在上篇博文中,我分享了近期较火的 JiT 论文,它从理论和实验上证明了:像素空间 DiT 难训练的原因是 patch size 太大,要拟合的分布太难。而这几天,有几篇同期工作都用基于像素级特征的解码器取代 unpatchify,取得了比 JiT 更好的生成效果。在这篇博文中,我将快速介绍 DiP, DeCo, PixelDiT 这三篇研究像素 DiT 的论文,并对它们做对比分析。这三篇论文奠定了未来 Pixel DiT 的设计范式,且能够拓展到其他任务上,值得一读。
本文核心要点:
- 三篇 Pixel DiT 论文都沿着「用像素级解码器取代 unpatchify」这个方向展开,但模型架构设计上不同。
- DiP 用了 U-Net, DeCo 用了无 attention 的 Transformer,PixelDiT 在 DeCo 的基础上加入了 attention。
- DeCo 提出了一种很有潜力的通用 loss,架构略逊 DiP。
- PixelDiT 比另外两个方法生成质量更好,且更适合引入其他模态。
- 我认为,像素 DiT 这个方向已经被做得差不多了,可以尝试挖掘它在其他任务上的应用。文末我会给出一些切实可行的科研想法。

背景:Pixel DiT 为什么需要像素级解码器?
我在上一篇博文「何恺明团队新作 JiT 解读与复现:解决大 patch DiT 难以训练的问题」中,已经对像素空间扩散模型进行了详细的回顾。这里不再赘述,感兴趣的读者可以去阅读这篇文章。
简单来讲,直接用像素空间 DiT 的问题是 token 太多,attention 太慢。为此,视觉 Transformer 的通用做法是加入 patchify 和 unpatchify 以减少 token 数:(patchify) 输入 Transformer 前,把相邻 pxp 个像素打包成通道数为 pxpx3 的一个 token;(unpatchify) 输出前,把 Transformer 输出先变换成通道数 pxpx3 的 token,再 reshape 成像素图像。
表面上这只是改变了 patch 大小,但 JiT 的研究结果表明:让模型直接预测 p×p×3 的高维数据很难。这在预测目标是 noise 或 velocity 时尤为明显。
因此,一个很自然的想法是:能不能只让 DiT 生成一个中间表示,再通过一个轻量的解码器还原像素输出呢?近期的三篇论文 DiP、DeCo、PixelDiT 都基于这一想法出色地解决了像素 DiT 生成任务,使用了一个中间变量全是像素级特征的解码器,只是在网络架构设计上不太一样。由于 JiT 论文已经充分介绍了像素 DiT 的设计动机,在这篇博文里,我只会着重分析各个论文的网络结构。
DiP - 基于 U-Net 的像素级解码器
论文速览
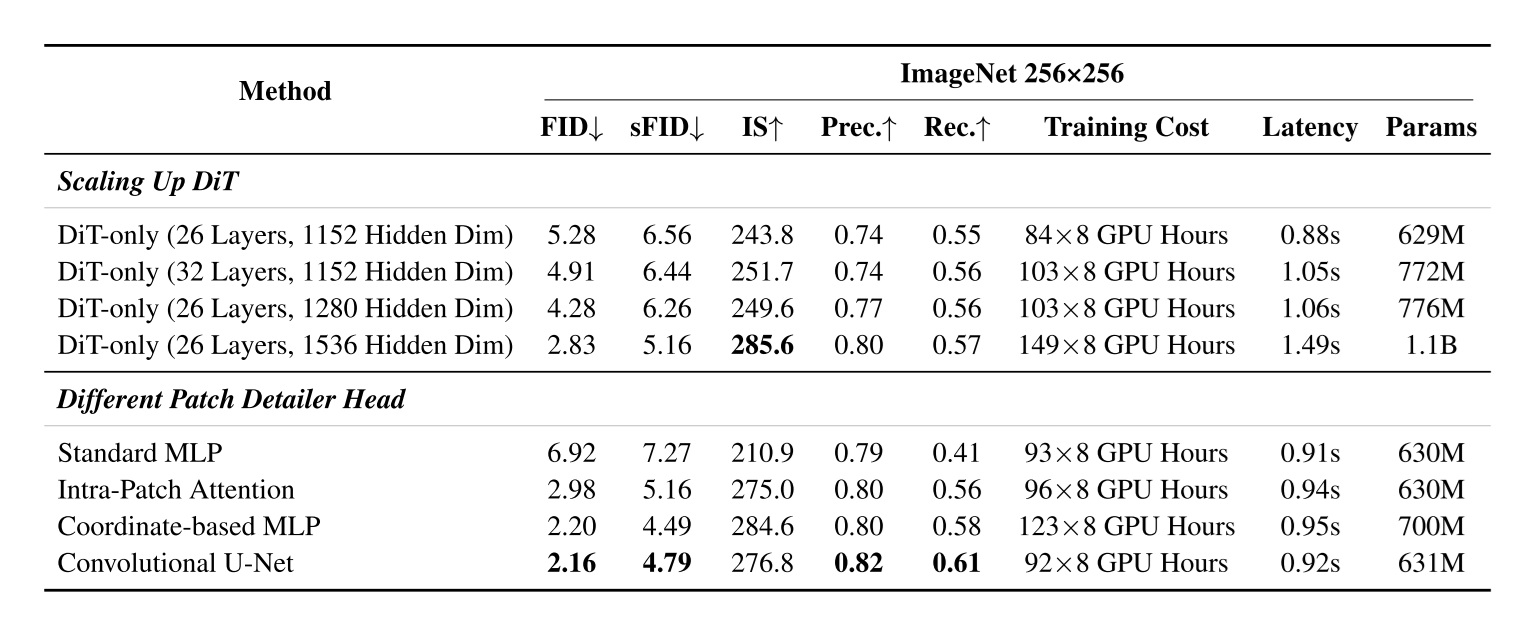
