前几个月,推出了著名文生图模型 Stable Diffusion 的 Stability AI 公司曝出了核心团队集体离职的消息。一时间,AI 从业者们议论纷纷,不知道这究竟是团队出现了矛盾,还是这些员工觉得文生图模型做下去没有前途了。而近期,该核心团队重新组建的创业团队 Black Forest Labs(黑森林实验室)带着名为 FLUX.1 的文生图模型「复仇归来」。FLUX.1 受到了用户的广泛好评,让人们期盼更强开源文生图模型的热情得以延续。
Black Forest Labs 的成员基本上都是 Stable Diffusion 3 的作者,其中三名元老级成员还是 Stable Diffusion 论文的作者。同时,FLUX.1 也是一个在 Stable Diffusion 3 架构上做改进的模型。不管从哪个角度,FLUX.1 都称得上是Stable Diffusion 3 的「精神续作」。秉承着此前的开源精神,FLUX.1 也在上线之始就为社区开放了源代码和模型权重。不过,配套的技术论文并没能及时发布,想要了解 FLUX.1 技术细节的用户恐怕还得等上一阵子。为了尽快搞清楚 FLUX.1 相较 Stable Diffusion 3 做了哪些改进,我直接去细读了 FLUX.1 的源码。在这篇文章中,按照惯例,我将主要从源码层面上分享 FLUX.1 中已知的科研创新,做一个官方论文发布前的前瞻解读,而不会评测 FLUX.1 的图像生成效果。
具体来说,我会介绍 FLUX.1 中的以下改动:
- 略微变动的图块化策略
- 不使用 Classifier-Free Guidance 的指引蒸馏
- 为不同分辨率图像调整流匹配噪声调度
- 用二维旋转式位置编码 (RoPE) 代替二维正弦位置编码
- 在原 Stable Diffusion 3 双流 Transformer 块后添加并行单流 Transformer 块
我会先简单介绍 FLUX.1 的官方公告及 Diffusers 版使用示例,再按照我读代码的逻辑,从熟悉整个代码框架,到深究每一处创新的代码细节,最后分享我对于 FLUX.1 科研改进上的分析。对源码不感兴趣的读者,可以跳过通读代码框架章节,或者直接阅读感兴趣的那部分改动。想看省流版文章的读者,可以直接跳到结尾看总结。
建议读者在学习 Flux.1 前熟悉 Stable Diffusion 3。欢迎参考我之前写的文章:Stable Diffusion 3 论文及源码概览。
模型简介与 Diffusers 示例脚本
在正式阅读源码前,我们先来看一下官方推文(https://blackforestlabs.ai/announcing-black-forest-labs/ )中有关 FLUX.1 的简介,并在 Diffusers 中跑通 FLUX.1 的图像生成示例脚本。
据官方介绍,FLUX.1 是一套文生图模型。它有三个变体(variant,可以理解成结构相似或相同,但权重不同的几个模型):
- FLUX.1 [pro]: FLUX.1 系列的最强模型,只能通过付费的 API 或者在线平台使用。
- FLUX.1 [dev]:FLUX.1 [pro] 的指引蒸馏(guidance-distilled)模型,质量与文本匹配度与原模型相近,运行时更高效。
- FLUX.1 [schnell]:为本地开发和个人使用而裁剪过的本系列最快模型。据 Diffusers 中的文档介绍,这是一个 Timestep-distilled(时间戳蒸馏)的模型,因此仅需 1~4 步就可以完成生成。无法设置指引强度。
官方对这些模型的详细介绍少之又少。FLUX.1 [dev] 用到的指引蒸馏技术似乎来自论文 On Distillation of Guided Diffusion Models,其目标是让模型直接学习 Classifier-Free Guidance (CFG) 的生成结果,使得模型一次输出之前要运行两次才能得到的指引生成结果,节约一半的运行时间。官方也没有讲 FLUX.1 [schnell] 的蒸馏细节,似乎它是从 FLUX.1 [dev] 中用扩散模型加速蒸馏手段得到的模型。因此,FLUX.1 [schnell] 不仅能一次输出有指引的生成结果,还能在极少的采样步数里完成生成。
官方推文中还说,FLUX.1 的生成神经网络基于 Stable Diffusion 3 的 MMDiT 架构和并行的 DiT 块,参数量扩大至 120 亿。生成模型是根据流匹配(flow matching)推导的扩散模型。为了提升性能与效率,模型新引入了旋转式位置编码 (RoPE) 和并行注意力层。
这段话这么长,还把并行注意力说了两遍,其实没有多少新东西。说白了,FLUX.1 就是在 Stable Diffusion 3 的基础上,加了 RoPE 和并行注意力层。官方推文到这里就没有其他有关模型细节的介绍了。FLUX.1 具体做了哪些改动,我们直接去源码里看。
FLUX.1 的官方仓库是 https://github.com/black-forest-labs/flux 。相比 Stable Diffusion 那个臃肿杂乱的 generative-models 仓库,这个仓库的代码要简洁很多。不过,我还是推荐使用 Diffusers 框架来运行 FLUX.1。
Diffusers 中运行 FLUX.1 的官方文档为 https://huggingface.co/docs/diffusers/main/en/api/pipelines/flux 。目前(2024 年 8 月 11 日),相关代码还在 Diffusers 的在线主分支里进行开发,并没有集成进 pip 版的 Diffusers 里。因此,要在 Diffusers 中使用 FLUX,必须要从源码安装 Diffusers:
1 | git clone https://github.com/huggingface/diffusers.git |
安装完毕后,我们可以随便新建一个 python 脚本,填入以下的官方示例代码。在能够连通 Hugging Face 的环境中运行此脚本的话,脚本会自动下载模型并把生成结果保存在 image.png 中。注意,FLUX.1 的神经网络很大,显存占用极高,可能至少需要在 RTX 3090 同等级的显卡上运行。在示例代码中,我还改了一行,使用 pipe.enable_sequential_cpu_offload() 让模型把更多参数临时放到 CPU 上,避免显存不够。经测试,改了这一行后,FLUX.1 才勉强能在显存为 24G 的 RTX 3090 上运行。
1 | import torch |
由于随机数是固定的,运行后,我们应该总能得到这样的图片:

通读代码框架
由于开发还没有结束,在当前 Diffusers 的 FLUX.1 源码中,我们能看到各种潦草的写法及残缺不全的文档,这让读源码变成了一项颇具趣味的挑战性任务。让我们先看一下代码的整体框架,找出 FLUX.1 相较 Stable Diffusioni 3 在代码上的改动,再来详细分析这些创新。
和 Diffusers 中的其他生成模型一样,FLUX.1 的采样算法写在一个采样流水线类里。我们可以通过示例脚本里的 FluxPipeline 类跳转到定义该类的文件 diffusers/pipelines/flux/pipeline_flux.py 里。这个文件是从 Stable Diffusion 3 的采样流水线文件 diffusers/pipelines/stable_diffusion_3/pipeline_stable_diffusion_3.py 改过来的,大部分文档都没有更新。我们可以用肉眼对比两份文件的区别。
先看构造函数。Stable Diffusion 3 用了三个文本编码器,clip-vit-large-patch14, CLIP-ViT-bigG-14-laion2B-39B-b160k, t5-v1_1-xxl,而 FLUX.1 没有用第二个 CLIP 编码器,只用了另外两个文本编码器。
1 | class StableDiffusion3Pipeline(DiffusionPipeline, SD3LoraLoaderMixin, FromSingleFileMixin): |
再往下翻,我们能用火眼金睛发现 FLUX.1 的 VAE 压缩比是 16,是所有版本的 Stable Diffusion VAE 压缩比的两倍。这是为什么呢?不是增加压缩比会让 VAE 重建效果下降吗?
