相信大家都在网上看过这种「笑容逐渐消失」的表情包:一张图片经过经过平滑的变形,逐渐变成另一张截然不同的图片。

对此,计算机科学中有一种专门描述此应用的任务——图像变形(image morphing)。给定两张图像,图像变形算法会输出一系列合理的插值图像。当按顺序显示这些插值图像时,它们应该能构成一个描述两张输入图像平滑变换的视频。
图像变形可以广泛运用于创意制作中。比如在做 PPT 时,我们可以在翻页处用图像变形做出炫酷的过渡效果。当然,图像变形也可以用在更严谨的场合。比如在制作游戏中的 2D 人物动画时,可以让画师只画好一系列关键帧,再用图像变形来补足中间帧。可是,这种任务对于中间插值图像的质量有着很高的要求。而传统的基于优化的图像变形算法只能对两张输入图像的像素进行一定程度的变形与混合,难以生成高质量的中间帧。有没有一种更好的图像变形算法呢?
针对这一需求,我们提出了 DiffMorpher —— 一种基于预训练扩散模型 (Stable Diiffusion)的图像变形算法。该研究由 DragGAN 作者潘新钢教授指导,经清华大学、上海人工智能实验室、南洋理工大学 S-Lab 合作完成。目前,该工作已经被 CVPR 2024 接收。

我们可以借助 DiffMorpher 实现许多应用。最简单的玩法是输入两张人脸,生成人脸的渐变图。

如果输入一系列图片,我们还能制作更长更丰富的渐变图。

而当输入的两张图片很相似时,我们可以用该工具制作出质量尚可的补间动画。

在这篇文章中,让我们来浏览一下 DiffMorpher 的工作原理,并学习如何使用这一工具。学习 DiffMorpher 的一些技术也能为我们开发其他基于扩散模型的编辑工具提供启发。
项目官网:https://kevin-thu.github.io/DiffMorpher_page/
