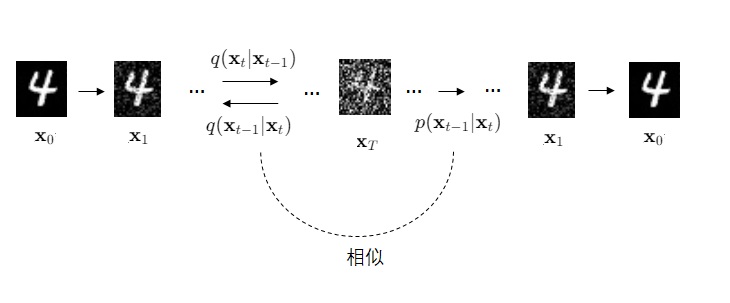
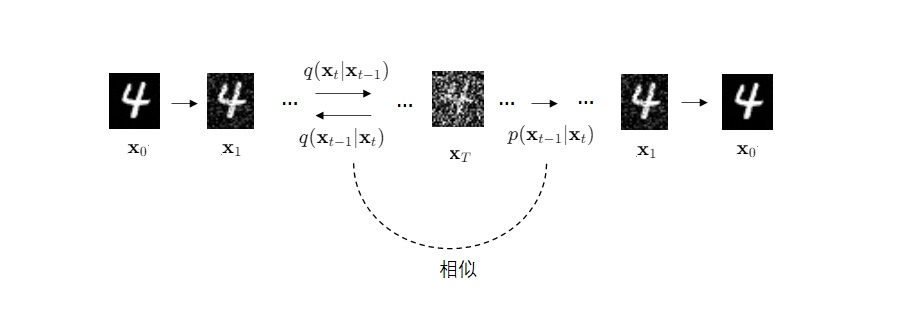
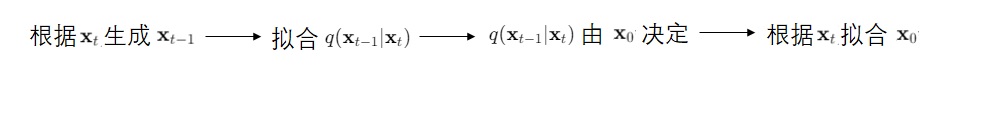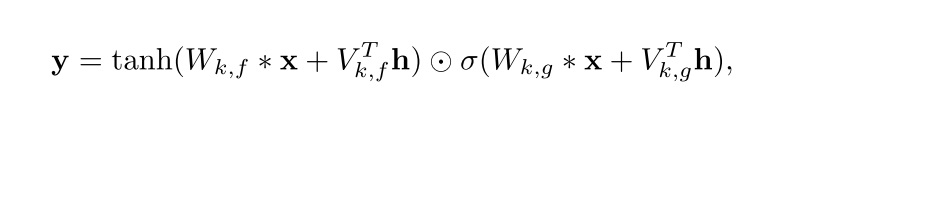Deep Unsupervised Learning using Nonequilibrium Thermodynamics: https://arxiv.org/abs/1503.03585 DDPM的前作,首个提出扩散模型思想的文章。其核心原理和DDPM几乎完全一致,但是模型结构和优化目标不够先进,生成效果没有改进后的DDPM好。数学公式较多,不必细读,可以在学习DDPM时对比着阅读。
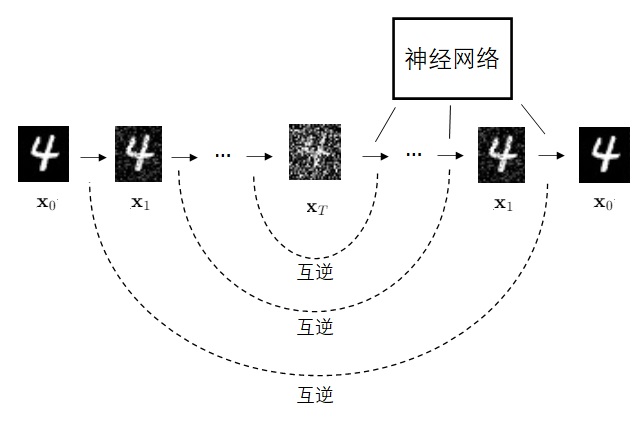
defsample_backward(self, img_or_shape, net, device, simple_var=True): ifisinstance(img_or_shape, torch.Tensor): x = img_or_shape else: x = torch.randn(img_or_shape).to(device) net = net.to(device) for t in tqdm(range(self.n_steps - 1, -1, -1), "DDPM sampling"): x = self.sample_backward_step(x, t, net, simple_var)
img_list = einops.rearrange(imgs, 'n c h w -> n h w c').numpy() output_dir = os.path.splitext(output_path)[0] os.makedirs(output_dir, exist_ok=True) for i, img inenumerate(img_list): if to_bgr: img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR) cv2.imwrite(f'{output_dir}/{i+index}.jpg', img)
# First iteration if index == 0: imgs = einops.rearrange(imgs, '(b1 b2) c h w -> (b1 h) (b2 w) c', b1=int(batch_size**0.5)) imgs = imgs.numpy() if to_bgr: imgs = cv2.cvtColor(imgs, cv2.COLOR_RGB2BGR) cv2.imwrite(output_path, imgs)
defsample_backward(self, img_shape, net, device, simple_var=True): x = torch.randn(img_shape).to(device) net = net.to(device) for t inrange(self.n_steps - 1, -1, -1): x = self.sample_backward_step(x, t, net, simple_var) return x
defsample_backward_step(self, x_t, t, net, simple_var=True): n = x_t.shape[0] t_tensor = torch.tensor([t] * n, dtype=torch.long).to(x_t.device).unsqueeze(1) eps = net(x_t, t_tensor)
if t == 0: noise = 0 else: if simple_var: var = self.betas[t] else: var = (1 - self.alpha_bars[t - 1]) / ( 1 - self.alpha_bars[t]) * self.betas[t] noise = torch.randn_like(x_t) noise *= torch.sqrt(var)
mean = (x_t - (1 - self.alphas[t]) / torch.sqrt(1 - self.alpha_bars[t]) * eps) / torch.sqrt(self.alphas[t]) x_t = mean + noise
defsample_backward(self, img_shape, net, device, simple_var=True): x = torch.randn(img_shape).to(device) net = net.to(device) for t inrange(self.n_steps - 1, -1, -1): x = self.sample_backward_step(x, t, net, simple_var) return x
