近期,有两个大型多模态模型于同期公布:一个是来自 Meta 的 Transfusion,另一个是来自 Show Lab 和字节跳动的 Show-o 。好巧不巧,二者都宣称自己的模型是几乎最早将多模态任务用一个 Transformer 完成的,不需要借助额外的文本编码器实现图像生成,同时结合了自回归生成和扩散模型。我很好奇这两篇工作究竟有多少创新,于是快速扫完了这两篇论文,并简单给大家分享一下它们的核心内容。
在这篇文章中,我会快速介绍两篇工作的核心模型架构与部分实验结果。由于我仅对视觉任务比较熟悉,对语言和多模态没有那么了解,我的分析将主要围绕视觉任务。
论文 Arxiv 链接:
Transfusion: https://arxiv.org/pdf/2408.11039
Show-o: https://arxiv.org/pdf/2408.12528
读前准备
在阅读这两篇新工作时,建议大家先熟悉以 Transformer 为代表的自回归生成、以 DDPM、LDM、DiT 为代表的扩散模型、以 MaskGIT (Masked Generative Image Transformer), MAR (Masked autoregressive models, 于 Autoregressive Image Generation without Vector Quantization 论文中提出) 为代表的掩码自回归图像生成这三类生成模型,并简单了解此前较为先进的 Chameleon (Chameleon: Mixed-Modal Early-Fusion Foundation
Models) 多模态模型。本文不会对这些知识做深入回顾,如果读者遇到了不懂的旧概念,请先回顾有关论文后再来看这两篇新文章。
自回归模型
自回归模型用于生成形如 $\mathbf{x}=\{x_1, x_2, …, x_n\}$ 这样的有序序列。自回归算法会逐个生成序列中的元素。假设正在生成第 $i$ 个元素,则算法 $F$ 会参考之前所有的信息 $\{x_j \mid j < i\}$,得到 $x_i = F(\{x_j \mid j < i\})$。比如:
自回归任务最常见的应用场景是文本生成。给定第一个词,生成第二个词;给定前两个词,生成第三个词……。
