Diffusers 库为社区用户提供了多种扩散模型任务的训练脚本。每个脚本都平铺直叙,没有多余的封装,把训练的绝大多数细节都写在了一个脚本里。这种设计既能让入门用户在不阅读源码的前提下直接用脚本训练,又方便高级用户直接修改脚本。
可是,这种设计就是最好的吗?关于训练脚本的最佳设计风格,社区用户们往往各执一词。有人更喜欢更贴近 PyTorch 官方示例的写法,而有人会喜欢用 PyTorch Lightning 等封装度高、重复代码少的库。而在我看来,选择哪种风格的训练脚本,确实是个人喜好问题。但是,在开始使用训练脚本之前,我们要从细节入手,理解训练脚本到底要做哪些事。学懂了之后,不管是用别人的训练库,还是定制适合自己的训练脚本,都是很轻松的。不管怎么说,Diffusers 的这种训练脚本是一份很好的学习素材。
当然,我在用 Diffusers 的训练脚本时,发现一旦涉及多类任务的训练,比如既要能训练 Stable Diffusion,又要能训练 VAE,那么这份脚本就会用起来比较困难,而写两份训练脚本又会有很大的冗余。Diffusers 的训练脚本依然有改进的空间。
在这篇文章中,我会主要面向想系统性学习扩散模型训练框架的读者,先详细介绍 Diffusers 官方训练脚本,再分享我重构训练脚本的过程,使得脚本能够更好地兼容多类模型的训练。文章的末尾,我会展示几个简单的扩散模型训练实例。
在阅读本文时,建议大家用电脑端,一边看源代码一边读文章。「官方训练脚本细读」一节细节较多,初次阅读时可以快速浏览,看完「训练脚本内容总结」中的流程图,再回头仔细看一遍。
准备源代码
我们将以最简单的 DDPM 官方训练脚本 examples/unconditional_image_generation/train_unconditional.py 为例,学习训练脚本的通用写法。examples 文件夹在位于 Diffusers 官方 GitHub 仓库中,用 pip 安装的 Diffusers 可能没有这个文件夹,最好是手动 clone 官方仓库,再在本地查看这个文件夹。使用 Diffusers 训练时,可能还要安装其他库。官方在不同的训练教程里给了不同的安装指令,建议大家都安装上。
1 | cd examples/text_to_image |
我为本教程准备的脚本在仓库 https://github.com/SingleZombie/DiffusersExample 中。请 clone 这个仓库,再切换到 TrainingScript 目录下。train_official.py 是原官方训练脚本 train_unconditional.py,train_0.py 是第一次修改后的训练脚本
,train_1.py 是第二次修改后的训练脚本。
官方训练脚本细读
先拉到文件的最底部,我们能在这找到程序的入口。在 parse_args 函数中,脚本会用 argparse 库解析命令行参数,并将所有参数保存在 args 里。args 会传进 main 函数里。稍后我们看到所有 args. 打头的变量调用,都表明该变量来自于命令行参数。
1 | if __name__ == "__main__": |
接着,我们正式开始学习训练主函数。一开始,函数会配置 accelerate 库及日志记录器。
1 | logging_dir = os.path.join(args.output_dir, args.logging_dir) |
在配置日志的中途,函数插入了一段修改模型存取逻辑的代码。为了让我们阅读代码的顺序与实际运行顺序一致,我们等待会用到了这段代码时再回头来读。