1 | # SD3 |
查看周围其他代码,我们能找到 _pack_latents,_unpack_latents 这两个方法。_pack_latents 其实就是一个图块化操作,它能把 $2 \times 2$ 个像素在通道维度上拼接到一起,而 _unpack_latents 是该操作的逆操作。原来,代码把图块化的两倍压缩比也算进 VAE 里了。这里直接把 vae_scale_factor 乘个 2 是一种非常差,歧义性极强的写法。
1 |
|
相比 SD3, FLUX.1 将图块化操作写在了去噪网络外面。因此,SD3 的去噪网络的输入通道数是 16,和 VAE 的隐空间通道数相同;而 FLUX.1 由于把 $2 \times 2$ 个像素在通道上拼接到了一起,其去噪网络的输入通道数是 64。
1 | { |
再来看采样主方法 __call__。先看一下它的主要参数。相比之下,FLUX.1 少了一组提示词,且没有负面提示词。少一组提示词是因为少用了一个文本编码器。而没有负面提示词是因为该模型是指引蒸馏过的,在文本指引上没那么灵活。我们稍后还会看到 FLUX.1 具体是怎么利用文本指引的。
1 | # SD3 |
之后的内容都与其他扩散模型流水线一样,代码会判断输入是否合法、给输入文本编码、随机生成初始化噪声。值得关注的是初始化噪声采样器前的一段新内容:代码会算一个 mu,并传进 retrieve_timesteps 里。这个变量最后会传到流匹配采样算法里。我们先把该改动记在心里,不看细节。
1 | mu = calculate_shift( |
在去噪循环部分,FLUX.1 没有做 Classifier-Free Guidance (CFG),而是把指引强度 guidance 当成了一个和时刻 t 一样的约束信息,传入去噪模型 transformer 中。CFG 的本意是过两遍去噪模型,一次输入为空文本,另一次输入为给定文本,让模型的输出远离空文本,靠近给定文本。而负面提示词只是一种基于 CFG 的技巧。把 CFG 里的空文本换成负面文本,就能让结果背离负面文本。但现在这个模型是一个指引蒸馏模型,指引强度会作为一个变量输入模型,固定地表示输入文本和空文本间的差距。因此,我们就不能在这个模型里把空文本换成负面文本了。
除了指引方式上的变动外,FLUX.1 的去噪网络还多了 txt_ids 和 img_ids 这两个输入。我们待会来看它们的细节。
FLUX.1 的去噪网络和 SD3 的一样,除了输入完整文本嵌入 prompt_embeds 外,依然会将池化过的短文本嵌入 pooled_prompt_embeds 输入进模型。我们现在可以猜测,FLUX.1 使用了和 SD3 类似的文本约束机制,输入了两类文本约束信息。
代码里的 /1000 是临时代码。之后所有涉及乘除 1000 的代码全可以忽略。
1 | for i, t in enumerate(timesteps): |
采样流水线最后会将隐空间图片解码。如前所述,由于现在图块化和反图块化是在去噪网络外面做的,这里隐空间图片在过 VAE 解码之前做了一次反图块化操作 _unpack_latents。对应的图块化操作是在之前随机生成初始噪声的 prepare_latents 方法里做的,为了节约时间我们就不去看了。
1 | if output_type == "latent": |
接下来,我们再简单看一下去噪网络的结构。在采样流水线里找到对应类 FluxTransformer2DModel,我们能用代码跳转功能定位到文件 diffusers/models/transformers/transformer_flux.py。SD3 去噪网络类是 SD3Transformer2DModel,它位于文件 diffusers/models/transformers/transformer_sd3.py。
同样,我们先对比类的构造函数。构造函数的新参数我们暂时读不懂,所以直接跳到构造函数内部。
在使用位置编码时,SD3 用了二维位置编码类 PatchEmbed。该类会先对图像做图块化,再设置位置编码。 而 FLUX.1 的位置编码类叫 EmbedND。从官方简介以及参数里的单词 rope 中,我们能猜出这是一个旋转式位置编码 (RoPE)。
1 | # SD3 |
再往下看,FLUX.1 的文本嵌入类有两种选择。不设置 guidance_embeds 的话,这个类就是 CombinedTimestepTextProjEmbeddings,和 SD3 的一样。这说明正如我们前面猜想的,FLUX.1 用了和 SD3 一样的额外文本约束机制,将一个池化过的文本嵌入约束加到了文本嵌入上。
设置 guidance_embeds 的话,CombinedTimestepGuidanceTextProjEmbeddings 类应该就得额外处理指引强度了。我们待会来看这个类是怎么工作的。
1 | text_time_guidance_cls = ( |
之后函数定义了两个线性层。context_embedder 在 SD3 里也有,是用来处理文本嵌入的。但神秘的 x_embedder 又是什么呢?可能得在其他函数里才能知道了。
1 | self.context_embedder = nn.Linear(self.config.joint_attention_dim, self.inner_dim) |
函数的末尾定义了两个模块列表。相比只有一种 Transformer 块的 SD3,FLUX.1 用了两种结构不同的 Transformer 块。
1 | self.transformer_blocks = nn.ModuleList( |
我们再来看 forward 方法,看看之前看构造函数时留下的问题能不能得到解答。
forward 里首先是用 x_embedder 处理了一下输入。原本在 SD3 中,输入图像会在 pos_embed 里过一个下采样两倍的卷积层,同时完成图块化和修改通道数两件事。而现在 FLUX.1 的图块化写在外面了,所以这里只需要用一个普通线性层 x_embedder 处理一下输入通道数就行了。这样说来,变量名有个 x 估计是因为神经网络的输入名通常叫做 x。既然这样,把它叫做 input_embedder 不好吗?
1 | # SD3 |
下一步是求时刻编码。这段逻辑是说,如果模型输入了指引强度,就把指引强度当成一个额外的实数约束,将其编码加到时刻编码上。具体细节都在 time_text_embed 的类里。
1 | timestep = timestep.to(hidden_states.dtype) * 1000 |
下一行是常规的修改约束文本嵌入。
1 | encoder_hidden_states = self.context_embedder(encoder_hidden_states) |
再之后的两行出现了一个新操作。输入的 txt_ids 和 img_ids 拼接到了一起,构成了 ids,作为旋转式位置编码的输入。
1 | ids = torch.cat((txt_ids, img_ids), dim=1) |
此后图像信息 hidden_states 和文本信息 encoder_hidden_states 会反复输入进第一类 Transformer 块里。和之前相比,模块多了一个旋转式位置编码输入 image_rotary_emb。
1 | encoder_hidden_states, hidden_states = block( |
本来过了这些块后,SD3 会直接会直接返回 hidden_states 经后处理后的信息。而 FLUX.1 在过完第一类 Transformer 块后,将图像和文本信息拼接,又输入了第二类 Transformer 块中。第二类 Transformer 块的输出才是最终输出。
1 | hidden_states = torch.cat([encoder_hidden_states, hidden_states], dim=1) |
到这里,我们就把 FLUX.1 的代码结构过了一遍。我们发现,FLUX.1 是一个基于 SD3 开发的模型。它在图块化策略、噪声调度器输入、位置编码类型、Transformer 块类型上略有改动。且由于开源的 FLUX.1 是指引蒸馏过的,该模型无法使用 CFG。[dev] 版可以以实数约束的方式设置指引强度,而 [schnell] 版无法设置指引强度。
在这次阅读中,我们已经弄懂了以下细节:
- 采样流水线会在去噪网络外面以通道堆叠的方式实现图块化。
- 指引强度不是以 CFG 的形式写在流水线里,而是以约束的形式输入进了去噪网络。
我们还留下了一些未解之谜:
- 输入进噪声采样器的
mu是什么? - 决定旋转式位置编码的
txt_ids和img_ids是什么? - 旋转式位置编码在网络里的实现细节是什么?
- 新的那种 Transformer 块的结构是怎么样的?
针对这些问题,我们来细读代码。
调整流匹配标准差
在采样流水线里,我们见到了这样一个神秘变量 mu。从名字中,我们猜测这是一个表示正态分布均值的变量,用来平移 (shift) 某些量的值。
1 | mu = calculate_shift(...) |
我们先看 calculate_shift 做了什么。第一个参数 image_seq_len 表示图像 token 数,可以认为是函数的自变量 x。后面四个参数其实定义了一条直线。我们可以认为 base_seq_len 是 x1, max_seq_len 是 x2,base_shift 是 y1,max_shift 是 y2。根据这两个点的坐标就可以解出一条直线方程出来。也就是说,calculate_shift 会根据模型允许的最大 token 数 4096 ($64 \times 64$) 和最小 token 数 256 ($16 \times 16$),把当前的输入 token 数线性映射到 0.5 ~ 1.16 之间。但我们暂时不知道输出 mu 的意义是什么。
1 | def calculate_shift( |
再追踪进调用了 mu 的 retrieve_timesteps 函数里,我们发现 mu 并不在参数表中,而是在 kwargs 里被传递给了噪声迭代器的 set_timesteps 方法。1
2
3
4
5
6
7
8
9
10def retrieve_timesteps(
scheduler,
num_inference_steps: Optional[int] = None,
device: Optional[Union[str, torch.device]] = None,
timesteps: Optional[List[int]] = None,
sigmas: Optional[List[float]] = None,
**kwargs,
):
...
scheduler.set_timesteps(timesteps=timesteps, device=device, **kwargs)
根据流水线构造函数里的类名,我们能找到位于 diffusers/schedulers/scheduling_flow_match_euler_discrete.py 调度器类 FlowMatchEulerDiscreteScheduler。1
2
3
4def __init__(
self,
scheduler: FlowMatchEulerDiscreteScheduler,
...)
