最近,我需要在Python里使用PatchMatch算法(一种算两张图片逐像素匹配关系的算法)。我去网上搜了一份实现,跑了下测试程序,发现它跑边长300像素的图片都要花三分钟。这个速度实在太慢了。我想起以前瞟到过一篇介绍Python加速的文章,里面提到过Numba这个库。于是,我现学现用,最终成功用Numba让原来要跑180秒的程序在0.6秒左右跑完。可见,Numba学起来是很快的。在这篇文章中,我将以这个Python版PatchMatch项目为例,介绍如何快速从零上手Numba,以大幅加速Python科学计算程序。这篇文章不会涉及PatchMatch算法的原理,只要你写过Python,就能读懂本文。
缘起:一份缓慢的 PatchMatch 实现
PatchMatch是Adobe提出的一种快速计算两张图片逐像素匹配关系的算法。也就是说,输入两张类似的图片A和B(比如视频里的连续两帧),算法能输出图片A中的每个像素对应B中的哪个像素(可能会出现多对一的情况)。为了快速验证算法的效果,我们可以输入图片A和B,用算法获取A到B的匹配关系,再根据匹配关系从B中取像素重建A。如果重建出来的图片和原来的图片A看上去差不多,那算法的效果就很不错。下图是一份PatchMatch测试程序的输出。

我在GitHub上找到了一份简明实用的Python版PatchMatch实现,得到了上面的输出结果。结果是挺不错,但哪怕是跑326x244这么小的图片,都要花约180秒才能跑完。
我懒得从头学一遍PatchMatch,决定直接上手优化代码。代码不长,其函数调用关系能很快理清。
代码入口函数是NNS()。它先是调用了initialization(),再循环itr次,每次遍历所有像素,对每个像素调用propagation()和random_search()。
1 | def NNS(img, ref, p_size, itr): |
initialization()先是定义了一些变量,之后对所有像素调用cal_distance()。
1 | def initialization(A, B, p_size): |
propagation()主要调用了一次cal_distance()。1
2
3
4
5
6
7
8
9
10
11
12def propagation(f, a, dist, A_padding, B, p_size, is_odd):
...
if is_odd:
if idx == 1:
...
dist[x, y] = cal_distance(a, f[x, y], A_padding, B, p_size)
if idx == 2:
...
dist[x, y] = cal_distance(a, f[x, y], A_padding, B, p_size)
else:
# 和 is_odd 时类似
...
random_search()则主要是在一个while循环里反复调用cal_distance()。
1 | def random_search(f, a, dist, A_padding, B, p_size, alpha=0.5): |
最后来看被调用最多的cal_distance()。这个函数用于计算图片A,B之间的某个距离。也别管这个距离是什么意思,总之是这一个有点耗时的计算。
1 | def cal_distance(a, b, A_padding, B, p_size): |
至此,这份程序就差不多看完了。可以发现,代码大部分时候都在遍历像素,且遍历每个像素时多次调用cal_distance()函数。而我们知道,拿Python本身做计算是很慢的,尤其是在一个很长的循环里反复计算。这份代码性能较低,正是因为代码在遍历每个像素时做了大量计算。
我以前看过一篇文章,说Numba库能够加速Python科学计算程序,尤其是加速带有大量循环的程序。于是,我去学习了一下Numba的基础用法。
Numba 基础
Numba的官方文档提供了非常友好的入门教程。我们来大致把教程过一下。
Numba可以用pip一键安装。
1 | pip install numba |
Numba尤其擅长加速循环以及和NumPy相关的计算。使用@jit(nopython=True)(或@njit)装饰一个函数后,我们可以在这个函数里随便写循环,随便用NumPy计算,就像在用C语言一样。经Numba优化后,这个函数会跑得飞快。以下是官方给出的入门示例程序。
1 | from numba import jit, njit |