1 | # `accelerate` 0.16.0 will have better support for customized saving |
跳过上面的代码,还是日志配置。
1 | # Make one log on every process with the configuration for debugging. |
之后其他版本的训练脚本会有一段设置随机种子的代码,我们给这份脚本补上。
1 | # If passed along, set the training seed now. |
接着,函数会创建输出文件夹。如果我们想把模型推送到在线仓库上,函数还会创建一个仓库。
这段代码还出现了一行比较重要的判断语句:if accelerator.is_main_process:。在多卡训练时,只有主进程会执行这个条件语句块里的内容。该判断在并行编程中十分重要。很多时候,比如在输出、存取模型时,我们只需要让一个进程执行操作就行了。这个时候就要用到这行判断语句。
1 | # Handle the repository creation |
准备完辅助工具后,函数开始准备模型。输入参数里的 model_config_name_or_path 表示预定义的模型配置文件。如果该配置文件不存在,则函数会用默认的配置创建一个 DDPM 的 U-Net 模型。在写我们自己的训练脚本时,我们需要在这个地方初始化我们需要的所有模型。比如训练 Stable Diffusion 时,除了 U-Net,需要在此处准备 VAE、CLIP 文本编码器。
1 | # Initialize the model |
这份脚本还帮我们写好了维护 EMA(指数移动平均)模型的功能。EMA 模型用于存储模型可学习的参数的局部平均值。有时 EMA 模型的效果会比原模型要好。
1 | # Create EMA for the model. |
此处函数还会根据 accelerate 配置自动设置模型的精度。
1 | weight_dtype = torch.float32 |
函数还会尝试启用 xformers 来提升 Attention 的效率。PyTorch 在 2.0 版本也加入了类似的 Attention 优化技术。如果你的显卡性能有限,且 PyTorch 版本小于 2.0,可以考虑使用 xformers。
1 | if args.enable_xformers_memory_efficient_attention: |
准备了 U-Net 后,函数会准备噪声调度器,即定义扩散模型的细节。
注意,扩散模型不是一个神经网络,而是一套定义了加噪、去噪公式的模型。扩散模型中需要一个去噪模型来去噪,去噪模型一般是一个神经网络。
1 | # Initialize the scheduler |
准备完所有扩散模型组件后,函数开始准备其他和训练相关的模块。其他版本的训练脚本会在这个地方加一段缓存梯度和自动放缩学习率的代码,我们给这份脚本补上。
1 | if args.gradient_checkpointing: |
函数先准备的训练模块是优化器。这里默认使用的优化器是 AdamW。
1 | optimizer = torch.optim.AdamW( |
函数随后会准备训练集。这个脚本用 HuggingFace 的 datasets 库来管理数据集。我们既可以读取在线数据集,也可以读取本地的图片文件夹数据集。自定义数据集的方法可以参考 https://huggingface.co/docs/datasets/v2.4.0/en/image_load#imagefolder 。
1 | if args.dataset_name is not None: |
