学习提示
这周要学习四项内容:错误分析、使用不匹配的数据、完成多个任务的学习、端到端学习。
其中,前两项内容是对上一周内容的扩展。学完这些知识后,我们能更好地决定下一步的改进计划。通过处理分布不匹配的数据,我们能够学会如何诊断一种新的问题:数据不匹配问题。之后,我们使用错误分析技术,找到模型具体的错误样例,进一步改进模型。
后两项内容分别是两项深度学习的应用技巧。我们会学习迁移学习、多任务学习这两种处理多个学习任务的方法。我们还会学习如何用深度学习把问题一步到位地解决,而不是分好几个步骤。
课堂笔记
错误分析
分析具体错误
当我们想提升模型的准确率时,一种做法是统计模型输出错误的样例,看看哪类数据更容易让模型出错。
比如,在提升一个小猫分类器的准确率时,我们可以去看看分类器最容易把其他哪种动物错分类成小猫。经过调查后,我们可能会发现一些小狗长得很像小猫,分类器在这些小狗图片上的表现不佳:

这时,我们可以考虑去提升模型在小狗图片上的表现。
但是,在决定朝着某个方向改进模型之前,我们应该先做一个数据分析,看看这样的改进究竟有没有意义。我们可以去统计100张分类错误的开发集图片,看看这些图片里有多少张是小狗。如果小狗图片的数量很小,比如说只有5张,那么无论我们再怎么提升模型辨别小狗的能力,我们顶多把10%的错误率降到9.5%,提升微乎其微;但如果错分为小狗图片的数量很多,比如有50张,那么我们最优情况下可以把错误率从10%降到5%,这个提升就很显著了。
更系统地,我们可以建立一套同时分析多个改进方向的数据分析方法。比如说,在小猫的错误样例中,一些输入样本是很像小猫的小狗,一些输入样本是其他大型猫科动物,一些输入样本过于模糊。我们可以挑一些错误的样例,分别去记录这些错误样例的出现情况:
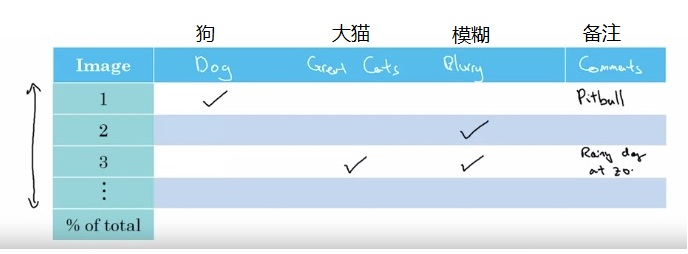
在这个表格中,我们可以记录每张分类错误的图片是由哪一种错误引起的,并留下一些备注。
调研已有问题的同时,我们还可以顺便去发现一些新的问题。比如我们可能会发现某些错分类的图片加了滤镜。发现这个新问题后,我们可以去表格中新建“滤镜”这一列。
手动分析完所有样例后,我们统计每种错误的百分比,看看改进哪种问题的价值更大。
清理标错的数据
在有监督学习中,标注数据往往是人工完成的,数据的标签有误也是情理之中的事。那么,如果数据中有标错的数据,它们会对模型的表现有什么影响呢?