DiP 探究了网络设计的两个设计空间:
应该在哪个地方引入像素级网络?是在 DiT 后面接一个新网络,还是将像素级网络的输出传给 DiT?
像素级网络应该用哪个架构?
从引入网络的位置来看,论文测试了三类方式:
- DiT 完成后再接 head
- 将高频信息回注到 DiT 内部
- 混合注入
三类方式的示意图及实验结果如下图所示。实验结果包括 FID 指标及网络中间特征在不同类别图像下的 t-SNE 可视化结果。

从实验结果来看,三种方法都能提升 FID。不过,接在 DiT 后面的效果最好,且实现最简单,因为加入它时完全不用修改 DiT 的架构。这也证明我们的直觉是正确的:用一个小型解码器取代 unpatchify 比较好,不需要修改 DiT 的其他部分。论文最终采用的就是这个配置。
此外,论文尝试了多种解码器架构。所有解码器的输入输出都是形状为 pxpx3 的像素级 token,条件信息为 DiT 的在该 patch 处的输出特征。该网络不直接包含 patch 与 patch 之间的信息交流,全局信息仅靠 DiT 输出特征提供。
- 标准 MLP:即一个把所有输入 flatten 的全连接网络,而不是 Transformer 里那种逐元素 MLP。这个做法仅仅是 patchify 的一个升级,网络的输入和输出还是高维的,并没有利用 patch 内部的空间信息。
- 坐标 MLP:类似 NeRF 的结构,目的是用神经网络表示一张连续的 2D 图像。我们用 DiT 的输出来生成 MLP 的权重,通过输入二维坐标来读取此处的输出像素值。这和之前的工作 PixNerd 完全一致。
- 块内 Transformer: 用一个小型 Transformer,对一个 patch 内所有像素级特征做 attention。缺点是效率低。
- U-Net(最终选择):标准去噪 U-Net。DiT 条件信息会拼接到 U-Net 的最深层。
表格下半部分的实验结果显示,U-Net 是生成质量最高且训练效率最高的。由于加入 U-Net 实际上增加了总网络参数,我们或许会怀疑继续增大 DiT 参数能否达到同样效果。但表格上半部分的实验结果显示,增加 DiT 参数的作用没有加一个像素级 U-Net 明显。
分析
DiP 确实出色解决了像素 DiT 生成任务。FID 超越了之前所有方法。
论文的实验表格有取巧之嫌:ImageNet-256 实验表格没有放最先进,比自己效果更好的 LDM 方法。我这里展示了 DiP 和此前最好方法 PixNerd 的对比。从效果上看,DiP 没有明显好于 PixNerd。但从上一个表格看,DiP 比 PixNerd 快很多。
经作者指正,上表的 Coordinate-based MLP 就是 PixNerd。论文表格会很快更新。
