在这篇文章中,我将详细地介绍一个英中翻译 Transformer 的 PyTorch 实现。这篇文章会完整地展示一个深度学习项目的搭建过程,从数据集准备,到模型定义、训练。这篇文章不仅会讲解如何把 Transformer 的论文翻译成代码,还会讲清楚代码实现中的诸多细节,并分享我做实验时碰到的种种坑点。相信初学者能够从这篇文章中学到丰富的知识。
项目网址: https://github.com/SingleZombie/DL-Demos/tree/master/dldemos/Transformer
如果你对 Transformer 的论文不熟,欢迎阅读我之前的文章:Attention Is All You Need (Transformer) 论文精读 。
数据集准备 我在 https://github.com/P3n9W31/transformer-pytorch 项目中找到了一个较小的中英翻译数据集。数据集只有几KB大小,中英词表只有10000左右,比较适合做Demo。如果要实现更加强大实用的模型,则需要换更大的数据集。但相应地,你要多花费更多的时间来训练。
我在代码仓库中提供了data_load.py文件。执行这个文件后,实验所需要的数据会自动下载到项目目录的data文件夹下。
该数据集由cn.txt, en.txt, cn.txt.vocab.tsv, en.txt.vocab.tsv这四个文件组成。前两个文件包含相互对应的中英文句子,其中中文已做好分词,英文全为小写且标点已被分割好。后两个文件是预处理好的词表。语料来自2000年左右的中国新闻,其第一条的中文及其翻译如下:
1 2 目前 粮食 出现 阶段性 过剩 , 恰好 可以 以 粮食 换 森林 、 换 草地 , 再造 西部 秀美 山川 。 the present food surplus can specifically serve the purpose of helping western china restore its woodlands , grasslands , and the beauty of its landscapes .
词表则统计了各个单词的出现频率。通过使用词表,我们能实现单词和序号的相互转换(比如中文里的5号对应“的”字,英文里的5号对应”the”)。词表的前四个单词是特殊字符,分别为填充字符、频率太少没有被加入词典的词语、句子开始字符、句子结束字符。
1 2 3 4 5 6 7 8 <PAD> 1000000000 <UNK> 1000000000 <S> 1000000000 </S> 1000000000 的 8461 是 2047 和 1836 在 1784
1 2 3 4 5 6 7 8 <PAD> 1000000000 <UNK> 1000000000 <S> 1000000000 </S> 1000000000 the 13680 and 6845 of 6259 to 4292
只要运行一遍data_load.py下好数据后,我们待会就能用load_train_data()来获取已经打成batch的训练数据,并用API获取cn2idx, idx2cn, en2idx, idx2en这四个描述中英文序号与单词转换的词典。我们会在之后的训练代码里见到它们的用法。
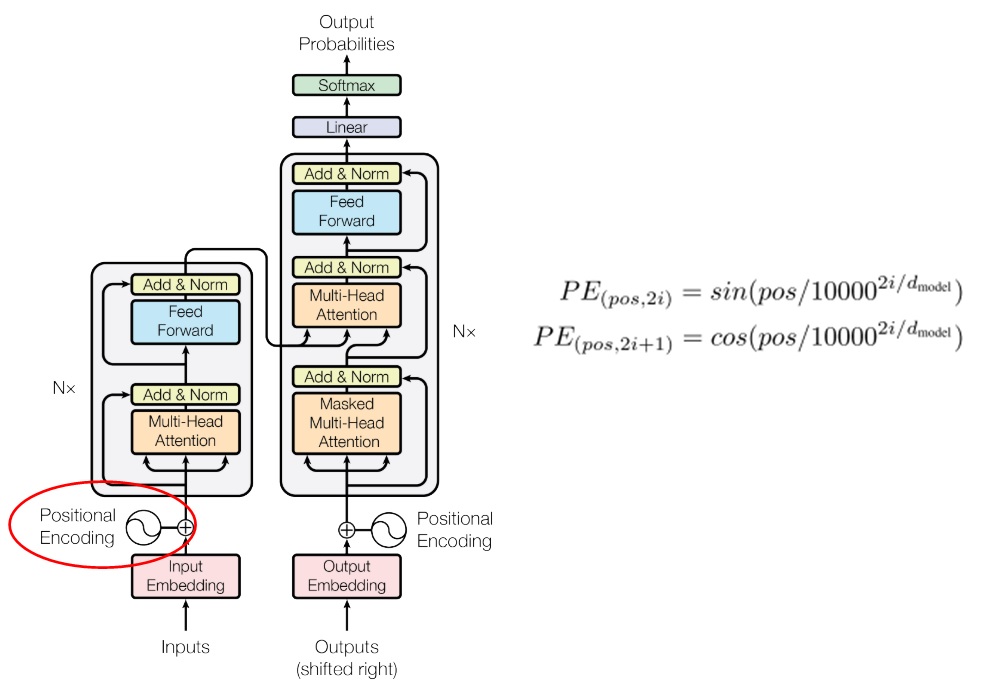
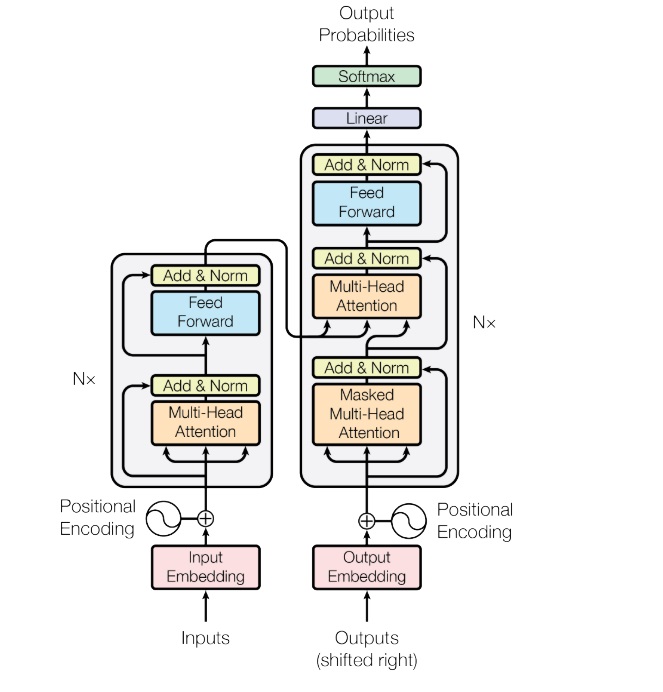
准备好数据后,接下来就要进入这个项目最重要的部分——Transformer 模型实现了。我将按照代码的执行顺序,从前往后,自底向上地介绍 Transformer 的各个模块:Positional Encoding, MultiHeadAttention, Encoder & Decoder, 最后介绍如何把各个模块拼到一起。在这个过程中,我还会着重介绍一个论文里没有提及,但是代码实现时非常重要的一个细节——<pad>字符的处理。
说实话,用 PyTorch 实现 Transformer 没有什么有变数的地方,大家的代码写得都差不多,我也是参考着别人的教程写的。但是,Transformer 的代码实现中有很多坑。大部分人只会云淡风轻地介绍一下最终的代码成品,不会去讲他们 debug 耗费了多少时间,哪些地方容易出错。而我会着重讲一下代码中的一些细节,以及我碰到过的问题。
Positional Encoding
模型一开始是一个 Embedding 层加一个 Positional Encoding。Embedding 在 PyTorch 里已经有实现了,且不是文章的创新点,我们就直接来看 Positional Encoding 的写法。
求 Positional Encoding,其实就是求一个二元函数的许多函数值构成的矩阵。对于二元函数$PE(pos, i)$,我们要求出$pos \in [0, seqlen - 1], i \in [0, d_{model} - 1]$时所有的函数值,其中,$seqlen$是该序列的长度,$d_{model}$是每一个词向量的长度。
理论上来说,每个句子的序列长度$seqlen$是不固定的。但是,我们可以提前预处理一个$seqlen$很大的 Positional Encoding 矩阵 。每次有句子输入进来,根据这个句子的序列长度,去预处理好的矩阵里取一小段出来即可。
这样,整个类的实现应该如下所示:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class PositionalEncoding (nn.Module ): def __init__ (self, d_model: int , max_seq_len: int ): super ().__init__() assert d_model % 2 == 0 i_seq = torch.linspace(0 , max_seq_len - 1 , max_seq_len) j_seq = torch.linspace(0 , d_model - 2 , d_model // 2 ) pos, two_i = torch.meshgrid(i_seq, j_seq) pe_2i = torch.sin(pos / 10000 **(two_i / d_model)) pe_2i_1 = torch.cos(pos / 10000 **(two_i / d_model)) pe = torch.stack((pe_2i, pe_2i_1), 2 ).reshape(1 , max_seq_len, d_model) self.register_buffer('pe' , pe, False ) def forward (self, x: torch.Tensor ): n, seq_len, d_model = x.shape pe: torch.Tensor = self.pe assert seq_len <= pe.shape[1 ] assert d_model == pe.shape[2 ] rescaled_x = x * d_model**0.5 return rescaled_x + pe[:, 0 :seq_len, :]
代码中有不少需要讲解的部分。首先,先看一下预处理好的矩阵pe是怎么在__init__中算出来的。pe可以很直接地用两层循环算出来。由于这段预处理代码只会执行一次,相对于冗长的训练时间,哪怕生成pe的代码性能差一点也没事。然而,作为一个编程高手,我准备秀一下如何用并行的方法求出pe。
为了并行地求pe,我们要初始化一个二维网格,表示自变量$pos, i$。生成网格可以用下面的代码实现。(由于$i$要分奇偶讨论,$i$的个数是$\frac{d_{model}}{2}$)
1 2 3 i_seq = torch.linspace(0 , max_seq_len - 1 , max_seq_len) j_seq = torch.linspace(0 , d_model - 2 , d_model // 2 ) pos, two_i = torch.meshgrid(i_seq, j_seq)
torch.meshgrid用于生成网格。比如torch.meshgrid([0, 1], [0, 1])就可以生成[[(0, 0), (0, 1)], [(1, 0), (1, 1)]]这四个坐标构成的网格。不过,这个函数会把坐标的两个分量分别返回。比如:
1 2 3 i, j = torch.meshgrid([0 , 1 ], [0 , 1 ])
利用这个函数的返回结果,我们可以把pos, two_i套入论文的公式,并行地分别算出奇偶位置的 PE 值。
1 2 pe_2i = torch.sin(pos / 10000 **(two_i / d_model)) pe_2i_1 = torch.cos(pos / 10000 **(two_i / d_model))
有了奇偶处的值,现在的问题是怎么把它们优雅地拼到同一个维度上。我这里先把它们堆成了形状为seq_len, d_model/2, 2的一个张量,再把最后一维展平,就得到了最后的pe矩阵。这一操作等于新建一个seq_len, d_model形状的张量,再把奇偶位置处的值分别填入。
1 pe = torch.stack((pe_2i, pe_2i_1), 2 ).reshape(1 , max_seq_len, d_model)