首先,来看训练集有误的影响。事实上,深度学习算法对随机错误的容忍度很高。如果有少量样本是不小心标错的,那么它们对训练结果几乎没有影响。但是,如果数据中有系统性错误,比如白色的小狗全部被标成了小猫,那问题就大了,因为模型也会学到数据集中这种错误的规律。
接着,我们来看开发集有误的影响。为了确认标错数据的影响,我们应该用刚刚的表格统计法,顺便调查一下标错数据的比例:
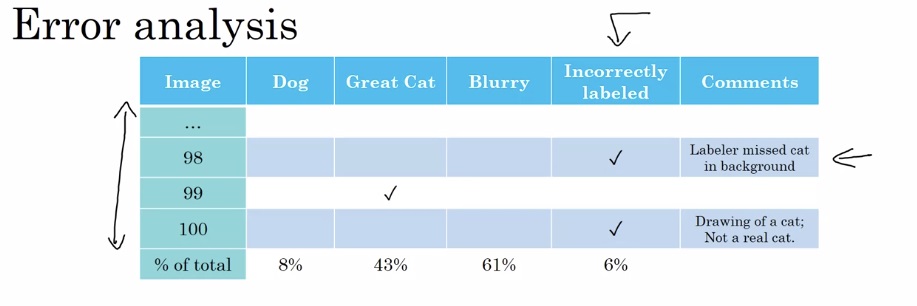
在开发集误差不同时,标错数据产生的影响也不同。假设我们分别有一个开发集误差为10%的分类器和一个误差为2%的分类器:

对于第一个分类器,总体占比0.6%的错标数据相对于10%的开发集错误率几乎可以忽略。但是,对于第二个误差为2%的分类器,0.6%的错标数据就显得占比很大了。在这种情况下,假如有同一个模型有两个权重记录点,一个误差为2.1%,一个误差为1.9%。由于误差的存在,我们不好说第二个记录点就优于第一个记录点。回想一下,开发集本来的目的就是帮助我们选择一个在开发集上表现更好的模型。分辨不出更好的模型,开发集就失效了。因此,我们必须要去纠正一下这些开发集中的错标数据。
在纠正错标数据时,我们要注意以下几点:
- 由于开发集和测试集应来自同一个分布,纠正数据的过程应该在开发集和测试集上同步进行。
- 不仅要检查算法输出错误的样本中的错标样本,还要考虑那些标注错误却输出正确的样本。
- 不一定要去训练集上纠正错标样本,因为训练集和开发集/测试集可以来自不同的分布。
吴恩达老师建议道,尽管很多人会因为检查数据这件事很琐碎而不愿意去一个一个检查算法输出错误的样本,但他还是鼓励大家这样做。他在自己领导的深度学习项目中,经常亲自去检查错误样本。检查错误样本往往能够确认算法之后的改进方向,在这件事上花时间绝对是值得的。
快速构建第一个系统,再迭代更新
在面对一个全新的深度学习问题时,我们不应该一上来就花很多时间去开发一个复杂的系统,而是应该按照下面的步骤尽快开始迭代:
- 快速建立开发集、测试集和评估指标以树立一个目标。
- 快速构建一个初始的系统。
- 使用偏差和方差分析、错误分析来获取后续任务的优先级。
简而言之,就是:快速构建第一个系统,再迭代更新。
当然,如果你在这个问题上已经很有经验了,或者这个问题已经有很多的科研文献,那么一上来就使用一套较为复杂却十分成熟的系统也是可以的。
这种快速迭代的思想同样适用于人生中的其他任务。比如,软件开发中,敏捷开发指的就是快速开发出原型,再逐步迭代。同样,我们在计划做一件事时,不必事先就想得面面俱到,可以尽快下手,再逐渐去改良做法。
不匹配的训练集与开发/测试集
在不同分布上训练与测试
到目前为止,我们已经多次学习过,开发集和测试集的分布必须一致,但是它们与训练集的分布不一定要一致。让我们来看一个实际的例子:
假设我们要开发一个小猫分类的手机程序。我们有两批数据,第一批是从网站上爬取的高清图片,共200,000张;第二批是使用手机摄像头拍摄上传的图片,有10,000张。最终,用户在使用我们的手机程序时,也是要通过拍照上传。

现在,有一个问题:该如何划分训练集、测试集、开发集呢?
一种方法是把所有数据混在一起,得到210,000张图片。之后,按照某种比例划分三个集合,比如按照205,000/2,500/2,500的比例划分训练/测试/开发集。