代码仓库:https://github.com/Kevin-thu/DiffMorpher
隐变量插值
如前所述,图像变形任务在生成插值图像时不仅需要混合输入图像的内容,还需要补充生成一些内容。用预训练的图像生成模型来完成图像变形是再自然不过的想法了。前几年,已经有一些工作探究了如何用 GAN 来完成图像变形。使用 GAN 做图像变形的方法非常直接:在 GAN 中,每张被生成的图片都由一个高维隐变量决定。可以说,隐变量蕴含了生成一张图像所需的所有信息。那么,只要先使用 GAN 反演(inversion)把输入图片变成隐变量,再对隐变量做插值,就能用其生成两张输入图像的一系列中间过渡图像了。
对于隐变量,我们一般使用球面插值(slerp)而不是线性插值。
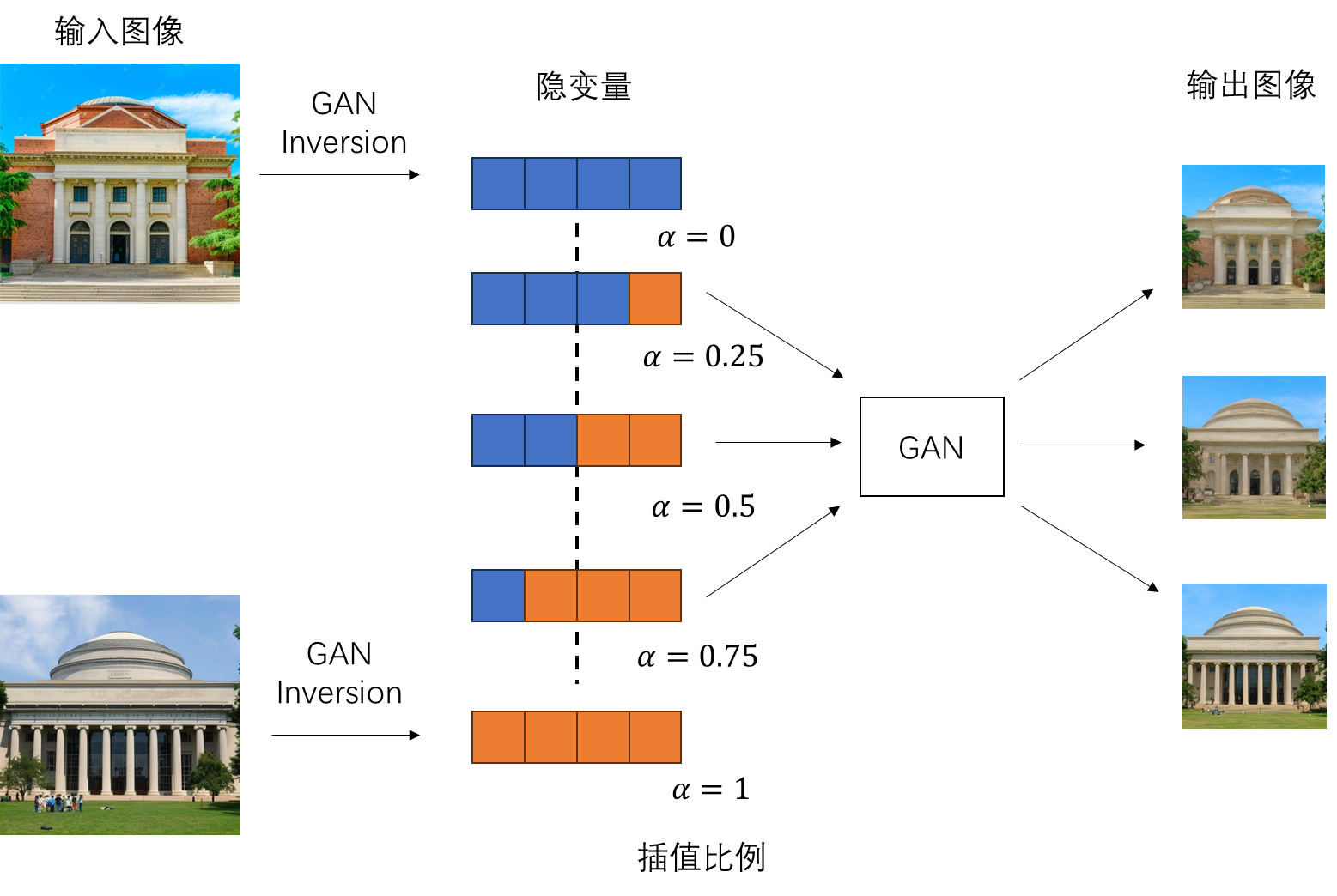
然而,GAN 生成的图像往往局限于某一类别,泛用性差。因此,用 GAN 做图像变形时,往往得不到高质量的图像插值结果。

而以 Stable Diffusion(SD)为代表的图像生成扩散模型以能生成各式各样的图像而著称。我们可以在 SD 上也用类似的过程来实现图像插值。具体来说,我们需要对 DDIM 反演得到的纯噪声图像(隐变量)进行插值,并对输入文本的嵌入进行插值,最后根据插值结果生成图像。
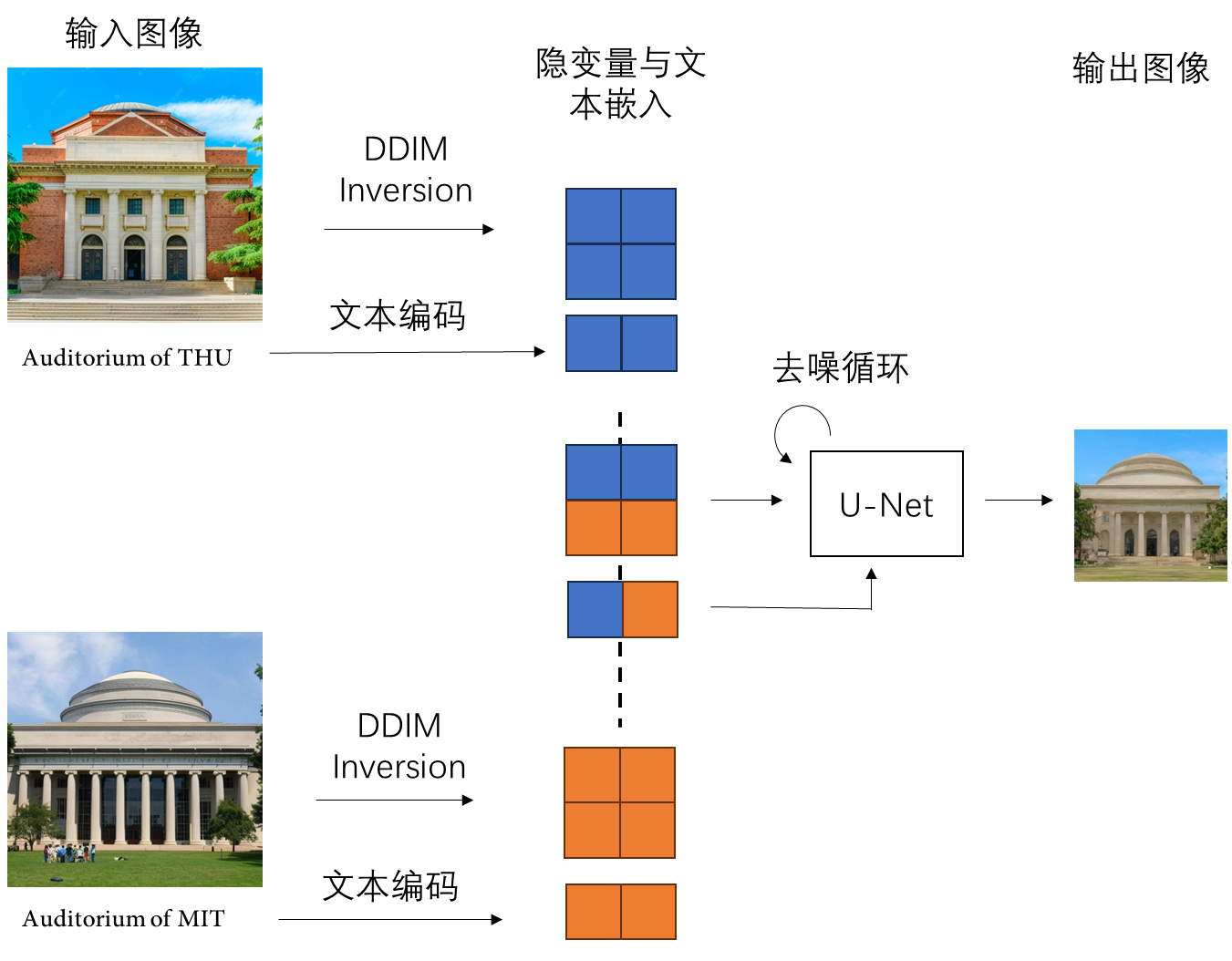
可是,扩散模型也存在缺陷:扩散模型的隐变量没有 GAN 的那么适合编辑。如下面的动图所示,如果仅使用简单的隐变量插值,会存在着两个问题:1)早期和晚期的中间帧和输入图像非常相近,而中期的中间帧又变化过快,图像的过渡非常突兀;2)中间帧的图像质量较低。这样的结果无法满足实际应用的要求。

LoRA 插值
