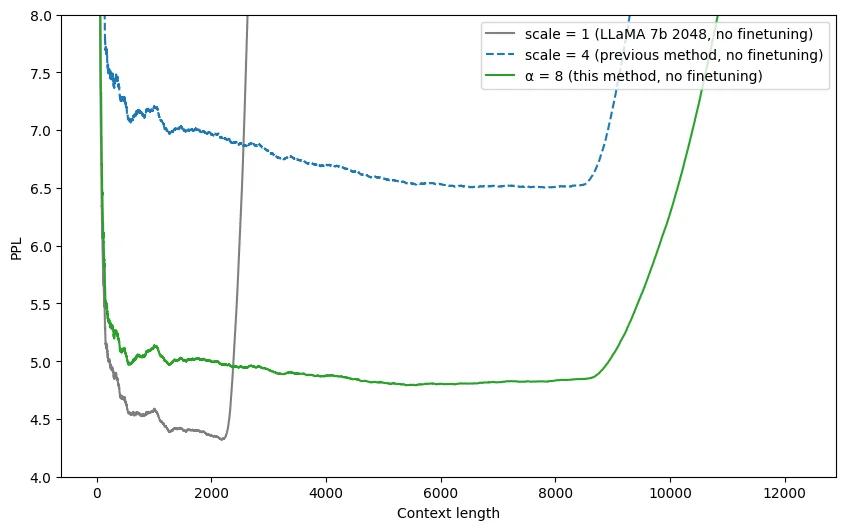
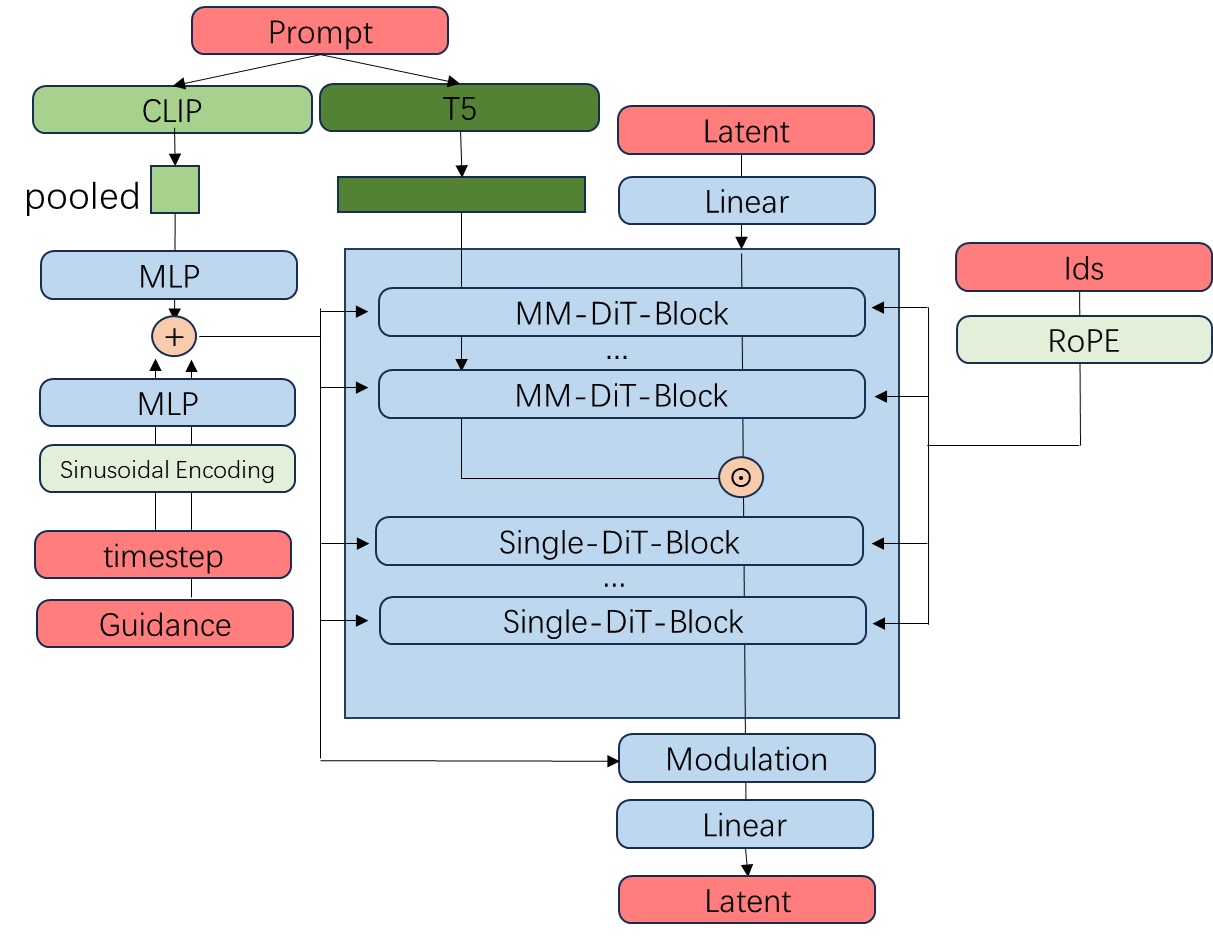
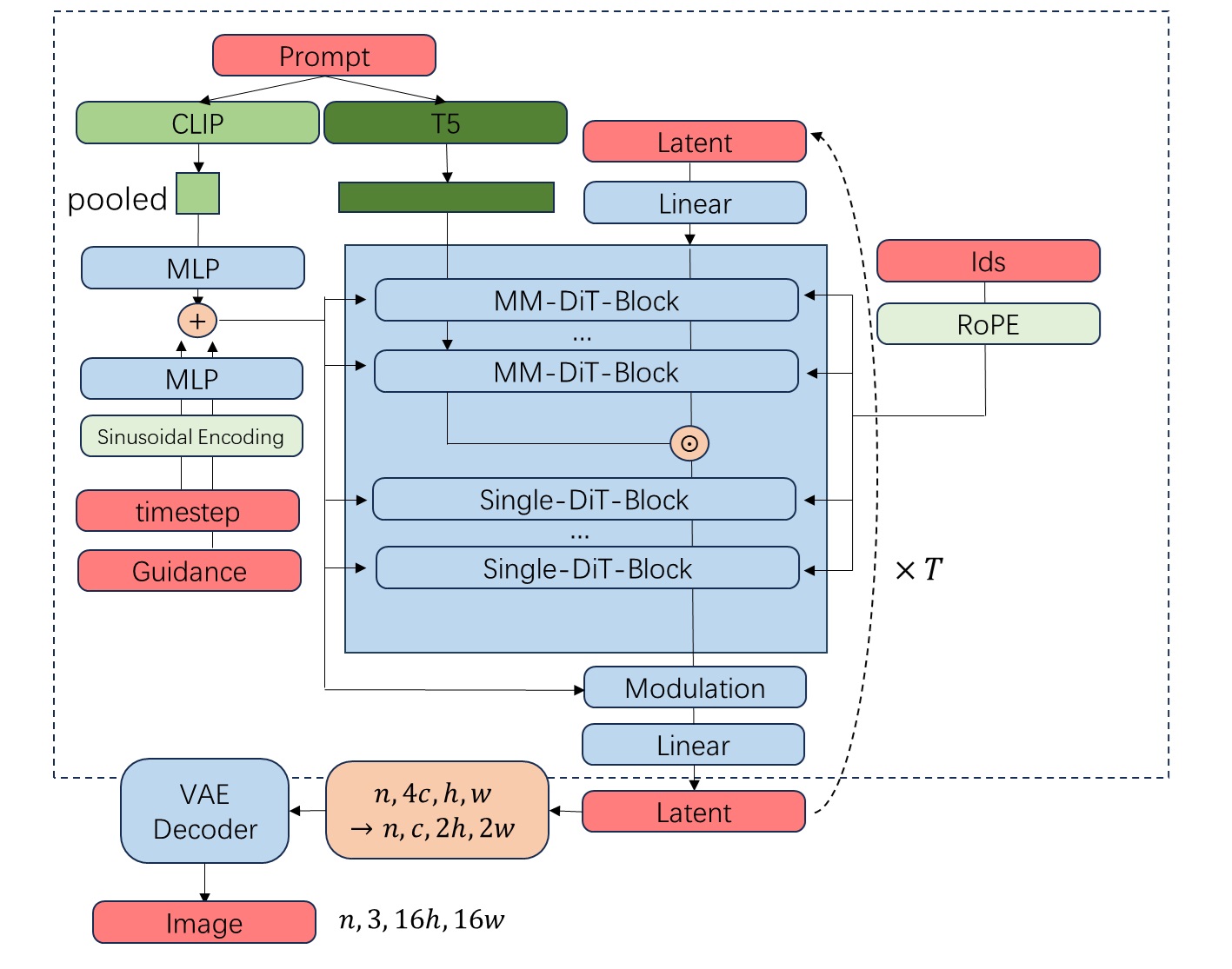
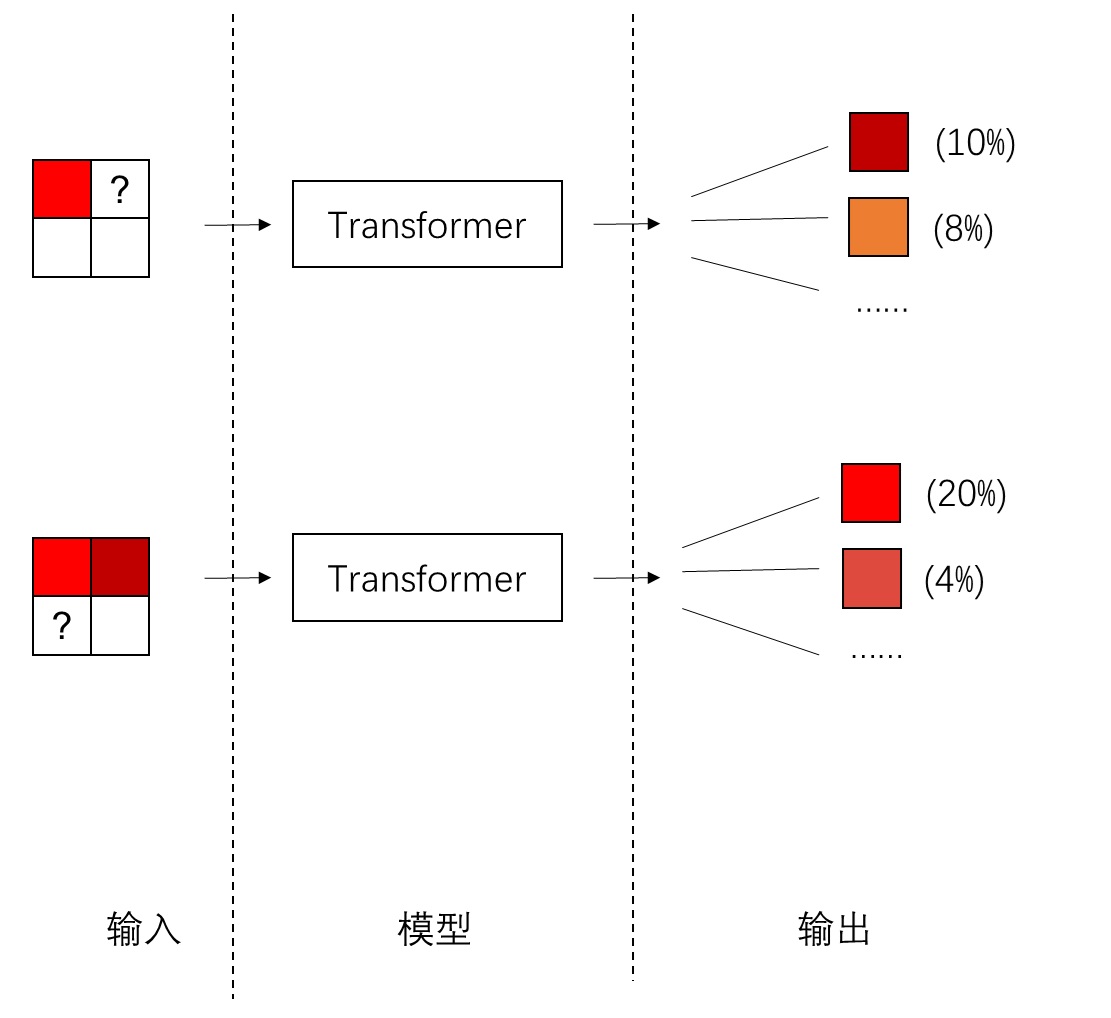
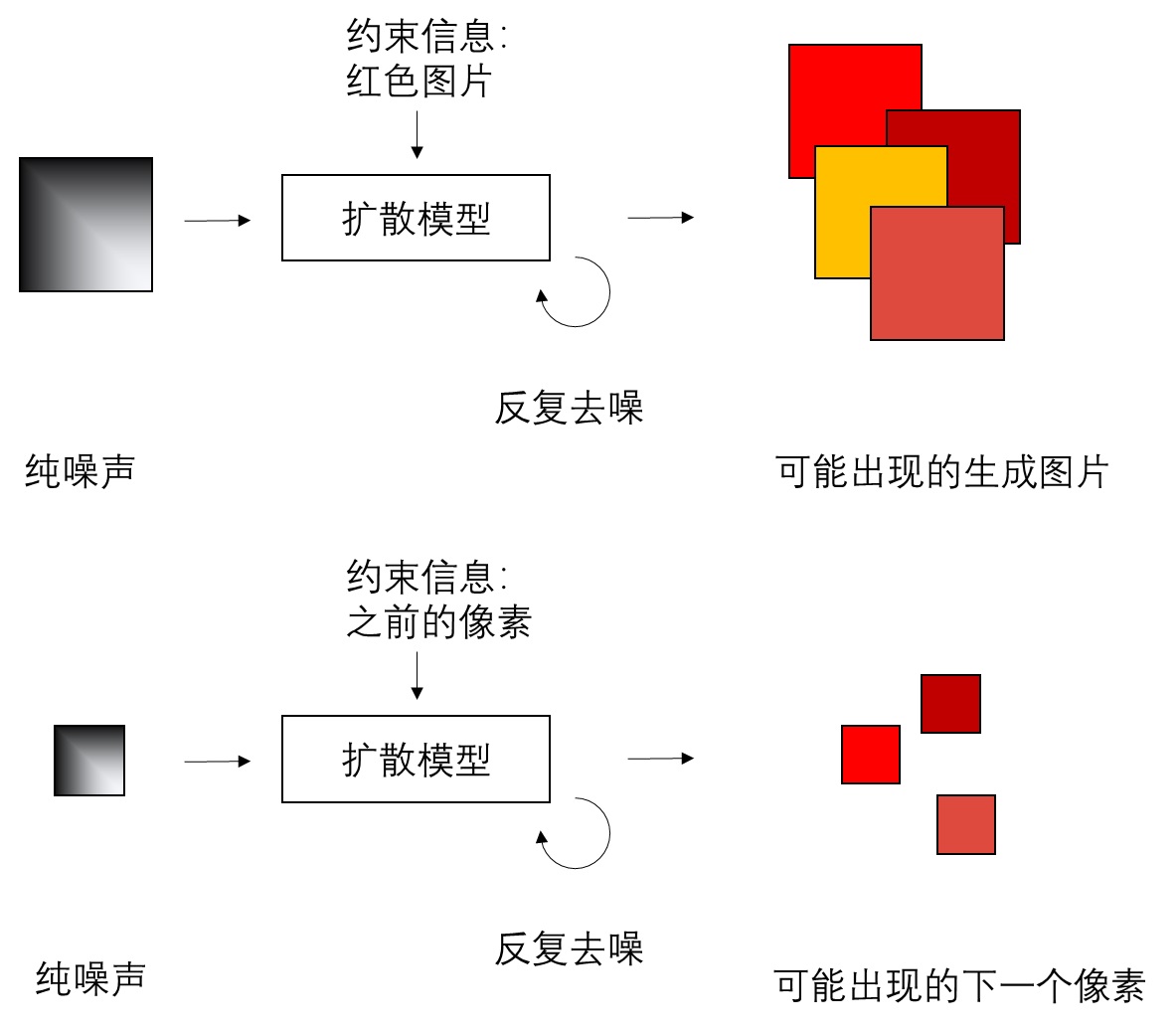
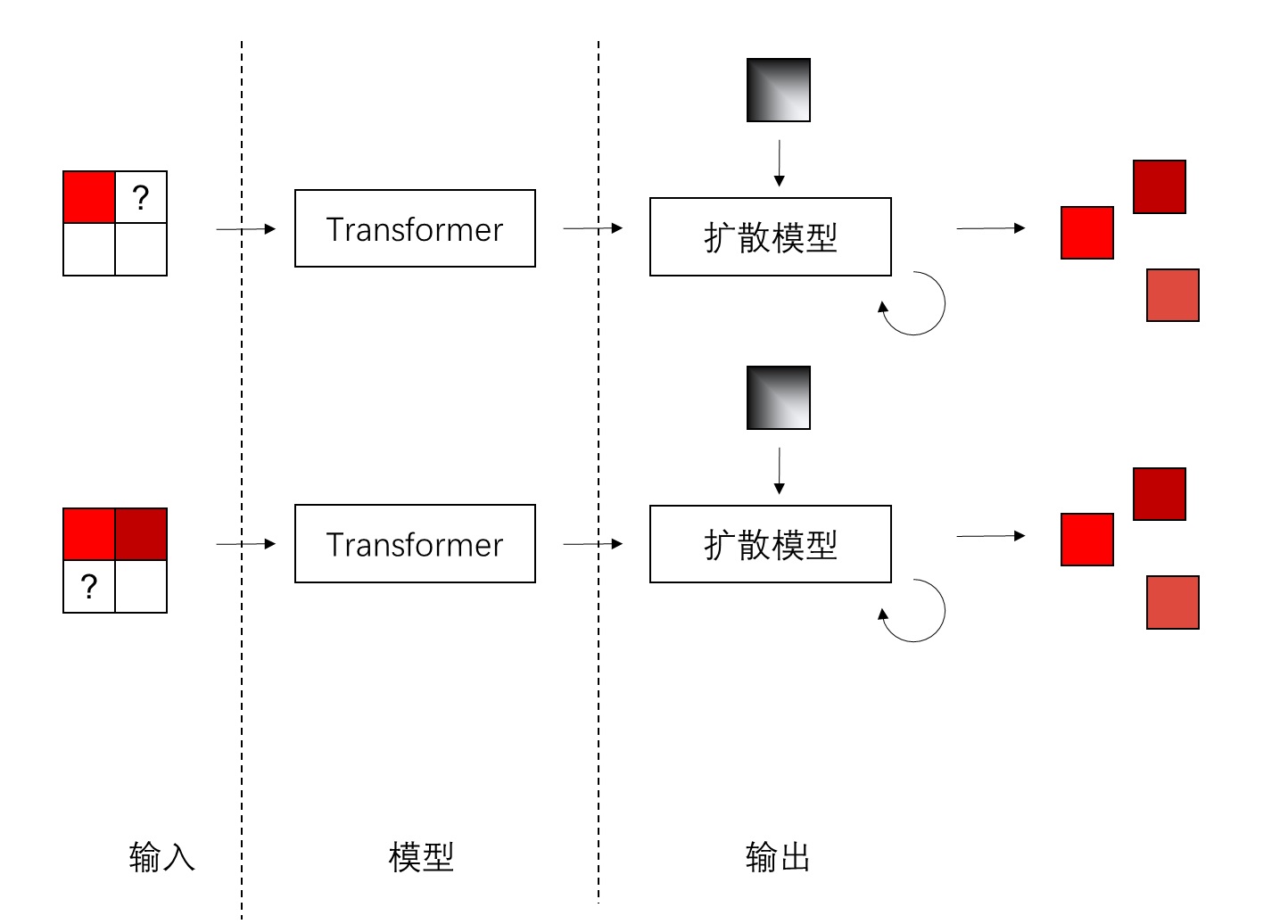
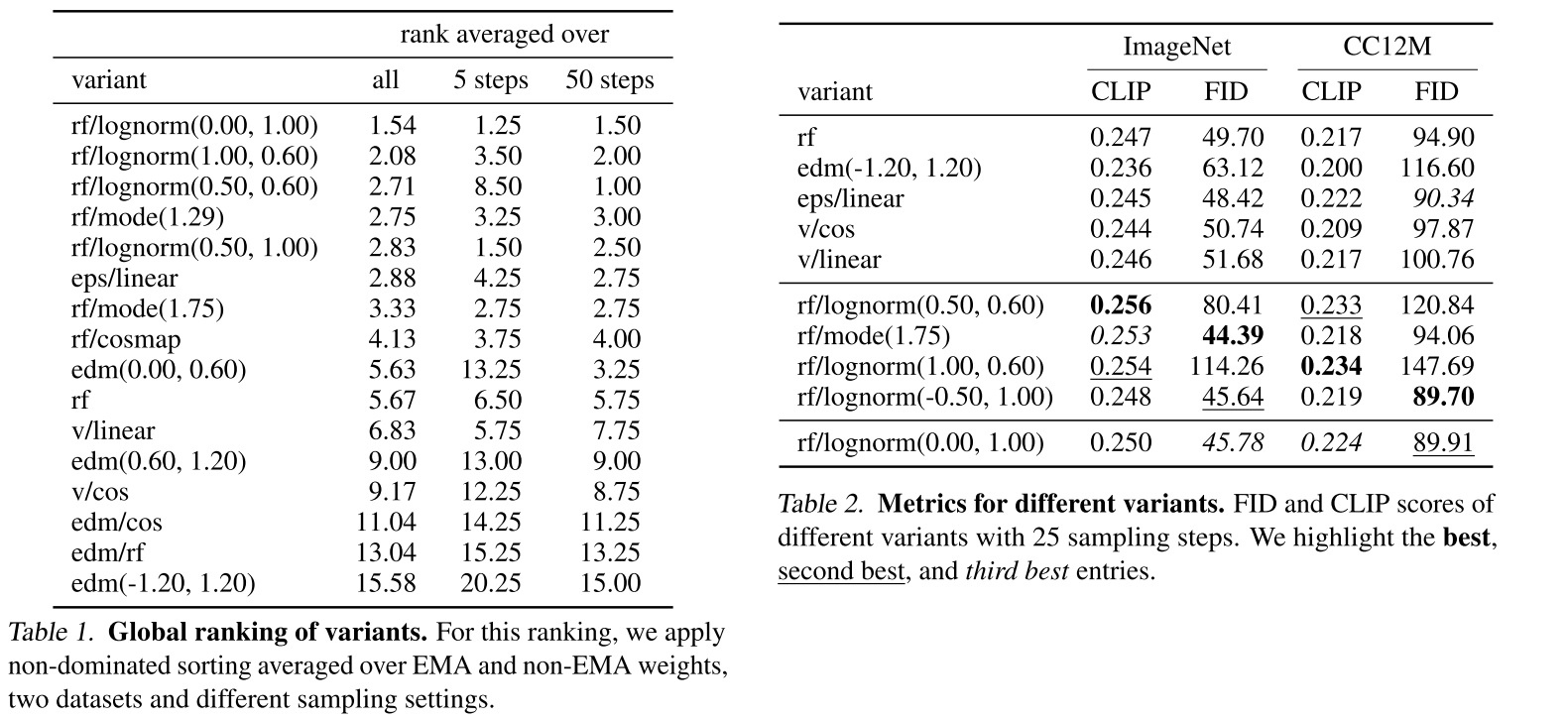
Lumina-Next,前沿扩散 Transformer (Diffusion Transformer, DIT) 模型,采用了长度外推技术:Lumina-Next : Making Lumina-T2X Stronger and Faster with Next-DiT (https://arxiv.org/abs/2406.18583)
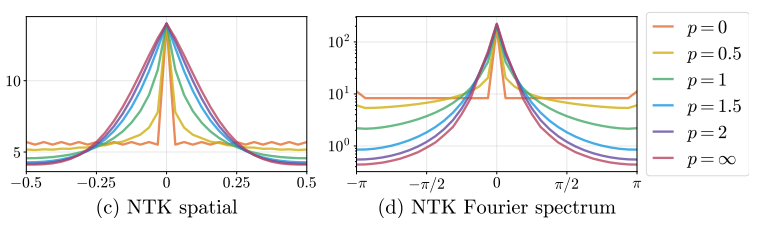
近几年和 NTK 理论比较相关的论文叫做 Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains。这篇论文用 NTK 理论分析了 NeRF 这种以位置坐标为输入的 MLP 需要位置编码的原因,并将这类位置编码归纳为「傅里叶特征」。
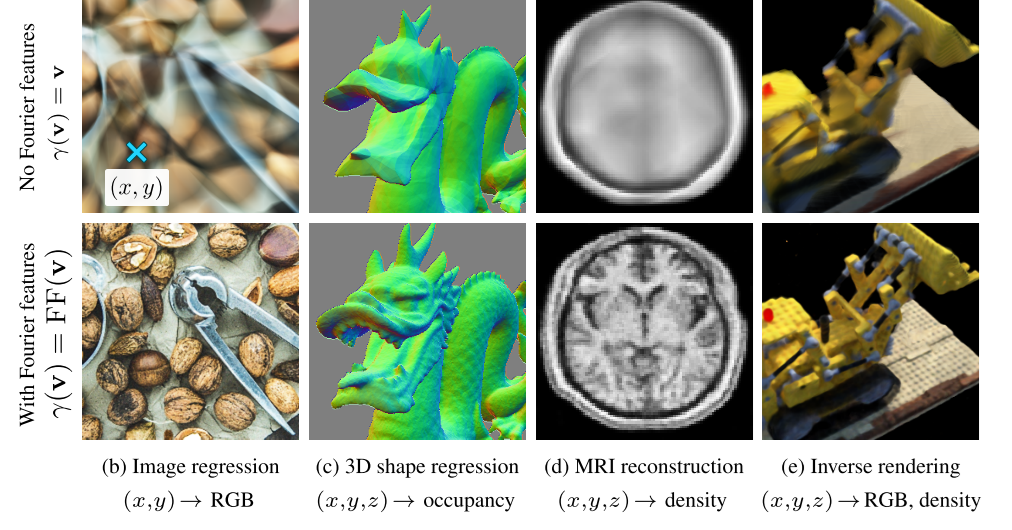
在这篇文章里,我主要基于论文 Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains (后文简称为「傅里叶特征论文」),介绍傅里叶特征这一概念。为了讲清这些理论的发展脉络,我会稍微讲一下 NTK 等理论概念。介绍完傅里叶特征后,我还会讲解它在其他方法中的应用。希望读完本文后,读者能够以这篇论文为基点,建立一个有关位置编码原理的知识网络,以从更深的层次来思考新的科研方向。
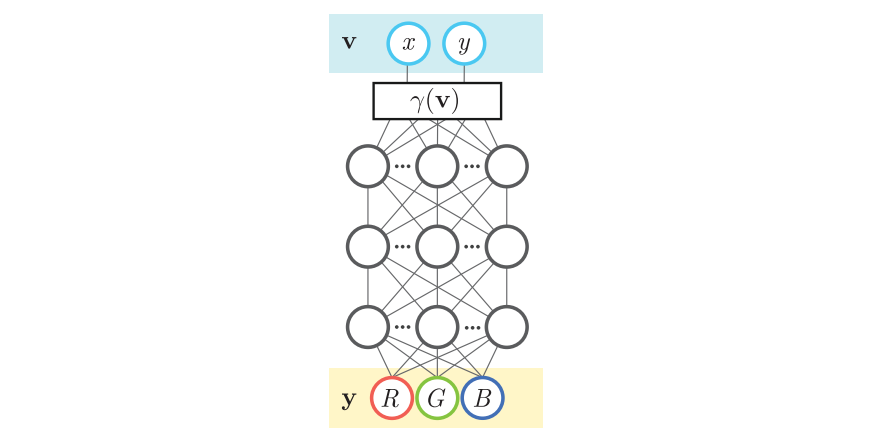
这种连续数据有什么好处呢?我们知道,计算机都是以离散的形式来存储数据的。比如,我们会把图像拆成一个个像素,每个像素存在一块内存里。对于图像这种二维数据,计算机的存储空间还勉强够用。而如果想用密集的离散数据表达更复杂的数据,比如 3D 物体,计算机的容量就捉襟见肘了。但如果用一个 MLP 来表达 3D 物体的话,我们只需要存储 MLP 的参数,就能获取 3D 物体在任何位置的信息了。
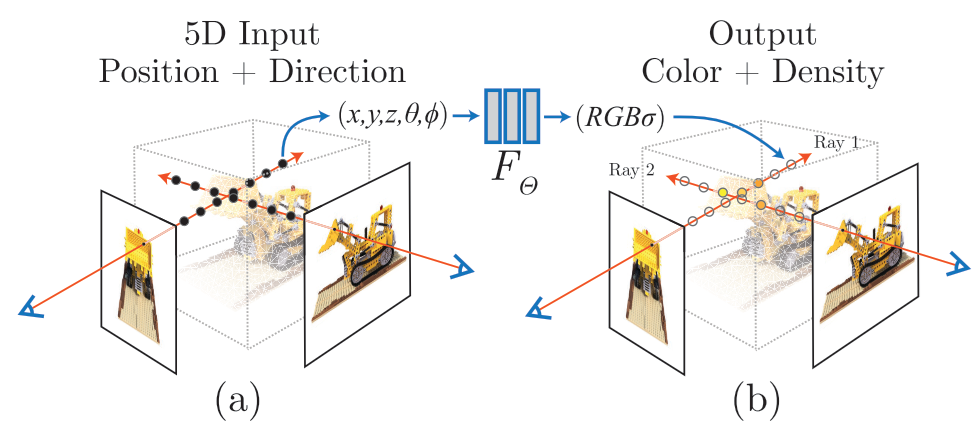