最后,要注意一点。只用 self.pe = pe 记录这个量是不够好的。我们最好用 self.register_buffer('pe', pe, False) 把这个量登记成 torch.nn.Module 的一个存储区(这一步会自动完成self.pe = pe)。这里涉及到 PyTorch 的一些知识了。
PyTorch 的 Module 会记录两类参数,一类是 parameter 可学习参数,另一类是 buffer 不可学习的参数。把变量登记成 buffer 的最大好处是,在使用 model.to(device) 把一个模型搬到另一个设备上时,所有 parameter 和 buffer 都会自动被搬过去。另外,buffer 和 parameter 一样,也可以被记录到 state_dict 中,并保存到文件里。register_buffer 的第三个参数决定了是否将变量加入 state_dict。由于 pe 可以直接计算,不需要记录,可以把这个参数设成 False。
预处理好 pe 后,用起来就很方便了。每次读取输入的序列长度,从中取一段出来即可。
另外,Transformer 给嵌入层乘了个系数$\sqrt{d_{model}}$。为了方便起见,我把这个系数放到了 PositionalEncoding 类里面。
1 2 3 4 5 6 7 def forward (self, x: torch.Tensor ): n, seq_len, d_model = x.shape pe: torch.Tensor = self.pe assert seq_len <= pe.shape[1 ] assert d_model == pe.shape[2 ] rescaled_x = x * d_model**0.5 return rescaled_x + pe[:, 0 :seq_len, :]
Scaled Dot-Product Attention
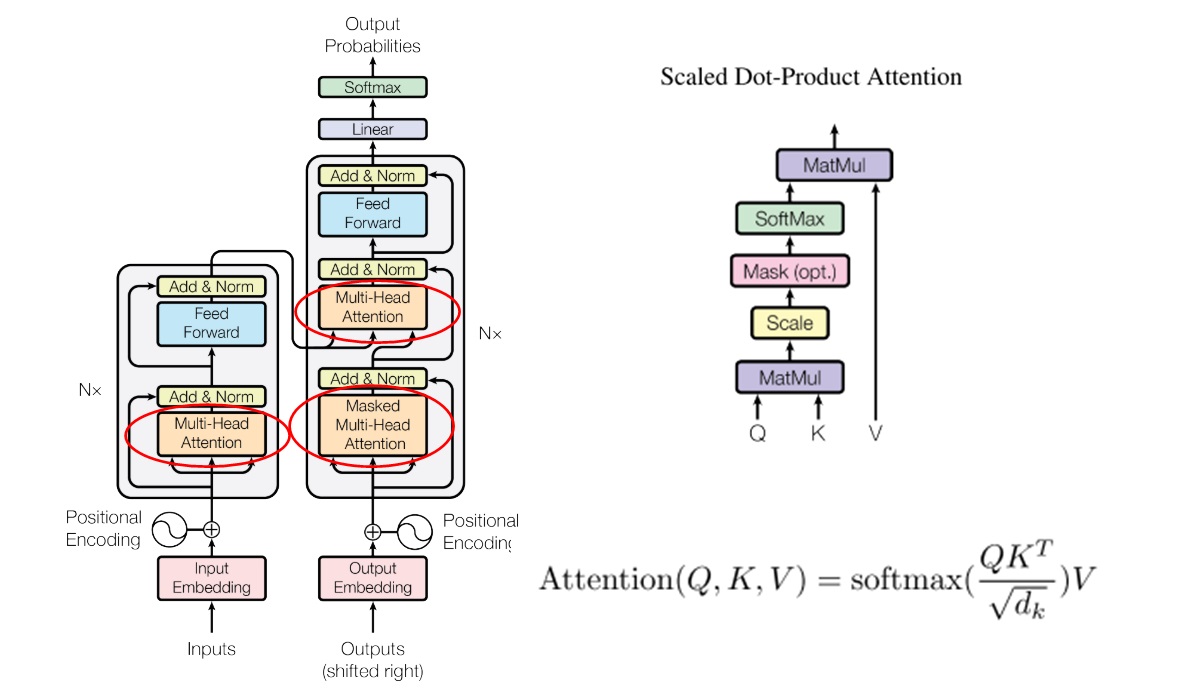
下一步是多头注意力层。为了实现多头注意力,我们先要实现 Transformer 里经典的注意力计算。而在讲注意力计算之前,我还要补充一下 Transformer 中有关 mask 的一些知识。
Transformer 最大的特点就是能够并行训练。给定翻译好的第1~n个词语,它默认会并行地预测第2~(n+1)个下一个词语。为了模拟串行输出的情况,第$t$个词语不应该看到第$t+1$个词语之后的信息。
输入信息
输出
(y1, —, —, —)
y2
(y1, y2, —, —)
y3
(y1, y2, y3, —)
y4
(y1, y2, y3, y4)
y5
为了实现这一功能,Transformer 在Decoder里使用了掩码。掩码取1表示这个地方的数是有效的,取0表示这个地方的数是无效的。Decoder 里的这种掩码应该是一个上三角全1矩阵。
掩码是在注意力计算中生效的。对于掩码取0的区域,其softmax前的$QK^T$值取负无穷。这是因为,对于softmax
令$x_i=-\infty$可以让它在 softmax 的分母里不产生任何贡献。
以上是论文里提到的 mask,它用来模拟 Decoder 的串行推理。而在代码实现中,还有其他地方会产生 mask。在生成一个 batch 的数据时,要给句子填充 <pad>。这个特殊字符也没有实际意义,不应该对计算产生任何贡献。因此,有 <pad> 的地方的 mask 也应该为0。之后讲 Transformer 模型类时,我会介绍所有的 mask 该怎么生成,这里我们仅关注注意力计算是怎么用到 mask 的。
注意力计算 补充完了背景知识,我们来看注意力计算的实现代码。由于注意力计算没有任何的状态,因此它应该写成一个函数,而不是一个类。我们可以轻松地用 PyTorch 代码翻译注意力计算的公式。(注意,我这里的 mask 表示哪些地方要填负无穷,而不是像之前讲的表示哪些地方有效)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 MY_INF = 1e12 def attention (q: torch.Tensor, k: torch.Tensor, v: torch.Tensor, mask: Optional [torch.Tensor] = None ): ''' Note: The dtype of mask must be bool ''' assert q.shape[-1 ] == k.shape[-1 ] d_k = k.shape[-1 ] tmp = torch.matmul(q, k.transpose(-2 , -1 )) / d_k**0.5 if mask is not None : tmp.masked_fill_(mask, -MY_INF) tmp = F.softmax(tmp, -1 ) tmp = torch.matmul(tmp, v) return tmp
这里有一个很坑的地方。引入了 <pad> 带来的 mask 后,会产生一个新的问题:可能一整行数据都是失效的,softmax 用到的所有 $x_i$ 可能都是负无穷。
这个数是没有意义的。如果用torch.inf来表示无穷大,就会令exp(torch.inf)=0,最后 softmax 结果会出现 NaN,代码大概率是跑不通的。
但是,大多数 PyTorch Transformer 教程压根就没提这一点,而他们的代码又还是能够跑通。拿放大镜仔细对比了代码后,我发现,他们的无穷大用的不是 torch.inf,而是自己随手设的一个极大值。这样,exp(-MY_INF)得到的不再是0,而是一个极小值。softmax 的结果就会等于分母的项数,而不是 NaN,不会有数值计算上的错误。
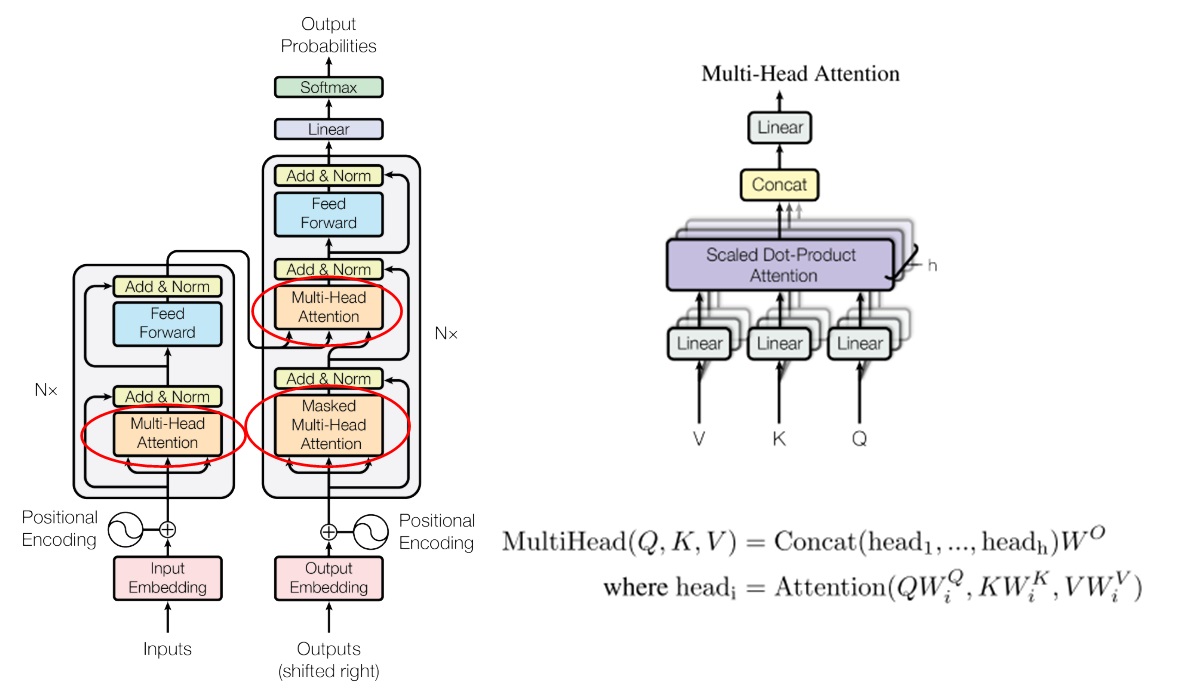
Multi-Head Attention
有了注意力计算,就可以实现多头注意力层了。多头注意力层是有学习参数的,它应该写成一个类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 class MultiHeadAttention (nn.Module ): def __init__ (self, heads: int , d_model: int , dropout: float = 0.1 ): super ().__init__() assert d_model % heads == 0 self.d_k = d_model // heads self.heads = heads self.d_model = d_model self.q = nn.Linear(d_model, d_model) self.k = nn.Linear(d_model, d_model) self.v = nn.Linear(d_model, d_model) self.out = nn.Linear(d_model, d_model) self.dropout = nn.Dropout(dropout) def forward (self, q: torch.Tensor, k: torch.Tensor, v: torch.Tensor, mask: Optional [torch.Tensor] = None ): assert q.shape[0 ] == k.shape[0 ] assert q.shape[0 ] == v.shape[0 ] assert k.shape[1 ] == v.shape[1 ] n, q_len = q.shape[0 :2 ] n, k_len = k.shape[0 :2 ] q_ = self.q(q).reshape(n, q_len, self.heads, self.d_k).transpose(1 , 2 ) k_ = self.k(k).reshape(n, k_len, self.heads, self.d_k).transpose(1 , 2 ) v_ = self.v(v).reshape(n, k_len, self.heads, self.d_k).transpose(1 , 2 ) attention_res = attention(q_, k_, v_, mask) concat_res = attention_res.transpose(1 , 2 ).reshape( n, q_len, self.d_model) concat_res = self.dropout(concat_res) output = self.out(concat_res) return output
这段代码一处很灵性的地方。在 Transformer 的论文中,多头注意力是先把每个词的表示拆成$h$个头,再对每份做投影、注意力,最后拼接起来,再投影一次。其实,拆开与拼接操作是多余的。我们可以通过一些形状上的操作,等价地实现拆开与拼接,以提高运行效率。
