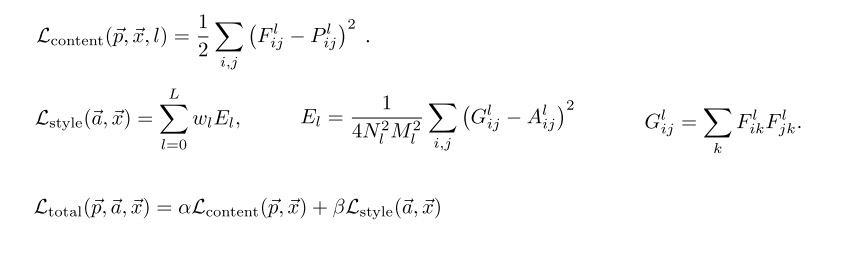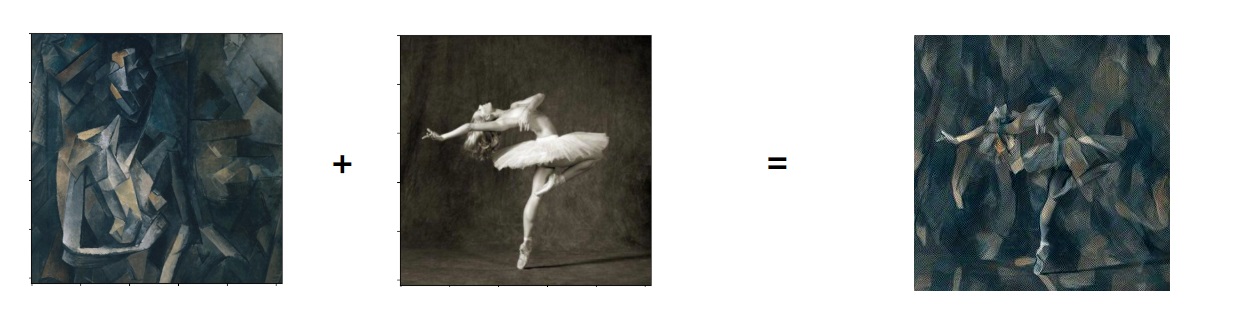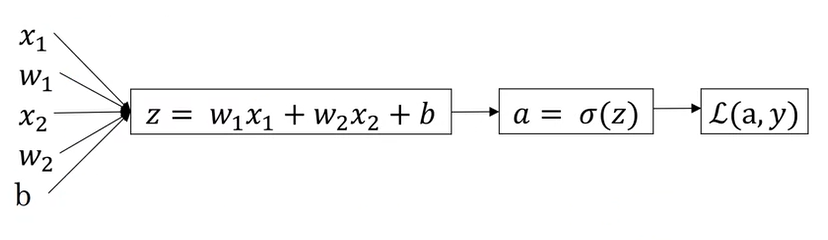for e inrange(total_epoch): for mini_batch_X, mini_batch_Y in mini_batch_XYs: mini_batch_Y_hat = model.forward(mini_batch_X) model.backward(mini_batch_Y) optimizer.zero_grad() optimizer.add_grad(model.get_grad_dict()) optimizer.step()
currrent_epoch = optimizer.epoch
if currrent_epoch % print_interval == 0: # print loss ...
