论文速览
平时我自己读新论文时,往往简单看一下摘要和图表就能差不多明白文章的大意。而要用一篇博文来详细介绍新论文的设计动机、实现方法,需要花多得多的时间来写作。为了能分享更多的新论文,并且让我自己能够更好地整理论文间的关系,从这篇文章开始,我会不定期发表「论文速览」类文章,以简明扼要的文字来帮助计算机视觉的同行们快速了解新论文。
和发文频繁的自媒体相比,我的论文速览文章几乎不会展示论文的结果,仅会从科研角度介绍文章的贡献及方法,并给出我的批判性分析。和我之前的论文详解文章相比,这个新系列的文章会用更少的文字介绍背景,几乎不介绍方法细节,力求用更少的文字来表达关键信息,提升文字沟通效率。不过另一方面,我会花更多心思在介绍新论文与过往论文的关系上,为不熟悉某些背景知识的读者提供学习途径,以填补背景介绍上的空缺。
Diffusion Forcing
视频扩散模型普遍存在视频质量随着视频长度增加不断下降的问题。为此,论文作者提出了 Diffusion Forcing 这一建模任何序列生成问题的新范式:在训练该扩散模型时,序列中的每个元素会独立地添加不同强度的噪声。作者在简单视频生成、决策 (decision-making) 任务上验证了这种生成范式的有效性。我将主要从视频生成的角度介绍本工作。
以往工作
稍后我们会了解到,Diffusion Forcing 与此前两种主流序列生成范式密切相关:自回归生成与全序列扩散模型。
在序列的自回归生成中,模型会不断根据序列前 $n-1$ 个元素,预测下一个元素(第 $n$ 个元素)。自回归生成在 NLP 中最为常见,RNN、Transformer 用的都是这种生成方法。
扩散模型可以直接生成任何形状的数据。如果我们不把视频视为一种由图像组成的序列数据,而是将其视为一种「三维图像」,那么我们可以直接将 2D 图像扩散模型简单地拓展成 3D 视频扩散模型。这种做法在这篇论文中被称为「全序列扩散模型」。使用这一方法的早期工作有 DDPM 的作者提出的 Video Diffusion Models。Stable Diffusion 的作者也基于 LDM 提出类似的 Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models(Video LDM)工作。
全序列扩散模型仅能生成固定长度的视频。为了将其拓展到长视频生成,还是得将其和自回归结合起来。但是,自回归视频生成存在着生成质量与训练集质量不匹配的问题。Stable Video Diffusion 等工作参考 Cascaded Diffusion Models 的做法,通过给约束图像/视频帧加噪声缓解此问题。
