以 Attention 计算为核心的 Transformer 模型是当今深度学习的基石。虽然 Attention 计算十分有效,但其高昂的计算成本往往成为了模型性能优化的瓶颈。为了在 GPU 上高效执行 Attention 计算,现在开发者们普遍都使用了 FlashAttention——一种高效的 Attention 并行实现算法。
相信有不少 AI 研究者都想学习一下 FlashAttention,却往往因其较高的学习门槛望而却步:理解 FlashAttention 需要高性能计算知识,它和大家平时学习的 Transformer、大模型等深度学习知识截然不同。而我最近在自学 FlashAttention 时,凭借以前稍微学过的一点并行编程知识,成功地在没有完全弄清细节的前提下学懂了 FlashAttention 的核心思想,并就此明晰了后续的学习路线。在近期的几篇博文中,我想分享我学习 FlashAttention 的过程,并涉及尽可能少的基础知识,让没有 GPU 编程基础的读者轻松学会 FlashAttention。
在这篇博文中,我会介绍理解 FlashAttention 所需的最简 GPU 编程知识,并通过逐步改进伪代码的方式,介绍 FlashAttention 的算法原理。在后续的文章中,我会继续介绍 FlashAttention 的前向传播、反向传播实现等进阶内容。为了方便读者的学习,我不会完全按照 FlashAttention 的论文的逻辑来介绍知识,也不会严谨地按论文里的算法来介绍,不使用 CUDA 编程术语(因为我也不是很懂),而是介绍一种尽可能简明的 FlashAttention 实现,帮助完全没有相关知识的读者入门 AI 高性能计算领域。
底层 GPU 编程模型
程序是由若干原子操作组成的。比如,对于高级语言而言,原子操作包括四则运算、if-else 构成的判断语句、函数定义等;而对于汇编语言而言,原子操作则由从地址读数据、写数据、程序跳转等操作组成。越是偏底层的语言,我们能够控制的细节越多,代码优化空间越大,但代价是开发的成本也越高。
FlashAttention 中的部分优化策略需要用比高级语言更底层的 GPU 编程模型来描述。在这篇文章中,我们会使用一个尽可能简单的 GPU 编程模型。我们将从访存、并行计算这两个方面认识 GPU 编程的特点。
存储模型
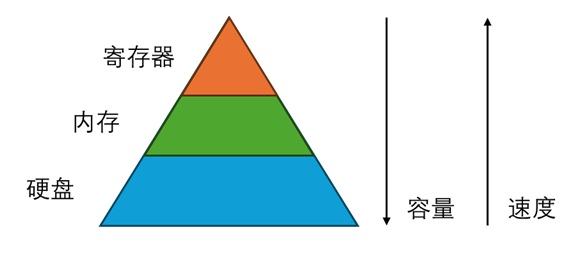
在学习计算机时,我们一般会将存储分为寄存器、内存、硬盘。它们的容量依次递增,读写速度依次递减。硬盘一般只负责存储数据,上面的数据不能做直接运算。内存存储了程序能直接「看到」的数据。使用高级编程语言时,内存是我们存储数据和对数据做运算的地方。但在最底层的运算实现中,程序实际上是先把数据从内存搬到寄存器上,再做运算,最后把数据搬回内存。只有在编写更底层的汇编语言时,我们才需要知道寄存器这一层。
当然,实际上在寄存器和内存之间还有缓存(cache)这一层,但这属于硬件上的实现细节,它在编程模型中是不可见的,硬件会自动处理缓存的逻辑。
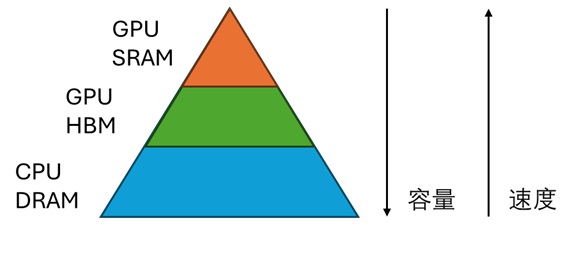