for e inrange(num_epoch): for mini_batch_X, mini_batch_Y in mini_batch_XYs: mini_batch_Y_hat = model.forward(mini_batch_X) model.backward(mini_batch_Y) model.gradient_descent(learning_rate)
defload(self, state_dict: Dict): self.v_dict = state_dict.get('v_dict', None) self.s_dict = state_dict.get('s_dict', None) if self.v_dict isNone: self.v_dict = deepcopy(self.param_dict) for k in self.v_dict: self.v_dict[k] = 0 if self.s_dict isNone: self.s_dict = deepcopy(self.param_dict) for k in self.s_dict: self.s_dict[k] = 0 super().load(state_dict)
defforward(self, X, train_mode=True): if train_mode: self.m = X.shape[1] A = X self.A_cache[0] = A for i inrange(self.num_layer): Z = np.dot(self.W[i], A) + self.b[i] if i == self.num_layer - 1: A = sigmoid(Z) else: A = get_activation_func(self.activation_func[i])(Z) if train_mode and self.dropout and i < self.num_layer - 1: keep_prob = 0.5 d = np.random.rand(*A.shape) < keep_prob A = A * d / keep_prob if train_mode: self.Z_cache[i] = Z self.A_cache[i + 1] = A
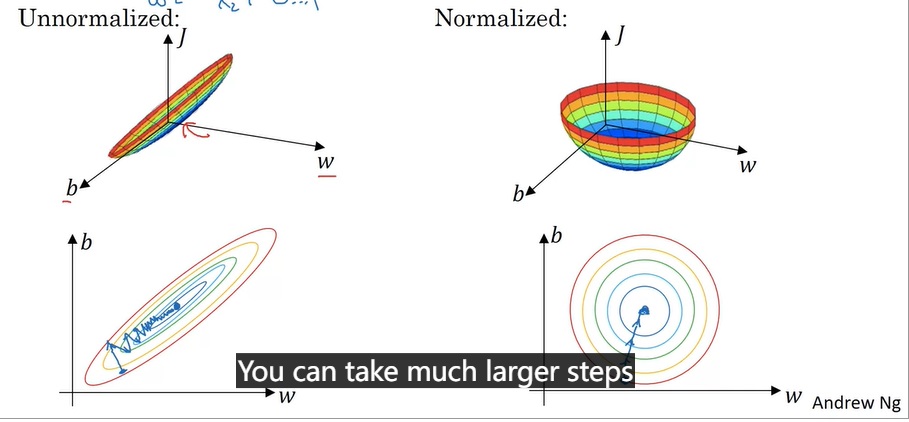
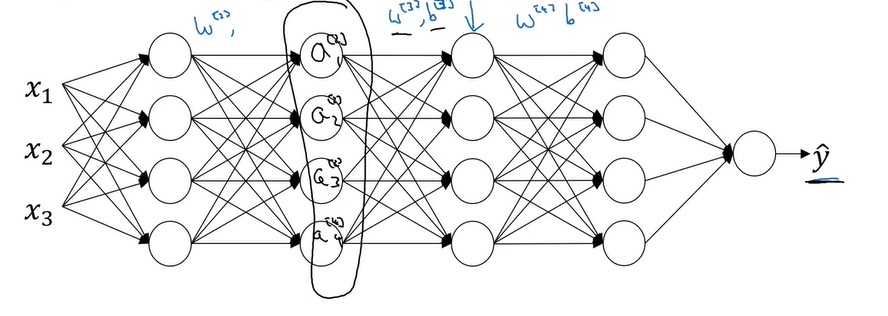
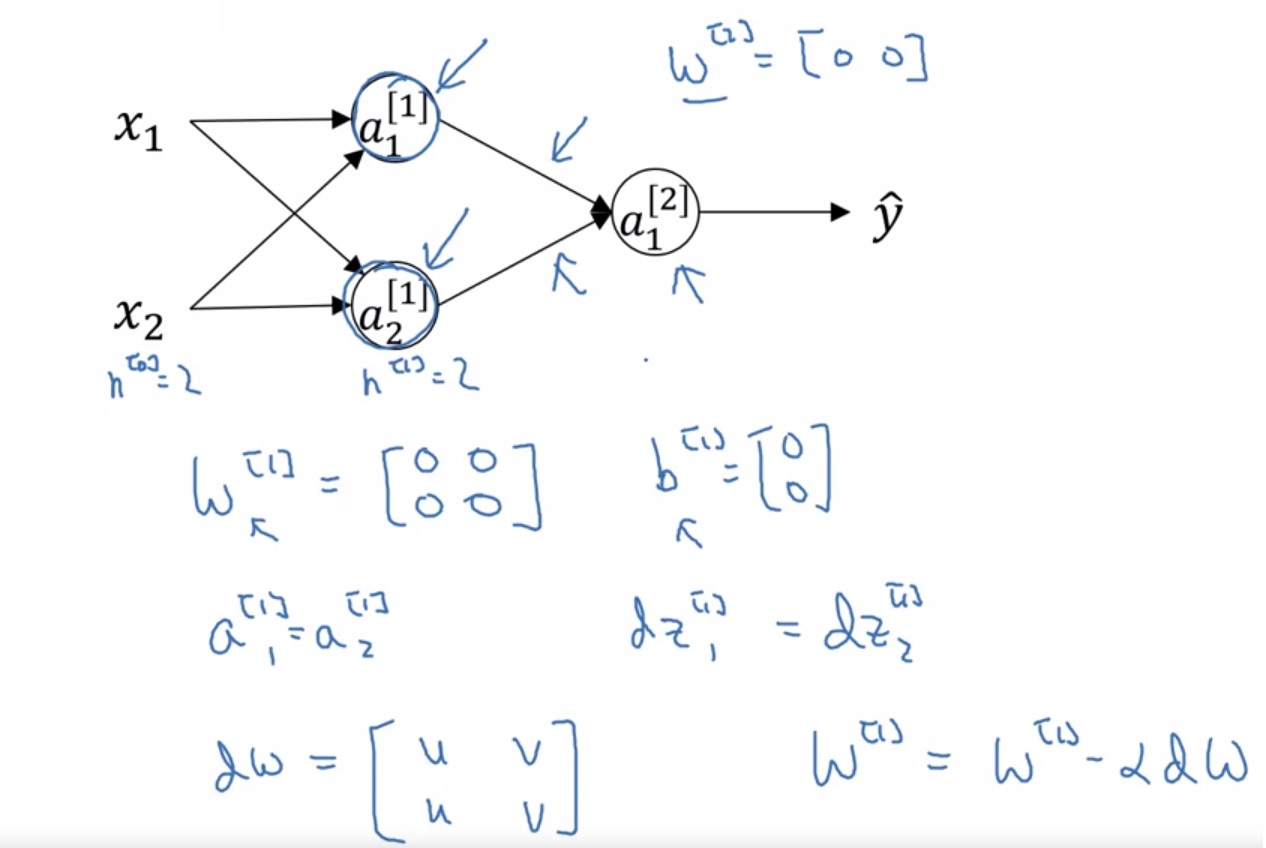
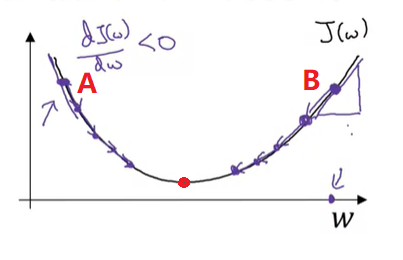
梯度下降:对于每个参数$p = w^{[l]} or b^{[l]}$,用$p := p-\alpha dp$更新参数。其中$\alpha$叫学习率,表示参数更新的速度。
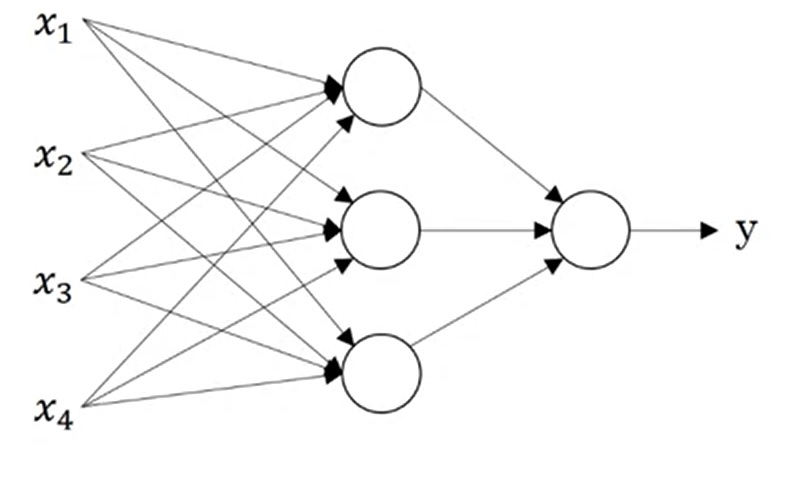