这里有一件很有趣的事:PixNerd 论文里汇报的 FID 是 2.15,而我在其他论文看到它的 FID 是 1.93 和 1.95。为啥会这样呢?我只好去找 PixNerd 的官方 GitHub,发现在论文公开后,作者又更新了一版 FID 更好的模型 (FID=1.93)。但那个 FID=1.95 我真不知道是哪找来的。
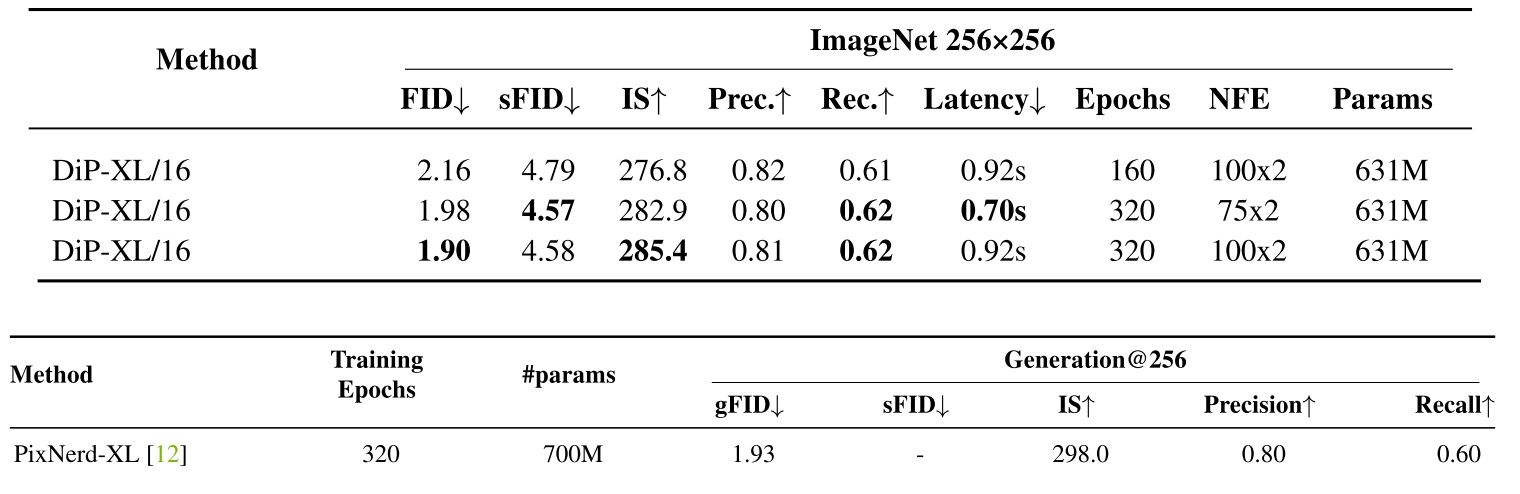
我对 DiP 展示的 baseline 结果有点疑惑:哪怕不加设计,仅仅是增加参数,v-prediction 的 DiT 的 FID 也能达到 2.83。这和 JiT 里的观察是不符的:不对网络结构做修改,只有 x-prediction 能训出较好的结果。我去查看了 DiP 的其他细节,发现它所有实验用的 DiT 是一种叫 DDT 的升级版 DiT,且在 loss 中加入了 REPA loss。可能这两项设计对于 baseline 的提升也十分明显,且能解决 JiT 里发现的问题吧。
看完论文,我最好奇的是为什么 intra-patch Transformer 比不过 U-Net。但论文一点 Transformer 的细节都没讲,也没给源码,没办法进一步分析。不过,后两篇论文的结果表明,Transformer 的架构还是更优的。
小结
DiP 主要探究了像素级解码器加入 DiT 的位置,最终发现拼在 DiT 后面并取代 unpatchify 是最合理的。DiP 用 U-Net 实现了像素级解码器,但 U-Net 不见得是最优的。
DeCo — 无 attention 的 Transformer 像素级解码器,并提出 Frequency-aware Loss
DeCo 对像素 DiT 做了两个方向上的改进:1)架构改进,在 DiT 后面接了一个无 attention 的 Transformer 作为像素级解码器;2)提出 Frequency-aware loss,把原本算 MSE loss 的图像放到频域按不同权重算 loss。
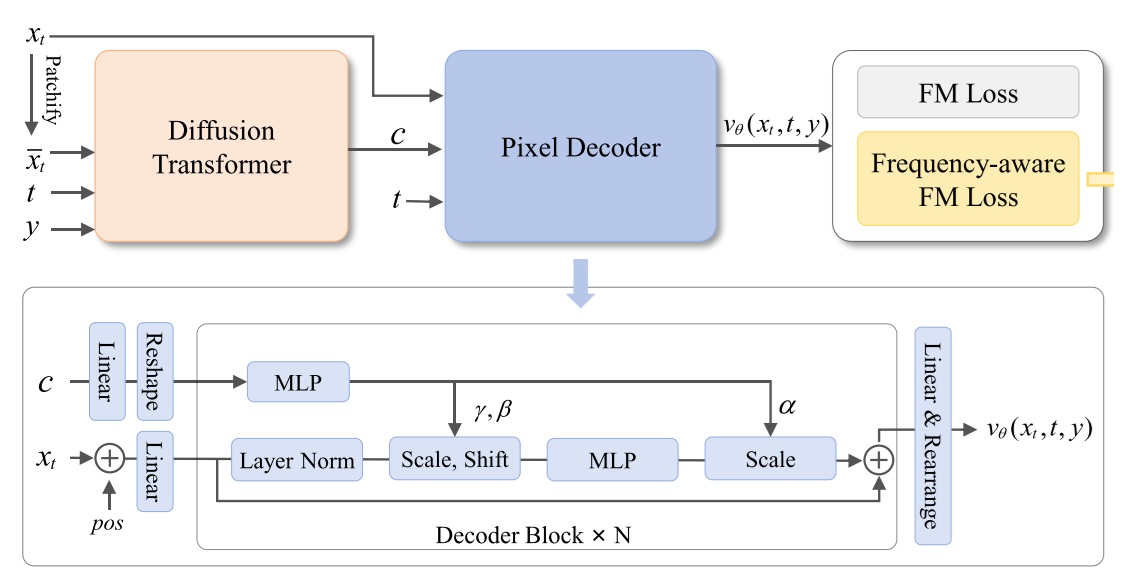
网络架构
DeCo 使用的网络结构如下图所示。它的结构和标准 DiT 很像:
- 将条件信息通过 AdaLN 的方式注入,只不过此处的条件信息不仅是时间
t,还有 DiT 的输出信息c。 - 使用逐元素 MLP。
- 多个相同的带残差连接的块拼在一起。
它和 DiT 的区别在于没有代价高昂的 self-attention 操作。由于没有 attention,自然也不能加 RoPE,位置编码只好换回传统的 sinusoidal 编码,加在输入上。
Frequency-aware FM loss
由于这篇文章和 JiT 是同期工作,在谈及为什么用一个像素级解码器时,作者从频率的角度做了解释:大 patch 的 DiT 仅适合提供低频信息,需要用其他方法提升输出高频细节的能力。顺着这一思路,除了模型上的改进外,DeCo 还提出了 Frequency-aware Flow-Matching Loss,它能强调视觉效果突出的频率,并抑制高频的噪声。