这种方法有一个问题:我们的开发集和测试集中有很多高清图片。但是,用户最终上传的图片可能都不是高清图片,而是模糊的收集摄像图片。在开发集和测试集中混入更简单的高清图片会让评估结果偏好,不能反映模型在实际应用中的真正表现。
另一种方法是只用手机拍摄的图片作为开发集和测试集。我们可以从手机拍摄的图片里选5,000张放进训练集里,剩下各放2,500张到开发/训练集里。这样的话,开发集和测试集就能更好地反映模型在我们所期望的指标上的表现了。
总结来说,如果我们有来自不同分布的数据,我们应该谨慎地划分训练集与开发/测试集,尽可能让开发/测试集只包含我们期待的分布中的数据,哪怕这样做会让训练集和开发/测试集的分布不一致。
不同数据分布下的偏差与方差问题
在之前的学习中,我们一直把机器学习模型的改进问题分为偏差问题和方差问题两种。而在使用不匹配的数据分布后,我们会引入一个新的分布不匹配问题。
还是在刚刚提到的小猫分类模型中,我们用第二种方法设置了分布不一致的训练集和开发/训练集。假设我们得到了1%的训练误差和10%的开发误差。但是,我们使用了不同分布的数据,开发/测试集的数据可能比训练数据要难得多。我们难以分辨更高的开发误差是过拟合导致的,还是开发集比训练集难度更高导致的。
为了区分这两种问题,我们需要划分出一个只评估一种问题的新数据集——训练开发集(Training-dev set)。训练开发集的用法和我们之前用的开发集类似,但是其数据分布和训练集一致,而不参与训练。通过比较模型在训练集和训练开发集上的准确度,我们就能单独评估模型的方差,进而拆分过拟合问题和数据不匹配问题了。
加入了这个数据集后,让我们对几个示例进行改进问题分析。
假设人类在小猫分类上的失误率是0%。现在,有以下几个不同准确率的模型:
| 误差/样本 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| 训练误差 | 1% | 1 | 10% | 10% |
| 训练开发误差 | 9% | 1.5% | 11% | 11% |
| 开发误差 | 10% | 10 | 12% | 20% |
| 问题诊断 | 高方差 | 数据不匹配 | 高偏差 | 高偏差、数据不匹配 |
也就是说,在多出了数据不匹配问题后,我们可以通过加入一个训练开发集来区分不同的问题。
当然,数据不匹配不一定会加大误差。如果开发/测试集上的数据更加简单,模型有可能取得比训练集还低的误差。
结合上周的知识,总结一下,考虑数据不匹配问题后,我们应该建立如下的表格:
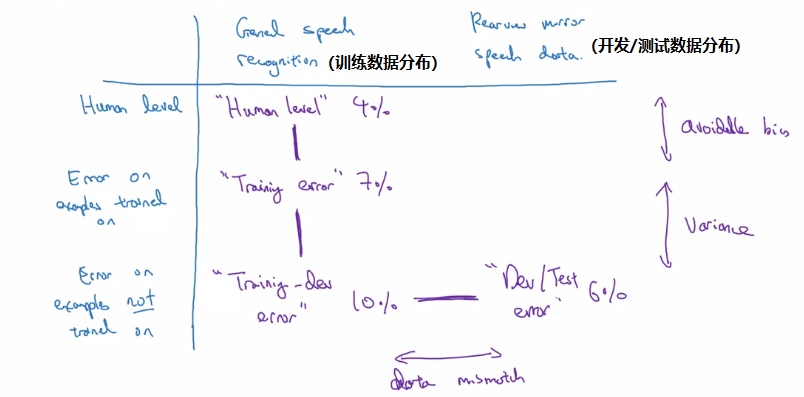
首先,我们要知道训练集上人类的表现,以此为贝叶斯误差的一个估计。之后,我们要测训练误差和训练开发误差。训练误差和人类表现之间的差距为可规避偏差,训练开发误差和训练误差之间的差距为方差。最后,我们计算开发/测试集误差,这个误差和训练开发误差之间的差距为数据不匹配造成的差距。
一般来说,只把上述内容填入表格即可明确当前模型存在的问题。不过,如果我们能够获取开发/测试数据分布上的人类误差和训练误差,把上表填满,我们就能获取更多的启发。比如上表中,如果我们发现在开发/测试数据上人类的表现也是6%,这就说明开发/测试数据对于人类来说比较难,但是对模型来说比较简单。
