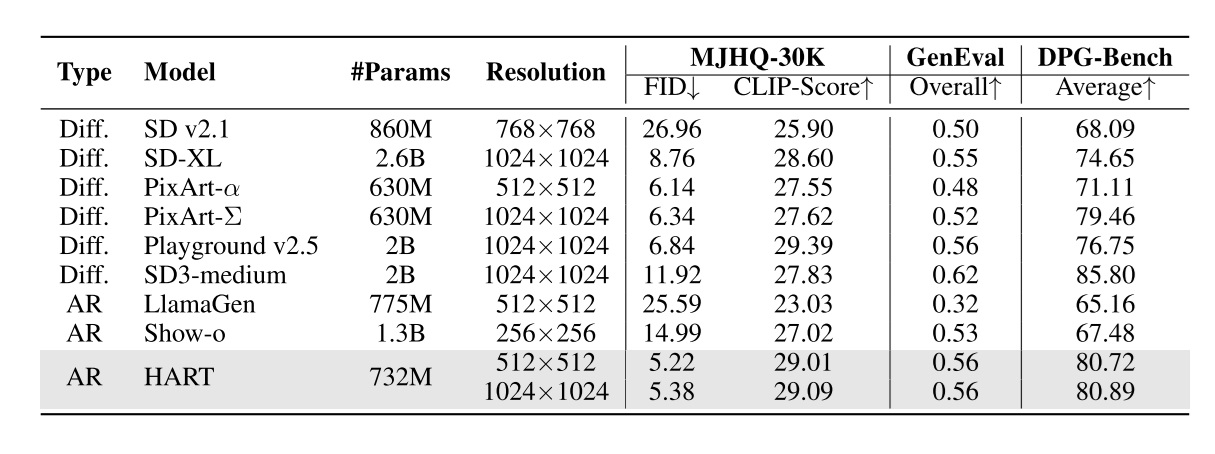
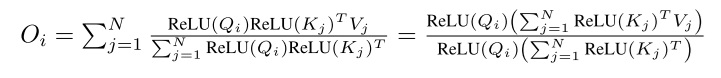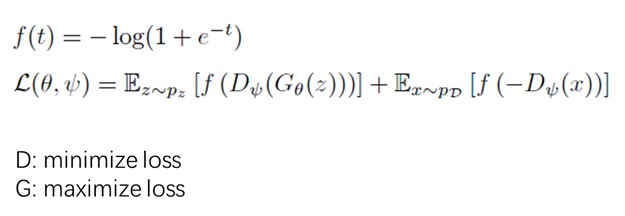大语言模型(LLM)社区近期的一大热点研究课题是推理时扩展 (Inference-time scaling),这一热点也逐渐传播到了以扩散模型技术为代表的图像生成社区。相比以往扩散模型图像编辑方法,这类新方法不是那么追求应用的实时性,反而更关注图像生成质量能否随着推理时间增加而提升。那么,在扩散模型中,该怎么实现推理时扩展呢?
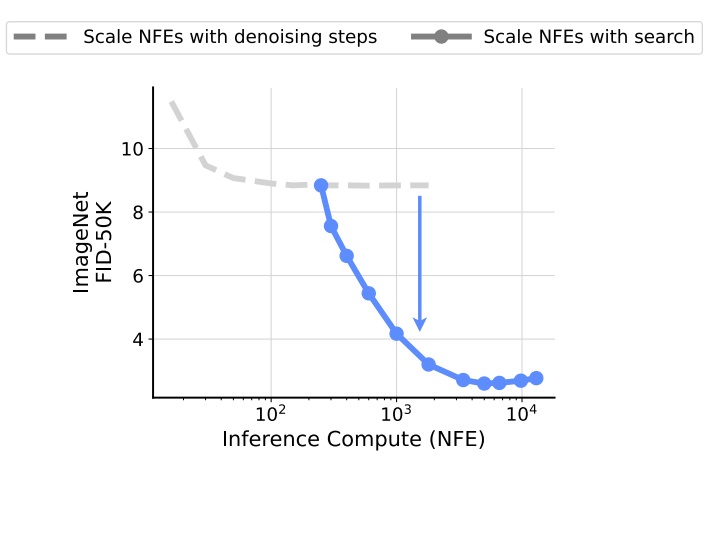
虽然扩散模型天生就有采样步数这一灵活的采样参数——采样步数越长,生成效果越好,但有实验表明,一旦采样步数多于一个值后,再扩增采样步数对生成质量的影响微乎其微。而近期不少工作从另一个角度挖掘了扩散模型的推理时扩展能力:既然扩散模型采样的开始和中间过程都受某些随机噪声影响,那么搜索更好的噪声,是不是就能带来更好的生成结果呢?如下图所示,谷歌近期的一篇论文表明,同样是增加函数调用次数(number of function evaluations, NFE),增加噪声搜索量比增加去噪步数的收益更显著。
在这篇博文中,我会分享我这几天学习的几篇有关扩散模型噪声搜索的论文。具体来说,我会分享 “Golden Noise” [1] 这篇直接输出最优噪声的论文,以及使用噪声搜索的 Inference-Time Scaling for Diffusion Models beyond Scaling Denoising Steps [2] 和 Inference-Time Text-to-Video Alignment with Diffusion Latent Beam Search [3] 论文。我会介绍这些论文的主要设计思想和重要实验结果,并分享一些个人科研观点。由于我也是刚开始学习,暂时不能理解论文里的所有公式,叙述时也可能会有一些纰漏。欢迎大家讨论与补充。
知识回顾
扩散模型简述
扩散模型定义了加噪过程和去噪过程:加噪过程中,训练图像 $x_0$ 会加噪 $T$ 次,最后变成纯高斯噪声 $x_T$;去噪过程中,纯噪声 $x_T$ 会被去噪 $T$ 次,最后变成生成图像 $x_0$ 。去噪过程即图像生成过程。为了让模型学习去噪,我们要通过加噪过程为模型提供训练样本。
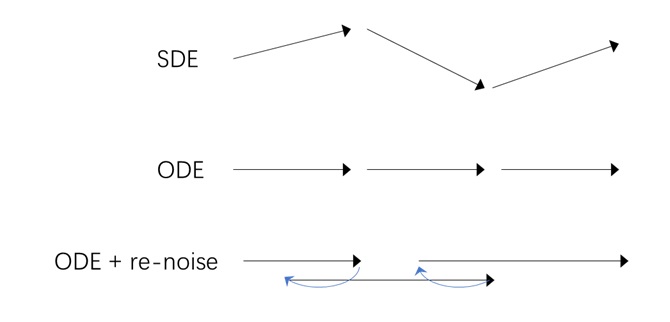
对于同一个训练好的去噪模型,我们可以用不同的数学模型建模其去噪过程:使用随机微分方程(SDE)建模时,每一步去噪都会受到某随机噪声的扰动;用常微分方程(ODE)建模时,每一步去噪都是决定性的,或者说无随机性的。从随机性的角度看两种建模方式,SDE 在采样初始噪声 $x_T$ 和中间每一步采样时都有随机性,而 ODE 仅在采样初始噪声时有随机性。
如果我们又想用 ODE 采样,又想在采样时加入随机性,该怎么办呢?这时,我们可以利用扩散模型定义好的加噪过程:比如当前采样到了 $x_t$,我们用加噪过程给它随机加噪两步,得到 $x_{t+2}$,再用 ODE 去噪三步,得到 $x_{t-1}$。这样,我们能在正常去噪的同时,通过加噪过程中的随机噪声引入随机性。