具体来说,作者参考了 JPEG 的处理方式,将网络输出的速度转到频域上,再对频域图像求加权 loss。其中,权重根据 JPEG 的量化表格算得。量化范围越小,说明该段频率对人眼来说更重要,在 loss 里的权重更高。
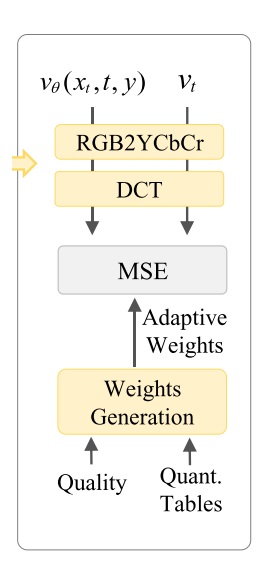
除了 Freq loss 外,和其他 ImageNet 上的前沿 DiT 一样,本文加入了 REPA loss。
实验
在小规模消融实验中,DeCo 做了非常严谨的对比实验。除了纯 DiT baseline 以及 PixelFlow, PixNerd 这两个早期方法外,作者还重新实现了 PixelDDT (把 latent space 的 DDT 方法迁移到了像素空间里),以及最新的 JIT 加上 REPA loss(因为其他几个方法几乎都用了 REPA loss)。
实验结果表明,加入像素级解码器后,方法已经超过了所有 baseline。而加入新的 Freq Loss 能进一步让 FID 变好。
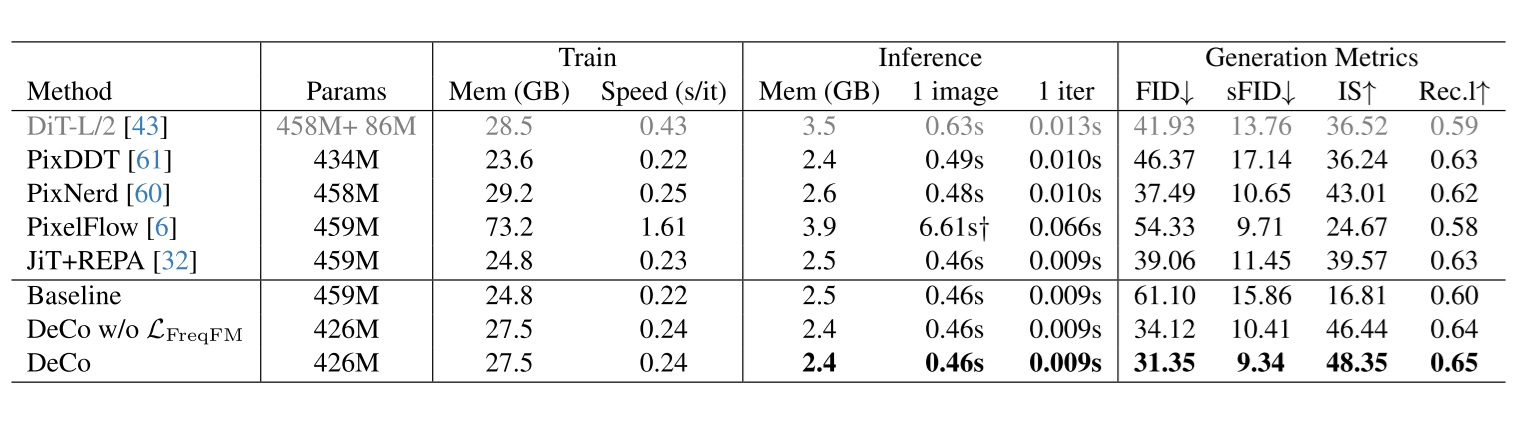
在 ImageNet-256 benchmark 上,DeCo 的 FID 和 DiP 一样,都是 1.90。但鉴于 DeCo 用了 Freq Loss,架构设计还是比不过 DiP。

DeCo 也在 BLIP3o 数据集上训练了一个小型文生图实验,在 GenEval 和 DPG-Bench 上的指标也还不错。
分析
我认为这篇工作的实验做得非常扎实。将像素级解码器设计成一个不带 attention 的 DiT 非常合理。参考之前的 DDT 工作,将 DiT 的条件信息以 AdaLN 的方式注入解码器也很合理。之后如果还有像素 DiT 的研究,多半会参考这一范式。但最终该不含 attention 的架构还是不如 DiP 的 U-Net。
这篇文章提出的 Freq Loss 其实和像素图像生成无关,可以用到任何扩散模型甚至是视觉模型上。论文表格显示这个设计是很有效的。希望未来能看到这个 loss 被广泛用在 DiT 中。
看完实验结果,我的一个小疑惑是消融实验中,PixelFlow 效果明显差于其他方法。这不太应该,因为它的 patch size=4。且消融结果与大规模训练的结果不符:相对其他模型,大规模训练过的 PixelFlow 没那么差。一种可能的原因是消融实验里除 DiT 外所有其他方法都用了 REPA loss,而 PixelFlow 没用。这说明其实 REPA loss 在实验中的影响还是挺大的。
小结
DeCo 通过加入无 attention 的 DiT 作为像素级解码器,并配合 Freq Loss,在像素 DiT ImageNet-256 任务上战平 DiP。该解码器架构有望成为同类方法的标准配置,但不加 attention 的效果确实不够看。Freq Loss 或许有着更广泛的运用空间。