有了数据集后,函数会继续准备 PyTorch 的 DataLoader。在这一步中,除了定义 DataLoader 外,我们还要编写数据预处理的方法。下面这段代码的编写顺序和执行顺序不同,我们按执行顺序来整理一遍下面的代码:
- 将预定义的预处理函数传给数据集对象
dataset.set_transform(transform_images)。在使用数据集里的数据时,才会调用这个函数预处理图像。 - 使用 PyTorch API 定义 DataLoader。
train_dataloader = ... - 每次用 DataLoader 获取数据时,一个数据词典
examples会被传入预处理函数transform_images。examples里既包含了图像数据,也包含了数据的各种标签。而对于无约束图像生成任务,我们只需要图像数据,因此可以直接通过词典的"image"键得到 PIL 格式的图像数据。用convert("RGB")把图像转成三通道后,该 PIL 图像会被传入预处理流水线。 - 图像预处理流水线
augmentations是用 Torchvision 里的transformAPI 定义的。默认的流水线包括短边缩放至指定分辨率、按分辨率裁剪、随机反转、归一化。 - 处理过的数据会被存到词典的
"input"键里。
1 | # Preprocessing the datasets and DataLoaders creation. |
在准备工作的最后,函数会准备学习率调度器。
1 | # Initialize the learning rate scheduler |
准备完了所有模块,函数会调用 accelerate 库来把所有模块变成适合并行训练的模块。
1 | model, optimizer, train_dataloader, lr_scheduler = accelerator.prepare( |
之后函数还会用 accelerate 库配置训练日志。默认情况下日志名 run 由当前脚本名决定。如果不想让之前的日志被覆盖的话,可以让日志名 run 由当前的时间决定。
1 | if accelerator.is_main_process: |
马上就要开始训练了。在此之前,函数会准备全局变量并记录日志。注意,这里函数会算一次总的 batch 数,它由输入 batch 数、进程数(显卡数)、梯度累计步数共同决定。梯度累计是一种用较少的显存实现大 batch 训练的技术。使用这项技术时,训练梯度不会每步优化,而是累计了若干步后再优化。
1 | total_batch_size = args.train_batch_size * \ |
在开始训练前,如果设置了 args.resume_from_checkpoint,则函数会读取之前训练过的权重。负责读取训练权重的函数是 load_state。
1 | if args.resume_from_checkpoint: |
在每个 epoch 中,函数会重置进度条。接着,函数会进入每一个 batch 的训练迭代。
1 | # Train! |
如果是继续训练的话,训练开始之前会更新当前的步数 step。
1 | # Skip steps until we reach the resumed step |
训练的一开始,函数会从数据的 "input" 键里取出图像数据。此处的键名是我们之前在数据预处理函数 transform_images 里写的。
1 | clean_images = batch["input"].to(weight_dtype) |
之后函数会设置扩散模型训练中的其他变量,包含随机噪声、时刻。由于本文的重点并不是介绍扩散模型的原理,这段代码我们就快速略过。
