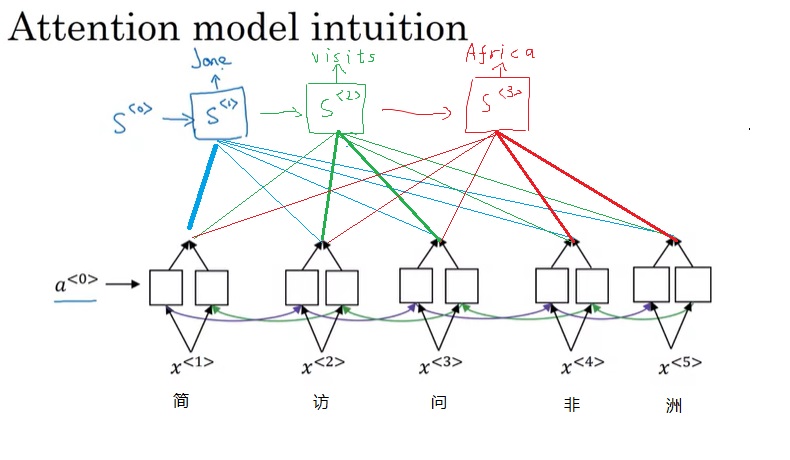
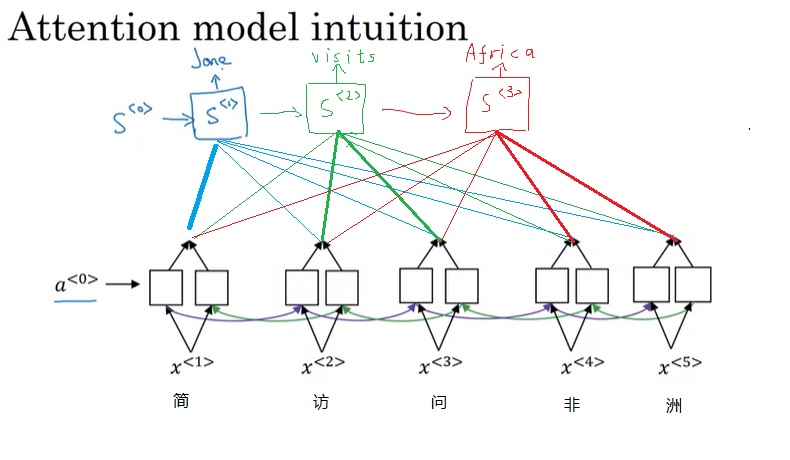
比如把“Jane九月要访问非洲”翻译成英文,可以翻译成”Jane is visiting Africa in September.”,也可以翻译成”Jane is going to be visiting Africa in September.”。上节提到的那个类似于语言模型的RNN架构可以生成出这两个句子中的任何一个。
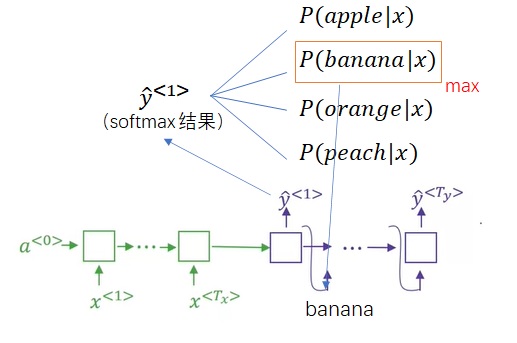
从语言的角度,”Jane is visiting Africa in September.”这个翻译比”Jane is going to be visiting Africa in September.”更好。或者说,前面那个句子的概率更高一点。用数学公式来表达,给定被翻译的句子$x$, 我们希望求一个使$P(y^{< 1 >}, y^{< 2 >}, …y^{< T_y >},|x)$最大的序列$y$。
然而,每次选一个概率最大的单词,不能保证整句话概率最大。比如,模型可能有”Jane is visiting Africa in September.”和”Jane is going to be visiting Africa in September.”这两个潜在的候选翻译结果。选第三个单词时,”going”的概率可能比”visiting”要高,按贪心算法,我们最后会生成出第二个句子。可是,从翻译质量来看,第一个句子显然更好,它的概率更高。
还是拿开始那句话的翻译为例,并假设$B=3$,词汇表大小为10000。生成第一个单词时,概率最高的三个单词可能是in, Jane, September。生成第二个单词时,我们要遍历第一个单词是in, Jane, September时的所有30000种两个单词组合的可能。最终,我们可能发现in September, Jane is, Jane visits这三个句子的概率最高。依次类推,我们继续遍历下去,直到生成句子里的所有单词。
# encoder a = 0 for i inrange(tx): a, _ = RNN(embed(x[i]), a) # decoder # step 1 a, p = RNN(0, a) a_arr = [a] * B words, prob = get_max_words_from_softmax(p, B) sentences = copy(words) # step 2 - ty for i inrange(ty - 1): all_words = [] all_prob = [] all_a = [] for j inrange(B): new_a, p = RNN(embed(words[j]), a_arr[j]) tmp_words, tmp_prob = get_max_words_from_softmax(p, B) tmp_a = [new_a] * B # Accmulative multiply the probablity for k inrange(B): tmp_prob[k] *= prob[j] all_words += tmp_words all_parob += tmp_prob all_a += tmp_a words, prob, a_arr = get_max_B(all_words, all_prob, all_a)
# Cancatenate output for j inrange(B): sentences[j].append(words[B])
y = get_max_sentences(sentences[j], prob) Output y
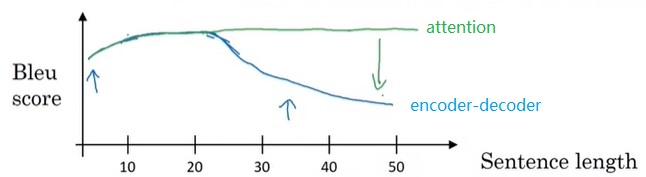
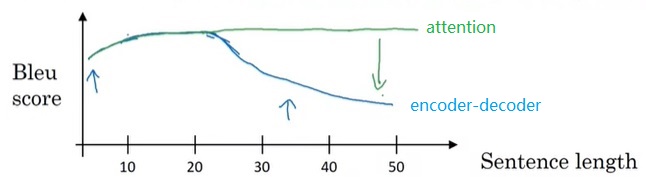
加入Beam Search会让我们调试机器翻译算法时更加困难。还是对于开始那个翻译示例,假如人类给出了翻译$y^{\ast}$:Jane visits Africa in September,算法给出了翻译$\hat{y}$:Jane visited Africa last September。这个算法的翻译不够好,我们想利用第三门课学的错误分析方法来分析错误的来源。这究竟是Beam Search出了问题,还是RNN神经网络出了问题呢?
