在上篇文章中,我们浏览了 Stable Video Diffusion (SVD) 的论文,并特别学习了没有在论文中提及的模型结构、噪声调度器这两个模块。在这篇文章中,让我们来看看 SVD 在 Diffusers 中的源码实现。我们会先学习 SVD 的模型结构,再学习 SVD 的采样流水线。在本文的多数章节中,我都会将 SVD 的结构与 Stable Diffusion (SD) 的做对比,帮助之前熟悉 SD 的读者快速理解 SVD 的性质。强烈建议读者在阅读本文前先熟悉 SD 及其在 Diffusers 中的实现。
Stable Diffusion Diffusers 实现源码解读
简单采样实验
目前开源的 SVD 仅有图生视频模型,即给定视频首帧,模型生成视频的后续内容。在首次开源时,SVD 有 1.0 和 1.0-xt 两个版本。二者模型结构配置相同,主要区别在于训练数据上。SVD 1.0 主要用于生成 14 帧 576x1024 的视频,而 1.0-xt 版本由 1.0 模型微调而来,主要用于生成 25 帧 576x1024 的视频。后来,开发团队又开源了 SVD 1.1-xt,该模型在固定帧率的视频数据上微调,输出视频更加连贯。为了做实验方便,在这篇文章中,我们将使用最基础的 SVD 1.0 模型。
参考 Diffusers 官方文档: https://huggingface.co/docs/diffusers/main/en/using-diffusers/svd ,我们来创建一个关于 SVD 的 “Hello World” 项目。如果你的电脑可以访问 HuggingFace 原站的话,直接运行下面的脚本就行了;如果不能访问原网站,可以尝试取消代码里的那行注释,访问 HuggingFace 镜像站;如果还是不行,则需要手动下载 “stabilityai/stable-video-diffusion-img2vid” 仓库,并将仓库路径改成本地下载的仓库路径。
1 |
|
成功运行后,我们能得到这样的一个火箭升空视频。它的第一帧会和我们的输入图片一模一样。

SVD 概览
由于 SVD 并没有在论文里对其图生视频模型做详细的介绍,我们没有官方资料可以参考,只能靠阅读源码来了解 SVD 的实现细节。为了让大家在读代码时不会晕头转向,我会在读代码前简单概述一下 SVD 的模型结构和采样方法。
SVD 和 SD 一样,是一个隐扩散模型(Latent Diffusion Model, LDM)。图像(视频帧)的生成由两个阶段组成:先由扩散模型生成压缩图像,再由 VAE 解码成真实图像。
扩散模型在生成图像时,会用一个去噪 U-Net $\epsilon_\theta$ 反复对纯噪声图像 $z_T$ 去噪,直至得到一幅有意义的图片 $z$。为了让模型输出我们想要的图像,我们会用一些额外的信息来约束模型,或者说将约束信息也输入进 U-Net。对于文生图 SD 来说,额外约束是文本。对于图生视频 SVD 来说,额外约束是图像。LDM 提出了两种输入约束信息的方式:与输入噪声图像拼接、作为交叉注意力模块的 K, V。SD 仅使用了交叉注意力的方式,而 SVD 同时使用了两种方式。
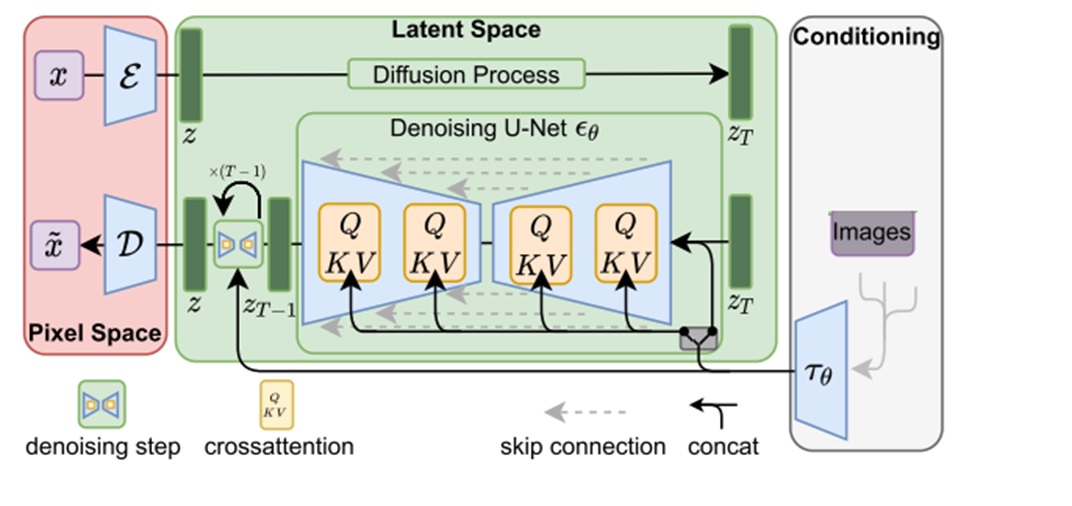
上面这两种添加约束信息的方法适用于信息量比较大的约束。实际上,还有一种更简单的输入实数约束信息的方法。除了噪声输入外,去噪模型还必须输入当前的去噪时刻 $t$。自最早的 DDPM 以来,时刻 $t$ 都是先被转换成位置编码,再输入进 U-Net 的所有残差块中。仿照这种输入机制,如果有其他的约束信息和 $t$ 一样可以用一个实数表示,则不必像前面那样将这种约束信息与输入拼接或输入交叉注意力层,只需要把约束也转换成位置编码,再与 $t$ 的编码加在一起。
SVD 给模型还添加了三种额外约束:噪声增强程度、帧率、运动程度。这三种约束都是用和时刻编码相加的形式实现的。
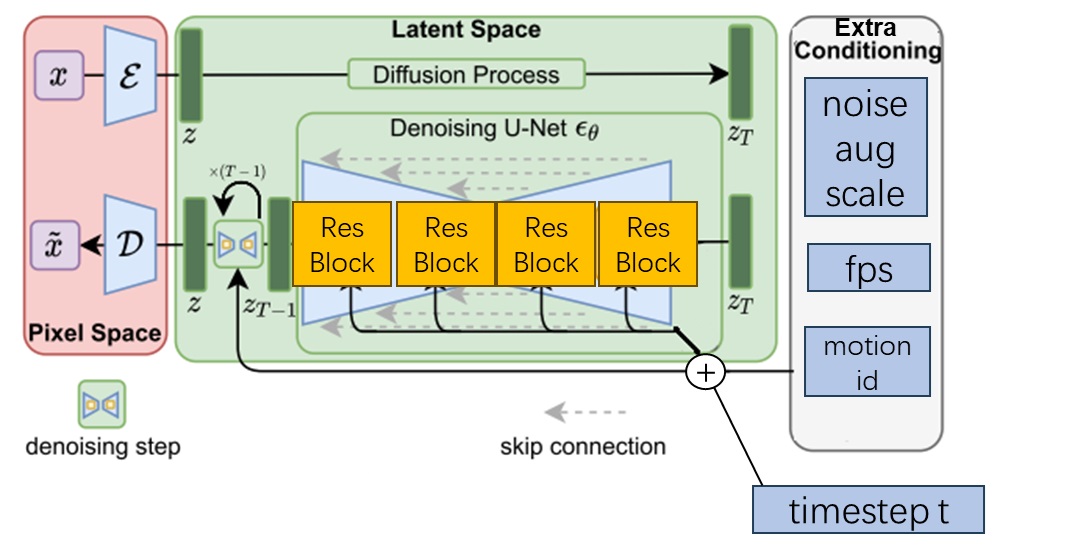
即使现在不完全理解这三种额外约束的意义也不要紧。稍后我们会在学习 U-Net 结构时看到这种额外约束是怎么添加进 U-Net 的,在学习采样流水线时了解这三种约束的意义。