1 | noise = torch.randn(...) |
接下来,函数会用去噪网络做前向传播。为了让模型能正确累计梯度,我们要用 with accelerator.accumulate(model): 把模型调用与反向传播的逻辑包起来。在这段代码中,我们会先得到模型的输出 model_output,再根据扩散模型得到损失函数 loss,最后用 accelerate 库的 API accelerator 代替原来 PyTorch API 来完成反向传播、梯度裁剪,并完成参数更新、学习率调度器更新、优化器更新。
1 | with accelerator.accumulate(model): |
确保一步训练结束后,函数会更新和步数相关的变量。
1 | if accelerator.sync_gradients: |
在这个地方,函数还会尝试保存模型。默认情况下,每 args.checkpointing_steps 步保存一次中间结果。确认要保存后,函数会算出当前的保存点名称,并根据最大保存点数 checkpoints_total_limit 决定是否要删除以前的保存点。做完准备后,函数会调用 save_state 保存当前训练时的所有中间变量。
1 | f accelerator.is_main_process: |
在这个地方,主函数开头设置的存取模型回调函数终于派上用场了。在调用 save_state 时,会自动触发下面的回调函数来保存模型。如果不加下面的代码,所有模型默认会以 .safetensor 的形式存下来。而用了下面的代码后,模型能够被 save_pretrained 存进一个文件夹里,就像其他标准 Diffusers 模型一样。
这里的输入参数
models来自于之前的accelerator.prepare,感兴趣可以去阅读文档或源码。
1 | def save_model_hook(models, weights, output_dir): |
与上面的这段代码对应,脚本还提供了读取文件的回调函数。它会在继续中断的训练后调用 load_state 时被调用。
1 | def load_model_hook(models, input_dir): |
两个回调函数需要用下面的代码来设置。
1 | accelerator.register_save_state_pre_hook(save_model_hook) |
回到最新的代码处。训练迭代的末尾,脚本会记录当前步的日志。
1 | logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0], "step": global_step} |
执行完了一个 epoch 后,脚本调用 accelerate API 保证所有进程均训练完毕。
1 | progress_bar.close() |
此处脚本可能会在主进程中验证模型或保存模型。如果当前是最后一个 epoch,或者达到了配置指定的验证/保存时刻,脚本就会执行验证/保存。
1 | if accelerator.is_main_process: |
脚本默认的验证方法是随机生成图片,并用日志库保存图片。生成图片的方法是使用标准 Diffusers 采样流水线 DDPMPipeline。由于此时模型 model 可能被包裹成了一个用于多卡训练的 PyTorch 模块,需要用相关 API 把 model 解包成普通 PyTorch 模块 unet。如果使用了 EMA 模型,为了避免对 EMA 模型的干扰,此处需要先保存 EMA 模型参数,采样结束再还原参数。
