Transformer 中平方复杂度的注意力运算一直是其性能瓶颈,该问题在序列长度极大的视觉生成任务中尤为明显。为了缓解此问题,并生成分辨率高至 4K (4096x4096) 的图像,英伟达近期推出了文生图模型 Sana。Sana 不仅使用了线性注意力的 Transformer,还通过增加 VAE 压缩比等方式,极大提升了超高分辨率图像生成的性能。
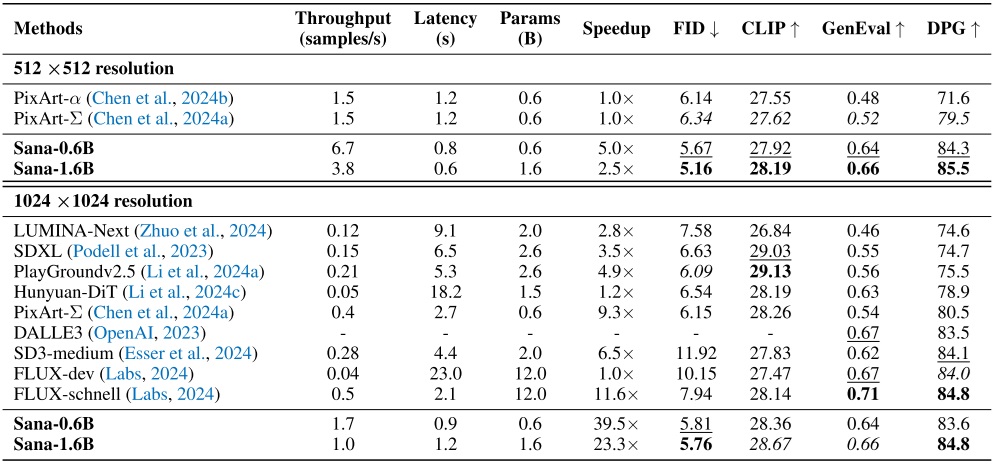
Sana 论文示意图如下,生成的图像看起来还不错。值得注意的是,在 1K 图像生成上,Sana-0.6B 的生成速度是 FLUX-Dev 的 25 倍。由于采用了线性注意力机制,这一速度优势会随着图像尺寸增加而越发明显。

在这篇博文里,我们来着重学习 Sana 相较标准 DiT 文生图模型 (SD3, FLUX.1) 做了哪些提升性能的改进。
本文中,计算机术语「性能」表示运行速度。
线性注意力真的是「免费午餐」吗?
在看完论文摘要后,我的第一反应不是去细读论文,而是立刻去网上搜索社区用户对于 Sana 的评价。我一直坚持一个观点:「天下没有免费的午餐」。线性注意力比标准注意力快了那么多,那么它的质量一定会有所下降,不然所有人都会立刻把标准注意力换成线性注意力。
有网友在 Reddit 上分享了 Sana 的生成结果并对此开展了讨论:https://www.reddit.com/r/StableDiffusion/comments/1hzxeb7/it_is_now_possible_to_generate_16_megapixel/ 。有关图像质量的讨论有:
- 楼主:「Sana 的 4K 模型生成出的图片没有 2K 的真实」。
- 社区用户:「生成结果看起来更靠近抽象艺术,但这些效果已经能够通过 SD 1.5 + 超分辨率达到了。能否用 Sana 生成照片级图片?」楼主:「它不太擅长生成照片级图片。」
- 社区用户:「4K 图片质量太差了,没有比 1K 图片更多的细节。许多上采样算法的结果会比这个更好。论文应该宣传其生成速度而不是丢人的 4K 图像质量。」
- 楼主:「手画得不是很好。」
另一个帖子 (https://www.reddit.com/r/StableDiffusion/comments/1h5xujr/sana_nvidia_image_generation_model_is_finally_out/ )里的评论有:
- 「考虑模型大小和速度的话,它的效果非常惊人。第一感看起来艺术感比 FLUX 好,但文本生成能力不太行。」
- 「有 SD 1.5 的质量,但很快。再训练它可以达到 SDXL 的质量。」同楼里另一个用户则认为,Sana 质量在 SDXL 基础版和 FLUX 之间。
简单看下来,根据社区用户的反馈,Sana 的质量没有显著好于 SDXL。它的 4K 图像生成效果跟先生成较低分辨率再使用超分辨率算法的结果差不多。我们应该着重关注 Sana 的加速方式而不是其生成质量。
以往工作
潜扩散模型(Latent Diffusion Models)
扩散模型能够在多次迭代中生成高质量图像。而有研究发现,扩散模型在生成时早早就生成完了图像结构,后续时间都浪费在完善图像细节上。为此,潜扩散模型 (Latent Diffusion Models, LDM)使用了一个两阶段方法来提升扩散模型的性能:
- 先用一个自编码器 VAE 把图像压缩成尺寸更小、信息更丰富的潜图像 (latent images)。
- 用标准扩散模型生成潜图像。