为了训练实现这一算法的模型,一般我们需要假设每个元素的取值是有限的。比如我们要建模一个生成单词的模型,每个元素是小写字母,那么元素的取值只有 a, b, c, ..., z。满足这个假设后,我们就可以像分类任务一样,用神经网络模型预测的类别分布建模已知之前所有元素时,下一个元素的分布,并用交叉熵损失函数去优化模型。这种训练任务被称为下一个词元预测 (next token prediction, NTP)。
用自回归生成建模某类数据时,最重要的是定义好每个元素的先后顺序。对于文本数据,我们只需要把每个词元 (token) 按它们在句子里的先后顺序编号即可。而对于图像中的像素,则有多种编号方式了。最简单的一种方式是按从左到右、从上到下的顺序给像素编号。
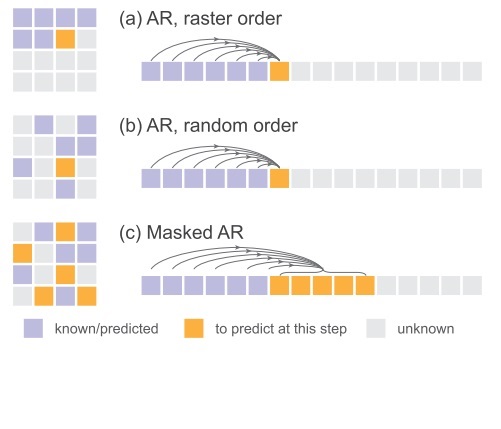
掩码自回归模型
由于图像的像素数很多,用自回归模型一个一个去生成像素是很慢的;另外,按从左到右、从上到下的顺序给像素编号显然不会是最合理的。为了提升自回归模型的速度和表现,研究者提出了掩码自回归模型。它做了两个改进:
1) 相比按序号一个一个生成元素的经典自回归模型,这种模型在每轮生成时可以生成多个像素(下图中的橙色像素)。
2) 相比从左到右、从上到下的固定顺序,像素的先后顺序完全随机(下图中的 (b) 和 (c) )。
由于这种方式下必须一次给模型输入所有像素,并用掩码剔除未使用的像素,所以这种自回归被叫做掩码自回归。
扩散模型
扩散模型将图像生成表示成一个噪声图像 $\mathbf{x}_T$ 从时刻 $T$ 开始随时间变化 $\mathbf{x}_t = F(\mathbf{x}_{t+1})$,最后得到目标图像 $\mathbf{x}_0$ 的过程。和输入输出为部分像素的自回归模型不同,扩散模型的输入输出自始至终都是完整图像。
为了减少扩散模型的计算量,参考 Latent Diffusion Model (LDM) 的做法,我们一般会先用一个自编码器压缩图像,再用扩散模型生成压缩过的小图像。正如 NLP 中将文本拆成单词、标点的「词元化」(tokenize) 操作一样,这一步操作可以被称为「图块化」(patchify)。当然,有些时候大家也会把图块叫做词元,把图块化叫做图像词元化。
严格来说,本文讲到的「像素」其实是代表一个图块的图像词元。用「像素」是为了强调图像元素的二维空间信息,用「图像词元」是强调图像元素在自回归模型中是以一维序列的形式处理的。
