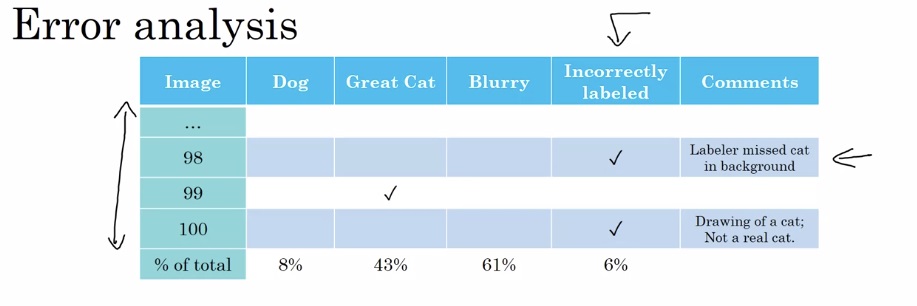
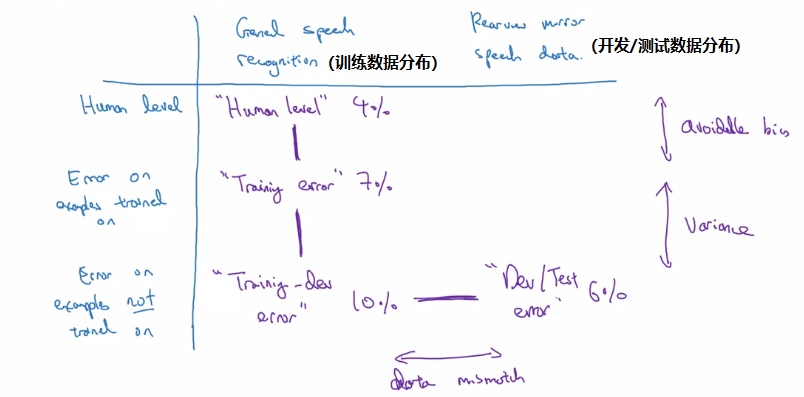
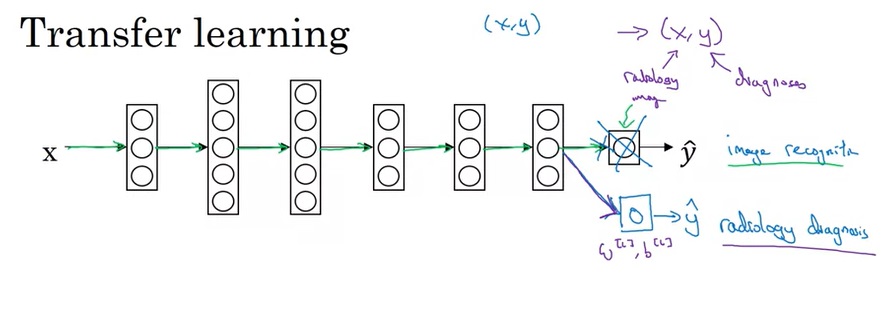
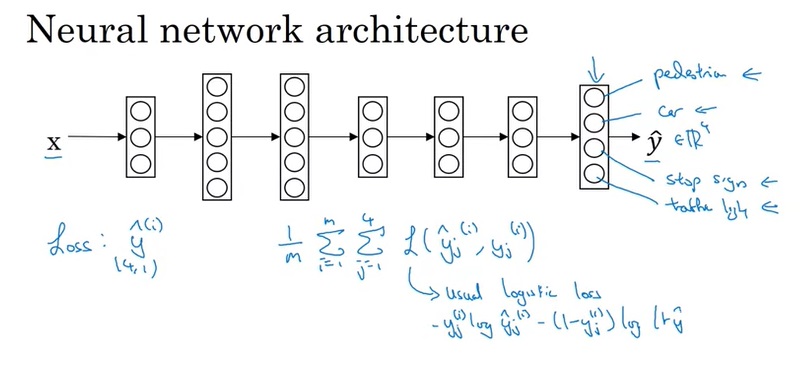
只有保研生参加的说明会结束后,大家都围着辅导员,焦急而欣喜地确认着自己的前程。待人群散开后,我走到辅导员身边,询问放弃保研的流程。
“只要写一张确认放弃保研的保证书即可。”
拿出先前准备好的纸笔,我流畅地写了几行字,提交了本专业唯一一份保研放弃书。
2022年6月,没有季节之分的新加坡,却到了毒蚊肆虐的高峰期。我不幸感染病毒,前往南洋理工大学的校医院就诊。
诊断结束后,医生关切地说道:“你这几天就不要去听课了。我给你开假条。”
我笑道:“我是员工,不是学生。”
是啊,不论穿着、相貌、言行多像一名学生,现在的我,确确实实是一名员工。
离开诊所,望了望晴朗的天空,我忽然意识到,夏天来了。
如果是在国内的话,已经是夏天了吧?