在图像分类中,我们可以用识别准确率来轻松地评价一个模型。但是,在机器翻译任务中,最优的翻译可能不只一个。比如把“小猫在垫子上”翻译成英文,既可以说”The cat is on the mat”,也可以说”There is a cat on the mat”。我们不太好去评价每句话的翻译质量。Bleu Score就是一种衡量翻译质量的指标。
我们可以把机器的翻译结果和这两句参考结果做对比。对比的第一想法是看看机器翻译的句子里的单词有多少个在参考句子里出现过。但是,这种比较方法有问题。假如机器输出了”the the the the the the the”,the在参考句子里出现过,输出的7个单词全部都出现过。因此,翻译准确率是$\frac{7}{7}$。这显然不是一个好的评价指标。
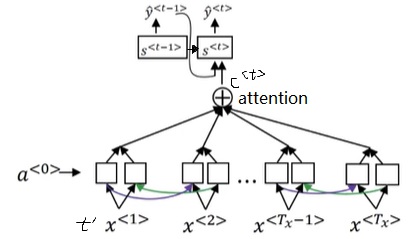
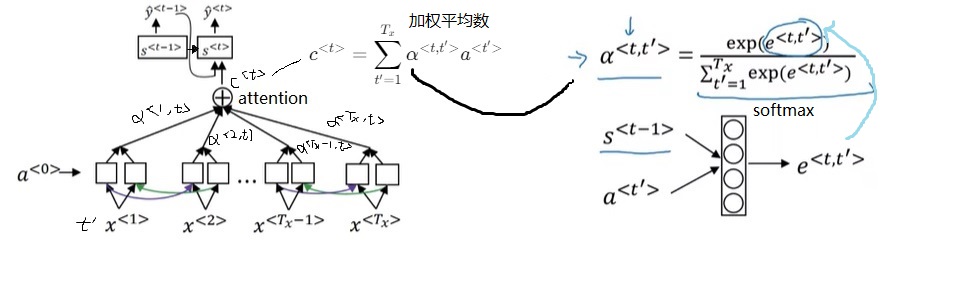
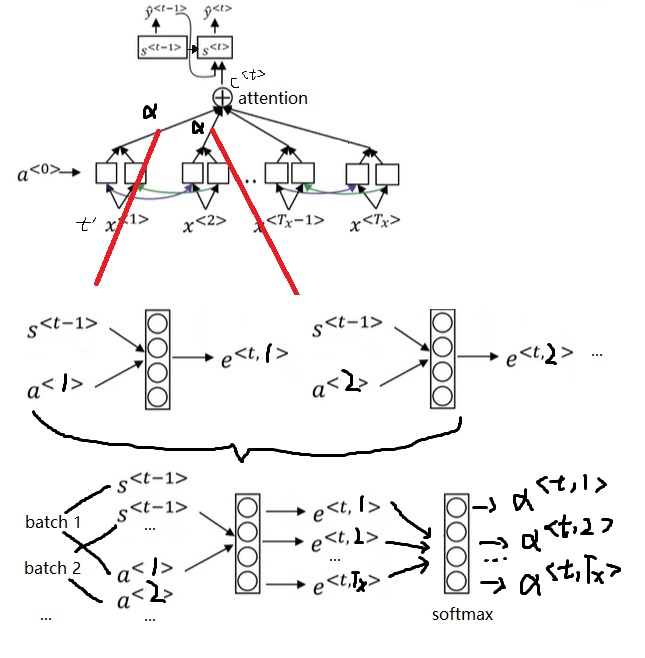
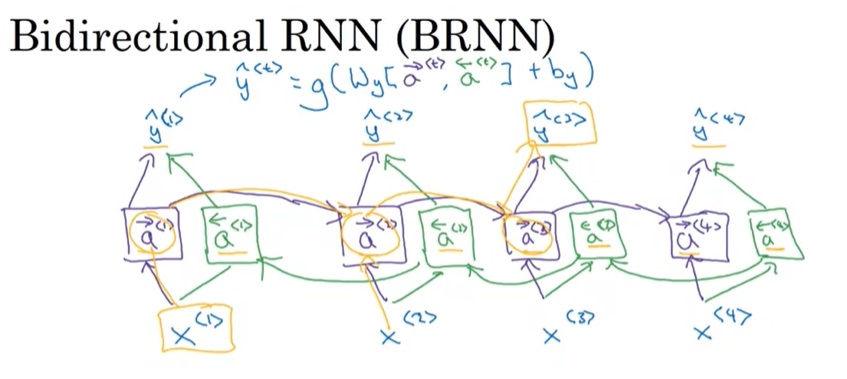
让我们看一下具体的计算过程。为了区分上下两个RNN,我们用$a$表示编码RNN的状态,$t’$表示输入序号;$s$表示解码RNN的状态,$t$表示输出序号。刚才提到的那种关注每个输入单词的注意力机制会给每个输出一个上下文向量$c^{< t >}$。这个向量和上一轮输出$\hat{y}^{< t-1 >}$拼在一起作为这轮解码RNN的输入。
注意,从逻辑上来讲,解码RNN有两个输入。第一个输入和我们之前见过的解码RNN一样,是上一轮的输出$\hat{y}^{< t-1 >}$。第二个输入是注意力上下文$c^{< t >}$。这两个输入通过拼接(concatenate)的方式一起输入解码RNN。我在学到这里的时候一直很疑惑,两个输入该怎么输入进RNN。原视频并没有强调两个输入是拼接在一起的。
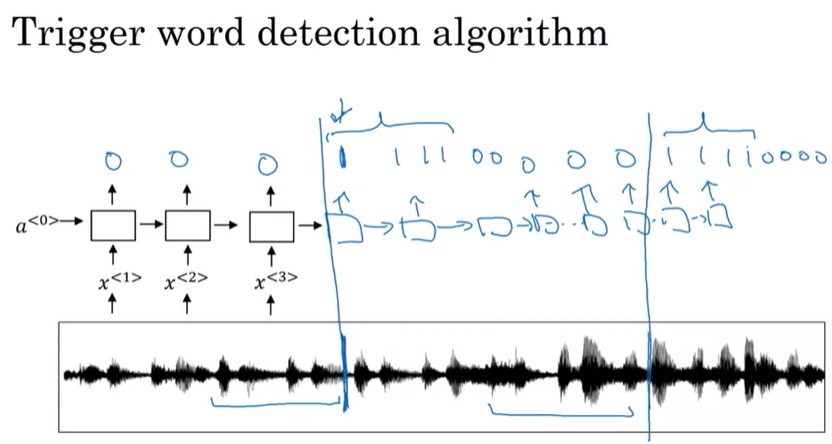
比如,对于句子”the quick brown fox”,我们可以把”the q”它扩充成ttt_h_eee____< space >____qqq__。这个和输入等长的序列表示每一个时刻发音者正在说哪个字母。序列中有一些特殊标记,下划线表示没有识别出任何东西,空格< space >表示英语里的空格。
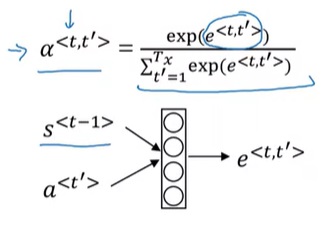
对于每一轮的输出$\hat{y}^{< t >}$,它的解码RNN的输入由上一轮输出$\hat{y}^{< t - 1>}$和注意力上下文$c^{< t >}$拼接而成。注意力上下文$c^{< t >}$,就是所有输入的编码RNN的隐变量$a^{< t >}$的一个加权平均数。这里加权平均数的权重$\alpha$就是该输出对每一个输入的注意力。每一个$\alpha$由编码RNN本轮状态$a^{< t’ >}$和解码RNN上一轮状态$s^{< t - 1 >}$决定。这两个输入会被送入一个简单的全连接网络,输出权重$e$(一个实数)。所有输入元素的$e$经过一个softmax输出$\alpha$。