得益于 ODE 的确定性,我们可以使用 ODE 反演 (Inversion) 来把真实图像 $x_0$ 重新变回噪声 $x_T$。相比加噪过程,由于这个反演过程没有任何随机性,我们可以保证再次对 $x_T$ 做 ODE 采样得到的重建图像 $\hat{x}_0$ 和原图像 $x_0$ 非常相似。重建图像的误差大小取决于反演算法的精确度。
在去噪时,我们可以启用 CFG (Classifier-free Guidance) 功能,让输出图像更符合某一条件信息。比如,我们可以用 CFG 让输出图像更符合文本提示词。具体来说,对于一个条件于文本信息 $c$ 的网络 $\epsilon_\theta(x_t, t, c)$,我们让它输出 $\epsilon_\theta(x_t, t, c)$, $\epsilon_\theta(x_t, t, \emptyset)$ 两个值,再令这一轮的最终输出为 $(w - 1)(\epsilon_\theta(x_t, t, c) - \epsilon_\theta(x_t, t, \emptyset)) + \epsilon_\theta(x_t, t, c)$,其中 $w$ 为 CFG 强度。直观上看,当 $w > 1$ 时,这一操作相当于是在原输出 $\epsilon_\theta(x_t, t, c)$ 的基础上,让输出更加远离空条件的输出,更加贴近有条件的输出。
在本文中,除非特别指明,否则默认扩散模型使用 ODE 采样。
搜索算法
搜索算法用于从某数据集合中搜索出最符合要求的数据项。一个最简单的场景是数据库搜索:我们输入某数据,将它与数据库中所有数据逐个比对,以判断它在数据库中是否存在。这个算法可以写成:
1 | input query |
我们可以从两个角度拓展这个算法。第一,我们要搜索的数据集合可能是由某个规则指定的搜索空间,而不是一个具体的数据库里的数据。比如,我们要搜索长度为 10 的由小写字母组成的单词,那么尽管我们没有提前存下所有的单词,我们也知道搜索空间里可能的单词有 $26^{10}$ 种。这种数据的搜索空间往往较大,我们通常不能用算法在较短的时间里搜索出最优解,只能用某些启发式算法搜索出一个较优解。
第二,我们不一定要让搜索成功的条件为「完全匹配」,而是可以设置一个评估函数,并从最终搜索中返回价值最大的那个数据项。
1 | input query, evaluator |
根据这个算法结构,在阅读这篇博文时,我们可以从以下几个角度整理每篇论文:
- 噪声的搜索空间是什么?(是只有开始的噪声可以修改,还是中间每一步去噪也有随机噪声?)
- 搜索算法是什么?
- 评估函数是什么?
噪声搜索的早期尝试
如前所述,在扩散模型时,我们会先从高斯分布中采样,得到一个纯噪声图像 $x_T \sim N(0, \textbf{I})$,再逐步对其去噪,得到 $x_{T-\Delta t}, x_{T-2\Delta t}, …$,最后得到清晰图像 $x_0$。在各种图像编辑应用中,由于最开始的纯噪声 $x_T$ 信息过少,我们一般会对中间每一步的带噪图像 $x_{T-i\Delta t}$ 都做编辑。经典的 Classifier Guidance 和 Classifier-free Guidance 都是按照这种方式改进生成图像。