具体来说,我们可以一开始就让所有头的数据经过同一个线性层。之后在做注意力之前把头和序列数这两维转置一下。这两步操作和拆开来做投影、注意力是等价的。做完了注意力操作之后,再把两个维度转置回来,这和拼接操作是等价的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 def forward (self, q: torch.Tensor, k: torch.Tensor, v: torch.Tensor, mask: Optional [torch.Tensor] = None ): assert q.shape[0 ] == k.shape[0 ] assert q.shape[0 ] == v.shape[0 ] assert k.shape[1 ] == v.shape[1 ] n, q_len = q.shape[0 :2 ] n, k_len = k.shape[0 :2 ] q_ = self.q(q).reshape(n, q_len, self.heads, self.d_k).transpose(1 , 2 ) k_ = self.k(k).reshape(n, k_len, self.heads, self.d_k).transpose(1 , 2 ) v_ = self.v(v).reshape(n, k_len, self.heads, self.d_k).transpose(1 , 2 ) attention_res = attention(q_, k_, v_, mask) concat_res = attention_res.transpose(1 , 2 ).reshape( n, q_len, self.d_model) concat_res = self.dropout(concat_res) output = self.out(concat_res) return output
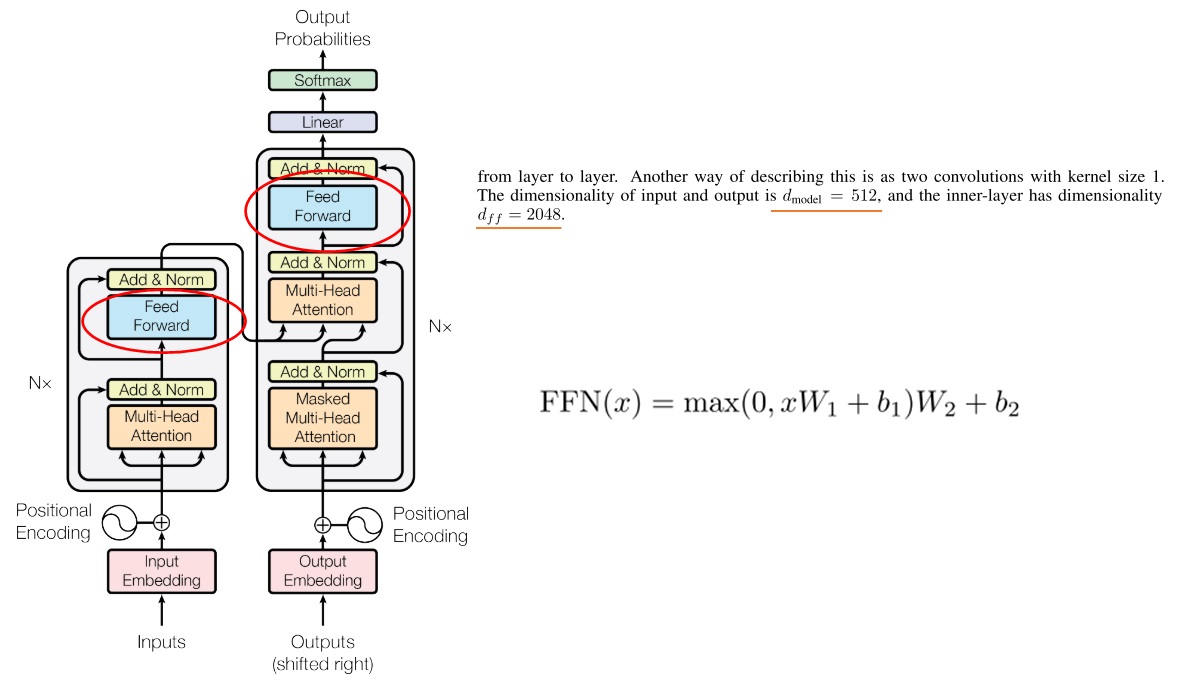
前馈网络
前馈网络太简单了,两个线性层,没什么好说的。注意内部那个隐藏层的维度大小$d_{ff}$会比$d_{model}$更大一点。
1 2 3 4 5 6 7 8 9 10 11 12 13 class FeedForward (nn.Module ): def __init__ (self, d_model: int , d_ff: int , dropout: float = 0.1 ): super ().__init__() self.layer1 = nn.Linear(d_model, d_ff) self.dropout = nn.Dropout(dropout) self.layer2 = nn.Linear(d_ff, d_model) def forward (self, x ): x = self.layer1(x) x = self.dropout(F.relu(x)) x = self.layer2(x) return x
Encoder & Decoder 准备好一切组件后,就可以把模型一层一层搭起来了。先搭好每个 Encoder 层和 Decoder 层,再拼成 Encoder 和 Decoder。
Encoder 层和 Decoder 层的结构与论文中的描述一致,且每个子层后面都有一个 dropout,和上一层之间使用了残差连接。归一化的方法是 LayerNorm。顺带一提,不仅是这些层,前面很多子层的计算中都加入了 dropout。
再提一句 mask。由于 encoder 和 decoder 的输入不同,它们的填充情况不同,产生的 mask 也不同。后文会展示这些 mask 的生成方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 class EncoderLayer (nn.Module ): def __init__ (self, heads: int , d_model: int , d_ff: int , dropout: float = 0.1 ): super ().__init__() self.self_attention = MultiHeadAttention(heads, d_model, dropout) self.ffn = FeedForward(d_model, d_ff, dropout) self.norm1 = nn.LayerNorm(d_model) self.norm2 = nn.LayerNorm(d_model) self.dropout1 = nn.Dropout(dropout) self.dropout2 = nn.Dropout(dropout) def forward (self, x, src_mask: Optional [torch.Tensor] = None ): tmp = self.self_attention(x, x, x, src_mask) tmp = self.dropout1(tmp) x = self.norm1(x + tmp) tmp = self.ffn(x) tmp = self.dropout2(tmp) x = self.norm2(x + tmp) return x class DecoderLayer (nn.Module ): def __init__ (self, heads: int , d_model: int , d_ff: int , dropout: float = 0.1 ): super ().__init__() self.self_attention = MultiHeadAttention(heads, d_model, dropout) self.attention = MultiHeadAttention(heads, d_model, dropout) self.ffn = FeedForward(d_model, d_ff, dropout) self.norm1 = nn.LayerNorm(d_model) self.norm2 = nn.LayerNorm(d_model) self.norm3 = nn.LayerNorm(d_model) self.dropout1 = nn.Dropout(dropout) self.dropout2 = nn.Dropout(dropout) self.dropout3 = nn.Dropout(dropout) def forward (self, x, encoder_kv: torch.Tensor, dst_mask: Optional [torch.Tensor] = None , src_dst_mask: Optional [torch.Tensor] = None ): tmp = self.self_attention(x, x, x, dst_mask) tmp = self.dropout1(tmp) x = self.norm1(x + tmp) tmp = self.attention(x, encoder_kv, encoder_kv, src_dst_mask) tmp = self.dropout2(tmp) x = self.norm2(x + tmp) tmp = self.ffn(x) tmp = self.dropout3(tmp) x = self.norm3(x + tmp) return x
Encoder 和 Decoder 就是在所有子层前面加了一个嵌入层、一个位置编码,再把多个子层堆起来了而已,其他输入输出照搬即可。注意,我们可以给嵌入层输入pad_idx参数,让<pad>的计算不对梯度产生贡献。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 class Encoder (nn.Module ): def __init__ (self, vocab_size: int , pad_idx: int , d_model: int , d_ff: int , n_layers: int , heads: int , dropout: float = 0.1 , max_seq_len: int = 120 ): super ().__init__() self.embedding = nn.Embedding(vocab_size, d_model, pad_idx) self.pe = PositionalEncoding(d_model, max_seq_len) self.layers = [] for i in range (n_layers): self.layers.append(EncoderLayer(heads, d_model, d_ff, dropout)) self.layers = nn.ModuleList(self.layers) self.dropout = nn.Dropout(dropout) def forward (self, x, src_mask: Optional [torch.Tensor] = None ): x = self.embedding(x) x = self.pe(x) x = self.dropout(x) for layer in self.layers: x = layer(x, src_mask) return x class Decoder (nn.Module ): def __init__ (self, vocab_size: int , pad_idx: int , d_model: int , d_ff: int , n_layers: int , heads: int , dropout: float = 0.1 , max_seq_len: int = 120 ): super ().