Possible output: short: 1986-02-25 2/25/86 medium: 1979-08-05 Aug 5, 1979 long: 1971-12-15 December 15, 1971 full: 2017-02-14 Tuesday, February 14, 2017 d MMM YYY: 1984-02-21 21 Feb 1984 d MMMM YYY: 2011-06-22 22 June 2011 dd/MM/YYY: 1991-08-02 02/08/1991 dd-MM-YYY: 1987-06-12 12-06-1987 EE d, MMM YYY: 1986-11-02 Sun 2, Nov 1986 EEEE d, MMMM YYY: 1996-01-26 Friday 26, January 1996
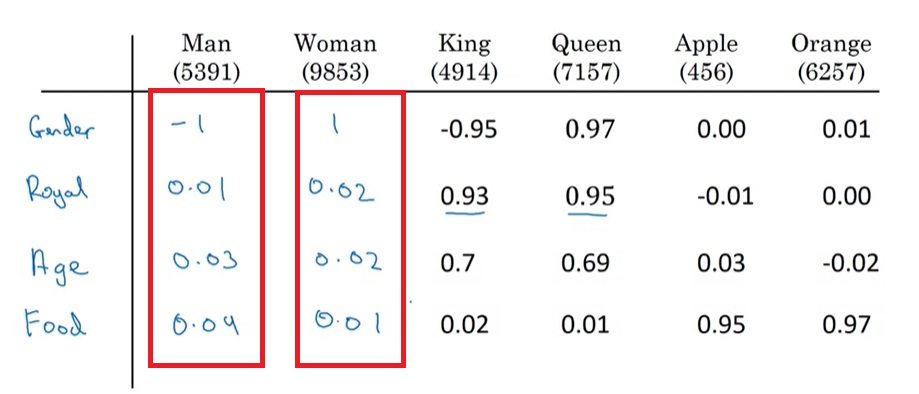
还是以命名实体识别任务为例。假设有这么一句话”Sally Johnson is an orange farmer”,我们能够推断出”Sally Johnson”是一个人名,这是因为我们看到了后面的”orange farmer”。橙子农民很可能与人名对应。
假设从刚刚那句话中,模型已经学会了橙子农民与人名之间的关系。现在,又有了一条新的训练样本”Robert Lin is an apple farmer”。使用了词嵌入的话,模型虽然不知道“苹果农民”是什么,但它知道”apple”和”orange”是很相似的东西,能够很快学会这句话的”Robert Lin”也是一个人名。
假设又有一条测试样本”Robert Lin is a durian cultivator”。模型可能从来在训练集里没有见过”durian”和”cultivator”这两个单词。但是,通过词嵌入,模型知道”durian(榴莲)”是一种和”apple”相近的东西,”cultivator(培育者)”是一种和”farmer”类似的东西。通过这层关系,模型还是能够推理出”Robert Lin”是一个人名。
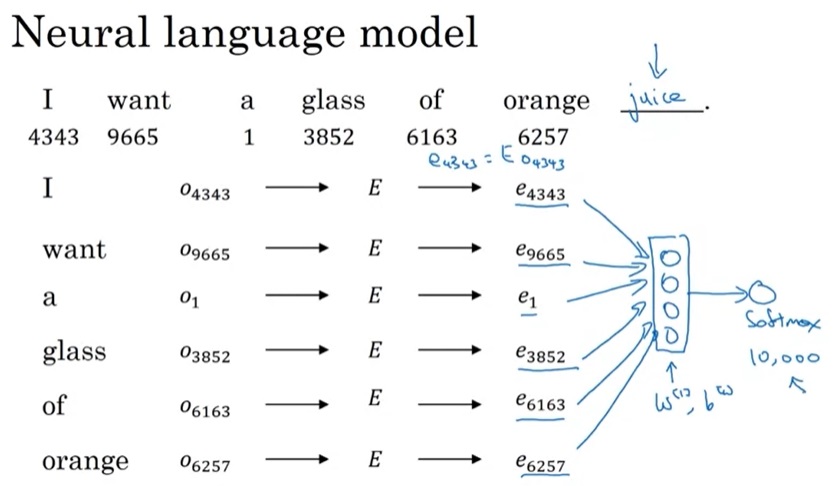
Word2Vec是一种比语言模型更高效的词嵌入学习算法。与语言模型任务的思想类似,Word2Vec也要完成一个单词预测任务:给定一个上下文(context)单词,要求模型预测一个目标(target)单词。但是,这个目标单词不只是上下文单词的后一个单词,而是上下文单词前后10个单词中任意一个单词。比如在句子”I want a glass of orange juice to go along with my cereal”中,对于上下文单词glass,目标单词可以是juice, glass, my。