扩散模型的隐变量不适合编辑,准确来说是其所在隐空间的性质导致的。模型只能处理隐空间中部分区域的隐变量。如果对隐变量稍加修改,让隐变量「跑」到了一个模型处理不了的区域,那模型就生成不了高质量的结果。而在对两个输入隐变量做插值时,插值的隐变量很可能就位于一个模型处理不了的区域。
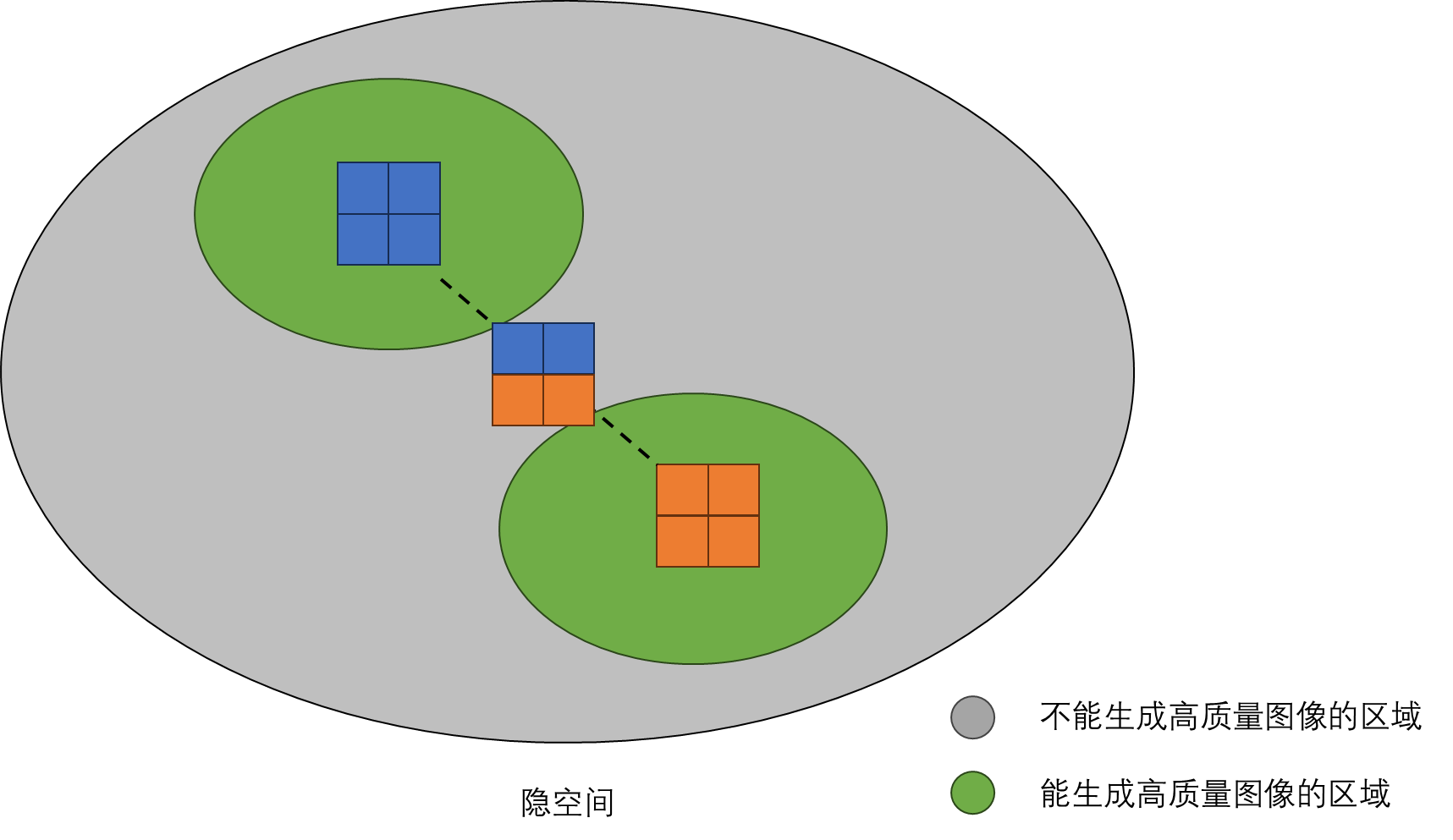
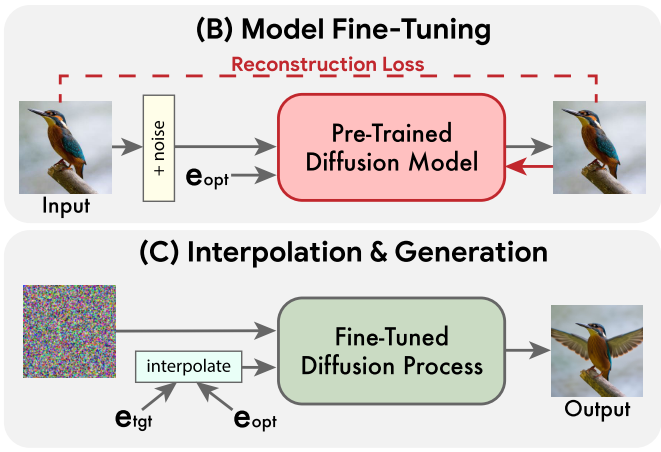
想解决此问题,我们需要参考一些其他的工作。为了提升扩散模型的编辑单张图像的能力,一些往期工作会在单张图片上微调预训练扩散模型(即训练集只由同一张图片构成,让模型在单张图片上过拟合)。这样,无论是调整初始的隐变量还是文本输入,模型总是能够生成一些和该图片很相近的图片。比如在 Imagic 工作中,为了编辑输入图片,算法会先在输入图片上微调扩散模型,再用新的文本描述重新生成一次图片。这样,最终生成的图片既和原图很接近(鸟的外观差不多),又符合新的文本描述(鸟张开了翅膀)。
后来,许多工作用 LoRA 代替了全参数微调。LoRA 是一种高效的模型微调技术。在训练 LoRA 时,原来的模型权重不用修改,只需要训练额外引入的少量参数即可。假设原模型的参数为$W$,则 LoRA 参数可以表示为 $\Delta W$,新模型可以表示为$W + \Delta W$,其中 $\Delta W$ 里的参数比 $W$ 要少得多。训练 LoRA 的目的和全参数微调是一样的,只不过 LoRA 相对而言更加高效。
对单张图片训练 LoRA,其实就是在把整个隐空间都变成一个能生成高质量图像的空间。但付出的代价是,模型只能生成和该图片差不多的图片。
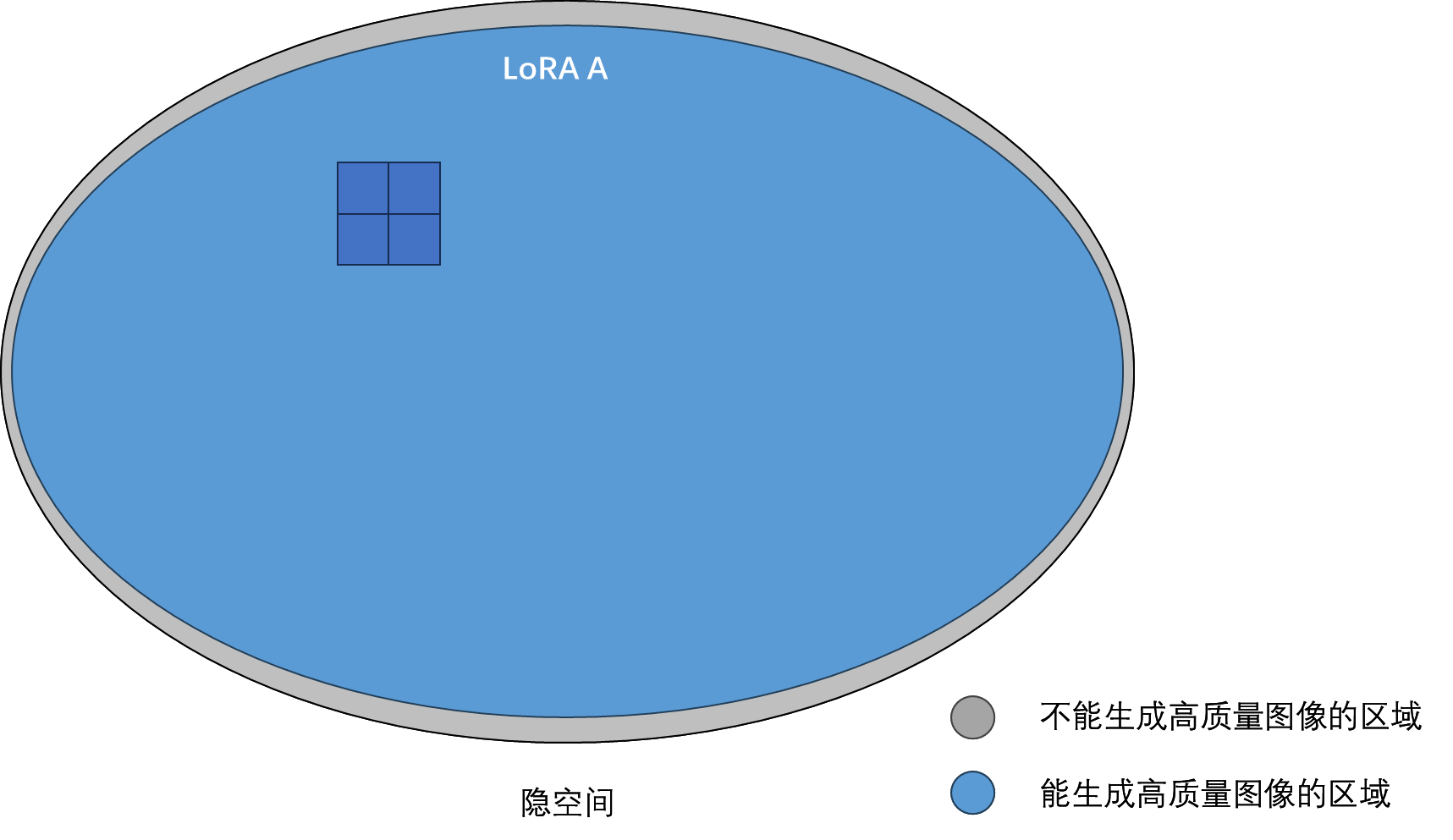