1 | if epoch % args.save_images_epochs == 0 or epoch == args.num_epochs - 1: |
在保存模型时,脚本同样会先用去噪模型 model 构建一个流水线,再调用流水线的保存方法 save_pretrained 将扩散模型的所有组件(去噪模型、噪声调度器)保存下来。
1 | if epoch % args.save_model_epochs == 0 or epoch == args.num_epochs - 1: |
一个 epoch 训练的代码就到此结束了。所有 epoch 的训练结束后,脚本调用 API 结束训练。这个 API 会自动关闭所有的日志库。训练代码到这里也就结束了。
1 | accelerator.end_training() |
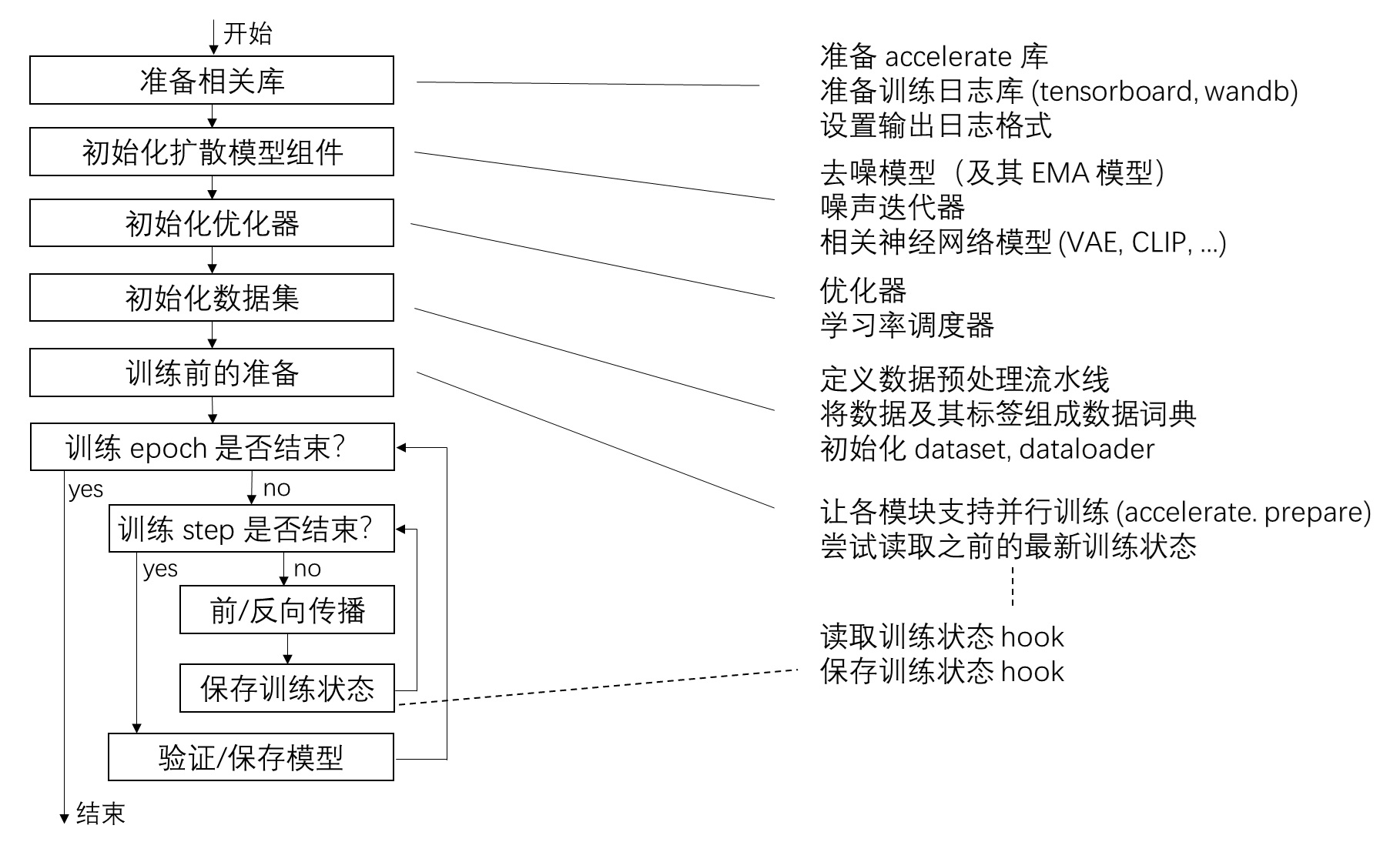
训练脚本内容总结
大概熟悉了一遍这份训练脚本后,我们可以用下面的流程图概括训练脚本的执行顺序和主要内容。
去掉命令行参数
我不喜欢用命令行参数传训练参数,而喜欢把训练参数写进配置文件里,理由有:
- 我一般会直接在命令行里手敲命令。如果命令行参数过多,我则会把要运行的命令及其参数保存在某文件里。这样还不如把参数写在另外的文件里。
- 将大量参数藏在一个词典
args里,而不是把所有需用的参数在某处定义好,是一种很差的编程方式。各个参数将难以追踪。
在正式重构脚本之前,我做的第一步是去掉脚本中原来的命令行参数,将所有参数先塞进一个数据类里面。脚本将只留一个命令行参数,表示参数配置文件的路径。具体做法如下:
先编写一个存命令行参数的数据类。这个类是一个 Python 的 dataclass。Python 中 dataclass 是一种专门用来放数据的类。定义数据类时,我们只需要定义类中所有数据的类型及默认值,不需要编写任何方法。初始化数据类时,我们只需要传一个词典或列表。一个示例如下(示例来源 https://www.geeksforgeeks.org/understanding-python-dataclasses/):1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25from dataclasses import dataclass
# A class for holding an employees content
class employee:
# Attributes Declaration
# using Type Hints
name: str
emp_id: str
age: int
city: str
emp1 = employee("Satyam", "ksatyam858", 21, 'Patna')
emp2 = employee("Anurag", "au23", 28, 'Delhi')
emp3 = employee({"name": "Satyam",
"emp_id": "ksatyam858",
"age": 21,
"city": 'Patna'})
print("employee object are :")
print(emp1)
print(emp2)
print(emp3)
我们可以用 dataclass 编写一个存储所有命令行参数的数据类,该类开头内容如下:
1 | from dataclasses import dataclass |
之后在训练脚本里,我们可以把旧的命令行参数全删了,再加一个命令行参数 cfg,表示训练配置文件的路径。我们可以用 omegaconf 打开这个配置文件,得到一个词典 data_dict,再用这个词典构建配置文件 cfg。接下来,只需要把原来代码里所有 args. 改成 cfg. 就行了。