应该是这样没错。去年的这个时候,学校里可热了。
全体学生聚在操场上的那一天,阳光正盛……
去年,我还是学生。
糊里糊涂地完成了毕业设计,通过了答辩,时间已经悄悄来到了六月。
这一天,太阳不遗余力地展示起了夏天的风采。火辣辣的阳光直射在北京理工大学中关村校区的操场上,我穿着严实的学士服,感到异常闷热。我一会儿调整着学士帽的角度以遮挡阳光,一会儿又摘下帽子当扇子扇风。
不一会儿,主持人宣布了毕业典礼的开始。在酷热的今天,哪怕是一向讨厌集会的我,也静了下来,默默地听着演讲。
主持人开始念起各专业毕业学生的名单了。理论上,名单是包含了每一位同学的名字的。可为了节约时间,主持人念完前几位学生的名字后,就会以“等人”来略过后面的名字。
一个个陌生的名字,就像一声声倒计时。我深深地感受到了毕业离校的临近。
有的人保研成功,已经去实验室待了几个月。
有的人面试成功,正在做正式入职的准备。
有的人考研成功,和未来的导师刚打完招呼。
可我呢?
我该去哪呢?
造成现在的局面,真的都是我自己的错吗?
不,我很早就想好自己的出路了。
早在大一,我就做好了出国留学的打算。
托福与GRE,硕士与博士。这些信息都我来说就如常识一般。
“先尝试科研,适合就读博士,不适合就读硕士。”
这是在综合了无数份信息后,得到的平均答案。
“大三开始在做科研,暑假去参加暑研。托福考试只有两年的有效期,也只能大三之后考。”
这也是平均而言的结论。
既然大家这么说,我也就这么做吧。
在快乐的算法竞赛中,我度过了大学的前两年。
大三到了,该做留学的准备了。
刚从竞赛暑期集训中缓过来的我,错过了,或者说压根就没注意过某个学校官方的大三暑研项目。“错过就错过吧,反正大家的暑研都是自己找的。到寒假了再找吧。”我勉强安慰着迷茫的自己。
按照计划,我去找了本校的老师做科研,提前看一看自己是否适合做研究。老师本来说让一个博士生带我做点项目,后来渐渐就没了音讯。大三课业繁重,又有最后半年竞赛要打,我也无暇顾及科研的事情了。
熬过上半学期,在留学上毫无进展的我,开始回家过寒假。我计划一边套磁(方言,意为“套近乎”,特指在申请出国留学时,提前给导师发邮件推荐自己)暑研,一边开始语言考试的准备,希望能在下半学期考完语言考试。
突如其来的一场疫情,打乱了我的计划。
当然,之前那个官方暑研项目也泡汤了。我只能以此来安慰自己。
为了让自己看上去在做一些什么,每天一个人在楼下上完网课后,我总会去套磁一个教授。
之所以每天只向一个教授发邮件,是因为我害怕发邮件这件事。
点开学校主页,找到教授的研究方向,在一堆陌生的名词中拎出一两个,组织成一封“我对你的研究感兴趣,请让我参与暑研”的邮件。这一过程对我来说,是一件很惶恐而绝望的事情。
每看完一个教授的简历后,我就隐隐感到自己的背景是绝不可能申请上他的暑研的。可是,正如坠落山崖的人总想抓住什么一样,我还是不得不把邮件发出去。每发出一封邮件,我就像了了一桩大事一般,如释重负。可是,每发出一封邮件,我又能意识到,又少了一个可以套磁的教授,无教授可找的绝望又离我近了一分。