I went and saw this movie last night after being coaxed to by a few friends of mine. I’ll admit that I was reluctant to see it because from what I knew of Ashton Kutcher he was only able to do comedy. I was wrong. Kutcher played the character of Jake Fischer very well, and Kevin Costner played Ben Randall with such professionalism. ……
This is a pale imitation of ‘Officer and a Gentleman.’ There is NO chemistry between Kutcher and the unknown woman who plays his love interest. The dialog is wooden, the situations hackneyed.
defmain(): lines = read_imdb() print('Length of the file:', len(lines)) print('lines[0]:', lines[0]) tokenizer = get_tokenizer('basic_english') tokens = tokenizer(lines[0]) print('lines[0] tokens:', tokens)
if __name__ == '__main__': main()
输出:
text
1 2 3
Length of the file: 12500 lines[0]: This is a very light headed comedy about a wonderful ... lines[0] tokens: ['this', 'is', 'a', 'very', 'light', 'headed', 'comedy', 'about', 'a', 'wonderful', ...
for x, y in train_dataloader: batchsize = y.shape[0] x = x.to(device) y = y.to(device) hat_y = model(x) hat_y = hat_y.squeeze(-1) loss = citerion(hat_y, y)
U.S. stock indexes fell Tuesday, driven by expectations for tighter Federal Reserve policy and an energy crisis in Europe. Stocks around the globe have come under pressure in recent weeks as worries about tighter monetary policy in the U.S. and a darkening economic outlook in Europe have led investors to sell riskier assets.