Numba是怎么完成加速的呢?从装饰器名jit(JIT,Just-In-Time Compiler的简称)中,我们能猜出,Numba使用了即时编译技术,把函数直接翻译成了机器码,而没有像普通Python程序一样解释执行。Numba有两种编译模式,最常见的模式是令参数nopython=True,在编译中完全不用Python解释器。这种模式下,函数能以最优性能翻译成机器码。
修改上面的代码,我们可以测试该函数的速度。注意,由于采用了即时编译,函数在初次调用时会被编译。如果只要计算函数在编译后的运行时间,应该从第二次调用后开始计时。
1 | from numba import jit |
我们可以得到类似于下面的输出:
1 | Elapsed (with compilation) = 1.0579542s |
我们可以尝试一下不用Numba,直接用Python循环。
1 | import numpy as np |
这个速度(4e-4)比用Numba慢了一个数量级。1
Elapsed (without Numba) = 0.00046979999999985367s
也就是说,我们只要在普通的Python计算函数上加一个@jit(nopython=True)(或@njit),其他什么都不用做,就可以加速代码了。让我们来用它改进一下之前的PatchMatch程序。
用Numba计时编译加速PatchMatch
让我们开始做PatchMatch的性能调优。首先,根据性能优化的一般做法,我们要得知每一行函数调用的运行时间,找到性能瓶颈,从瓶颈处开始优化。我们可以用line_profiler来分析每一行代码的运行时间。用pip即可安装这个库。
1 | pip install line_profiler |
把主函数修改一下,在调用算法入口函数时拿LineProfiler封装一下,再用lp.add_function添加想监控的函数,即可开始性能分析。
1 | if __name__ == "__main__": |
性能分析结果会显示每一行代码的运行时间及占用时间百分比。从结果中可以看出,在入口函数NNS()中,random_search()最为耗时。这是符合预期的,因为random_search()里还有一层while循环。

现在,我们应该着重优化random_search()的性能。我们继续查看一下random_search()的性能分析结果。
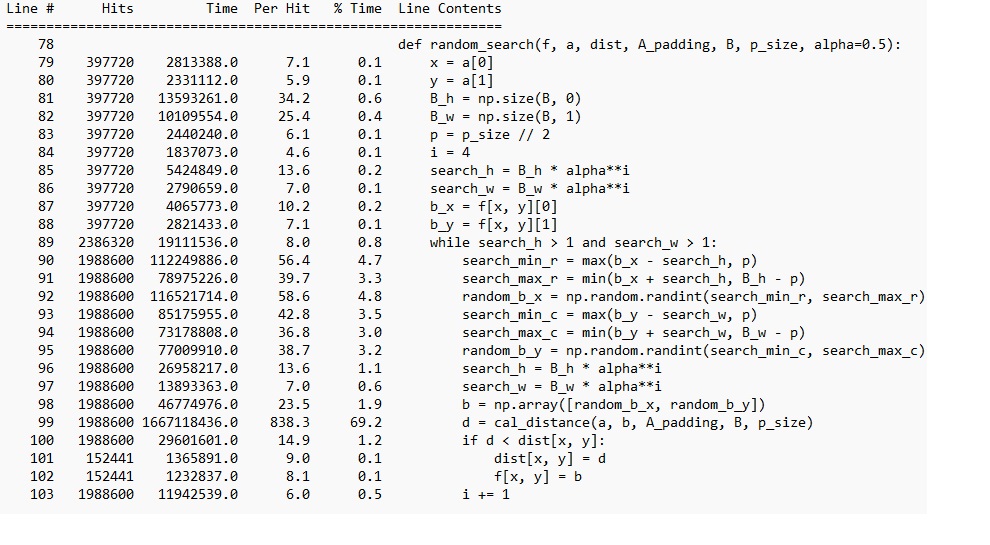
结果显示,绝大多数时间都消耗在了while循环里。也和我们之前分析得一样,cal_distance()是耗时最多的一行。除了random_search()外,其他几个函数也多次调用了cal_distance()。因此,我们目前代码优化的目标就定格在了cal_distance()身上。
刚刚学完了Numba,这不正好可以用上了吗?我们可以尝试直接给cal_distance()加一个@njit装饰器。
1 |
|
修改完代码后,再次运行程序。这次,程序报了一大堆错误。大致是说,在某一行碰到了Numba识别不了的函数。应该把np.int32()的强制类型转换改成.astype(np.int32)
1 | num = np.sum(1 - np.int32(np.isnan(temp))) |
改完之后,如果Numba版本较老,还会碰到新的报错:
1 | Use of unsupported NumPy function 'numpy.nan_to_num' or unsupported use of the function. |
报错显示,numpy.nan_to_num函数没有得到支持。再次翻阅Numba文档,可以发现,Numba并不支持所有NumPy函数。Numba对NumPy的支持情况可以在文档里查询(需要把文档切换到你当前Numba的版本)。
总之,cal_distance()这个函数不改不行了。得认真阅读一下这个函数的原理。原来,cal_distance(a, b, A_padding, B, p_size)函数是算图像A_padding和图像B中某一个像素块的均方误差的平均值,其中,像素块的边长为p_size,像素块在A_padding的坐标由a表示,在B中的坐标由b表示。
1 | def cal_distance(a, b, A_padding, B, p_size): |
代码里还有一些奇怪的有关nan的运算:如果像素块里某处有nan,就说明此处像素无效,不应该参与均方误差的运算。为什么图像里会有nan呢?我们得阅读代码的其他部分。
nan是在初始化函数initialization()里加入的。A_padding原来是图像A在周围填了一圈nan的结果。我们大致能猜测出作者填充nan的原因:从A中取像素块时,若像素块在边缘,则有一些像素就不应该被计算了。拿条件语句判断这些无效像素比较麻烦,作者选择干脆在图像A周围填一圈nan,保证每次取像素块时不用判断无效像素。等算误差的时候再判断根据nan排除无效像素。