1 | from omegaconf import OmegaConf |
第一次修改过的训练脚本为 train_0.py,配置文件类在 training_cfg_0.py 里,示例配置文件为 cfg_0.json,一个简单 DDPM 模型配置写在 unet_cfg 目录里。可以直接运行下面的命令测试此训练脚本。
1 | python train_0.py cfg_0.json |
在配置文件里,我们只需要改少量的训练参数就行了。如果想知道还有哪些参数可以改,可以去查看 training_cfg_0.py 文件。
1 | { |
读者感兴趣的话也可以尝试这样改一遍代码。这样做会强迫自己读一遍训练脚本,让自己更熟悉这份代码。
适配多种任务的训练脚本
如果只是训练一种任务,Diffusers 的这种训练脚本还算好用。但如果我们想用完全相同的训练流程训练多种任务,这种脚本的弊端就暴露出来了:
- 各任务的官方示例脚本本身就不完全统一。比如有的训练脚本支持设置随机种子,有的不支持。
- 一旦想修改训练过程,就得同时修改所有任务的脚本。这不符合编程中「代码复用」的思想。
为此,我想重构一下官方训练脚本,将训练流程和每种任务的具体训练过程解耦开,让一份训练脚本能够被多种任务使用。于是,我又从头过了一遍训练脚本,将代码分成两类:所有任务都会用到的代码、仅 DDPM 训练会用到的代码。如下图所示,我用红字表示了训练脚本中应该由具体任务决定的部分。
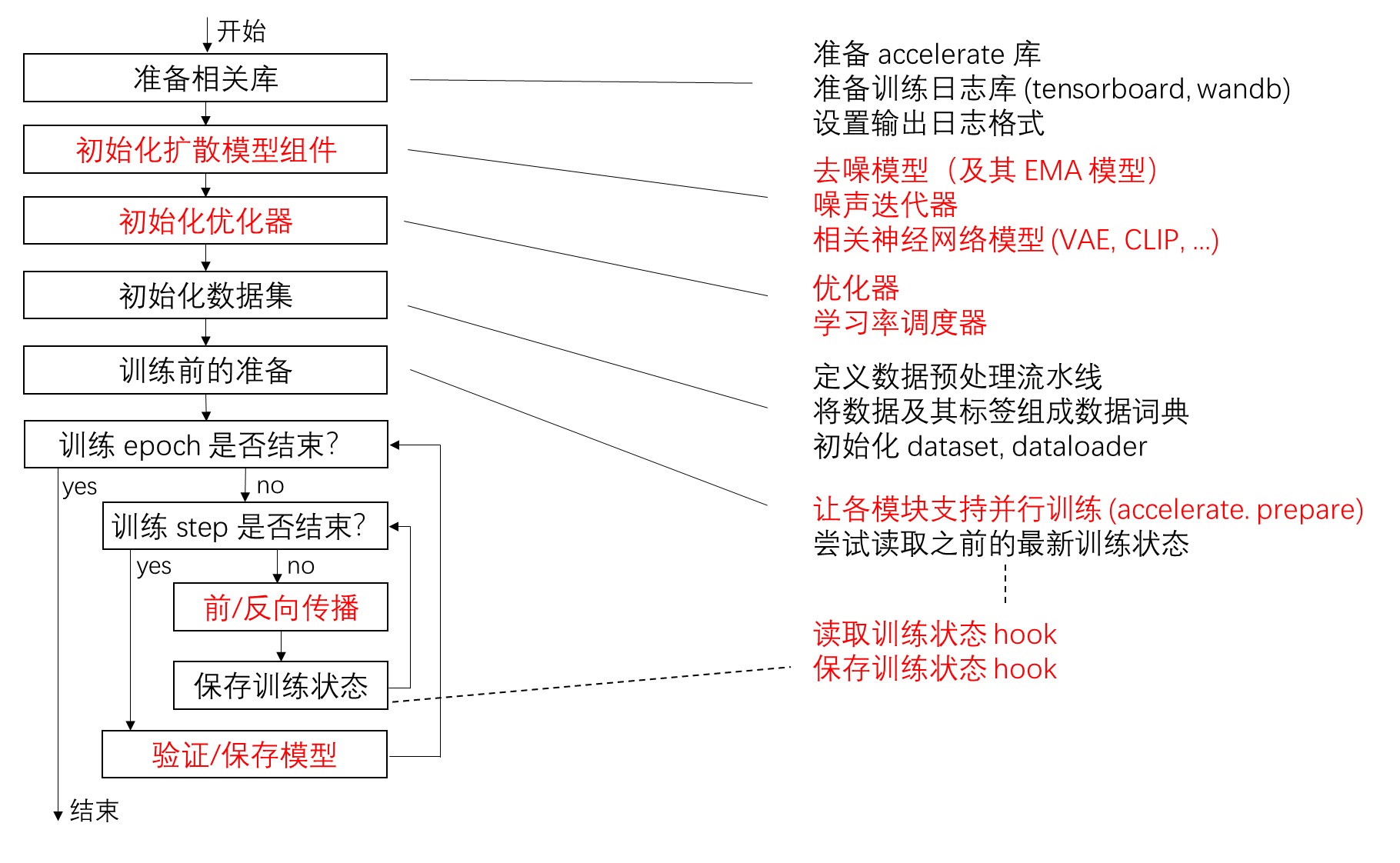
根据这个划分规则,我将仅和 DDPM 相关的代码剥离出来,并用一个描述某具体任务的训练器接口类的方法调用代替原有代码。这样,每次换一个训练任务,只需要重新实现一个训练器类就行了。如下图所示,原流程图中所有红字的内容都可以由接口类的方法代替。对于不同任务,我们需要实现不同的训练器类。
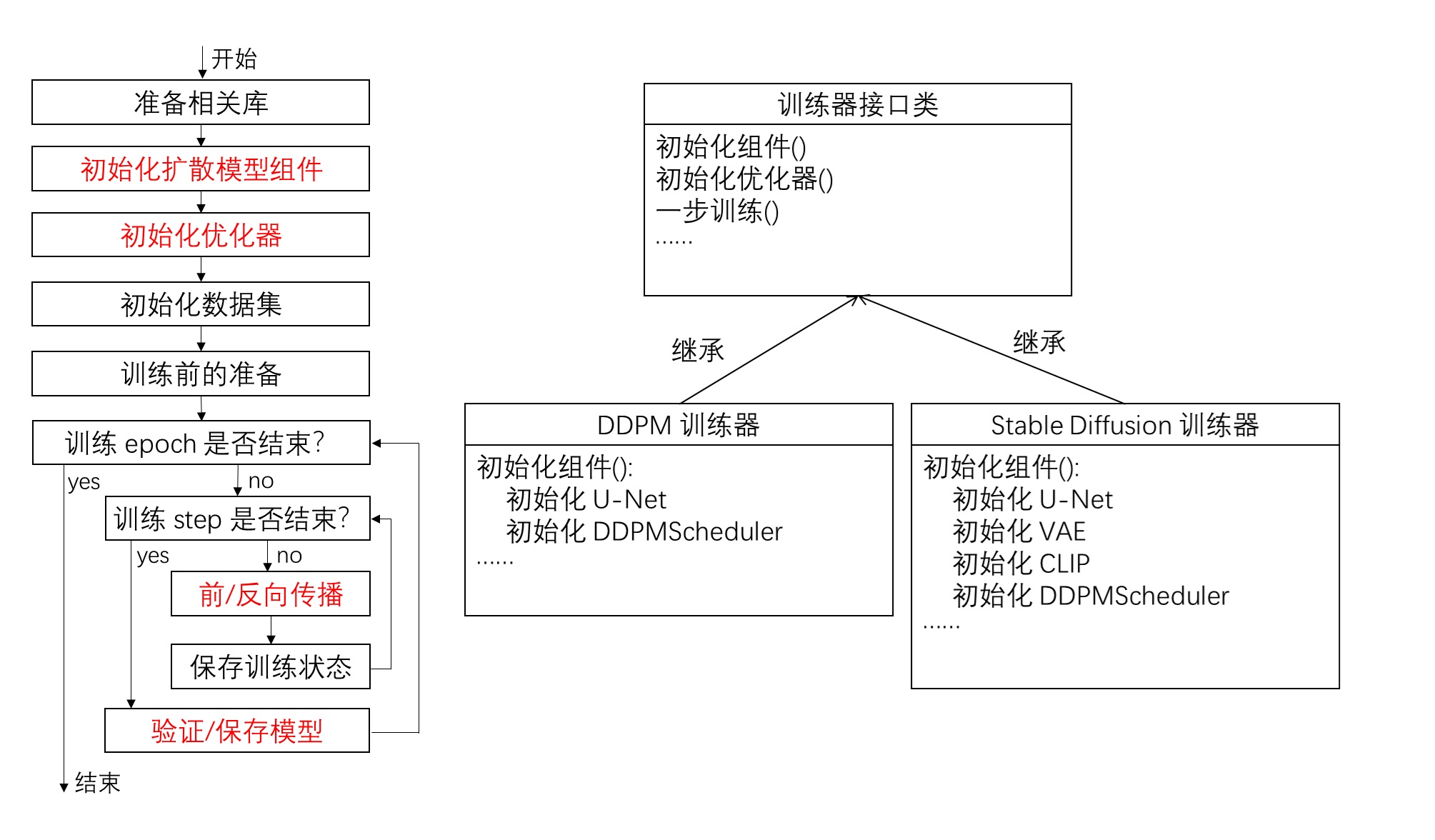
具体在代码中,我写了一个接口类 Trainer。
1 | class Trainer(metaclass=ABCMeta): |
根据类型名和初始化参数可以创建具体的训练器。
1 | def create_trainer(type, weight_dtype, accelerator, logger, cfg_dict) -> Trainer: |
原来训练脚本里的具体训练逻辑被接口类方法调用代替。比如:
1 | # old |
原来仅和 DDPM 训练相关的代码全被我搬到了 DDPMTrainer 类中。与之对应,除了代码需要搬走外,原配置文件里的数据也需要搬走。我在 DDPMTrainer 类里加了一个 DDPMTrainingConfig 数据类,用来存对应的配置数据。
1 |
|
因此,我们需要用稍微复杂一点的方式来创建配置文件。现在全局训练配置和任务配置放在两组配置里。配置文件最外层除 "base" 外的那个键表明了训练器的类型。
1 | { |
1 | __TYPE_CLS_DICT = { |
这样改完过后,训练脚本开头也需要稍作更改,其他地方保持不变。
1 | from training_cfg_1 import BaseTrainingConfig, load_training_config |
这次修改过的训练脚本为 train_1.py,配置文件类在 training_cfg_1.py 里,DDPM 训练器在 TrainingScript/ddpm_trainer.py 里,示例配置文件为 cfg_1.json。可以直接运行下面的命令测试此训练脚本。
