最近一篇论文因其吸引眼球的标题而刷屏科技自媒体:”The GAN is dead; long live the GAN!
A Modern Baseline GAN (GAN 已死?GAN 万岁!一个现代 GAN 基模)”。我不喜欢这种浮夸的标题,因为真正有价值的论文不必靠标题吸引人。带着怨气通读完论文后,我发现这篇论文果然没有做出特别大的创新。
这篇论文提出了一种叫做 R3GAN (读作 “Re-GAN”)的 GAN 基准模型。R3GAN 综合使用了 RpGAN 损失函数和特殊的梯度惩罚 (Gradient Penalty, GP) 损失函数,并基于前沿卷积网络 ConvNeXt 重新设计了一套 GAN 网络。实验表明 R3GAN 在 FFHQ 和低分辨率 ImageNet 图像生成上有着比肩扩散模型的 FID 分数。该工作主要是在工程实验上做了贡献,没有提出太多科研创新。在这篇博文里,我会简单介绍 R3GAN 的主要实现细节,并为各项细节提供参考文献而不做深入讲解,感兴趣的读者可以查阅文末总结的参考文献。
GAN 回顾
在这一小节里,我们会回顾读懂 R3GAN 必备的和生成对抗网络 (GAN) 相关的知识。
GAN 基础知识
和其他多数生成模型一样,GAN 的训练目标是建模一个好采样的分布(高斯分布)到一个不好训练的分布(训练数据集)的映射方式。具体来说,GAN 会用一个生成器 (Generator) 把来自高斯分布的噪声 $z$ 设法变成图像 $x$。其他生成模型大多有自己的一套理论基础,并根据某理论来设置生成器的学习目标。而 GAN 用另一个神经网络——判别器 (Discriminator) 来学习生成器的训练目标。
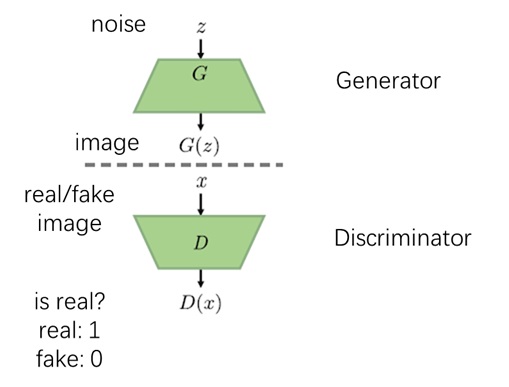
两个模型的学习是通过一种博弈游戏实现的:判别器试图分辨图片是否是「假」的,或者说是否是生成出来的,而生成器通过提升生成图像质量来让判别器无法分辨图片真假。二者共用一套优化目标,但一方希望最小化目标而另一方希望最大化目标。
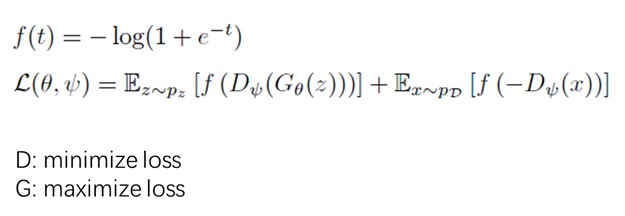
在上面的损失函数中,$f$ 有很多种选取方式。R3GAN 选用了 softplus 函数,如上图所示。
两大经典结构 DCGAN 和 StyleGAN
GAN 的开山之作是用全连接网络实现的。在 GAN 的后续发展过程中,有两个经典的网络结构:2016 年 的 DCGAN 和 2019 年的 StyleGAN。
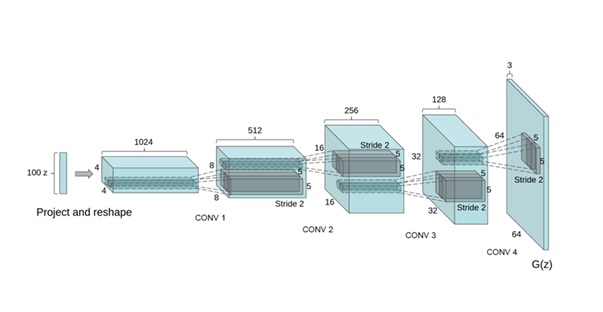