有人认为,掩码自回归模型是一种逐渐把纯掩码图像变成有意义图像的模型,它和逐渐把纯噪声图像变成有意义图像的扩散模型原理类似。因此,他们把掩码自回归模型称为离散扩散模型。还有人认为扩散模型也算一种更合理的自回归,每轮输入一个高噪声图像,输出一个噪声更少的图像。但这些观点仅仅是从称呼上统一两种模型,两种模型在实现上还是有不少差别的。
Chameleon
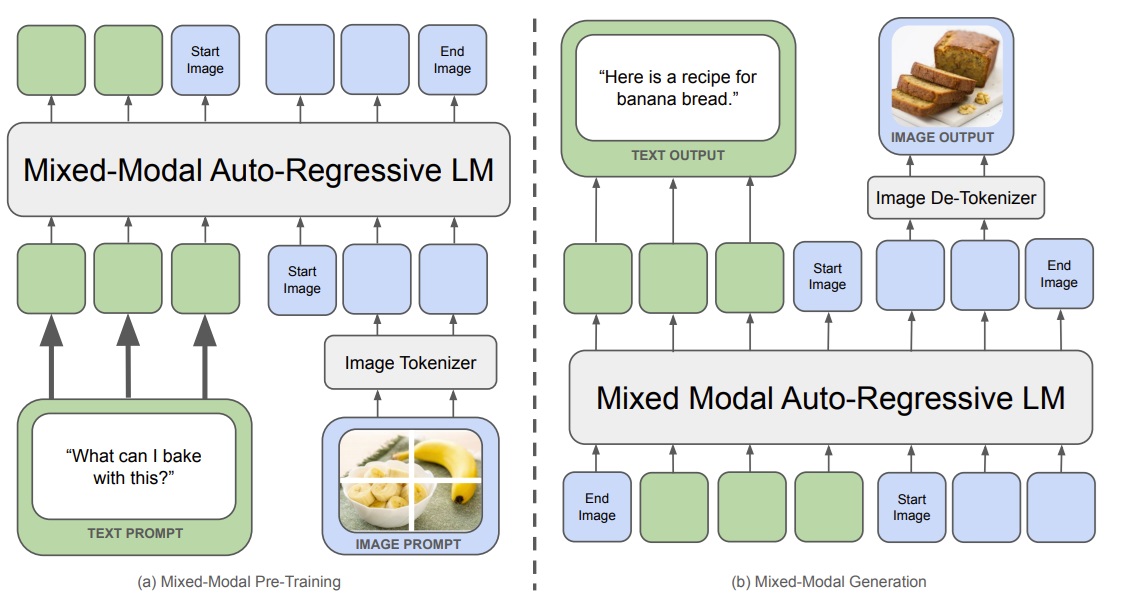
Chameleon 似乎是此前最为先进的多模态模型,它是这两篇新工作的主要比较对象。在语言模型的基础上,Chameleon 并没有对图像的处理多加设计,只是以离散自编码器(如 VQGAN)的编码器为图像词元化工具,以其解码器为图像词元化还原工具,让被词元化后的图像词元以同样的方式与文本词元混在一起处理。
功能与效果
看方法前,我们先明确一下两个多模态模型能做的任务,及各任务的输入输出。
Transfusion 是一个标准多模态模型,也就是一个输入输出可以有图像词元的语言模型。它输入已知文本和图像,输出后续文本和图像。
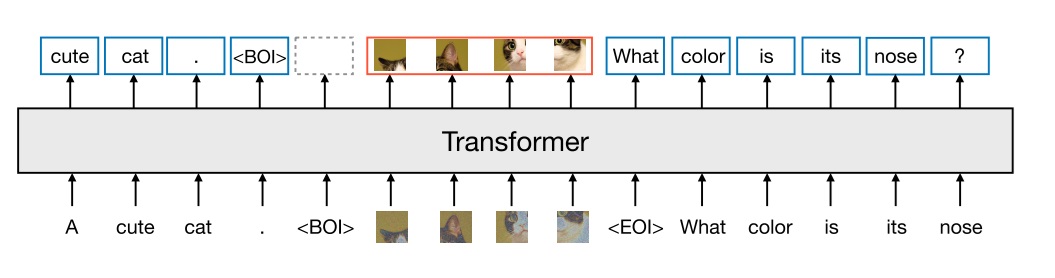
基于这个多模态模型,可以做文生图任务。

这个模型似乎没有为特定任务设置特殊词元,所有图像功能完全靠文本指定。因此,要做图像编辑任务的话,需要在带文本标注的图像编辑数据集上微调。文章指出,只需要在一个仅有 8000 项数据的数据集上微调就能让模型具有一定的编辑能力。

相比之下,Show-o 可以在序列前多输入一个区分任务的特殊词元。因此,Show-o 可以完成多模态理解(输入多模态,输出文本描述)、图像生成(根据文字生成图像或填补图像)、多模态生成(输入输出都包含图片、文本)等丰富的任务。似乎特殊词元仅有多模态理解 (MMU, Multi-modal Understanding MMU)、文生图 (T2I, Text to Image) 这两种。
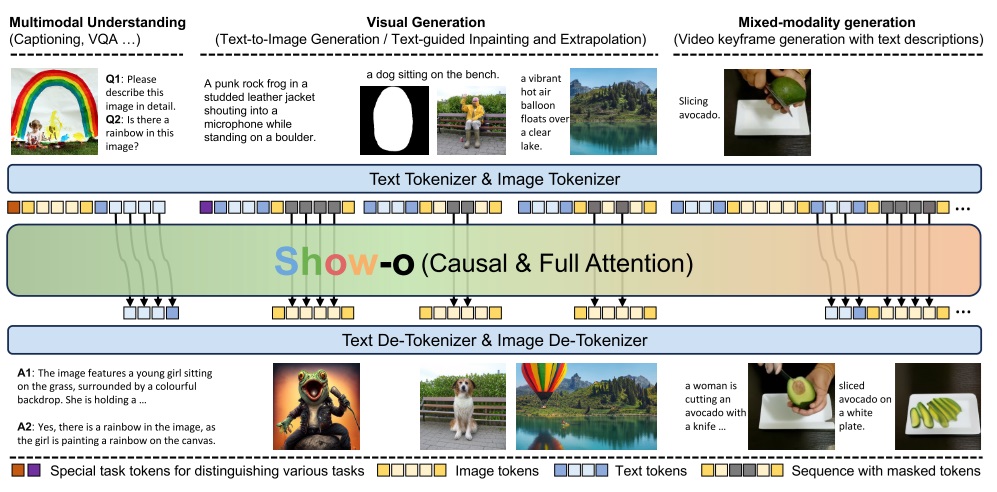
Transfusion 的基础模型在微调后才能做根据文本提示来编辑图像的任务,而 Show-o 的基础模型默认是在此类带有文本提示的图像编辑数据集上微调的。
方法
对于熟悉此前图像生成模型、语言模型的研究者来说,这两篇工作都仅用了现有技术,核心方法非常易懂。这两篇工作并不是试图开发一种新的图像生成技术,而是在考虑如何更好地将现有图像模型融入多模态模型。