1 | python train_1.py cfg_1.json |
运行这一版或者上一版的训练脚本后,我们都能很快训练完一个 MNIST 上的 DDPM 模型。从训练可视化结果可以看出,代码重构大概是没有出错,模型能正确生成图片。

对训练器类的程序设计思路感兴趣的话,欢迎阅读附录。
添加新的训练任务
为了验证这套新代码的可拓展性,我仿照 Diffusers 官方 SD LoRA 训练脚本 examples/text_to_image/train_text_to_image_lora.py,快速实现了一个 SD LoRA 训练器类。这个类在 sd_lora_trainer.py 文件里。
我来简单介绍添加新训练任务的过程。要添加新训练任务,要修改三处:
- 创建新文件,在文件里定义配置数据类及实现训练器类。
- 在
trainer.py里导入新训练器类。 - 在
training_cfg_1.py里导入新配置数据类。
先来看较简单的第二处和第三处修改。导入新训练器类只需要加一行 import 和一条词典项。
1 | def create_trainer(type, weight_dtype, accelerator, logger, cfg_dict) -> Trainer: |
导入新配置数据类也一样,一行 import 和一项词典项。
1 | from sd_lora_trainer import LoraTrainingConfig |
而实现一个训练器类会比较繁琐。我是先把 DDPM 训练器类复制了过来,在此基础上进行修改。由于 SD LoRA 训练器有官方训练脚本作为参考,我还是和之前实现 DDPM 训练器一样,从官方训练脚本里抠出对应代码,将其填入训练器类方法里。比如在初始化模块时,我们不仅需要初始化 U-Net,还有 VAE 等模块。在初始化优化器时,应该只优化 LoRA 参数。
1 | class LoraTrainer(Trainer): |
SD LoRA 训练器类在 sd_lora_trainer.py 文件里,对应配置文件为 cfg_lora.json。用下面的代码即可尝试 LoRA 训练。
1 | python train_1.py cfg_lora.json |
可能是 MNIST 数据集的图片太小了,而 SD 又是为较大的图片设计的,又或是 LoRA 的拟合能力有限,生成的效果不是很好。但可以看出,SD LoRA 学到了 MNIST 的图片风格。

就我自己使用下来,添加一个新的训练任务还是非常轻松的。我可以只关心初始化模型、训练、验证等实现细节,而不用关心那些通用的训练代码。当然,这份通用训练脚本还不够强大,还不能处理更复杂的数据集。SD LoRA 其实需要一个带文本标注的数据集,但由于我只是想测试添加新训练器的难度,就没有去改数据集,只是默认用了空文本来训练 LoRA。
总结
我自己在使用 Diffusers 训练脚本时,发现这种训练脚本难以适配多任务训练,于是重构了一份拓展性更强的训练脚本。在这篇文章中,我先是介绍了 Diffusers 训练脚本的通用框架,再分享了我改写脚本的过程。相信读者在读完本文后,不仅能够熟悉 Diffusers 训练脚本的具体原理,还能够动手修改它,或者基于我的这一版改进脚本,编写一份适合自己的训练脚本。
我重构的这套训练器也没有太多封装,在维持 Diffusers 那种平铺直叙风格的同时,将每种训练任务独有的代码、数据搬了出来,让开发者专注于编写新的逻辑。我没怎么用过别的训练框架,不太好直接对比。但至少相比于 PyTorch Lightning 那种模型和训练逻辑写在同一个类里的写法,我更认可 Diffusers 这种将模型结构和训练、采样分离的设计。这套框架的训练器也只有训练的逻辑,不会掺杂其他逻辑。
