在使用预训练 Stable Diffusion (SD) 生成图像时,如果将其 U-Net 的自注意力层在某去噪时刻的输入 K, V 替换成另一幅参考图像的,则输出图像会和参考图像更加相似。许多无需训练的 SD 编辑科研工作都运用了此性质。尤其对于是对于视频编辑任务,如果在生成某一帧时将注意力输入替换成之前帧的,则输出视频会更加连贯。在这篇文章中,我们将快速学习 SD 自注意力替换技术的原理,并在 Diffusers 里实现一个基于此技术的视频编辑流水线。
注意力计算
我们先来回顾一下 Transformer 论文中提出的注意力机制。所有注意力机制都基于一种叫做放缩点乘注意力(Scaled Dot-Product Attention)的运算:
其中,$Q \in \mathbb{R}^{a \times d_k}, K \in \mathbb{R}^{b \times d_k}, V \in \mathbb{R}^{b \times d_v}$。注意力计算可以理解成先算 $a$ 个长度为 $d_k$ 的向量对 $b$ 个长度为 $d_k$ 的向量的相似度,再以此相似度为权重算 $a$ 个向量对 $b$ 个长度为 $d_v$ 的向量的加权和。
注意力计算是没有可学习参数的。为了加入参数,Transformer 设计了如下所示的注意力层,其中 $W^Q, W^K, W^V, W^O$ 都是参数。
一般在使用注意力层时,会让$K=V$。这种注意力叫做交叉注意力。交叉注意力可以理解成数据 $A$ 想从数据 $B$ 里提取信息,提取的根据是 $A$ 里每个向量和 $B$ 里每个向量的相似度。
交叉注意力的特例是自注意力,此时 $Q=K=V$ 。这表示数据里的向量两两之间交换了一次信息。
SD 中的自注意力替换
SD 的 U-Net 既用到了自注意力,也用到了交叉注意力。自注意力用于图像特征自己内部信息聚合。交叉注意力用于让生成图像对齐文本,其 Q 来自图像特征,K, V 来自文本编码。
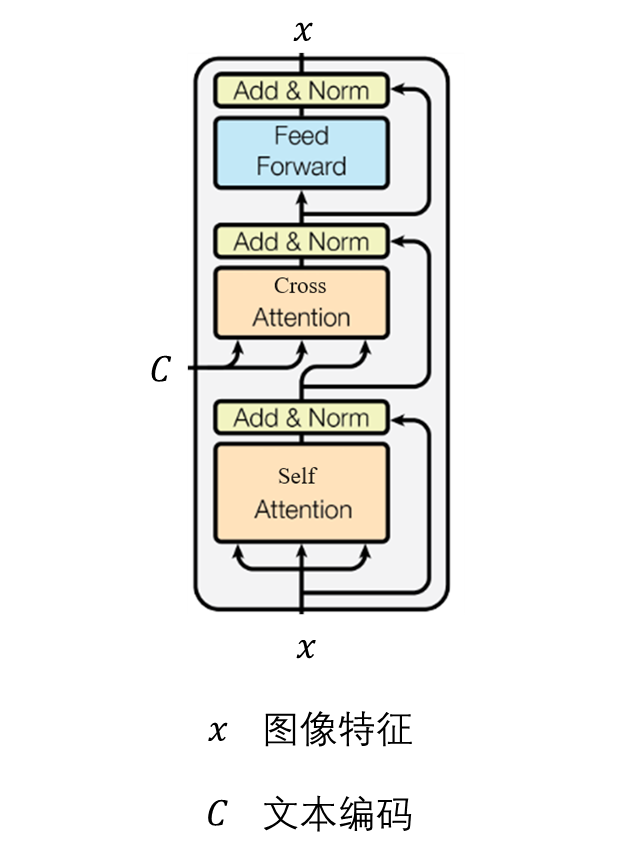
由于自注意力其实可以看成一种特殊的交叉注意力,我们可以把自注意力的 K, V 替换成来自另一幅参考图像的特征。这样,扩散模型的生成图片会既和原本要生成的图像相似,又和参考图像相似。当然,用来替换的特征必须和原来的特征「格式一致」,不然就生成不了有意义的结果了。
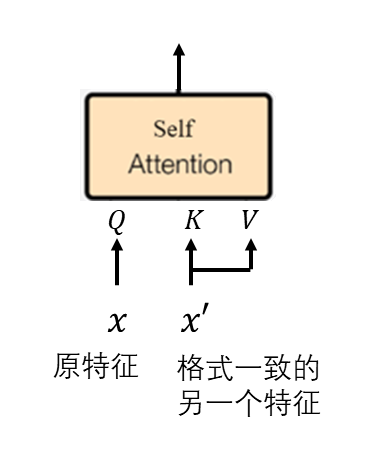
什么叫「格式一致」呢?我们知道,扩散模型在采样时有很多步,U-Net 中又有许多自注意力层。每一步时的每一个自注意力层的输入都有自己的「格式」。也就是说,如果你要把某时刻某自注意力层的 K, V 替换,就得先生成参考图像,用生成参考图像过程中此时刻此自注意力层的输入替换,而不能用其他时刻或者其他自注意力层的。