类似地,在 GPU 上,也有类似的存储模型。CPU 内存 (DRAM) 上的数据不能直接用 GPU 运算,必须要放到 GPU HBM 里,就像对 CPU 中硬盘和内存的关系一样。GPU HBM 就是我们常说的「显存」。使用高级语言(如 PyTorch)编写 GPU 程序时,我们可以认为数据全是在 HBM 上运算的。同样,在更底层,我们需要先把数据从 GPU HBM 读取到 GPU SRAM (类似于 CPU 中的寄存器)上,做运算,再把数据写回 GPU HBM。
下图的存储模型及命名方式出自 FlashAttention 论文。同样,下图只是一个逻辑模型,实际硬件中 GPU SRAM 既包括了寄存器,也包括了缓存。但在学习 FlashAttention 时,我们只需要了解这个逻辑模型,而不需要将其与实际的硬件对应。
认识了存储模型后,我们来看 GPU 编程模型相比高级语言的编程模型有哪些变化。
在高级语言中,如果要把两个变量相加得到第三个变量,只需要编写如下代码。
1 | c = a + b |
而加入了「访存」这一概念后,我们需要在计算前后加入变量的读取和存储指令。此外,如果计算中产生了新的变量,需要为新变量新建空间。如下面的代码所示,a_mem, b_mem, 是在 GPU HBM 上的变量,我们用需要用 load 把它们读入到 SRAM 中,得到 SRAM 上的变量 a, b。之后,我们在 SRAM 上创建新变量 c, 并用它存储加法结果。最后把 c 写回 HBM 的 c_mem 里。
1 | c_mem = new_hbm_memory() |
可以看出,为了实现一次加法,我们做了两次读取,一次存储,访存带来的时间开销不可忽略。
除此之外,这里为新变量创建空间的操作出现了两次:一次是在 HBM,一次是在 SRAM。上面这个例子比较简单,输入输出都只有一个变量,没有空间不足的问题。但一般来说,算子的输入都是很长的数组。我们默认 HBM 的存储空间一定足够,但 SRAM 的空间不一定足够。因此,我们需要用到「分块」操作,一块一块地把输入从 HBM 读入到 SRAM 并运算。稍后我们会看到一个更具体的例子。
FlashAttention 的主要贡献就是减少了 Attention 的内存操作开销(读取、存储、新建空间)。
算子融合与访存优化
通过上面的例子,我们发现,算上了访存后,哪怕是实现一个简单的加法都十分费劲。因此,大多数程序员都只会编写高级语言,并让编译器来自动补全访存的逻辑。比如对于 c=a+b 而言,编译器会自动生成两个读取指令,一个存储指令。
可是,编译器自动生成的 GPU 代码一定是最优的吗?这显然不是。考虑下面这个高级语言中的函数 add_more:
1 | def add_more(a, b, c, d): |
如果让编译器按照最直接的方式翻译这段高级语言,那么翻译出的 GPU 程序中会包含如下的指令(为只关注读写次数,我们不写变量在 HBM 上的名称,默认所有变量都在 SRAM 上,且忽略新建空间操作):
1 | load a, b |
但仔细观察这些读写指令,我们会发现部分读写指令是多余的:a 只要被读取一次就行了。最优的程序应为:
1 | load a, b, c, d |
由于我们知道了 add_more 函数的某些特性,我们可以通过手写 GPU 程序,而不是让编译器死板地逐行翻译算子的方式,实现一个更高效的「大型算子」。这种做法被称为 「算子融合」(operator fusion)。由于 GPU 上的函数一般被称为 kernel,所以这种做法也会称为「核融合」(kernel fusion)。