随后,有研究发现,仅优化初始噪声 $x_T$ 也能提升生成质量。较早研究这一性质的论文是 CVPR 2024 的 INITNO [4]。该论文发现,对于同样的提示词,有一些「有效」噪声对应的输出更符合提示词。
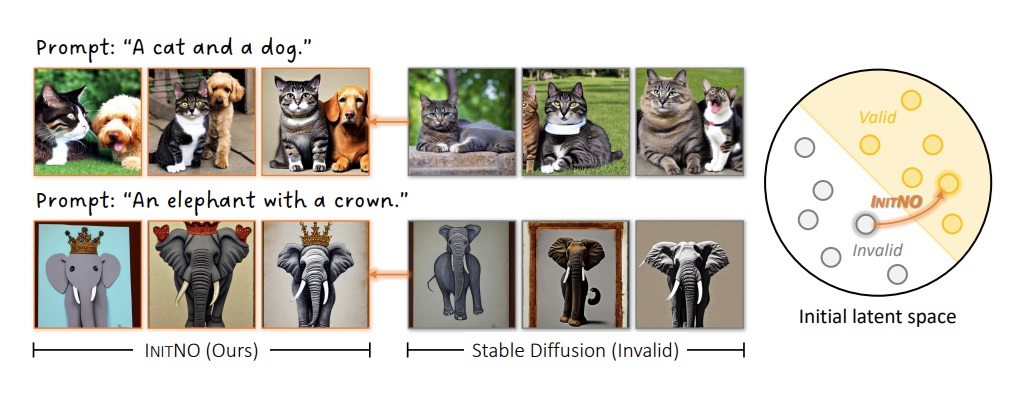
基于这个观察,INITNO 使用如下算法搜索最优噪声:
- 对于当前某个随机噪声 $x_T$,令它每一轮优化后的值为 $\mu + \sigma x_T$。
- 每一轮优化中,将 $\mu + \sigma x_T$ 输入进去噪网络中。根据某个来自于去噪网络的可微评价指标,用梯度下降更新 $\mu$, $\sigma$。
- 将最后的噪声 $\mu + \sigma x_T$ 加入噪声池。
- 多次采样初始噪声 $x_T$ ,执行上述步骤,以扩充噪声池。
- 最后,再次根据评价指标,选出噪声池里的最优噪声。
这篇论文选用的评价指标为去噪网络注意力模块响应程度,这种设计受到了 Attend-and-excite [5] 论文的启发。由于该指标的原理与本文主要介绍的内容无关,此处不对其做深入探讨。我们只需知道 INITNO 使用了一个两步噪声搜索算法:1)优化某个随机噪声;2)多次获取优化后噪声,再次选取一个全局最优噪声。评价噪声好坏的标准是其去噪过程中去噪网络注意力块的中间输出,这是因为这些中间输出与文本匹配度密切相关。
稍晚一些的工作 “Not All Noises Are Created Equally” [6] 也汇报了类似的观察:并非所有噪声本质相同,有些噪声的生成质量更高。这个工作实现了两类搜索算法:
1) 噪声选取:从多个随机噪声中直接选取指标最优的那一个。
2) 噪声优化:从当前噪声开始,根据优化指标用梯度下降优化当前噪声。

从搜索算法上看,这个工作相当于把 INITNO 里的两步搜索算法拆成了两种算法。
这个工作用了一种有趣的评价指标。对于噪声 $x_T$,我们求它先生成,再 DDIM 反演 (DDIM Inversion) 得到重建噪声 $\x’_T$。之后,我们令重建稳定性为 $x_T$ 和 $\x’_T$ 的 cos 相似度。论文指出,重建稳定性更好的噪声具有更高的生成质量。尽管作者并没有严谨地分析这个指标,但实验表明这种指标确实有效。我们在后文中会看到,该团队的后续工作对这个指标的原理进行了一定的解释。
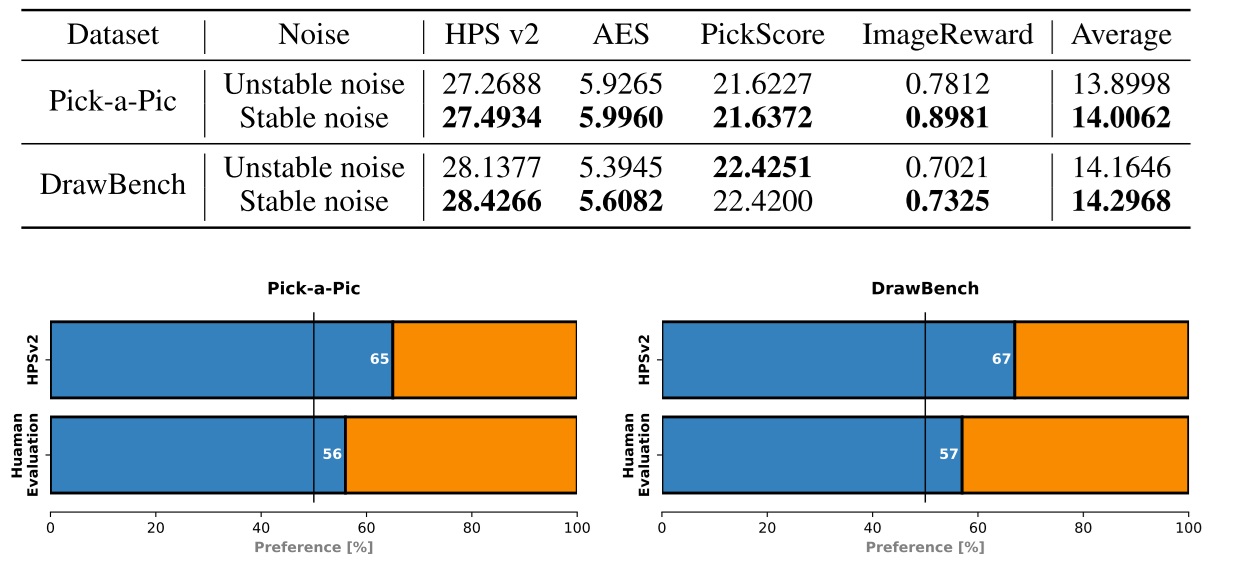
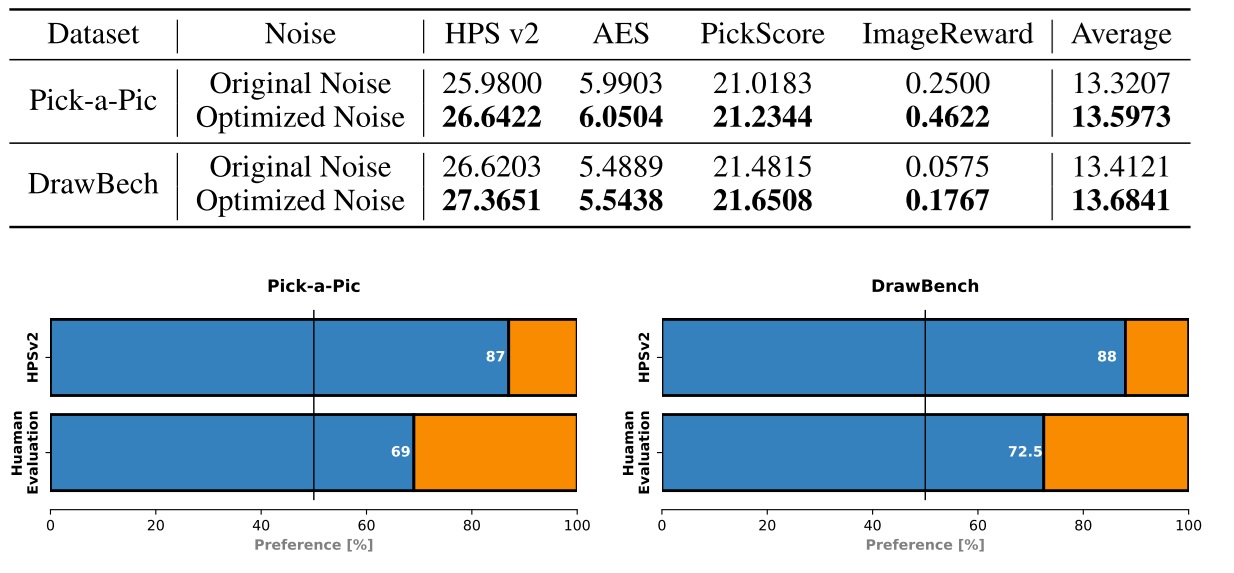
Golden Noise: 直接输出临近最优噪声
“Not All Noises Are Created Equally” 的研究团队后续推出了其改进版 Golden Noise for Diffusion Models: A Learning Framework [1]。这篇论文最大的亮点是不直接使用噪声搜索,而是先用噪声优化方法得到「差噪声-好噪声」这样的数据对作为训练样本,再用一个小网络学习差噪声到好噪声的映射。在阅读这篇论文时,我们主要关注两件事:1)如何为差噪声找到对应的好噪声?2)噪声优化网络有何亮点?