再找到类的 set_timesteps 方法。set_timesteps 一般是用来设置推理步数 num_inference_steps 的。有些调度器还会在总推理步数确定后,初始化一些其他变量。比如这里的流匹配调度器,会在这个方法里初始化变量 sigmas。我们可以忽略这背后的原理,仅从代码上看,输入 mu 会通过 time_shift 修改 sigmas 的值。
这里的变量命名又乱七八糟,输入
time_shift的sigmas是第三个参数,而在time_shift里的sigmas是除了self以外的第二个参数。这是因为 Diffusers 在移植官方代码时没有取好变量名。
1 | def time_shift(self, mu: float, sigma: float, t: torch.Tensor): |
我们再跑出去看一下流水线里输入的 sigmas 是什么。假设总采样步数为 $T$,则 sigmas 是 $1$ 到 $\frac{1}{T}$ 间均匀采样的 $T$ 个实数。
1 | sigmas = np.linspace(1.0, 1 / num_inference_steps, num_inference_steps) |
现在要解读 mu 的作用就很容易了。假设 sigmas 是下标和值构成的点,我们可以测试 mu 不同的情况下, sigmas 经过 time_shift 函数形成的曲线图。
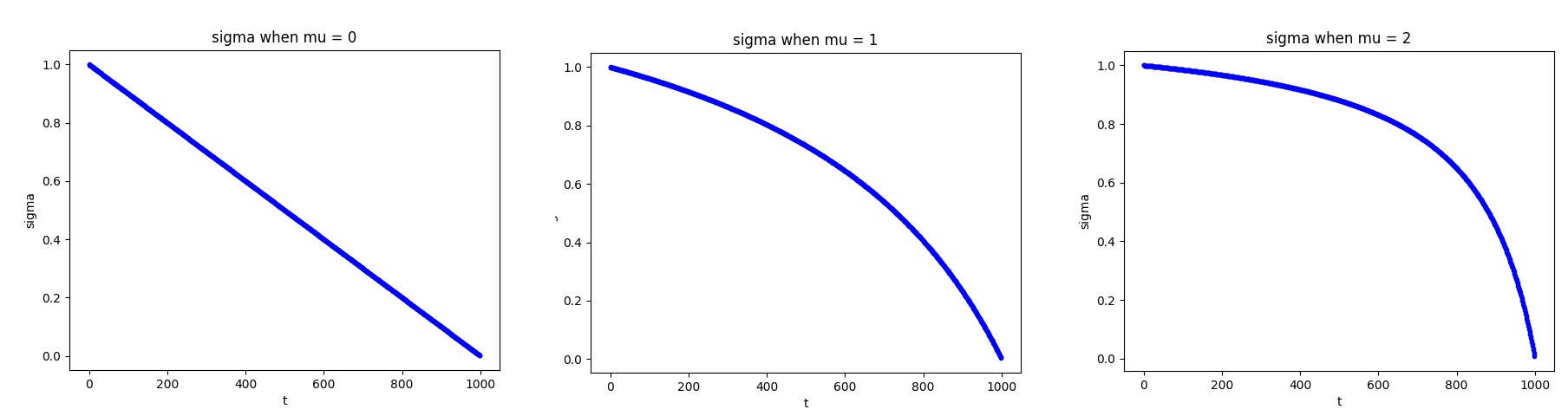
可以看出,mu=0则不修改曲线。随着 mu 增大,曲线逐渐上凸。
我对流匹配的具体细节不是很懂,只能大概猜测 mu 的作用。流匹配中,图像沿着某条路线从纯噪声运动到训练集中,标准差 sigma 用于控制不同时刻图像的不确定性。时刻为 0 时,图像为纯噪声,标准差为 1; 时刻为 1 时,图像为生成集合中的图像,标准差要尽可能趋于 0。对于中间时刻,标准差默认按照时刻线性变化。而 mu 是一个 0.5 ~ 1.16 之间的数,可能控制的是中间时刻的噪声均值。图像分辨率越大,token 越多,mu 越大,要加的噪声越重。这也符合之前 Stable Diffusion 3 论文在 Resolution-dependent shifting of timestep schedules 小节里的设计,对于分辨率越高的图像,需要加更多噪声来摧毁原图像的信号。总之,这个 mu 可能是训练的时候加的,用于给高分辨率图像加更多噪声,推理时也不得不带上这个变量。
FLUX.1 官方仓库对应部分是这样写的:
1 | def get_lin_function( |