在读新技术之前,我们先以 Chameleon 为例,看一下之前的多模态模型是怎么做生成的。在我看来,之前的多模态模型不应该叫「多模态模型」,而应该叫「强行把图像当成词元的语言模型」。语言模型在处理文本时,文本中的词语、标点会根据规则被拆成「词元」,成为模型的最小处理单位。然而,要用同样的方式处理图像,就要定义什么是「图像词元」。受到之前图像离散压缩模型(以 VQGAN 为代表)的启发,大家用一个编码器把图像切成图块,每个图块可以用一个 1, 2, 3 这样的整数序号表示,再用一个解码器把用序号表示的图块翻译回真实图像。这里的带序号图块就和文本里的单词一样,可以用「词元」来表示。文本、图像都被统一成词元后,就能用标准 Transformer 的下一个词元预测任务来训练多模态模型。
如下图所示,训练时,文本基于程序规则变成词元,而图像经过一个编码器模型变成词元。两类词元被当成一类数据,以同样的方式按下一个词元预测任务训练。生成时,多模态模型自回归地生成所有词元,随后文本词元基于程序规则恢复成文本,而图像词元通过解码器模型恢复成图像。
这种多模态模型最大的问题是没有充分设计图像词元生成,还是暴力地用 Transformer 自回归那一套。虽然有些模型会多加入一些图像生成上的设计,比如 LaVIT (Unified Language-Vision Pretraining in LLM with Dynamic Discrete Visual Tokenization) 用扩散模型来做图像词元的解码,但核心的图像词元生成还是离不开标准自回归。
Transfusion 和 Show-o 的设计初衷都是引入更先进的图像生成技术来改进图像词元生成。先看 Show-o。要改进标准的一个一个按顺序生成图像词元的图像自回归模型,最容易想到的做法就是按照 MaskGIT, MAR 那一套,将标准自回归换成掩码自回归。在做掩码自回归时,像素的先后顺序完全随机,且一次可以生成多个像素。另外,图像词元之间可以两两互相做交叉注意力,而不用像文本词元一样只能后面的对前面的做交叉注意力。
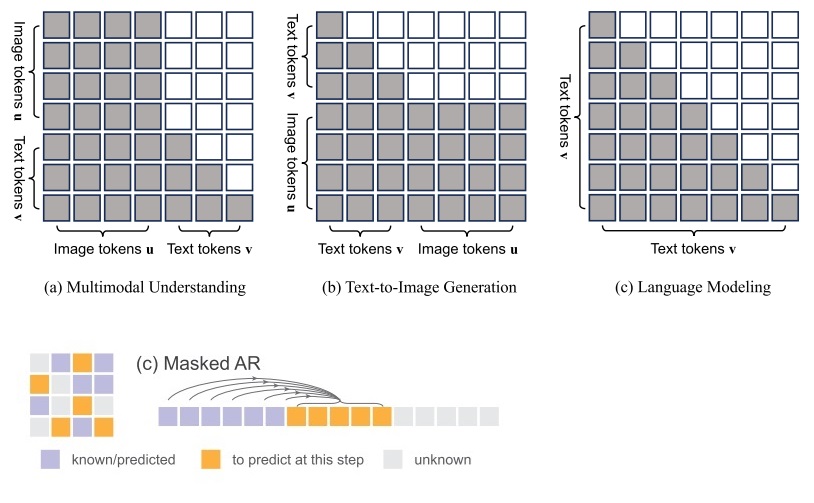
Show-o 莫名其妙地把自己的图像生成模型称为离散扩散模型。如前文所述,叫离散扩散模型还是掩码自回归,只是一个称呼上的问题。由于问题建模上的重大差异,大家一般还是会把扩散模型和掩码自回归看成两类模型。