__init__() self.embedding = nn.Embedding(vocab_size, d_model, pad_idx) self.pe = PositionalEncoding(d_model, max_seq_len) self.layers = [] for i in range (n_layers): self.layers.append(DecoderLayer(heads, d_model, d_ff, dropout)) self.layers = nn.Sequential(*self.layers) self.dropout = nn.Dropout(dropout) def forward (self, x, encoder_kv, dst_mask: Optional [torch.Tensor] = None , src_dst_mask: Optional [torch.Tensor] = None ): x = self.embedding(x) x = self.pe(x) x = self.dropout(x) for layer in self.layers: x = layer(x, encoder_kv, dst_mask, src_dst_mask) return x
终于,激动人心的时候到来了。我们要把各个子模块组成变形金刚(Transformer)了。先过一遍所有的代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 class Transformer (nn.Module ): def __init__ (self, src_vocab_size: int , dst_vocab_size: int , pad_idx: int , d_model: int , d_ff: int , n_layers: int , heads: int , dropout: float = 0.1 , max_seq_len: int = 200 ): super ().__init__() self.encoder = Encoder(src_vocab_size, pad_idx, d_model, d_ff, n_layers, heads, dropout, max_seq_len) self.decoder = Decoder(dst_vocab_size, pad_idx, d_model, d_ff, n_layers, heads, dropout, max_seq_len) self.pad_idx = pad_idx self.output_layer = nn.Linear(d_model, dst_vocab_size) def generate_mask (self, q_pad: torch.Tensor, k_pad: torch.Tensor, with_left_mask: bool = False ): assert q_pad.device == k_pad.device n, q_len = q_pad.shape n, k_len = k_pad.shape mask_shape = (n, 1 , q_len, k_len) if with_left_mask: mask = 1 - torch.tril(torch.ones(mask_shape)) else : mask = torch.zeros(mask_shape) mask = mask.to(q_pad.device) for i in range (n): mask[i, :, q_pad[i], :] = 1 mask[i, :, :, k_pad[i]] = 1 mask = mask.to(torch.bool ) return mask def forward (self, x, y ): src_pad_mask = x == self.pad_idx dst_pad_mask = y == self.pad_idx src_mask = self.generate_mask(src_pad_mask, src_pad_mask, False ) dst_mask = self.generate_mask(dst_pad_mask, dst_pad_mask, True ) src_dst_mask = self.generate_mask(dst_pad_mask, src_pad_mask, False ) encoder_kv = self.encoder(x, src_mask) res = self.decoder(y, encoder_kv, dst_mask, src_dst_mask) res = self.output_layer(res) return res
我们一点一点来看。先看初始化函数。初始化函数的输入其实就是 Transformer 模型的超参数。总结一下,Transformer 应该有这些超参数:
d_model 模型中大多数词向量表示的维度大小d_ff 前馈网络隐藏层维度大小n_layers 堆叠的 Encoder & Decoder 层数head 多头注意力的头数dropout Dropout 的几率
另外,为了构建嵌入层,要知道源语言、目标语言的词典大小,并且提供pad_idx。为了预处理位置编码,需要提前知道一个最大序列长度。
照着子模块的初始化参数表,把参数归纳到__init__的参数表里即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def __init__ (self, src_vocab_size: int , dst_vocab_size: int , pad_idx: int , d_model: int , d_ff: int , n_layers: int , heads: int , dropout: float = 0.1 , max_seq_len: int = 200 ): super ().__init__() self.encoder = Encoder(src_vocab_size, pad_idx, d_model, d_ff, n_layers, heads, dropout, max_seq_len) self.decoder = Decoder(dst_vocab_size, pad_idx, d_model, d_ff, n_layers, heads, dropout, max_seq_len) self.pad_idx = pad_idx self.output_layer = nn.Linear(d_model, dst_vocab_size)
再看一下 forward 函数。forward先预处理好了所有的 mask,再逐步执行 Transformer 的计算:先是通过 Encoder 获得源语言的中间表示encoder_kv,再把它和目标语言y的输入一起传入 Decoder,最后经过线性层输出结果res。由于 PyTorch 的交叉熵损失函数自带了 softmax 操作,这里不需要多此一举。
Transformer 论文提到,softmax 前的那个线性层可以和嵌入层共享权重。也就是说,嵌入和输出前的线性层分别完成了词序号到词嵌入的正反映射,两个操作应该是互逆的。但是,词嵌入矩阵不是一个方阵,它根本不能求逆矩阵。我想破头也没想清楚是怎么让线性层可以和嵌入层共享权重的。网上的所有实现都没有对这个细节多加介绍,只是新建了一个线性层。我也照做了。
1 2 3 4 5 6 7 8 9 10 11 def forward (self, x, y ): src_pad_mask = x == self.pad_idx dst_pad_mask = y == self.pad_idx src_mask = self.generate_mask(src_pad_mask, src_pad_mask, False ) dst_mask = self.generate_mask(dst_pad_mask, dst_pad_mask, True ) src_dst_mask = self.generate_mask(dst_pad_mask, src_pad_mask, False ) encoder_kv = self.encoder(x, src_mask) res = self.decoder(y, encoder_kv, dst_mask, src_dst_mask) res = self.output_layer(res) return res
等了很久,现在可以来仔细看一看 mask 的生成方法了。回忆一下,表示该字符是否有效的 mask 有两个来源。第一个是论文里提到的,用于模拟串行推理的 mask;另一个是填充操作的空白字符引入的 mask。generate_mask 用于生成这些 mask。
generate_mask 的输入有 query 句子和 key 句子的 pad mask q_pad, k_pad,它们的形状为[n, seq_len]。若某处为 True,则表示这个地方的字符是<pad>。对于自注意力,query 和 key 都是一样的;而在 Decoder 的第二个多头注意力层中,query 来自目标语言,key 来自源语言。with_left_mask 表示是不是要加入 Decoder 里面的模拟串行推理的 mask,它会在掩码自注意力里用到。