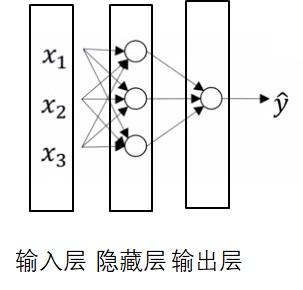
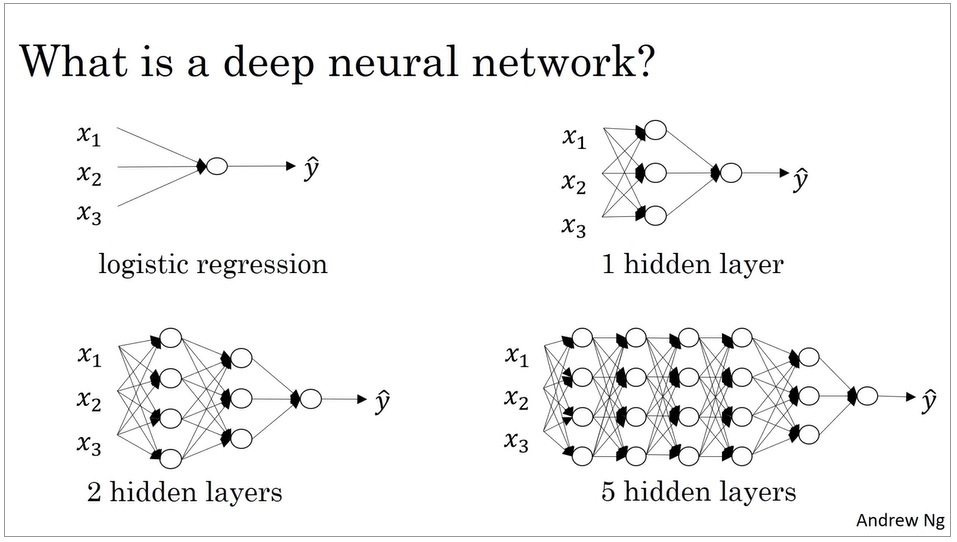
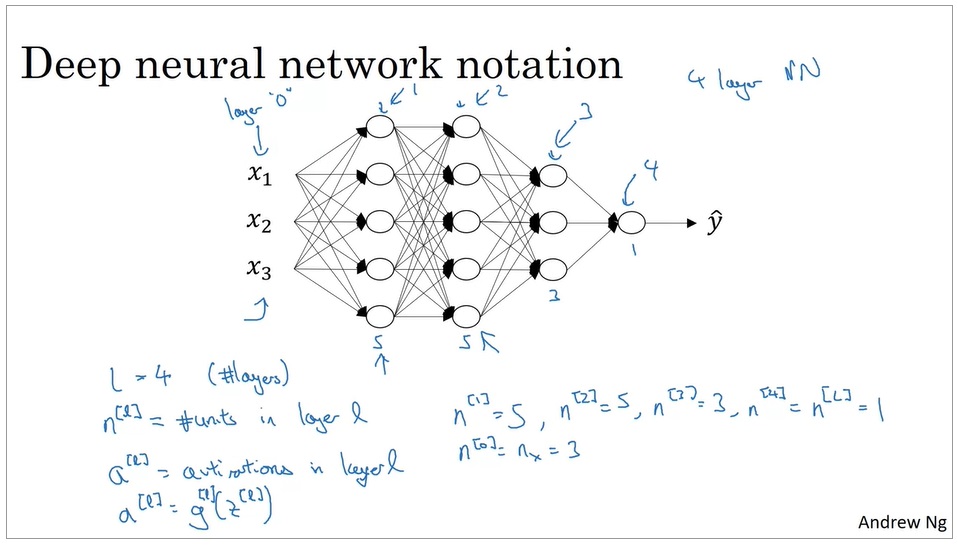
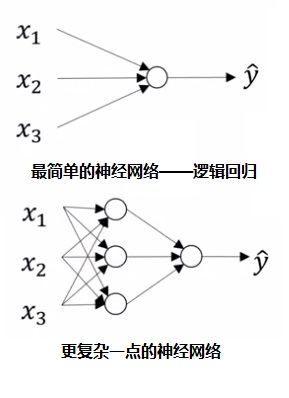
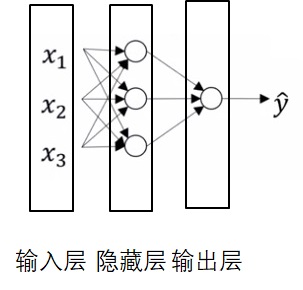
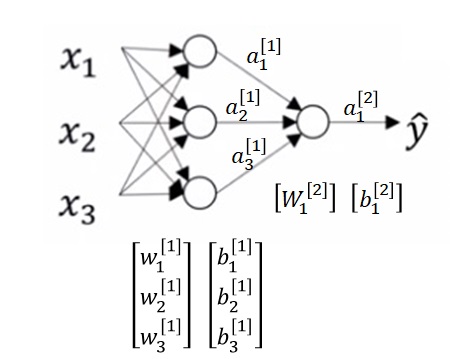
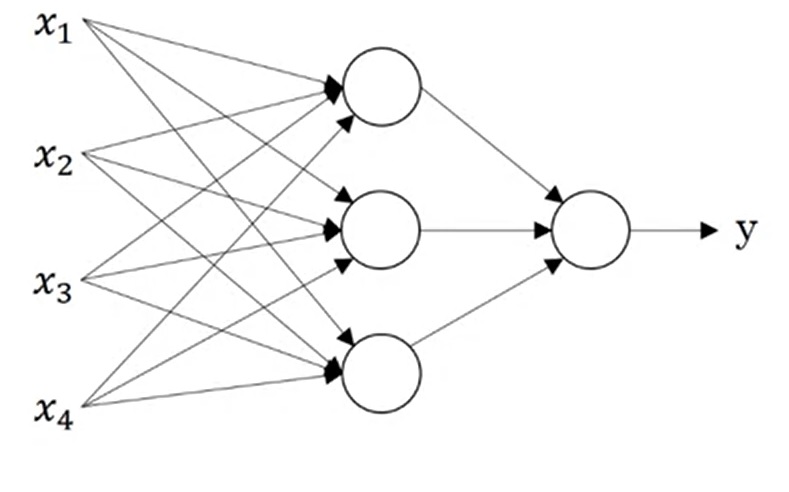
用numpy实现神经网络
把输入图片进行“压平”操作:
1
images = np.reshape(images, (-1))
初始化参数
1 2
W = np.random.randn(neuron_cnt[i + 1], neuron_cnt[i]) * 0.01 b = np.zeros((neuron_cnt[i + 1], 1))
前向传播
1 2 3 4 5 6 7
self.A_cache[0] = A for i inrange(self.num_layer): Z = np.dot(self.W[i], A) + self.b[i] A = get_activation_func(self.activation_func[i])(Z) if train_mode: self.Z_cache[i] = Z self.A_cache[i + 1] = A
