我还剩软件工程这门课要考。这门课没留下真题,直接复习很难定下具体的目标。于是我决定还是用写复习笔记来复习,让复习的目的性更强,同时激发斗志,收获成就感。
软件工程这门课的性质十分特殊。这是一门几乎不涉及理论,却涉及工具的使用、大量的经验与人为设定的规则的一门课。讲得清楚一些,就是这门课几乎没有什么干货,应该更多地考察实践能力,而不是用靠着一张瞎记瞎理解就能回答的卷子来考察。但没办法,我纵使有着极为丰富的项目经验教训与软件工程方法实践心得,平时学这门课的时候也还算认真,考前还是不得不去做一下复习。
吐槽完了,来谈一下具体的复习策略。课本无效内容较多,每一章的有效内容量分布不均,最气人的是复习大纲和课本还对应不起来。没办法,我只能自己把这门课讲的内容分个类,针对每个类的内容集中复习。
从实际的编程方法来看,这门课讲了结构化编程和面向对象编程两种编程方式。这两种编程方式有着不一样的分析和设计方法、工具。因此,我会各用一篇文章来复习这两部分的方法和工具。此外,还有不少内容和具体的编程方法无关,比如软件测试、软件维护,这些内容我会用一篇文章来复习。还有一些比较细致的,略有理论性的东西,比如耦合的分类等内容,我单独用一篇文章来写这些理论知识。最后我对照复习大纲,扫干净剩下的知识点。
软件工程复习1:结构化编程
需求分析
结构化需求分析的核心的数据。围绕着数据,要建立三种模型:数据建模、功能建模、行为建模。三种模型有各自的建模工具,三种模型中涉及的概念会被统一写在数据字典中以方便查看。
数据建模
数据建模描述的是数据的静态信息。准确来说,是一个数据可以进一步被分解成哪些属性,以及一个数据和另一个数据的关系中出现的新属性。
数据建模使用的E-R图。矩形是实体,圆圈是实体的属性,菱形是实体间的关系。有关系的实体要写上是几对几关系。
E-R图在上学期学数据库的时候学了,我就不多加复习了。只要看了E-R图的一个例子,就能很快搞懂这个图的意义与使用方法。
功能建模
理论上来说,有了静态模型,剩下的应该是动态模型。我对剩下两种模型的理解是:功能模型是对数据整体处理方式的建模,行为建模是对数据局部具体处理方式的建模。
所有程序全部可以看成是一个输入转换成输出的过程。输入输出不仅是传统的数据,输入可能是鼠标的一次点击、键盘的一次输入;输出可能是屏幕窗口的一个变化。功能建模就是描述输入数据是怎么一步一步变成输出数据的。
数据流图(DFD)是常用的(考试考察的)功能建模工具。DFD按照自顶向下的思想,用多层图来逐步分解数据加工过程。顶层图只有一个数据加工过程,之后的1、2层图会把上一层的数据加工过程细分。
每一层中,圆圈表示数据加工;矩形表示外部的实体,也就是和数据交互的对象;封了半边口的矩形是数据库;箭头是数据流向,箭头上要有数据流名。
DFD有以下要求:
- 父图和子图要平衡。具体来说,父图和子图的输入输出要一致。子图可以把父图的输入分解。
- 数据变换部分要按次序编号
这种图看了一遍例子就能理解图的意思,但要自己画一画才能掌握画的方法。正常来说DFD至少要分解到第二层,但考试要求我们只画一层。为了复习,我来做一道例题。