import torch import torch.nn as nn from dldemos.ddpm.dataset import get_dataloader, get_img_shape from dldemos.ddpm.ddpm import DDPM import cv2 import numpy as np import einops
batch_size = 512 n_epochs = 100
deftrain(ddpm: DDPM, net, device, ckpt_path): # n_steps 就是公式里的 T # net 是某个继承自 torch.nn.Module 的神经网络 n_steps = ddpm.n_steps dataloader = get_dataloader(batch_size) net = net.to(device) loss_fn = nn.MSELoss() optimizer = torch.optim.Adam(net.parameters(), 1e-3)
for e inrange(n_epochs): for x, _ in dataloader: current_batch_size = x.shape[0] x = x.to(device) t = torch.randint(0, n_steps, (current_batch_size, )).to(device) eps = torch.randn_like(x).to(device) x_t = ddpm.sample_forward(x, t, eps) eps_theta = net(x_t, t.reshape(current_batch_size, 1)) loss = loss_fn(eps_theta, eps) optimizer.zero_grad() loss.backward() optimizer.step() torch.save(net.state_dict(), ckpt_path)
for x, _ in dataloader: current_batch_size = x.shape[0] x = x.to(device) t = torch.randint(0, n_steps, (current_batch_size, )).to(device) eps = torch.randn_like(x).to(device)
defforward(self, input): x = self.conv1(input) x = self.bn1(x) x = self.actvation1(x) x = self.conv2(x) x = self.bn2(x) x += self.shortcut(input) x = self.actvation2(x) return x
self.residual_blocks = nn.ModuleList() prev_channel = C for channel in intermediate_channels: self.residual_blocks.append(ResidualBlock(prev_channel, channel)) if insert_t_to_all_layers: self.pe_linears.append(nn.Linear(pe_dim, prev_channel)) else: self.pe_linears.append(None) prev_channel = channel self.output_layer = nn.Conv2d(prev_channel, C, 3, 1, 1)
defforward(self, x, t): n = t.shape[0] t = self.pe(t) for m_x, m_t inzip(self.residual_blocks, self.pe_linears): if m_t isnotNone: pe = m_t(t).reshape(n, -1, 1, 1) x = x + pe x = m_x(x) x = self.output_layer(x) return x
defforward(self, x): out = self.ln(x) out = self.conv1(out) out = self.activation(out) out = self.conv2(out) ifself.residual: out += self.residual_conv(x) out = self.activation(out) return out
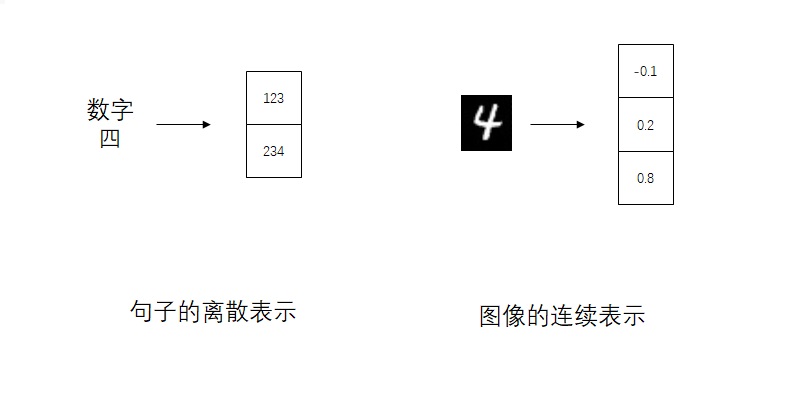
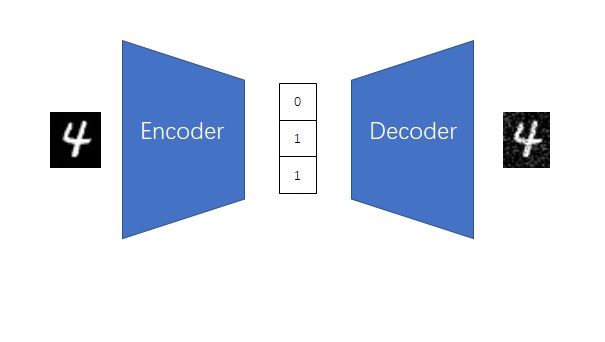