PixelDiT — 用下采样+注意力构建 Transformer 像素级解码器
这篇论文提出了一种叫做 PixelDiT 的像素级解码器。相比 DeCo,PixelDiT 的区别是加入 self-attention。为解决注意力计算量过大,PixelDiT 采用「下采样 → attention → 上采样」的架构。它的效果比 DeCo 好,且架构更通用,更适合未来多模态扩展。
架构设计
看完了 DeCo 后,我们看一眼 PixelDiT 的结构图就能明白这篇文章做了什么。
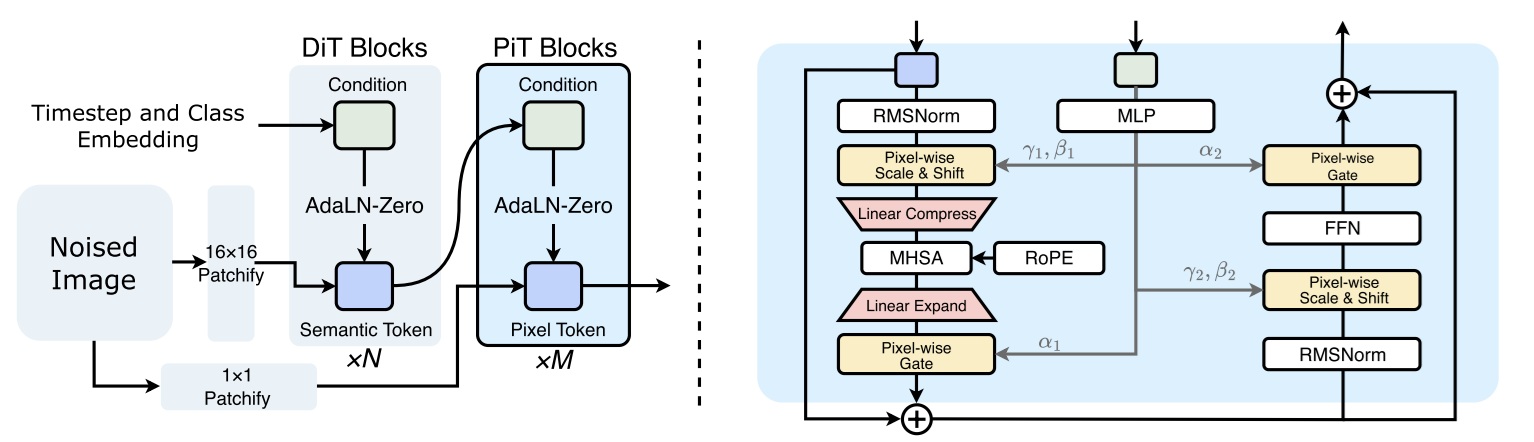
在 DeCo 解码器的基础上,PixelDiT 加上了 self-attention,也就顺带请回了 RoPE,让这个模型变成了一个名副其实的 Transformer。
在方法部分,论文主要讨论了两件事:怎么加 self-attention,怎么传 DiT 的条件信息。
直接对所有像素级特征做 self-attention 计算开销太大。PixelDiT 在此处采取了类似 patchify, unpatchify 的操作,把 self-attention 放到一张更小的 token image 上做。当然,作者也讲到,这个 self-attention 无法生成细节,只用于维持全局信息。高频细节还是靠其他逐像素操作维护的。
关于怎么传 DiT 条件信息的问题,我们在看 DeCo 时跳过了这个细节,这里我们稍微多谈几句。传条件信息时会面临数据空间维数不匹配的问题:DiT 的输出是针对每个 patch,而像素级解码器的输入是所有像素。应该如何把一个特征传播到该 patch 所在的 pxp 个像素的特征上?论文讨论了直接 repeat(复制)和用类似于 unpatchify 的 MLP 这两种做法,最后采用了后者。英雄所见略同,DeCo 也采取的是 MLP 策略。和 DeCo 一样,DiT 的输出最后接到了 PixelDiT 的 AdaLN 模块。
实验
论文的消融结果表明,PixelDiT 用到的两项设计都是有效的:加入基于 Transformer 像素级解码器;提升 DiT 条件信息的粒度,从 patch 级信息变成 pixel 级信息。
论文还讨论了剔除自注意力后 PixelDiT 的效果。不用自注意力,FID 从 2.36 变成了 2.56,效果有一定下降。
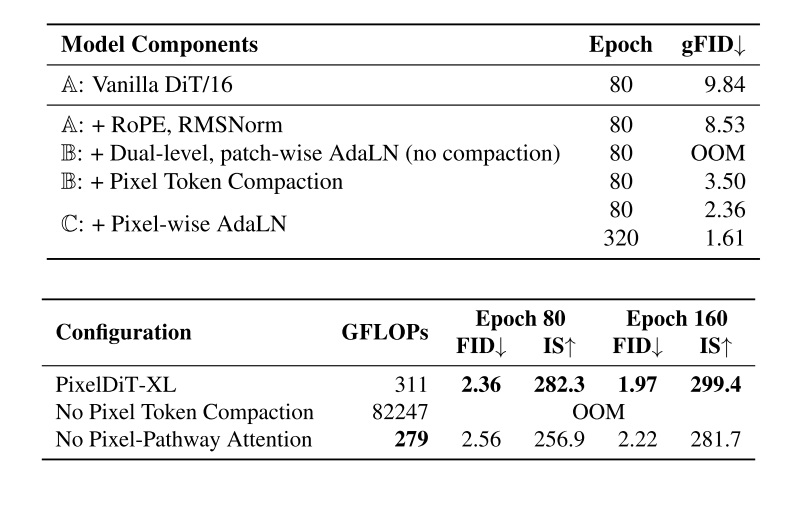
PixelDiT 在 ImageNet-256 上的 FID 为 1.61,明显好于 DiP 和 DeCO。这说明加自注意力非常有用。PixelDiT 也做了文生图模型,指标和 DeCo 各有上下。但文生图模型没有一个统一的数据集和模型架构,对比意义不大。为节约版面,此处就不贴论文里的表格了。