反向传播
1 2 3 4 5 6 7 8
for i inrange(self.num_layer - 1, -1, -1): dZ = dA * get_activation_de_func(self.activation_func[i])( self.Z_cache[i]) dW = np.dot(dZ, self.A_cache[i].T) / self.m db = np.mean(dZ, axis=1, keepdims=True) dA = np.dot(self.W[i].T, dZ) self.dW_cache[i] = dW self.db_cache[i] = db
梯度下降
1 2 3
for i inrange(self.num_layer): self.W[i] -= learning_rate * self.dW_cache[i] self.b[i] -= learning_rate * self.db_cache[i]
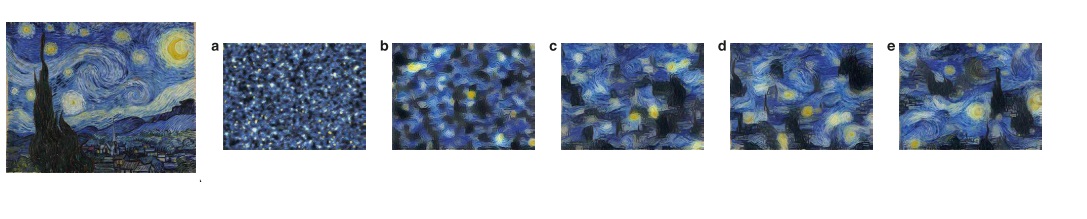
[1] Gatys L A, Ecker A S, Bethge M. Image style transfer using convolutional neural networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 2414-2423.