1 2 3 4 def generate_mask (self, q_pad: torch.Tensor, k_pad: torch.Tensor, with_left_mask: bool = False ):
一开始,先取好维度信息,定好张量的形状。在注意力操作中,softmax 前的那个量的形状是 [n, heads, q_len, k_len],表示每一批每一个头的每一个query对每个key之间的相似度。每一个头的mask是一样的。因此,除heads维可以广播外,mask 的形状应和它一样。
1 mask_shape = (n, 1 , q_len, k_len)
再新建一个表示最终 mask 的张量。如果不用 Decoder 的那种 mask,就生成一个全零的张量;否则,生成一个上三角为0,其余地方为1的张量。注意,在我的代码中,mask 为 True 或1就表示这个地方需要填负无穷。
1 2 3 4 if with_left_mask: mask = 1 - torch.tril(torch.ones(mask_shape)) else : mask = torch.zeros(mask_shape)
最后,把有 <pad> 的地方也标记一下。从mask的形状[n, 1, q_len, k_len]可以知道,q_pad 表示哪些行是无效的,k_pad 表示哪些列是无效的。如果query句子的第i个字符是<pad>,则应该令mask[:, :, i, :] = 1; 如果key句子的第j个字符是<pad>,则应该令mask[:, :, :, j] = 1。
下面的代码利用了PyTorch的取下标机制,直接并行地完成了mask赋值。
1 2 3 for i in range (n): mask[i, :, q_pad[i], :] = 1 mask[i, :, :, k_pad[i]] = 1
完整代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 def generate_mask (self, q_pad: torch.Tensor, k_pad: torch.Tensor, with_left_mask: bool = False ): assert q_pad.device == k_pad.device n, q_len = q_pad.shape n, k_len = k_pad.shape mask_shape = (n, 1 , q_len, k_len) if with_left_mask: mask = 1 - torch.tril(torch.ones(mask_shape)) else : mask = torch.zeros(mask_shape) mask = mask.to(q_pad.device) for i in range (n): mask[i, :, q_pad[i], :] = 1 mask[i, :, :, k_pad[i]] = 1 mask = mask.to(torch.bool ) return mask
看完了mask的生成方法后,我们回到前一步,看看mask会在哪些地方被调用。
在 Transformer 中,有三类多头注意力层,它们的 mask 也不同。Encoder 的多头注意力层的 query 和 key 都来自源语言;Decoder 的第一个多头注意力层的 query 和 key 都来自目标语言;Decoder 的第二个多头注意力层的 query 来自目标语言, key 来自源语言。另外,Decoder 的第一个多头注意力层要加串行推理的那个 mask。按照上述描述生成mask即可。
1 2 3 4 5 6 7 8 9 10 11 def forward (self, x, y ): src_pad_mask = x == self.pad_idx dst_pad_mask = y == self.pad_idx src_mask = self.generate_mask(src_pad_mask, src_pad_mask, False ) dst_mask = self.generate_mask(dst_pad_mask, dst_pad_mask, True ) src_dst_mask = self.generate_mask(dst_pad_mask, src_pad_mask, False ) encoder_kv = self.encoder(x, src_mask) res = self.decoder(y, encoder_kv, dst_mask, src_dst_mask) res = self.output_layer(res) return res
到此,Transfomer 模型总算编写完成了。
这里再帮大家排一个坑。PyTorch的官方Transformer中使用了下面的参数初始化方式。但是,实际测试后,不知道为什么,我发现使用这种初始化会让模型训不起来。
1 2 3 4 def init_weights (self ): for p in self.parameters(): if p.dim() > 1 : nn.init.xavier_uniform_(p)
我去翻了翻PyTorch的Transformer示例,发现官方的示例根本没用到Transformer,而是用子模块nn.TransformerDecoder, nn.TransformerEncoder自己搭了一个新的Transformer。这些子模块其实都有自己的init_weights方法。看来官方都信不过自己的Transformer,这个Transformer类的初始化方法就有问题。
在我们的代码中,我们不必手动对参数初始化。PyTorch对每个线性层默认的参数初始化方式就够好了。
训练 准备好了模型、数据集后,剩下的工作非常惬意,只要随便调用一下就行了。训练的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 import torchimport torch.nn as nnimport timefrom dldemos.Transformer.data_load import (get_batch_indices, load_cn_vocab, load_en_vocab, load_train_data, maxlen) from dldemos.Transformer.model import Transformerbatch_size = 64 lr = 0.0001 d_model = 512 d_ff = 2048 n_layers = 6 heads = 8 dropout_rate = 0.2 n_epochs = 60 PAD_ID = 0 def main (): device = 'cuda' cn2idx, idx2cn = load_cn_vocab() en2idx, idx2en = load_en_vocab() Y, X = load_train_data() print_interval = 100 model = Transformer(len (en2idx), len (cn2idx), PAD_ID, d_model, d_ff, n_layers, heads, dropout_rate, maxlen) model.to(device) optimizer = torch.optim.Adam(model.parameters(), lr) citerion = nn.CrossEntropyLoss(ignore_index=PAD_ID) tic = time.time() cnter = 0 for epoch in range (n_epochs): for index, _ in get_batch_indices(len (X), batch_size): x_batch = torch.LongTensor(X[index]).to(device) y_batch = torch.LongTensor(Y[index]).to(device) y_input = y_batch[:, :-1 ] y_label = y_batch[:, 1 :] y_hat = model(x_batch, y_input) y_label_mask = y_label != PAD_ID preds = torch.argmax(y_hat, -1 ) correct = preds == y_label acc = torch.sum (y_label_mask * correct) / torch.sum (y_label_mask) n, seq_len = y_label.shape y_hat = torch.reshape(y_hat, (n * seq_len, -1 )) y_label = torch.reshape(y_label, (n * seq_len, )) loss = citerion(y_hat, y_label) optimizer.zero_grad() loss.backward() torch.nn.utils.clip_grad_norm_(model.parameters(), 1 ) optimizer.step() if cnter % print_interval == 0 : toc = time.time() interval = toc - tic minutes = int (interval // 60 ) seconds = int (interval % 60 ) print (f'{cnter:08d} {minutes:02d} :{seconds:02d} ' f' loss: {loss.item()} acc: {acc.item()} ' ) cnter += 1 model_path = 'dldemos/Transformer/model.pth' torch.save(model.state_dict(), model_path) print (f'Model saved to {model_path} ' ) if __name__ == '__main__' : main()