AR-Diffusion: Auto-Regressive Diffusion Model for Text Generation 进一步探讨了自回归生成与全序列扩散模型的结合方法:在生成文本时,不同时刻的文本噪声不同,越早的文本上的噪声越少。无独有偶,FIFO-Diffusion: Generating Infinite Videos from Text without Training 提到了如何在预训练视频扩散模型上,以不同的噪声强度来生成不同的视频帧。或许是受到这些工作的启发,Diffusion Forcing 系统探讨了如何在训练时独立地给序列元素添加噪声。
科研动机
本工作的作者发现了自回归与全序列扩散模型的不足之处,并认为这两种生成范式是互补的:
- 自回归不能在推理时加入新的优化目标,且存在着前述的训练采样质量不匹配导致的降质问题。
- 全序列扩散模型不能生成变长的序列。
反过来讲:
- 全序列扩散模型可以在推理加入 Classifier-guidance,且在固定序列长度内几乎不存在降质。
- 自回归可以生成变长序列。
那能不能把二者结合起来呢?在推理时,我们希望序列是按时间顺序先后生成的。同时,从噪声强度这一维度上,我们希望每个元素能够从完全带噪到完全清晰逐渐生成。结合二者的方法是:在采样时,较早的元素有较少的噪声,较新的元素有较多的噪声,不同噪声强度的元素在序列中同时生成。比如采样分3步完成,共生成3帧,那么一步去噪会让$[x_1^{1/3\cdot T}, x_2^{2/3\cdot T}, x_3^{T}]$变成$[x_1^0, x_2^{1/3\cdot T}, x_3^{2/3\cdot T}]$。
为了实现这样的采样,我们在训练时就要让每一元素能够在其他元素和自己的噪声强度不同时也能顺利去噪。和以往的工作不同,本工作的作者发现,训练时我们不必和推理时一样固定每一元素的噪声强度,而是可以独立地对每帧随机采样噪声强度。
简单视频生成模型
本文的想法十分简洁,只需要在 DDPM 序列生成模型上把训练和推理时的噪声强度换掉即可。为了进一步了解本工作的方法,我们来看一下论文中有关视频模型的方法与实验。
整体上看,训练时,方法和 $\epsilon$ 预测的普通 DDPM 一样,只是不同帧噪声强度不一样。
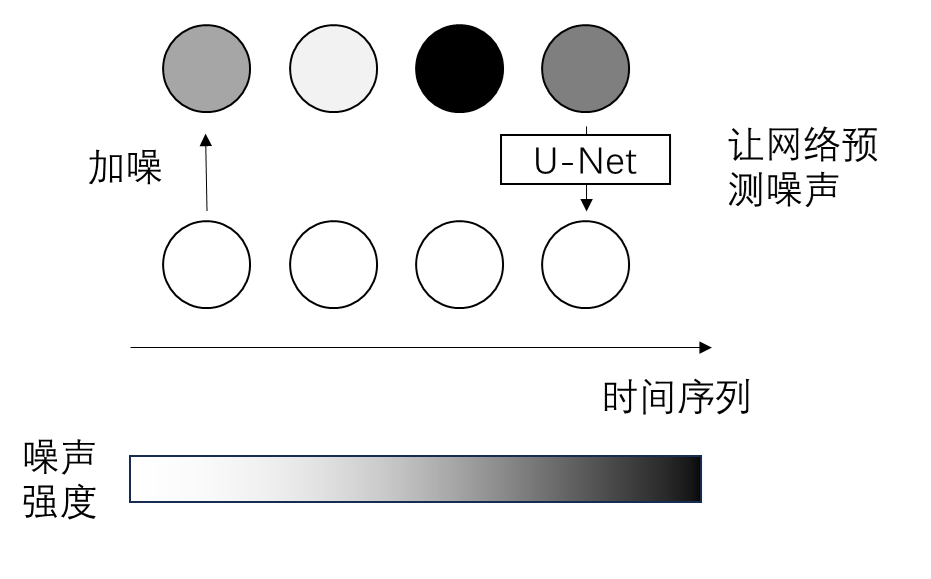