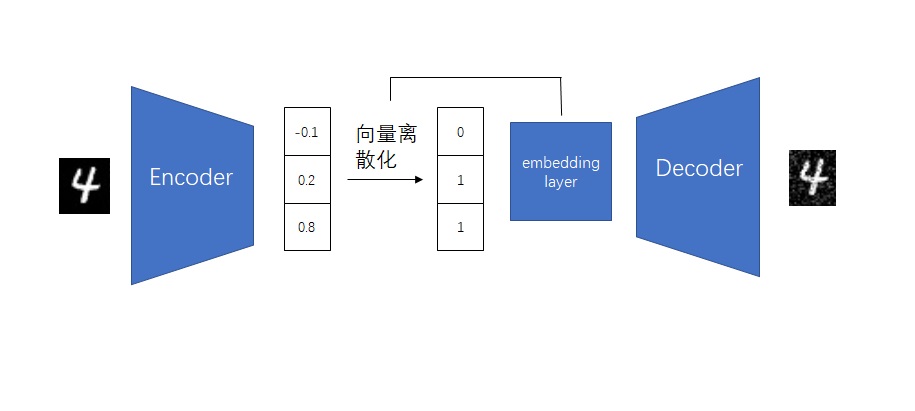
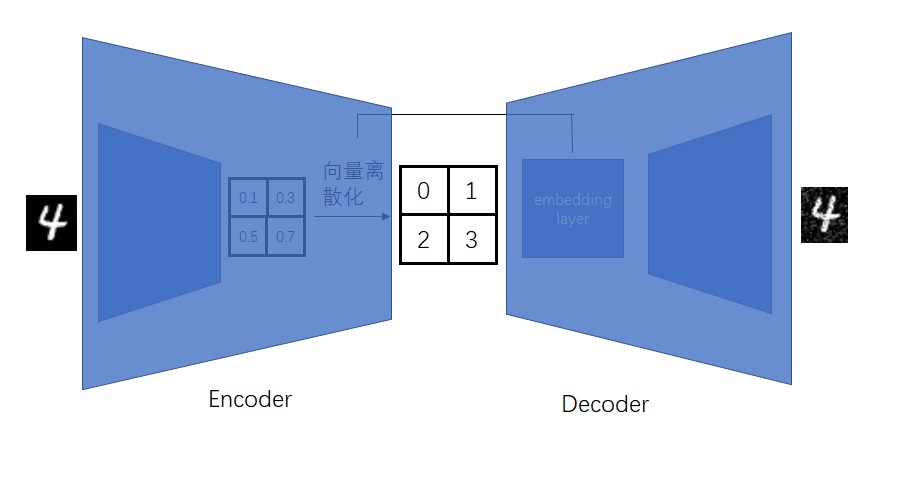
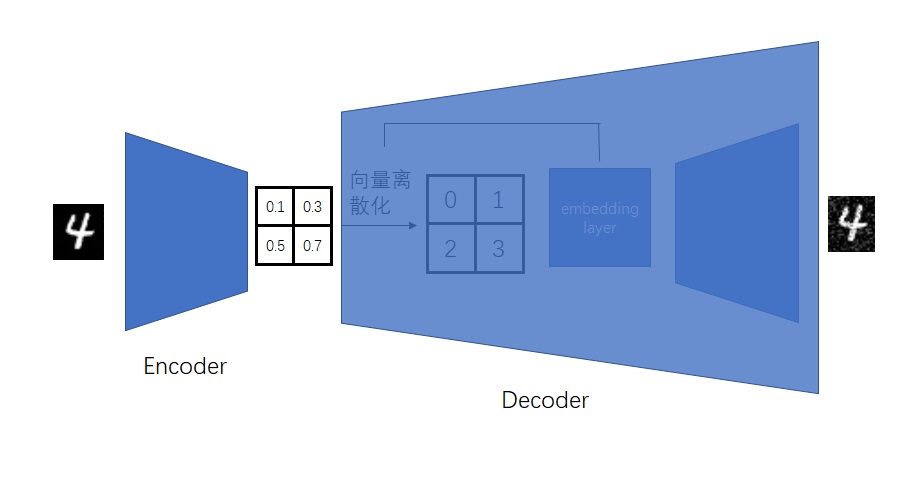
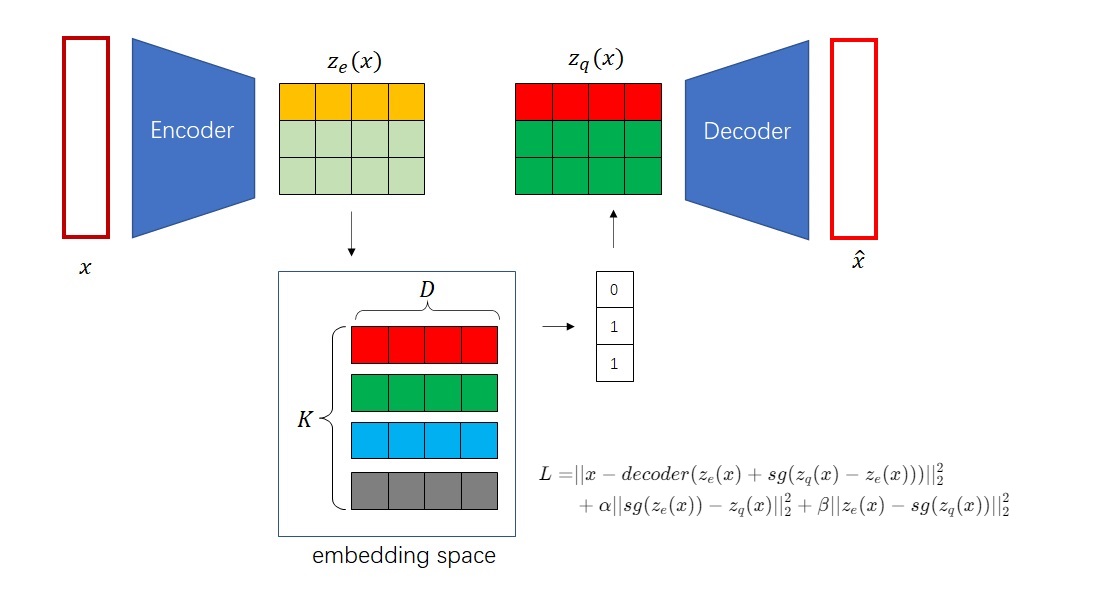
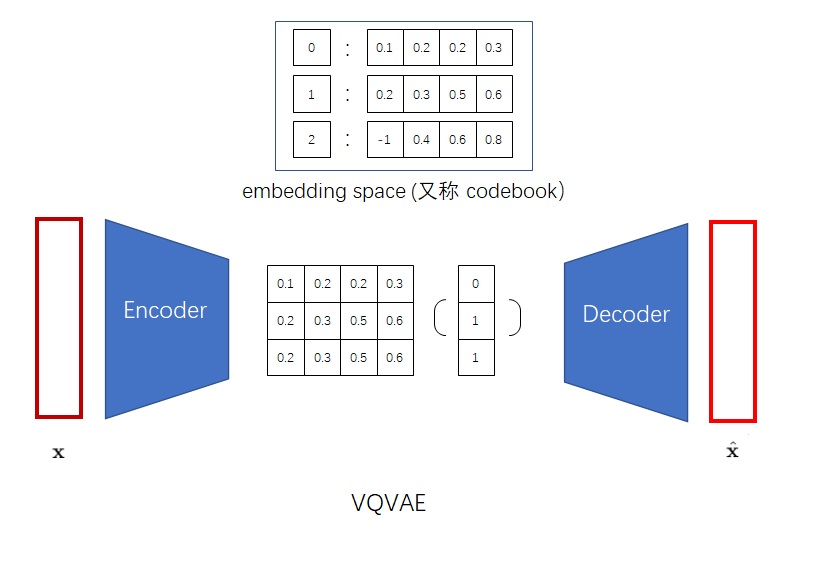
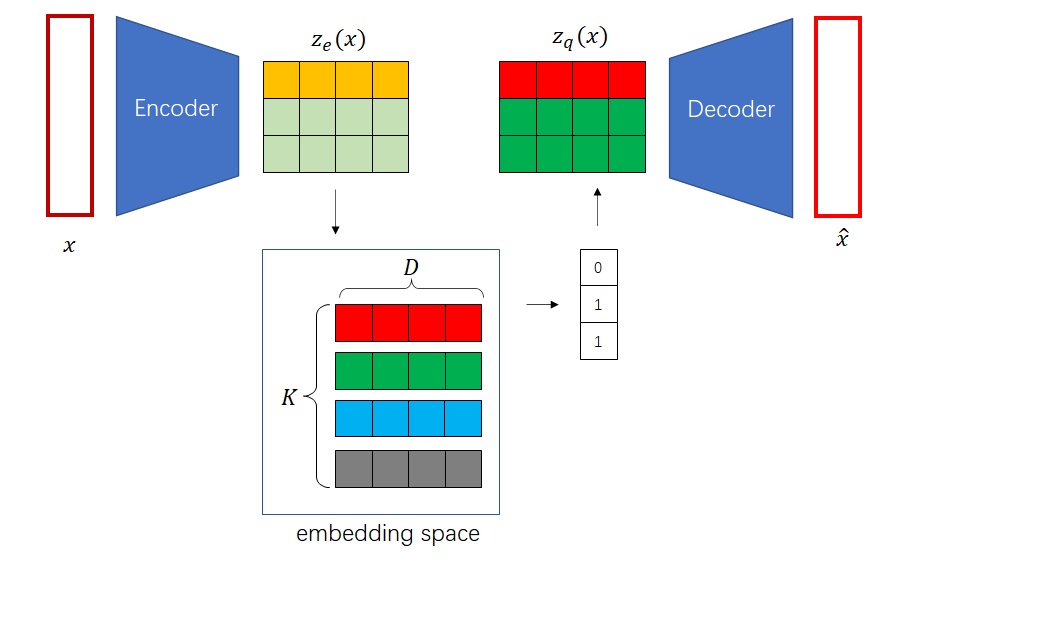
from taming.modules.diffusionmodules.model import Encoder, Decoder from taming.modules.vqvae.quantize import VectorQuantizer2 as VectorQuantizer from taming.modules.vqvae.quantize import GumbelQuantize from taming.modules.vqvae.quantize import EMAVectorQuantizer
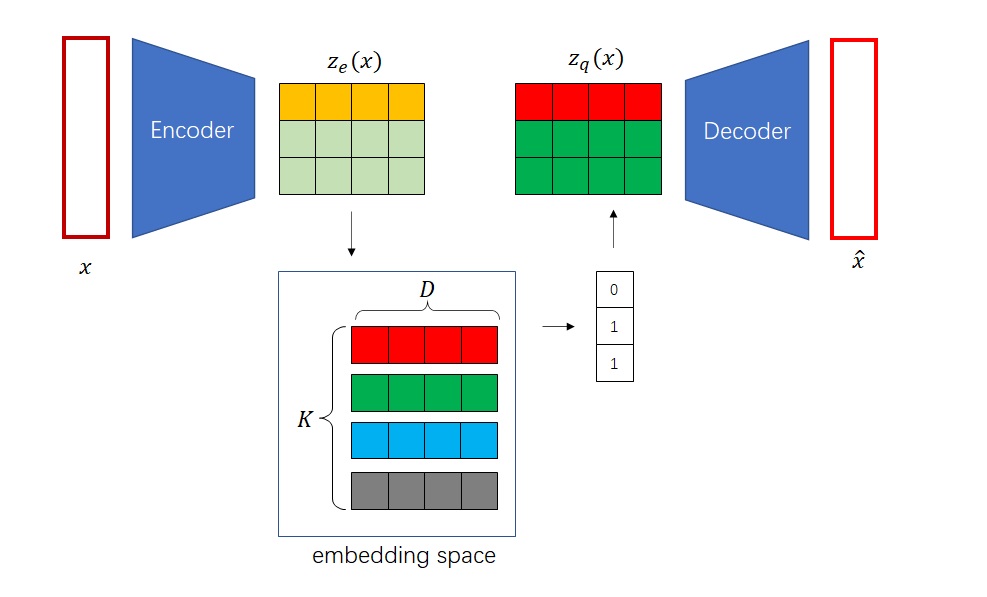
defforward(self, z): z = z.permute(0, 2, 3, 1).contiguous() z_flattened = z.view(-1, self.e_dim) # distances from z to embeddings e_j (z - e)^2 = z^2 + e^2 - 2 e * z
res = [spatial_average(lins[kk].model(diffs[kk]), keepdim=True) for kk inrange(len(self.chns))] val = res[0] for l inrange(1, len(self.chns)): val += res[l] return val
classNLayerDiscriminator(nn.Module): """Defines a PatchGAN discriminator as in Pix2Pix --> see https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/blob/master/models/networks.py """ def__init__(self, input_nc=3, ndf=64, n_layers=3, use_actnorm=False): """Construct a PatchGAN discriminator Parameters: input_nc (int) -- the number of channels in input images ndf (int) -- the number of filters in the last conv layer n_layers (int) -- the number of conv layers in the discriminator norm_layer -- normalization layer """ super(NLayerDiscriminator, self).__init__() ifnot use_actnorm: norm_layer = nn.BatchNorm2d else: norm_layer = ActNorm iftype(norm_layer) == functools.partial: # no need to use bias as BatchNorm2d has affine parameters use_bias = norm_layer.func != nn.BatchNorm2d else: use_bias = norm_layer != nn.BatchNorm2d
kw = 4 padw = 1 sequence = [nn.Conv2d(input_nc, ndf, kernel_size=kw, stride=2, padding=padw), nn.LeakyReLU(0.2, True)] nf_mult = 1 nf_mult_prev = 1 for n inrange(1, n_layers): # gradually increase the number of filters nf_mult_prev = nf_mult nf_mult = min(2 ** n, 8) sequence += [ nn.Conv2d(ndf * nf_mult_prev, ndf * nf_mult, kernel_size=kw, stride=2, padding=padw, bias=use_bias), norm_layer(ndf * nf_mult), nn.LeakyReLU(0.2, True) ]