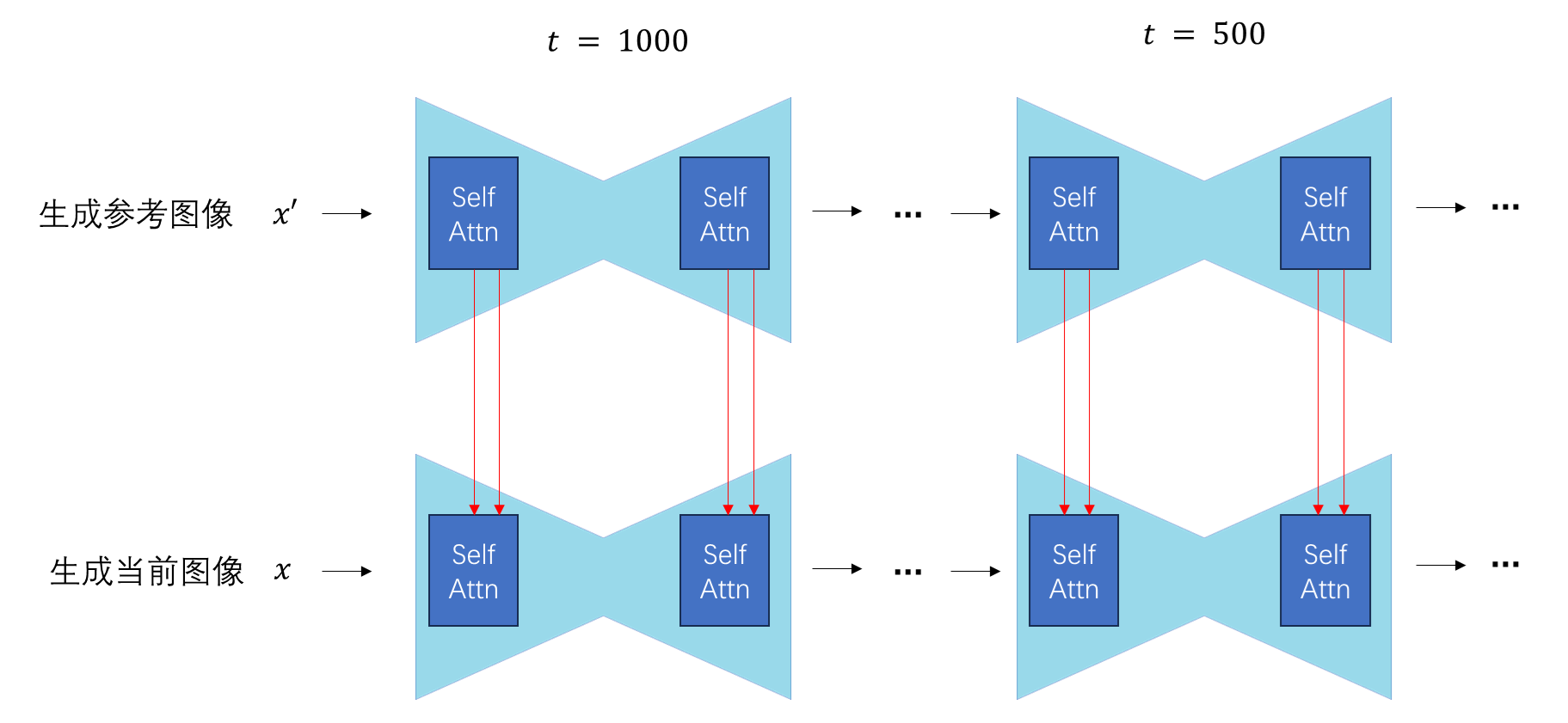
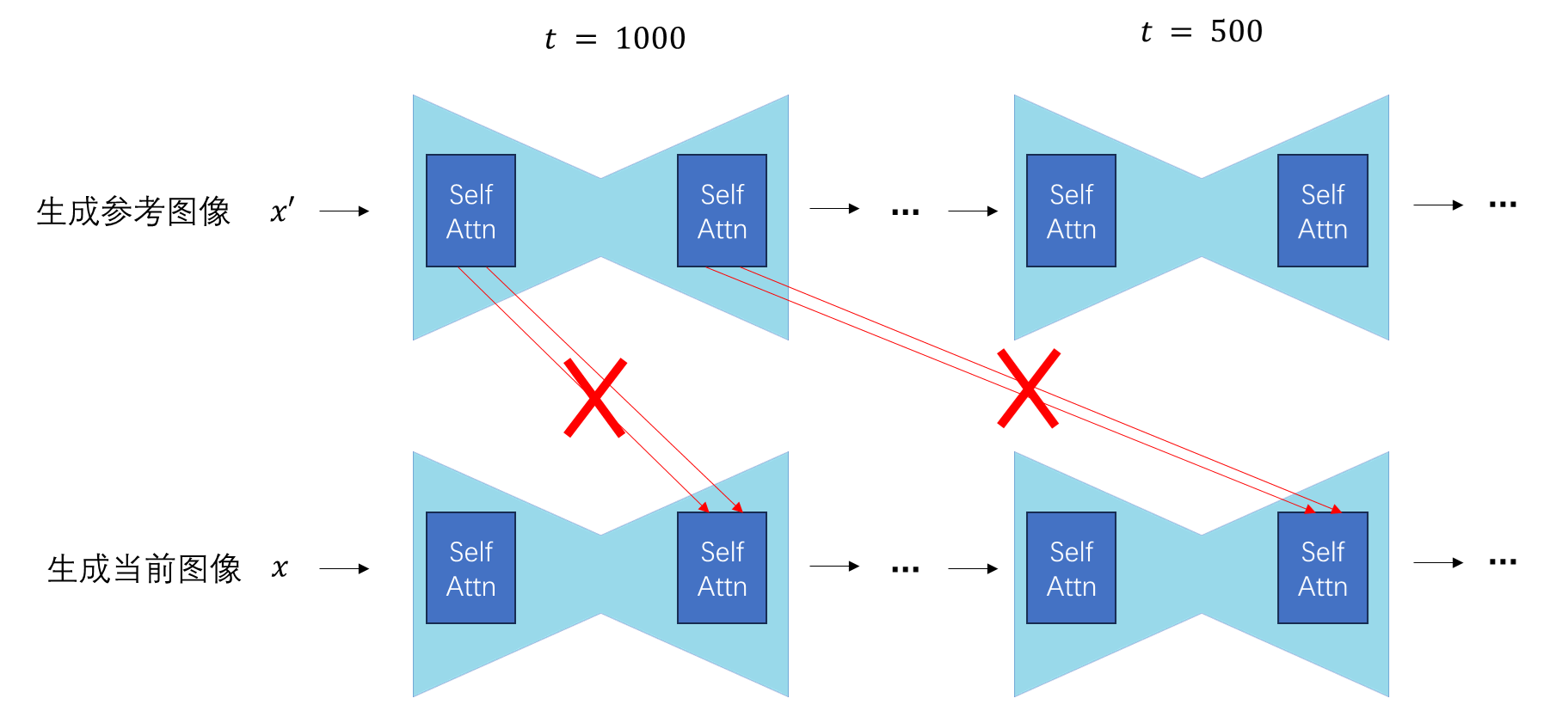
一般这种编辑技术只会用在自注意力层而不是交叉注意力层上,这是因为 SD 中的交叉注意力是用来关联图像与文字的,另一幅图像的信息无法输入。当然,除了 SD,只要是用到了自注意力模块的扩散模型,都能用此方法编辑,只不过大部分工作都是基于 SD 开发的。
自注意力替换的应用
自注意力替换最常见的应用是提升 SD 视频编辑的连续性。在此任务中,一般会先正常编辑第一帧,再将后续帧的自注意力的 K, V 替换成第一帧的。这种技术在文献中一般被称为帧间注意力(cross-frame attention)。较早提出此论文的工作是 Text2Video-Zero。
自注意力替换也可以用于提升单幅图像编辑的保真度。一个例子是拖拽单幅图像的 DragonDiffusion。此应用可以拓展到图像插值上,比如 DiffMorpher 在图像插值时对两幅参考图像的自注意力输入等比例插值,再替换掉对应插值图像的自注意力的 K, V。
在 Diffusers 里实现自注意力替换
Diffusers 的 U-Net 专门提供了用于修改注意力计算的 AttentionProcessor 类。借助相关接口,我们可以方便地修改注意力的计算方法。在这个示例项目中,我们来用 Diffusers 实现一个参考第一帧和上一帧的注意力输入的 SD 视频编辑流水线。相比逐帧生成编辑图片,该流水线的结果会更加平滑一点。项目网址:https://github.com/SingleZombie/DiffusersExample/tree/main/ReplaceAttn 。
AttentionProcessor
在 Diffusers 中,U-Net 的每一个注意力模块都有一个 AttentionProcessor 类的实例。AttentionProcessor 类的 __call__ 方法描述了注意力计算的过程。如果我们想修改某些注意力模块的计算,就需要自己定义一个注意力处理类,其 __call__ 方法的参数需与 AttentionProcessor 的兼容。之后,我们再调用相关接口把原来的处理类换成我们自己写的处理类。下面我们将先看一下 AttentionProcessor 类的实现细节,再实现我们自己的
注意力处理类。
AttentionProcessor 类在 diffusers/models/attention_processor.py 文件里。它只有一个 __call__ 方法,其主要内容如下:
1 | class AttnProcessor: |
方法参数中,hidden_states 是 Q, encoder_hidden_states 是 K, V。如果 K, V 没有传入(为 None),则 K, V 会被赋值成 Q。该方法的实现细节和 Tranformer 中的注意力层完全一样,此处就不多加解释了。一般替换注意力的输入时,我们不用改这个方法的实现,只会在需要的时候调用这个方法。
attention_processor.py 文件中还有一个功能类似的类 AttnProcessor2_0,它和 AttentionProcessor 的区别在于它调用了 PyTorch 2.0 起启用的算子 F.scaled_dot_product_attention 代替手动实现的注意力计算。这个算子更加高效,如果你确定 PyTorch 版本至少为 2.0,就可以用 AttnProcessor2_0 代替 AttentionProcessor。
看完了 AttentionProcessor 类后,我们来看该怎么在 U-Net 里将原注意力处理类替换成我们自己写的。U-Net 类的 attn_processors 属性会返回一个词典,它的 key 是每个处理类所在位置,比如 down_blocks.0.attentions.0.transformer_blocks.0.attn1.processor,它的 value 是每个处理类的实例。为了替换处理类,我们需要构建一个格式一样的词典attn_processor_dict,再调用 unet.set_attn_processor(attn_processor_dict) ,取代原来的 attn_processors。假如我们自己实现了处理类 MyAttnProcessor,我们可以编写下面的代码来实现替换:
1 | attn_processor_dict = {} |
实现帧间注意力处理类
熟悉了 AttentionProcessor 类的相关内容,我们来编写自己的帧间注意力处理类。在处理第一帧时,该类的行为不变。对于之后的每一帧,该类的 K, V 输入会被替换成视频第一帧和上一帧的输入在序列长度维度上的拼接结果,即:
你是否会感到疑惑:为什么 K, V 的序列长度可以修改?别忘了,在注意力计算中,Q, K, V 的形状分别是:$Q \in \mathbb{R}^{a \times d_k}, K \in \mathbb{R}^{b \times d_k}, V \in \mathbb{R}^{b \times d_v}$。注意力计算只要求 K,V 的序列长度 $b$ 相同,并没有要求 Q, K 的序列长度相同。