我们能不能把 LoRA 的这种性质放在隐变量插值上呢?我们可以认为,LoRA 的参数 $\Delta W$ 存储了新的隐空间的一些信息。如果我们不仅对两个输入图片的隐变量做插值,还对分别对两个输入图片训练一个 LoRA,得到$\Delta W_1, \Delta W_2$,再对两个 LoRA 的参数进行插值,得到$\Delta W = \alpha \Delta W_1 + (1-\alpha) \Delta W_2$,就能让中间的插值隐变量也能生成有意义的图片,且该图片会保留两个输入图片的性质。
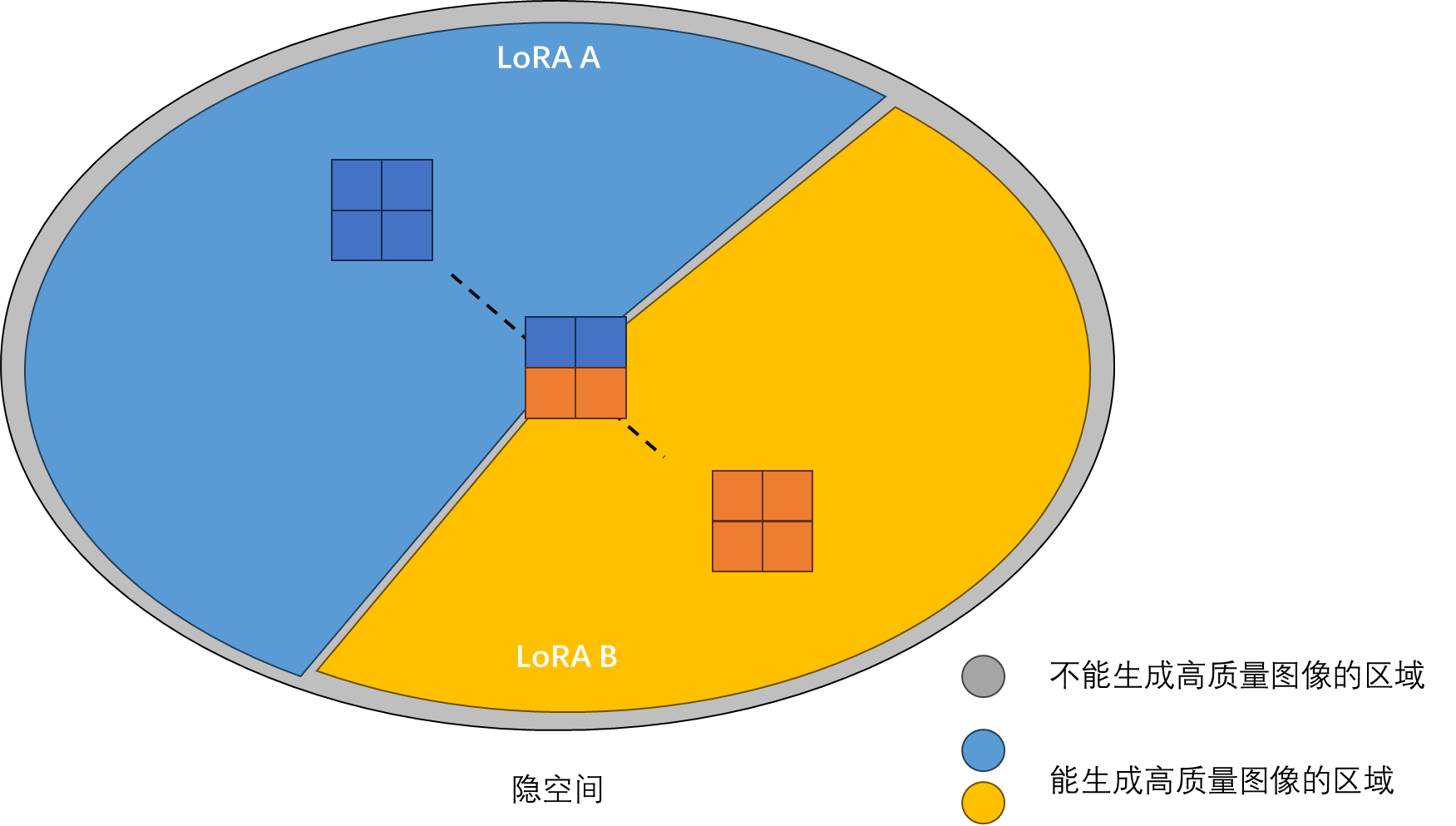
相关实验结果能支撑我们的假设。下图展示了不同 LoRA 配置下,对隐变量做插值得到的结果。第一行和第二行表示分别仅使用左图或右图的 LoRA,第三行表示对 LoRA 也进行插值。可以看出,使用 LoRA 后,所有图片的质量都还不错。固定 LoRA,对隐变量做插值时,图像的风格会随隐变量变化而变化,而图像的语义内容会与训练该 LoRA 的图像相同。而对 LoRA 也进行插值的话,图像的风格、语义都会平滑过渡。

下图是前文那个例子的某些中间帧不使用 LoRA 插值和使用 LoRA 插值的结果。可以看出,使用了 LoRA 后,图像质量提升了很多。而通过对 LoRA 的插值,输出图像也会保留两个输入图像的特征。

自注意力输入的插值与替换
使用 LoRA 插值后,中间帧的图像质量得到了大幅提升,可是图像变形不连贯的问题还是没有得到解决。要提升图像变换的连贯性,还需要使用到一项和自注意力相关的技术。
深度学习中常见的注意力运算都可以表示成交叉注意力 $CrossAttn(\mathbf{x}, \mathbf{y})$,它表示数据 $\mathbf{x}$ 从数据 $\mathbf{y}$ 中获取了一次信息。交叉注意力的特例是自注意力 $SelfAttn(\mathbf{x}) = CrossAttn(\mathbf{x}, \mathbf{x})$,它表示数据 $\mathbf{x}$ 自己内部做了一次信息聚合。多数扩散模型的 U-Net 都使用了自注意力层。