再看另一个例子:
1 | def add_twice(a, b, c): |
如果使用自动编译,会得到下面的 GPU 程序:
1 | load a, b |
但我们可以发现,d 只是中间变量,不用写进 HBM 又读回去。更高效的程序如下:
1 | load a, b |
从上面两个例子中,我们能总结出算子融合提高效率的原理:如果连续的多个运算都要用到同一批数据,我们可以对这批数据只读写一次,以减少访存开销;此外,我们应该将中间结果尽可能保留到 SRAM 上,不要反复在 HBM 上读写。
并行编程
和使用高级语言编程相比,在进行 GPU 编程时,我们除了要考虑访存,还需要编写可以并行执行的程序。我们说 GPU 比 CPU 快,并不是因为 GPU 里的计算单元比 CPU 的高级,而是因为 GPU 里的计算单元更多。用一个常见的比喻,GPU 编程就像是把复杂的数学运算拆成简单的加减乘除,再交给许许多多的小学生来完成。作为 GPU 程序员,我们不仅要决定运算的过程,还需要像「小学老师」一样,知道如何把整个运算拆成若干个更简单、可并行执行的运算。
「计算单元」在不同的硬件模型、编程模型中有不同的所指。这里我们笼统地用「计算单元」来表示一个有独立计算资源(存储、运算器)的单元,可以独立地运行一段程序。
为了快速入门并行编程,我们先通过一个简单的例子来了解一般并行程序的写法,再通过一个反例认识怎样的运算是不能并行的。最后,我们会简要总结并行编程的设计方式。
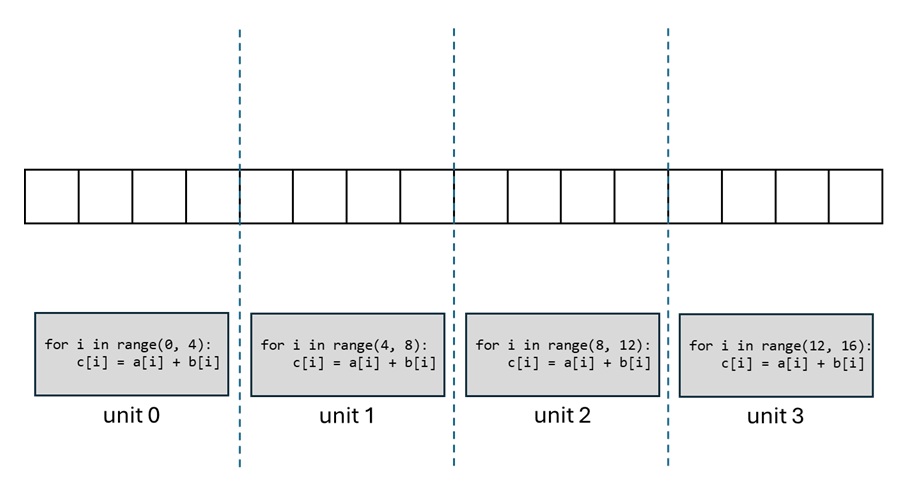
考虑这样一个向量加法任务:假设向量数组 a, b, c 的长度都是 16,我们要在 4 个 GPU 计算单元上实现 c=a+b 的操作,应该怎么为每个计算单元编写程序呢?
最直观的想法肯定是把向量平均拆成四组,让每个计算单元计算 4 个分量的加法结果。这是因为如果任务分配不均匀,任务完成的总时间会取决于任务最多的那个计算单元,这个时间会比平均分更久。因此,我们可以为每个计算单元各自编写如下所示的程序。
为每个计算单元单独写一段程序太累了,能不能只写一段程序,然后让所有计算单元都执行同一段程序呢?这当然可以,但还有一个小小的额外要求:由于现在所有计算单元共用一段程序,我们需要额外输入当前计算单元的 ID 来告知程序正在哪个计算单元上运行。得知了这个额外信息后,我们就可以自动算出当前计算单元应该处理的数据范围,写出下面的程序。
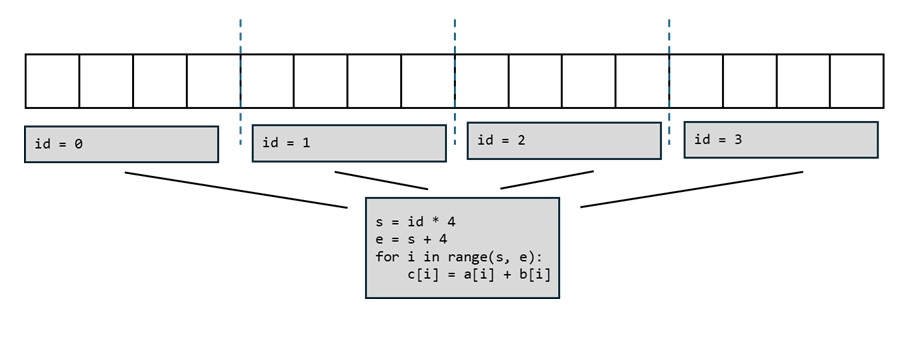
有了这段通用的程序,我们其实就可以实现任意长向量的加法运算。比如当向量的长度变成 32 时,我们可以分配 8 个计算单元来计算。可见,并行编程的目标就是写一段通用的程序,并根据计算单元的 ID 选取同样数量的数据做计算。
在上面的例子中,我们让每个计算单元都计算 4 个数据。实际情况中,应该给每个计算单元分配多少数据呢?一般来说,一个计算单元的并行计算器和存储空间都是有限的,应该尽可能用满它的计算资源。比如一个计算单元最多能并行算 4 个数据,且内存也只够存 4 个数据,那么我们就给它分配 4 个数据。