mu 的作用确实和高信号图片有关。但他们的设计初衷是偏移时间戳,而不是根据某种公式修改 sigma。比如原来去噪迭代 0~500 步就表示 t=0 到 t=0.5,偏移时间戳后,0~500 步就变成了 t=0 到 t=0.3。偏移时间戳使得模型能够把更多精力学习对如何对高噪声的图像去噪。
使用单流并行注意力层的 Transformer 架构
接下来的问题都和 FLUX.1 的新 Transformer 架构相关。我们先把整个网络架构弄懂,再去看旋转式位置编码的细节。
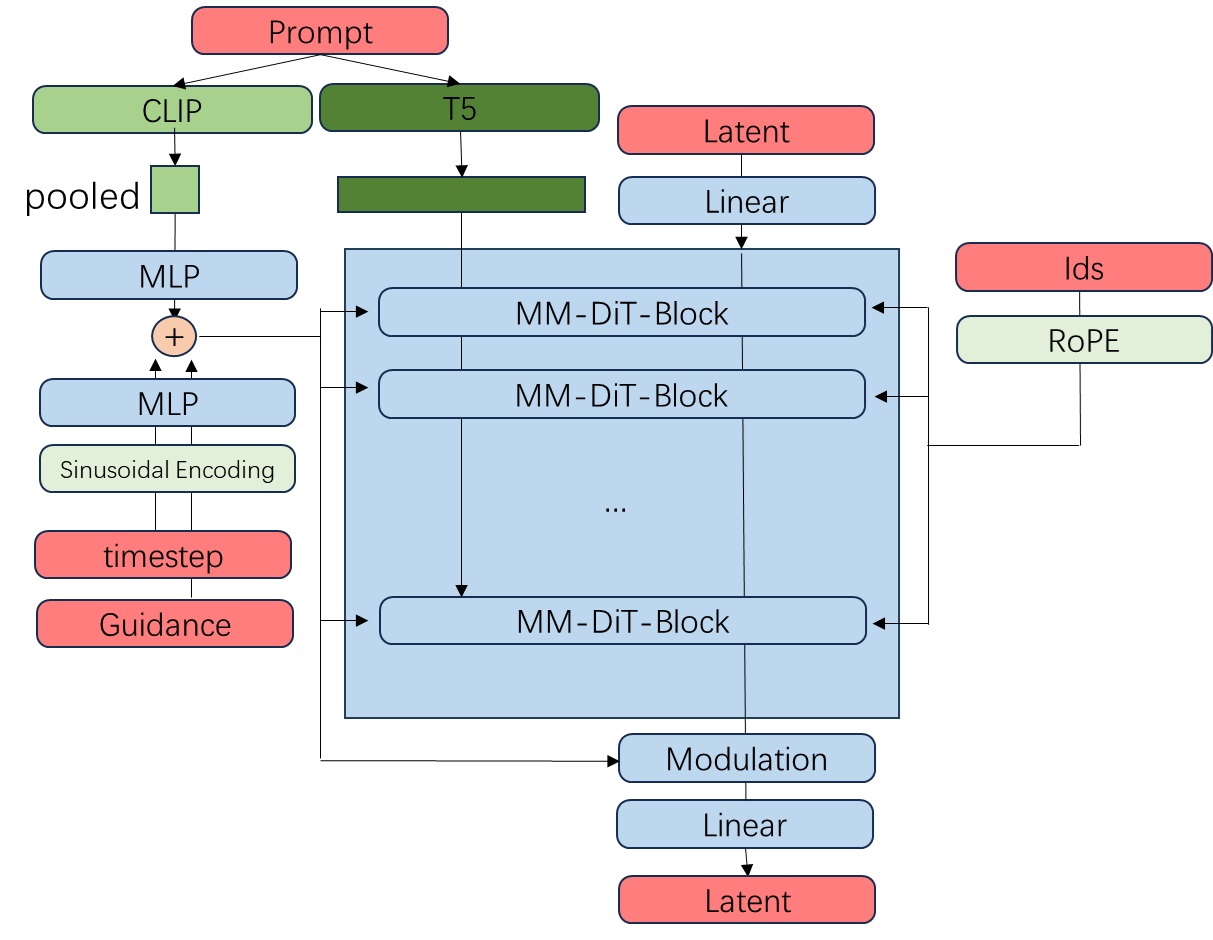
为了理清网络架构,我们来根据已知信息,逐步完善网络的模块图。首先,我们先粗略地画一个 Transformer 结构,定义好输入输出。相比 SD3,FLUX.1 多了指引强度和编号集 txt_ids, img_ids这两类输入。
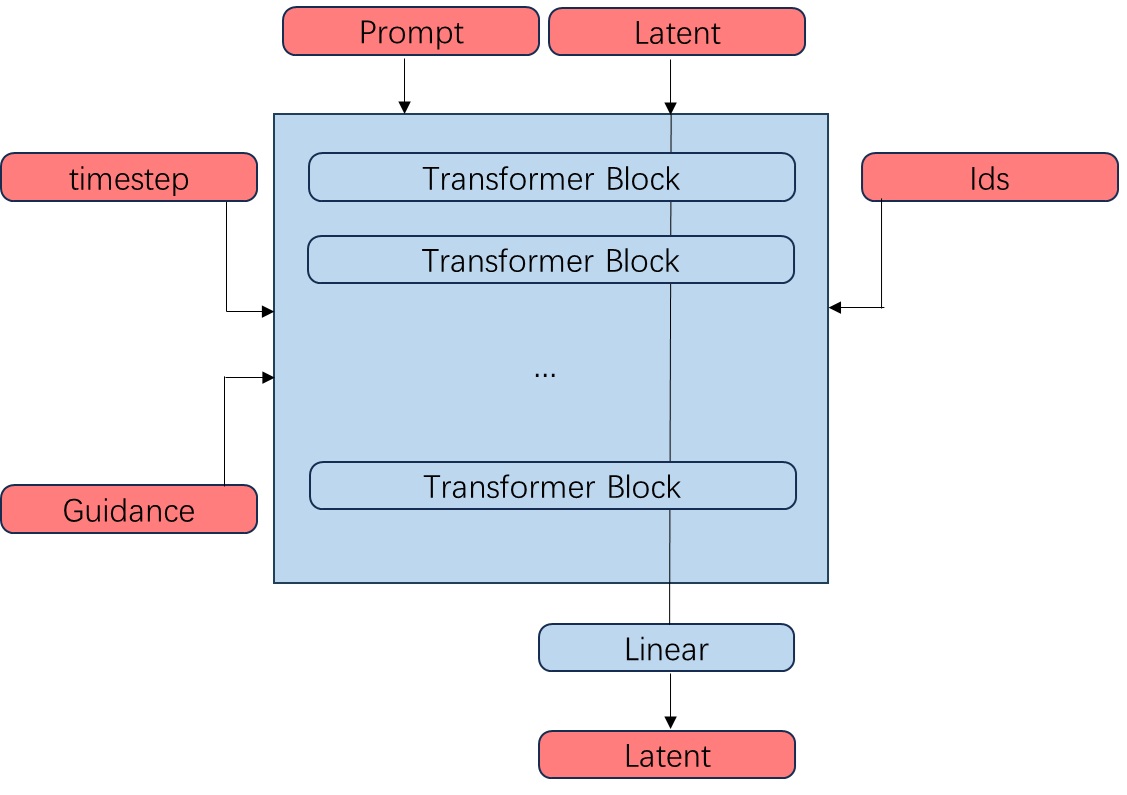
接下来,我们把和 SD3 相似的结构画进来。所有 Transformer 块都是那种同时处理两类 token 的双流注意力块。输入文本的 T5 嵌入会作为文本支流进入主模型。输入文本的 CLIP 嵌入会经池化与MLP,与经过了位置编码和 MLP 的时刻编码加到一起。时刻编码会以 AdaLayerNorm 的方式修改所有层的数据规模,以及数据在输出前的尺寸与均值。
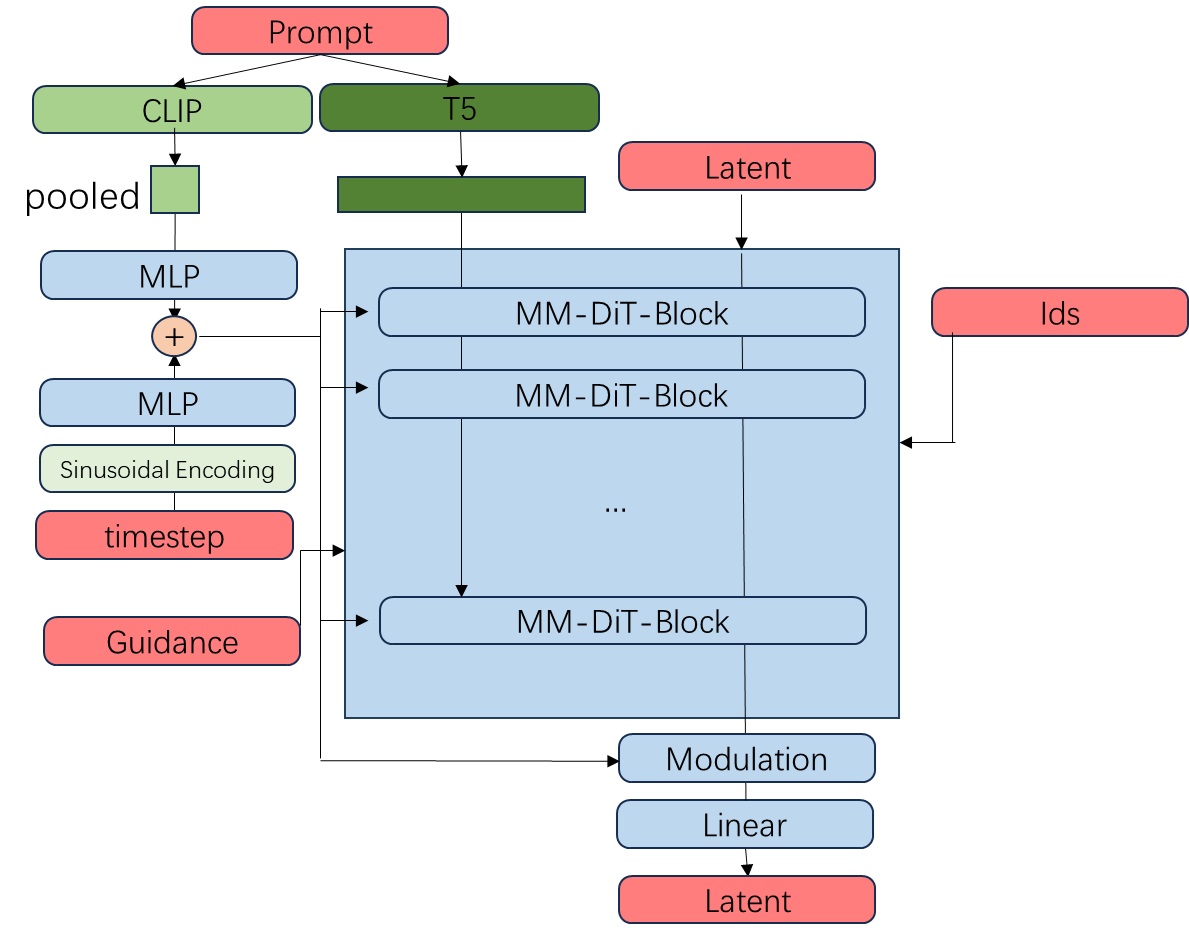
在 CombinedTimestepGuidanceTextProjEmbeddings 类中,我们能知道小文本嵌入、时刻嵌入、指引嵌入是怎么加到一起的。我们主要关心指引嵌入的有关操作。由于指引强度 guidance 和时刻 timestep 都是实数,所以 guidance_emb 的处理方式与 timesteps_emb 一模一样。
1 | class CombinedTimestepGuidanceTextProjEmbeddings(nn.Module): |
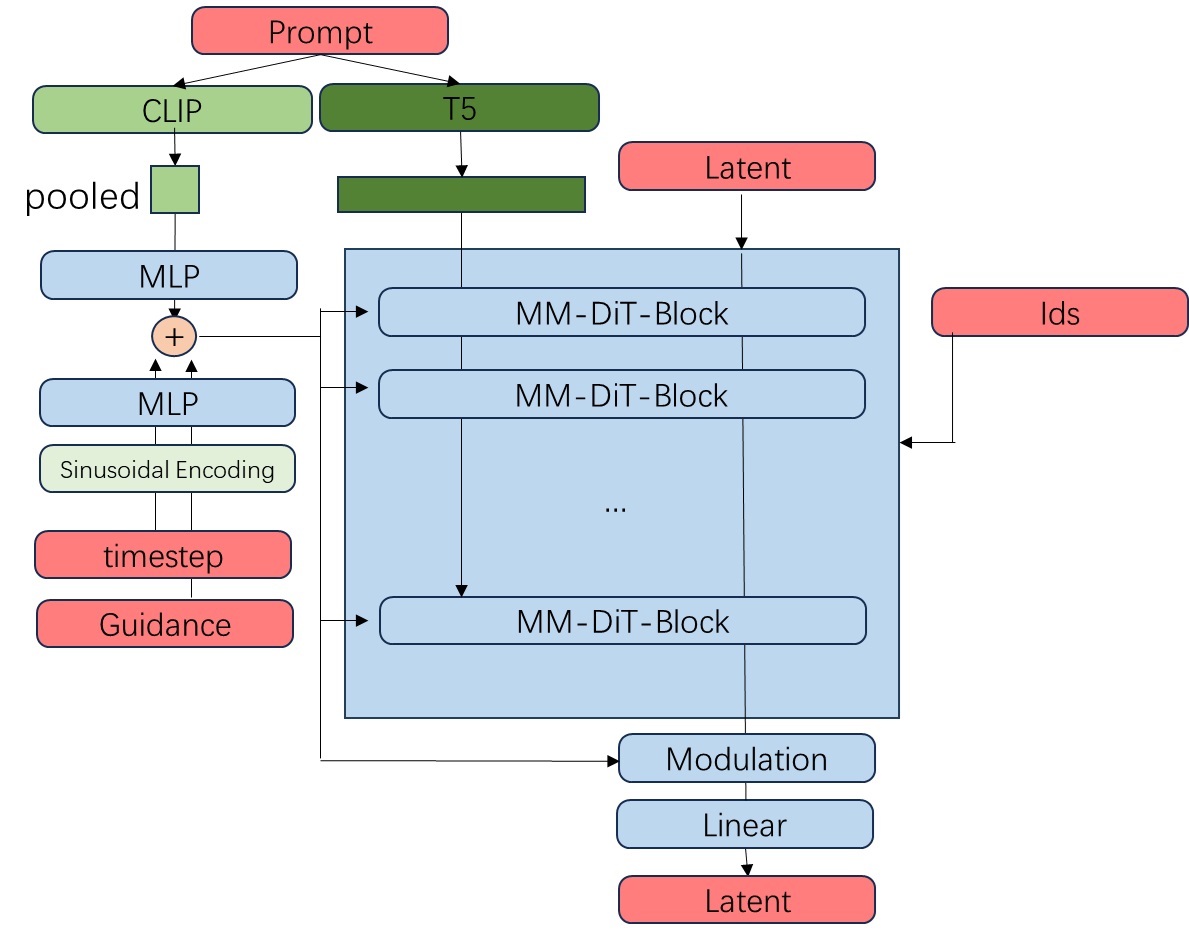
在去噪模型 FluxTransformer2DModel 的 forward 方法中,原先的图块化及二维位置编码模块被一个简单的线性层 x_embedder 取代了,现在的位置编码 image_rotary_emb 会输入进所有层中,而不是一开始和输入加在一起。
1 | def forward(hidden_states, ...): |
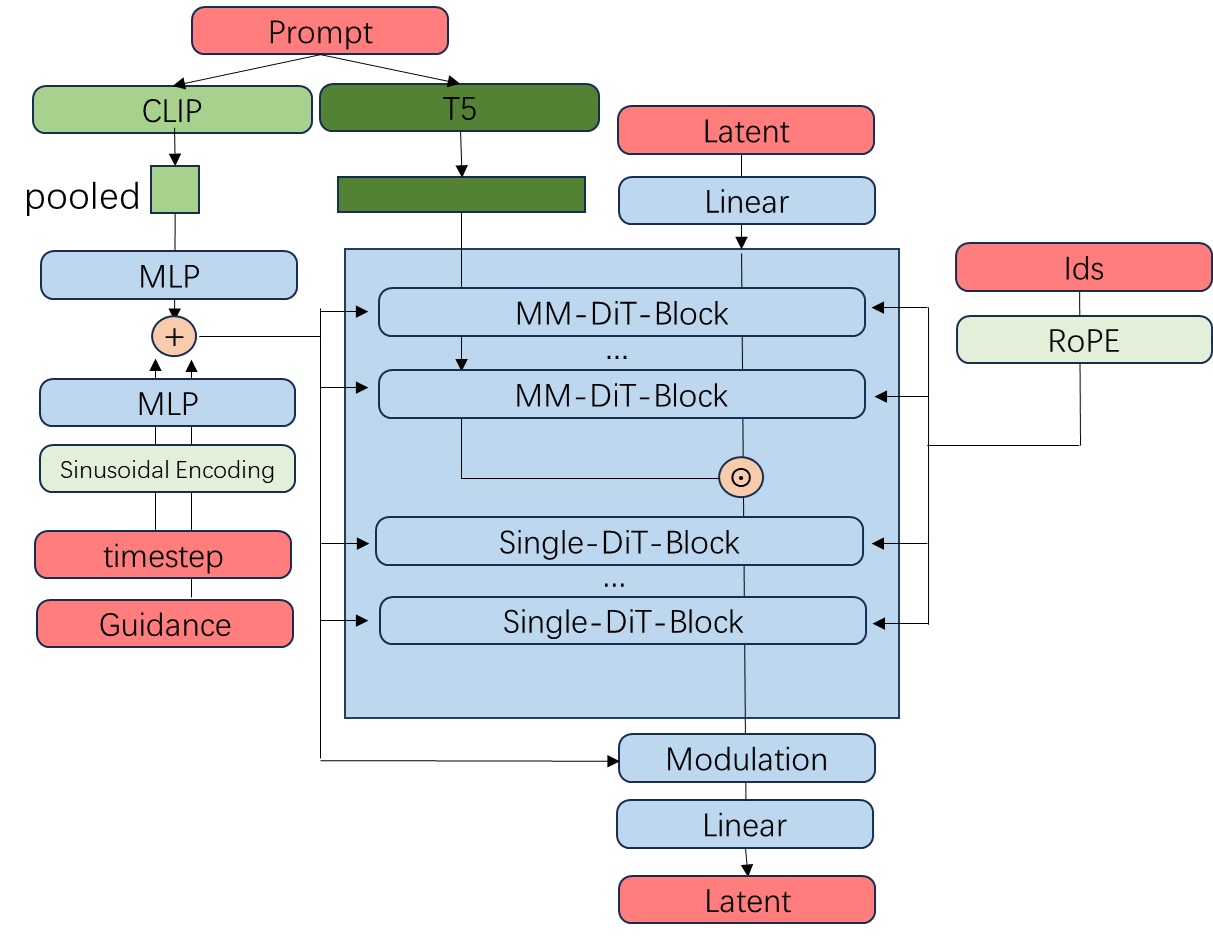