就这样,为了消化套磁每天带来的压力,我只敢一天发一封邮件。
每天向不同的人告白,告白前就已经意识到了失败。可是,还是要为明天的告白做准备。大概就是这样痛苦的感觉吧。
虽然我还没有可以自由选择方向的资格,但我只想做图形学的研究。可是,我之前几乎没有任何相关科研经历,也没有任何人脉。纯粹做图形学的教授也越来越少。想找到暑研的难度是极大的。
我的心情很矛盾。一方面,我为做图形学的教授很少,没有套磁目标而担忧;另一方面,我又为做图形学的教授很少,可以过滤掉一批做其他方向的教授以逃避发邮件而感到释怀。或许,我所谓“热爱图形学”只是一块遮羞布而已。我害怕前途未卜的未来,我害怕在黑暗中迷失,但我又害怕迈出脚步。我选择图形学,或许只是图形学的教授很少,套磁失败起来很快而已。套磁完所有只做图形学的教授,失败了,我就可以以“我已经努力过了”来安慰自己。、
事实也确实如我所预料得一样,只有一个教授回了我邮件——一封找了一个温柔而拙劣的理由把我拒绝的邮件。我再也不用去套磁了,再也不用忍受发邮件的煎熬了。可是,我所担心的没有去处的未来,正在向我一步一步逼近。
大三下学期,我以“优等生”的姿态活着。
即使是网课,我也认真听着老师的讲解,认真完成着大作业。课余时间,我还继续在本校老师那做一点“科研”。
但是,我在留学上没有任何进展。
以“大三的作业太多”、“回学校后一切就能好起来”为借口,我暂时忘掉了留学这件事,舒服地过了几个月。
2020年年中,特朗普的一纸10043总统令,禁止某些中国高校的学生去美国留学,粉碎了无数学子的留学梦。历史的尘埃,恰恰就砸在了我们学校上。
听到这个消息,我的第一反应不是愤慨,不是焦虑,而是释怀:这下好了,大家都去不了美国了。
虽然我之前一直只打算申请美国的学校,但这个令我规划彻底失效的消息却使我获得了某种程度上的解脱。
是真的解脱了吗?还只是受到巨大打击之后的应激反应呢?
我不知道。
我只知道我必须要做一点什么,一定要迈出脚步。
我不想被无路可走的黑暗吞没。
有人说,这个留学禁令只会持续一年,明年的留学生肯定不受影响。我根本来不及仔细思考,立刻把这个判断奉为真理,继续之前的留学准备。
我一直都在做一点什么。
没有暑研,我就在学期结束后立刻返校,捣鼓我那怎么都没有成果的“科研”。
正式开学后,我立刻开启了托福的准备。
我一直都在做一点什么。
但我真的什么都不想做。
但凡做起和留学相关的事,我就感到无比煎熬。开始做了一会儿后,巨大的负担就压在了我的心上。没办法,我必须要逃避。我的炉石传说酒馆战棋打到了一万多分。
但我还是觉得该做一些什么。
我勉强考出了过线的GRE,快要过线的托福。
我参与了本校教授和国外教授的合作科研项目。两位美国老教授高风亮节,视如己出,言传身教,令我彻底下定决心去读博士。他们虽然颇有名誉,但和我不是一个专业,在留学上给不了我功利性的帮助。即使如此,我依然非常感激他们。
我急匆匆地做好了材料准备,提交了数个学校的博士申请。
12月中旬,我提交完了所有美国学校的申请。
一切都结束了。
我不用再做一些什么了吧?