总结一下,除了添加了少数模块外,SVD 和 SD 的整体架构一样,都是以去噪 U-Net 为核心的 LDM。除了原本扩散模型要求的噪声、去噪时刻这两种输入外,SVD 还加入了 4 种约束信息:约束图像(视频首帧)、噪声增强程度、帧率、运动程度。约束图像是最主要的约束信息,它会与噪声输入拼接,且输入进 U-Net 的交叉注意力层中。后三种额外约束会以和处理去噪时刻类似的方式输入进 U-Net 中。
去噪模型结构
接下来,我们来学习 SVD 的去噪模型的结构。在 Diffusers 中,一个扩散模型的参数、配置全部放在一个模型文件夹里,该文件夹的各个子文件夹存储了模型的各个模块,如自编码器、去噪模型、调度器等。我们可以在 https://huggingface.co/stabilityai/stable-video-diffusion-img2vid/tree/main 找到 SVD 的模型文件夹,或者访问我们本地下载好的模型文件夹。
SVD 的去噪 U-Net 放在模型文件夹的 unet 子文件夹里。通过阅读子文件夹里的 config.json,我们就能知道模型类的名字是什么,并知道初始化模型的参数有哪些。
1 | { |
通过在本地 Diffusers 库文件夹里搜索类名 UNetSpatioTemporalConditionModel,或者利用 IDE 的 Python 智能提示功能,在前文的示例脚本里跳转到 StableVideoDiffusionPipeline 所在文件,再跳转到 UNetSpatioTemporalConditionModel 所在文件,我们就能知道 SVD 的去噪 U-Net 类定义在 diffusers/models/unet_spatio_temporal_condition.py 里。我们可以对照位于 diffusers/models/unet_2d_condition.py 的 SD 的 2D U-Net 类 UNet2DConditionModel 来看一下 SVD 的 U-Net 有何不同。
先来看 __init__ 构造函数。SVD U-Net 几乎就是一个写死了许多参数的特化版 2D U-Net,其构造函数也基本上是 SD 2D U-Net 的构造函数的子集。比如 2D U-Net 允许用 act_fn 来指定模型的激活函数,默认为 "silu",而 SVD U-Net 直接把所有模块的激活函数写死成 "silu"。经过简化后,SVD U-Net 的构造函数可读性高了很多。我们从参数开始读起,逐一了解构造函数每一个参数的意义:
sample_size=None:隐空间图片边长。供其他代码调用,与 U-Net 无关。in_channels=8:输入通道数。out_channels=4: 输出通道数。down_block_types:每一大层下采样模块的类名。up_block_types:每一大层上采样模块的类名。block_out_channels = (320, 640, 1280, 1280):每一大层的通道数。addition_time_embed_dim=256: 每个额外约束的通道数。projection_class_embeddings_input_dim=768: 所有额外约束的通道数。layers_per_block=2: 每一大层有几个结构相同的模块。cross_attention_dim=1024: 交叉注意力层的通道数。transformer_layers_per_block=1: 每一大层的每一个模块里有几个 Transformer 层。num_attention_heads=(5, 10, 10, 20): 各大层多头注意力层的头数。num_frames=25: 训练时的帧数。供其他代码调用,与 U-Net 无关。
SVD U-Net 的参数基本和 SD 的一致,不同之处有:1)稍后我们会在采样流水线里看到,SVD 把图像约束拼接到了噪声图像上,所以整个噪声输入的通道数是原来的两倍,从 4 变为 8;2)多了一个给采样代码用的 num_frames 参数,它其实没有被 U-Net 用到。
我们再来大致过一下构造函数的实现细节。SVD U-Net 的整体结构和 2D U-Net 的几乎一致。数据先经过下采样模块,再经过中间模块,最后过上采样模块。下采样模块和上采样模块之间有短路连接。
1 | for i, down_block_type in enumerate(down_block_types): |