在帧间关系上,Diffusion Forcing 用因果(causal)关系建模,即当前帧只能看到之前帧的信息。
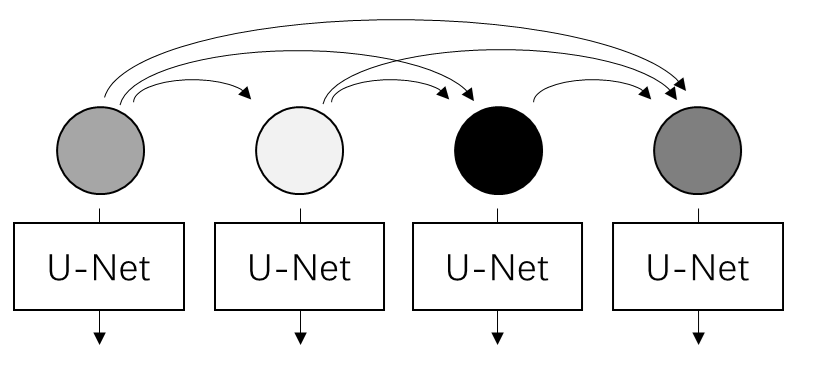
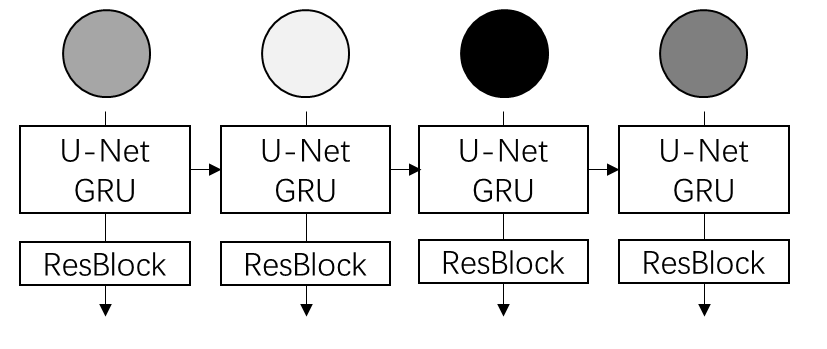
具体来说,本工作用 RNN (准确来说是 GRU)的隐变量来建模之前帧传过来的信息。加入了 RNN 后,论文把本来很简单的公式变得无比复杂,不建议读者深究论文中有关 RNN 的内容。
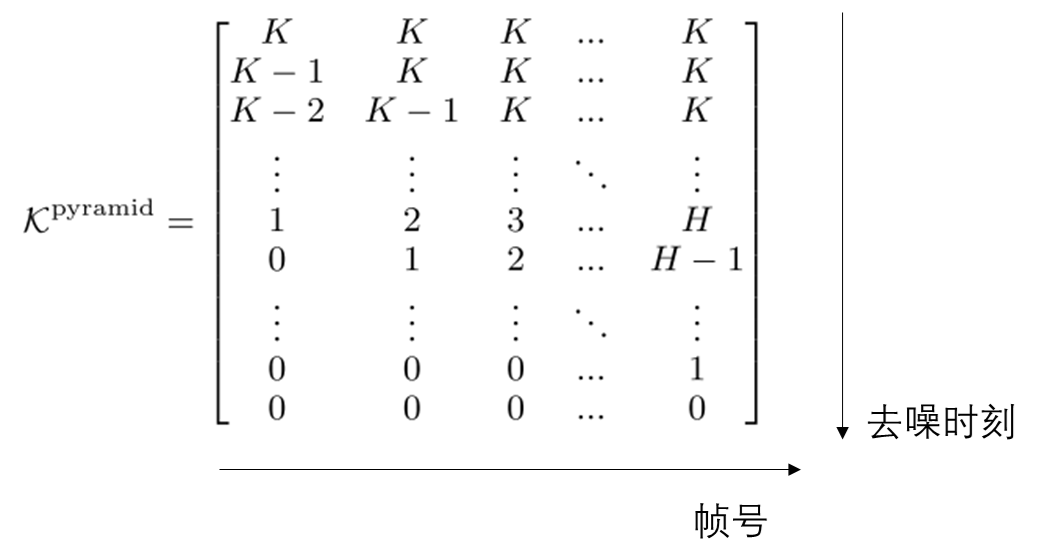
在采样时,由于不同帧的噪声强度不同,现在我们需要定义一个二维的噪声强度表,表示每一帧在不同位置及不同去噪时刻的噪声强度。为了让每一时刻的噪声强度不同,一开始较新帧的去噪时刻会停留在原地。作者在附录中介绍了同时刻去噪的详细设计。
作者发现,Diffusion Forcing 的这种序列生成方式可以自然地推广到无限长度的视频生成上:在生成下一个片段时,不用滑动窗口,直接把 RNN 的初始隐变量初始化为上一个片段的隐变量输出。
作者用同样的 RNN 结构训练了两个基准模型:一个自回归模型,一个全序列因果扩散模型。定性结果表明,不管是在预定视频长度内,还是超出原本长度的长视频生成,Diffusion Forcing 的结果均好于基准方法。结果可以在官方项目网站上查看:
https://boyuan.space/diffusion-forcing/
批判性分析
论文开头说自回归模型在推理时缺少添加约束的方法。但这对视频生成来说并不致命,因为一般可以在训练时加入约束,推理时用 Classifier-free Guidance 就行了。
作者说出于简洁,他们在论文中用 RNN 实现了 Diffusion Forcing。但很明显 3D U-Net 才应该是直观上最简单实用的实现方法,毕竟最早期的视频扩散模型就是拿 3D U-Net 做的。在官方仓库中,有本科生帮他们实现了一个 3D U-Net 加时间注意力的模型,比原来视频模型效果要好。
我认为本文的视频生成基准方法设置过低。对于自回归视频生成/图生成视频,现在大家都会参照 Cascaded Diffusion, 对约束图像加噪并把噪声强度做为额外约束传入当前帧的生成模型。这种设计和 Diffusion Forcing 原理相似。为了体现新方法的好处,有必要跟这个更加强大的基准自回归方法做对比。