1 | def initialization(A, B, p_size): |
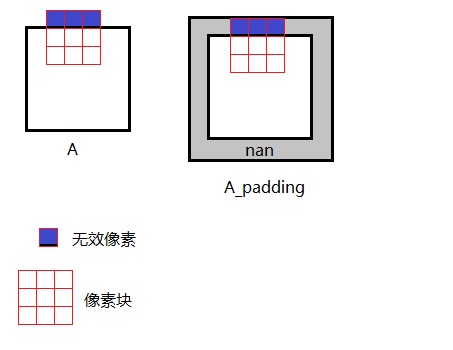
使用nan填充,既耗时,兼容性又不好。为了尽可能加速cal_distance(),我把填充改成了edge填充,即让填充值等于边界值,并取消了无效像素的判断。也就是说,若像素块取到了图像外的像素,则认为这个像素和边界处的像素一样。这个假设是很合理的,这种修改几乎不会损耗算法的效果。
除此之外,为了进一步减少cal_distance()中的计算,我把要用到的变量都提前在外面算好再传进来。由于现在不需要考虑无效像素的数量,可以直接对误差求和,不用再算平均值,少做一次除法。还有,现在用@njit装饰了函数,可以放心大胆地在循环里做计算。
1 | def initialization(A, B, p_size): |
当然,用NumPy实现cal_distance也是可以的。1
2
3
4
5# NumPy 等价写法,加上@njit更快
def cal_distance(x, y, x2, y2, A_padding, B, p):
patch_a = A_padding[x:x + p, y:y + p, :].astype(np.float32)
patch_b = B[x2 - p:x2 + p + 1, y2 - p:y2 + p + 1, :]
return np.sum((patch_a - patch_b)**2)
经测试,把nan的判断全部去掉后,使用NumPy版的cal_distance(),程序的运行时间降到了60秒。给NumPy版的cal_distance()加上@njit,运行时间进一步降低到了33秒。而如果使用带@njit装饰的循环写法,则运行时间也差不多是33秒,甚至还略快一些。这些测试结果印证了Numba的特性:
- Numba可以加速和NumPy张量相关的计算
- 在Numba中使用循环不会降低运行速度
成功用@njit优化完了代码中最深层的cal_distance(),我们会想,是不是所有函数都可以用同样方法加速?我们可以来做个实验,给最外层的入口函数NNS()加上@njit。
1 |
|
运行程序,会得到类似于下面的报错:1
Untyped global name 'initialization': Cannot determine Numba type of <class 'function'>
把报错放网上一搜,原来,加@njit的自定义函数只能调用加@njit的自定义函数。也就是说,在上面这份代码里,我们虽然用@njit装饰了NNS(),但我们自己定义的initialization(), propagation(),random_search()全部都没有用@njit装饰,因此NNS()的编译会出错。看来,我们得自底向上一步一步加上@njit了。
先来尝试修改一下initialization()。很可惜,直接加上@njit会报错。
1 |
|
报错是说有不支持的NumPy函数numpy.size。实际上,不仅是numpy.size,Numba也不支持有三个参数的np.random.randint。为了解决此问题,和刚刚对numpy.nan_to_num的处理一样,最好是能用其他等价写法来代替不支持的函数。如果不行的话,则应该把不支持的运算和支持的运算分离开,只加速支持的那一部分。对于initialization(),我采用了第二种解决方法,把函数中耗时的循环拆开来单独用@njit装饰,其余有不支持的NumPy函数的部分就不用Numba优化了。
1 |
|
另外的两个函数propagation()和random_search()只会碰到取形状函数numpy.size的问题。这个问题很好解决,只要把numpy.size挪到函数调用外即可。
给initialization_loop()、propagation()、random_search()都加上@njit后,程序的运行时间从33秒猛地降到了3秒左右。可以说,只用加@njit的方法的话,程序已经没有优化空间了。
用Numba提前编译加速PatchMatch
又看了看PatchMatch的源码,我发现,PatchMatch算法会先为每个像素随机生成一个匹配关系。然后,算法会迭代更新匹配关系。迭代得越久,匹配关系越准。而我之后要用PatchMatch处理一段视频,算所有帧对第1帧的匹配关系。那么,对于视频这种连续的图像序列,我能不能让第3帧初始化匹配关系时复用第2帧的匹配结果,第4帧复用第3帧的匹配关系,以此类推,以减少迭代次数呢?