扩散模型还需要处理去噪时刻约束 $t$。U-Net 会先用正弦编码(Transformer 里的位置编码)time_proj 来将时刻转为向量,再用一系列线性层 time_embedding 预处理这个编码。该编码后续会输入进 U-Net 主体的每一个模块中。
1 | self.time_proj = Timesteps(block_out_channels[0], True, downscale_freq_shift=0) |
除了多数扩散模型都有的 U-Net 模块外,SVD 还加入了额外约束模块。如前文所述,对于能用一个实数表示的约束,可以使用和处理时刻类似的方式,先让其过位置编码层,再过线性层,最后把得到的输出编码和时刻编码加起来。所以,和这种额外约束相关的模块在代码里叫做 add_time。在 2D U-Net 里,额外约束是可选的。SD 没有用到额外约束。而 SVD 把额外约束设为了必选模块。稍后我们会在采样流水线里看到,SVD 将视频的帧率、运动程度、噪声增强强度作为了生成时的额外约束。这些约束都是用这种与时刻编码相加的形式实现的。1
2self.add_time_proj = Timesteps(addition_time_embed_dim, True, downscale_freq_shift=0)
self.add_embedding = TimestepEmbedding(projection_class_embeddings_input_dim, time_embed_dim)
构造函数的代码就看完了。在构造函数中,我们认识了 SVD U-Net 的各个模块,但对其工作原理或许还存在着些许疑惑。我们来模型的前向传播函数 forward 里看一下各个模块是怎么处理输入的。
看代码前,我们先回顾一下概念,整理一下 U-Net 的数据处理流程。下面是我之前给 SD U-Net 画的示意图。该图对 SVD 同样适用。和 SD 相比,SVD 的输入 x 不仅包括噪声图像(准确说是多个表示视频帧的图像),还包括作为约束的首帧图像; c 换成了首帧图像的 CLIP 编码;t 不仅包括时刻,还包括一些额外约束。
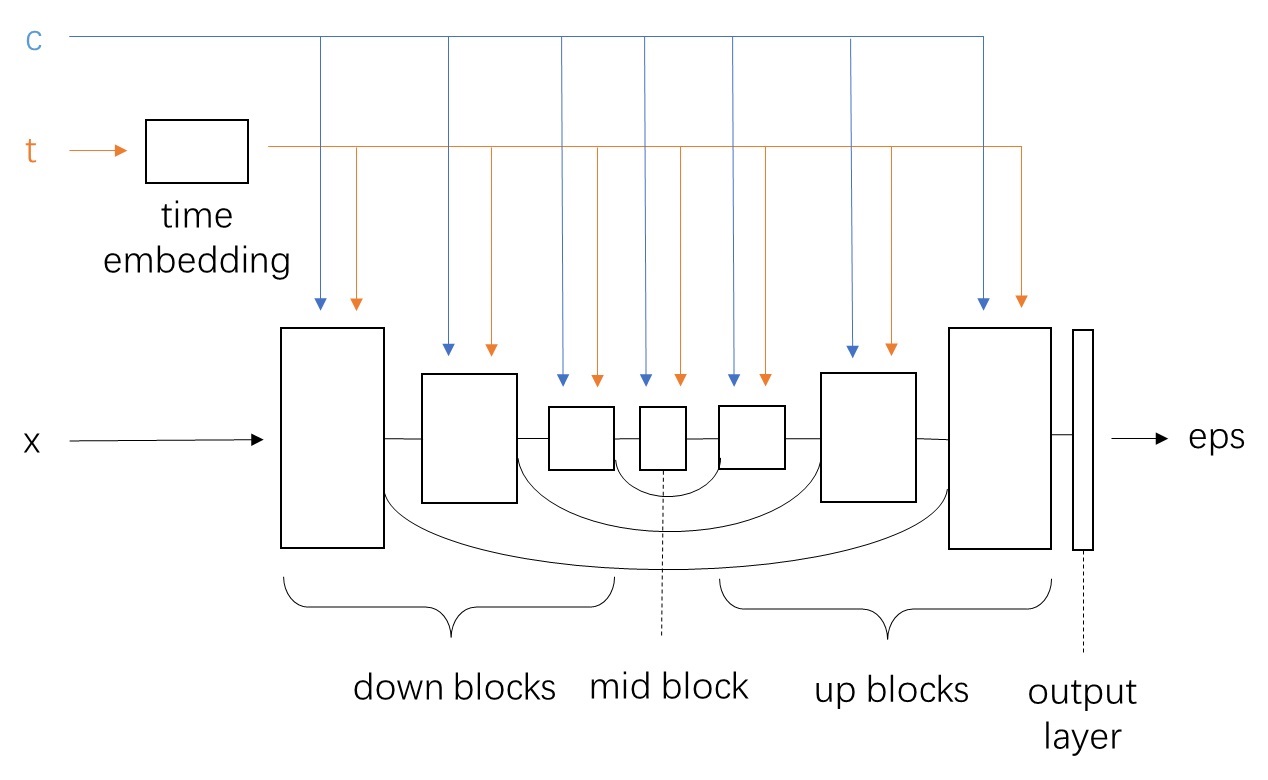
和上图所示的一样,SVD U-Net 的 forward 方法的输入包含图像 sample,时刻 timestep,交叉注意力层约束(图像编码) encoder_hidden_states , 额外约束 added_time_ids。
1 | def forward( |
方法首先会处理去噪时刻和额外参数,我们来看一下这两个输入是怎么拼到一起的。
做完一系列和形状相关的处理后,输入时刻 timestep 变成了 timesteps。随后,该变量会先过正弦编码(位置编码)层 time_proj,再过一些线性层 time_embedding,得到最后输入 U-Net 主体的时刻嵌入 emb。这两个模块的命名非常容易混淆,千万别弄反了。类似地,额外约束也是先过正弦编码层 add_time_proj,再过一些线性层 add_embedding,最后其输出 aug_emb 会加到 emb 上。当然,为了确保结果可以相加,time_embedding 和 add_time_proj 的输出通道数是相同的。
1 | # preprocessing |
这里有关额外约束的处理写得很差,逻辑也很难读懂。在构造函数里,额外约束的正弦编码层 add_time_proj 的输出通道数 addition_time_embed_dim 是 256, 线性模块 add_embedding 的输入通道数 projection_class_embeddings_input_dim 是 768。两个通道数不一样的模块是怎么接起来的?
1 | def __init__( |
原来,在下面这份模块前向传播代码中,added_time_ids 的形状是 [batch_size, 3]。其中的 3 表示有三个额外约束。做了 flatten() 再过 add_time_proj 后,可以得到形状为 [3 * batch_size, 256] 的正弦编码 time_embeds。之所以三个约束可以用同一个模块来处理,是因为正弦编码没有学习参数,对所有输入都会产生同样的输出。得到 time_embeds 后,再根据从输入噪声图像里得到的 batch_size,用 reshape 把 time_embeds 的形状变成 [batch_size, 768]。这样,time_embeds 就可以输入进 add_embedding 里了。 add_embedding 是有可学习参数的,三个约束必须分别处理。