</br>
例:银行活期现金存取款柜台业务软件系统。存款时,储户将存款金额及存折,交给银行柜台操作员;取款时,储户则直接将取款数额告知操作员,并递交存折。具体存取款过程如下:
(1) 存款处理
- 清点现金,确认存款金额;
- 输入帐号、存款金额;
- 根据存款金额记录分户账及总账,并登记存折及打印凭条。
(2)取款处理
- 输入帐号,取款金额;
- 储户输入密码,系统核对密码并查询余额;
- 若余额充足,根据取款金额记录分户账及总账,并由票据打印机打印登折数据和凭条数据。
</br>
要求:画出系统顶层和一层数据流图 。
老师给的参考答案:
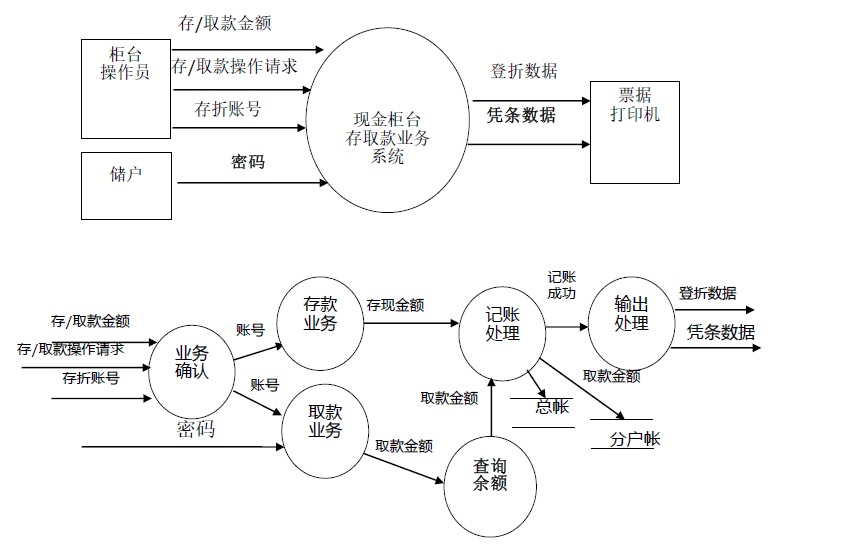
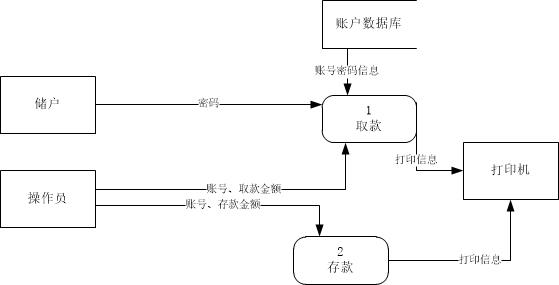
我第一遍的答案:

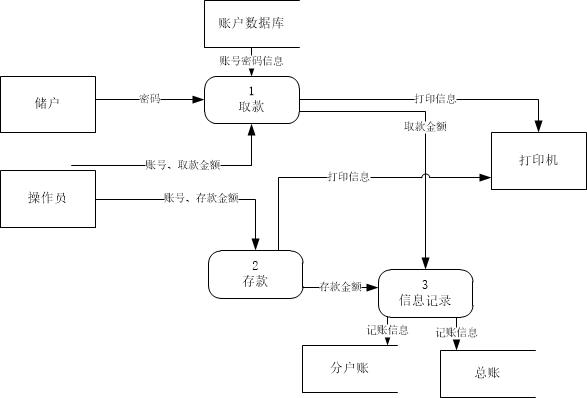
看了答案后修改的答案:
先声明一下,这道题我们之前上课做了一遍,我不是第一次做。
首先先看一下顶层图,顶层图其实就是这个系统包含的范围,以及系统涉及的实体。把存折给操作员等行为并不是在软件中,因此不能放进软件系统里;打印机是一个独立的系统,不算在这个软件里面。所以最终顶层图画成了那个样子。我对顶层图答案没什么异议。
重点在一层图上。我这次第一遍画的时候,看到需求很明确地把软件的需求分成了存款和取款两个部分,所以我直接就分了两个数据变换模块,没有去管存取款的实现细节。讲道理,一层图不需要画那么细,这样画一样理论上就可以了。
但我看了答案之后,加入了一个信息记录模块。因为把修改分户账和总账在存款和取款中都出现了,单独拿出来也说得过去。
但是答案剩下的部分我就不能赞同了。首先是业务确认模块。需求只提到存款要确认,但没有提到取款要确认。虽然按常识来说存取款都是要确认操作的,但是这里需求没有给出,就不应该加进来。既然取款不需要确认,那么就不能写一个公共的业务确认模块。再来是查询余额模块。查询余额显然是属于取款的,这个应该属于实现细节,在一层图就写出来还早了一点。
老师上课的时候也跟我们说,由于只要求画一层图,这张图细节部分写得多了一些。按理来说,参考答案做的并不是很好。我觉得我第二遍的答案更好一些。甚至在实际实现的时候,我觉得第一遍的答案就够了,细节就应该在之后的图里显示出来。哪怕存取款有重合的部分,也可以在实现的时候进行模块复用。
我觉得这道题的最大启示不是一层图该如何分解,而是顶层图如何划分软件系统的边界的。我上课第一次画的时候就把递存折写进系统,而且没有画打印机,这些都是很明显的错误。当然我不知道考试的题会怎么出,应该把题目涉及的实体和数据变换模块找出来,把每一个重要的词都画进系统里应该就问题不大。
行为建模
前面也提到了,我觉得行为建模就是对更具体的数据变换过程进行建模。课本上介绍了两种建模方法:状态转换图(STD)和过程描述语言(PDL)或伪码语言(PL)。
