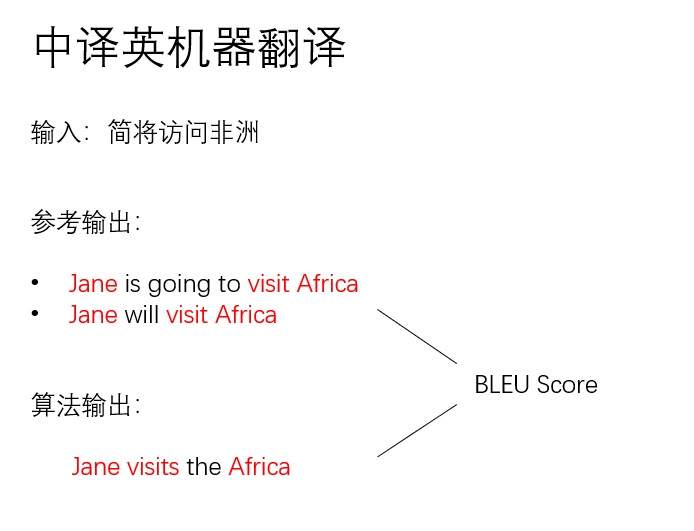
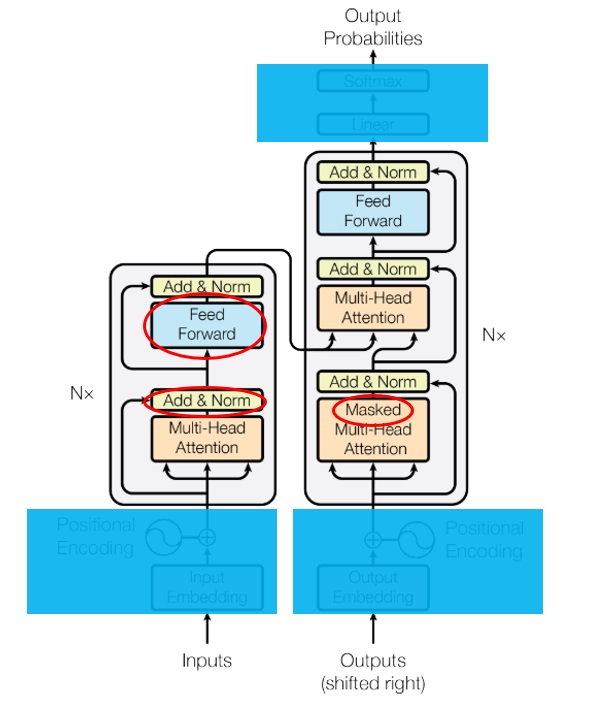
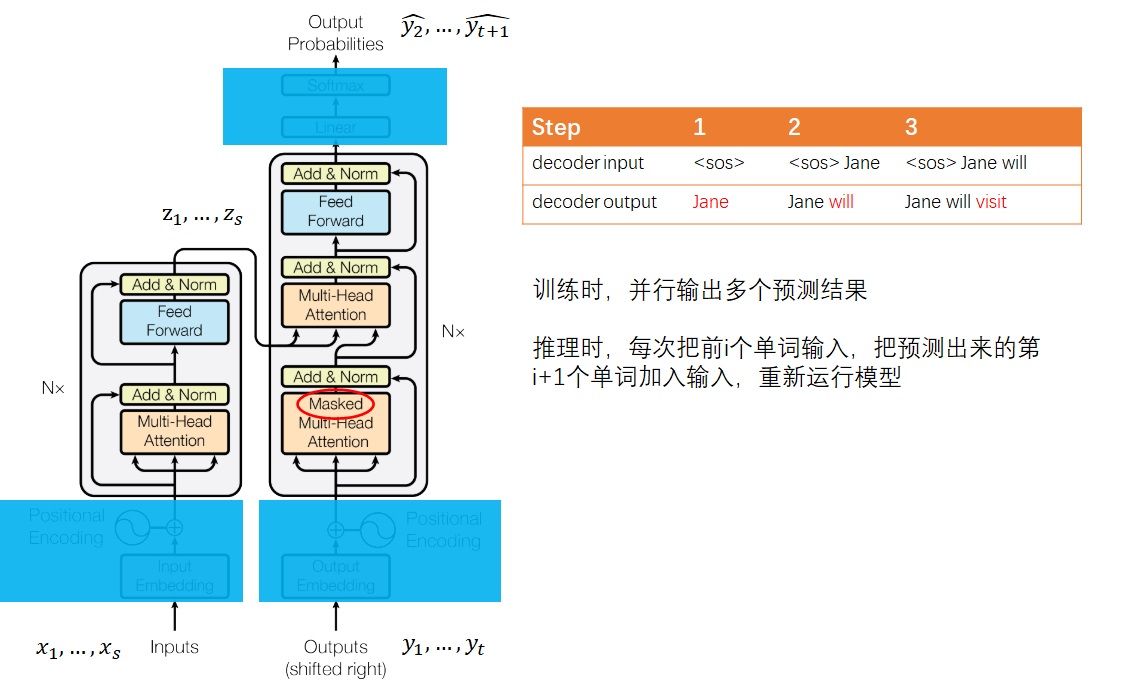
最近,我在考托福。第一次考完,我惊讶地发现我的听力只有19分(满分30)。我两年前考的成绩都不止这么一点。这两年我也一直在接触英语,英语水平不可能退步。如果托福真的是一个合理的,能够反映考生真实水平的考试,那我不可能考出差别这么大的分数。因此,我认为,考出这么差的分数,不是我的问题,是托福考试的问题。托福考试过分强调应试技巧,而无法稳定地反映我的水平。为了证明我的观点,我不服气地宣誓道:「我要用一周时间,学习听力应试技巧,考出一个较高的听力分数。」一周后,我又考了一次托福。结果很喜人,我的听力考了27分。
在这几天里,我总结了网上的托福听力准备方法,用一套规范的算法流程把方法表达了出来。我将分享一下这一套和深度学习算法形式相似的托福听力准备方法。我会从头把方法的背景、解决方法讲清楚。哪怕你不需要准备托福考试,或者说对深度学习没那么了解,也可以把这篇文章当故事读一遍。
托福听力规则
托福听力主要涉及两类材料:对话与讲座。对话通常发生在学生与教授或学校工作人员之间,描述了校园中常见的一些讨论、询问。讲座则模拟了真实的课堂教学,讲师会对某一专业话题做简要的描述,偶尔会穿插几句学生的提问。讲座涉及的知识面很广,常常会谈及艺术、历史、生物学、地理学、心理学等领域。不过,这些讲座不会讲特别深入的内容,也不会讲过于偏离生活的概念,保证多数人都能听懂讲座的内容。
一场无加试的托福听力由两轮组成。每轮会听1段对话和1~2段讲座。对话有5题,讲座有6题。
托福听力的答题形式和国内多数英语考试不同。每段听力中,考生只有听完了听力材料后,才能看到题目。并且,只有确认提交了前一题才能答下一题。当然,可以在听的同时记笔记。
题目全是选择题。每段听力材料给3~4分钟,基本不会有时间不够的情况出现。
托福这种不允许提前看题的考试模式把考生的记忆力也变成了考察目标之一,为考试增添了不合理的难度。后续算法的诸多改进都是为了解决「记不住」这一问题。
托福应试流程
大多数人在初次接触托福听力时都会采用这一套非常直观的算法:
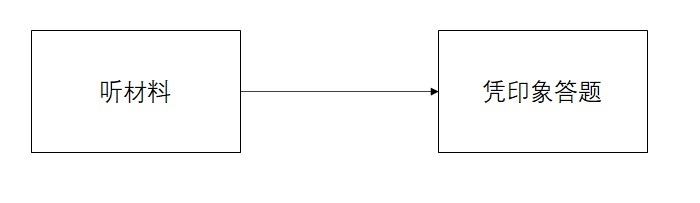
但是,这套算法有一个问题:无论我们的听力水平多么优秀,都不可能把材料原原本本地记忆下来。一旦有题目考察了一个我们没记住的地方,这道题就答不上来了。