在构建训练样本时,Golden Noise 并没有用噪声搜索技术,而是用规则直接得到更好的噪声。和前作”Not All Noises Are Created Equally” 一样,这篇论文把噪声 $x_T$ 先去噪再 DDIM 反演的重建噪声当成一个更好的噪声。稍有不同的是,这篇文章明确指出,去噪时使用的 CFG 强度大于 1,而反演的时候 CFG 强度等于 1。这样得到的重建噪声 $x’_T$ 能够更加贴近条件文本的描述。
作者用公式推导介绍了这项技术的原理。通过合并去噪和 DDIM 反演的公式,我们能够用下面的式子描述原噪声 $x_T$ 和反演噪声 $x’_T$ 的关系。我们可以忽略多数参数,只看后面 $\epsilon$ 做差的那一项。前面的系数 $w_l - w_w$ 表示去噪 CFG 强度 $w_l$ 减去重建 CFG 强度 $w_w$。可以发现,这个式子和 CFG 类似,也是写成了带条件输出 $\epsilon(\cdot, c)$ 减去无条件输出 $\epsilon(\cdot, \emptyset)$ 的形式。那么,它的作用也和 CFG 类似,可以把噪声「推向」更靠近文本描述的方向。
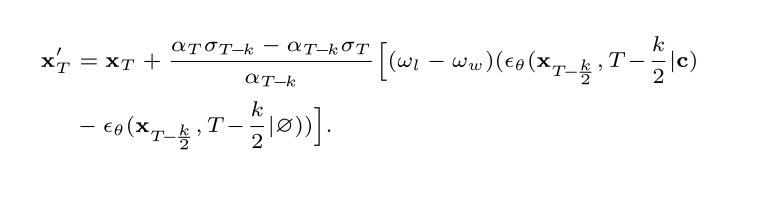
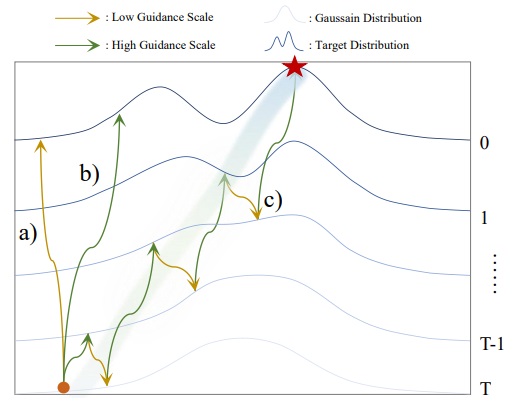
该团队的同期工作 Zigzag Diffusion Sampling [7] 用了更多示意图来直观解释这项技术的原理。从语义贴合度的角度看,使用 CFG > 1 的强度做去噪会提升噪声的语义贴合度,而使用 CFG = 1 的强度做反演几乎不会改变噪声的语义贴合度。因此,只要反复执行去噪-反演过程,就能让噪声的语义贴合度逐渐提升。
先去噪再反演只能提升噪声的语义贴合度,而不能保证图像的质量提升。因此,在构建好噪声时,Golden Noise 还使用了一种拒绝采样策略,以确保找到的「好噪声」确实能生成高质量图片。具体来说,Golden Noise 用一个基于神经网络的图像质量评估器和原噪声 $x_T$ 对应图像 $x_0$ 和新噪声 $x’_T$ 对应图像 $x’_0$ 分布打分。只有 $x’_0$ 的分数比 $x_0$ 高出一点时,才把 $(x_T, x’_T)$ 加入训练集。
我们再简单看一下噪声预测网络的设计。这个网络会根据输入的差噪声 $x_T$ 输出语义贴合度高且质量更高的噪声 $x’_T$。作者发现,每对噪声的 SVD (奇异值分解) 结果非常相似。因此,Golden Noise 设计了一个两路网络:一个网络根据输入噪声,输出预测噪声的大致 SVD,它决定了最终噪声的主要内容;另一个网络根据输入噪声和文本嵌入,输出一个残差噪声,用于补充细节。
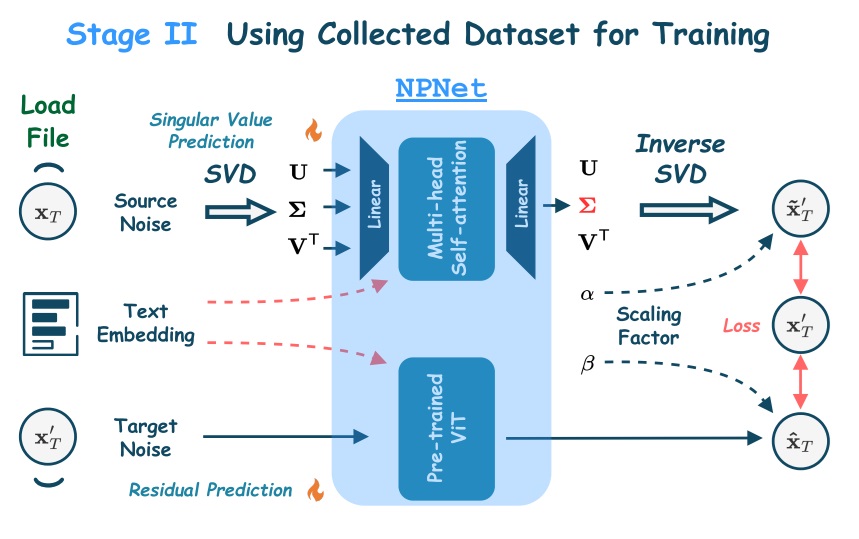
一套完整的噪声搜索基础框架
2025 年 1 月,谷歌谢赛宁团队公布了论文 Inference-Time Scaling for Diffusion Models beyond Scaling Denoising Steps。这篇论文依然是从搜索更优的初始噪声或中间噪声的角度来提升扩散模型采样质量。但相比之前的工作,这个工作作出了两大贡献:
- 从推理时扩展 (Inference-time scaling) 的角度认识噪声搜索,研究采样计算量与图像指标的关系。
- 提出了一套系统性的噪声搜索框架,指明了框架的两个设计维度:评估图像质量的评估函数和搜索时使用的算法。这篇博文对搜索算法的建模方式主要参考自这一框架。
下图是论文中的第一张示意图。彩色的线是增加噪声搜索量的结果,灰色的线是增加采样步数的结果。可以看出,不管是哪个评价指标,增加噪声搜索量对图像质量的提升都更加明显。