之后,除了过 MM-DiT 块以外,文本信息还会和图像信息融合在一起,过若干个单流 Transformer 块。过了这些模块后,原来文本 token 那部分会被丢弃。
1 | for index_block, block in enumerate(self.transformer_blocks): |
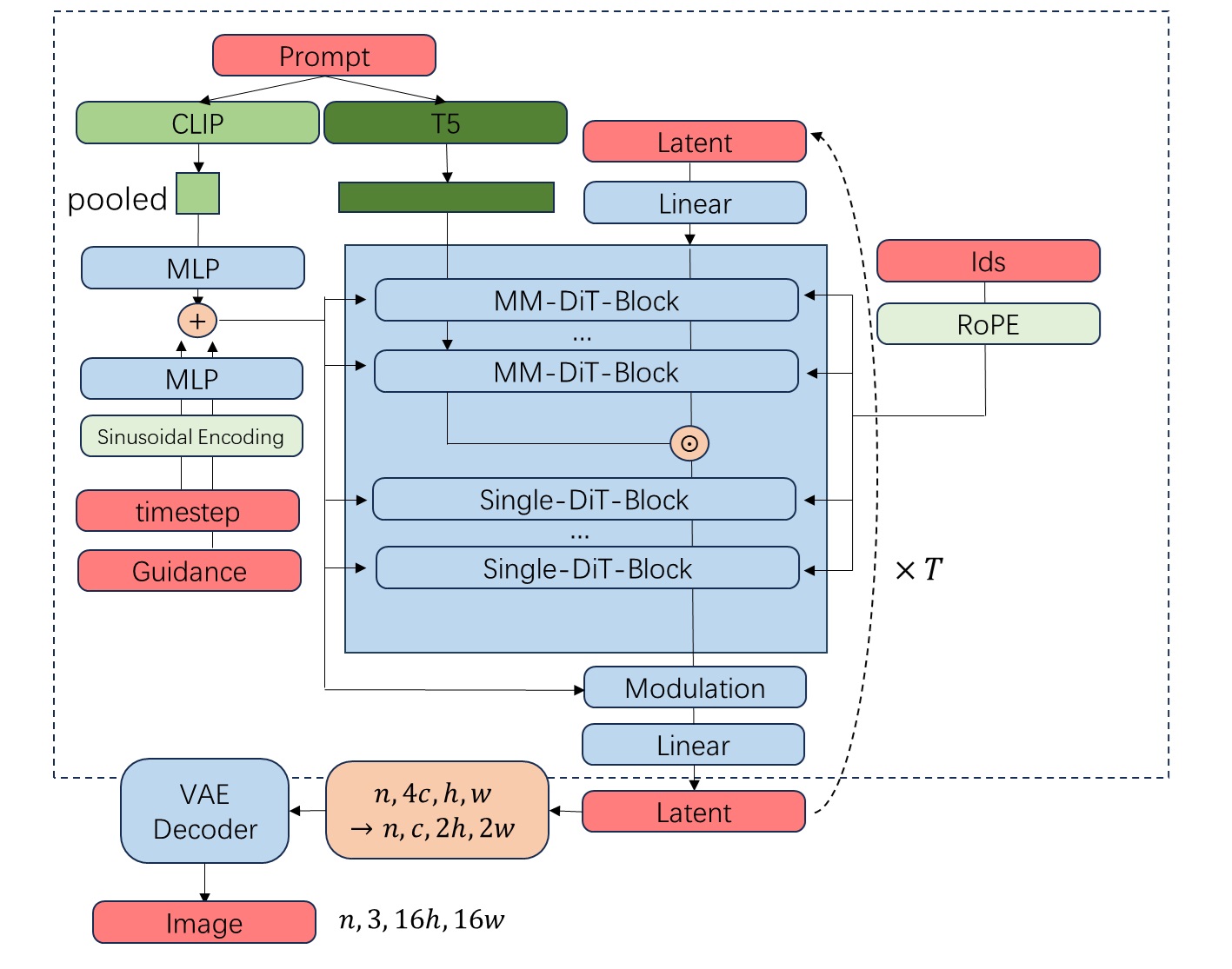
我们已经画完了去噪模型的结构,最后把 VAE 部分加上就比较完美了。
多数模块的细节都可以在 SD3 的论文里找到,除了 RoPE 和单流 DiT 块。我们在这一节里再仔细学习一下单流 DiT 块的结构。
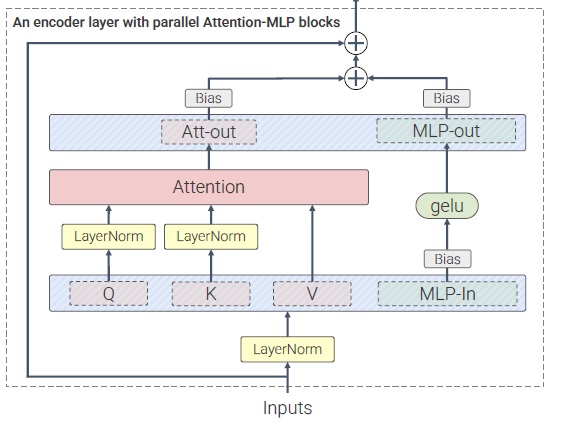
根据官方介绍,FLUX.1 的 Transformer 里用到了并行 Transformer。准确来说,FLUX.1 仅在最后的单流 DiT 块里用到了并行注意力层。并行注意力层是在文章 Scaling Vision Transformers to 22 Billion Parameters 中提出的。如下图所示,这项技术很好理解,只不过是把注意力和线性层之间的串联结构变成并联结构。这样的好处是,由于数据在过注意力层前后本身就要各过一次线性层,在并联后,这些线性层和 MLP 可以融合。这样的话,由于计算的并行度更高,模型的运行效率会高上一些。
顺带一提,在 Q, K 后做归一化以提升训练稳定性也是在这篇文章里提出的。SD3 和 FLUX.1 同样用了这一设计,但用的是 RMSNorm 而不是 LayerNorm。
我们可以在 FluxSingleTransformerBlock 类里找到相关实现。代码不长,我们可以一次性读完。相比上面的示意图,Q, K, V 的投影操作被单独放进了 Attention 类里,并没有和第一个线性层融合。而做了注意力操作后,Att-out 和 MLP-out 确实是放在一起做的。attn_output 和 mlp_hidden_states 拼接了起来,一起过了 proj_out。此外,这里的归一化层还是 DiT 里的 AdaLN,模块能接收时刻编码的输入。
1 | class FluxSingleTransformerBlock(nn.Module): |
此处具体的注意力运算写在 FluxSingleAttnProcessor2_0 类里。跳过前面繁杂的形状变换操作,我们来看该注意力运算的关键部分。在做完了标准注意力运算 scaled_dot_product_attention 后,一般要调用 attn.to_out[0](hidden_states) 对数据做一次投影变换。但是,在这个注意力运算中,并没有对应的操作。这表明该模块确实是照着并行注意力层设计的,离开注意力的投影与 MLP 的第二个线性层融合到了一起。