所有的超参数都写在代码开头。在模型结构上,我使用了和原论文一样的超参数。
1 2 3 4 5 6 7 8 9 10 batch_size = 64 lr = 0.0001 d_model = 512 d_ff = 2048 n_layers = 6 heads = 8 dropout_rate = 0.2 n_epochs = 60 PAD_ID = 0
之后,进入主函数。一开始,我们调用load_data.py提供的API,获取中英文序号到单词的转换词典,并获取已经打包好的训练数据。
1 2 3 4 5 6 7 def main (): device = 'cuda' cn2idx, idx2cn = load_cn_vocab() en2idx, idx2en = load_en_vocab() Y, X = load_train_data()
接着,我们用参数初始化好要用到的对象,比如模型、优化器、损失函数。
1 2 3 4 5 6 7 8 9 10 11 print_interval = 100 model = Transformer(len (en2idx), len (cn2idx), PAD_ID, d_model, d_ff, n_layers, heads, dropout_rate, maxlen) model.to(device) optimizer = torch.optim.Adam(model.parameters(), lr) citerion = nn.CrossEntropyLoss(ignore_index=PAD_ID) tic = time.time() cnter = 0
再然后,进入训练循环。我们从X, Y里取出源语言和目标语言的序号数组,输入进模型里。别忘了,Transformer可以并行训练。我们给模型输入目标语言前n-1个单词,用第2到第n个单词作为监督标签。1 2 3 4 5 6 7 for epoch in range (n_epochs): for index, _ in get_batch_indices(len (X), batch_size): x_batch = torch.LongTensor(X[index]).to(device) y_batch = torch.LongTensor(Y[index]).to(device) y_input = y_batch[:, :-1 ] y_label = y_batch[:, 1 :] y_hat = model(x_batch, y_input)
y_hat后,我们可以把输出概率分布中概率最大的那个单词作为模型给出的预测单词,算一个单词预测准确率。当然,我们要排除掉<pad>的影响。
1 2 3 4 y_label_mask = y_label != PAD_ID preds = torch.argmax(y_hat, -1 ) correct = preds == y_label acc = torch.sum (y_label_mask * correct) / torch.sum (y_label_mask)
我们最后算一下loss,并执行梯度下降,训练代码就写完了。为了让训练更稳定,不出现梯度过大的情况,我们可以用torch.nn.utils.clip_grad_norm_(model.parameters(), 1)裁剪梯度。
1 2 3 4 5 6 7 8 9 n, seq_len = y_label.shape y_hat = torch.reshape(y_hat, (n * seq_len, -1 )) y_label = torch.reshape(y_label, (n * seq_len, )) loss = citerion(y_hat, y_label) optimizer.zero_grad() loss.backward() torch.nn.utils.clip_grad_norm_(model.parameters(), 1 ) optimizer.step()
实验 在本项目的实验中,使用单卡3090,约10分钟就能完成训练。最终的训练准确率可以到达90%以上。
1 00006300 12 :12 loss: 0.43494755029678345 acc: 0.9049844145774841
该数据集没有提供测试集(原仓库里的测试集来自训练集,这显然不合理)。且由于词表太小,不太好构建测试集。因此,我没有编写从测试集里生成句子并算BLEU score的代码,而是写了一份翻译给定句子的代码。要编写测试BLUE score的代码,只需要把翻译任意句子的代码改个输入,加一个求BLEU score的函数即可。这份翻译任意句子的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 import torchfrom dldemos.Transformer.data_load import (load_cn_vocab, load_en_vocab, idx_to_sentence, maxlen) from dldemos.Transformer.model import Transformerbatch_size = 1 lr = 0.0001 d_model = 512 d_ff = 2048 n_layers = 6 heads = 8 dropout_rate = 0.2 n_epochs = 60 PAD_ID = 0 def main (): device = 'cuda' cn2idx, idx2cn = load_cn_vocab() en2idx, idx2en = load_en_vocab() model = Transformer(len (en2idx), len (cn2idx), 0 , d_model, d_ff, n_layers, heads, dropout_rate, maxlen) model.to(device) model.eval () model_path = 'dldemos/Transformer/model.pth' model.load_state_dict(torch.load(model_path)) my_input = ['we' , "should" , "protect" , "environment" ] x_batch = torch.LongTensor([[en2idx[x] for x in my_input]]).to(device) cn_sentence = idx_to_sentence(x_batch[0 ], idx2en, True ) print (cn_sentence) y_input = torch.ones(batch_size, maxlen, dtype=torch.long).to(device) * PAD_ID y_input[0 ] = en2idx['<S>' ] with torch.no_grad(): for i in range (1 , y_input.shape[1 ]): y_hat = model(x_batch, y_input) for j in range (batch_size): y_input[j, i] = torch.argmax(y_hat[j, i - 1 ]) output_sentence = idx_to_sentence(y_input[0 ], idx2cn, True ) print (output_sentence) if __name__ == '__main__' : main()
一开始,还是先获取词表,并初始化模型。
1 2 3 4 5 6 7 8 9 10 11 12 def main (): device = 'cuda' cn2idx, idx2cn = load_cn_vocab() en2idx, idx2en = load_en_vocab() model = Transformer(len (en2idx), len (cn2idx), 0 , d_model, d_ff, n_layers, heads, dropout_rate, maxlen) model.to(device) model.eval () model_path = 'dldemos/Transformer/model.pth' model.load_state_dict(torch.load(model_path))