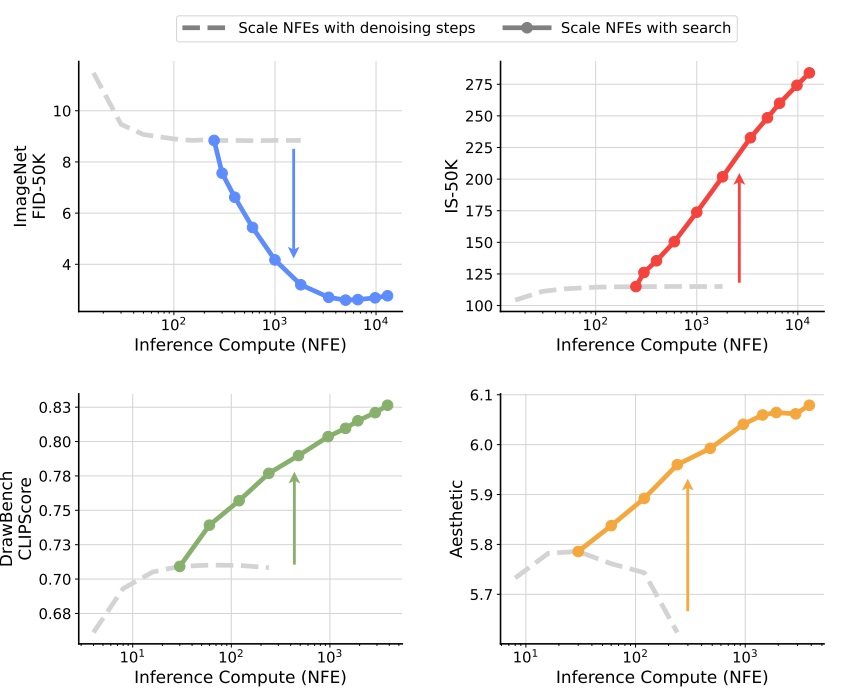
这篇论文的叙述逻辑十分流畅。让我们按照论文的叙述顺序,看看这个工作用到了哪些搜索算法与图像质量评价指标。
早期验证
为了简单验证是否可以通过增加噪声搜索量来提升图像质量,这篇论文开展了一个简单的验证实验:使用在 ImageNet-256 上训练的 SiT [8] 模型,使用较简单的搜索算法和最直接的评估指标,观察模型按类别生成(额外输入一个类别标签)质量随搜索量的变化趋势。
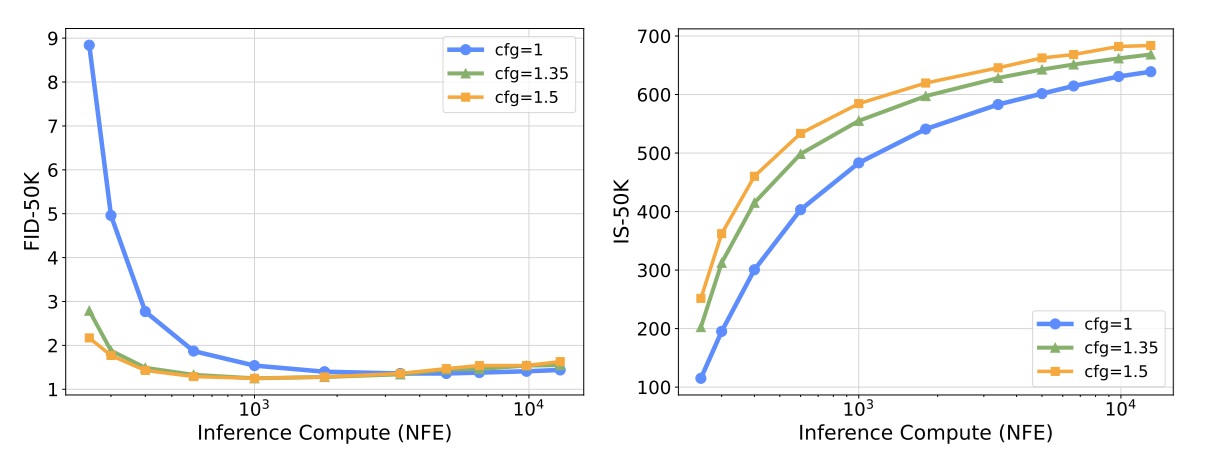
具体来说,在搜索算法上,作者采用了「随机搜索」(random research) 算法:和 “Not All Noises Are Created Equally” 中的噪声选取一样,算法随机采样大量噪声,然后选择效果最好的那个噪声。在评估函数上,作者采用了简单粗暴的「面向答案」策略:如果最终的测试指标是 Inception Score,就选取 Inception V3 网络的对输入类别的分类概率最大的噪声;同理,如果最终测试指标是 FID,就贪心地选取让 FID 尽可能小的噪声。由于实际应用中,我们不能用这种「作弊」的方法提前知道评测指标,因此这种评估函数仅供概念验证使用。
以下是早期验证实验的结果。由图可知,提升计算量能够明显提升图像质量。比如,左侧 FID 结果中,对于 CFG=1 的曲线,不使用噪声搜索(NFE 最少的那个点)的结果很差;然而,增加噪声搜索量后,CFG=1 的 FID 分数甚至能超过 CFG=1.5 的。
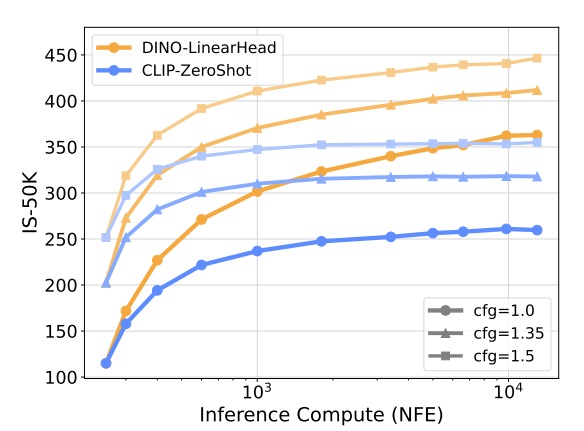
之后,论文测试了两个更加合理的评估函数:使用 CLIP 和 DINO 分类器。和前面的 Inception V3 网络一样,评估函数会找出分类概率最大的输出。
用 CLIP 做类别分类器时,需要把类别转换成文本。
使用更合理的评估函数后,依然能观察到图像 Inception Score 随搜索量增长的现象。
其他搜索算法
随机搜索算法虽然表现不错,但这个算法会导致验证器欺骗 (verifier hacking):算法快速在整个高斯噪声空间中找到了那些验证分数更高的噪声。但是,验证器总是存在偏见的,验证器高分不总是代表图像质量高。因此,验证器欺骗会导致输出图像分数虚高,且多样性下降。
为了缓解这个问题,论文尝试了其他搜索算法。论文先尝试了零阶搜索(Zero-Order Search, ZO)算法 :对于某个输入噪声,仅在其小邻域里搜索更好的噪声。搜索时,我们随机从邻域里取一些噪声,然后选评估分数最高的那一个噪声。之所以把这个算法称为「零阶」,是因为先有一阶搜索算法:让评估函数对噪声求梯度,沿着令评估分数更好的梯度方向优化。但作者发现,一阶搜索算法需要反向传播梯度,速度太慢了,相较零阶搜索并没有明显优势。
“Not All Noises Are Created Equally” 的噪声优化算法是一种一阶搜索算法。
另外,论文还尝试了沿路径搜索(Search over Paths)算法。在这个算法中,作者把原来的 ODE 采样改成了 ODE-重加噪采样:每次去噪几步,稍微加噪几步,又去噪几步。这样,就可以在采样过程中也引入随机噪声。沿路径搜索希望找到一条最优的生成路径,这个路径既涉及初始噪声,也涉及中间噪声。
在搜索时,沿路径搜索采用了 beam search 的策略:维护一个大小为 $N$ 的当前最优带噪图像。每一步,对每个带噪图像(也就是每条采样路径)采样 $M$ 个噪声,得到 $NM$ 个可能的下一轮带噪图像。最后,使用评估函数,从 $NM$ 个图像中挑选最优的 $N$ 个。