1 | def __call__( |
旋转式位置编码思想及 FLUX.1 实现
旋转式位置编码是苏剑林在 RoFormer: Enhanced Transformer with Rotary Position Embedding 中提出的一种专门为注意力计算设计的位置编码。在这篇文章中,我们来简单地了解一下旋转式位置编码的设计思想,为学习 FLUX.1 的结构做准备。
想深究旋转式位置编码的读者可以去阅读苏剑林的博文,先阅读《让研究人员绞尽脑汁的Transformer位置编码》(https://kexue.fm/archives/8130) 了解该怎么设计位置编码,再阅读《Transformer升级之路:2、博采众长的旋转式式位置编码》(https://kexue.fm/archives/8265) 了解旋转式位置编码的细节。
Transformer 仅包括注意力和全连接两种运算,这两种运算都是和位置无关的。为了让 Transformer 知道词语的前后关系,或者像素间的空间关系,就要给 Transformer 中的 token 注入某种位置信息。然而,仅仅告诉每个 token 它的绝对位置是不够好的,这样做最明显的缺点是模型无法处理训练时没有见过的长序列。比如训练集里最长的句子是 512 个 token,如果输入 600 个 token,由于模型没有见过编号超过 512 的位置编码,就不能很好地处理 512 号以后的 token。因此,我们不仅希望每个 token 知道自己的绝对位置,还希望 token 能从位置编码里知道相对位置的信息。
在提出 Transfomer 的论文中,作者给出了如下的一套正弦位置编码方案。这也是多数工作默认使用的位置编码方式。为了简化表示,我们假设输入 token 是一个二维向量,这样,每个 token 需要的位置编码也是一个二维向量。
其中,$k$ 表示第 $k$ 个 token。这样做的好处是,根据三角函数和角公式,位置编码之间可以用线性组合来表示,这种编码蕴含了一定的相对位置信息。
当我们要把二维向量拓展成 $d$ 维向量时,只需要把 $d$ 维两两打包成一组,每组用不同周期的正弦函数即可。因此,在后文中,我们也不讨论 $d$ 维的 token,只需要搞明白二维的 token 该怎么编码就行。
尽管正弦编码能表示一定的相对信息,但是,由于位置编码之间是线性关系,经过了 Transformer 中最重要的操作——注意力操作后,这种相对位置信息几乎就消失了。有没有一种位置编码方式能够让注意力计算也能知道 token 间的相对位置关系呢?