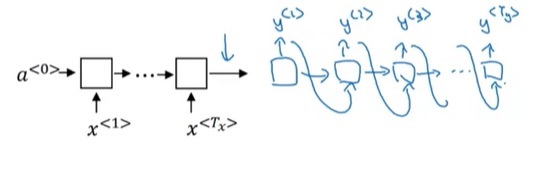
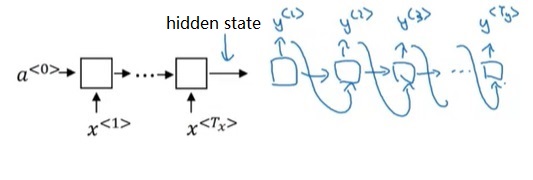
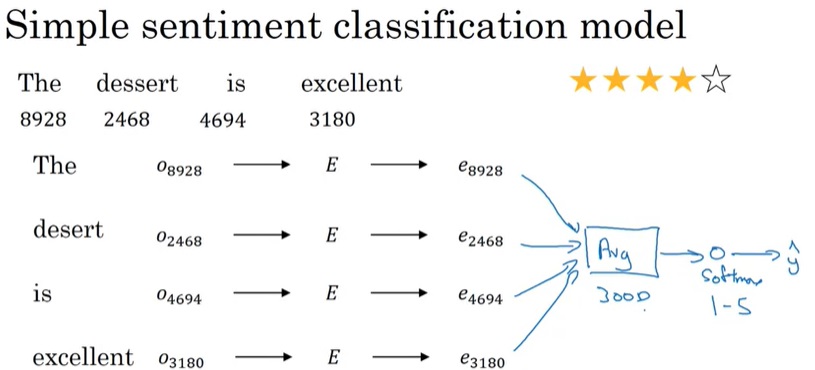
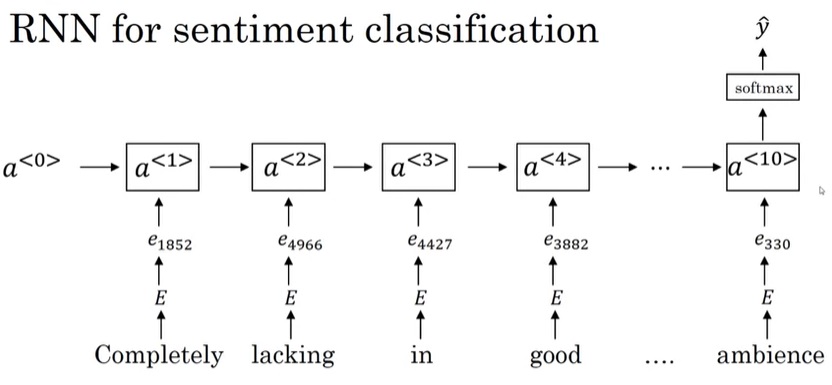
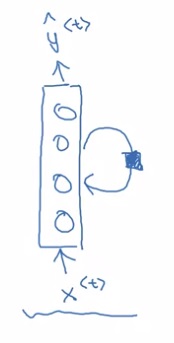
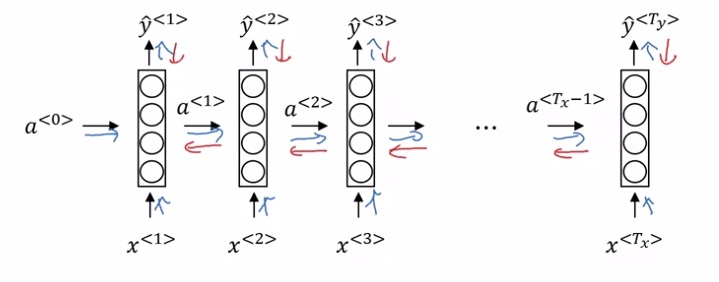
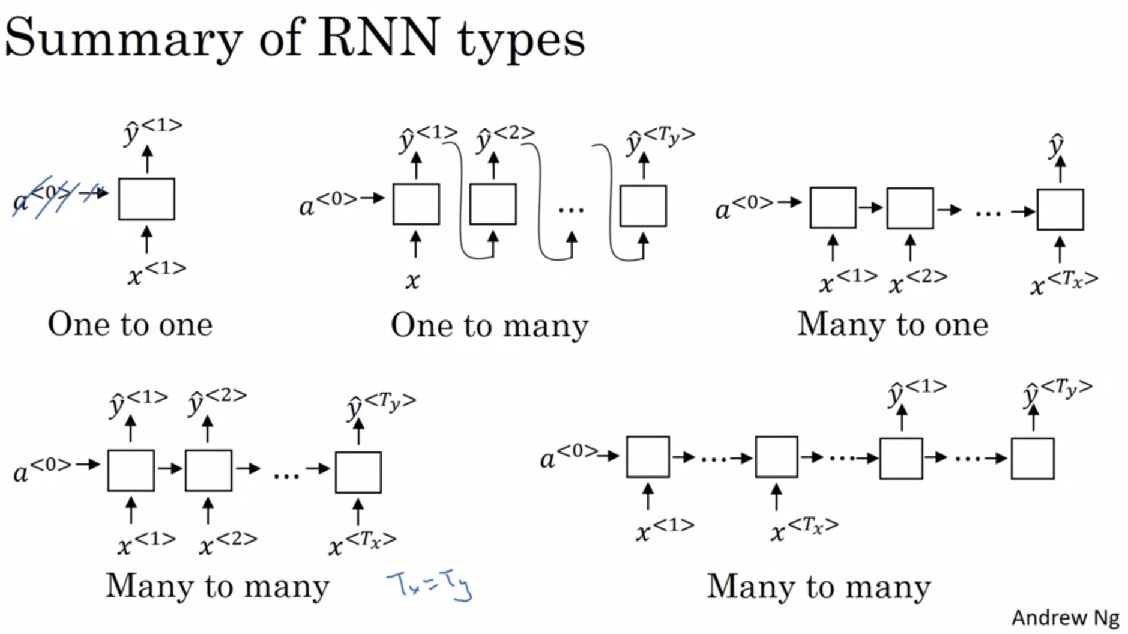
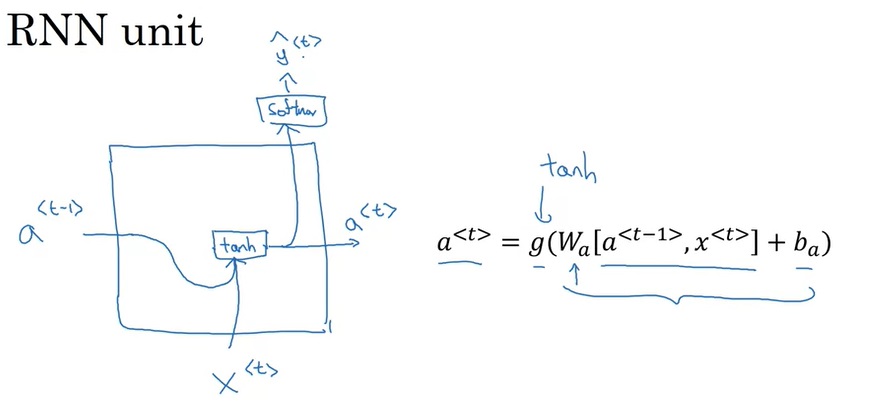
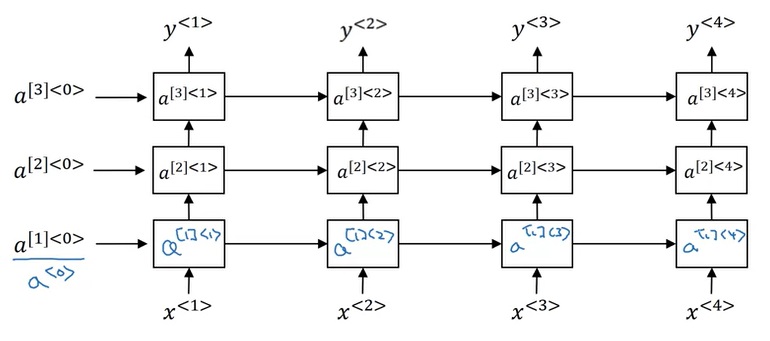
RNN运算过程如下图所示。在RNN中,对于一个样本,我们每次只输入一个单词$x^{< t >}$,得到一个输出$y^{< t >}$。除了输出$y^{< t >}$外,神经网络还会把中间激活输出$a^{< t >}$传递给下一轮计算,这个$a^{< t >}$记录了之前单词的某些信息。所有的输出按照这种方法依次计算。当然,第一轮计算时也会用到激活输出$a^{< 0 >}$,简单地令$a^{< 0 >}$为零张量即可。注意,所有的计算都是用同一个权重一样的神经网络。
语言模型是NLP中的一个基础任务。一个语言模型能够输出某种语言某句话的出现概率。通过比较不同句子的出现概率,我们能够开发出很多应用。比如在英语里,同音的”apple and pear”比”apple and pair”的出现概率高(更可能是一个合理的句子)。当一个语音识别软件听到这句话时,可以分别写下这两句发音相近的句子,再根据语言模型断定这句话应该写成前者。
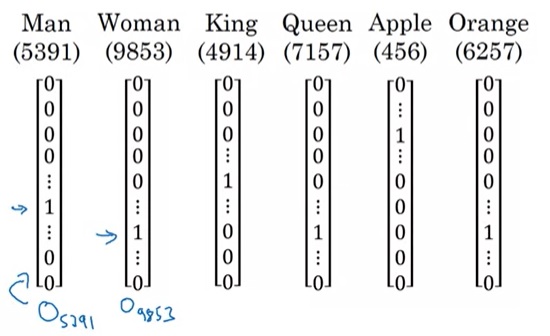
由于语料库中包含的是自然语言,而RNN的输入是one-hot编码,所以这中间要经过一个预处理的步骤。在NLP中,这一步骤叫做符号化(tokenize)。如我们在「符号标记」一节所学的,我们可以找来一个大小为10000的词汇表,根据每个单词在词汇表中的位置,生成一个one-hot编码。除了普通的词汇外,NLP中还有一些特殊的符号,比如表示句尾的<EOS> (End Of Sentence),表示词汇表里没有的词的<UNK> (Unknown)。
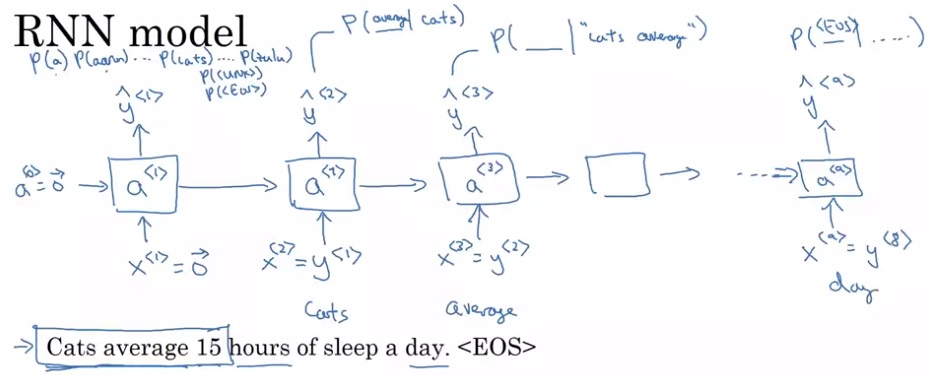
这个计算过程初次接触时有些令人费解,我们慢慢来看懂它。先竖着看一轮计算是怎么完成的。对于每一轮计算,都会给定一个单词编码$x^{< i >}$,输出一个softmax后的概率分布$\hat{y}^{< i >}$,它要对齐的训练标签是训练集某一句话的某个单词$y^{< i >}$。$\hat{y}$表示接收之前所有的输入单词后,此时刻应该输出某单词的概率分布,这个输出的含义和多分类中的类似。
我们刚刚学过,在计算一句话的概率时,RNN会把句子里的每一个单词输入,输出单词出现在前几个单词之后的概率分布$\hat{y}$。反过来想,我们可以根据RNN输出的概率分布,随机采样出某一个单词的下一个单词出来。具体来说,我们先随机生成句子里的第一个单词,把它输入RNN。再用RNN生成概率分布,对概率分布采样出下一个单词,采样出一个单词就输入一个单词,直到采样出< EOS >。这个过程就好像是在让AI生成句子一样。
语言模型是NLP中的一个基础任务。假设我们以单词为基本元素,句子为序列,那么一个语言模型能够输出某句话的出现概率。通过比较不同句子的出现概率,我们能够开发出很多应用。比如在英语里,同音的”apple and pear”比”apple and pair”的出现概率高(更可能是一个合理的句子)。当一个语音识别软件听到这句话时,可以分别写下这两句发音相近的句子,再根据语言模型断定这句话应该写成前者。
words = re.sub(u'([^\u0020\u0061-\u007a])', '', words)
这样,一个读取词汇表文件的函数就长这样:
1 2 3 4 5 6 7 8 9
defread_imdb_vocab(dir='data/aclImdb'): fn = os.path.join(dir, 'imdb.vocab') withopen(fn, 'rb') as f: word = f.read().decode('utf-8').replace('\n', ' ') words = re.sub(u'([^\u0020\u0061-\u007a])', '', word.lower()).split(' ') filtered_words = [w for w in words iflen(w) > 0]
lines = read_imdb() print('Length of the file:', len(lines)) print('lines[0]:', lines[0]) words = read_imdb_words(n_files=100) print('Length of the words:', len(words)) for i inrange(5): print(words[i])