状态转换图
正如其名,状态转换图描述了数据对象不同时刻的不同属性,以及在不同状态间的转换方式。
我先以个人经验讲一下状态转换图的必要性。我之前做游戏的时候,被一个逻辑搞得十分头疼:卡牌游戏中鼠标的控制逻辑。正常情况下,鼠标可以拖动卡牌,也可以放到敌人头上或者一个buff上查看具体信息。在拖一张卡的时候,卡移到我方头上或者对方头上就不能显示信息,而应该根据卡牌是否能对这个目标使用而高亮目标。拖手牌里的一张卡和拖场面上的一张卡的拖动状态还是不一样的。由于没有事先设计,这个逻辑写的我非常混乱。我一看到了状态转换图,就立刻知道了以后该怎么处理这种状态转换情况。课本上再栩栩如生的案例也不如一次个人的经历对我理解这个概念的帮助大。
状态转换图就类似自动机,是一个点和边构成的图。点是状态,边是转移条件。在STD中,黑点代表初态,带圈黑点表示终态,大圆角矩形框表示中间状态。中间状态要写上状态名、状态变量、状态此时的活动。
状态转移图我还没画过,虽然考试不一定会考怎么画,但我还是想练习一下。
我画的时候发现visio的状态图和课本上的不太一样,就不打算画了。
加工逻辑
加工逻辑就是描述流程或算法。工具就是我们非常熟悉的伪代码。
伪代码理论上没什么格式要求。我喜欢按C语言的风格写。当然有些人喜欢拿箭头表示赋值。
数据字典
数据字典就是对之前建模过程中的数据流、数据变换、数据做一个详细的定义,以方便沟通交流。
数据字典本身是一个概念性质的东西,其实现形式多种多样。课本上讲了三种定义数据字典的方法。
词条描述
非常死板非常麻烦的数据词典表示法,也许在实际运用中非常好用,因为它读起来的时候非常详细。但在学这门课的时候我是不愿这样写数据字典的。
直接拿一个例子来讲词条描述的表法吧:
1 | 数据元素名:词 |
定义式
用一种类似上下文无关语言的方法来定义一种数据。还是直接上例子:
1 | 日期 = 年 + 月 +日 |
数据表
直接把数据库二维表当成数据字典。比如
| 编号 | 属性 | 英文名 | 备注 |
|---|---|---|---|
| 001 | 姓名 | Name | 无 |
结构化设计
设计分成概要设计和详细设计。这两个阶段的具体定义可能会在其他文章中讲。
在结构化设计中,概要设计就是根据数据流图设计出整体结构,详细设计则是在语句层面具体设计某一个算法、过程。概要设计用面向数据流的设计方法,详细设计会用到流程图、盒图、问题分析图(PAD)、判定树。
面向数据流的设计方法(画结构图)
面向数据流的设计方法就是根据需求分析时的数据流图,设计出程序的模块。和画DFD一样,这个过程也是自顶向下进行的。
结构图
这个过程用到的工具有层次图和结构图(SC)。但从课本上的介绍来看,结构图是层次图的一个拓展。也就是这两种图不是并列关系,而是递进关系。后续的分析也是基于结构图的。
层次图用方框表示模块,只是把模块一层一层地越分越细。结构图在层次图的基础行,要求在模块之间的线上加上数据流的描述
数据流图转结构图