只申请美国,只申请图形学,只申请博士。
我恐怕根本不是奔着成功留学去的,只是想做什么就做了什么而已。所谓“眼高手低”,大抵如此吧。
我是真的眼高手低吗?
聪明绝顶的我怎么可能没有对自己的一个客观认识。我知道,申请成功的概率微乎其微;我知道,六月之后即迎来“失学”的未来;我知道,我害怕失败,害怕无路可走的绝望。
但是,我更清楚我想要什么,不想要什么。
成功,不是美国顶尖学校的博士录取通知书,不是4.0的绩点,不是110分以上的托福分数,不是330分以上的GRE分数,不是光鲜亮丽的获奖记录,不是琳琅满目的论文发表记录。
成功,不是奖学金获得记录,不是年级第一的成绩,不是饱满的社会工作经历,不是“努力”、“感人”的苦学经历。当然,也不是我唯一能展示出来的,ACM金牌的获得记录。
成功,不是金钱,不是地位,不是权力,不是名誉,不是异性缘,不是房子,不是车子,不是你在哪国生活,不是你的照片多好看,不是你展示出来自己的生活过得有多好。
成功,是:我觉得成功,就是成功。
我觉得,只有做自己喜欢的事情,在自己喜欢的领域做出了令自己满意的成就,才叫成功。
打了三年左右的竞赛,大奖我拿的确实不多。但是,在这段时间里,我过得很开心。我触摸到了灵魂的兴奋点,初次体会到了人生的意义。
我害怕。
我害怕未来。
我害怕上不了学的未来。
我害怕申请失败上不了学的未来。
我害怕因为套磁不够积极导致申请失败上不了学的未来。
我害怕因为方向选得不够多套磁不够积极导致申请失败上不了学的未来。
因此,
我放弃。
我放弃思考。
我放弃人生规划的思考。
我放弃留学相关人生规划的思考。
我放弃寻找更合适的国内研究项目人生规划的思考。
我放弃套磁更多方向的教授寻找更合适的国内研究项目人生规划的思考。
但是,
我坚持。
我坚持底线。
我坚持人生价值的底线。
我坚持不随留学结果变动的人生价值的底线。
我坚持不肯妥协不随留学结果变动的人生价值的底线。
我坚持不肯妥协不随留学结果变动只为自己开心的人生价值的底线。
最终,我任性而顽固地在焦虑中失败了。不过,我也很庆幸,不管我的感受有多么糟糕,我在潜意识里依旧坚持了自己的底线。我没有为了留学而留学,也丝毫没有怀疑过自己对人生目标的判断。
后来,我依然焦急地寻找着出路。
我知道自己为逃避选择而产生的任性是很不合理的。赶在截止日期之前,我去尝试申请了其他国家的学校,尝试申请了可以转成博士的研究型硕士。结果,时间已晚,剩余的机会并不多,我也没有申请成功。
我已经在积累压力和释放压力中循环多次了。写套磁信时积累压力,发邮件时释放压力;申请学校时积累压力,申请季结束后释放压力;等结果时积累压力,收到拒信时释放压力。这就像一个溺水的人,反复挣扎出水面,难得呼吸到一两口新鲜空气一样。那么,收到最后一封拒信时,就是我最后一次能够离开水面了。
但是,我依然没有放弃“生的希望”。或许在很早之前,我就已经在心里默认自己会踏上这条退路了。
这条退路就是gap,去实验室先当科研助理,积累背景,再去申请博士。
gap是一个从国外传来的词,表示毕业后不去上学,而是去玩个一两年。用中文来说的话,gap year可以翻译成“间隔年”。到了国内留学圈,gap的意思就变了。毕业之后,不管你是不是在享受没有学业的人生,只要你没有上学,就可以称为gap。当科研助理,是一种最常见的gap方式。
从大一就开始看留学经验分享的我,很早就知道了gap的存在。通过分析他人的gap经验,我也欣然接受了gap,做好了心理准备。或许我在留学季的种种挣扎,不过是自我欺骗而已。我内心早就放弃了本科直接申请博士。由于有这个底牌的存在,我可以索性破罐子破摔,只去追求小概率的自己想要的结果。