definit_first_stage_from_ckpt(self, config): model = instantiate_from_config(config) model = model.eval() model.train = disabled_train self.first_stage_model = model
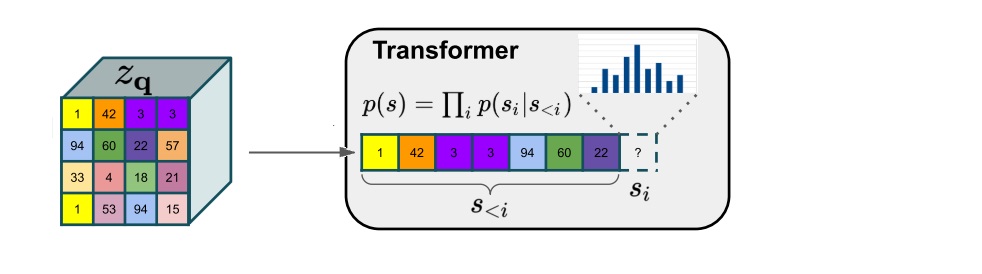
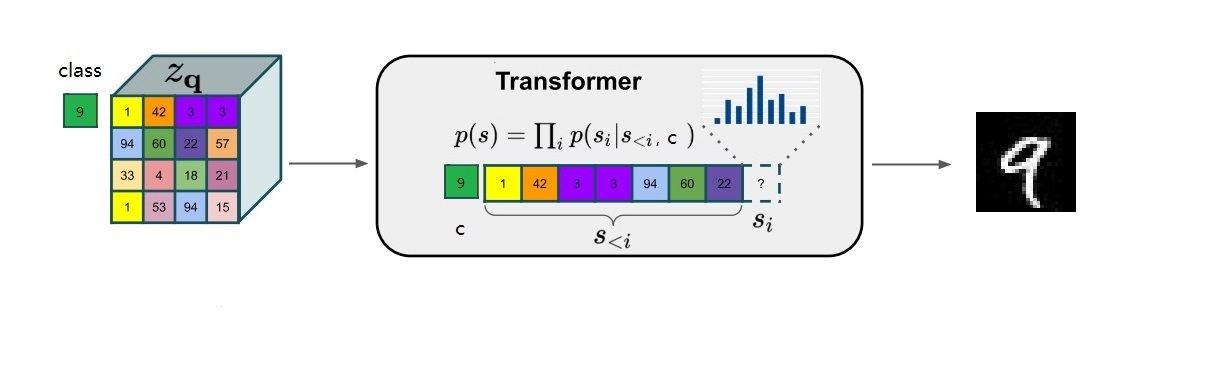
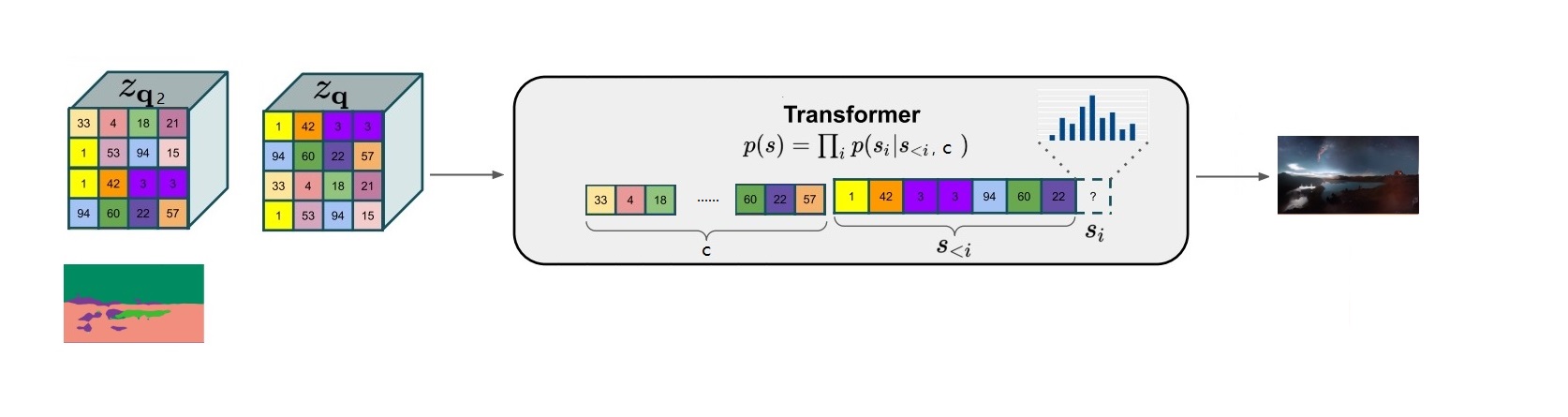
# target includes all sequence elements (no need to handle first one # differently because we are conditioning) target = z_indices # make the prediction logits, _ = self.transformer(cz_indices[:, :-1]) # cut off conditioning outputs - output i corresponds to p(z_i | z_{<i}, c) logits = logits[:, c_indices.shape[1]-1:]
defforward(self, idx, embeddings=None, targets=None): # forward the GPT model token_embeddings = self.tok_emb(idx) # each index maps to a (learnable) vector
t = token_embeddings.shape[1] assert t <= self.block_size, "Cannot forward, model block size is exhausted." position_embeddings = self.pos_emb[:, :t, :] # each position maps to a (learnable) vector x = self.drop(token_embeddings + position_embeddings) x = self.blocks(x) x = self.ln_f(x) logits = self.head(x)
# if we are given some desired targets also calculate the loss loss = None if targets isnotNone: loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1))
defforward(self, x, layer_past=None, return_present=False): # TODO: check that training still works if return_present: assertnotself.training # layer past: tuple of length two with B, nh, T, hs attn, present = self.attn(self.ln1(x), layer_past=layer_past)
x = x + attn x = x + self.mlp(self.ln2(x)) if layer_past isnotNoneor return_present: return x, present return x
目前 粮食 出现 阶段性 过剩 , 恰好 可以 以 粮食 换 森林 、 换 草地 , 再造 西部 秀美 山川 。 the present food surplus can specifically serve the purpose of helping western china restore its woodlands , grasslands , and the beauty of its landscapes .
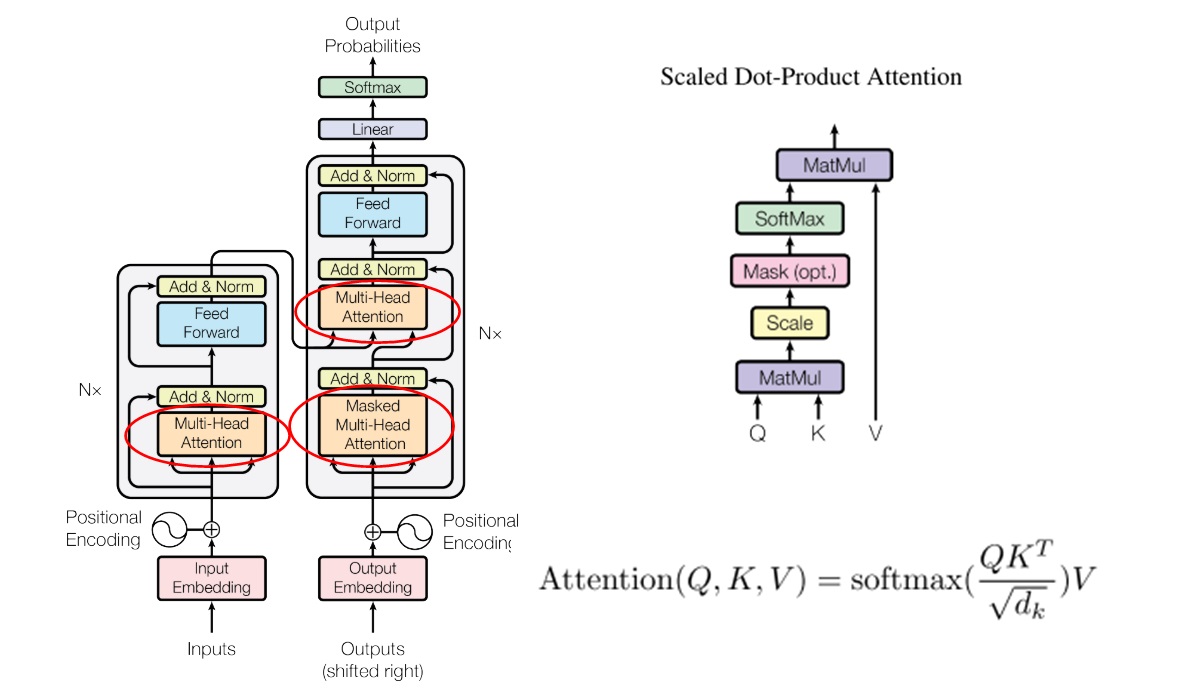
defforward(self, q: torch.Tensor, k: torch.Tensor, v: torch.Tensor, mask: Optional[torch.Tensor] = None): # batch should be same assert q.shape[0] == k.shape[0] assert q.shape[0] == v.shape[0] # the sequence length of k and v should be aligned assert k.shape[1] == v.shape[1]