1 | time_embeds = self.add_time_proj(added_time_ids.flatten()) |
这些代码不应该这样写的。当前的写法不仅可读性差,还不利于维护。比较好的写法是在构造函数里把输入参数从projection_class_embeddings_input_dim 改为 num_add_time,表示额外约束的数量。之后,把 add_embedding 的输入通道数改成 num_add_time * addition_time_embed_dim。这样,使用者不必手动设置合理的 add_embedding 的输入通道数(比如保证 768 必须是 256 的 3 倍),只设置有几个额外约束就行了。这样改了之后,为了提升可读性,还可以像下面那样把 reshape 里的那个 -1 写清楚来。Diffusers 采用这种比较混乱的写法,估计是因为这段代码是从 2D U-Net 里摘抄出来的。而原 2D U-Net 需要兼容更复杂的情况,所以 add_time_proj 和 add_embedding 的通道数需要分别指定。
1 | time_embeds = time_embeds.reshape((batch_size, -1)) |
预处理完时刻和额外约束后,方法还会修改所有输入的形状,使得它们第一维的长度都是 batch_size 乘视频帧数。正如我们在上一篇文章中学到的,为了兼容图像模型里的模块,我们要先把视频长度那一维和 batch 那一维合并,等到了和时序相关的模块再对视频长度那一维单独处理。
1 | # Flatten the batch and frames dimensions |
后面的代码就和 2D U-Net 的几乎一样了。数据依次经过下采样块、中间块、上采样块。下采样块的中间结果还会保存在栈 down_block_res_samples 里,作为上采样模块的额外输入。
1 | sample = self.conv_in(sample) |
光看 U-Net 类,我们还看不出 SVD 的 3D U-Net 和 2D U-Net 的区别。接下来,我们来看一看 U-Net 中某一个具体的模块是怎么实现的。由于 U-Net 下采样块、中间块、上采样块的结构是类似的,我们只挑某一大层的下采样模块类 CrossAttnDownBlockSpatioTemporal 来学习。
在 CrossAttnDownBlockSpatioTemporal 类中,我们可以看到 SVD U-Net 的每一个子模块都可以拆成残差卷积块和 Transformer 块。数据在经过子模块时,会先过残差块,再过 Transformer 块。我们来继续深究时序残差块类 SpatioTemporalResBlock 和时序 Transformer 块 TransformerSpatioTemporalModel 的实现细节。
1 | # __init__ |
在开始看代码之前,我们再回顾一下论文里有关 3D U-Net 块的介绍。SVD 的 U-Net 是从 Video LDM 的 U-Net 改过来的。下面的模块结构图源自 Video LDM 论文,我将其改成了能描述 SVD U-Net 块的图。图中红框里的模块表示在原 SD 2D U-Net 块的基础上新加入的模块。可以看出,SVD 实际上就是在原来的 2D 残差块后面加了一个 3D 卷积层,原空间注意力块后面加了一个时序注意力层。旧模块输出和新模块输出之间用一个比例 $\alpha$ 来线性混合。中间数据形状变换的细节我们已经在上篇文章里学过了,这篇文章里我们主要关心这些模块在代码里大概是怎么定义的。
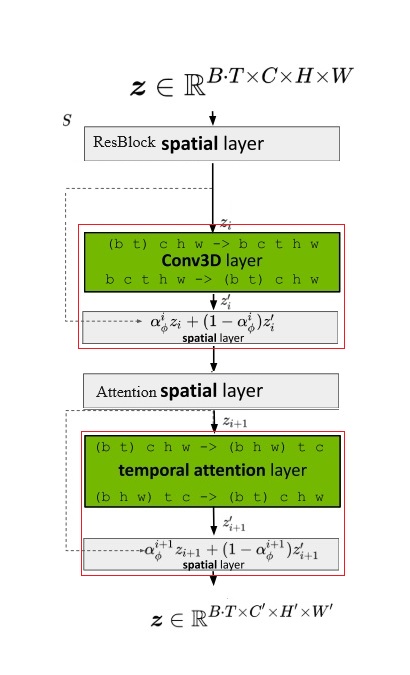
3D 残差块类 SpatioTemporalResBlock 在 diffusers/models/resnet.py 文件中。它有三个子模块,分别对应上文示意图中的 2D 残差块、时序残差块(3D 卷积)、混合模块。在运算时,旧模块的输出会缓存到