完成多个任务
迁移学习
深度学习的一大强大之处,就是一个深度学习模型在某任务中学习到的知识,能够在另一项任务中使用。比如在计算机视觉中,目标检测等更难的任务会把图像分类任务的模型作为其模型组成的一部分。这种技术叫做迁移学习。
假如我们有一个通用图像识别的数据集和一个医学图像识别数据集,我们可以先训好一个通用的图像识别模型,再对模型做一些调整,换医学图像数据上去再训练出一个医学图像识别模型。
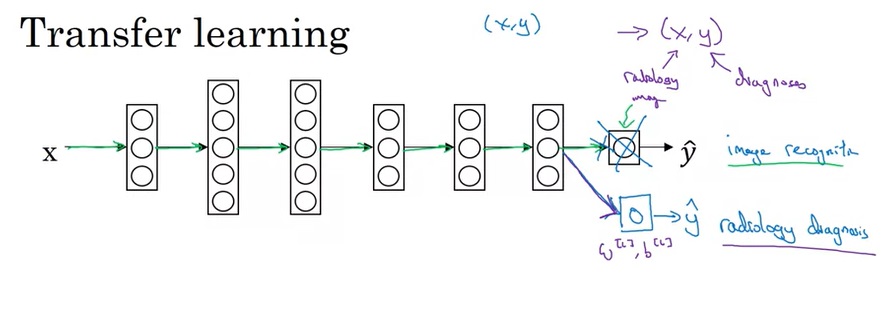
具体来说,以上图中展示的情况为例,我们可以在训练完通用图像识别模型后,删掉最后一个输出层,初始化一个符合医学图像识别任务要求的输出层。之后,我们使用医学图像来训练。在这个过程中,如果新数据较少,我们既可以只训练最后的输出层,而保持其他层参数不变;如果新数据够多,我们可以让所有参数都参与训练。
这里还要介绍两个重要的深度学习名词。如果换新数据后要训练所有参数,则换数据前的训练过程称为预训练(pre-training) ,换数据后的训练过程称为微调(fine-tuning) 。
在上面的例子中,我们只是删掉了一个输出层,加了一个输出层。实际上,删哪些层换哪些层都没有一定的标准。如果任务变得更难了,我们可以删一个输出层,再加几个隐藏层和一个输出层。
迁移学习最常见的场合,是我们想完成训练数据较少的B任务,却在相似的A任务中有大量的训练数据。这时,我们就可以先学A任务,再迁移到B任务上。如果A、B任务的数据量差不多,那迁移学习就没什么意义了,因为同样是一份数据,对于B任务来说,一份B任务的数据肯定比一份A任务的数据要有用得多。
另外,迁移学习之所以能有效,是因为神经网络的浅层总能学到一些和任务无关,而之和数据相关的知识。因此,A任务和B任务要有一样的输入,且A任务的浅层特征能够帮助到任务B。
多任务学习
在刚刚学的迁移学习中,模型会先学任务A,再学任务B。而在另一个面向多个任务的学习方法中,模型可以并行地学习多个任务。这种学习方法叫做多任务学习。
还是来先看一个例子。在开发无人驾驶车时,算法要分别识别出一张图片中是否有人行道、汽车、停止路牌、红绿灯……。识别每一种物体是否存在,都是一个二分类问题。使用多任务学习,我们可以让一个模型同时处理多个任务,即把模型的输出堆叠起来:
这里,一定要区分多个二分类问题和多分类问题。多分类中,一个物体只可能属于多个类别中的一种;而多个二分类问题中,图片可以被同时归为多个类别。

使用多任务学习时,除了输出数据格式需要改变,网络结构和损失函数也需要改变。多个二分类任务的网络结构和多分类的类似,都要在最后一层输出多个结果;而误差和多分类的不一样,不使用softmax,而是使用多个sigmoid求和(每个sigmoid对应一个二分类任务)。
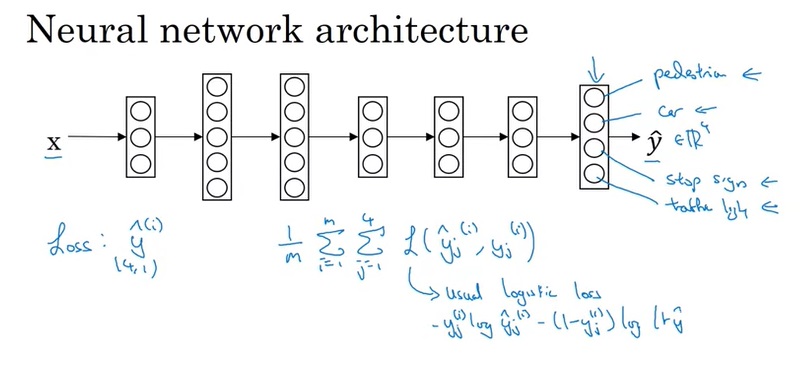
此外,多个二分类任务和多分类任务还有一个不同。在执行多分类学习时,由于所有任务都用统一的数据,数据的标注可能有缺失。比如某几张图片可能没有标出红绿灯,另外几张图片又没有标出人行道。在多任务学习中,我们是允许数据中出现“模糊不清”的现象的,可以把没有标注的数据标成”?”。这样,碰到标注是”?”的数据时,我们就不对这一项进行损失函数的计算。
和迁移学习一样,多任务学习在使用上有一些要求。