现在,注意力计算不再是一个没有状态的计算,它的运算结果取决于第一帧和上一帧的输入。因此,我们在注意力处理类中需要额外维护这两个变量。我们可以按照如下代码编写类的构造函数。除了处理继承外,我们还需要创建两个数据词典来存储不同时间戳下第一帧和上一帧的注意力输入。
1 | class CrossFrameAttnProcessor(AttnProcessor): |
在运行方法中,我们根据 encoder_hidden_states 是否为空来判断该注意力是自注意力还是交叉注意力。我们仅修改自注意力。当该注意力为自注意力时,假设我们知道了当前时刻 t,我们就可以根据 t 获取当前时刻第一帧和前一帧的输入,并将它们拼接起来得到 cross_map。以此 cross_map 为当前注意力的 K, V,我们就实现了帧间注意力。
1 | def __call__(self, attn: Attention, hidden_states, encoder_hidden_states=None, **kwargs): |
由于 Diffusers 经常修改函数接口,在调用普通的注意力计算接口时,最好原封不动地按照
super().__call__(..., **kwargs)写,不然这份代码就不能兼容后续版本的 Diffusers。
上述代码只描述了后续帧的行为。如前所述,我们的注意力计算有两种行为:对于第一帧,我们不修改注意力的计算过程,只缓存其输入;对于之后每一帧,我们替换注意力的输入,同时维护当前「上一帧」的输入。既然注意力在不同情况下有不同行为,我们就应该用一个变量来记录当前状态,让 __call__ 能根据此变量决定当前的行为。相关的伪代码如下:
1 | def __call__(self, attn: Attention, hidden_states, encoder_hidden_states=None, **kwargs): |
在伪代码中,self.state 表示当前注意力的状态,它的值表明注意力计算是在处理第一帧还是后续帧。在视频编辑流水线中,我们应按照下面的伪代码,先编辑第一帧,再修改注意力状态后编辑后续帧。
1 | edit(frames[0]) |
现在,有一个问题:我们该怎么修改怎么每一个注意力模块的处理器的状态呢?显然,最直接的方式是想办法访问每一个注意力模块的处理器,再直接修改对象的属性。
1 | modules = unet.get_attn_moduels |
但是,每次都去遍历所有模块会让代码更加凌乱。同时,这样写也会带来代码维护上的问题:我们每次遍历注意力模块时,都可能要判断该注意力模块是否应该修改。而在用前面讲过的处理类替换方法 unet.set_attn_processor 时,我们也得判断一遍。同一段逻辑重复写在两个地方,非常不利于代码更新。