hidden_states_mix 中,新模块的输出为 hidden_states,二者最终会送入混合模块 time_mixer 做一个线性混合。
1 | class SpatioTemporalResBlock(nn.Module): |
ResnetBlock2D 是 SD 2D U-Net 的残差模块,我们在这篇文章里就不去学习它了。 时序残差块 TemporalResnetBlock 和 2D 残差块的结构几乎完全一致,唯一的区别在于 2D 卷积被换成了 3D 卷积。从代码中我们可以知道,这个模块是一个标准的残差块,数据会依次过两个卷积层,并在最后输出前与输入相加。扩散模型中的时刻约束 temb 会在数据过完第一个卷积层后,加到数据上。值得注意的是,虽然类里面的卷积层名字叫 3D 卷积,但实际上它的卷积核形状为 (3, 1, 1),这说明这个卷积层实际上只是一个时序维度上窗口大小为 3 的 1D 卷积层。
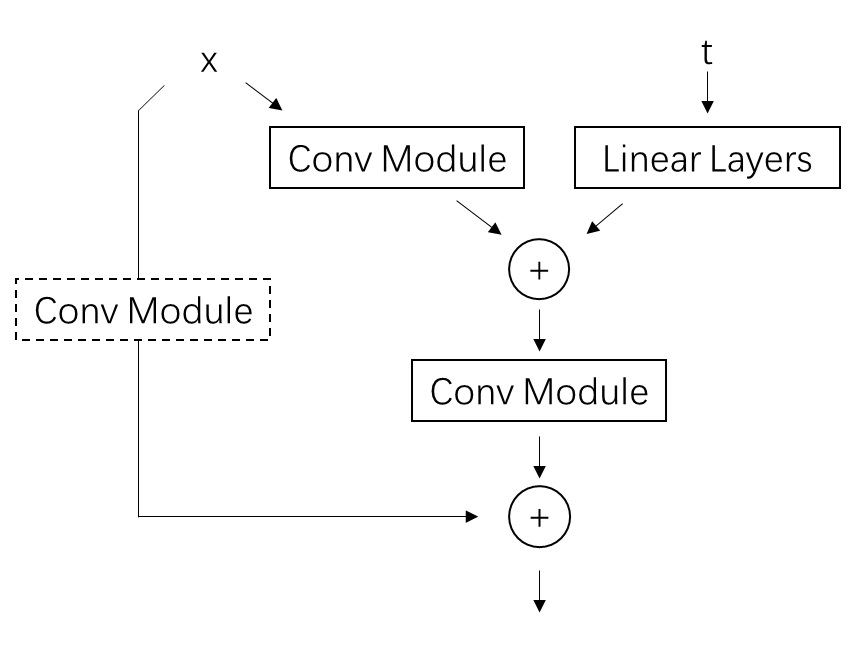
1 | class TemporalResnetBlock(nn.Module): |
混合模块 AlphaBlender 其实就只是定义了一个可学习的混合比例 mix_factor,之后用这个比例来混合空间层输出和时序层输出。
1 | class AlphaBlender(nn.Module): |
看完了3D 残差块 SpatioTemporalResBlock 的内容,我们接着来看 3D 注意力块 TransformerSpatioTemporalModel 的内容。TransformerSpatioTemporalModel 也主要由 2D Transformer 块 BasicTransformerBlock、时序 Transformer 块 TemporalBasicTransformerBlock 、混合模块组成 AlphaBlender。它们的连接方式和上面的残差块类似。时序 Transformer 块和普通 2D Transformer 块一样,都是有自注意力、交叉注意力、全连接层的标准 Transformer 模块,它们的区别只在于时序 Transformer 块对输入做形状变换的方式不同,会让数据在时序维度上做信息交互。这里我们就不去进一步深究它们的实现细节了。
1 | class TransformerSpatioTemporalModel(nn.Module): |
这个时序 Transformer 模块类有一个地方值得注意。我们知道,Transformer 模型本身是不知道输入数据的顺序的。无论是注意力层还是全连接层,它们都与顺序无关。为了让模型知道数据的先后顺序,比如在 NLP 里我们希望模型知道一句话里每个单词的前后顺序,我们会给输入数据加上位置编码。而有些时候我们觉得模型不用知道数据的先后顺序。比如在 SD 的 2D 图像 Transformer 块里,我们把每个像素当成一个 token,每个像素在 Transformer 块的运算方式是相同的,与其所在位置无关。而在处理视频时序的 Transformer 块中,知道视频每一帧的先后顺序看起来还是很重要的。所以,和 SD 的 2D Transformer 块不同,SVD 的时序 Transformer 块根据视频的帧号设置了位置编码,用和 NLP 里处理文本类似的方式处理视频。SVD 的时序 Transformer 类在构造函数里定义了生成位置编码的模块 TimestepEmbedding, Timesteps。在前向传播时,forward 方法会用 torch.arange(num_frames) 根据总帧数生成帧号列表,并经过两个模块得到最终的位置编码嵌入 emb。嵌入 emb 会在数据过时序 Transformer 块前与输入 hidden_states_mix 相加。
1 | class TransformerSpatioTemporalModel(nn.Module): |
到这里,我们就读完了 SVD U-Net 的主要代码。相比 SD U-Net,SVD U-Net 主要做了以下修改:
- 由于输入多了一张约束图像,输入通道数变为原来的两倍。