defforward(self, q: torch.Tensor, k: torch.Tensor, v: torch.Tensor, mask: Optional[torch.Tensor] = None): # batch should be same assert q.shape[0] == k.shape[0] assert q.shape[0] == v.shape[0] # the sequence length of k and v should be aligned assert k.shape[1] == v.shape[1]
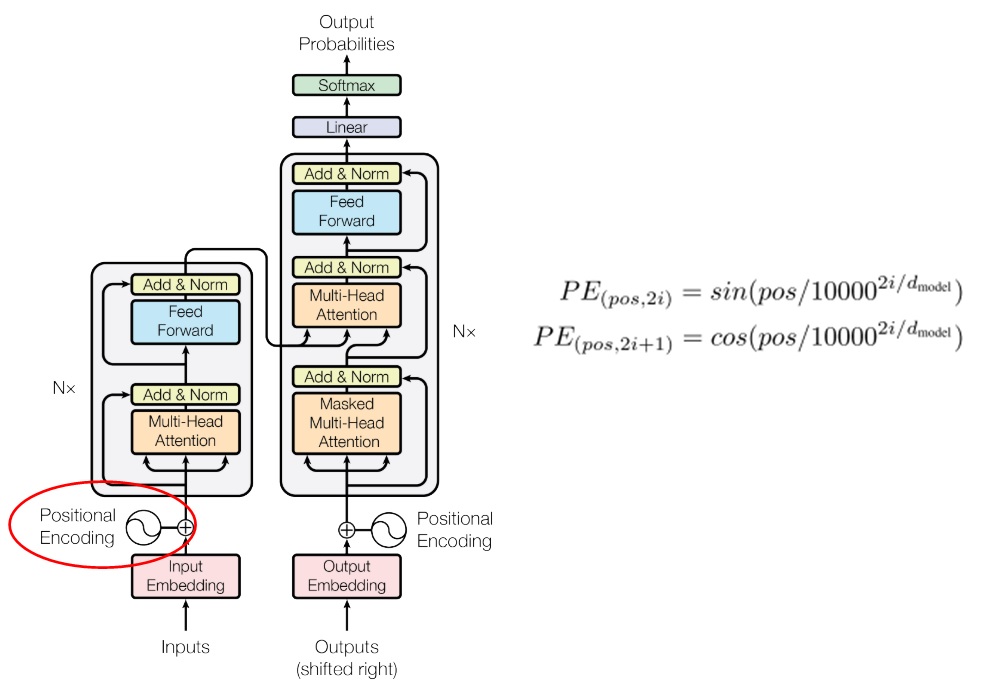
defforward(self, x, src_mask: Optional[torch.Tensor] = None): x = self.embedding(x) x = self.pe(x) x = self.dropout(x) for layer in self.layers: x = layer(x, src_mask) return x
defforward(self, x, encoder_kv, dst_mask: Optional[torch.Tensor] = None, src_dst_mask: Optional[torch.Tensor] = None): x = self.embedding(x) x = self.pe(x) x = self.dropout(x) for layer in self.layers: x = layer(x, encoder_kv, dst_mask, src_dst_mask) return x
# y_input = y_batch with torch.no_grad(): for i inrange(1, y_input.shape[1]): y_hat = model(x_batch, y_input) for j inrange(batch_size): y_input[j, i] = torch.argmax(y_hat[j, i - 1])
tokenizer = get_tokenizer('basic_english') english = tokenizer(english)
而中文分词方面,我使用了jieba库。该库可以直接 pip 安装。
1
pip install jieba
分词的 API 是 jieba.cut。由于分词的结果中,相邻的词之间有空格,我一股脑地把所有空白符给过滤掉了。
1 2 3
import jieba chinese = list(jieba.cut(chinese)) chinese = [x for x in chinese if x notin {' ', '\t'}]
经过这些处理后,每句话被转换成了中文词语或英文单词的数组。整个处理代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
defread_file(json_path): english_sentences = [] chinese_sentences = [] tokenizer = get_tokenizer('basic_english') withopen(json_path, 'r') as fp: for line in fp: line = json.loads(line) english, chinese = line['english'], line['chinese'] # Correct mislabeled data ifnot english.isascii(): english, chinese = chinese, english # Tokenize english = tokenizer(english) chinese = list(jieba.cut(chinese)) chinese = [x for x in chinese if x notin {' ', '\t'}] english_sentences.append(english) chinese_sentences.append(chinese) return english_sentences, chinese_sentences
def__getitem__(self, index): x = np.concatenate(([SOS_ID], self.en_tensor[index], [EOS_ID])) x = torch.from_numpy(x) y = np.concatenate(([SOS_ID], self.zh_tensor[index], [EOS_ID])) y = torch.from_numpy(y) return x, y
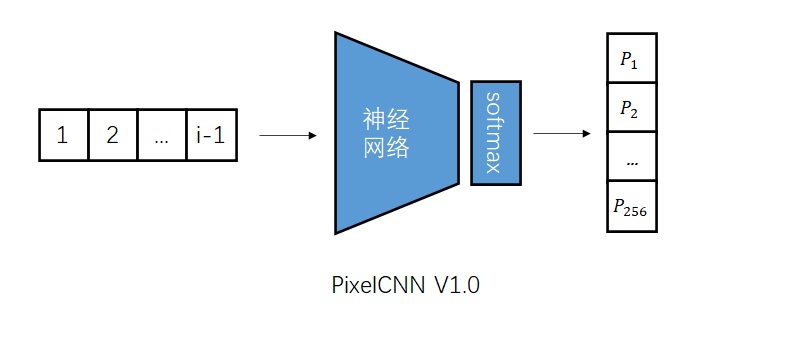