text
1 2 3 4 5 6 7 8 9 10
the and Length of the file: 12500 lines[0]: Bromwell High is a cartoon ... Length of the words: 23425 bromwell high is a cartoon
def__getitem__(self, index): """return the (one-hot) encoding vector of a word""" word = self.words[index] + ' ' word_length = len(word) if self.is_onehot: tensor = torch.zeros(self.max_length, EMBEDDING_LENGTH) for i inrange(self.max_length): if i < word_length: tensor[i][LETTER_MAP[word[i]]] = 1 else: tensor[i][0] = 1 else: tensor = torch.zeros(self.max_length, dtype=torch.long) for i inrange(word_length): tensor[i] = LETTER_MAP[word[i]]
def__getitem__(self, index): """return the (one-hot) encoding vector of a word""" word = self.words[index] + ' ' word_length = len(word) if self.is_onehot: tensor = torch.zeros(self.max_length, EMBEDDING_LENGTH) for i inrange(self.max_length): if i < word_length: tensor[i][LETTER_MAP[word[i]]] = 1 else: tensor[i][0] = 1 else: tensor = torch.zeros(self.max_length, dtype=torch.long) for i inrange(word_length): tensor[i] = LETTER_MAP[word[i]]
return tensor
注意!短单词的填充部分应该全是空字符。千万不要忘记给空字符的one-hot编码赋值。
1 2 3 4 5
for i inrange(self.max_length): if i < word_length: tensor[i][LETTER_MAP[word[i]]] = 1 else: tensor[i][0] = 1
defget_dataloader_and_max_length(limit_length=None, is_onehot=True, is_vocab=True): if is_vocab: words = read_imdb_vocab() else: words = read_imdb_words(n_files=200)
max_length = 0 for word in words: max_length = max(max_length, len(word))
if limit_length isnotNoneand max_length > limit_length: words = [w for w in words iflen(w) <= limit_length] max_length = limit_length
a = torch.zeros(batch, self.hidden_units, device=word.device) x = torch.zeros(batch, EMBEDDING_LENGTH, device=word.device) for i inrange(Tx): next_a = self.tanh(self.linear_a(torch.cat((a, x), 1))) hat_y = self.linear_y(next_a) output[i] = hat_y x = word[i] a = next_a
a = torch.zeros(batch, self.hidden_units, device=word.device) x = torch.zeros(batch, EMBEDDING_LENGTH, device=word.device) for i inrange(Tx): next_a = self.tanh(self.linear_a(torch.cat((a, x), 1))) hat_y = self.linear_y(next_a) output[i] = hat_y x = word[i] a = next_a
