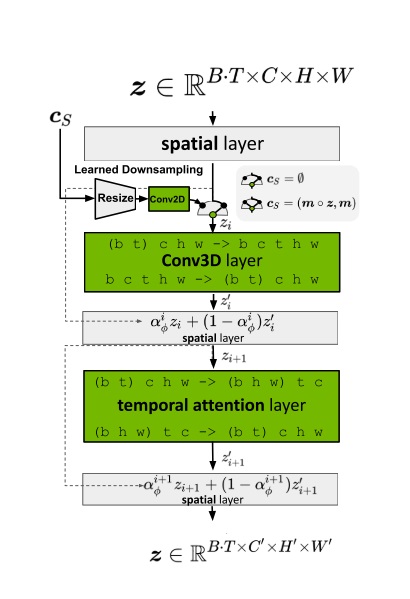
在 SD 的基础上,Video LDM 做对模型结构了两项改动:在扩散模型的去噪模型 U-Net 中加入时序层、在对图像压缩和解压的 VAE 的解码器中加入时序层。
添加时序层
Video LDM 在 U-Net 中加入时序层的方法与多数同期方法相同,是在每个原来处理图像的空间层后面加上处理视频的时序层。Video LDM 加入的时序层包括 3D 卷积层与时序注意力层。这些新模块本身不难理解,但我们需要着重关注这些新模块是怎么与原模型兼容的。
要兼容各个模块,其实就是要兼容数据的形状。本来,图像生成模型的 U-Net 的输入形状为 B C H W,分别表示图像数、通道数、高、宽。而视频数据的形状是 B T C H W,即视频数、视频长度、通道数、高、宽。要让视频数据复用之前的图像模型的结构,只要把数据前两维合并,变成 (B T) C H W 即可。这种做法就是把 B 组长度为 T 的视频看成了 $B \cdot T$ 张图片。
对于之前已有的空间层,只要把数据形状变成 (B T) C H W 就没问题了。而 SVD 又新加入了两种时序层:3D 卷积和时序注意力。我们来看一下数据是怎么经过这些新的时序层的。
2D 卷积会对 B C H W 的数据的后两个高、宽维度做卷积。类似地,3D 卷积会对数据最后三个时间、高、宽维度做卷积。所以,过 3D 卷积前,要把形状从 (B T) C H W 变成 B C T H W,做完卷积再还原。
接下来我们来看新的时序注意力。这个地方稍微有点难理解,我们从最简单的注意力开始一点一点学习。最早的 NLP 中的注意力层的输入形状为 B L C,表示数据数、token 长度、token 通道数。L 这一维最为重要,它表示了 L个 token 之间互相交换信息。如果把其拓展成图像空间注意力,则 token 表示图像的每一个像素。在这种注意力层中,L 是 (H W),B C H W 的数据会被转换成 B (H W) C 输入进注意力层。这表示同一组图像中,每个像素两两之间交换信息。而让视频数据过空间注意力层时,只需要把 B 换成 (B T) 即可,即把数据形状从 (B T) C H W 变为 (B T) (H W) C。这表示同一组、同一帧的图像的每个像素之间,两两交换信息。
在 SVD 新加入的时序注意力层中,token 依旧指代是某一组、某一帧上的一个像素。然而,这次我们不是让同一张图像的像素互相交换信息,而是让不同时刻的像素互相交换信息。因此,这次 token 长度 L 是 T,它表示要像素在时间维度上交换信息。这样,在视频数据过时序层里的自注意力层时,要把数据形状从 (B T) C H W 变成 (B H W) T C。这表示每一组、图像每一处的像素独立处理,它们仅与同一位置不同时间的像素进行信息交换。
此处如果你没有理解注意力层的形状变换也不要紧,它只是一个实现细节,不影响后面的阅读。如果感兴趣的话,可以回顾一下 Transformer 论文的代码,看一下注意力运算为什么是对
B L C的数据做操作的。
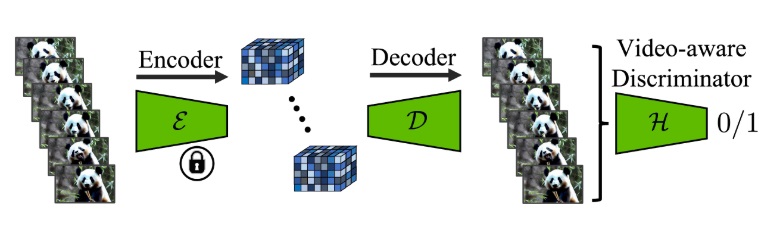
微调 VAE 解码器
Video LDM 的另一项改动是修改了图像压缩模型 VAE 的解码器。具体来说,方法先在 VAE 的解码器中加入类似的时序层,并在 VAE 配套的 GAN 的判别器里也加入了时序层,随后开始微调。在微调时,编码器不变,仅训练解码器和判别器。
如果你没听过这套 VAE + GAN 的架构的话,请回顾 Stable Diffusion 论文及与其紧密相关的 VQGAN 论文。
以上就是 Video LDM 的模型结构。SVD 对其没有做任何更改,所以也没有在论文里对模型结构做详细介绍。稍有不同的是,Video LDM 仅微调了新加入的模块,而 SVD 在加入新模块后对模型的所有参数都进行了重新训练。