经苏剑林设计,假设每个 token 的二维位置编码是一个复数,如果用以下的公式来定义绝对位置编码,那么经过注意力计算里的求内积操作后,结果里恰好会出现相对位置关系。设两个 token 分别位于位置 $m$ 和 $n$,令给位置为 $j$ 的注意力输入 Q, K $q_j, k_j$ 右乘上 $e^{ij/10000}$的位置编码,则求 Q, K 内积的结果为:
其中,$i$ 为虚数单位,$*$ 为共轭复数,$Re$ 为取复数实部。只是为了理解方法的思想的话,我们不需要仔细研究这个公式,只需要注意到输入的 Q, K 位置编码分别由位置 $m$, $n$ 决定,而输出的位置编码由相对位置 $m-n$ 决定。这种位置编码既能给输入提供绝对位置关系,又能让注意力输出有相对位置关系,非常巧妙。
根据欧拉公式,我们可以把 $e^i$ 用一个含 $sin$ 和 $cos$ 的向量表示。由于该变换对应向量的旋转,所以这种位置编码被称为「旋转式位置编码」。在实际实现时,我们不需要复数库,只需要用两个分别含 $sin$ 和 $cos$ 的数来表示一个位置编码。也就是说,原来正弦位置编码中每个位置的编码只有一个实数,现在需要两个实数,或者说要一个二维向量。
总结一下用旋转式位置编码替换正弦位置编码后,我们在实现时应该做的改动。现在,我们不是提前算好位置编码,再加到输入上,而是先预处理好位置编码,在每次注意力 Q,K 求内积前给输入乘上。和正弦编码一样,我们会把特征长度为 $d$ 的 token 向量的分量两两分组,分别维护位置关系。但是,现在每个分量的编码由两个而不是一个实数表示。所以,在之后的代码中,我们会看到生成位置编码时,会先把 token 特征向量长度除以二,再给每组 token 生成 $2 \times 2$ 个编码,对应每组两个编码,每个编码长度为二。
我们来看一下 FLUX.1 的 Transformer 是怎么处理位置编码的。在 FluxTransformer2DModel 的 forward 方法中,我们能看到输入的 0, 1, 2, 3 这样的整数位置编码 ids 被传入了位置编码层 pos_embed 中。
1 | ids = torch.cat((txt_ids, img_ids), dim=1) |
位置编码层类 EmbedND 定义了位置编码的具体计算方式。这个类的逻辑我们暂时跳过,直接看最后真正在算旋转式位置编码的 rope 函数。函数中,输入参数 pos 是一个 0, 1, 2, 3 这样的整数序号张量,dim 表示希望生成多长的位置编码,其值应该等于 token 的特征长度,theta 用来控制三角函数的周期,一般都是取常数 10000。我们能看到,rope 计算了输入的三角函数值,并把长度为 dim 的编码两两分组,每组有 (2, 2) 个位置编码值。
1 | def rope(pos: torch.Tensor, dim: int, theta: int) -> torch.Tensor: |
我们来看一下位置编码是怎么传入 Transformer 块的注意力计算的。在预处理完位置编码后,image_rotary_emb 会作为输入参数传入所有 Transformer 块,包括前面的双流块和后面的单流块。
1 | def forward(...): |
位置编码 image_rotary_emb 最后会传入双流注意力计算类 FluxAttnProcessor2_0 和单流注意力计算类 FluxSingleAttnProcessor2_0。由于位置编码在这两个类中的用法都相同,我们就找 FluxSingleAttnProcessor2_0 的代码来看一看。在其 __call__ 方法中,可以看到,在做完了 Q, K 的投影变换、形状变换、归一化后,方法调用了 apply_rope 来执行旋转式位置编码的计算。而 apply_rope 会把 Q, K 特征向量的分量两两分组,根据之前的公式,模拟与位置编码的复数乘法运算。
1 | class FluxSingleAttnProcessor2_0: |
这样,我们就看完了旋转式位置编码在 FLUX.1 里的实现。但是,我们还遗留了一个重要问题:在 NLP 中,句子天然有前后关系,我们按照 0, 1, 2, 3 给 token 编号就行了。而在这个模型中,既有图像 token,又有文本 token,该怎么给 token 编号呢?
图像及文本 token 的位置编号
现在,我们把目光倒回到流水线类。输入给去噪模型的序号变量有两个:text_ids,latent_image_ids。它们是怎么得到的?
1 | noise_pred = self.transformer( |
在文本编码方法中,我们看到,text_ids 竟然只是一个全零张量。它的第一维表示 batch 大小,第二维序列长度等于文本编码 prompt_embeds 的长度,第三维序号长度为 3。也就是说,对于每一个文本 token 的每一个位置,都用 (0, 0, 0) 来表示它的位置编号。这也暗示在 FLUX.1 中,token 的位置是三维的。
1 | def encode_prompt( |
而 latent_image_ids 主要是在 _prepare_latent_image_ids 函数里生成的。这个函数的主要输入参数是图像的高宽。根据高宽,函数会生成 (0, 0) ~ (height, width) 的二维位置坐标表格,作为位置坐标 latent_image_ids 的第二、第三维。而位置坐标的第一维全是 0。也就是说,位置为 (i, j) 的像素的位置编号为 (0, i, j)。代码里给高宽除以 2 是因为输入没有考虑 2 倍的图块化,这写得真够乱的。
1 | def _prepare_latent_image_ids(batch_size, height, width, device, dtype): |
文本位置编号 txt_ids 和 img_ids 会在第二维,也就是序列长度那一维拼接成 ids。ids 会输入给 EmbedND 类的实例 pos_embed。EmbedND 的构造函数参数中,dim 完全没有被用到,theta 控制编码的三角函数周期,axes_dim 表示位置坐标每一维的编码长度。比如 FLUX.1 的位置坐标是三维的, axes_dim 是 [16, 56, 56],那么它就表示第一个维度用长度 16 的位置编码,后两维用长度 56 的位置编码。位置编号经 rope 函数计算得到旋转式位置编码后,会拼接到一起,最后形成 128 维的位置编码。注意,所有 Transformer 块每个头的特征数 attention_head_dim 也是 128。这两个值必须相等。
「头」指的是「多头注意力」里的「头」。头数乘上每次参与注意力运算的特征长度才等于总特征长度。由于位置编码是给 Q, K 准备的,所以位置编码的长度应该与参与注意力运算的特征长度相同。
1 | class FluxTransformer2DModel(): |
我们来整理一下 FLUX.1 的位置编码机制。每个文本 token 的位置编号都是 (0, 0, 0)。位于 (i, j) 的像素的位置编号是 (0, i, j)。它们会生成 128 维的位置编码。编码前 16 个通道是第一维位置编号的位置编码,后面两组 56 个通道分别是第二维、第三位位置编号的位置编码。也就是说,在每个头做多头注意力运算时,特征的前 16 个通道不知道位置信息,中间 56 个通道知道垂直的位置信息,最后 56 个通道知道水平的位置信息。
乍看下来,这种位置编号方式还是非常奇怪的。所有 token 的第一维位置编号都是 0,这一维岂不是什么用都没有?
FLUX.1 旋转式位置编码原理猜测与实验
在这一节中,我将主观分析 FLUX.1 的现有源码,猜测 FLUX.1 未开源的 [pro] 版本中旋转式位置编码是怎么设置的。此外,我还会分享一些简单的相关实验结果。
已开源的 FLUX.1 为什么会出现 (0, 0, 0), (0, i, j) 这样奇怪的位置编号呢?由于现在已开源的两版模型是在 FLUX.1 [pro] 上指引蒸馏的结果,很可能原模型在指引机制,也就是和文本相关的处理机制上与现有模型不同。因此,我使用我独创的代码心理学,对现有源码进行了分析。
首先,令我感到疑惑的是采样流水线里生成位置编号的代码。latent_image_ids 一开始是一个全零张量,你写它加一个数,和直接赋值的结果不是一样的吗?为什么要浪费时间多写一个加法呢?