这就是经典工作神经辐射场 (Neural Radiance Field, NeRF) 的设计初衷。NeRF 用一个 MLP 拟合 3D 物体的属性,其输入输出如下图所示。我们可以用 MLP 学习每个 3D 坐标的每个 2D 视角处的属性(这篇文章用的属性是颜色和密度)。根据这些信息,利用某些渲染算法,我们就能重建完整的 3D 物体。
import torch import torch.nn as nn import torch.nn.functional as F from torchvision.io import read_image, ImageReadMode from torchvision.transforms.functional import to_pil_image
from tqdm import tqdm from einops import rearrange
classFourierFeature(nn.Module): def__init__(self, in_c, out_c, scale): super().__init__() fourier_basis = torch.randn(in_c, out_c // 2) * scale self.register_buffer('_fourier_basis', fourier_basis) defforward(self, x): N, C, H, W = x.shape x = rearrange(x, 'n c h w -> (n h w) c') x = x @ self._fourier_basis x = rearrange(x, '(n h w) c -> n c h w', h = H, w = W) x = 2 * torch.pi * x x = torch.cat([torch.sin(x), torch.cos(x)], dim=1) return x feature_length = 256 model = MLP(feature_length).to(device) fourier_feature = FourierFeature(2, feature_length, 10).to(device) optimizer = torch.optim.Adam(model.parameters(), lr=1e-4) n_loops = 400 for epoch in tqdm(range(n_loops)): x = fourier_feature(grid) output = model(x) loss = F.l1_loss(output, input_image) optimizer.zero_grad() loss.backward() optimizer.step() if epoch % 100 == 0or epoch == n_loops - 1: viz_image(output[0]) print(loss.item()) prev_output = output
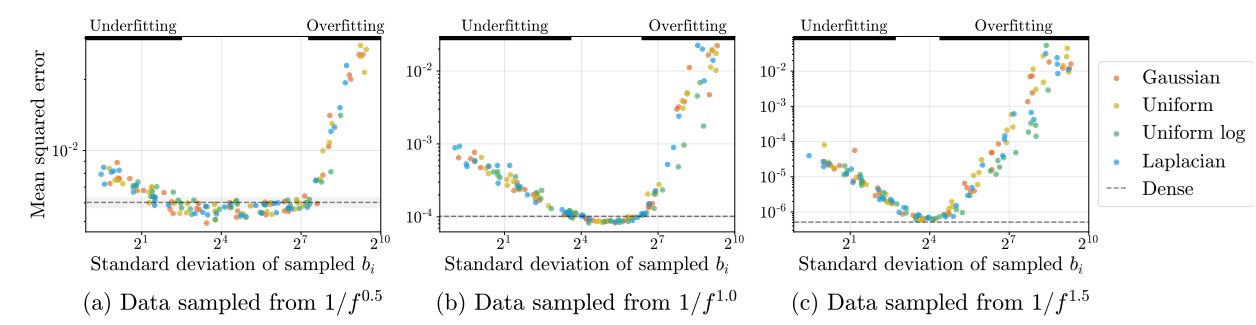
根据之前的研究 Random features for large-scale kernel machines 表明,我们不需要密集地采样傅里叶特征,只需要稀疏地采样就行了。具体来说,我们可以从某个分布随机采样 $m$ 个频率 $\mathbf{b_j}$ 来,这样的学习结果和密集采样差不多。当然,根据前面的分析,我们还是令所有系数 $a_j=1$。在实验中,作者发现,$\mathbf{b_j}$ 从哪种分布里采样都无所谓,关键是 $\mathbf{b_j}$ 的采样分布的标准差,因为这个标准差决定了傅里叶特征的带宽,也决定了网络拟合高频信息的能力。实验的结果如下:
我们可以不管图片里 $1/f^x$ 是啥意思,只需要知道 a, b, c 是三组不同的实验就行。虚线是密集采样傅里叶特征的误差,它的结果反映了一个「较好」的误差值。令人惊讶的是,不管从哪种分布里采样 $\mathbf{b_j}$,最后学出来的网络误差都差不多。问题的关键在于采样分布的标准差。把标准差调得够好的话,模型的误差甚至低于密集采样的误差。
classFourierFeature(nn.Module): def__init__(self, in_c, out_c, scale): super().__init__() fourier_basis = torch.randn(in_c, out_c // 2) * scale self.register_buffer('_fourier_basis', fourier_basis) defforward(self, x): N, C, H, W = x.shape x = rearrange(x, 'n c h w -> (n h w) c') x = x @ self._fourier_basis x = rearrange(x, '(n h w) c -> n c h w', h = H, w = W) x = 2 * torch.pi * x x = torch.cat([torch.sin(x), torch.cos(x)], dim=1) return x feature_length = 256 model = MLP(feature_length).to(device) fourier_feature = FourierFeature(2, feature_length, 10).to(device) optimizer = torch.optim.Adam(model.parameters(), lr=1e-4) n_loops = 400 for epoch in tqdm(range(n_loops)): x = fourier_feature(grid) output = model(x) loss = F.l1_loss(output, input_image) optimizer.zero_grad() loss.backward() optimizer.step() if epoch % 100 == 0or epoch == n_loops - 1: viz_image(output[0]) print(loss.item()) prev_output = output
傅里叶特征通过类 FourierFeature 实现。其代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classFourierFeature(nn.Module): def__init__(self, in_c, out_c, scale): super().__init__() fourier_basis = torch.randn(in_c, out_c // 2) * scale self.register_buffer('_fourier_basis', fourier_basis) defforward(self, x): N, C, H, W = x.shape x = rearrange(x, 'n c h w -> (n h w) c') x = x @ self._fourier_basis x = rearrange(x, '(n h w) c -> n c h w', h = H, w = W) x = 2 * torch.pi * x x = torch.cat([torch.sin(x), torch.cos(x)], dim=1) return x
构造函数里的 fourier_basis 表示随机傅里叶特征的频率,对应论文公式里的$\mathbf{b}$,scale 表示采样的标准差。初始化好了随机频率后,对于输入位置 x,只要按照公式将其投影到长度为 out_c / 2 的向量上,再对向量的每一个分量求 sin, cos 即可。按照之前的分析,我们令所有系数 $a$ 为 $1$,所以不需要对输出向量乘系数。