作者对于全序列视频扩散模型的设计也很奇怪。全序列视频扩散模型的初衷就是把视频当成 3D 图像来看待,允许帧间两两交换信息,只保证预定长度内的视频是连贯的。作者现在用 RNN 实现了一个因果版全序列视频模型,这个模型的表现肯定是不如非因果版的。虽然作者说 Diffusion Forcing 在因果视频生成上总是比全序列扩散模型更加连贯,我很怀疑去掉了因果这个条件后 Diffusion Forcing 还能否比得过。
Diffusion Forcing 在视频生成的主要好处应该体现在超出预定长度的长视频生成。因此,哪怕在预定长度内比不过全序列扩散模型,也没有关系。作者应该比较结合自回归和全序列扩散模型的方法,比如用 Stable Video Diffusion 这种图生视频模型,把上一个视频的末帧当作下一个视频的首帧约束,证明 Diffusion Forcing 在长视频生成上的优越性。
综上,我认为作者在视频生成任务上的实验是不够充分的。也的确,这篇论文有一半篇幅是在决策任务上,没有只讲视频生成任务。我相信 Diffusion Forcing 的设计会在长视频生成上缓解降质问题,这需要后续大公司的工作来跟进。但是,长视频的根本问题是记忆缺失,这一本质问题是 Diffusion Forcing 这种方法难以做好的。
这篇工作对我最大的启发是,我们一直把视频当成完整的 3D 数据来看待,却忘了视频可以被看成是图像序列。如果把视频当成 3D 数据的话,不同帧只能通过时序注意力看到其他帧在当前去噪时刻的信息;而对于序列数据,我们可以在不同帧的依赖关系上做更多设计,比如这篇工作的不同去噪强度。我很早前就在构思一种依赖更加强的序列生成范式:我们可不可以把序列中其他元素的所有去噪时刻的所有信息(包括中间去噪结果及去噪网络的中间变量)做为当前元素的约束呢?这种强约束序列模型可能对多视角生成、视频片段生成等任务的一致性有很大帮助。由于生成是约束于另一个去噪过程的,我们对此去噪过程做的任何编辑,都可以自然地传播到当前元素上。比如在视频生成中,如果整个视频约束于首帧的去噪过程,那么我们用任意基于扩散模型的图像编辑方法来编辑首帧,都可以自然地修改后续帧。当然,我只是提供一个大致的想法,暂时没有考虑细节,欢迎大家往这个方向思考。
有人肯定也会想到能否把 Diffusion Forcing 拓展到图像像素间关系上。我认为要实现训练是完全没有问题的,问题出在推理上:Diffusion Forcing 在推理时需要预定义不同元素间的去噪强度。对于视频这种有先后顺序的数据,我们很自然地可以让越早的帧噪声强度越低。但是,对于图像来说,如何定义不同像素在不同去噪步数时的去噪强度并不是一个易解的问题。