目前主流的扩散模型几乎都属于 LDM。其中,最经典的 LDM 是 LDM 论文作者实现的 Stable Diffusion (SD)。根据 LDM 论文的实验结果,令 VAE 的压缩比 f 为 4 或 8 比较好。SD 采用了 f=8 的 VAE。后续多数 LDM 都使用了这样的压缩比。
Diffusion Transformers
早期扩散模型是用 U-Net 实现的,而后来大家逐渐把 U-Net 替换成了 DiT (Diffusion Transformers)。基于 DiT 的著名文生图模型有 SD3, FLUX。这些模型的核心仍是标准 Transformer 中的多头注意力运算。
线性注意力
设矩阵 $Q \in \mathbb{R}^{n \times d}, K \in \mathbb{R}^{n \times d}, V \in \mathbb{R}^{n \times d}$,其中 $n$ 为序列长度,$d$ 为特征长度,则注意力操作可以简写成:
对于矩阵 $A \in \mathbb{R}^{a \times b}, B \in \mathbb{R}^{b \times c}$,不做加速的前提下,朴素的矩阵乘法 $A B$ 的复杂度是 $O(a \cdot b \cdot c)$。
根据这个结论,注意力操作的复杂度为 $O(n^2d)$。这是因为 $Q \in \mathbb{R}^{n \times d}, K^T \in \mathbb{R}^{d \times n}$,第一步 $QK^T$ 的复杂度是 $O(n^2d)$。类似地,后一步矩阵乘法也是同样的复杂度。总复杂度不变,仍是 $O(n^2d)$。
由于模型特征长度 $d$ 是常数,我们只考虑序列长度 $n$ 的变化,所以可以认为标准注意力操作的复杂度是 $O(n^2)$。
但假如注意力运算中没有 softmax 操作的话,注意力运算就是两次矩阵乘法。
由于矩阵乘法满足结合律,通过改变矩阵乘法的顺序,我们能够神奇地改变注意力运算的计算复杂度。
由于 $K^T \in \mathbb{R}^{d \times n}, V \in \mathbb{R}^{n \times d}$,$K^TV$ 操作的复杂度是 $O(nd^2)$。由于 $Q \in \mathbb{R}^{n \times d}, K^TV \in \mathbb{R}^{d \times d}$,第二步矩阵乘法的复杂度还是 $O(nd^2)$。因此,总复杂度变为 $O(nd^2)$。不考虑 $d$ 的增长的话,这种注意力运算就是线性复杂度的。
我们再回头看去掉 softmax 对注意力运算有什么影响。softmax 函数同时做了两件事:1)保证 QK 的输出非负,以表示相似度;2)保证对于一个 query,它对所有 key 的相似度权重之和为 1,使得输出向量的范数(向量的「大小」)几乎不变。所以,线性注意力都会设置一个非负相似度函数 $sim(q, k)$,并用下面的注意力公式保证权重归一化。
根据 NLP 社区的反馈,线性注意力的效果比不过标准注意力。
相比之下,CV 社区对线性注意力的探索没有那么多。Sana 主要参考的早期工作为 Efficientvit: Lightweight multi-scale attention for high-resolution dense prediction。
Sana 模型架构改进
在模型架构上,Sana 主要做了三大改进:增加 VAE 压缩比、使用线性注意力、使用轻量级文本编码器。
深度压缩 VAE