虽说是早就做好了心理准备,但被压力挤得喘不过气的我,还是慢慢吞吞而消极地进行着gap的计划。我本来做好了去一家公司的准备,就没有去找第二个选择了。可是,毕业前我想了解入职事项时,却发现我莫名其妙地被鸽了。
毕业典礼即将到来,我选择享受最后一刻的本科时光,搁置了gap的事。
本科毕业后,作为无业游民的我回到了家里,立刻开始了科研助理的套磁。
和之前的暑研套磁一样,申请科研助理也要用同样的方式发邮件申请岗位。一想起暑研,整个留学过程给我带来的压力的总和就扑面而来。同样,我的心理承受能力只允许我一天只发一两封邮件。
待在家里天天吃干饭,我肯定会被无尽的压力给冲垮。恰巧同学邀请我去毕业旅行,我欣然答应。不知怎地,我就是有一种能在旅游中申请成功的自信。
由于美国的学校都去不了了,现在我只能从其他国家入手。这次,我不再头铁了,从对ACM竞赛认可度最高的华人圈开始申请。同时,由于做图形学的人太少了,我决定扩大范围,也申请计算机视觉方向的研究。计算机视觉我也不讨厌,我会让自己尽快喜欢上这个领域,并且尽可能选择和图形学相关的细分方向。
我认真套了几个香港的教授,杳无音讯。我又看到南洋理工大学在招聘平台上正式招募科研助理,就顺手投了一份简历。正当我为没收到任何回信,准备进一步扩大方向的选择范围时,我申请得最不认真的南洋理工大学竟然向我发出了面试邀请。
说是面试,但这毕竟不是庄重的博士申请。能给科研助理的申请发面试机会,基本上就是决定要你了。我本来还准备了英文ppt和英文演讲腹稿,谁知面试开始后,老师亲切地对我说可以说中文。谈起选择我的理由时,老师说,像我这样有扎实的底层编程基础的人不多,而且我的博客写得很好。在轻松的氛围中,我们聊了聊我过去的经历,敲定了科研助理一事。由于疫情,新加坡签证管得严,我要等半年才能拿到签证。老师帮我先安排了一个和他的实验室有合作的国内工作岗位,就当是为之后的学习打基础。
没想到,这一次,如我所愿地,我在旅行中完成了套磁、科研助理面试、国内工作岗位面试。旅行的时间不短,在享受完旅行后没在家躺几天,我就得动身前往上海办入职了。
七月底,我去上海人工智能实验室的OpenMMLab以全职员工的身份“实习”。也就是说,工资按正式员工的发,但是和实习生一样不待很长时间。大概六个月后,签证就会办好。
总算,我也是从学校迈向社会了。很幸运,OpenMMLab是混沌社会中的一块净土。OpenMMLab主要做的是开源项目,不以业务为导向,没有什么KPI的压力。同时,由于大组刚刚成立不久,同事的素质都很高。全职员工大多是名校硕士,实习生中有名校本科生,也有在读博士的科研大佬。
站在徐汇西岸智塔的高层,俯视着蓝天下的黄浦江,我有一种说不出来的畅快。这样开阔的风景,是矮小的校园里所见不到的。从这里望出去,哪怕是上海交通大学,也不过我眼睛里的一点而已。
公司里见到的,都是年轻的面孔。于其说是同事,倒是更像大学里的同学。可是,多数同事都已经工作多年,早已褪去了学生的稚嫩。从他们口中,听到的更多是人情冷暖。房子、车子、伴侣……尽是些我插不上嘴的话题。
作为工资可观,又随时准备走人的单身程序员,我的日子倒是逍遥得很。可是,同事们比我有更多的可待之物。即使公司的工作环境比其他许多地方都要舒适,他们依然觉得上班养家是一件很不容易的事情。从他们身上,我看到了自己可能的一个未来:我就这样一辈子生活在上海,结婚生子,悠闲度日……
然而,现在安逸的生活让我忘记了本科申请时的所有烦恼。我以前所未有的高效率生活着,对未来的人生也有了更多的期冀。既然看到了校园内看不到的风景,那就要树立本科时想不到的理想。
说是全国最大的开源算法体系,也不过如此嘛。
不然,为什么重构代码库的事情,会让工作时间不过四个月的我来承担呢?