SVD 训练细节
SVD 分四节介绍了模型训练过程。第一节介绍了数据精制的过程,后三节分别介绍了训练的三个阶段:文生图预训练、视频预训练、高质量视频微调。
获取了一个大规模视频数据集后,SVD 的数据精制主要由预处理和标注这两步组成。由于视频生成模型主要关注生成同一个场景的视频,而不考虑转场的问题,每段训练视频也应该尽量只包含一个场景。为此,预处理主要是在用一些自动化视频剪切工具把收集到的视频进一步切成连续的片段。经切片后,视频片段数变为原来的4倍。标注主要是给视频加上文字描述,以训练一个文生视频的模型。SVD 在添加文字描述时用到了多个标注模型,并使用大语言模型来润色描述。经预处理和标注后,得到的数据集被称作 LVD (Large Video Dataset)。
SVD 数据精制的细节中,比较值得注意的是有关视频帧数的处理。由于开发团队发现视频数据的播放速度快慢不一,于是他们使用光流预测模型来大致估计每段视频的播放速度(以帧率 FPS 表示),并将视频的帧率也作为标注。这样,在训练时,视频的帧率也可以作为一种约束信息。这样的好处是,在我们在生成视频时,可以用该约束来指定视频的播放速度。
之后我们来看 SVD 模型训练的三个阶段。对于第一个文生图预训练阶段,论文没有对模型结构做过多修改,因为他们在这一步使用了之前训练好的 SD 2.1。不过,SVD 在这一步做了一个非常重要的改进:SVD 的噪声调度器从原版的 DDPM 改成了 EDM,采样方法也改成了 EDM 的。
EDM 的论文全称为 Elucidating the Design Space of Diffusion-Based Generative Models 。这篇论文用一种概括性较强的数学模型统一表示了此前各种各样的扩散模型结构,并提出了改进版模型的训练及采样策略。简单来说,EDM 把扩散模型不同时刻的噪声强度表示成 $\sigma_t$,它表示在 $t$ 时刻时,对来自数据集的图像加了标准差为 $\sigma_t$ 的高斯噪声 $\mathcal{N}(\mathbf{0}, \sigma_t^2\mathbf{I})$。一开始,对于没加噪声的图像,$\sigma_0=0$。对于最后一个时刻 $T$ 的图像,$\sigma_T$ 要足够大,使得原图像的内容被完全破坏。
这里时刻 $0$ 与时刻 $T$ 的定义与 DDPM 论文相同,与 EDM 论文相反。
有了这样一种统一的表示后,EDM 对扩散模型的训练和采样都做了不少改进。这里我们仅关注其中最重要的一条改进:将离散噪声改进成连续噪声。原来 DDPM 的去噪模型会输入时刻 $t$ 这个参数。EDM 论文指出,$t$ 实际上表示了噪声强度 $\sigma_t$,应该把 $\sigma_t$ 输入进模型。与其用离散的 $t$ 训练一个只认识离散噪声强度的去噪模型,不如训练一个认识连续噪声强度 $\sigma$ 的模型。这样,在采样 $n$ 步时,我们不再是选择离散去噪时刻[timestep[n], timestep[n - 1], ..., 0],而是可以选择连续噪声强度[sigma[n], sigma[n - 1], ..., 0] 。这样采样更灵活,效果也更好。在第一个训练阶段中,SVD 照搬了 EDM 的这种训练方法,改进了原来的 DDPM。SVD 的默认采样策略也使用了 EDM 的 。我们会在之后的代码实践文章中详细学习这种新采样方法。
对于第二个视频预训练阶段,或许是因为视频模型和图像模型的训练过程毫无区别,论文的介绍重点依然放在了这一阶段的数据处理上,而没有强调训练方法上的创新。简单来看,这一阶段的目标是得到一个过滤后的高质量数据集 LVD-F。为了找到这样一种合适的过滤方案,开发团队先用排列组合生成了大量的过滤方案:对每类指标(文本视频匹配度、美学分数、帧率等)都设置 12.5%, 25% 或 50% 的过滤条件,然后不同指标的条件之间排列组合。之后,开发团队抽取原数据集的一个子集 LVD-10M,用各个方案得到过滤后的视频子集 LVD-10-F。最后,用这样得到的子数据集分别训练模型,比较模型输出的好坏,以决定在完整数据集上使用的最优过滤方案。