由于自注意力本质上是一种交叉注意力,我们可以把另一个图像的自注意力输入替换某图像的自注意力输入。具体来说,我们可以先生成一张参考图像,将自注意力输入$\mathbf{x’}$缓存下来。再开始生成当前图片,对于原来的自注意力计算 $CrossAttn(\mathbf{x}, \mathbf{x})$,我们把第二个 $\mathbf{x}$ 换成 $\mathbf{x’}$,让计算变成 $CrossAttn(\mathbf{x}, \mathbf{x’})$。这样,在生成当前图片时,当前图片会和参考图片更加相似一些。
在扩散模型生成图像时,每个去噪时刻的每个自注意力模块的输入都有自己的意义。在替换输入时,我们必须用参考图像当前时刻当前模块的输入来做替换。
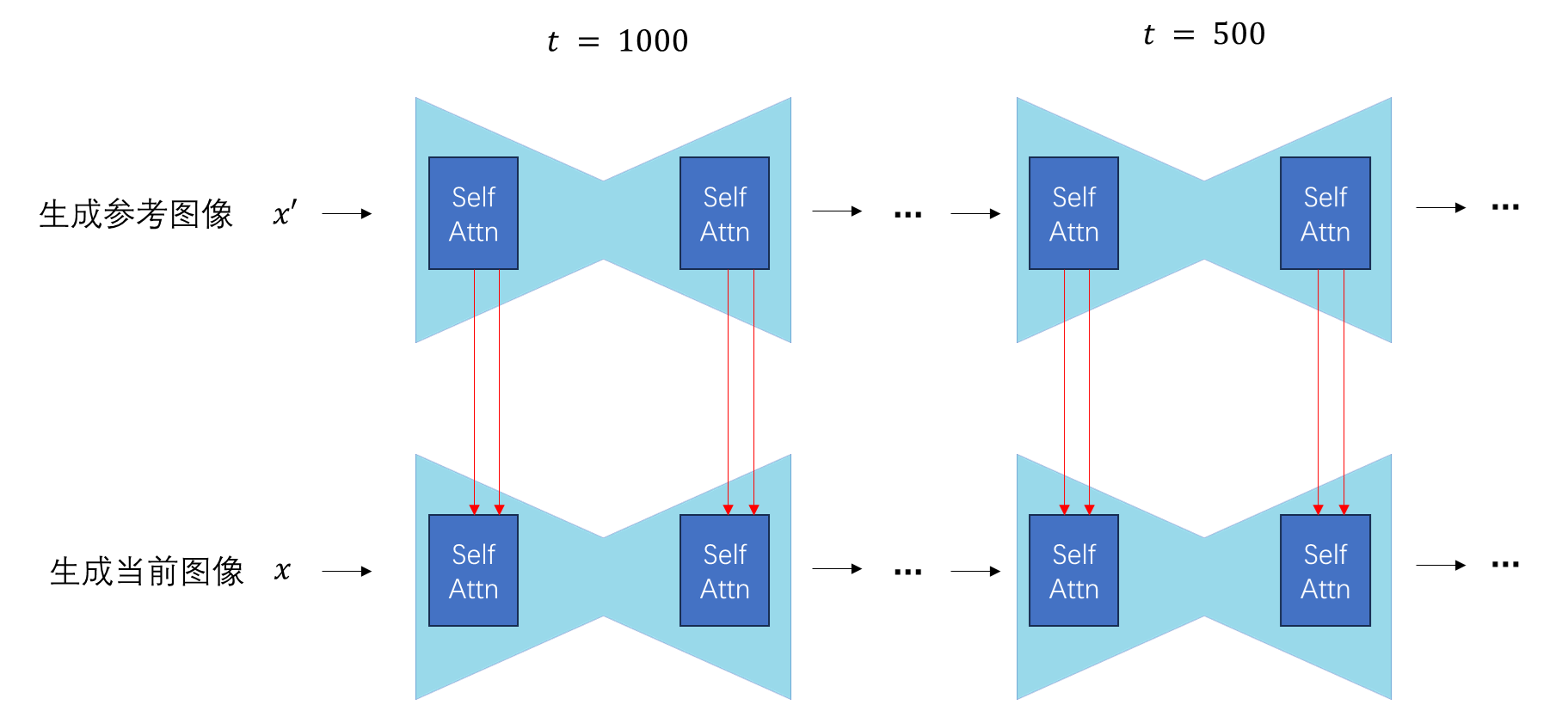
这种注意力替换技巧通常用在基于图像扩散模型的视频编辑任务里。一般我们会以输出视频的第一帧为参考图像,让生成后续帧的自注意力模块参考第一帧的信息。这样视频每一帧的风格都会更加一致。
我们可以把视频编辑任务的这种技巧挪用到图像变形任务里。在图像变形中,每一个中间帧要以一定的混合比例参考两个输入图像。那么,我们也可以先分别生成两个输入图像,缓存它们的自注意力输入$\mathbf{x}_0, \mathbf{x}_1$。在生成混合比例为 $\alpha$ 的中间帧时,我们先混合自注意力输入$\mathbf{x’} = \alpha \mathbf{x}_0 + (1-\alpha) \mathbf{x}_1$,再以 $\mathbf{x’}$ 为自注意力的第二个参数,计算 $CrossAttn(\mathbf{x_{\alpha}}, \mathbf{x’})$。