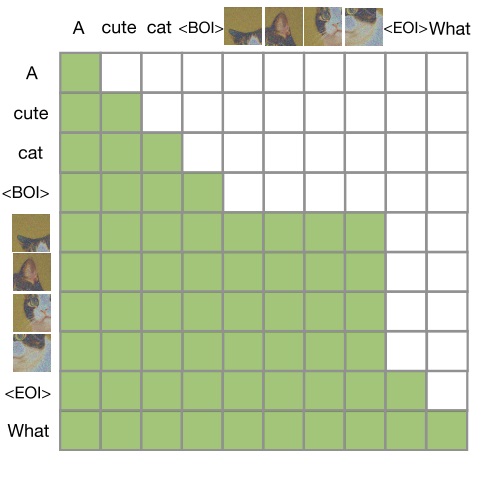
而 Transfusion 更加激进地在革新了多模态模型中的图像生成方式。现在最好的图像生成技术不是扩散模型吗?我们干脆直接把整个扩散模型搬过来。于是,在 Transfusion 生成多模态内容时,程序会交替执行两种模式:在语言模型模式下,程序按标准自回归逐个生成文本词元。一旦生成了特殊词元 BOI (begin of image),就切换到扩散模式。在扩散模式下,程序按 DiT, SD 3 (Stable Diffusion 3) 那种标准扩散模型的方式,一次性生成所有图像词元。结束此模式后,程序往词元序列里填一个 EOI (end of image),重返语言模型模式。
同理,在训练时,两种模态也用不同的任务来训练。语言模型老老实实地按下一个词元预测训练,而扩散模型那部分就按照训练扩散模型的标准方式,先给所有图像词元加噪,再预测噪声。因此,只看图像生成任务的话,Transfusion 更像 SD 3 这种文生图模型,而不像此前的基于语言模型的多模态模型。
Transfusion 和 SD 3 之间的最大区别在于,文本词元还是按照语言模型那一套,只能在交叉注意力看到之前的文本词元。而图像词元之间两两都能看到。这种交叉注意力的设计和 Show-o 是一模一样的。当然,由于现在文本也会在同一个 Transformer 里处理,所以 Transfusion 自己就扮演了解读文本的工作,而不像 SD 3 那样还需要单独的文本编码器。
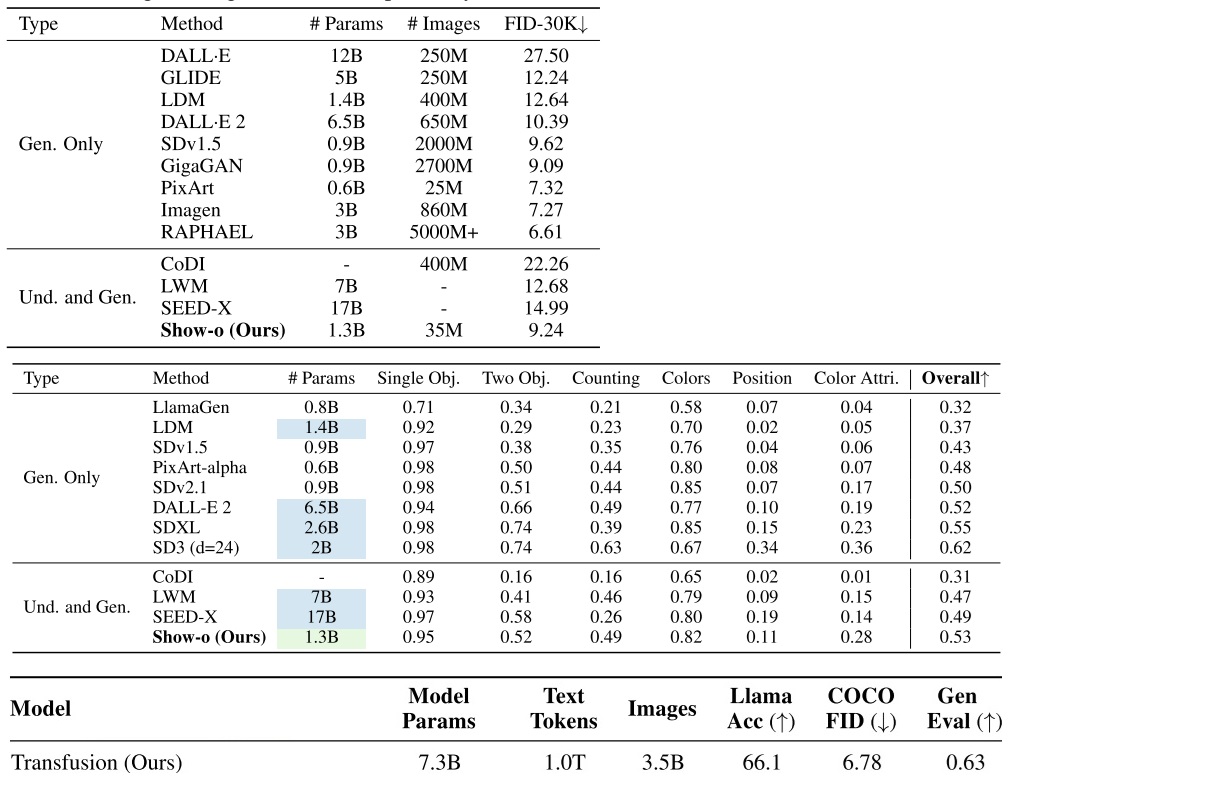
定量评测结果
我们最后来看一下两篇文章展示的定量评测结果。
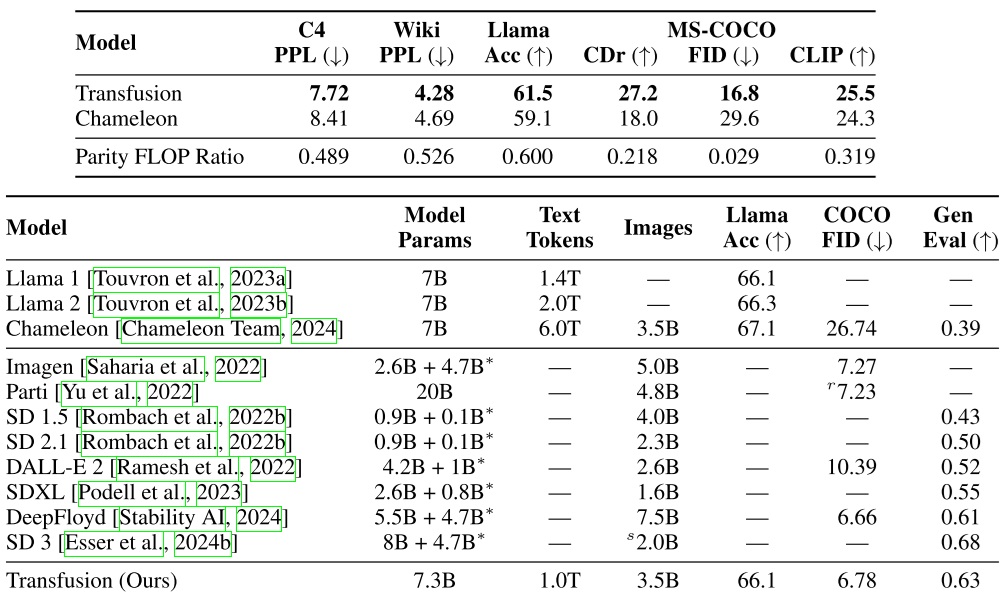
Transfusion 用了许多篇幅来展示它与 Chameleon 之间的对比。从数值指标上看,Transfusion 全面领先 Chameleon。明明没有对文本任务做特别的优化,Transfusion 却在文本任务超越了 Chameleon,这挺令人惊讶的。为了探究这一现象的原因,作者从同一个预训练语言模型开始,以同样的配置训练了 Transfusion, Chameleon。结果显示,相比加入图像扩散模型,加入 Chameleon 那种离散图像词元对文本指标的损害更大。作者猜测,这是因为扩散模型更加高效,模型能够把更多精力放在文本任务上。