之后,我们来尝试在傅里叶特征中只用正弦函数。我们将投影矩阵的输出通道数从 out_c / 2 变成 out_c,再在 forward 里只用 sin 而不是同时用 sin, cos。经实验,这样改了后完全不影响重建质量,甚至由于通道数更多了,重建效果更好了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classFourierFeature(nn.Module): def__init__(self, in_c, out_c, scale): super().__init__() fourier_basis = torch.randn(in_c, out_c) * scale self.register_buffer('_fourier_basis', fourier_basis) defforward(self, x): N, C, H, W = x.shape x = rearrange(x, 'n c h w -> (n h w) c') x = x @ self._fourier_basis x = rearrange(x, '(n h w) c -> n c h w', h = H, w = W) x = 2 * torch.pi * x x = torch.sin(x) return x
只用 sin 而不是同时用 sin, cos 后,似乎我们之前对 NTK 平移不变的推导完全失效了。但是,根据三角函数的周期性可知,只要是把输入映射到三角函数上后,网络主要是从位置间的相对关系学东西。绝对位置对网络来说没有那么重要,不同的绝对位置只是让所有三角函数差了一个相位而已。只用 sin 的神经网络似乎也对绝对位置不敏感。为了证明这一点,我把原来位于 [0, 1] 间的坐标做了一个幅度为 10 的平移。结果网络的误差几乎没变。
1 2 3 4 5 6 7
for epoch in tqdm(range(n_loops)): x = fourier_feature(grid + 10) output = model2(x) loss = F.l1_loss(output, input_image) optimizer.zero_grad() loss.backward() optimizer.step()
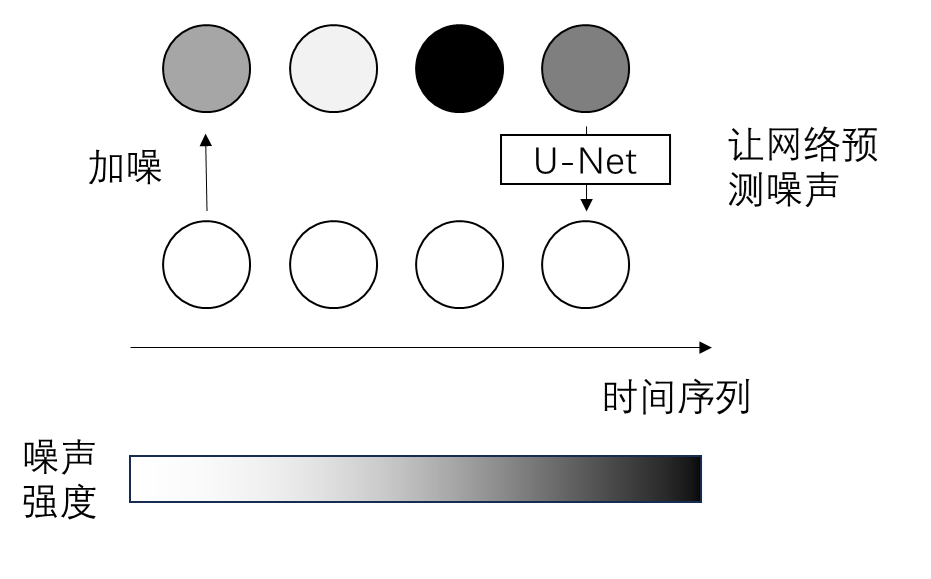