在前两种搜索算法中,我们都是得到了最终的生成图片 $x_0$,再用评估函数来评估 $x_0$ 的质量。但在沿路径搜索中,我们在采样过程中途就要决定当前带噪图像 $x_t$ 的质量。为了高效评测 $x_t$ 的质量,沿路径搜索会先对 $x_t$ 执行一步去噪,再根据扩散模型公式算出一个临时预估的 $x_0$,最后评估该 $x_0$ 的质量。
如下图所示,这两个新搜索算法也是有效的。各项实验的详细参数请参考原论文。

文生图模型实验
在较为简单的按类别图像生成任务上验证了想法的有效性后,论文展示了文生图任务上噪声搜索的效果。
将任务拓展成文生图后,不需要重新设计搜索算法,只需要更新评估方法。论文选用的评估方法包括 ASP (Aesthetic Score Predictor), CLIPScore, ImageReward。它们的评估标准如下:
- ASP 模型为输入图像预测一个美学分数。
- CLIPScore 表示 CLIP 输出的图文匹配程度。
- ImageReward 能够从图文匹配度、美学质量、无害度等多个角度评估图像。
除了单独使用上述某个评估方法外,还能够将所有评估方法组合成一个集成(ensemble),更综合地评估图像。
在测试时,论文使用了同样的指标。但是,为了确保对比的公平性,我们应该忽略评估方法和测试指标完全相同时的结果。另外,论文还汇报了多模态大语言模型 (MLLM) 的打分结果,作为补充测试指标。
下图展示了在 FLUX.1-dev 上使用上述评估方法做噪声搜索的实验结果。第一行的实验是不使用噪声搜索,只用 30 次 NFE 做去噪的实验结果。后面的实验都是用了 2880 次 NFE 在搜索上。相比之前 ImageNet 上的 FID 实验,此处指标提升得并不明显。
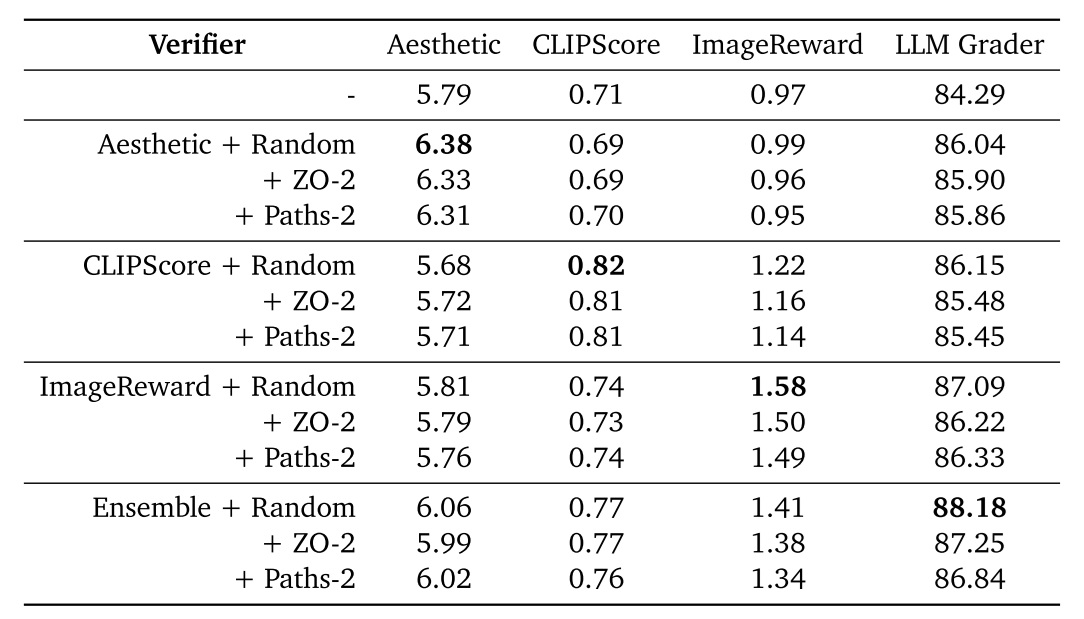
论文还展示定性实验结果。每一行前三张图像是增加去噪 NFE 的结果,从第四张图像开始是增加搜索 NFE 的结果。
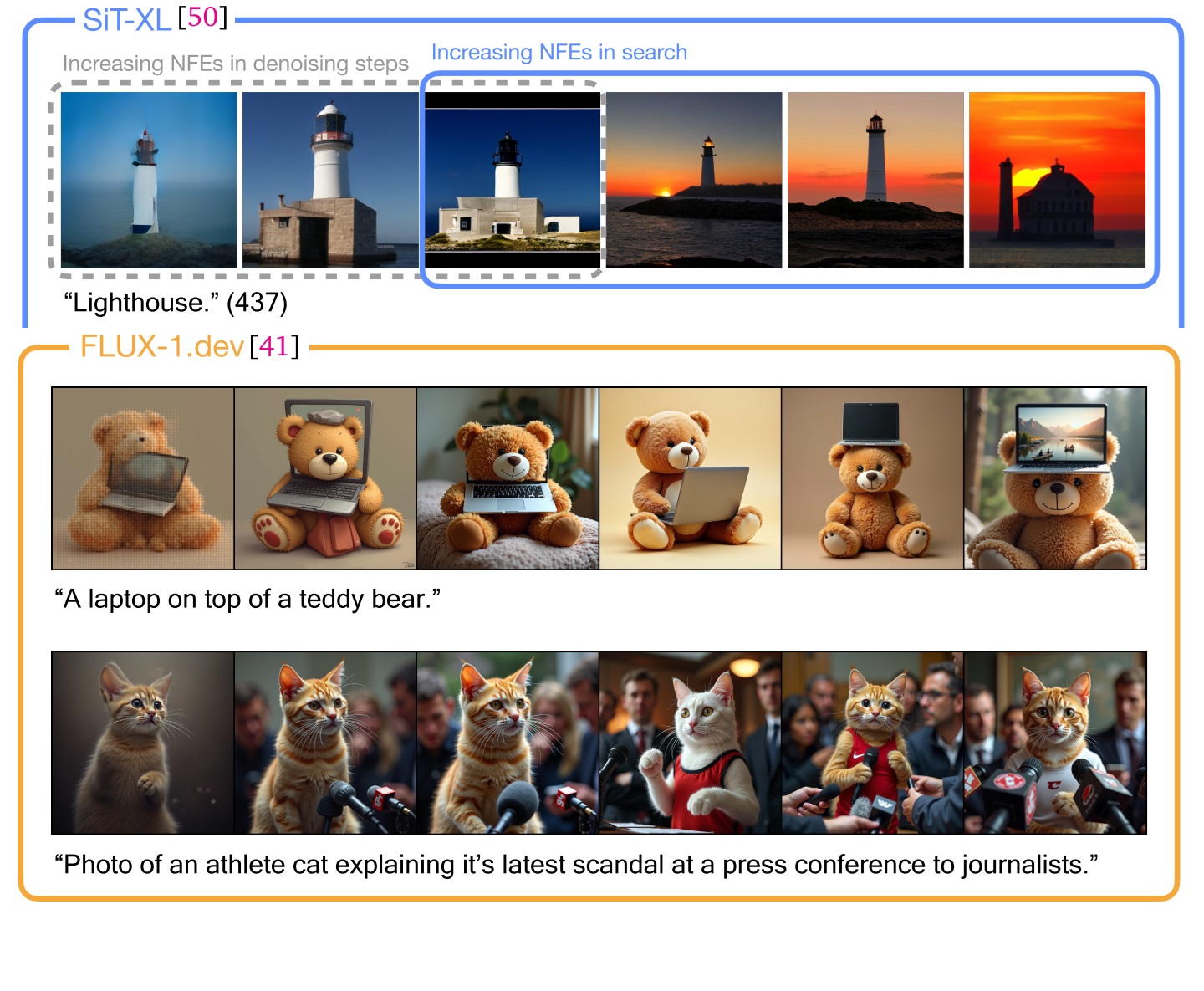
与偏好微调结合
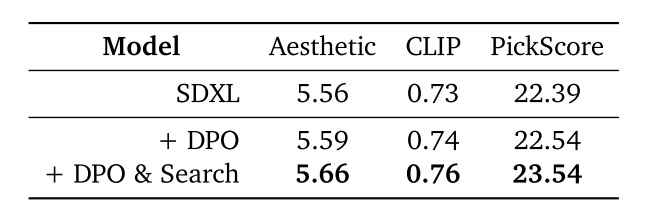
现在 LLM 普遍采用了根据奖励函数微调模型的策略,比如直接偏好优化(Direct Preference Optimization,DPO)。这些微调技术也被用到了扩散模型中,比如 Diffusion-DPO [9]。而噪声搜索的做法和这些微调方法很像,都是基于某一个奖励函数,让模型的输出更符合人类的偏好。那么,对于微调过的模型,噪声搜索还有用吗?
论文展示了在 Diffusion-DPO 中的 SDXL-DPO 上应用噪声搜索的实验结果。可以看出,噪声搜索同样兼容偏好微调模型。
视频扩散模型中的 Beam Search
最后,我们来简单浏览近期另一篇使用噪声搜索技术的论文: Inference-Time Text-to-Video Alignment with Diffusion Latent Beam Search [3]。相比前几篇论文,这篇论文主要是把噪声技术拓展到了视频模型上。阅读这篇论文时,我们会简单看一下论文的搜索算法和视频评估函数,并讨论论文中的部分理论推导。
Beam Search 噪声搜索
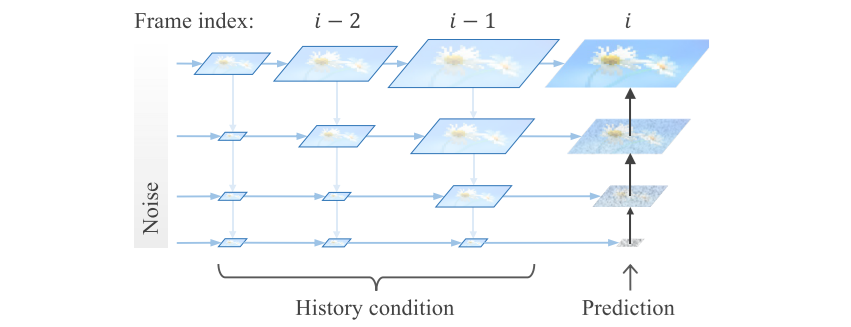
这篇论文用到的搜索策略和上文中的沿路径搜索完全相同。即一轮去噪中,我们维护 $N$ 个最优带噪视频,并从 $NM$ 个下一轮带噪视频中选取最优的 $N$ 个。一个 $N=2, M=2$ 的示意图如下所示:
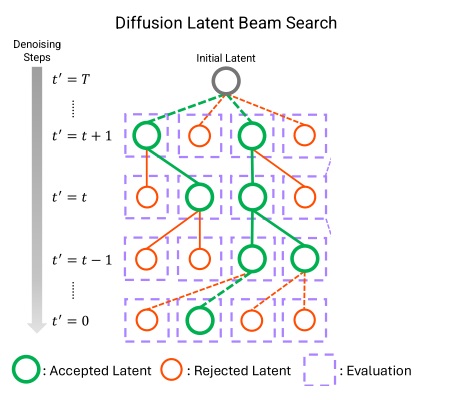