在基于 LDM 的 DiT 中,和图块数(参与 Transformer 计算的元素个数,类似于 NLP 的 token)相关的超参数有:
- VAE 压缩比例
f - DiT 图块化 (patchify) 比例
p
此外,VAE 输出的潜图像通道数 c 决定了重建质量与学习难度:c 越大,自编码器的重建效果越好,但扩散模型的学习难度也变大。
经过 VAE 后,图像会从 $H \times W \times 3$ 压缩成 $\frac{H}{f} \times \frac{W}{f} \times C$。又经过图块化操作后,图像大小会变成 $\frac{H}{fp} \times \frac{W}{fp} \times d$,其中 $d$ 是 Transformer 的特征长度。决定 Transformer 运算量的是图像尺寸 $\frac{H}{fp} \times \frac{W}{fp}$。标准 Transformer 一般至多处理 $64 \times 64$ 大小的图像。
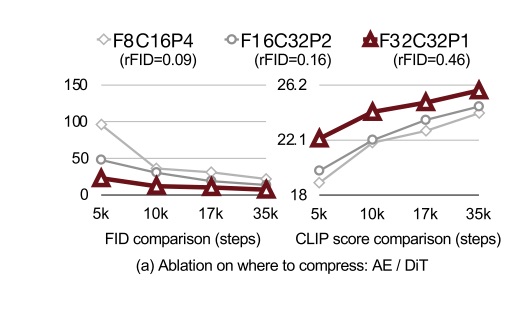
此前的文生图 DiT 一般采用 f8 c4 p2 或 f8 c16 p2 的配置。而 Sana 直接把 f 设置成了 32,实现了一个 f32 c32 的 VAE。
其实,LDM 论文尝试用过一个 f32 c64 的 VAE,但生成效果并不好。为什么这次 Sana 的 VAE 就好了不少呢?论文对此没有做深入分析,只是简单列举了一些 Sana 的 VAE 做出的改进:
- 从模型设计与训练策略上:此前
f32VAE 效果不好的一大原因是模型没有充分收敛。为此,Sana VAE 将模型中的标准自注意力换成了线性注意力。另外,为了提升在高分辨率图像上的生成效果,Sana VAE 先在低分辨率上训练,之后在 1K 图像上微调。 - 从通道数上:作者比较了
f=32时c=16, 32, 64的实验结果,发现将c=64改成c=32会显著提升扩散模型收敛速度。
尽管 VAE 是卷积网络,里面还是包含了自注意力运算。
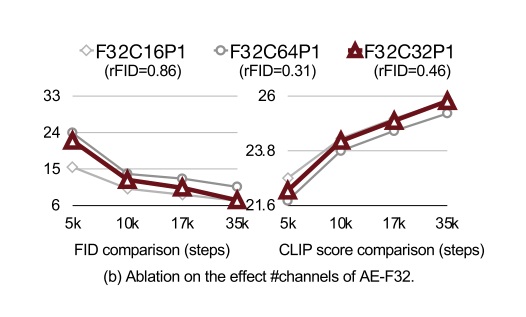
除了调整 f, c 外,作者还认为 p=1,即不使用图块化操作,是最好的。论文展示了总压缩比 fp 不变的前提下, p 提升、 f下降后扩散模型的学习进度。结果发现,不用图块化而让 VAE 全权负责压缩是最好的。
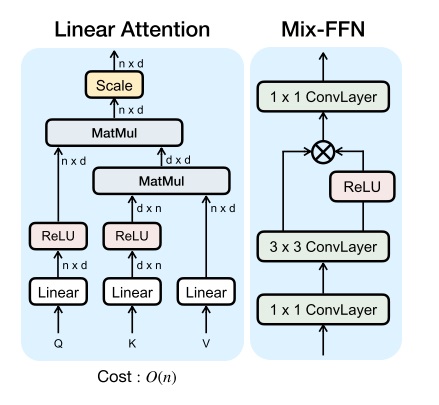
线性 Transformer 块
为了降低注意力操作的复杂度以提升性能,Sana 使用了线性注意力操作。如前所述,线性注意力会去掉 softmax 并通过矩阵乘法的结合律来降低计算复杂度,但需要通过额外设计一个相似度指标。
Sana 对线性注意力的定义如下:
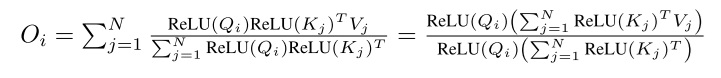
其中,$O_i$ 是某一条 query $Q_i$ 的输出。这其实是让相似度函数为:
ReLU 函数用于让相似度非负。
在上面的线性注意力公式中,不管是分子还是分母,都可以通过结合律来优化计算复杂度。此处细节可参见原论文。
根据之前的经验,线性注意力会降低注意力运算的效果。为了弥补这一点,Sana 参考 EfficientViT,把前馈网络 (FFN) 从 MLP (即 1x1 卷积网络)换成了带 3x3 逐深度卷积的网络。这个小卷积网络不仅提升了整个 Transformer 块的拟合能力,还省去了位置编码——由于卷积网络天然能够建模相对位置关系并打破 Transformer 的对称性,不需要再加入位置编码了。