- 多加了三个和视频相关的额外约束。它们是通过和扩散模型的时刻嵌入相加输入进模型的。它们的命名通常与
add_time相关。 - 仿照 Video LDM 的结构设计,SVD 也在 2D 残差块后面加入了由 3D 卷积组成的时序残差块,在空间 Transformer 块后面加入了对时序维度做注意力的时序 Transformer 块。新旧模块的输出会以一个可学习的比例线性混合。
VAE 结构
SVD 不仅微调了 SD 的 U-Net,还微调了 VAE 的解码器,让输出视频在时序上更加连贯。由于更新 VAE 和更新 U-Net 的方法几乎一致,我们就来快速看一下 SVD 的时序 VAE 的结构,而跳过每个模块的更新细节。
通过阅读 VAE 的配置文件,我们可以知道时序 VAE 的类名为 AutoencoderKLTemporalDecoder,它位于文件 diffusers/models/autoencoders/autoencoder_kl_temporal_decoder.py 中。从它的构造函数里我们可以知道,时序 VAE 的编码器类是 Encoder,和 SD 的一样,只是解码器类从 Decoder 变成了 TemporalDecoder。我们来看一下这个新解码器类的代码做了哪些改动。
1 | class AutoencoderKLTemporalDecoder(ModelMixin, ConfigMixin): |
在 SD 中,VAE 和 U-Net 的组成模块是几乎一致的,二者的结构主要有三个区别:1)由于 VAE 的解码器和编码器是独立的,它们之间没有残差连接。而 U-Net 是一个整体,它的编码器(下采样块)和解码器(上采样块)之间有残差连接,以减少数据在下采样中的信息损失; 2)由于 VAE 中图像的尺寸较大,仅在 VAE 最深层图像尺寸为 64x64 时才有自注意力层。具体来说,这个自注意力层加到了 VAE 解码器的一开头,代码中相关模块称为 mid_block;3)VAE 仅有空间自注意力,而 SD U-Net 用了完整的 Transformer 块(包含自注意力层、交叉注意力层、全连接层)。由于 SD VAE 和 U-Net 结构上的相似性,SVD 的开发者直接把对 U-Net 的更新也搬到了 VAE 上来。
SVD VAE 解码器仅做了两项更新:1)将所有模块里的 2D 残差块都被换成了我们在上文中见过的 3D 残差块;2)在最终输出前加了一个 3D 卷积(时序维度上的 1D 卷积)。VAE 的自注意力层的结构并没有更新。更新 2D 残差块的方法和 U-Net 的是一致的。比如在新的上采样块类 UpBlockTemporalDecoder 中,我们就可以看到之前在新 U-Net 里看过的 3D 残差块类 SpatioTemporalResBlock 的身影。
1 |
|
采样流水线
看完了 U-Net 和 VAE 的代码后,我们来看整套 SVD 的采样代码。和其他方法一样,在 Diffusers 中,一套采样方法会用一个流水线类 (xxxPipeline)来表示。SVD 对应的流水线类叫做 StableVideoDiffusionPipeline。我们可以利用 IDE 的代码跳转功能,在本文开头的示例采样脚本中跳转至 StableVideoDiffusionPipeline 所在源文件 diffusers/pipelines/stable_video_diffusion/pipeline_stable_video_diffusion.py。
如示例脚本所示,使用流水线类时,可以将类实例 pipe 当成一个函数来用。这种用法实际上会调用实例的 __call__ 方法。所以,在阅读流水线类的代码时,我们可以先忽略其他部分,直接看 __call__ 方法。
1 | pipe = StableVideoDiffusionPipeline.from_pretrained(...) |
__call__ 的参数定义如下:
1 | def __call__( |