一种更优雅的实现方式是:我们定义一个状态管理类,所有注意力处理器都从同一个全局状态管理类对象里获取当前的状态信息。想修改每一个处理器的状态,不需要遍历所有对象,只需要改一次全局状态管理类对象就行了。
按照这种实现方式,我们先编写一个状态类。
1 | class AttnState: |
在注意力处理类中,我们在初始化时保存状态类对象的引用,在运行时根据状态类对象获取当前状态。
1 | class CrossFrameAttnProcessor(AttnProcessor): |
到目前为止,假设已经维护好了之前的输入,我们的注意力处理类能执行两种不同的行为了。现在,我们来实现之前输入的维护。使用之前的注意力输入时,我们其实需要知道当前的时刻 t。当前的时刻也算是另一个状态,最好是也在状态管理类里维护。但为了简化我们的代码,我们可以偷懒让每个处理类自己维护当前时刻。具体做法是:如果知道了去噪迭代的总时刻数,我们就可以令当前时刻从0开始不断自增,直到最大时刻时,再重置为0。加入了时刻处理及之前输入维护的完整代码如下:
1 | class AttnState: |
代码中,tot_timestep 为总时刻数,cur_timestep 为当前时刻。每运算一次,cur_timestep 加一,直至总时刻时再归零。在处理第一帧时,我们把当前时刻的输入同时存入第一帧缓存 first_maps 和上一帧缓存 prev_maps 中。对于后续帧,我们先做替换过输入的注意力计算,再更新上一帧缓存 prev_maps。
视频编辑流水线
准备好了我们自己写的帧间注意力处理类后,我们来编写一个简单的 Diffusers 视频处理流水线。该流水线基于 ControlNet 与图生图流水线,其主要代码如下:
1 | class VideoEditingPipeline(StableDiffusionControlNetImg2ImgPipeline): |
在构造函数中,我们创建了一个全局注意力状态对象 attn_state。它的引用会传给每一个帧间注意力处理对象。一般修改自注意力模块时,只会修改 U-Net 上采样部分的,而不会动下采样部分和中间部分的。因此,在过滤注意力模块时,我们的判断条件是 k.startswith("up")。把新的注意力处理器词典填完后,用 unet.set_attn_processor 更新所有的处理类对象。
1 | self.attn_state = AttnState() |