而从图像生成模型的对比上看,Transfusion 比之前多数文生图模型都要好,只是比顶尖文生图模型 SD 3 要差一点。
再来看 Show-o 的评测结果。Show-o 在部分文本指标上超过了之前的语言模型。作者也坦言,这些指标仅表明 Show-o 有潜力在文本任务上做到顶尖。
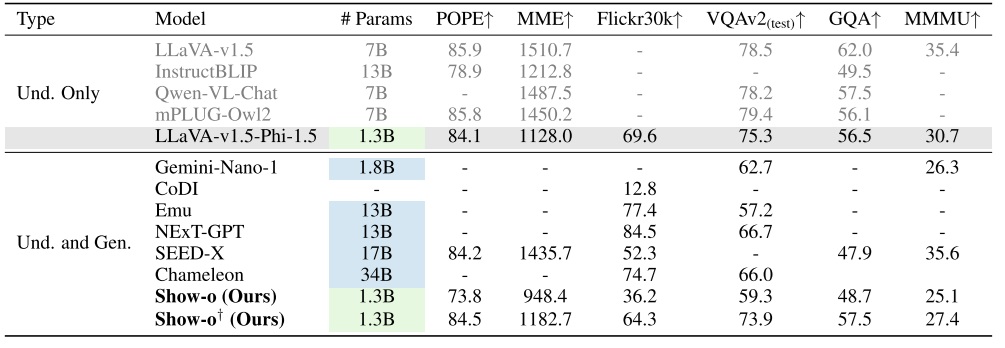
Show-o 也展示了图像任务的指标。和 Transfusion 一样,Show-o 展示了表示图像质量的 COCO FID 指标以及评价文本图像匹配度的 GenEval 指标。Show-o 在图像指标上超越了此前多数多模态模型,且超越了 Stable Diffusion 2.1 等图像生成模型。但是其图像指标比 Transfusion 还是差了不少。Show-o 的最大优点是需要的图像训练数据远远少于其他模型。
总结与讨论
此前多模态模型都只是强行把图像变成离散图像词元,再用标准自回归来生成图像词元。为了改进这些多模态模型,无独有偶,Transfusion 和 Show-o 都用到了更先进的图像生成技术。Show-o 将标准自回归改成了更强大的掩码自回归,而 Transfusion 激进地引入了完整的图像扩散模型,并把文本生成和图像生成当成两个相对独立的任务。二者的相同之处如下:
- 两个多模态模型都用同一个 Transformer 来处理文本和图像。
- 两个模型的 Transformer 都使用了同样的交叉注意力机制。文本词元只能看到此前的图像、文本词元,而图像词元可以看到此前的文本词元和当前所有图像词元。
二者的不同之处在于:
- Transfusion 使用标准扩散模型实现图像生成,而 Show-o 使用掩码自回归实现图像生成。Show-o 强行将自己的图像生成模型称为「离散扩散模型」,有借扩散模型的名头宣传之嫌。
- Transfusion 没有用特殊词元来区分不同任务。要用 Transfusion 编辑图像,需要在基础模型上用图像编辑数据集微调。Show-o 用特殊词元来区分不同任务,默认支持文本理解、图像生成、图像编辑、多模态生成等多种任务。
- 二者在文本、图像指标上都超越了之前的多模态模型。但二者相互对比之下,Transfusion 的表现更好,而 Show-o 需要的训练资源少得多。