数据流图经过很简单的转换就能变成结构图。课本介绍了两种转换方法。这两种方法输出的结构图的整体结构与大致算法大致相同,但分析数据流图的理解角度不同。
第一种方法是变换分析法。这种方法把整个程序看成输入处理、输出处理、变换控制三个大模块。在一层数据流图中,根据数据流与变换的形状关系,把变换分进这三种大模块里。每一个变换属于大模块里的一个小模块。
用这种方法画结构图要按以下步骤:首先,画一个主控模块(MC)、输入模块(MI)、输出模块(MO),变换控制模块(MT)。MC在最上面,MI、MT、MO分别画在下面,与MC连线。之后,再一层数据流图中画两条边界,把一层图分成三部分。最后,把数据流图“旋转”一下,把对应的数据流和变换模块都写到大模块下方。只要有了数据流图,划分了边界,就可以立刻把数据流图转换成结构图。看了书上的例子就能很快理解这个转换方法。
第二种方法是事物分析法。该方法是思想是找到一层数据流图中有多条路径的变换,把这个变换当成事务中心。所有的输入在经过预处理后经过事物中心进行变换,没有输出模块。
用这种方法画结构图有以下步骤:首先,在一层数据流图中找到事物中心,把事物中心的输入部分划分到一起。之后,画一个主控模块(MC)、输入模块(MI)、事物调度模块(该模块名就是选择的事务中心的变换名)。最后,用和变换分析法类似的方法把数据流图“旋转”一下,在大模块下补上小模块。
当然还有第三种方法,叫混合分析法,就是把两种方法综合一下,变换分析法的输出模块改成事物调度模块。
程序流程图
这是高中就学过的工具,用以描述程序设计的三种结构(顺序、分支、循环)。
圆矩形表示开始结束,方矩形表示是操作,菱形表示判断,箭头表示控制流方向。
盒图
盒图也是用来描述程序设计的。相比程序流程图,盒图没有随意的控制流,能够更好地划分数据的区域。
整个盒图画在一个方形中。具体形式看后面的示例。
问题分析图
问题分析图(PAD)也是用于程序设计的图。它也能规避控制流的任意性。
PAD从上到下是流程,从左到右是模块的细分。
例:
把代码转换成盒图和PAD。
1 | A; |
(原题来自课本的一个流程图)
解:
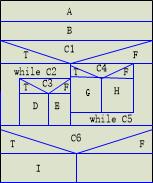
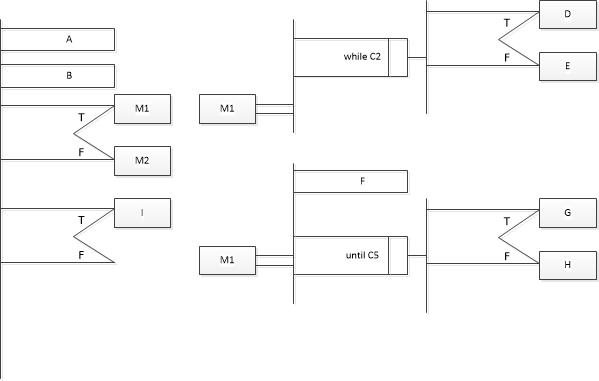
判定树
判定树用来表述复杂的条件判断。由于if语句本身符合树结构,用一棵树来表示判断语句是非常自然的。
判定树画起来很简单,左边是条件,每个条件都可以分叉成多个子情况里的条件。最右边是该分支下的结构。
判定表
判定表和判定树作用一样,也是设计复杂条件判断的工具。
判定表的行分成两部分,一部分是条件,另一部分是动作。判定表的每一列表示一个条件和动作的组合情况(条件用T、F表示,执行的动作打个勾)。
一些后续的事情
由于我没有管理好精力,我没有对后面几章做系统的复习。还好,考试没有考很多死板的内容,考的东西偏向理解,我几乎都能答得上来。有一点要特别提一下:考前说好数据流图只画一层,考试的时候要求画两层。