刚到公司时,我确实是懵懵懂懂的。我配开发环境配了一两天,给我开通企业微信又花了一周多,好不容易才安顿下来。
第一次小组会,我是以一个听众的身份参加的。ONNX Runtime、TensorRT、ncnn……这些犹如外星语的名词一个一个蹦出,令唯一一个听众感到战战兢兢:“这么多复杂的技术,我能学得过来吗?”
我们小组负责模型部署代码库的开发。学了一段时间的相关知识后,我发现,模型部署,可是光鲜的“算法”项目中最脏最累的活。对内,我们要对接数个计算机视觉的开源库;对外,我们又要使用数个运行深度学习模型的推理引擎。其他各个代码库之间不一致的地方,就要靠我们来硬生生地焊接起来。
这么琐碎的工作,自然也容易出现纰漏。正在学习我们的代码库时,我发现了一个bug。正好,我决定修复这个bug,作为我对我们组的第一份贡献。
提交代码,必须要使用到代码管理工具。本科时,我只会用傻瓜式的图形界面来使用Git这项代码管理工具。我们是做开源项目的,自然要把代码放到基于Git技术的GitHub开源代码平台上。由于经验不足,我只能在实践中慢慢学习Git的用法。
和组里的同时讨教过后,我修完了bug,并在自己电脑上完成了代码管理。之后,只剩下把代码提交到小组的代码平台,并把我写的那部分代码合入到整个代码库里了。我接下来的操作会改动代码库,一旦出了纰漏,肯定会引起很严重的后果。因此,我小心翼翼地进行着提交代码的操作。
提交完成后,代码库网站上突然出现了一个大大的红叉。这可把我吓坏了。我连忙向同事求救,一面拜托他们快点撤销掉我的操作,一面询问着正确的操作方法。还好,我错误的操作没有什么破坏性。原来,在使用Git和GitHub时,我不能直接向主代码库提交代码,而是应该先向自己克隆出的代码库提交代码。只要按照正确的步骤,重新操作一次就好了。
有惊无险地,我的第一份代码总算合入了整个项目中。虽然代码上的改动只有四五行,但我还是很骄傲地在下次组会上汇报了我的成就。小组领导也在会议记录上欣然记录下了我的这项产出,与其他人涉及上百行代码修改的成果一起。
提交完第一次代码之后,原先像城堡一样复杂的开源代码,在我眼里就成了一排排的破房子。我们的工作,不过是立几根杆子撑住快要倒塌的房子,又去旁边的土地上新建几座房子而已。
从提交几行代码修复小bug,到对接一个视觉算法库,我的贡献度逐渐向其他同事靠拢。几个月后,把略有难度的重构任务交给我,也算是自然而然的事。
为了完成重构,不阻碍他人的工作进度,我高压工作了几天。不过,我倒是不怎么感到疲惫——
我们的代码库要开源了。
2021年的平安夜,上海下着小雨。街头的树上挂着灯饰,点亮了黑夜,也点亮了路旁的积水。街道仿佛笼罩在一片白雪之中,就和人们印象中的圣诞节一样。
到处都是圣诞节的氛围。我从公司楼下的商场走出,一路上看到了不少情侣。恰逢本周最后一个工作日,大家都早早地下班过节。不知怎地,在这种氛围的感染下,我望着天空,感到一丝惆怅。
大概是因为,下周一,我们的项目就要开源了吧。
虽说我们的项目叫做“开源项目”,但是在代码功能尚未齐全的早期,项目是在私有账号下闭源开发的。在基本功能差不多完备了后,大组领导会择一良辰吉日,隆重向世人宣布开源。最后一次开源评审的通过、宣传视频终稿的提交、暂停开发工作后无聊而紧张的查缺补漏……一切都预示着项目开源的到来。
周一的晚上,一切准备就绪。小组的各位都聚在同一台电脑前。
这些代码是属于谁的呢?