因此,多数托福教程会给出一套改进的算法。这套算法把「听材料」细分成了两部分。第一部分是「语音转文字」,这是我们大脑自己训练出来的功能。理解了听力材料的内容后,我们根据一些先验知识(知道听力材料的哪些部分容易出考题),对部分内容做重点记忆。重点记忆的方法可以是竖起耳朵集中注意力,也可以是用笔记记录关键词。最后,根据重点记忆的内容和大脑中残留的其他记忆,回答问题。

这套算法出色地把托福听力分成了三个独立的子任务:语音识别、记忆、阅读理解。这三个子任务恰好对应了三种要考察的能力:听力能力、记忆能力、理解能力。把这三种能力拆开来讨论是很有必要的。如果你没有意识到自己哪种能力相对相差,盲目地做题,尝试同时提升这三项能力,那你的学习是十分低效的。后文我们将基于这一套算法讨论如何分别提升这三种能力。
错因分析
在正式开始学习之前,我们一定要诊断出自己哪方面的能力有所缺失,进而对症下药,从最差的一项开始练习。为了找出做听力的问题,我们要进行错因分析。
为了考察听力、记忆、理解这三种能力,我们固然可以用做托福听力题以外的方式去分别测试这三种能力。但是,使用其他测试方式的话,我们不能保证我们测试出来的能力恰好是托福考试要求的能力。比如,你可以拿托福阅读来测试自己的理解能力。但是,由于托福阅读的理解难度比听力的理解难度要大,哪怕你阅读做得不好,也不能说明你听力就理解不好。因此,做托福听力题这件事本身就是最好的测试方式。
可是,正如前文所述,做托福听力会同时考察三种能力。该怎么分别考察这三种能力呢?其实,使用一些巧妙的控制变量法,就可以把这些能力区分出来了。我把网上提出的各种错因分析方法加以总结融合,提出了一种「反掩码错因分析」法。
什么是「反掩码」呢?众所周知,掩码 (mask),指的是计算机中用于屏蔽其他数据的一种数据,有时也泛指屏蔽数据这一过程。那么,我提出的「反掩码」,指的就是把原本不透明的数据变得透明。
在托福听力中,听力材料是不透明的。你需要通过自己的听力能力把听力材料变成可理解的文字。如果直接把听力材料变成了阅读材料,你就可以直接根据听力原文答题。这样,做题考察的就只有理解能力,而不再考察听力和记忆能力了。
因此,为了考察自己的理解能力。可以先听一遍材料,做题,不看答案,读一遍原文,再做题。第一遍做题是正常的练习,第二次做题是控制变量。如果第二次做题还是错了很多,就说明理解能力不行;如果第一遍做题相较第二遍错了很多,就说明听力和记忆存在问题。
同理,为了进一步区分听力和记忆的问题,我们可以调整反掩码,使用更精妙的控制变量方式:先听一遍材料,做题,不看答案,再听一遍材料,再做题。在第二次听力的时候,你已经知道题目了,不存在记不住的问题。如果第二遍答题还是错了很多,就说明听力和理解有问题;如果第一遍相较第二遍错了很多,就说明记忆有问题。当然,如果你的理解已经基本没问题了,在这一步就可以排除掉理解能力的影响,直接区分听力问题和记忆问题。