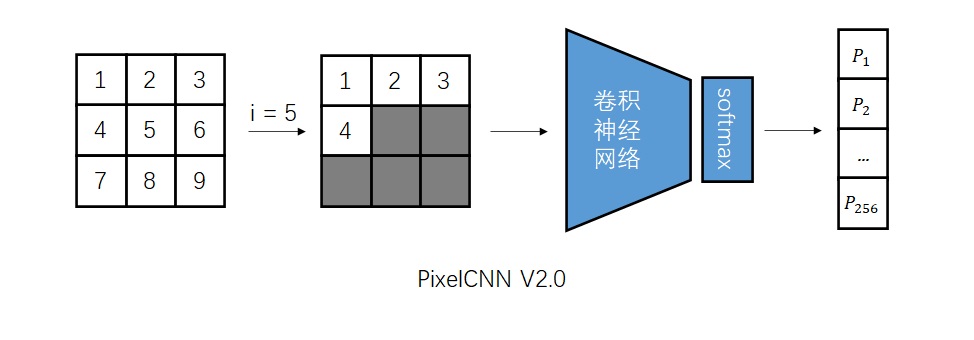
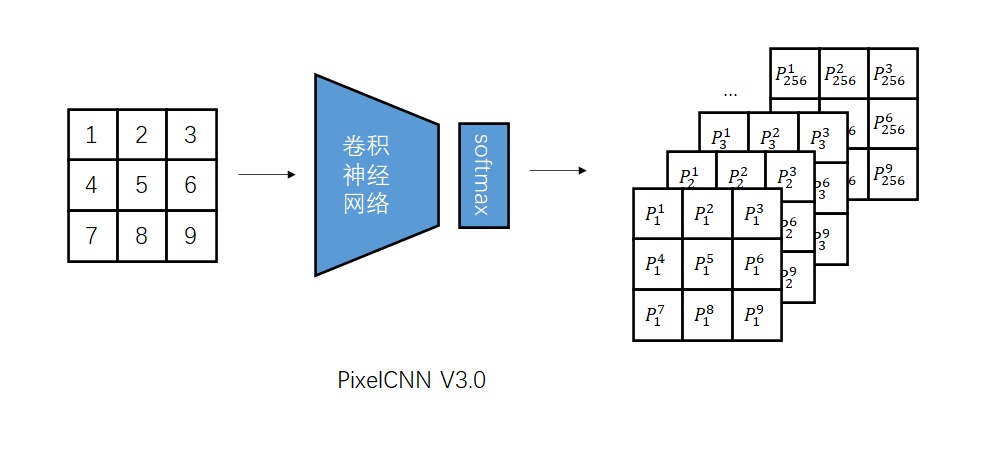
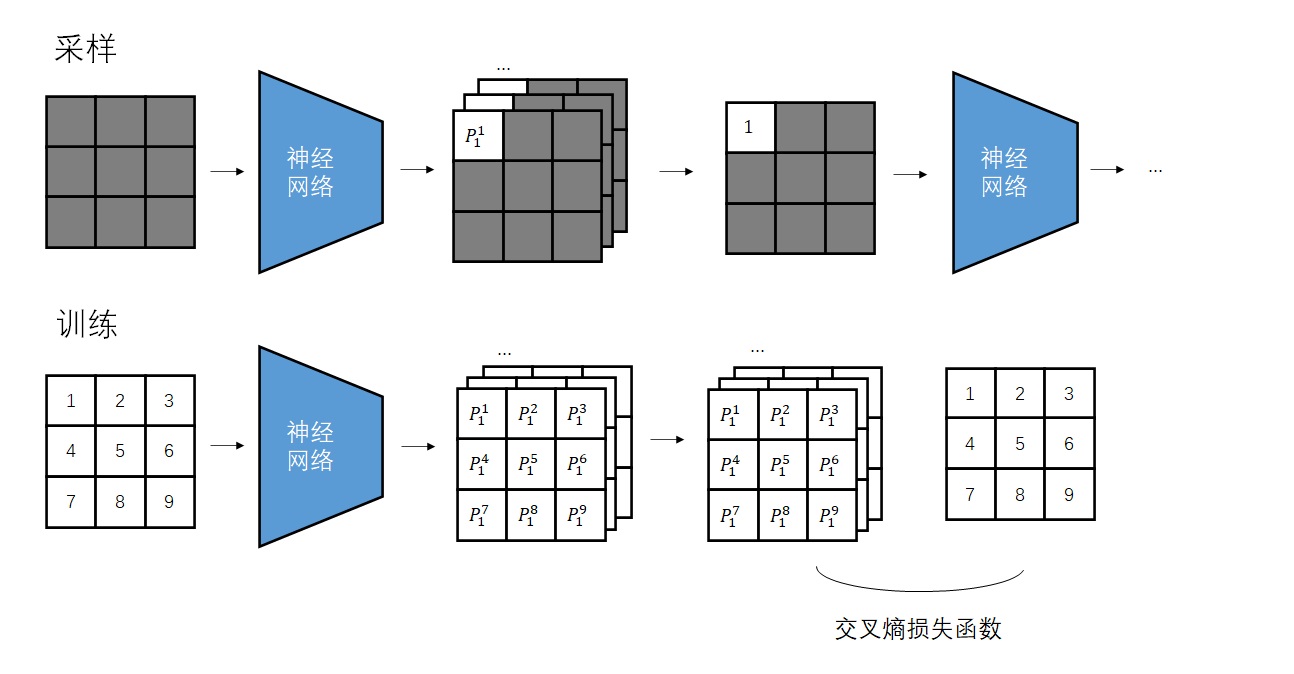
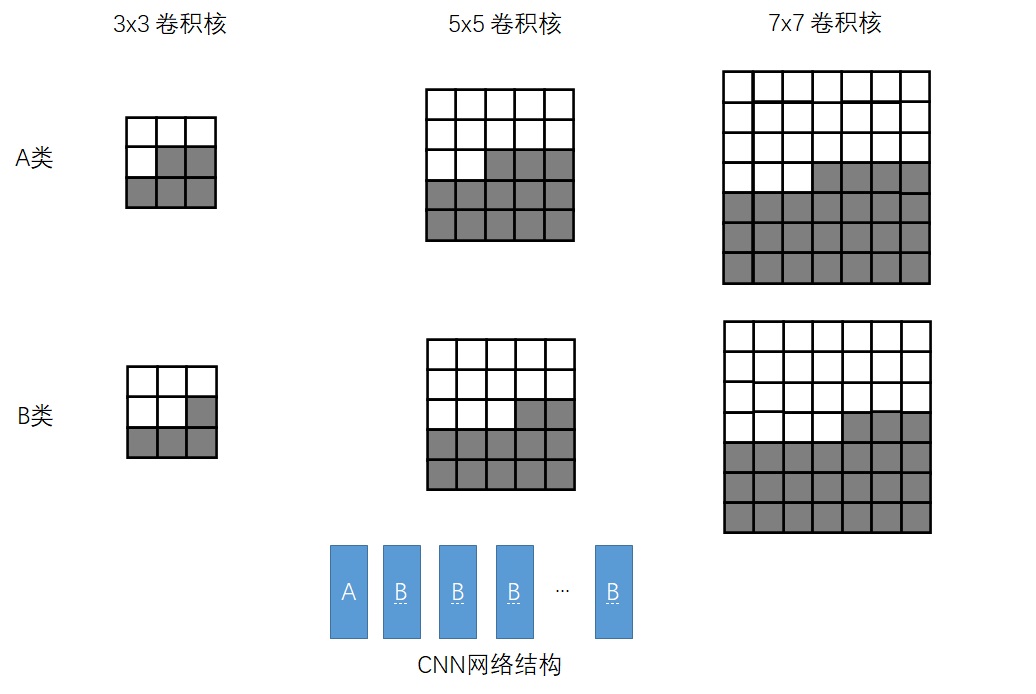
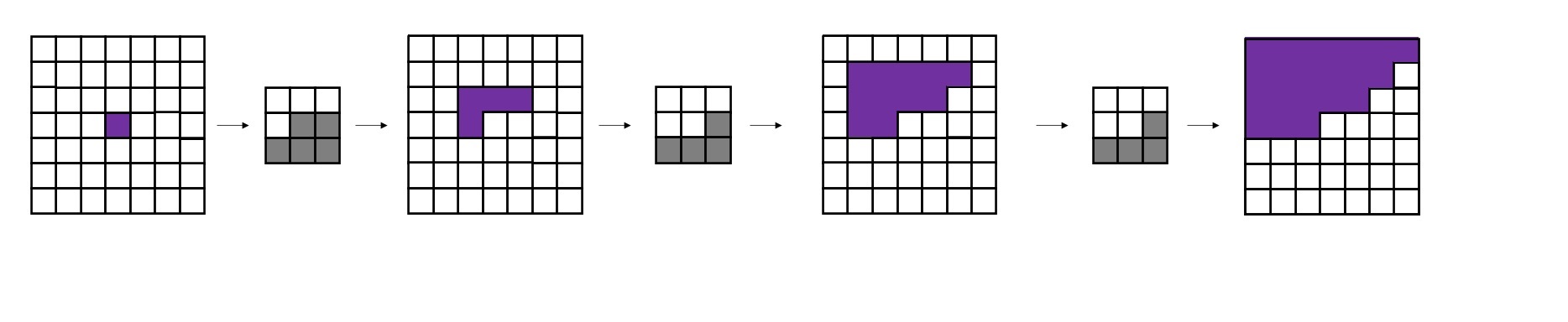
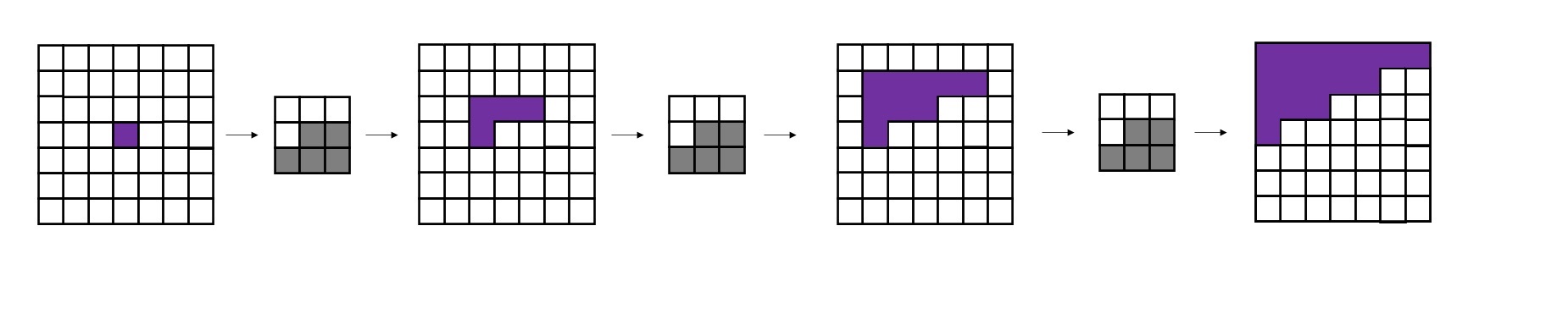
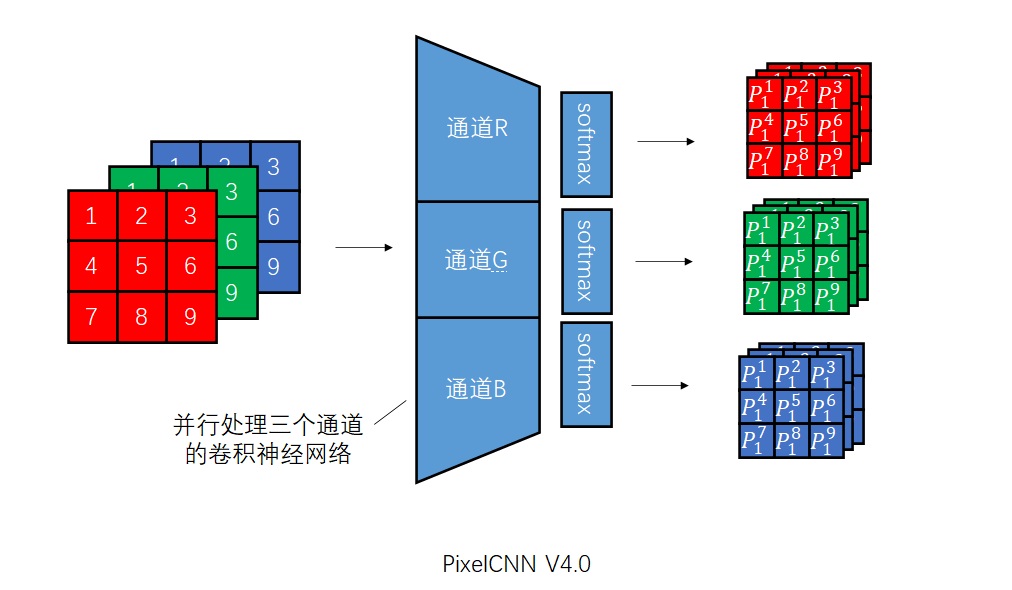
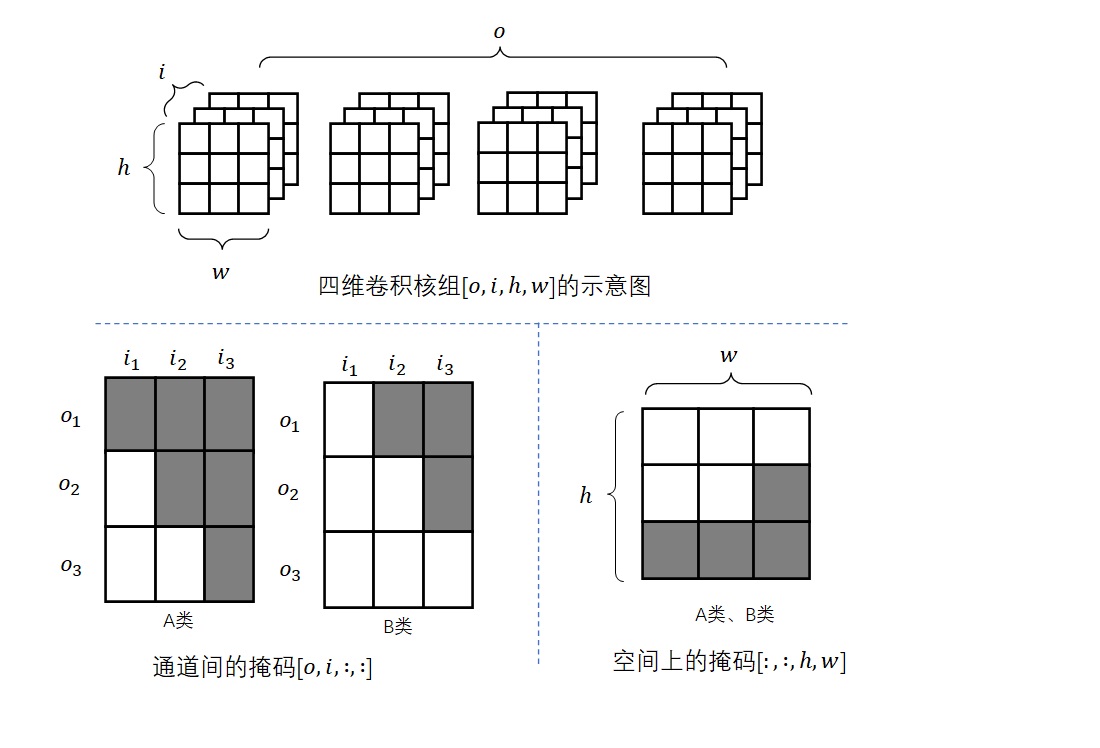
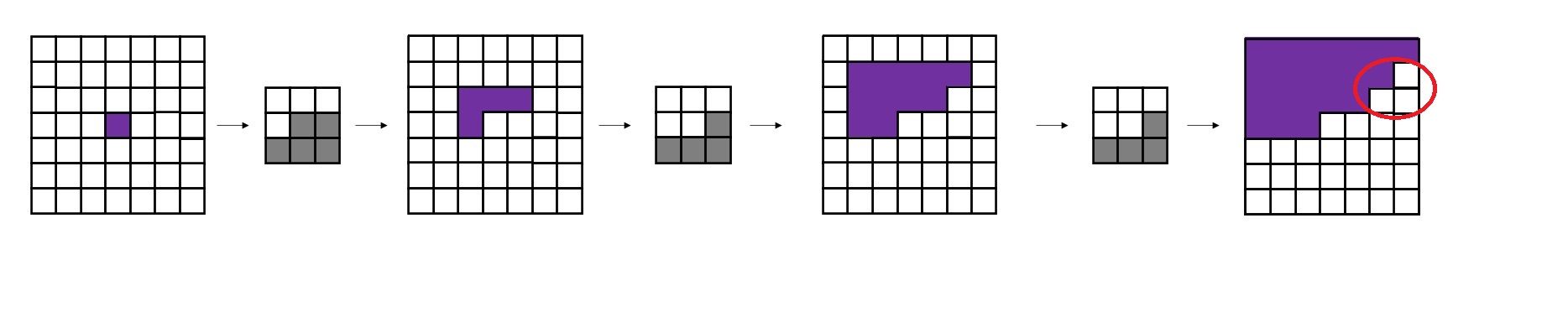
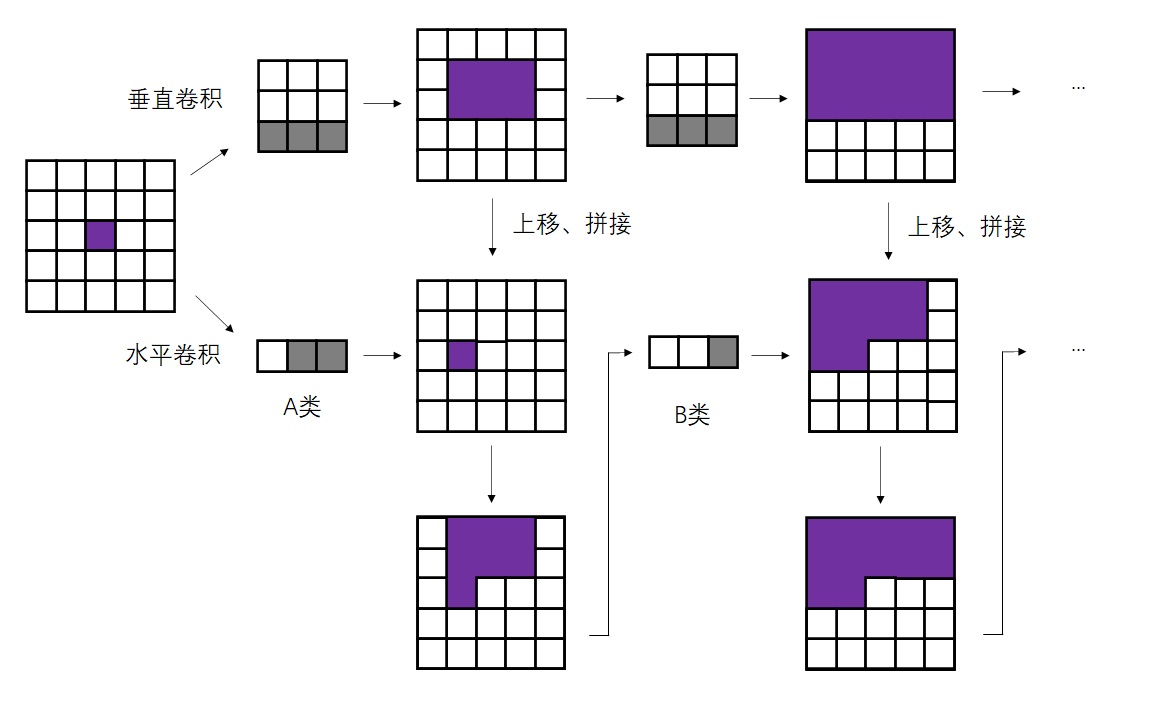
Conditional Image Generation with PixelCNN Decoders 是提出Gated PixelCNN的文章。可以主要阅读消除视野盲区和门激活函数的部分。
PixelCNN++: Improving the PixelCNN with Discretized Logistic Mixture Likelihood and Other Modifications 是提出PixelCNN++的文章。整篇文章非常简练,可以整体阅读一遍,并且着重阅读离散logistic混合似然的部分。不过,这篇文章有很多地方写得过于简单了,连公式里的字母都不好好交代清楚,我还是看代码才看懂他们想讲什么。建议搭配本文的讲解阅读。
defforward(self, x): y = self.relu(x) y = self.conv1(y) y = self.bn1(y) y = self.relu(y) y = self.conv2(y) y = self.bn2(y) y = self.relu(y) y = self.conv3(y) y = self.bn3(y) y = y + x return y
defforward(self, x): x = self.conv1(x) x = self.bn1(x) for block in self.residual_blocks: x = block(x) x = self.relu(x) x = self.linear1(x) x = self.relu(x) x = self.linear2(x) x = self.out(x) return x
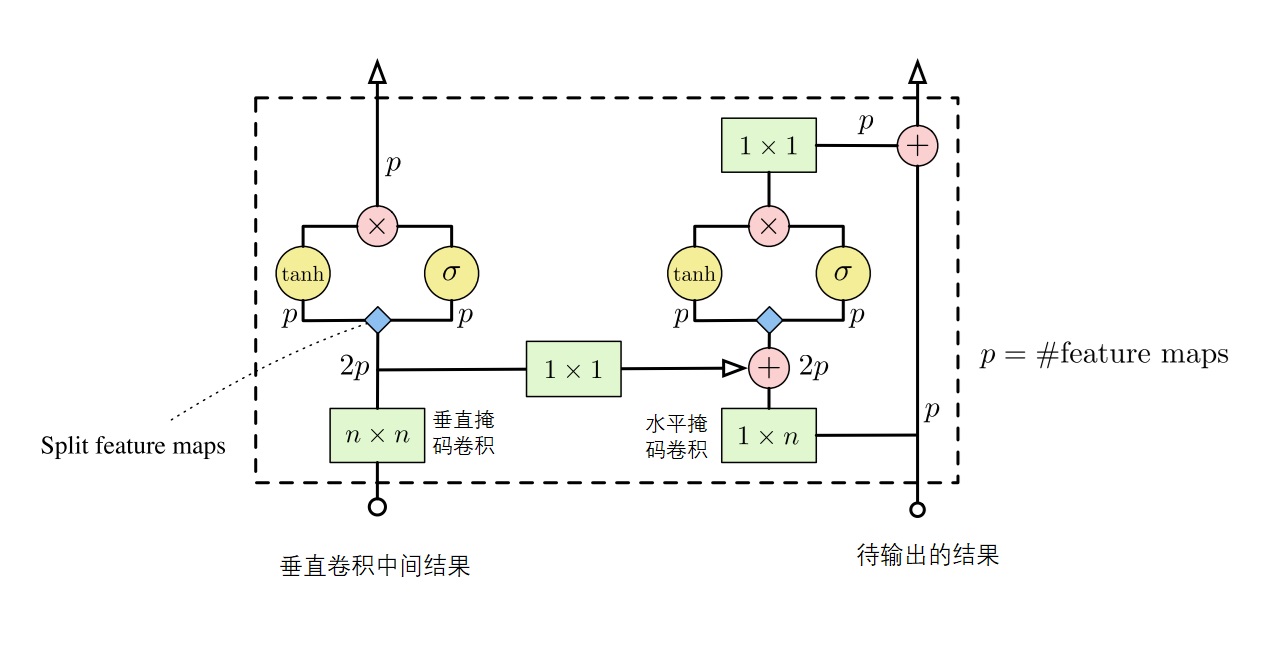
h = self.h_conv(h_input) h = self.bn3(h) h = h + v_to_h h1, h2 = h[:, :self.p], h[:, self.p:] h1 = torch.tanh(h1) h2 = torch.sigmoid(h2) h = h1 * h2 h = self.h_output_conv(h) h = self.bn4(h) if self.conv_type == 'B': h = h + h_input return v, h
defforward(self, x): v, h = self.block1(x, x) for block in self.blocks: v, h = block(v, h) x = self.relu(h) x = self.linear1(x) x = self.relu(x) x = self.linear2(x) x = self.out(x) return x
u_list = [nn.down_shift( nn.down_shifted_conv2d(x_pad, num_filters=nr_filters, filter_size=[2, 3]) )] # stream for pixels above ul_list = [nn.down_shift( nn.down_shifted_conv2d(x_pad, num_filters=nr_filters, filter_size=[1,3]) ) + nn.right_shift( nn.down_right_shifted_conv2d(x_pad, num_filters=nr_filters, filter_size=[2,1]) )] # stream for up and to the left
u = u_list.pop() ul = ul_list.pop() for rep inrange(nr_resnet): u = nn.gated_resnet(u, u_list.pop(), conv=nn.down_shifted_conv2d) ul = nn.gated_resnet(ul, tf.concat([u, ul_list.pop()],3), conv=nn.down_right_shifted_conv2d) tf.add_to_collection('checkpoints', u) tf.add_to_collection('checkpoints', ul)