作为员工,这些代码应该是属于公司的吧。
作为开源项目,这些代码又应该属于整个开源社区的吧。
但是,此时此刻,这些代码就是只属于我们的作品。
按下确认开源代码库的按钮后,大家纷纷鼓起了掌。
随后,大家不约而同地转发了我们代码库开源的宣传文章。
我想,现在,其他几位同事的感受,应该和我是一样的。
过了几天,仗着OpenMMLab的名气,我们的代码库登上了GitHub Trending榜第一。
之后,我们的身份从纯粹的开发者,变成了时而回答社区问题的客服人员。
再之后,就过年了。
过年回来,没待两周,我就收到了新加坡签证通过的消息。我很快办好了离职。
虽说是离职了,但我也没能立刻就离开上海。我心安理得地放了一周的假,像相恋多年和平分手却又一时不习惯分离的情侣一样,天天在公司里吃了一顿又一顿的散伙饭。
在香港转机时,我们需要在机场就地过夜。
在明亮的大厅里,我睡不着,又想起了同样明亮的那个夜晚。
原来,令我惆怅的,是一月份的到来。从一月往前数六个月,就是由热转凉的七月啊。
到了新加坡后,我很快就熟悉了学校里的生活。
去食堂点菜,刚掏出员工卡时,总有店家会向我确认道:“付款方式是学生卡吧?”我也总是点头默认。
被别人当成学生时,我总会很开心。 或许,我一直向往“学生”般天真烂漫、无拘无束的生活吧。
很幸运,现在,我正享受着这种生活。
我当了十六年学生,一直对众人口中所谓的“学习”嗤之以鼻。没想到,我却在不是学生的今天,体会到了真正的学习:没有家长,没有作业,没有考试,我可以出于热爱,为了自己而学习。在导师的计划下,除了完成实验室的项目外,我的主要任务就是从头认真学一遍深度学习,为以后的科研打下基础。
做着喜欢的事情,朝着理想一步一步迈进,这是我梦寐以求的生活。
没有学业的约束,没有最晚起床时间,能整天都抱着电脑。
其实,我现在有的条件,去年大四时也有。
这一年来,究竟是哪改变了呢?
我想,应该是心境吧。
去年,我一直带着“前途未卜”这项异常状态。
虽说是一直有这么个东西压在心上,可从客观上来看,我大四一年的生活都没受到任何影响。该考试考试,该写论文写论文,该毕业毕业。一切都正常地进行着。
可是,毕业,对没有去处的我来说就像是世界末日一样。仿佛一毕业,一盆水就浇到了我人生的水彩画上,我拥有的一切都将褪色,消逝。我根本不敢考虑之后的事情。
我的感受,完全是自己创造出来的。我惧怕未来,所以给自己创造了一个险恶的心理环境。虽然我想挣扎着逃出,可每一项努力的失败,又在我心中下起了一阵阵暴雨。我在自己给自己设下的绝境中,无法自拔。
我口口声声说着自己不忌惮世俗的眼光,可到头来还是难以免俗。分数、论文数量、录取学校,这些东西都成我心中挥之不去的阴影。
我所谓做好了gap的准备,不过是自欺欺人。连现在的东西都不肯割舍,连未来的方向都不敢主动去寻找。我只是一直在被外界推着前进,而难以自己迈出脚步。
阻碍我的,是我自己的心境。
可是,当时的我真的就有能力去改变自己的心境吗?