在学习和设计并行算法时,我们不需要知道每个计算单元具体分配多少数据,但要设计把数据拆分进每个计算单元的方式。比如对于形状为 $N \times M$ 的二维矩阵,计算单元一次能计算 $d$ 个数据,我们要决定是把数据在两个维度上拆分,得到 $ \frac{N}{\sqrt{d}} \times \frac{M}{\sqrt{d}}$ 组,还是只在第二维上拆分,得到 $N \times \frac{M}{d}$ 组。
向量加法只是一个非常简单的运算,由于每个分量之间的计算是独立的,它天然就支持并行计算。而其他的运算就不一定满足这个性质了。比如向量求和:对于一个长度 16 的向量,我们要求出其 16 个分量之和。如果是串行算法,我们会写成这样:
1 | sum = 0 |
在每一步运算中,我们都需要读取当前的 sum,并更新 sum 的值。每步运算之间不是独立的,实现并行计算的方式不是很直观。
用 GPU 编程实现更复杂的算子时,我们要仔细分析运算的过程,区分哪块运算像向量加法一样,是互相独立的;而哪些运算像向量求和一样,不好进行并行计算。之后,我们就要巧妙地对数据拆分,分配到各个计算单元中。比如,我们要求二维矩阵第二维(每一行)的和,我们发现矩阵每行之间的运算是独立的。因此,我们可以在第一维把数据拆分,让每个计算单元串行计算矩阵某一行的和。
GPU 编程新知识总结
相比使用高级语言编程,在 GPU 编程时,我们要多考虑两件事:1)访存开销;2)将可并行的运算拆分。具体的知识点有:
- GPU 的存储从顶到底分为三层: GPU SRAM, GPU HBM, CPU DRAM,它们的访存速度依次递减。编程时我们一般只考虑前两层之间的读写开销。
- 通过观察算子本身的性质,我们可以利用算子融合技术减少访存开销。不反复读取同一批数据、不读写中间结果是两个常见的优化场景。
- GPU 由许多独立的计算单元组成,且每个计算单元本身也可以并行计算多个数据。但每个计算单元一次能并行处理的数据是有限的。如果数据量超过了计算单元的显存,要设法拆分数据。
- 实现并行编程,实际上就是写一个输入参数包含计算单元 ID 的程序。我们要根据 ID 选取同样长度的一段数据,仅考虑这段数据该如何运算。
- 并行编程的一大难点在于观察哪些运算是独立的,并把可以独立运算的部分分配仅不同计算单元。
Attention 运算
Attention 运算建模了一个常见的场景:已有数据 $a$,该如何从数据集合 $B=\{b_i\}$ 中提取信息。比如一个像素要从图像中所有像素中提取信息,或者一个句子里的 token (词元)从另一个句子的所有 token 中提取信息。
Attention 具体实现方式如下图所示:我们先算出 $a$ 对 $b_i$ 的相似度 $s_i$,它描述了 $a$ 对 $B$ 里第 $i$ 项数据的 「注意力」。之后,假设 $b_i$ 里存储的值 (value) 是 $v(b_i)$,我们用 $s_iv(b_i)$ 算出从单项数据中提取的信息。对所有提取出的信息求和,就能得到 Attention 操作的输出。
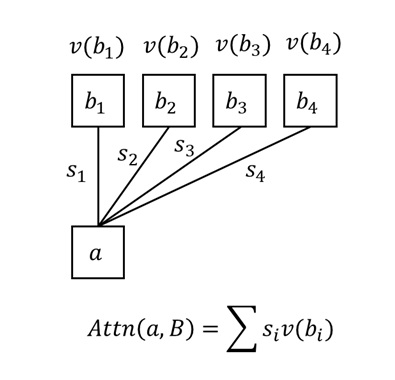