在第三个阶段,参考以往多阶段训练图像模型的经验,SVD 也在另一个小而精的视频数据集上进行微调。此数据集的获取方法并没有在论文中给出,大概率是人工手动收集并标注。
SVD 应用
经上述训练后,开发团队得到了一个低分辨率的基础文生视频模型。在实验部分,SVD 论文除了给出视频生成模型在各大公开数据集上的指标外,还分享了几个基于基础模型的应用。
高分辨率文生视频
基础文生视频最直接的应用就是高分辨率文生视频。实现的方法很简单,只要准备一个高分辨率的视频数据集,在此数据集上微调原基础模型即可。SVD 高分辨率文生视频模型能生成 576 x 1024 的视频。

高分辨率图生视频
除了文生视频外,也可以用基础模型来微调出一个图生视频模型。为了把约束从文本换成图像,开发团队将 U-Net 交叉注意力层的约束从文本嵌入变成了约束图像的图像嵌入,并将约束图像与原 U-Net 的噪声输入在通道维度上拼接在一起。特别地,参考以往 Cascaded diffusion models 论文的经验,约束图像在与噪声输入拼接前,会加上一些噪声。除此之外,由于约束机制的变动,像文生图模型一样将约束强度(CFG scale)设成 7.5 会让 SVD 图生视频模型产生瑕疵。因此,SVD 图生视频模型每一帧的约束强度不同,从第一帧到最后一帧以 1.0 到 3.0 线性增长。

参考之前 AnimateDiff 工作,SVD 也成功训练了相机运动 LoRA,使得图生视频模型只会生成平移、缩放等某一种特定相机运动的视频。

视频插帧
Video LDM 曾提出了一种把基础视频模型变成视频插帧模型方法。该方法以视频片段的首末帧为额外约束,在此新约束下把视频生成模型微调成了预测中间帧的视频预测模型。SVD 以同样方式实现了这一应用。
多视角生成
多视角生成是计算机视觉中另一类重要的任务:给定 3D 物体某个视角的图片,需要算法生成物体另外视角的图片,从而还原 3D 物体的原貌。而视频生成模型从数据中学到了物体的平滑变换规律,恰好能帮助到多视角生成任务。SVD 论文用不少篇幅介绍了如何在 3D 数据集上生成视频并微调基础模型,从而得到一个能生成环绕物体旋转的视频的模型。

结语
Stable Video Diffusion 是在文生图模型 Stable Diffusion 2.1 的基础上添加了和 Video LDM 相同的视频模块微调而成的一套视频生成模型。SVD 的论文主要介绍了其精制数据集的细节,并展示了几个微调基础模型能实现的应用。通过微调基础低分辨率文生视频模型,SVD 可以用于高分辨率文生视频、高分辨率图生视频、视频插帧、多视角生成。
对于没有资源与需求训练大视频模型的多数科研人员而言,没有深究这篇文章细节的必要。并且,由于 SVD 只开源了图生视频模型 (3D模型后来是在 SV3D 论文中正式公布的),这篇文章比较有用的只有和图生视频相关的部分。为了彻底搞懂 SVD 的原理,读这篇论文是不够的,我们还需要通过回顾 Video LDM 论文来了解模型结构,学习 EDM 论文来了解训练及采样机制。
这篇文章主要是面向熟悉 Stable Diffusion 的读者的。如果你缺少某些背景知识,欢迎读我之前介绍 Stable Diffusion 的文章。我没有在本文过多介绍 SVD 的实现细节,欢迎阅读我之后发表的 SVD 代码实践文章。
Stable Diffusion 解读(一):回顾早期工作
Stable Diffusion 解读(二):论文精读
Stable Diffusion 解读(三):原版实现及Diffusers实现源码解读