小结
PixelDiT 在 DeCo 的基础上加了个下采样版自注意力。这个模块的提升非常明显。另外,加一个注意力的潜在好处是做多模态任务,可以把其他模块的信息加到这个注意力中。
从 「unpatchify = 反卷积」产生的想法
看完这篇文章后,我对文章中提到的「把 patch 级特征上采样」有一些想法。在这类涉及 patchify(以及其他地方的下采样)的 DiT 中,总不可避免地会有 unpatchify 类操作,即把 patch 级特征上采样回 pixel 级特征。其实,现在这些用 MLP 扩张维度的做法等价于在图像上做一个步长等于卷积核边长的反卷积。
而在当时学 U-Net 时,我发现大家最早是先用反卷积实现上采样,但因为反卷积存在棋盘格 artifact 等缺陷,后来将反卷积换成了先 bilinear 上采样,再做普通卷积。类似地,我们能否在现在所有这些 DiT 中在 unpatchify 类操作时加一个 bilinear 呢?这个想法是有论文支撑的。去年的 VAR 论文在处理不同分辨率的特征时,也用到了 bilinear。总之,这是一个值得尝试的想法。
三篇论文的对比
我们可以用以下表格总结这三篇论文的方法:
| 论文 | 加解码器的位置 | 解码器架构 | 解码器信息交流 | 备注 |
|---|---|---|---|---|
| DiP | DiT 之后 | U-Net | patch 内所有像素 | |
| DeCo | DiT 之后 | 无注意力 Transformer | 无 | 还提出了 Freq Loss |
| PixelDiT | DiT 之后 | 下采样 attention 版 Transformer | 所有像素 | 加入 attention 有明显提升 |
其中,DeCo 和 PixelDiT 在架构设计上高度相似,这套架构有望成为未来的标准范式。PixelDiT 明显更有应用前景,因为加入 attention 效果好,且适合融合多模态信息。
三篇论文在训练、采样步数相同时的指标对比如下: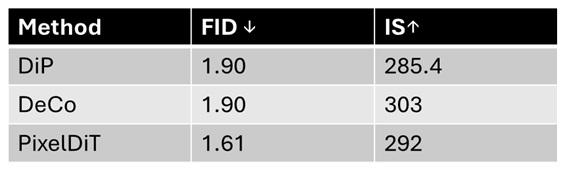
只看 FID 指标的好坏,看上去是 DeCo = DiP < PixelDiT。但 DeCo 用了 Freq Loss,所以架构的排名应该是 DeCo < DiP < PixelDiT。这个排名很合理,因为三者主要区别体现在「解码器信息」这一栏,信息交流得越多,自然效果越好。
总结
虽然 JiT,DiP,DeCo,PixelDiT 是同期论文,但我们可以从 JiT 开始引出一条清晰的逻辑线:
- JiT 论文表明,直接用大 patch size DiT 生成高分辨率像素图片不行,因为