之后,我们用自己定义的句子(要做好分词)代替原来的输入x_batch。如果要测试某个数据集,只要把这里x_batch换成测试集里的数据即可。idx_to_sentence转回英文,看看序号转换有没有出错。
1 2 3 4 5 my_input = ['we' , "should" , "protect" , "environment" ] x_batch = torch.LongTensor([[en2idx[x] for x in my_input]]).to(device) cn_sentence = idx_to_sentence(x_batch[0 ], idx2en, True ) print (cn_sentence)
这段代码会输出we should protect environment。这说明x_batch是我们想要的序号数组。
最后,我们利用Transformer自回归地生成句子,并输出句子。
1 2 3 4 5 6 7 8 9 10 11 y_input = torch.ones(batch_size, maxlen, dtype=torch.long).to(device) * PAD_ID y_input[0 ] = en2idx['<S>' ] with torch.no_grad(): for i in range (1 , y_input.shape[1 ]): y_hat = model(x_batch, y_input) for j in range (batch_size): y_input[j, i] = torch.argmax(y_hat[j, i - 1 ]) output_sentence = idx_to_sentence(y_input[0 ], idx2cn, True ) print (output_sentence)
要自回归地生成句子,我们先给句子填入无效字符<pad>,再把第一个字符换成句子开始字符<S>。
1 2 3 y_input = torch.ones(batch_size, maxlen, dtype=torch.long).to(device) * PAD_ID y_input[0 ] = en2idx['<S>' ]
之后,我们循环调用Transformer,获取下一个单词的概率分布。我们可以认为,概率最大的那个单词就是模型预测的下一个单词。因此,我们可以用argmax获取预测的下一个单词的序号,填回y_input。这里的y_input和训练时那个y_batch是同一个东西。
1 2 3 4 5 6 with torch.no_grad(): for i in range (1 , y_input.shape[1 ]): y_hat = model(x_batch, y_input) for j in range (batch_size): y_input[j, i] = torch.argmax(y_hat[j, i - 1 ])
最后只要输出生成的句子即可。
1 2 output_sentence = idx_to_sentence(y_input[0 ], idx2cn, True ) print (output_sentence)
由于训练数据非常少,而且数据都来自新闻,我只好选择了一个比较常见的句子”we should protect environment”作为输入。模型翻译出了一个比较奇怪的结果。
1 <S> 要 保护 环境 保护 环境 保护 环境 保护 环境 保护 环境 保护 环境 保护 环境 的 生态 环境 落实 好 环境 </S> 环境 </S> 有效 保护 环境 </S>...
可以看出,模型确实学到了东西,能翻译出“要保护环境”。但是,这翻译的结果也太长太奇怪了。感觉是对训练数据过拟合了。当然,还是那句话,训练集里的数据太少。要提升模型性能并缓解过拟合,加数据集是最好的方法。这个结果起码说明我们Tranformer的编写没有问题。
在生成新句子的时候,我直接拿概率最高的单词当做预测的下一个单词。其实,还有一些更加高级的生成算法,比如Beam Search。如果模型训练得比较好,可以用这些高级一点的算法提高生成句子的质量。
我读了网上几份Transformer实现。这些实现在生成句子算BLEU score时,竟然直接输入测试句子的前n-1个单词,把输出的n-1个单词拼起来,作为模型的翻译结果。这个过程等价于告诉你前i个翻译答案,你去输出第i+1个单词,再把每个结果拼起来。这样写肯定是不合理的。正常来说应该是照着我这样自回归地生成翻译句子。大家参考网上的Transformer代码时要多加留心。
总结 只要读懂了 Transfomer 的论文,用 PyTorch 实现一遍 Transformer 是很轻松的。但是,代码实现中有非常多论文不会提及的细节,你自己实现时很容易踩坑。在这篇文章里,我完整地介绍了一个英中翻译 Transformer 的 PyTorch 实现,相信读者能够跟随这篇文章实现自己的 Transformer,并在代码实现的过程中加深对论文的理解。
再稍微总结一下代码实现中的一些值得注意的地方。代码中最大的难点是 mask 的实现。mask 的处理稍有闪失,就可能会让计算结果中遍布 NaN。一定要想清楚各个模块的 mask 是从哪来的,它们在注意力计算里是怎么被用上的。
另外,有两处地方的实现比较灵活。一处是位置编码的实现,一处是多头注意力中怎么描述“多头”。其他模块的实现都大差不差,千篇一律。
最后再提醒一句,要从头训练一个模型,一定要从小数据集上开始做。不然你训练个半天,结果差了,你不知道是数据有问题,还是代码有问题。我之前一直在使用很大的训练集,每次调试都非常麻烦,浪费了很多时间。希望大家引以为戒。
参考资料 感谢 https://github.com/P3n9W31/transformer-pytorch 提供的数据集。
一份简明的Transformer实现代码 https://github.com/hyunwoongko/transformer
一篇不错的Transformer实现教程 https://towardsdatascience.com/how-to-code-the-transformer-in-pytorch-24db27c8f9ec
过期内容 我第一次写这篇文章时过于仓促,文章中有不少错误,实验部分也没写完。我后来把本文又重新修改了一遍,补充了实验部分。
我之前使用了一个较大的数据集,但发现做实验做得很慢,于是换了一个较小的数据集。以前的数据集预处理介绍就挪到这里了。
数据集与评测方法 在开启一个深度学习项目之初,要把任务定义好。准确来说,我们要明白这个任务是在完成一个怎样的映射,并准备一个用于评测的数据集,定义好评价指标。
英中翻译,这个任务非常明确,就是把英文的句子翻译成中文。英中翻译的数据集应该包含若干个句子对,每个句子对由一句英文和它对应的中文翻译组成。
中英翻译的数据集不是很好找。有几个比较出名的数据集的链接已经失效了,还有些数据集需要注册与申请后才能获取。我在中文NLP语料库仓库(https://github.com/brightmart/nlp_chinese_corpus)找到了中英文平行语料 translation2019zh。该语料库由520万对中英文语料构成,训练集516万对,验证集3.9万对。用作训练和验证中英翻译模型是足够了。
机器翻译的评测指标叫做BLEU Score。如果模型输出的翻译和参考译文有越多相同的单词、连续2个相同单词、连续3个相同单词……,则得分越高。
PyTorch 提供了便捷的API,我们可以用一行代码算完BLEU Score。
1 2 3 4 5 >>> from torchtext.data.metrics import bleu_score>>> candidate_corpus = [['My' , 'full' , 'pytorch' , 'test' ], ['Another' , 'Sentence' ]]>>> references_corpus = [[['My' , 'full' , 'pytorch' , 'test' ], ['Completely' , 'Different' ]], [['No' , 'Match' ]]]>>> bleu_score(candidate_corpus, references_corpus) 0.8408964276313782
数据清洗 得到数据集后,下一步要做的是对数据集做处理,把原始数据转化成能够输入神经网络的张量。对于图片,预处理可能是裁剪、缩放,使所有图片都有一样的大小;对于文本,预处理可能是分词、填充。
在网盘 上下载好 translation2019zh 数据集后,我们来一步一步清洗这个数据集。这个数据集只有两个文件translation2019zh_train.json, translation2019zh_valid.json,它们的结构如下:
text 1 2 3 4 {"english": <english>, "chinese": <chinese>} {"english": <english>, "chinese": <chinese>} {"english": <english>, "chinese": <chinese>} ...