说干就干。我准备先测试一下减少迭代次数后代码运行时间能缩短多少。迭代次数itr是在main函数里指定的,作者默认的数值是5。我把它改成1测试了一下。
1 | if __name__ == "__main__": |
结果,原来要花3秒的程序还是要花接近3秒,时间缩短得非常不明显。这不应该啊,理论上程序的运行时间应该大致和itr成正比啊。
测试了半天,我突然想起Numba文档里讲过,@njit是即时编译,函数的编译会在初次调用函数时完成。我每次运行程序时,大部分时间都花在了编译上,因此整个程序的运行时间几乎不由迭代次数决定。
我之后要反复运行PatchMatch程序,而不是通过运行一次程序来处理大批数据。即时编译的代价我是接受不了的。于是,我去文档里找到了Numba提前编译(AOT,ahead of time)的使用方法。
Numba AOT可以把Python函数编译进一个模块文件中。想在其他地方调用被编译的函数时,只需要import 模块名即可 。
官方给出的Numba AOT示例如下:
1 | from numba.pycc import CC |
首先,程序要用一个模块名实例化一个CC。该模块名是未来我们import时用到的名称。之后,对于想编译的函数,我们要用@cc.export装饰它。@cc.export的第一个参数是调用时的函数名(原来的函数名会被舍弃),第二个参数用于指定函数返回值和参数的类型。做完所有这些准备后,使用cc.compile()即可完成编译。
运行该程序,会得到一个模块文件。根据平台的不同,该模块文件名可能是my_module.so、my_module.pyd或my_module.cpython-34m.so。不管文件名是什么,只要是在同一个文件夹下,我们就可以用下面的Python命令调用这个模块文件。
1 | import my_module |
用Numba做即时编译时,函数的返回值类型和参数类型可填可不填。而Numba提前编译中,必须要填入函数的返回值类型和参数类型。这让编写Numba提前编译的工作量大了不少,已经不像是在写Python,而是在写C了。
还有一点值得注意。和使用即时编译时一样,自定义的函数在调用其他自定义函数时,必须要加上@njit。所以,会出现一个函数即有@njit,又有@cc.export的情况。
学习使用Numba提前编译时,最主要是要学习Numba是怎么用字符串代表参数类型的。比如,i4是32位整型,u1是8位无符号整型,u1[:, :, :]是三维8位无符号整型,void是无返回值。这些表示可以在官方文档里找到。
以我写的Numba AOT PatchMatch的编译代码为例,我们可以看一看参数类型和返回值类型是怎么描述的。
1 | import numpy as np |
运行该程序后,在我的电脑上得到了名为patch_match_module.cp37-win_amd64.pyd的模块文件。可以在其他代码里通过import patch_match_module调用编译好的函数了,比如:
1 | import patch_match_module |
加上最后这步提前编译后,PatchMatch的运行时间从3秒降低到了0.6秒多。程序从最开始的180秒降到了0.6秒,几乎快了300倍。而且,如果是处理视频,还可以通过复用前一帧信息来减少迭代次数,进一步缩短每一帧的平均处理时间。能加速这么多,并不是我太强,而是Python实在太慢了。纯Python就不应该用来写科学计算程序。
总结
通过阅读这篇文章,相信大家能根据我这次Python PatchMatch性能优化经历,在不阅读Numba文档的前提下自然而然地学会Numba的用法。我把文章中提到的和Numba性能优化有关的知识点按使用顺序总结一下。
- 在面向应用的程序中,不要用Python写科学计算程序。哪怕要写,也要尽可能避免在循环中使用大量计算,而是去调用各个库的向量化计算。
- 直接在想优化的函数前加
@njit装饰。在待优化函数里使用循环、NumPy函数都是很欢迎的。 - 如果碰到了Numba不支持的函数,可以通过两种方式解决:1)用等价的Numba支持的函数代替;2)把不支持和支持的部分分离,只加速支持的部分。
- 一个带
@njit函数在调用另一个自定义的函数时,那个函数也得加上@njit。因此,应该自底向上地实现Numba即时编译函数。 - 如果你接受不了计时编译的编译时间,可以使用提前编译技术。使用提前编译时,主要的工作是给参数和返回值标上正确的类型。
Numba确实很容易上手,只要会加@njit,剩下碰到了什么问题去搜索一下就行。Numba的官方文档很详细,想深入学习的话直接看文档就行了。
本项目的代码仓库为:https://github.com/SingleZombie/Fast-Python-PatchMatch 。在原作者仓库的基础上,我添加了PatchMatch_numba_jit.py、PatchMatch_numba_compile.py、PatchMatch_numba_aot.py这三个文件。它们分别表示即时编译运行程序、提前编译编译程序、提前编译运行程序。