DCGAN 是一个生成器基于卷积神经网络 (CNN) 的 GAN。它的特点是对低通道特征逐渐上采样并逐渐减少通道数,直至生成目标大小的三通道图像。
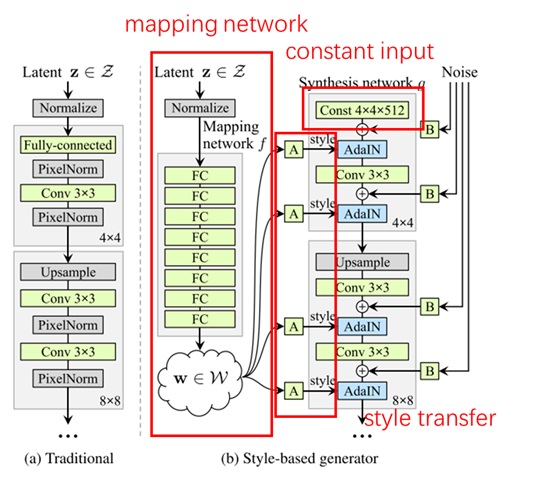
StylGAN 是一个训练较稳定且适合做图像编辑的 GAN。和传统 GAN 生成器相比,StyleGAN 从一条「旁路」输入被映射网络 (Mapping Network) 预处理过的噪声 $z$,此处信息注入的方式是风格转换 (Style Transfer) 中的 AdaIN 操作。由于输入噪声的方式变了,原来的低分辨率特征图输入被换成了一个常量。
两大难题:难收敛和模式崩溃
相比其他生成模型,GAN 常被诟病「难训练」。这种难训练体现在难收敛、模式崩溃 (Mode Collapse)。难收敛即意味着模型对数据集拟合效果不佳,我们可以用 FID 来评估模型输出与训练集的相似程度。模式崩溃指的是对于一个多类别数据集,模型只能生成其中少数类别,示意图如下所示(图片来源)。为了检测是否出现模式崩溃,我们既可以让网络随机生成大量图片并用另一个分类网络统计其中出现的类别数,也可以用生成召回率 (recall) 来大致评估模型的采样丰富度。

R3GAN 实现方法
R3GAN 在引言里把 StyleGAN 中的各种提升 GAN 稳定性的小技巧批判了一通,并主张应该使用尽可能简洁的 GAN 生成器。虽然论文是这样写的,但实际上 R3GAN 是在更早的 DCGAN 的基础上,更新了损失函数,并用上了最新的 CNN 结构,和 StyleGAN 结构几乎无关。我们来从这两个方面来学习 R3GAN:损失函数和模型结构。
损失函数
在描述博弈游戏的 GAN 损失上,R3GAN 把标准 GAN 损失换成了 RpGAN (relativistic pairing GAN) 论文中的 GAN 损失。相比之下,RpGAN 损失用一对真假样本的判别器输出之差送入激活函数 $f$,而不是分别把真假样本的判别器输出送入 $f$。

根据之前的研究结果,作者从直觉和理论上简单解释了 RpGAN 的好处:
- 以前的 GAN 损失只要求判别器区分真假样本,而不要求真假样本之间的距离要尽可能大。通过把一对真假样本的差输入损失函数,RpGAN 损失可以让真假样本之间的差距尽可能大。
- 根据之前论文的理论分析,在一些简单的配置下,标准 GAN loss 有数量指数增长的较差局部极小值,而 RpGAN loss 的每个局部极小值都是全局最小值。