在 __call__ 方法中,我们要基于原图像编辑流水线 super().__call__(),实现我们的视频编辑流水线。在这个过程中,我们的主要任务是维护好注意力管理对象中的状态。一开始,我们要把管理类重置,根据参数设置最大去噪时刻数。经重置后,注意力处理器的状态默认为 STORE,即会保存第一帧的输入。处理完第一帧后,我们运行 attn_state.to_load() 改变注意力处理器的状态,让它们每次做注意力运算时先读第一帧和上一帧的输入,再维护上一帧输入的缓存。
1 | def __call__(self, *args, images=None, control_images=None, **kwargs): |
运行该流水线的示例脚本在项目根目录下的 replace_attn.py 文件中。示例中使用的视频可以在 https://github.com/williamyang1991/Rerender_A_Video/blob/main/videos/pexels-koolshooters-7322716.mp4 下载,下载后应重命名为 woman.mp4。不使用和使用新注意力处理器的输出结果如下:
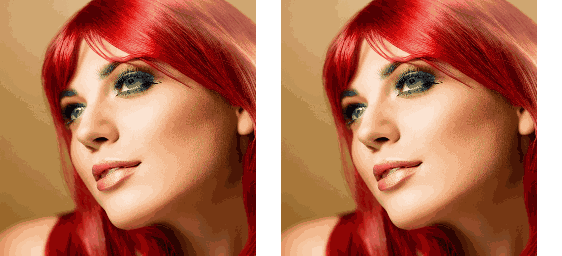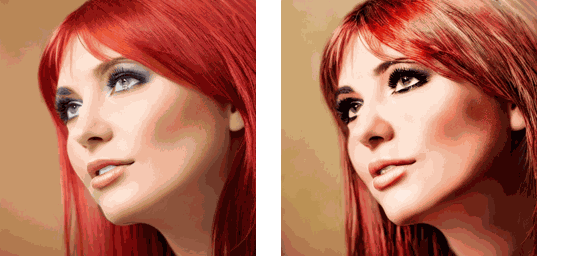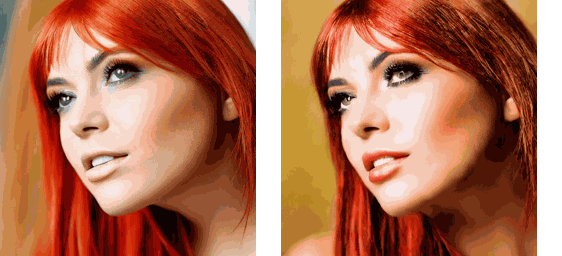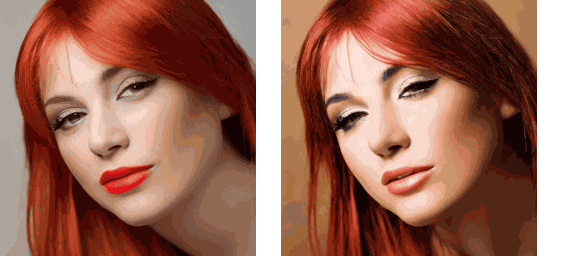
可以看出,虽然注意力替换不能解决生成视频的闪烁问题,但帧间的一致性提升了不少。将注意力替换技术和其他技术结合起来的话,我们就能得到一个不错的 SD 视频生成工具。
总结
扩散模型中的自注意力替换是一种常见的提升图片一致性的技术。该技术的实现方法是将扩散模型 U-Net 中自注意力的 K, V 输入替换成另一幅图片的。在这篇文章中,我们学习了一个较为复杂的基于 Diffusers 开发的自注意力替换示例项目,用于提升 SD 视频生成的一致性。在这个过程中,我们学习了和 AttentionProcessor 相关接口函数的使用,并了解了如何基于全局管理类实现一个代码可维护性强的多行为注意力处理类。如果你能看懂这篇文章的示例,那你在开发 Diffusers 的注意力处理类时基本上不会碰到任何难题。
项目网址:https://github.com/SingleZombie/DiffusersExample/tree/main/ReplaceAttn
如果你想进一步学习 Diffusers 中视频编辑流水线的开发,可以参考我给 Diffusers 写的流水线:https://github.com/huggingface/diffusers/tree/main/examples/community#Rerender_A_Video