#define CHECK_CUDA(x) \ TORCH_CHECK(x.device().is_cuda(), #x " must be a CUDA tensor") #define CHECK_CPU(x) \ TORCH_CHECK(!x.device().is_cuda(), #x " must be a CPU tensor") #define CHECK_CONTIGUOUS(x) \ TORCH_CHECK(x.is_contiguous(), #x " must be contiguous") #define CHECK_CUDA_INPUT(x) \ CHECK_CUDA(x); \ CHECK_CONTIGUOUS(x) #define CHECK_CPU_INPUT(x) \ CHECK_CPU(x); \ CHECK_CONTIGUOUS(x)
#define CUDA_1D_KERNEL_LOOP(i, n) \ for (int i = blockIdx.x * blockDim.x + threadIdx.x; i < (n); \ i += blockDim.x * gridDim.x)
#define CUDA_2D_KERNEL_LOOP(i, n, j, m) \ for (size_t i = blockIdx.x * blockDim.x + threadIdx.x; i < (n); \ i += blockDim.x * gridDim.x) \ for (size_t j = blockIdx.y * blockDim.y + threadIdx.y; j < (m); \ j += blockDim.y * gridDim.y)
#define CUDA_2D_KERNEL_BLOCK_LOOP(i, n, j, m) \ for (size_t i = blockIdx.x; i < (n); i += gridDim.x) \ for (size_t j = blockIdx.y; j < (m); j += gridDim.y)
#define THREADS_PER_BLOCK 512
inlineintGET_BLOCKS(constint N, constint num_threads = THREADS_PER_BLOCK){ int optimal_block_num = (N + num_threads - 1) / num_threads; int max_block_num = 4096; returnmin(optimal_block_num, max_block_num); }
template <typename T> __device__ T bilinear_interpolate(const T* input, constint height, constint width, T y, T x, constint index /* index for debug only*/){ // deal with cases that inverse elements are out of feature map boundary if (y < -1.0 || y > height || x < -1.0 || x > width) return0;
if (y <= 0) y = 0; if (x <= 0) x = 0;
int y_low = (int)y; int x_low = (int)x; int y_high; int x_high;
voidmy_conv_shape_check(at::Tensor input, at::Tensor weight, int kH, int kW, int dH, int dW, int padH, int padW, int dilationH, int dilationW, int group) { TORCH_CHECK( weight.ndimension() == 4, "4D weight tensor (nOutputPlane,nInputPlane,kH,kW) expected, but got: %s", weight.ndimension());
TORCH_CHECK(weight.is_contiguous(), "weight tensor has to be contiguous");
TORCH_CHECK(kW > 0 && kH > 0, "kernel size should be greater than zero, but got kH: %d kW: %d", kH, kW);
TORCH_CHECK((weight.size(2) == kH && weight.size(3) == kW), "kernel size should be consistent with weight, ", "but got kH: %d kW: %d weight.size(2): %d, weight.size(3): %d", kH, kW, weight.size(2), weight.size(3));
TORCH_CHECK(dW > 0 && dH > 0, "stride should be greater than zero, but got dH: %d dW: %d", dH, dW);