下面是不使用/使用自注意力替换的结果。可以看出,不使用注意力替换时,视频中间某帧会出现突变。而使用了注意力替换后,视频平滑了很多。

在实验中我们也发现,直接用 $\mathbf{x’}$ 来替换注意力输入会降低中间帧的质量。为了权衡质量与过渡性,我们会让替换的注意力输入在原输入 $\mathbf{x_{\alpha}}$ 和 $\mathbf{x’}$ 之间做一个混合,即令插入的注意力输入为 $\mathbf{x’} \gets \lambda \mathbf{x’} + (1-\lambda) \mathbf{x_{\alpha}}$。最终实验中我们令 $\lambda=0.6$。
重调度采样
通过注意力插值,我们解决了中间帧跳变的问题。然而,视频的变换速度还是不够平均。在开始和结束时,视频的变化速度较慢;而在中间时刻,视频的变化又过快。
我们使用了一种重新选择混合比例 $\alpha$ 的重调度策略来解决这一问题。之前,我们在选择混合比例时,是均匀地在 0~1 之间采样。比如要生成 10 段过渡,9个中间帧,我们就可以令混合比例为 $[0, 0.1, 0.2, …, 0.9, 1]$。但是,由于不同比例处插值图像的变化率不同,这样选取混合比例会导致每两帧之间变化量不均匀。
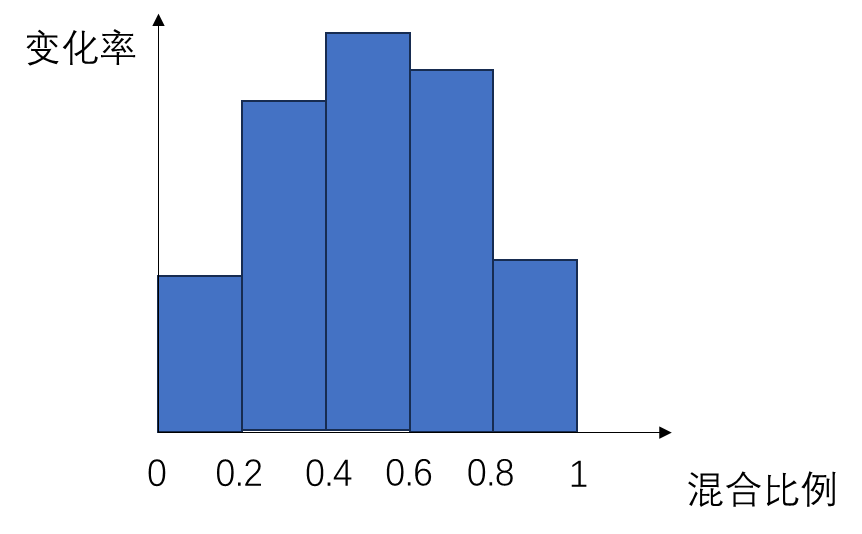
上图是一个可能的变化率分布图。图的横坐标是插值的混合比例,或者说视频渐变的时刻,图的纵坐标是图像内容随时间的变化率。每个矩形的面积表示相邻两帧之间的 LPIPS 感知误差。如果等间距采样混合比例的话,由于每个时刻的变化率不同,矩形的面积也不同,图像的变化会时快时慢。