同样,在这个搜索算法中,我们无法提前获取清晰视频 $x_0$,需要用某种方法即时评估带噪视频 $x_t$。上一篇论文通过一步去噪并提前获取预测 $x_0$ 的方式实现了在线评估。而这篇论文采取了另一种类似的策略:对当前带噪视频执行一个步数极少(2~3)步的 DDIM 采样,以快速预测当前 $x_t$ 对应的 $x_0$,再评估预测的 $x_0$ 的质量。
视频评估指标
这篇论文将 MLLM 的打分结果作为最终优化目标。但由于此评估方法过于耗时,在搜索时,该论文还是用了一些更高效的评价指标,包括:
- 主体一致性:用帧间 DINO 特征的相似度表示
- 运动平滑性:借助视频插帧网络提取视频运动特征
- 运动程度:用光流表示
- 美学质量:用 LAION 美学预测器评估
- 图像质量:用一个能够检测图片是否过曝、模糊的 low-level 质量评估网络评估
- 文本-视频一致性:用一个视频版 CLIP 评估
论文以上述 6 个指标的线性组合为最终评估指标。为了获取最优的线性组合权重,论文暴力尝试了若干组参数,并根据 MLLM 的打分结果选取最优线性组合。
理论推导
尽管这篇论文最后还是使用了简单粗暴的噪声搜索技术来优化扩散模型生成质量,但论文为这种做法提供了一些理论解释。作者借助了随机最优控制 (stochastic optimal control)中的相关技术,把让采样结果更符合某个奖励函数这一问题,转化成先求奖励函数对带噪图像梯度,再把该梯度加入去噪公式。这一技术和 Classifier Guidance 的思想非常相似:如下图所示,在 Classifier Guidance 中,我们可以对网络输出加上一个对 $x_t$ 求梯度的项,使得 $x_t$ 往某个奖励函数 (此处的奖励函数是一个分类网络,用于让图像更像某类物体)的方向靠近。
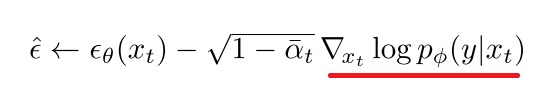
但是,求梯度太耗时了。而求梯度的一种高效近似就是零阶搜索:随机搜索附近的一些 $x_t$,找到值最优的那个 $x_t$。所以,我们可以把噪声搜索看成是 Classifier Guidance 的一种近似操作。
总结与评价
噪声搜索是扩散模型采样过程中一种通过选取最优初始、中间噪声来提升图像质量的技术。在这篇博文中,我们主要学习了早期利用扩散模型自身性质搜索噪声的 INITNO 和 Not All Noises Are Created Equally,直接用神经网络预测更优噪声的 Golden Noise,系统性建模噪声搜索的 Inference-Time Scaling for Diffusion Models beyond Scaling Denoising Steps,以及将噪声搜索应用到视频生成的 Inference-Time Text-to-Video Alignment with Diffusion Latent Beam Search。我们可以从是否搜索中间噪声、搜索算法、评估函数三个维度描述一个噪声搜索方法。本文的方法可以总结如下:
| 方法 | 搜索中间噪声? | 搜索算法 | 评估函数 |
|---|---|---|---|
| INITNO | 否 | 局部一阶搜索+全局随机搜索 | 扩散模型注意力输出 |
| No All Noise | 否 | 全局随机搜索/局部一阶搜索 | 去噪-反演稳定性 |
| Golden Noise | 否 | 神经网络预测 | 去噪-反演稳定性+图像质量 |
| beyond Scaling Denoising Steps | 仅在沿路径搜索中 | 全局随机搜索/局部零阶搜索/沿路径零阶 beam search | 分类器最大概率/美学打分器/ImageReward |