pxpx3维特征太难学习。 - 应该加入 pixel-level decoder 以取代 unpatchify。(DiP 证明了这一点)
- DiP 和 PixNerd 使用的 U-Net,坐标 MLP 还不够好。
- PixelDiT 表明,解码器架构最好是带 attention 的 Transformer。去掉 attention 的 DeCo 不如 DiP。
DeCo 和 PixelDiT 采取的 Transformer 架构可能成为这个任务的标准架构。该架构设计灵感来自 DDT 和 MAR 论文:编码器(在这个任务里是 DiT)的输出通过 AdaLN 传到解码器上。
PixelDiT 加入的 attention 模块不仅在 FID 指标上有一定的提升,而且能辅助多模态任务。
DeCo 的 Freq Loss 可能可以用在更广的场景中。
后续我如果自己基于 DeCo 和 PixelDiT 做了实验,会在博客上分享实验结果。此外,在此之前有很多重要的 DiT 技术,如 REPA 系列,我没能及时分享出来,后续有机会补上。
我的科研想法
在今年上半年,Pixel DiT 的研究是不足的。但没想到这段时间随着 CVPR deadline 的结束,一批相关论文如雨后春笋般冒了出来。现在看来,原本缺乏探索的 Pixel DiT 领域,一下子就人满为患了。后续工作除非对网络架构等地方做出比较本质的改进,不然再刷新指标也意义不大。
从理解模型工作原理的角度,我认为我们还可以自己针对这些模型做一些消融实验,看看究竟哪个设计起到了较大的作用。相比「天然无添加」的 JiT,这几个工作都用了很多先进的设计,比如 REPA loss。研究每个模块的作用,有助于我们发现现有方法的不足,产生新科研想法。
按研究深度由浅至深的顺序,我将介绍两类想法:1)稍微改善 Pixel DiT 的效果;2)集成进其他应用。
由于 Pixel DiT 的主要范式已经被这几篇论文定下来了,以后还用类似的方法,虽然中论文不难,但很难做出较大的影响力。明显可以改进的方向包括:1)把 DeCo 的 Freq Loss 和 PixelDiT 的 attention 都用上;2)尝试我在正文讲的在所有 unpatchify 处加入 bilinear 上采样;3)增加 PixelDiT attention 的粒度。如果把若干个小改进用上,最后能在所有 DiT 中取得 ImageNet-256 上的 SOTA 成果的话,应该也能引起关注。此外,要尝试这个方向,还需要动手拆解 latent space 最新方法的各个模块,试图分析哪些 latent space 的技巧可以迁移到 pixel space 中。
和我在看完 JiT 后的想法一样,我认为所有像素 DiT 的研究意义不在于像素生成本身,而在于任意高分辨率/长序列数据生成。我们完全可以尝试把这些像素 DiT 方法搬到那些即使加入了 VAE 还是数据量太大的任务中,比如视频生成和超高分辨率生成。从工程实现的难易看,要我做的话,我会先从 4K 图像生成开始尝试。这个方向尝试的人不多,只要做出还可以的成果也能发论文。