扩散模型可以直接生成任何形状的数据。如果我们不把视频视为一种由图像组成的序列数据,而是将其视为一种「三维图像」,那么我们可以直接将 2D 图像扩散模型简单地拓展成 3D 视频扩散模型。这种做法在这篇论文中被称为「全序列扩散模型」。使用这一方法的早期工作有 DDPM 的作者提出的 Video Diffusion Models。Stable Diffusion 的作者也基于 LDM 提出类似的 Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models(Video LDM)工作。
全序列扩散模型仅能生成固定长度的视频。为了将其拓展到长视频生成,还是得将其和自回归结合起来。但是,自回归视频生成存在着生成质量与训练集质量不匹配的问题。Stable Video Diffusion 等工作参考 Cascaded Diffusion Models 的做法,通过给约束图像/视频帧加噪声缓解此问题。
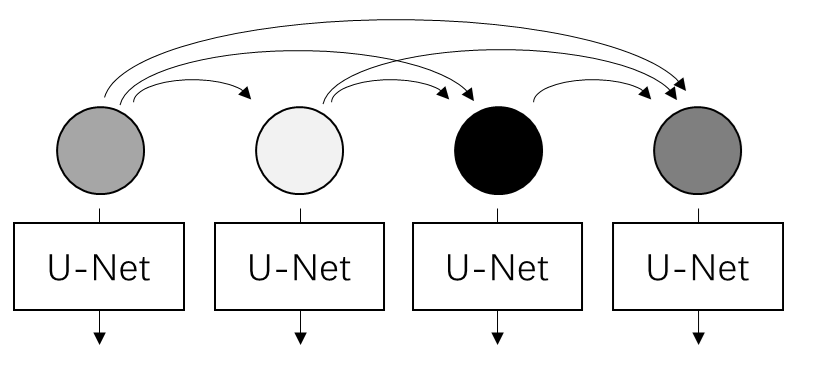
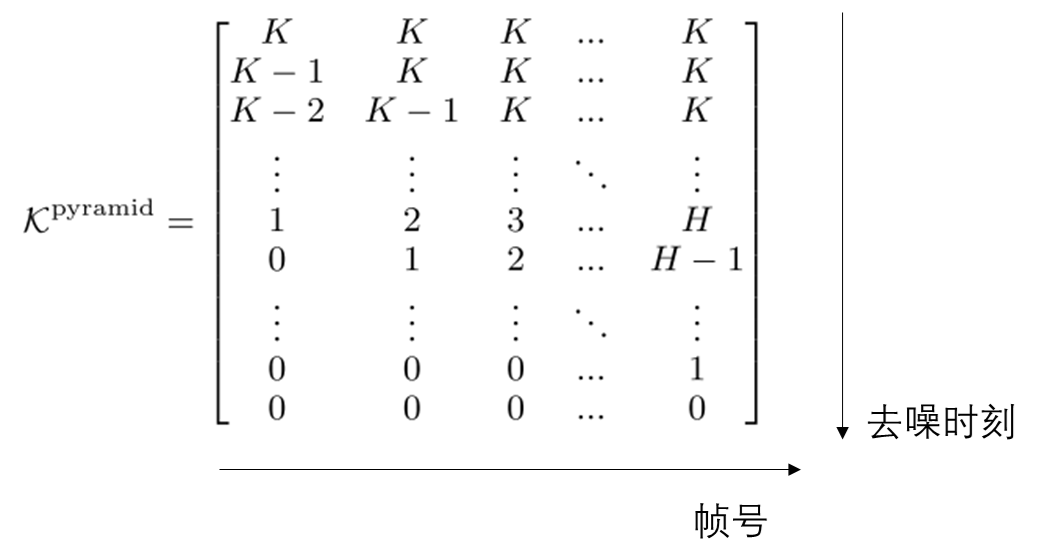
AR-Diffusion: Auto-Regressive Diffusion Model for Text Generation 进一步探讨了自回归生成与全序列扩散模型的结合方法:在生成文本时,不同时刻的文本噪声不同,越早的文本上的噪声越少。无独有偶,FIFO-Diffusion: Generating Infinite Videos from Text without Training 提到了如何在预训练视频扩散模型上,以不同的噪声强度来生成不同的视频帧。或许是受到这些工作的启发,Diffusion Forcing 系统探讨了如何在训练时独立地给序列元素添加噪声。
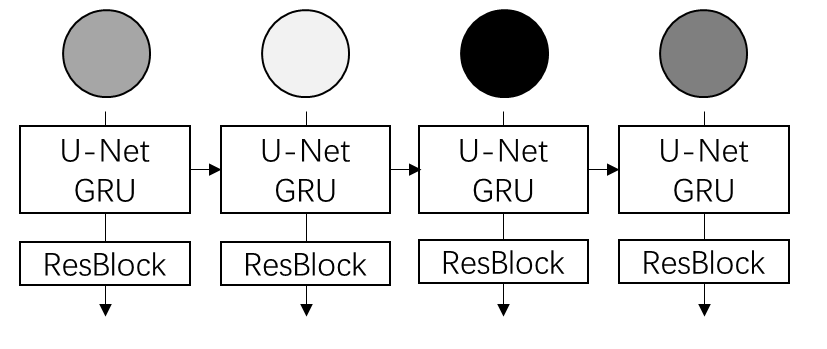
作者说出于简洁,他们在论文中用 RNN 实现了 Diffusion Forcing。但很明显 3D U-Net 才应该是直观上最简单实用的实现方法,毕竟最早期的视频扩散模型就是拿 3D U-Net 做的。在官方仓库中,有本科生帮他们实现了一个 3D U-Net 加时间注意力的模型,比原来视频模型效果要好。
这篇工作对我最大的启发是,我们一直把视频当成完整的 3D 数据来看待,却忘了视频可以被看成是图像序列。如果把视频当成 3D 数据的话,不同帧只能通过时序注意力看到其他帧在当前去噪时刻的信息;而对于序列数据,我们可以在不同帧的依赖关系上做更多设计,比如这篇工作的不同去噪强度。我很早前就在构思一种依赖更加强的序列生成范式:我们可不可以把序列中其他元素的所有去噪时刻的所有信息(包括中间去噪结果及去噪网络的中间变量)做为当前元素的约束呢?这种强约束序列模型可能对多视角生成、视频片段生成等任务的一致性有很大帮助。由于生成是约束于另一个去噪过程的,我们对此去噪过程做的任何编辑,都可以自然地传播到当前元素上。比如在视频生成中,如果整个视频约束于首帧的去噪过程,那么我们用任意基于扩散模型的图像编辑方法来编辑首帧,都可以自然地修改后续帧。当然,我只是提供一个大致的想法,暂时没有考虑细节,欢迎大家往这个方向思考。