这些json文件有点不合标准,每对句子由一行json格式的记录组成。english属性是英文句子,chinese属性是中文句子。比如:
text 1 {"english": "In Italy ...", "chinese": "在意大利 ..."}
因此,在读取数据时,我们可以用下面的代码提取每对句子。
1 2 3 4 5 6 import jsonwith open (json_path, 'r' ) as fp: for line in fp: line = json.loads(line) english, chinese = line['english' ], line['chinese' ]
这个数据集有一点不干净,有一些句子对的中英文句子颠倒过来了。为此,我们要稍微处理一下,把这些句子对翻转过来。如果一个英文句子不全由 ASCII 组成,则它可能是一个被标错的中文句子。
1 2 3 if not english.isascii(): english, chinese = chinese, english
经过这一步,我们只得到了中英文的字符文本。而在NLP中,大部分处理的最小单位都是符号(token)——对于英文来说,符号是单词、标点;对于中文来说,符号是词语、标点。我们还需要一个符号化的过程。
英文符号化非常方便,torchtext 提供了非常便捷的英文分词 API。
1 2 3 4 from torchtext.data import get_tokenizertokenizer = get_tokenizer('basic_english' ) english = tokenizer(english)
而中文分词方面,我使用了jieba库。该库可以直接 pip 安装。
分词的 API 是 jieba.cut。由于分词的结果中,相邻的词之间有空格,我一股脑地把所有空白符给过滤掉了。
1 2 3 import jiebachinese = list (jieba.cut(chinese)) chinese = [x for x in chinese if x not in {' ' , '\t' }]
经过这些处理后,每句话被转换成了中文词语或英文单词的数组。整个处理代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def read_file (json_path ): english_sentences = [] chinese_sentences = [] tokenizer = get_tokenizer('basic_english' ) with open (json_path, 'r' ) as fp: for line in fp: line = json.loads(line) english, chinese = line['english' ], line['chinese' ] if not english.isascii(): english, chinese = chinese, english english = tokenizer(english) chinese = list (jieba.cut(chinese)) chinese = [x for x in chinese if x not in {' ' , '\t' }] english_sentences.append(english) chinese_sentences.append(chinese) return english_sentences, chinese_sentences
词语转序号 为了让计算机更方便地处理单词,我们还要把单词转换成序号。比如令apple为0号,banana为1号,则句子apple banana apple就转换成了0 1 0。
给每一个单词选一个标号,其实就是要建立一个词典。一般来说,我们可以利用他人的统计结果,挑选最常用的一些英文单词和中文词语构成词典。不过,现在我们已经有了一个庞大的中英语料库了,我们可以直接从这个语料库中挑选出最常见的词构成词典。
根据上一步处理得到的句子数组sentences,我们可以用下面的 Python 代码统计出最常见的一些词语,把它们和4个特殊字符<sos>, <eos>, <unk>, <pad>(句子开始字符、句子结束字符、频率太少没有被加入词典的词语、填充字符)一起构成词典。统计字符出现次数是通过 Python 的 Counter 类实现的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 from collections import Counterdef create_vocab (sentences, max_element=None ): """Note that max_element includes special characters""" default_list = ['<sos>' , '<eos>' , '<unk>' , '<pad>' ] char_set = Counter() for sentence in sentences: c_set = Counter(sentence) char_set.update(c_set) if max_element is None : return default_list + list (char_set.keys()) else : max_element -= 4 words_freq = char_set.most_common(max_element) words, freq = zip (*words_freq) return default_list + list (words)
准备好了词典后,我还编写了两个工具函数sentence_to_tensor,tensor_to_sentence,它们可以用于字符串数组与序号数组的互相转换。测试这些代码的脚本及其输出如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def main (): en_sens, zh_sens = read_file( 'data/translation2019zh/translation2019zh_valid.json' ) print (*en_sens[0 :3 ]) print (*zh_sens[0 :3 ]) en_vocab = create_vocab(en_sens, 10000 ) zh_vocab = create_vocab(zh_sens, 30000 ) print (list (en_vocab)[0 :10 ]) print (list (zh_vocab)[0 :10 ]) en_tensors = sentence_to_tensor(en_sens, en_vocab) zh_tensors = sentence_to_tensor(zh_sens, zh_vocab) print (tensor_to_sentence(en_tensors[0 ], en_vocab, True )) print (tensor_to_sentence(zh_tensors[0 ], zh_vocab))
text 1 2 3 4 5 6 ['slowly', 'and', 'not', 'without', 'struggle', ',', 'america', 'began', 'to', 'listen', '.'] ...] ['美国', '缓慢', '地', '开始', '倾听', ',', '但', '并非', '没有', '艰难曲折', '。'] ...] ['<sos>', '<eos>', '<unk>', '<pad>', 'the', '.', ',', 'of', 'and', 'to'] ['<sos>', '<eos>', '<unk>', '<pad>', '的', ',', '。', '在', '了', '和'] slowly and not without struggle , america began to listen . 美国缓慢地开始倾听,但并非没有<unk>。
在这一步中,有一个重要的参数:词典的大小。显然,词典越大,能处理的词语越多,但训练速度也会越慢。由于这个项目只是一个用于学习的demo,我设置了比较小的词典大小。想提升整个模型的性能的话,调大词典大小是一个最快的方法。
生成 Dataloader 都说程序员是新时代的农民工,这非常有道理。因为,作为程序员,你免不了要写一些繁重、无聊的数据处理脚本。还好,写完这些无聊的预处理代码后,总算可以使用 PyTorch 的 API 写一些有趣的代码了。
把词语数组转换成序号句子数组后,我们要考虑怎么把序号句子数组输入给模型了。文本数据通常长短不一,为了一次性处理一个 batch 的数据,要把短的句子填充,使得一批句子长度相等。写 Dataloader 时最主要的工作就是填充并对齐句子。
先看一下Dataset的写法。上一步得到的序号句子数组可以塞进Dataset里。注意,每个句子的前后要加上表示句子开始和结束的特殊符号。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 SOS_ID = 0 EOS_ID = 1 UNK_ID = 2 PAD_ID = 3 class TranslationDataset (Dataset ): def __init__ (self, en_tensor: np.ndarray, zh_tensor: np.ndarray ): super ().__init__() assert len (en_tensor) == len (zh_tensor) self.length = len (en_tensor) self.en_tensor = en_tensor self.zh_tensor = zh_tensor def __len__ (self ): return self.length def __getitem__ (self, index ): x = np.concatenate(([SOS_ID], self.en_tensor[index], [EOS_ID])) x = torch.from_numpy(x) y = np.concatenate(([SOS_ID], self.zh_tensor[index], [EOS_ID])) y = torch.from_numpy(y) return x, y
接下来看一下 DataLoader 的写法。在创建 Dataloader 时,最重要的是 collate_fn 的编写,这个函数决定了怎么把多条数据合成一个等长的 batch。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def get_dataloader (en_tensor: np.ndarray, zh_tensor: np.ndarray, batch_size=16 ): def collate_fn (batch ): ... dataset = TranslationDataset(en_tensor, zh_tensor) dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True , collate_fn=collate_fn) return dataloader
collate_fn 的输入是多个 dataset __getitem__ 的返回结果构成的数组。对于我们的 dataset 来说,collate_fn 的输入是 [(x1, y1), (x2, y2), ...] 。我们可以用 zip(*batch) 把二元组数组拆成两个数组 x, y 。
collate_fn 的输出就是将来 dataloader 的输出。PyTorch 提供了 pad_sequence 函数用来把一批数据填充至等长。
1 2 3 4 5 6 7 8 from torch.nn.utils.rnn import pad_sequencedef collate_fn (batch ): x, y = zip (*batch) x_pad = pad_sequence(x, batch_first=True , padding_value=PAD_ID) y_pad = pad_sequence(y, batch_first=True , padding_value=PAD_ID) return x_pad, y_pad
实现完collate_fn后,我们就可以得到了DataLoader。这样,数据集预处理部分大功告成。