轻量级文本编码器
之前的 SD3 和 FLUX 都用 T5 作为文本编码器,但 Sana 为了提升模型性能,使用了速度为 T5-XXL 6 倍的 Gemma-2-2B。
定量实验
最后,我们简单看一下论文的主要实验结果。论文用到的实验数据集为 MJHQ-30K,包含三万张 Midjourney 生成的图像。
从定量指标上看,Sana 确实好过不少此前的文生图模型。但是,这些指标无法如实反映人类的审美偏好。如前文所述,社区用户认为 Sana 并没有明显好于 SDXL,但指标无法反映这一点。这些指标参考价值不大的另一个证据是 FLUX-dev 和 FLUX-schnell 的比较结果——作为一个被进一步蒸馏出来的模型,schnell 显然是比 dev 的生成质量更差的,但它的 FID, GenEval, DPG 竟然比 dev 还好。因此,在比较文生图模型质量时,我个人建议不要参考文生图的定量指标,而是去参考社区用户的反馈。
另外,虽然 Sana-1.6B 比 FLUX-dev 快了很多,但它比 FLUX-schnell 只快了一倍。或许 Sana 也可以通过蒸馏获得进一步的推理加速。
总结
Sana 是一个以降低运算开销为主要目标的高分辨率文生图模型。它主要通过增加 VAE 压缩比例、使用线性注意力来提升 DiT 的效率。为了弥补线性注意力的能力损失,Sana 将 FFN 改成了 3x3 卷积网络,在提升模型能力的同时免去了位置编码。除了这两大主要设计外,Sana 还通过使用轻量级文本编码器等诸多细节改进提升了模型的训练与推理效率。整体上看,这个工作主要在工程上作出了贡献,线性注意力的设计几乎照搬了之前的工作,没有使用比较新颖的模块设计。
从生成效果上看,尽管 Sana 论文给出的定量指标还不错,但这些指标是否能如实反映文生图质量还存疑。据社区用户反映,Sana 的质量没有明显好于 SDXL。另外,虽然论文一开头就宣称 Sana 能够生成 4096x4096 的图片,但这种图片的细节很差,和 1024x1024 的差不多。这是因为不管是 VAE 还是 DiT 都只在 1024x1024 上训练过。在加大生成尺寸后,图像的清晰程度没有变,只是看起来像素变多了。这篇论文真正应该强调的是生成 4K 图像的速度会更快,而不应该去强调 4K 图像的质量有多高。
从生成速度上来看,Sana 确实比最强开源文生图模型 Flux-Dev 要快很多。但尴尬的是,在 1024x1024 图像生成上,Sana 的速度仅仅是精心蒸馏的 Flux-schnell 的两倍。当然这个对比可能不是很公平,因为 Sana 还没有经过蒸馏。但就目前来看社区用户在生成 1024x1024 的图像时难以感受到 Sana 性能优势。
这篇文章很好地指明了 DiT 的一个发展方向:我们能不能将线性注意力更好地引入 DiT 呢?按我目前的理解,线性注意力就是通过牺牲自注意力全局依赖关系来提升模型计算速度。它的本质和 MAR (Autoregressive Image Generation without Vector Quantization)、VAR (Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction) 很像,都是通过减少计算像素间的依赖关系来提升速度。这个假设在视觉任务中是很合理的:在确定了图像的主要结构后,理解细节只需要局部像素信息。然而,这些加速方法都不可避免地降低模型的能力。在完全不用和完全使用全局信息之间,我们或许要找到一个平衡点,来使 DiT 具有最佳性能和效果。