本文的代码链接为 https://github.com/SingleZombie/DiffusersExample/tree/main/TrainingScript
注意,这份代码是我随手写的,只测试了简单的训练命令。如果发现 bug,欢迎提 issue。这份代码仅供本文教学使用,功能有限,以后我会在其他地方更新这份代码。另外,以后我写其他训练教程时也会复用这套代码。
附录:训练器程序设计思路
在设计训练器接口类的接口时,其实我没有做多少主观设计,基本上都是按照一些设计原则,机械地将原来的训练脚本进行重构。我也不知道这些原则是怎么想出来的,只是根据我多年写代码的经验,我感觉按照这些规则做可以保证训练脚本和训练器之间耦合度更低,易于拓展。这些原则有:
- 如果在另一项任务里这行代码会变动,则这项代码应写入训练器类。
- 如果某一数据的调用全部都被放入了训练器类里,那么这个数据应该是训练器类的成员变量。如果该数据来自配置文件,则将该数据的定义从全局配置移入训练器配置。
- 如果某数据既要在训练脚本中使用,又要在训练器类里使用,则在训练脚本中初始化该数据,并以初始化参数或者接口参数两种方式将数据传入训练器。传入方式由数据被确定的时刻决定。比如脚本一开始就初始化好的日志对象应该作为初始化参数,而一些中途计算的当前 batch 数等参数应该作为接口参数。
- 原则上,训练脚本不从数据类里获取数据。
根据这些原则,在设计训练器接口类时,我并没有一开始就定下有哪些接口、接口的参数分别是什么,而是一边搬运代码,一边根据代码的实际内容动态地编写接口类。比如一开始,我的接口类构造函数并没有加入日志库类型。
1 | class Trainer(metaclass=ABCMeta): |
后来写训练器验证方法时,我发现这里必须要获取日志类的类型,不得已在构造函数里多加了一个参数。1
2
3
4
5
6def validate(self, epoch, global_step):
...
if self.logger == "tensorboard":
...
def __init__(self, weight_dtype, accelerator, logger, cfg):
原则 3 和原则 4 本质上是将训练脚本也看成一个对象。所有数据要么属于训练脚本,要么属于训练类。原则 4 不从训练器里获取信息,某种程度上体现了面向对象中的封装性,不让训练器去改训练脚本里的数据。我尽可能地遵守了原则 4,但只有一处例外。在调用 accelerate.prapare 后,train_dataloader 在训练器里发生了更改。而 train_dataloader 其实是属于训练脚本的。没办法,这里只能去训练器里获取一次数据。我没来得及仔细研究,说不定 accelerate.prapare 可以多次调用,这样我就能让训练脚本自己维护 train_dataloader。
1 | trainer.prepare_modules() |
这样看下来,这份代码框架在各种角度上都有很大的改进空间。以后我会来慢慢改进这份代码。就目前的设计,训练中整体逻辑、数据集、训练器三部分应该是相互独立的。数据集我还没有单独拿出来写。应该至少实现纯图像、带文本标注图像这两种数据集。
这次重构之后,我也有一些程序设计上的体会。重构代码比从头做程序设计要简单很多。重构只需要根据已有代码,设计出一套更合理的逻辑,像我这样按照某些原则,无脑地修改代码就行了。而程序设计需要考虑未知的情况,为未来可能加入的功能铺路。也正因为从头设计更难,有时会出现设计过度或者设计不足的情况。感觉更合理的开发方式是从头设计与重构交替进行。