u = nn.down_shifted_deconv2d(u, num_filters=nr_filters, stride=[2, 2]) ul = nn.down_right_shifted_deconv2d(ul, num_filters=nr_filters, stride=[2, 2])
for rep inrange(nr_resnet+1): u = nn.gated_resnet(u, u_list.pop(), conv=nn.down_shifted_conv2d) ul = nn.gated_resnet(ul, tf.concat([u, ul_list.pop()],3), conv=nn.down_right_shifted_conv2d) tf.add_to_collection('checkpoints', u) tf.add_to_collection('checkpoints', ul)
u = nn.down_shifted_deconv2d(u, num_filters=nr_filters, stride=[2, 2]) ul = nn.down_right_shifted_deconv2d(ul, num_filters=nr_filters, stride=[2, 2])
for rep inrange(nr_resnet+1): u = nn.gated_resnet(u, u_list.pop(), conv=nn.down_shifted_conv2d) ul = nn.gated_resnet(ul, tf.concat([u, ul_list.pop()],3), conv=nn.down_right_shifted_conv2d) tf.add_to_collection('checkpoints', u) tf.add_to_collection('checkpoints', ul)
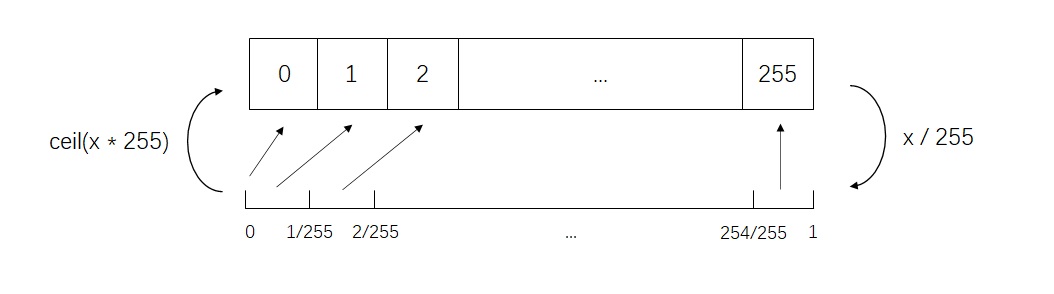
defdiscretized_mix_logistic_loss(x,l,sum_all=True): """ log-likelihood for mixture of discretized logistics, assumes the data has been rescaled to [-1,1] interval """ xs = int_shape(x) # true image (i.e. labels) to regress to, e.g. (B,32,32,3) ls = int_shape(l) # predicted distribution, e.g. (B,32,32,100) nr_mix = int(ls[-1] / 10) # here and below: unpacking the params of the mixture of logistics logit_probs = l[:,:,:,:nr_mix] l = tf.reshape(l[:,:,:,nr_mix:], xs + [nr_mix*3]) means = l[:,:,:,:,:nr_mix] log_scales = tf.maximum(l[:,:,:,:,nr_mix:2*nr_mix], -7.) coeffs = tf.nn.tanh(l[:,:,:,:,2*nr_mix:3*nr_mix]) x = tf.reshape(x, xs + [1]) + tf.zeros(xs + [nr_mix]) # here and below: getting the means and adjusting them based on preceding sub-pixels m2 = tf.reshape(means[:,:,:,1,:] + coeffs[:, :, :, 0, :] * x[:, :, :, 0, :], [xs[0],xs[1],xs[2],1,nr_mix]) m3 = tf.reshape(means[:, :, :, 2, :] + coeffs[:, :, :, 1, :] * x[:, :, :, 0, :] + coeffs[:, :, :, 2, :] * x[:, :, :, 1, :], [xs[0],xs[1],xs[2],1,nr_mix]) means = tf.concat([tf.reshape(means[:,:,:,0,:], [xs[0],xs[1],xs[2],1,nr_mix]), m2, m3],3) centered_x = x - means inv_stdv = tf.exp(-log_scales) plus_in = inv_stdv * (centered_x + 1./255.) cdf_plus = tf.nn.sigmoid(plus_in) min_in = inv_stdv * (centered_x - 1./255.) cdf_min = tf.nn.sigmoid(min_in) log_cdf_plus = plus_in - tf.nn.softplus(plus_in) # log probability for edge case of 0 (before scaling) log_one_minus_cdf_min = -tf.nn.softplus(min_in) # log probability for edge case of 255 (before scaling) cdf_delta = cdf_plus - cdf_min # probability for all other cases mid_in = inv_stdv * centered_x log_pdf_mid = mid_in - log_scales - 2.*tf.nn.softplus(mid_in) # log probability in the center of the bin, to be used in extreme cases (not actually used in our code)
xs = int_shape(x) # true image (i.e. labels) to regress to, e.g. (B,32,32,3) ls = int_shape(l) # predicted distribution, e.g. (B,32,32,100) nr_mix = int(ls[-1] / 10) # here and below: unpacking the params of the mixture of logistics logit_probs = l[:,:,:,:nr_mix] l = tf.reshape(l[:,:,:,nr_mix:], xs + [nr_mix*3]) means = l[:,:,:,:,:nr_mix] log_scales = tf.maximum(l[:,:,:,:,nr_mix:2*nr_mix], -7.) coeffs = tf.nn.tanh(l[:,:,:,:,2*nr_mix:3*nr_mix])
centered_x = x - means inv_stdv = tf.exp(-log_scales) plus_in = inv_stdv * (centered_x + 1./255.) cdf_plus = tf.nn.sigmoid(plus_in) min_in = inv_stdv * (centered_x - 1./255.) cdf_min = tf.nn.sigmoid(min_in) log_cdf_plus = plus_in - tf.nn.softplus(plus_in) # log probability for edge case of 0 (before scaling) log_one_minus_cdf_min = -tf.nn.softplus(min_in) # log probability for edge case of 255 (before scaling) cdf_delta = cdf_plus - cdf_min # probability for all other cases
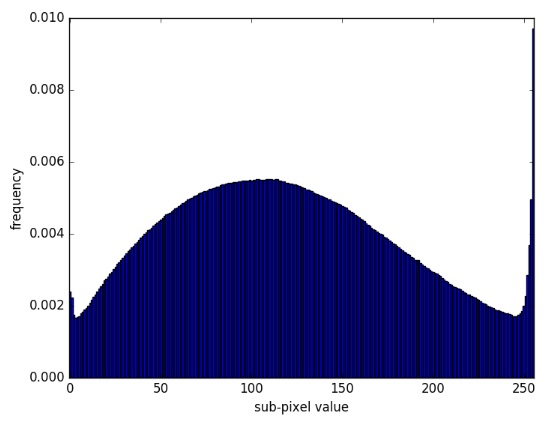
作者还算了积分区间中心的概率,以处理某些边界情况。实际上这个值没有在代码中使用。
1 2 3
mid_in = inv_stdv * centered_x log_pdf_mid = mid_in - log_scales - 2.*tf.nn.softplus(mid_in) # log probability in the center of the bin, to be used in extreme cases (not actually used in our code)
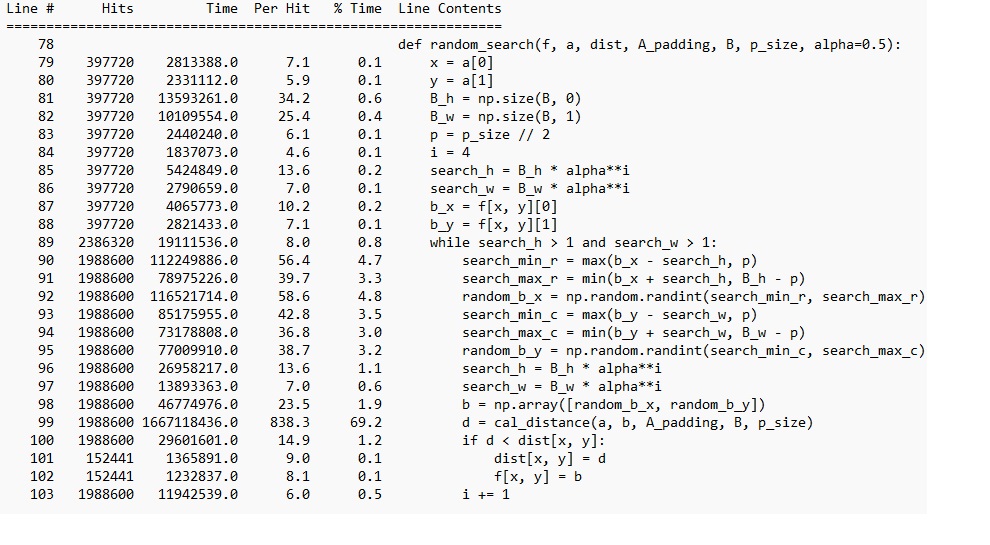
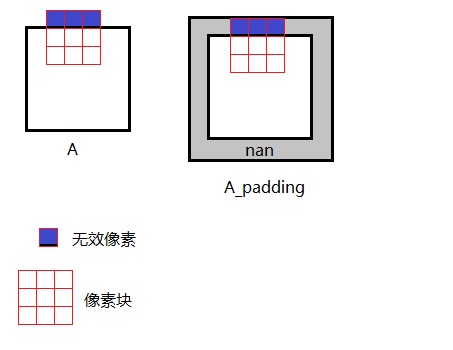
# Numba 循环写法 @njit defcal_distance(x, y, x2, y2, A_padding, B, p): sum = 0 for i inrange(p + p + 1): for j inrange(p + p + 1): for k inrange(3): a = float(A_padding[x + i, y + j, k]) bb = B[x2 - p + i, y2 - p + j, k] sum += (a - bb)**2 returnsum