既然都谈到 latent space 了,我们不妨将 LDM 和这个带了像素级解码器的 Pixel DiT 做对比。仔细一看,二者其实非常相近。最本质的区别在于 VAE 不负责任何去噪功能,而 Pixel DiT 的解码器既负责把压缩信息还原成像素信息,又直接输出去噪结构。我感觉可以尝试这样一件事:复用现在某个 LDM 的编码器和去噪模型部分,将其输出传入一个像素级解码器里,finetune 模型,输出像素级去噪结果。这样整个模型可以端到端训练,不会有 VAE 的重建误差。如果这个想法是可行的,那么这个像素级解码器也可以放到多模态模型里:MLLM 用自回归/扩散模型输出像素解码器的条件,解码器再用一个扩散模型直接生成出像素级输出。
勘误
在之前阅读 DeCo 实验表格时,我忽略了训练轮数、推理步数这两栏,错将一个训了很久、推理步数很多的 DeCo 结果与其他两个方法的结果对比。由于对比基础不统一,原文的一些评价因此产生偏差。
从结果看,我之前高估了 DeCo 的实验结果。我在「论文对比」章节重新画了一个三个方法在相同训练、推理配置下的对比表格,并修正了所有分析。改正后的结论有:
- 只看 FID 的好坏,DeCo = DiP < PixelDiT。去除 Freq Loss 的影响,架构设计上应该是 DeCo < DiP < PixelDiT。
- 这个结果很合理。解码器信息交流越多,效果越好。
之前的内容若使读者产生误解,还请见谅。
参考文献
(JiT) Back to Basics: Let Denoising Generative Models Denoise
(DiP) DiP: Taming Diffusion Models in Pixel Space
(DeCo) DeCo: Frequency-Decoupled Pixel Diffusion for End-to-End Image Generation
(PixelDiT) PixelDiT: Pixel Diffusion Transformers for Image Generation
(PixelFlow) PixelFlow: Pixel-Space Generative Models with Flow
(PixNerd) PixNerd: Pixel Neural Field Diffusion
(MAR) Autoregressive Image Generation without Vector Quantization
(DDT) DDT: Decoupled Diffusion Transformer
(REPA) Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think