[2] Gatys L, Ecker A S, Bethge M. Texture synthesis using convolutional neural networks[J]. Advances in neural information processing systems, 2015, 28.
import torch import torch.nn.functional as F import torch.optim as optim import torchvision.models as models import torchvision.transforms as transforms from PIL import Image
defclosure(): with torch.no_grad(): input_img.clamp_(0, 1) global steps global prev_loss optimizer.zero_grad() model(input_img) content_loss = 0 style_loss = 0 for l in content_losses: content_loss += l.loss for l in style_losses: style_loss += l.loss loss = content_weight * content_loss + style_weight * style_loss loss.backward() steps += 1 if steps % 50 == 0: print(f'Step {steps}:') print(f'Loss: {loss}') # Open next line to save intermediate result # save_image(input_img, f'work_dirs/output_{steps}.jpg') prev_loss = loss return loss
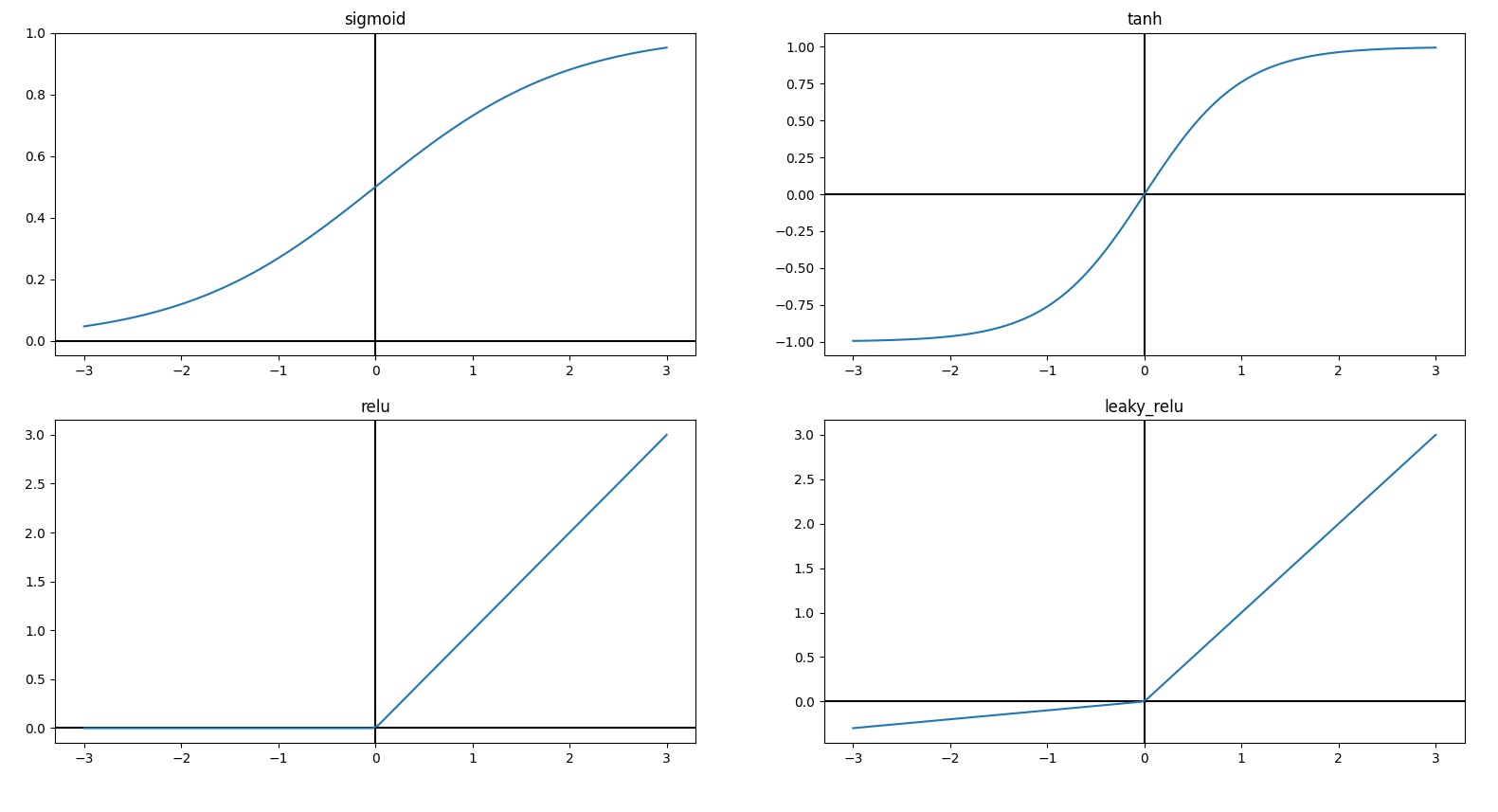
defget_activation_func(name): if name == 'sigmoid': return sigmoid elif name == 'relu': return relu else: raise KeyError(f'No such activavtion function {name}')
defget_activation_de_func(name): if name == 'sigmoid': return sigmoid_de elif name == 'relu': return relu_de else: raise KeyError(f'No such activavtion function {name}')
defforward(self, X, train_mode=True): if train_mode: self.m = X.shape[1] A = X self.A_cache[0] = A for i inrange(self.num_layer): Z = np.dot(self.W[i], A) + self.b[i] A = get_activation_func(self.activation_func[i])(Z) if train_mode: self.Z_cache[i] = Z self.A_cache[i + 1] = A return A