| Inference-Time Text-to-Video Alignment | 是 | 沿路径零阶 beam search | 主体一致性/运动平滑性/运动程度/美学质量/图像质量 |
从任务目标来看,噪声搜索希望模型输出能够满足某个奖励函数,尤其是满足人类偏好的奖励函数。它和相关技术的对比如下:
- Classifier Guidance: 用奖励函数一阶导数指导生成。
- 噪声搜索:使用零阶搜索时,可以看成 Classifier Guidance 的高效近似版。
- 偏好优化 finetune:用奖励函数微调模型参数。
我认为这项技术并不是一个很好的科研方向,原因有:
- 噪声搜索的做法太简单暴力了。使用过 AI 绘画的用户,应该都尝试过随机生成大量图片,然后从中挑选自己满意的图片。所谓噪声搜索只不过把这个过程自动化了而已。所有这些方法中只有 Golden Noise 的直接预测噪声看起来比较新奇。
- 不同噪声对应的图像质量不同是一个有趣的观察。但是,这些论文并没有深入分析这个问题的原因,只是用实验去证明哪些做法可以缓解这个问题。从科研上,我们更希望有文章能够深入解释某一个现有问题。
- 虽然有文章宣称噪声搜索是一种推理时扩展,但仔细浏览实验表格,噪声搜索带来的提升太有限了:网络运算次数从 30 增大到了 2880,是原来运行时间的 96 倍,换来的只是一点微小的指标提升。还不能排除文章中展示的定性图片是精挑细选的结果。
我猜测不同噪声的本质不同在于,当前扩散模型的初始噪声是放在一个二维像素网格里的。在随机采样完成后,像素间的某些关联性就被确定下来了。无论在后续采样过程中怎么干预,一开始的图像结构都难以改变。但我们更希望一开始噪声的每个维度都互相解耦合的,这样噪声的生成质量的方差或许会更小一点。要让噪声的每个维度一开始互相独立,我们可能需要设计一种新的图像表示方法,而不用二维像素结构。
我认为扩散模型的推理时扩展确实是一个有价值的研究方向。但就目前来看,噪声搜索显然不是实现这个目标的最优解。
部分参考文献
对于某些经典论文 (如 CLIP, Classifier Guidance),可以直接通过搜索关键词找到论文。其他一些较新的论文有:
[1] Golden Noise for Diffusion Models: A Learning Framework
[2] Inference-Time Scaling for Diffusion Models beyond Scaling Denoising Steps
[3] Inference-Time Text-to-Video Alignment with Diffusion Latent Beam Search
[4] INITNO: Boosting Text-to-Image Diffusion Models via Initial Noise Optimization
[5] Attend-and-excite: Attention-based semantic guidance for text-to-image diffusion models
[6] Not All Noises Are Created Equally: Diffusion Noise Selection and Optimization Zipeng
[7] Zigzag Diffusion Sampling: Diffusion Models Can Self-Improve via Self-Reflection
[8] Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers.
[9] Diffusion model alignment using direct preference optimization.