1 | latent_image_ids = torch.zeros(height // 2, width // 2, 3) |
为了确认这段代码不是 Diffusers 的开发者写的,我去看了 FLUX.1 的官方代码,发现他们的写法是一样的。在看 Diffusers 源码时,我们还看到了其他一些写得很差的代码,这些代码其实也都是从官方仓库里搬过来的。
1 | def prepare(t5: HFEmbedder, clip: HFEmbedder, img: Tensor, prompt: str | list[str]) -> dict[str, Tensor]: |
从这些代码中,我们不难猜出开发者的心理。FLUX.1 的开发者想,我们要赶快搞一个大新闻,论文也不写了,直接加班加点准备开源。Diffusers 的开发者一看,你们这么急,我们也得搞快一点。于是他们先把 SD3 的代码复制了一遍,然后又照搬了 FLUX.1 官方仓库里的一些逻辑,直接修改 SD3 的代码。
相信大家都有这样的代码重构经历:把自己写的个人开发代码,急忙删删改改,变成能给别人看的代码。能少改一点,就少改一点。上面的代码用加法而不是赋值,就是重构的时候代码没删干净的痕迹。这说明,一开始的 img_ids 很可能不是一个全零张量,而是写了一些东西在里面。
而另一边,设置文本位置编号的官方源码里,非常干脆地写着一个全零向量。我倾向于这部分代码没有在开源时改过。
1 | txt_ids = torch.zeros(bs, txt.shape[1], 3) |
那么,问题就来了,这个看似全零的图像位置编号一开始是什么?它对整个位置编码的设计有什么影响?
1 | img_ids = torch.zeros(h // 2, w // 2, 3) |
我猜开发者设置这个变量的目的是为了区分文本和图像 token。目前,所有文本 token 的位置编号是 (0, 0, 0),这其实不太合理,因为这种做法实际上是把所有文本 token 都默认当成位置为 (0, 0) 图像 token。为了区分文本和图像 token,应该还有其他设计。我猜最简单的方法是在第一维上做一些改动,比如令所有图像 token 的第一维都是 1。但看起来更合理的做法是对三个维度的编号都一些更改,比如给所有图像位置编号都加上一个常量 (a, b, c)。这样,图像 token 间的相对位置并不会变,而图像和文本 token 的相对位置就不同了,文本就不会默认在图像 (0, 0) 处了。从代码里的加法来看,我更倾向于认为 img_ids 原来是一个三个维度都有值的常量,且这个量或许是可以学习的。而在指引蒸馏时,位置编号的设计被简化了。
网上有人说文本位置编码全零是因为 t5 编码器自带位置编码。而在我看来,过了一个文本编码器后,文本的每个 token 已经包含所有文本的全局信息,文本 token 之间的位置编码在这里已经不重要了。重要的是文本 token 和图像 token 之间的「位置」关系,这并不能通过 t5 的位置编码来反映。
为了验证位置编码的作用,我尝试修改了图像位置编号的定义,还是跑本文开头那个测试示例。
如果把图像位置编号全置零,会得到下面的结果。这说明位置编码对结果的影响还是很大的,模型只能从位置编码处获取 token 间的相对关系。

如果把位置编号除以二,会得到下面的结果。我们能发现,图像好像变模糊了一点,且像素有锯齿化的倾向。这非常合理,因为位置编号除以二后,模型实际上被要求生成分辨率低一倍的结果。但突然又多了一些距离为 0.5 的像素,模型突然就不知道怎么处理了,最终勉强生成了这种略显模糊,锯齿现象明显的图片。注意哦,这里虽然像素间的关系不对,但图中的文字很努力地想要变得正常一点。

位置编号乘二的结果如下所示。可能模型并没有见过没有距离为 1 的图像 token 的情况,结果全乱套了。但尽管是这样,我们依然能看到图中的 “Hello World”。结合上面的结果,这说明文本指引对结果的影响还是很大的,正常的文本 token 在努力矫正图像生成结果。

位置编号乘 1.2 的结果如下所示。图像的结果还是比较正常的。这说明这套位置编码允许位置编号发生小的扰动,且模型能认识非整数的位置编号,即在模型看来,位置编号是连续的。

原图片和将位置编号第一维全置 1 的结果如下所示。如我所料,位置编号的第一维几乎没什么作用。图片只是某些地方发生了更改,整体的画面结构没有变化。

目前看下来,由于现在我们有了显式定义 token 相对位置关系的方法,要在 FLUX.1 上做一些图像编辑任务的科研,最容易想到地方就是位置编码这一块。我目前随便能想到的做法有两个:
- 直接基于位置编号做超分辨率。想办法修改位置编码的机制,使得所有图像 token 距离 2 个单位时也能某种程度上正常输出图片。以此配置反演一张低分辨率图片,得到纯噪声,重新以图像 token 距离 1 单位的正常配置来生成图片,但旧像素不对新像素做注意力,再想一些办法控制文本那部分,尽量保持旧像素输出不变,最后就能得到两倍超分辨率的结果了。inpainting 似乎也能拿类似的思路来做。
- 目前所有文本 token 的位置默认是
(0, 0),改变文本 token 的位置编号或许能让我们精确控制文本指定的生成区域。当然,这个任务在之前的 Stable Diffusion 里好像已经被做滥了。
总结
在这篇文章中,我们围绕 FLUX.1 相对 Stable Diffusion 3 的改动,仔细阅读了 FLUX.1 在 Diffusers 中的源码。这些改动具体总结如下:
- SD3 是在去噪网络里用下采样 2 倍的卷积实现图块化,而 FLUX.1 通过把 $2 \times 2$ 个图像 token 在通道上堆叠直接实现图块化。
- FLUX.1 目前公布的两个模型都是指引蒸馏过的。我们无需使用 Classifier-Free Guidance,只要把指引强度当成一个约束条件输出进模型,就能在一次推理中得到带指定指引强度的输出。
- FLUX.1 遵照 Stable Diffusion 3 的噪声调度机制,对于分辨率越高的图像,把越多的去噪迭代放在了高噪声的时刻上。但相较 Stable Diffusion 3,似乎不仅训练时有这种设计,采样时也需要用到这种设计。
- FLUX.1 将文本的位置编号设为
(0, 0, 0),图像的位置编号设为(0, i, j),之后用标准的旋转式位置编码对三个维度的编号编码,再把三组编码拼接。这种看似不太合理的位置编号设计方式或许是指引蒸馏导致的,目前从源代码中看不出原 FLUX.1 模型的位置编号设计方式。 - 在原 Stable Diffusion 的 MM-DiT 块之后,FLUX.1 将文本和图像 token 拼接,输入进了一个单流的 Transformer 块。该 Transformer 块遵照之前并行注意力层的设计,注意力层和 MLP 并联执行,在执行速度上有所提升。
FLUX.1 的总模型结构图如下所示。
作为最强开源 DiT 文生图模型,FLUX.1 狠狠打脸了拖拖拉拉刚开源没多久的 Stable Diffusion 3。可以预见,之后大家会把开发图像编辑工作的基础模型从 U-Net 版 Stable Diffusion 逐渐换成 FLUX.1。这方面的研究目前还是蓝海,值得大家投入精力研究。
FLUX.1 还是在科研上能给我们一些启示的。RoPE 都是 NLP 那边已经出了很久的工作了,直到现在才搬到图像生成这边来。我们或许能够把 NLP 或者其他视觉任务中使用的神经网络技术搬到图像生成这边来,不费什么力气地改进现有的图像生成模型。
但是,在搬运 NLP 技术中,我们也要思考如何更合理地在视觉应用中使用这些技术。文本和图像存在本质上的区别:文本是离散的,而图像是连续的。这种连续性不仅体现在图像的颜色值上,还体现在图像像素间的位置关系上。就以这里的旋转式位置编码为例,NLP 中,token 间的距离就得是整数。而在 CV 中,如果我们认为图像是一种连续信号,那么非整数的 token 距离或许也是有意义的。从文本和图像的本质区别出发,我们或许能够把 NLP 的技术更好地适配到 CV 上,而不是把 Transformer 搬过来,然后加数据一把梭。