我们希望重新选择一些采样的横坐标,使得相邻帧构成的矩形的面积尽可能一致。通过使用类似于平均颜色分布的直方图均衡化(histogram equalization)算法,我们可以得到重采样的混合比例 $[0, \alpha_1, \alpha_2, …, \alpha_{n-1}, 1]$,达到下面这种相邻帧变化量几乎相同的结果。
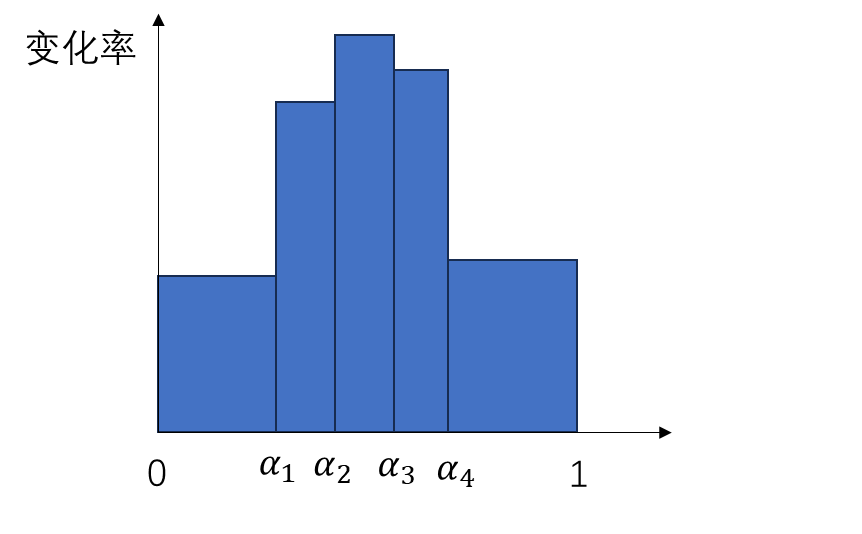
下面是不使用/使用重采样的结果。可以看出,二者生成的中间图像几乎是一致的,但左边的视频在开头和结尾会停顿一会儿,而右边的视频的内容一直都在均匀地变化。

在线示例与代码
看完了该工作的原理,我们来动手使用一下 DiffMorpher。我们先来运行一下在线示例。在线示例可以在 OpenXLab (https://openxlab.org.cn/apps/detail/KaiwenZhang/DiffMorpher ) 或者 HuggingFace(https://huggingface.co/spaces/Kevin-thu/DiffMorpher )上访问。
使用 WebUI 时,可以直接点击 Run 直接运行示例,或者手动上传两张图片并给定 prompt 再运行。
如果你对一些细节感兴趣,也可以手动 clone GitHub 仓库。配置环境的过程也很简单,只需要准备一个有 PyTorch 的运行环境,再安装相关 Pip 包即可。注意,该项目用的 Diffusers 版本较旧,最新的 Diffusers 可能无法成功运行,建议直接照着 requirements.txt 里的版本来。
1 | git clone https://github.com/Kevin-thu/DiffMorpher.git |