综上,「反掩码错因分析」的流程如下:
- 找出几套听力题。先听一遍材料,做题,不看答案,读一遍原文,再做题。主要分析自己的理解是否存在问题。
- 理解能力最容易提升。先想办法提升理解能力。
- 再找出几套听力题。先听一遍材料,做题,不看答案,再听一遍材料,再做题。区分听力问题和记忆问题。
- 根据诊断结果,先后提升听力问题和记忆问题。
能力提升
诊断出了问题后。就应该考虑如何设计子任务分别训练这三种能力了。
听力能力
使用听力能力时,输入是英语音频,输出是大脑中可理解的英文文字。这一过程完全由大脑的本能决定,几乎不需要主观思考。因此,我们可以设计一个非常直接的子任务:使用任意一种英语音频,一边听,一边「输出」自己的听到的文字。听完音频后,比较自己的输出和原文,看看自己哪些地方没听懂。不断反思,让大脑自己提升。
网上的很多托福听力攻略会叫你去「精听」,「听写」,或者使用什么「影子跟读法」。其实,所有这些方法都只是为了提升听力水平。他们的目的都是构造一个输入音频输出文字的训练任务。只是「输出」的方式不同而已。在我看来,输出文字的方式,可以是复述,可以是听写,甚至不用讲出来,在大脑里有个印象就行。所有这些具体的方法里,我不推荐听写法,因为你大量的学习时间都会浪费在写单词上。听完一句话后,复述这句话即可。至于是一句话反复听,还是听完一整段材料,这些形式都不重要。保证你在强迫自己不断输出听到的内容即可。
另外,与其纠结听力练习的具体方法,不如去花一点时间准备恰当的听力材料。对于有高考英语听力水平的人,直接拿托福官方题目(TPO)的听力材料练就可以,类似于TED的知识分享、新闻播报也可以。看电视剧的提升可能没那么快,因为电视剧的语速较快,且通常只有日常用语,与托福听力材料的内容不符。我个人推荐去上自己专业的英文公开课,比如大名鼎鼎的「MIT线性代数」。这些公开课语速适中,用语朴素,比较容易听懂,形式与托福听力类似,还可以顺便学一下专业知识。
记忆能力
托福听力考试的记忆分两类:第一类是被动记忆,也就是你听完整段材料后自然残留在大脑里的记忆;另一类是主动记忆,是你根据以往的答题经验,对材料中你认为的重点段落的记忆(或者笔记)。被动记忆我们没法操控,只能祈求考试当天头脑清醒一点。因此,练习记忆时,主要是练习托福听力应试技巧,提高对出题点的灵敏度,并且做到在不影响听力的情况下记下笔记。
在培训班或者网上,都能找到大量的托福听力技巧。这些技巧告诉你什么地方容易出题,听到哪些词的时候做笔记之类的。但是,我觉得背技巧的效率是很低的。最好的方式是,自己去尝试发现技巧,有了一定的经验后再去和别人的技巧对比。