首先,所有任务都必须受益于相同的浅层特征。这是显而易见的。
其次,每类任务的数据集都要差不多大。在迁移学习中,我们有比较大的数据集A和比较小的数据集B。而在迁移学习中,假如我们有100项任务,每种数据有1000条数据。对于每一项任务来说,其他99项任务的99000条数据就像数据集A一样,自己的1000条数据就像数据集B一样。
最后,经研究,只有当神经网络模型足够大时,使用多任务学习才至少不比分别学习每个任务差。
在实践中,迁移学习比多任务学习常见得多。
端到端深度学习
深度学习的另一大强大之处,就是端到端(end-to-end)学习。这项技术可以让搭建学习算法简单很多。让我们先看看端到端学习具体是指什么。
不使用深度学习的话,一项任务可能会被拆成多个子步骤。比如在NLP(自然语言处理)中,为了让电脑看懂人类的语言,传统方法会先提取语言中的词语,再根据语法组织起词语,最后再做进一步的处理。而在端到端学习中,深度学习可能一步就把任务完成了。比如说机器翻译这项NLP任务,用深度学习的话,输入是某语言的句子,输出就是另一个语言的句子,中间不需要有其他任何步骤。
相较于多步骤的方法,端到端学习的方法需要更多的数据。仅在数据足够的情况下,端到端学习才是有效的。下面,我们来看一个反例。
在人脸识别任务中,输入是一张图片,输出是图片中人脸的身份。这里有一个问题:识别人脸之前,算法需要先定位人脸的位置。如果使用端到端学习的话,学习算法要花很长时间才能学会找到人脸并识别人脸的身份。
相比之下,我们可以把这个人物拆成两个阶段:第一阶段,算法的输入是图片,输出是一个框,框出了人脸所在位置;第二阶段,输入是框里的人脸,输出是人脸的身份。学习算法可以轻松地完成这两个子问题,这种非端到端的方法反而更加通用。
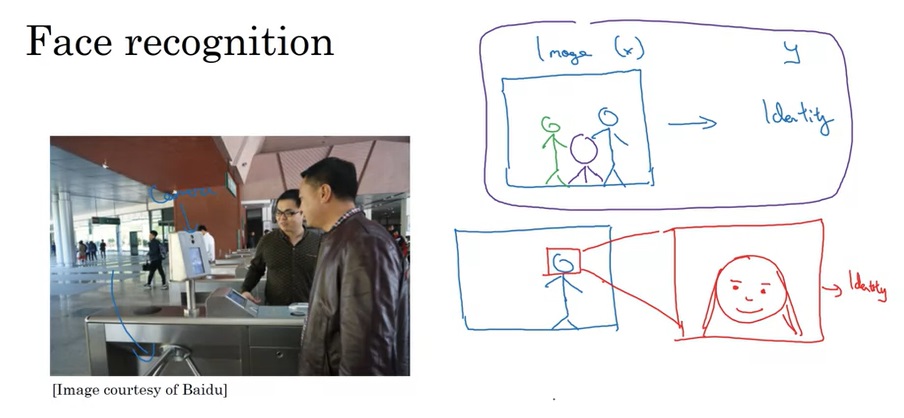
总结一下,非端到端学习想要优于端到端学习,必须满足两个条件:每个子任务都比较简单;每个子任务的数据很多,而整个任务的数据很少。
那么,具体哪些情况下该用端到端学习,哪些情况下不用呢?我们来看看端到端学习的优缺点:
优点:
- 让数据说话。相较于手工设计的某些步骤,端到端学习能够从海量数据中发现于更适合计算机理解的统计规律。
- 减少手工设计的工作量,让设计者少花点精力。
缺点:
- 可能需要大量的数据。
- 排除了可能有用的手工设计的东西。比如人脸识别中,显然,找出人脸是一个绕不过去的子步骤。
归根结底,还是数据量决定了是否使用端到端学习。在复杂的任务中,要达成端到端需要非常非常多的数据,在不能够获取足够数据之前,还是使用多阶段的方法好;而对于简单的任务,可能要求的数据不多,直接用端到端学习就能很好地完成任务了。
总结
这周的知识点如下:
- 错误分析
- 用表格做错误分析
- 统计错标数据
- 数据不匹配
- 何时使用数据分布不同的训练集和开发/测试集
- 训练开发集
- 如何诊断数据不匹配问题
- 完成多个任务
- 迁移学习的定义与常见做法
- 预训练、微调
- 多任务学习的定义
- 多个二分类任务
- 迁移学习与多任务学习的优劣、使用场景
- 端到端深度学习
- 认识端到端学习的例子
- 何时使用端到端学习
和上周一样,这周的知识都是一些只需要了解的概念,没有什么很复杂的公式。大家可以较为轻松地看完这周的内容。
另外,这周也没有官方的编程作业。