我再来谈一下我看完这两篇文章后的一些感想。此前我对多模态模型很不感兴趣,觉得它们就是在语言模型的基础上,强行加入图像信息,然后加数据、加显卡,大火乱炖,没有太大的创新。而 Transfusion 和 Show-o 的设计令我眼前一亮。我觉得这两篇文章的结果再次表明,图像和文本的处理方法不应该是一致的,不能强行把文本自回归那套方法直接搬到图像任务上。不管是换成 MaskGIT 掩码自回归那一套,还是完全用扩散模型,都比之前的方法要好。
而究竟是掩码自回归好还是扩散模型更好呢?在我看来,扩散模型是更好的。文本是离散的,而图像是连续的。这种连续性不仅体现在图像的颜色值上,还体现在图像像素间的位置关系上。强行用 Transformer 自回归生成图像,一下子把这两种连续信息都破坏了。而何恺明团队近期的 MAR 工作则试图找回图像在颜色值上的连续性,但依然无法充分利用空间上的连续性。相比之下,扩散模型每步迭代都是对整幅图像做操作,不会破坏图像的连续性。这两个多模态工作也反映了这一点,Transfusion 的表现要比 Show-o 好很多。
在生成图像时,Transfusion 的行为几乎和 SD 3, FLUX.1 这些文生图模型一样了。两类模型的区别在于,SD 3 它们得用一个预训练的语言处理模型。而 Transfusion 用同一个 Transformer 来处理文本、图像信息。尽管现在 Transfusion 还没有超过 SD 3,但我认为文生图任务本质上是一个多模态任务,这两类模型的后续发展路线很可能会交汇到一起。文生图也应该从多模态中汲取经验。比如我们在 SD 3 的基础上,加入一些语言任务上的学习,说不定能进一步提升文生图时的图文匹配度。
当然,仅根据我读完这两篇文章后有限的认知,我认为多模态并不是一个值得广大科研人员投入的研究方向,而只适合有足够资源的大公司来做。其根本原因是验证多模态设计的代价太大了。在图像生成领域,要验证一个生成模型好不好,我们拿 ImageNet,甚至拿只有几万张图像的人类数据集训练及评测,都很有说服力。而多模态任务必须在大量文本、图像数据集上训练,评测文本、图像上的多种指标,小一点的团队根本做不来。这样,各种小创新都难以验证。而没有各种各样的小创新,领域也就很难快速发展。所以多模态只能不断从纯语言生成、纯图像生成方向找灵感,很难有仅属于多模态任务的创新。