那么,数据间的相似度应该怎么求呢?在标准 Attention 运算中,我们用向量内积来反映数据间的相似度。但下一个问题又来了:该怎么从数据 $a$, $b_i$ 中提取出一个用于计算相似度的向量呢?在实际的 Transformer 模型中,我们一般通过线性层来实现这件事。但在这篇文章中,我们假设每项数据的所有属性已经算好了。我们用 $q(a)$, $k(b_i)$ 来分别表示 $a$, $b_i$ 的用于算相似度的向量 (q 表示 query,k 表示 key),$v(b_i)$ 表示 $b_i$ 中的信息。
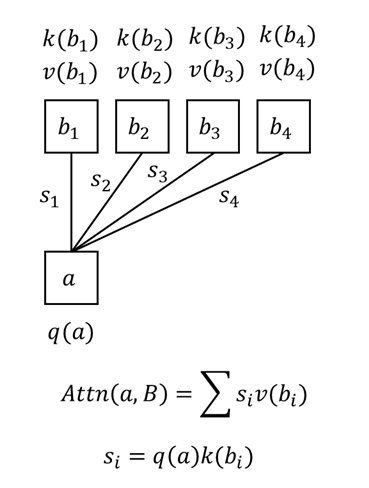
这个计算还不完美:假如内积相似度 $s_i$ 之和 $\sum{s_i}$ 大于 1,那么 Attention 输出向量里的数值会越来越大,让神经网络的计算变得不稳定。因此,我们希望用归一化让相似度之和为 1。
最容易想到的归一化方法是线性归一化:先算出每个相似度及相似度之和,再除以相似度之和。
但标准 Attention 运算用了一种更高级的 softmax 归一化:先对相似度求自然指数,再做线性归一化。
最后,我们得到了 Transformer 论文中的标准 Attention 运算。
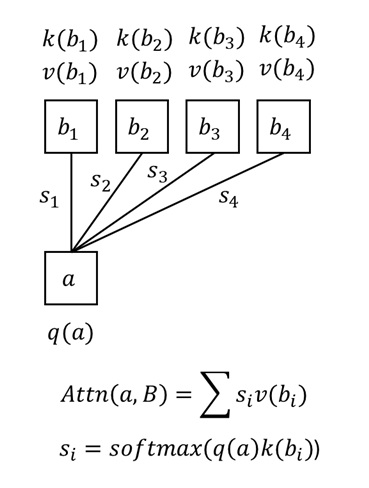
在多数 Attention 实现中,我们会对 softmax 前的相似度乘一个系数 $1/\sqrt{d}$。在这篇文章的讨论中,我们会忽略这个缩放系数。
为了简化上述公式,我们可以把 key, value 向量的集合合并成矩阵。各项数据的形状及合并后的公式如下所示。
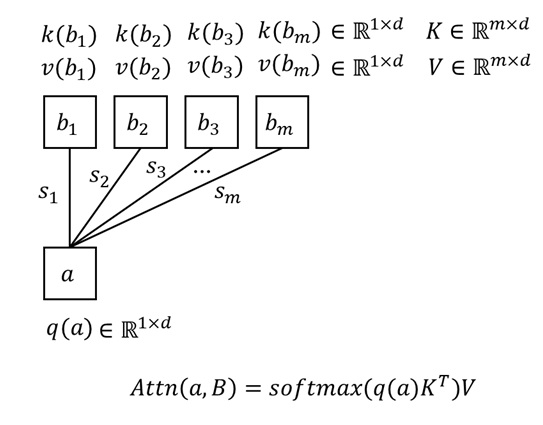
假设现在不止是数据 $a$,而是有 $n$ 个数据 $\{a_i | i \leq n\}$ 要从 B 中查询信息,那么我们可以把上述运算重复 $n$ 次,得到 $n$ 个结果 $Attn(a_i, B)$。如果我们把 $a_i$ 的相关属性 (即 query) 也合并成矩阵,就可以得到我们最熟悉的 Attention 公式。
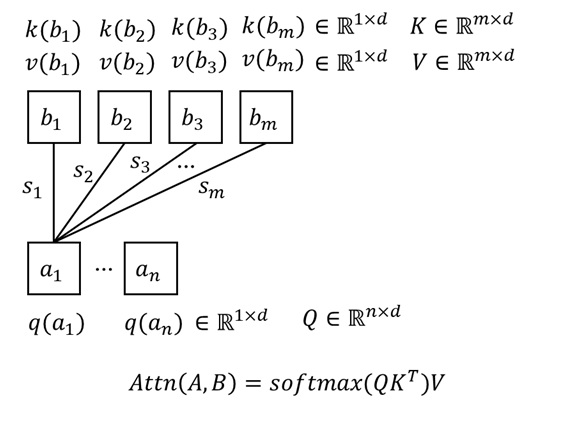
我们花了不少时间来回顾 Attention 运算。不管读者此前是否熟悉 Attention 运算,我都建议在学习 FlashAttention 前把 Attention 的计算细节回顾一遍。
通过上面的回顾,我们发现 Attention 计算有一些特别的性质:
不同 $q$ 之间的计算是独立的。而对于同一个 $q$,算它的 Attention 输出时最复杂的一步是计算 softmax 相似度。
由于 softmax 归一化的存在,我们只有在算完了 $qk$ 的所有内积相似度后,才能计算 softmax 的输出。
在后文的算法设计中,我们会用到这些性质。
自行设计 FlashAttention
简要了解 GPU 编程和 Attention 运算后,我们已经能够自行设计出一种比较高效的 FlashAttention 了。在这一节中,我们将由浅至深地了解 Attention 的实现细节。我们会先看其 PyTorch 实现,再看加入了访存操作后的 GPU 实现。随后,我们来尝试优化这份实现,最终设计出一版简易版的 FlashAttention。
PyTorch 版 Attention 及其访存操作
PyTorch 版 Attention 的代码如下所示。