__call__ 的参数就是我们在使用 SVD 采样时能修改的参数,我们需要把其中的主要参数弄懂。各参数的解释如下:
image:SVD 会根据哪张图片生成视频。height, width: 生成视频的尺寸。如果输入图片与这个尺寸对不上,会将输入图片的尺寸调整为该尺寸。num_frames: 生成视频的帧数。SVD 1.0 版默认 14 帧,1.0-xt 版默认 25 帧。min_guidance_scale,max_guidance_scale: 使用 Classifiser-free Guidance (CFG) 的强度范围。SVD 用了一种特殊的设置 CFG 强度的机制,稍后我们会在采样代码里见到。fps:输出视频期望的帧率。SVD 的额外约束。实际上这个帧率肯定是不准的,只不过提高这个值可以让视频更平滑。motion_bucket_id: SVD 的额外约束。官方没有解释该值的原理,只说明了提高该值能让输出视频的运动更多。noise_aug_strength: 对输入图片添加的噪声强度。值越低输出视频越像原图。decode_chunk_size: 一次放几张图片进时序 VAE 做解码,用于在内存占用和效果之间取得一个平衡。按理说一次处理所有图片得到的视频连续性最好,但那样也会消耗过多的内存。num_videos_per_prompt: 对于每张输入图片 (prompt),输出几段视频。generator: PyTorch 的随机数生成器。如果想要手动控制生成中的随机种子,就手动设置这个变量。latents: 强制指定的扩散模型的初始高斯噪声。output_type: 输出图片格式,是 NumPy、PIL,还是 PyTorch。callback_on_step_end,callback_on_step_end_tensor_inputs用于在不修改原流水线代码的情况下向采样过程中添加额外的处理逻辑。学习代码的时候可以忽略。return_dict: 流水线是返回一个词典,还是像普通 Python 函数一样返回用元组表示的多个返回值。
大致搞清楚了输入参数的意义后,我们来看流水线的执行代码。一开始的代码都是在预处理输入,可以直接跳过。
1 | # 0. Default height and width to unet |
之后,代码开始预处理交叉注意力层的约束信息。在 SD 里,约束信息是文本,所以这一步会用 CLIP 文本编码器得到约束文本的嵌入。而 SVD 是一个图生视频模型,所以这一步会用 CLIP 图像编码器得到约束图像的嵌入。
1 | # 3. Encode input image |
代码还把额外约束帧率 fps 减了个一,因为训练的时候模型实际上输入的额外约束是 fps - 1。
1 | fps = fps - 1 |
接着,代码开始处理与噪声拼接的约束图像。回顾一下,SVD 的约束图像以两种形式输入进模型:一种是过 CLIP 图像编码器,以交叉注意力 K,V 的形式输入,其预处理如上部分的代码所示;另一种形式是与原去噪 U-Net 的噪声输入拼接,其预处理如当前这部分代码所示。
在预处理要拼接的图像时,代码会先调用预处理器 image_processor.preprocess,把其他格式的图像转成 PyTorch 的 Tensor 类型。之后,代码会随机生成一点高斯噪声,并把噪声根据噪声增强强度 noise_aug_strength 加到这张约束图像上。这种做法来自于之前有约束图像的扩散模型 Cascaded diffusion models。noise_aug_strength 稍后会作为额外约束输入进 U-Net 里,与去噪时刻的编码相加。
1 | image = self.image_processor.preprocess(image, height=height, width=width).to(device) |
加了这个噪声后,图像会过 VAE 的编码器,得到 image_latents。image_latents 会通过 repeat 操作复制成多份,并于稍后拼接到每一帧带噪图像上。注意,一般图像在过 VAE 的编码器后,要乘一个系数 vae.config.scaling_factor; 在过 VAE 的解码器前,要除以这个系数。然而,只有在这个地方,image_latents 没有乘系数。我个人觉得这是开发者的一个失误。当然,做不做这个操作对于模型来说区别不大,因为模型能很快学会这种系数上的差异。
1 | # 4. Encode input image using VAE |
下一步,代码会把三个额外约束拼接在一起,得到 added_time_ids。它会接入到 U-Net 中,与时刻编码加到一起。在训练时,帧率 fps 和 运动程度 motion_bucket_id 完全来自于数据集标注,而 noise_aug_strength 是可以随机设置的。在采样时,这三个参数都可以手动设置。