作为一名未来的游戏设计师,每次看到这类「今天 AI 又取代了创作者」的新闻,我的第一反应总会是愤怒:创作是人类智慧的最高结晶,能做到这种程度的 AI 必然是强人工智能。但显然现在 AI 的水平没有那么高,那么这类宣传完全是无稽之谈。我带着不满看完了论文,果然这个工作并没有在技术上有革命性的突破。不过,这篇论文还是提出了一个比较新颖的科研任务并漂亮地将其解决了的,算是一篇优秀的工作。除了不要脸地将自己的模型称为「游戏引擎」外,这篇工作在宣传时还算克制,对模型的能力没有太多言过其实的描述。
为了生成足够多的图片,作者利用强化学习训练了一个玩游戏的 AI。在这一块,作者用了一个非常巧妙的设计:和其他强化学习任务不同,这个玩游戏的 AI 并不是为了将游戏漂亮地通关,而是造出尽可能多样的数据。因此,该强化学习的奖励函数包括了击中敌人、使用武器、探索地图等丰富内容,鼓励 AI 制造出不同的游戏画面。
有人可能还会说:「我也同意深度学习代替不了人类,但也不能说这些技术就完全没用」。这我非常同意,我就认为大家应该把现在的 AI 当成一种全新的工具。基于这些新工具,我们把创新的重点放在如何适配这些工具上,辅助以前的应用,或者开发一些新的应用,而不是非得一步到位直接妄想着把人类取代了。比如,根据简笔画生成图片就是一个很好的新应用啊。
这篇工作用图像模型学习了 3D 场景在移动后的变化。也就是说,模型「理解」了 3D 场景。那么,有没有办法从模型中抽取出相关的知识呢?按理说,能理解 3D,就能理解物体是有远近的。那么,深度估计、语义分割这种任务是不是可以直接用这种模型来做呢?以交互为约束的图像生成模型可能蕴含了比文生图模型更加丰富的图像知识。很可惜,不知道这篇工作最后会不会开源。
GameNGen 将模拟 3D 可交互场景的任务定义为根据历史画面、历史及当前操作生成当前画面的带约束图像生成任务。该工作用强化学习巧妙造出大量数据,用扩散模型实现带约束图像生成。结果表明,该模型不仅能自回归地生成连贯的游戏画面,还能学会子弹、血量等复杂交互信息。然而,受制于硬件及模型架构限制,模型要求的训练资源极大,且一次只能看到 3.2 秒内的信息。这种大量数据驱动的做法难以在学校级实验室里复刻,也不能够归纳至更一般的 3D 世界模拟任务上。
我个人认为,从科研的角度来看,这篇工作最大的贡献是提出了一种用带约束图像生成来描述 3D 世界模拟任务的问题建模方式。其次的贡献是确确实实通过长期的工程努力把这个想法做成功了,非常不容易。但从游戏开发的角度来看,这个工作现阶段没什么用处。