TORCH_CHECK( dilationW > 0 && dilationH > 0, "dilation should be greater than 0, but got dilationH: %d dilationW: %d", dilationH, dilationW);
int ndim = input.ndimension(); int dimf = 0; int dimh = 1; int dimw = 2;
if (ndim == 4) { dimf++; dimh++; dimw++; }
TORCH_CHECK(ndim == 3 || ndim == 4, "3D or 4D input tensor expected but got: %s", ndim);
long nInputPlane = weight.size(1) * group; long inputHeight = input.size(dimh); long inputWidth = input.size(dimw); long nOutputPlane = weight.size(0); long outputHeight = (inputHeight + 2 * padH - (dilationH * (kH - 1) + 1)) / dH + 1; long outputWidth = (inputWidth + 2 * padW - (dilationW * (kW - 1) + 1)) / dW + 1;
if (outputWidth < 1 || outputHeight < 1) AT_ERROR( "Given input size: (%ld x %ld x %ld). " "Calculated output size: (%ld x %ld x %ld). Output size is too small", nInputPlane, inputHeight, inputWidth, nOutputPlane, outputHeight, outputWidth);
TORCH_CHECK(input.size(1) == nInputPlane, "invalid number of input planes, expected: %d, but got: %d", nInputPlane, input.size(1));
TORCH_CHECK((inputHeight >= kH && inputWidth >= kW), "input image is smaller than kernel"); }
voidmy_conv_forward(Tensor input, Tensor weight, Tensor bias, Tensor output, Tensor columns, int kW, int kH, int dW, int dH, int padW, int padH, int dilationW, int dilationH, int group, int im2col_step) { bool isCuda = false; if (input.device().is_cuda()) { CHECK_CUDA_INPUT(input); CHECK_CUDA_INPUT(weight); CHECK_CUDA_INPUT(bias); CHECK_CUDA_INPUT(output); CHECK_CUDA_INPUT(columns); isCuda = true; } else { CHECK_CPU_INPUT(input); CHECK_CPU_INPUT(weight); CHECK_CPU_INPUT(bias); CHECK_CPU_INPUT(output); CHECK_CPU_INPUT(columns); }
voidmy_conv_forward(Tensor input, Tensor weight, Tensor bias, Tensor output, Tensor columns, int kW, int kH, int dW, int dH, int padW, int padH, int dilationW, int dilationH, int group, int im2col_step)
import torch from torch.autograd import Function import torch.nn as nn from torch import Tensor from torch.nn.modules.utils import _pair from torch.nn.parameter import Parameter
// Modify from https://github.com/open-mmlab/mmcv/blob/my_conv/mmcv/ops/csrc/common/cuda/deform_conv_cuda_kernel.cuh // Copyright (c) OpenMMLab. All rights reserved. #include<torch/types.h>