1 | # 5. Get Added Time IDs |
再下一步,代码会将采样的总步数 num_inference_steps 告知采样调度器 scheduler。这一步是 Diffusers API 的要求。
1 | # 6. Prepare timesteps |
然后,代码会随机生成初始高斯噪声。不同的随机噪声即对应不同的输出视频。
1 | # 7. Prepare latent variables |
开始采样前,SVD 对约束图像的强度做了一种很特殊的设定。在看代码之前,我们先回顾一下约束强度的意义。现在的扩散模型普遍使用了 CFG (Classifier-free Guidance) 技术,它允许我们在采样时灵活地调整模型和约束信息的相符程度。这个强度默认取 1.0。我们可以通过增大强度来提升模型的生成效果,比如在 SD 中,这个强度一般取 7.5,这代表模型会更加贴近输入文本。
而 SVD 中,约束信息为图像。开发者对视频的不同帧采用了不同的约束强度:首帧为 min_guidance_scale, 末帧为 max_guidance_scale。强度从首帧到末帧线性增加。默认情况下,约束强度的范围是 [1, 3]。
1 | # 8. Prepare guidance scale |
最后,就来到了扩散模型的去噪循环了。根据之前采样调度器返回的采样时刻列表 timesteps,代码从中取出去噪时刻,对纯噪声输入迭代去噪。
1 | num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order |
去噪迭代的一开始,代码会根据是否要执行 CFG 来决定是否要把输入额外复制一份。这是因为做 CFG 时,我们需要把同一个输入过两次去噪模型,一次带约束,一次不带约束。为了简化这个流程,我们可以直接把输入复制一遍,这样只要过一次去噪模型就能得到两个输出了。下一行的 scale_model_input 是 Diffusers 的 API 要求,可以忽略。
1 | # expand the latents if we are doing classifier free guidance |
接着,加了噪声、过了 VAE 解码器、没有乘系数的约束图像 image_latents 会与普通的噪声拼接到一起,作为模型的直接输入。
1 | # Concatenate image_latents over channels dimension |
准备好了所有输入后,代码调用 U-Net 对输入噪声图像去噪。输入包括直接输入 latent_model_input,去噪时刻 t,约束图像的 CLIP 嵌入 image_embeddings,三个额外约束的拼接 added_time_ids。
1 | # predict the noise residual |
去噪结束后,代码根据公式做 CFG。
1 | # perform guidance |
有了去噪的输出 noise_pred 还不够,我们还需要用一些比较复杂的公式计算才能得到下一时刻的噪声图像。这一切都被 Diffusers 封装进调度器里了。
1 | # compute the previous noisy sample x_t -> x_t-1 |
以上就是一步去噪迭代的主要内容。代码会反复执行去噪迭代。这后面除了下面这行会调用 VAE 解码器将隐空间的视频解码回真实视频外,没有其他重要代码了。
1 | frames = self.decode_latents(latents, num_frames, decode_chunk_size) |
总结
在这篇文章中,我们学习了图生视频模型 SVD 的模型结构和采样代码。整体上看,SVD 相较 SD 在模型上的修改不多,只是在原来的 2D 模块后面加了一些在时序维度上交互信息的卷积块和 Transformer 块。在学习时,我们应该着重关注 SVD 的采样流水线。SVD 使用拼接和交叉注意力两种方式添加了图像约束,并以与时刻编码相加的方式额外输入了三种约束信息。由于视频不同帧对于首帧的依赖情况不同,SVD 还使用了一种随帧号线性增长的 CFG 强度设置方式。