配置好了环境后,可以直接尝试仓库里自带的示例:
1 | python main.py \ |
运行后,就能得到下面的结果:

总结与展望
图像变形任务的目标是在两个有对应关系的图像之间产生一系列合理的过渡帧。传统基于像素变形与混合的方法无法在中间帧里生成新内容。我们希望用包含丰富图像信息的预训练扩散模型来完成图像变形任务。然而,直接对扩散模型的隐变量插值,会出现中间帧质量低、结果不连贯这两个问题。为了解决这两个问题,我们对扩散模型生成两个输入图像时的诸多属性进行了插值,包括 LoRA 插值、自注意力插值,分别解决了中间帧质量与结果连贯性的问题。另外,加入了重调度采样后,输出视频的连贯性得到了进一步的提升。
受限于图像变形这一任务本身的上限,DiffMorpher 在实际应用中的质量难以比拟专门面向某一任务的方法(比如只做拖拽式编辑,或者只做视频插帧)。这篇工作在科研上的贡献会远大于其在应用上的贡献。方法中一些较为新颖的插值手段或许会帮助到未来的图像编辑工作。
尽管 DiffMorpher 已经算是一个不错的图像变形工具了,该方法并没有从本质上提升扩散模型的可编辑性。相比 GAN 而言,逐渐对扩散模型的隐变量修改难以产生平滑的输出结果。比如在拖拽式编辑任务中,DragGAN 只需要优化 GAN 的隐变量就能产生合理的编辑效果,而扩散模型中的类似工具(如 DragDiffusion, DragonDiffusion)需要更多设计才能达到同样的结果。从本质上提升扩散模型的可编辑性依然是一个值得研究的问题。
出于可读性的考虑,本文没有过多探讨技术细节。如果你对相关技术感兴趣,欢迎阅读我之前的文章:
LoRA 在 Stable Diffusion 中的三种应用:原理讲解与代码示例
Stable Diffusion 中的自注意力替换技术与 Diffusers 实现