那么,怎么去学会洞察听力材料的出题点呢?有两个方面的事要做。一方面,做完了题目后,总结归纳常见题型,并且找题目对应的原文,总结规律;另一方面,在听材料时,多做一点笔记,做题时看看哪些笔记用到了,哪些没有。甚至,对于以前练过的材料,可以直接跳过听力,读原文,猜出题点。通过正向和反向的练习,很快就能掌握技巧。
作为示例,我来分享几个我发现的技巧。
- 对话材料90%会问对话发起的原因是什么。注意,这道题不是问整段对话的主题是什么,而是问学生为什么找老师或老师为什么找学生。很可能两个人寒暄了老半天,学生突然支支吾吾地说出自己过来的原因,然后话题一下就飞走了。如果你没有预判出题点,很可能这一句话就被你忽略了。
- 讲座有时会先讲理论,再讲示例。题目会问这个示例是揭示哪个理论。如果示例里恰好冒出两个专有名词,你又不知道这里会出题,这个例子就会被你忘掉了。因此,听到示例,赶快把示例里涉及的几个名词记下来。
- 讲座中,老师和学生都可能会表达对于某一理论的态度。尤其是结尾,老师很可能冷不丁地说「虽然这个理论很有名,但我并不是很认可」。题目很喜欢考这些态度。你可能辛辛苦苦听了4分钟的材料,想着听力要结束了,可以放松一下了。结果最后这两句很重要的态度就被你忽略了。
找到材料中的出题点,其实只是比较初级的技巧。如果你想成为高手,还有一种高阶的,更一般的方法。我把它称之为「基于注意力的记忆法」。听力材料,甚至是阅读材料,以及我们生活中各种各样的文字讯息,都是有很多废话的。如果你知道哪些话言之无物,你就可以过滤掉这些话,而集中记忆那些有意义的话。更进一步,如果你知道听力中哪些话一定不会出题,那么这些话也可以过滤掉。你可以只把注意力集中在哪些容易出题的有意义的话上。
比如说,老师讲「好久不见」、「我们上节课讲了什么什么,但是这节课……」。这些话都可以直接当成废话忽略掉。讲座时提到某个名人出生于何处,几几年在哪上学,这种过于细节的地方也不可能出题,可以忽略掉。
这种基于注意力的记忆法是很有用的。一来,它可以帮你找到重点和非重点的话,有助于合理安排精力;二来,在知道这句话不重要时,可以放心地去记上一句话的笔记。
这种记忆法不用刻意训练,多听了几段材料后就能自然地知道听力材料中哪些地方是可以忽略的。
理解能力
托福听力中的理解,既包括对材料的理解,也包含对题目和选项的理解。整体来说,托福听力对理解的要求不高。只要清楚地听懂了材料,做题时一般不会因为理解而扣分。
材料理解比较简单。只有介绍一个复杂的理科概念,或者人物表明态度时过于委婉,才可能导致材料理解错误。只要把托福阅读题练好,听力材料不可能有理解问题。