R3GAN 还重新对最佳的梯度惩罚(Gradient Penalty, GP)损失函数做了消融实验。$n$-GP 表示让模型对输入的梯度尽可能靠近实数 $n$,从而使得训练更加稳定。常用的 GP 有 0-GP 和 1-GP:
- 0-GP:最优情况下,模型对任意输入都给出完全一样的结果。
- 1-GP:最优情况下,模型的输出对输入平滑变动:输入张量的范数变 1,输出张量的范数也变 1。
作者认为 0-GP 对 GAN 判别器是较好的。因为当生成器的输出完全和训练集一样时,判别器是无法区分任何输入的,对任何输入都会给出一样的输出。
对判别器的 GP 有 $R_1$ 和 $R_2$ 两种形式,分别表示对真/假数据采取 GP。作者发现同时用 $R_1$ 和 $R_2$ 更好。

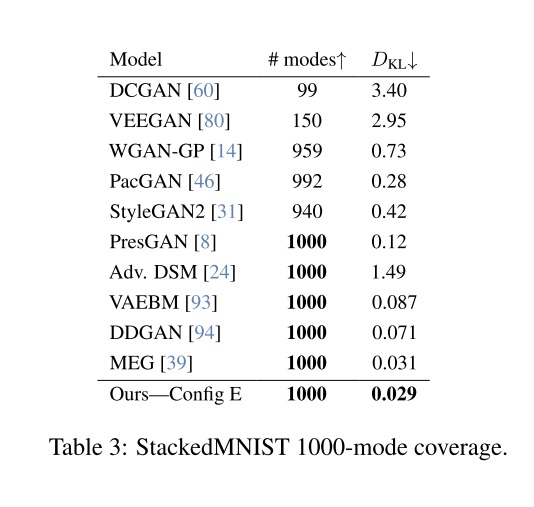
总结一下,R3GAN 使用的损失函数为 RpGAN + $R_1$ + $R_2$。作者用简单的实验证明这是最优的。如下图所示,在一个有 1000 种类别的简单数据集上,最佳损失配置能够生成所有类别的数据,且有更小的分布距离 $D_{KL}$ (和 FID 指标类似,越小越好)。不用 RpGAN 损失会同时降低输出多样性和收敛度,不用 $R_2$ 会使训练完全无法收敛。

现代化的卷积网络
找出了一个简洁而有效的损失函数后,R3GAN 论文接着探究了更优的卷积网络结构。文中提及了五套配置:
- A:原版 StyleGAN2
- B:把 StyleGAN2 里的绝大多数设计删掉,让模型和 DCGAN 几乎相同。
- C:换用上一节里发现的新损失函数
- D:把类似 VGG 的神经网络加上 ResNet 中的残差连接
- E:用 ConvNeXt 里的模块更新 ResNet
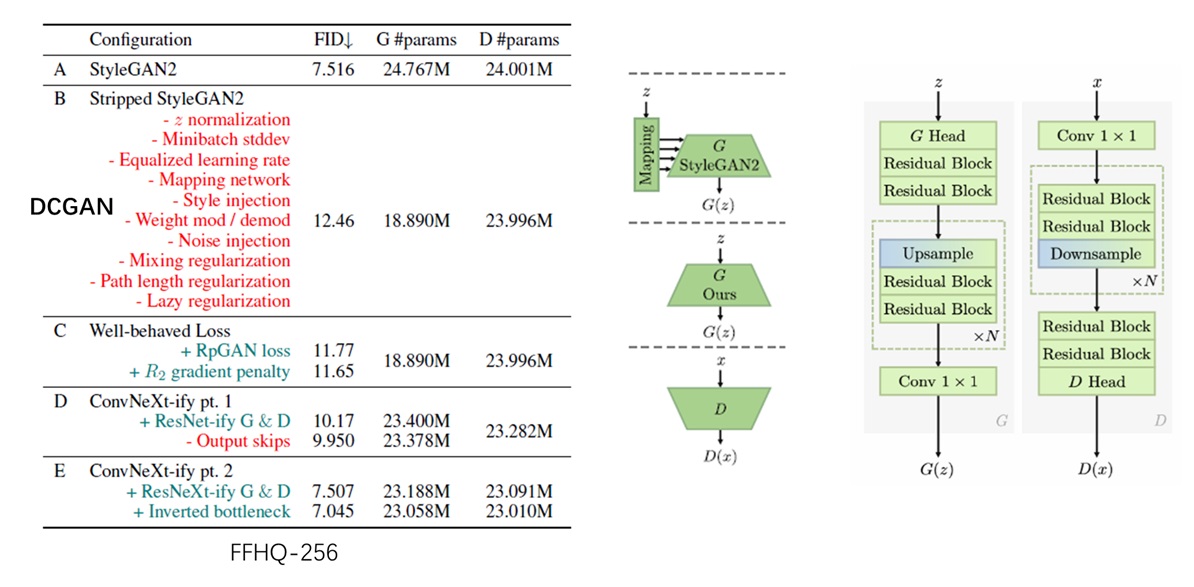
我不明白作者为什么要强行从 StyleGAN2 开始做实验,然后把 StyleGAN2 中的设计批评一顿,删掉全部设计,再换成一个更早期的 DCGAN。直接用 DCGAN 不是更加简洁吗?我猜测是因为作者用了 StyleGAN2 的代码做开发,花很多精力把 StyleGAN2 删成了 DCGAN。既然代码都改了,不写进论文就太浪费了。
我们跳过配置 A,直接看配置 B 和早期的 DCGAN 有什么区别。经作者总结,配置 B 中比较重要的几项区别有:
- a) 用 $R_1$ 损失。
- b) 用较小的学习率且关闭 Adam 优化器中的动量
- c) 所有网络中均不使用 Normalization 层
- d) 用 bilinear 上采样代替反卷积
其中,不改 a), b), c) 会使训练失败。d) 是当今神经网络上采样的标准配置,可以防止出现棋盘格 artifact。