做不到的。
当时的我,只能看到那些东西。
从学校到公司不过一个多月,我的心情就大有转变。显然,并不是我聪明了多少,或是坚强了多少。一切,都只是环境变了。
找到出路,不过是让我能够从泥潭中走出。而在半年的实习经验,则洗净了我身上的泥。
人的思考方式不可能在短期改变,能够快速改变的,只有身处的环境。环境的改变,有时更能让人产生思考、心境上的转变。
正是因为见到了从未见过的东西,我才能认识到之前的浅薄。如果当年在学校时,我能够多找一些有相同境遇的人交流,或是提前去社会里看看,又或是暂别学校好好清醒几天,说不定早就能够走出心理上的牢笼。
心境决定了感觉上的好恶,环境又很大程度上影响了心境。
面对心里的险境,一方面要看开一点,在更广的时间和空间上看待目前的处境;另一方面,不必去苛责自己,说不定换一个环境,一切都会好起来。
这世上所有与内心的苦难所斗争的人啊:
你们千万不要气馁。
人的一生,必然是伴随苦难的。小时候,有做不完的假期作业,父母老师的责骂,吓人的期末考试;长大了,有千军万马过独木桥的高考、考研,有毕业后逃不开的就业;再往后,还可能有破产、众叛亲离、疾病缠身。
苦难压得人喘不过气,让人想要逃避。
可是,逃避又有什么错呢?
遭遇苦难,必然是在追求自我超越的路途之中的。敢于去挑战困难,本来就不是一件容易的事。
那么,短暂的逃避,也不过是出于自我保护,为了让干涸的心灵多浸润几滴甘露而已。
真正的勇士,从来都不是一帆风顺的人。有拼搏,有苦难,有逃避,有自责,有前进。这样的人,才称得上是勇敢的。
我想,笼中之鸟,也梦想过展翅翱翔;井底之蛙,也畅想过圆形以外的世界。不论现状多么糟糕,不论视野多么受限,大家都不会放弃对美好的期盼。这时,不妨转换一下环境,调整自己的心境。说不定现在看来天都快塌下来的事情,在未来只是一桩笑谈。
未来,随着我能做到的越来越多,肯定会经历更大的挫折,面对更难的挑战。我也不能保证自己就不会再次陷入心情的低谷中。但是,无论何时,我都会坚持自己的追求。不论是从主观上改变对困难本身的看法,还是改变客观的环境让自己冷静下来,我会用种种手段来摆脱困境。因此,在未来,只会留下更多我战胜困难的事迹。
保研说明会是在大四开学不久后召开的。当时,我连语言考试都没有准备好。说明会一结束,我就回去练听力了。如果能让现在的我给当时的自己带一句话,我会说:
池中寄卧又何妨,风雨之巅尽是晴。
我的评论
我本来是打算取得了某些成就后,再认真总结留学的心得的。恰逢上个月CSDN办了一场征文活动(活动的质量烂得一塌糊涂),我就随手写了一篇人生感想。等我以后确实有成就了,再写一篇有关CS PhD留学的思路指南。
这篇文章的质量很一般。用词还需要多加考究,事情完全贴合实际而少了一些阅读上的趣味,并且很多文字我是以演讲者的视角写的,念起来通顺但不严格符合语法。文章分了几次写完,行文中有不连贯之处。说理时略显僵硬,明明有很多方面的感想,却只能勉强揉成一团表达出来。倒是叙事结构上稍有构想,略微超出了我的平均写作水平。
但是,这篇文章最重要的,是文章内容中传递出来的“我”的心理活动,以及文字写作中传递出来的我的心理活动。这些感受都是很真切的。我觉得这是本文最宝贵的地方。
顺带一提,我是不怎么读书的,文学积累严重不足。为了写本文最后的诗句,我还特意去查一下格律,确保平仄没有写错。这两句话质量如何,我现在评价不了。但还是一样,它们蕴含了我的志气。
写这篇文章,我的主要目的是吹牛,试图收割流量。另外,我也很想把我的经历分享给更多的人。一方面,我知道大部分人都会经历和我类似的境遇,都会体会到孤立无援的感觉,相信这篇文章能给人启发;另一方面,我认为世界上广泛流传的价值观全是错的,我必须去宣传一些能让大家变得更好的思考方式。
希望大家读后能有所收获。