理解题目、选项时则可能会碰到一些问题。比如在主旨题中,每一个选项概括主旨都概括得不是很确切,但是其中三个选项有明显错误,一个选项概括得不全。这个时候,得选择那个概括得不全的选项。为了解决这个问题,只需要多做点题,总结记录选项理解错误导致的错题,很快避开常见的一些坑。另外,听力的时间非常充足,碰到模棱两可的选项时可以多读两遍题,千万不要把题目读错。
综合练习
TPO 30之前的题都比较简单,可以拿这些题目来反复训练各个子能力。预训练好了大脑中的各个子模块后,就可以直接开始做TPO 30之后的题,进一步综合训练所有能力。
综合练习时,应按照正常的应试流程,一边听材料,一边做笔记。听完了材料就做题,对答案。有题目做错了,大致把错因归个类,看看是三步中哪一步出了问题。根据错题的情况做进一步的查缺补漏。
在评估自己的综合练习水平时,除了对答案,还需要反思两件事:材料中的哪几句话没有听清;笔记是否记下了重要信息。
很多时候,你可能听漏了某几句话,但依然把题目都做对了。但这样并不保险,最好是把每一句话都理解透来,保证听力能力没有问题。
哪怕你已经熟悉了材料中的出题点,依然需要练习一下记笔记的方法。首先,你要保证记笔记的时机合理,不能影响听力。其次,你要保证重要的信息没有记漏。在不影响听力的前提下,多记笔记是没有坏处的。因此,反思时,只需要评估哪些题目中考察的信息是漏记的,尤其是哪些导致你做题出错的漏记的信息。
最后,再总结一下各种能力在托福听力中的重要性。理解能力是必须的,也是难度最低的。一定要把理解能力练到满分。听力能力是答题的基础,是托福听力题的主要考察对象。听力能力是最考验基本功,最难在短期提升的,一定要早做准备。记忆能力是把听力能力转换成分数的必备途径,你可能文章听得津津有味,答题时却头脑发昏。记忆能力最好提升,几天内就可以总结套路,掌握记忆关键信息的方法。
方法总结
我们来把这篇文章讲过的托福听力准备方法和应试方法整理一下。
准备考试:
- 做几套TPO听力,使用分析错因,找出自己较弱的能力。分析错因时,先听一遍,做题,然后在不看答案的前提下再听一遍或看一遍原文,排除出做题出错的原因。
- 从较弱的能力开始,逐个提升提升能力。
- 练得差不多了以后,综合练习,查缺补漏,同时练习应试的状态与技巧。
考试时:
- 听语音,在脑中把语音变成文字,判断这句话有没有重要信息。
- 如果觉得这句话很重要,就着重记在脑子里,或者用笔记记下。对话可以少记或不记笔记。讲座必须记下关键信息,比如举例、分类讨论、态度之类的。
- 根据笔记或印象答题。
托福听力题本质上还是在考察听力能力。如果你听力的基础不好,还是要把主要的时间花在打基础上。等听力水平差不多了,可以按照这篇文章介绍的内容,学习一些技巧,把听力能力转换成分数。希望大家能够考出一个不错的托福分数。
附录:托福听力框架图