配置 C 中的新损失函数我们已经在上一节中讨论过了。
包括 StyleGAN 在内,此前 GAN 的神经网络多采用了类 VGG 结构,没有残差块。而配置 D 将标准 ResNet 中的 1-3-1 残差块引入了网络。
配置 E 则是进一步更新了卷积层的设计。该配置首先引入了 group convolution 操作(将通道分组,同组通道相互连接。group=1 即 depthwise convolution)。由于该操作更加高效,网络能够在总运行时间不变的前提下加入更多参数。此外,配置 E 还用到了 ConvNeXt 中的反瓶颈(inverted bottleneck)块,该模块的设计灵感来自于 Transformer 中的全连接层。
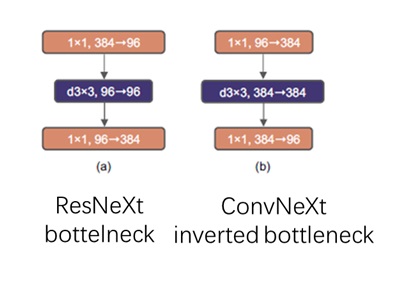
我们再看一次各配置的简单消融实验结果。看起来新损失函数并没有多大的提升,最后比较有效的是网络架构的改进。最好的配置 E 模型能够略优于 StyleGAN2。
定量实验结果
最后,我们来看论文中的定量结果。如前所述,我们主要关心 GAN 的两个指标:多样性与收敛度/图像质量。前者能够通过数类别或者召回率反映,后者能够通过与训练集的 FID(以及本文使用的 $D_{KL})$反映。
多样性
在小型多类别数据集上,R3GAN 能够生成出所有类别,且有最好的训练集相似度。而 StyleGAN2 无法生成少数类别。
另一个能够反映图像多样性的指标是召回率,它大致表示了训练集有多少内容能够在生成集里找到。论文没有提供表格,只简单说了一下 CIFAR-10 上 StyleGAN-XL 是 0.47,R3GAN 0.57。但总体来看 R3GAN 的召回率总是会低于扩散模型。
收敛度
本工作宣传时的一大亮点是它在部分数据集的 FID 分数超过了扩散模型。我们看一下本工作在单一、多样数据集上的 FID 结果。
先看经典的 FFHQ 人脸数据集。在这种多样性较低的数据集上,GAN 的表现一直很不错。R3GAN 的 FID 好于 StyleGAN2 和多数扩散模型,且只需要一次推理 (NFE=1)。但它的 FID 并没有优于此前最好的 GAN 模型。当然,此前的 GAN 用了一种提升 FID 而不提升图像质量的技巧,R3GAN 没有用。
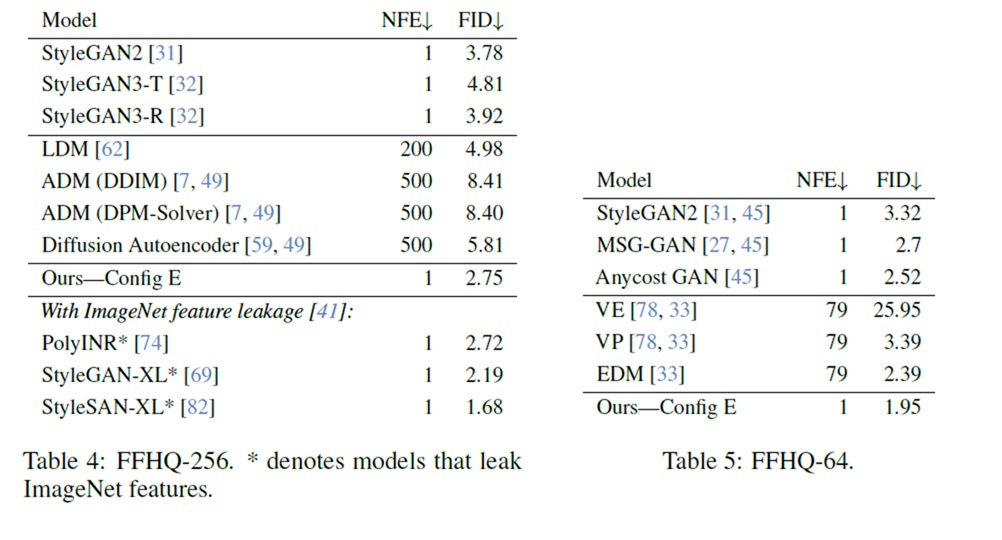
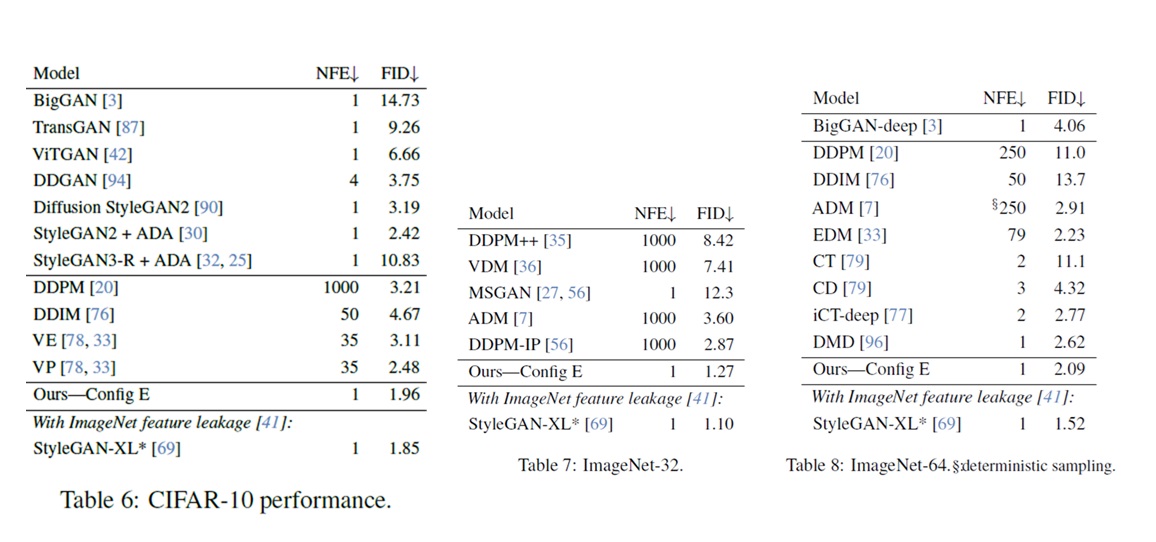