光看 PyTorch 代码,我们还看不出哪里还有优化空间。因此,我们可以把访存操作加进去。假设一行 PyTorch 代码对应一个标准库里的 GPU 算子,要加入的 IO 操作如下。

这样,我们就能立刻发现一个可优化项:中间变量 s, p 前脚刚写入 HBM,后脚又被读回了 SRAM。如果能用算子融合技术,把整个 Attention 运算放到同一个 GPU 算子里,就能规避这些额外的访存操作。
需要注意的是,如果中间变量不多,多读写两次并不会浪费多少时间。然而,此处的 s, p 是两个数据量很大的变量。这是因为在当今大模型的 Transformer 中,(多头注意力的)特征维度 D 一般只是 32, 64 这样比较小的数,而序列长度 SL 至少是 $10^4$ 这个数量级。所以,形状为 [SL, SL] 的中间变量 s, p 比形状为 [SL, D] 的输入输出要大得多,它们的访存开销严重拖慢了普通 Attention 的速度。
拆分数据读写
现在,我们来考虑如何把 Attention 都在同一个 GPU 算子里实现。如前文所述,每个 GPU 程序描述了一个计算单元上的运算。而由于计算单元本身的 SRAM 存储是有限的,我们需要根据程序 ID,拆分数据,仅处理部分数据。这里,我们假设每个计算单元能存储量级为 D 的数据,但无法存储量级为 SL 的数据。
基于这一限制,我们来继续修改上面的程序。现在,我们不能一次读写形状为 [SL, D] 的数据了,该怎么拆分任务呢?在前文有关注意力运算的回顾中,我们知道,每个 query 之间的运算是独立的。因此,我们可以在上一份代码的基础上修改,只不过这一次我们只在一个并行程序里处理一个 query 和一个 output 的计算。

当然,除了 Q, O,我们也不能一次性读写全部 K, V 了。既然如此,我们只能使用循环,在每一步迭代里读一个 k 或 v。改写后的程序如下。

可是,程序中还有一处超出了内存限制:通过拆分运算,我们将中间变量 s, p 的形状从 [SL, SL] 降低到了 [SL],但它们依然超过了内存限制。能否优化它们的内存占用呢?这一步优化,正是 FlashAttention 的核心贡献。
拆解 softmax
在进行算子融合时,并不是把几个算子拼接起来就做好了。我们往往要深入原算子的计算过程,看看是否能通过交换计算顺序或结合运算,提升整体的计算效率。这里也是同理。我们在优化和 softmax 相关的 s, p 变量时碰到了瓶颈,那我们就要拆解 softmax 的计算过程,看它和前后的两次点乘操作能否融合到一起以优化性能。
softmax 的定义如下:
它的计算可以拆成三步:
- 算 exp,得到分子
- 向量求和,得到分母
- 分子除以分母
因此,softmax 在 attention 中的实现如下。

拆分了 softmax 之后,我们立刻就能发现一个可优化项:变量 s[i] 被求了一次 exp 后就再也没用过了。既然如此,我们不必再用一个循环求 numerator,只需要求出了 q, k 的点乘 s 后,立刻求 numerator[i] = exp(s[i]) 即可。

类似地,我们也不用在另一个循环里对分母求和,一边算一边求和即可。

做完这些优化后,我们确实消除了 softmax 的部分冗余运算。然而,最关键的问题还是没有解决:中间变量 numerator, p 的长度依然是 SL,该怎么接着优化呢?