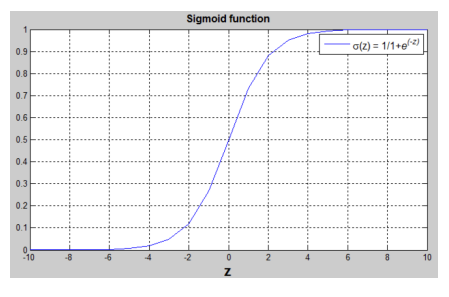
defforward(self, X, train_mode=True): Z = np.dot(self.w.T, X) + self.b A = sigmoid(Z) # hat_Y = A if train_mode: self.m_cache = X.shape[1] self.X_cache = X self.A_cache = A return A
对计算机知识有所了解的人会知道,在计算机中,颜色主要是通过RGB(红绿蓝)三种颜色通道表示。每一种通道一般用长度8位的整数表示,即用一个0~255的数表示某颜色在红、绿、蓝上的深浅程度。这样,一个颜色就可以用一个长度为3的向量表示。一幅图像,其实就是许多颜色的集合,即许多长度为3的向量的集合。颜色通道,再算上某颜色所在像素的位置$(x, y)$,图像就可以看成一个3维张量$I \in \mathcal{R}^{H \times W \times 3}$,其中$H$是图像高度,$W$是图像宽度,$3$是图像的通道数。在把图像输入逻辑回归时,我们会把图像“拉直”成一个一维向量。这个向量就是前面提到的网络输入$x$,其中$x$的长度$n_x$满足$n_x = H \times W \times 3$。这里的“拉直”操作就是把张量里的数据按照顺序一个一个填入新的一维向量中。
deftrain_step(w, b, X, Y, lr): m = X.shape[1] Z = np.dot(w.T, X) + b A = sigmoid(Z) d_Z = A - Y d_w = np.dot(X, d_Z.T) / m d_b = np.mean(d_Z) return w - lr * d_w, b - lr * d_b
在这段代码中,我们根据前面算好的公式,算出了w, b的梯度并对w, b进行更新。
训练
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
definit_weights(n_x=224 * 224 * 3): w = np.zeros((n_x, 1)) b = 0.0 return w, b deftrain(train_X, train_Y, step=1000, learning_rate=0.00001): w, b = init_weights() print(f'learning rate: {learning_rate}') for i inrange(step): w, b = train_step(w, b, train_X, train_Y, learning_rate)
# 输出当前训练进度 if i % 10 == 0: y_hat = predict(w, b, train_X) ls = loss(y_hat, train_Y) print(f'step {i} loss: {ls}') return w, b