再看类别比较丰富的 CIFAR-10 和 ImageNet 数据集。R3GAN 的表现也比所有扩散模型和大部分 GAN 强。但 R3GAN 没有在更大分辨率的 ImageNet 上测试。现在前沿生成模型一般都会测试 ImageNet-256,而 R3GAN 并没有提供相关实验结果。
总结与评论
R3GAN 是一种现代版的 DCGAN。它从损失函数和模型结构两个方面做了改进。损失函数方面,DCGAN 用了 RpGAN + $R_1$ + $R_2$ 损失函数;模型结构方面,R3GAN 用 ConvNeXt 中的最新卷积结构代替了原来的 VGG 结构。实验表明 R3GAN 在 FFHQ-256 和 ImageNet-64 的 FID 分数上超过了全部扩散模型和多数 GAN,略差于此前最强的 GAN。在生成多样性上,R3GAN 依然没有扩散模型好。
从科研贡献上来看,这篇文章并没有提出新理论或新想法,完全复用了之前工作提出的方法。这篇文章主要提供了一些工程上的启发,有助于我们去开发更好的基于 CNN 的 GAN。从结果来看,R3GAN 并没有在目前主流指标 ImageNet-256 上测试,没有迹象表明它能好过扩散模型。我们可以从其他数据集上的实验结果推断,R3GAN 的最佳表现和之前的 GAN 差不多,没有对 GAN 作出本质的改进。综上,我认为这篇文章是质量满足顶会要求的平庸之作,被 NIPS 2024 选为 Poster 合情合理。
参考文献
DCGAN: Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
StyleGAN: A Style-Based Generator Architecture for Generative Adversarial Networks
StyleGAN2: Analyzing and Improving the Image Quality of StyleGAN
GP (WGAN-GP): Improved Training of Wasserstein GANs
RpGAN: The relativistic discriminator: a key element missing from standard GAN
RpGAN Landscape Explanation: Towards a Better Global Loss Landscape of GANs
ConvNeXt: A convnet for the 2020s
ImageNet FID Trick: The role of imagenet classes in fréchet inception distance