消除长度为 SL 的中间变量
刚刚我们把 softmax 的部分操作和 q, k 点乘合并了。能否顺着这个思路,把剩余操作和 p, v 的乘法合并呢?
直观上看,这些操作不能合并。这是因为 p 的分母要在跑完了长度为 SL 的循环后才能算出。算出了正确的 p,我们才能接着算 p, v 的乘法。
可见,问题的瓶颈在 p 的分母上。如果不需要除以那个 softmax 的分母,就没那么多限制了。我们先尝试忽略除法那一行,看看代码能优化多少。这时,可以把后面的循环和前面的循环合并起来,得到下面的代码。

接着,我们来回头纠正输出。这个错误的 O 和之前正确的结果差了多少?其实就是少除以了一个 denominator。并且,修改了代码后,有关 denominator 的计算完全没变过。循环结束后,denominator 也就算出来了。所以,我们完全可以在循环结束后再除以分母。

改完代码后,我们发现,p 不用再算了,只剩最后一个长度为 SL 的变量了——numerator。仔细观察代码,现在我们每次只需要用到 numerator[i],不需要重新访问整个 numerator 向量。既然如此,我们可以把 numerator 向量换成一个临时变量。

终于,这份程序成为了一段满足内存限制的可运行 GPU 程序。相比各个运算用独立算子表示的 PyTorch 版 Attention,这份高效 Attention 实现规避了形状为 [SL, SL] 的中间变量的读写开销,大大提升了运行效率。这版 Attention 就是一种简易的 FlashAttention。

优化思路总结
让我们回顾一下优化 Attention 的过程。
- 由于 Attention softmax 输出的内存占用过高,我们希望利用算子融合技术,避免将中间变量从 SRAM 写入 HBM。
- GPU 程序需要设计数据的拆分方式以决定并行计算方式。恰好 Attention 每个 query 的计算是独立的。我们让一个 GPU 程序只处理一个 query 的计算。
- 一个计算单元无法存下长度高达
SL的数据。因此,我们只能用长度为SL的循环来逐个处理 key, value 的运算。但是,softmax 的输出长度仍为SL。 - 为了进一步优化,我们需要拆解并优化 softmax 的计算。softmax 的部分运算可以和 query, key 的点乘合并。但由于 softmax 分母需要遍历所有 key 后才能算出,仍需存储长度为
SL的 softmax 分子。 - 通过观察,我们发现 softmax 的除法运算不影响后面与 value 的乘法运算。因此,我们可以在一个循环里直接算完 query, key, value 的乘法,并维护 softmax 的分母。循环结束后,我们再除以分母。这样,就不再需要长度为
SL的中间变量了。
总结
在这篇文章中,我们先了解了学习 GPU 编程的必须知识,并回顾了 Attention 的运算过程。之后,我们通过逐步优化代码的方式,实现了一个没有过长中间变量、可以在 SRAM 上运行的算子融合版 Attention,即简易版 FlashAttention。在这个过程中,我们理解了 FlashAttention 的设计动机和优化方向:普通 Attention 会产生长度为序列长度平方的中间变量,它的访存时间严重拖慢了 Attention 的运算速度。在优化该运算时,我们的关键发现是 softmax 的除法运算并不影响 q, k, v 的矩阵乘法运算。因此,我们可以在同一个循环里算 q, k, v 乘法,并同时维护 softmax 的分母。这样,就不用维护一个过长的中间变量了。
在学习过程中,我们或许能发现,GPU 编程比 PyTorch 编程要复杂得多,可能光看这篇博文还看不太懂。之后有时间的话,我会介绍 FlashAttention 的 Triton 实现,让读者能够亲身体会 GPU 编程方式及其带来的优化效果。这篇文章介绍的并不是真正的 FlashAttention 算法,也欢迎读者去阅读原论文和其他文章来深入学习 FlashAttention。