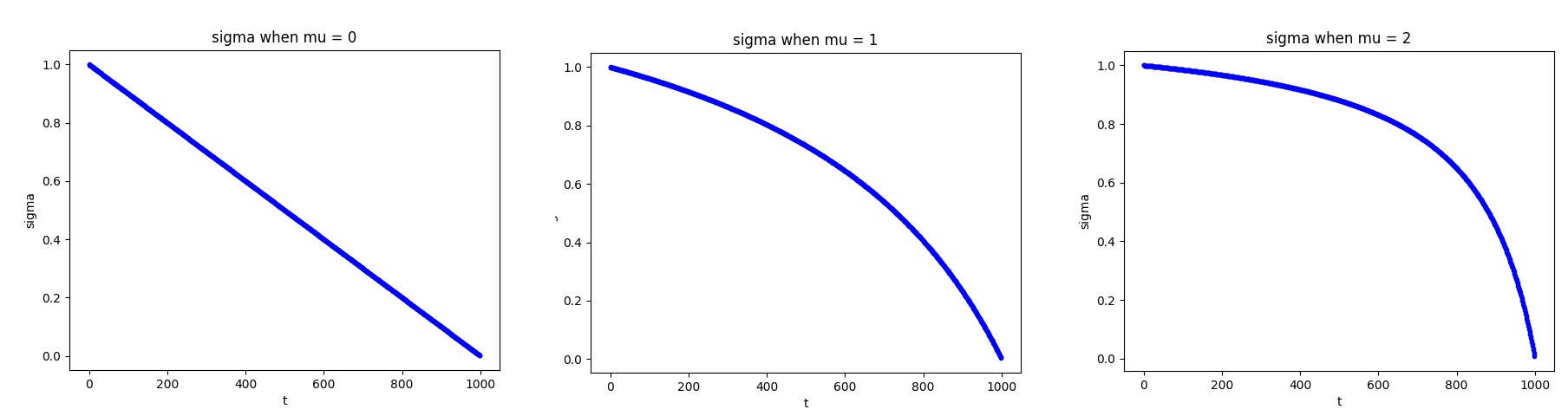
defcalculate_shift( image_seq_len, base_seq_len: int = 256, max_seq_len: int = 4096, base_shift: float = 0.5, max_shift: float = 1.16, ): m = (max_shift - base_shift) / (max_seq_len - base_seq_len) b = base_shift - m * base_seq_len mu = image_seq_len * m + b return mu
再追踪进调用了 mu 的 retrieve_timesteps 函数里,我们发现 mu 并不在参数表中,而是在 kwargs 里被传递给了噪声迭代器的 set_timesteps 方法。
# shifting the schedule to favor high timesteps for higher signal images if shift: # eastimate mu based on linear estimation between two points mu = get_lin_function(y1=base_shift, y2=max_shift)(image_seq_len) timesteps = time_shift(mu, 1.0, timesteps)
经苏剑林设计,假设每个 token 的二维位置编码是一个复数,如果用以下的公式来定义绝对位置编码,那么经过注意力计算里的求内积操作后,结果里恰好会出现相对位置关系。设两个 token 分别位于位置 $m$ 和 $n$,令给位置为 $j$ 的注意力输入 Q, K $q_j, k_j$ 右乘上 $e^{ij/10000}$的位置编码,则求 Q, K 内积的结果为:
其中,$i$ 为虚数单位,$*$ 为共轭复数,$Re$ 为取复数实部。只是为了理解方法的思想的话,我们不需要仔细研究这个公式,只需要注意到输入的 Q, K 位置编码分别由位置 $m$, $n$ 决定,而输出的位置编码由相对位置 $m-n$ 决定。这种位置编码既能给输入提供绝对位置关系,又能让注意力输出有相对位置关系,非常巧妙。
for index_block, block inenumerate(self.single_transformer_blocks): hidden_states = block( ... image_rotary_emb=image_rotary_emb, )
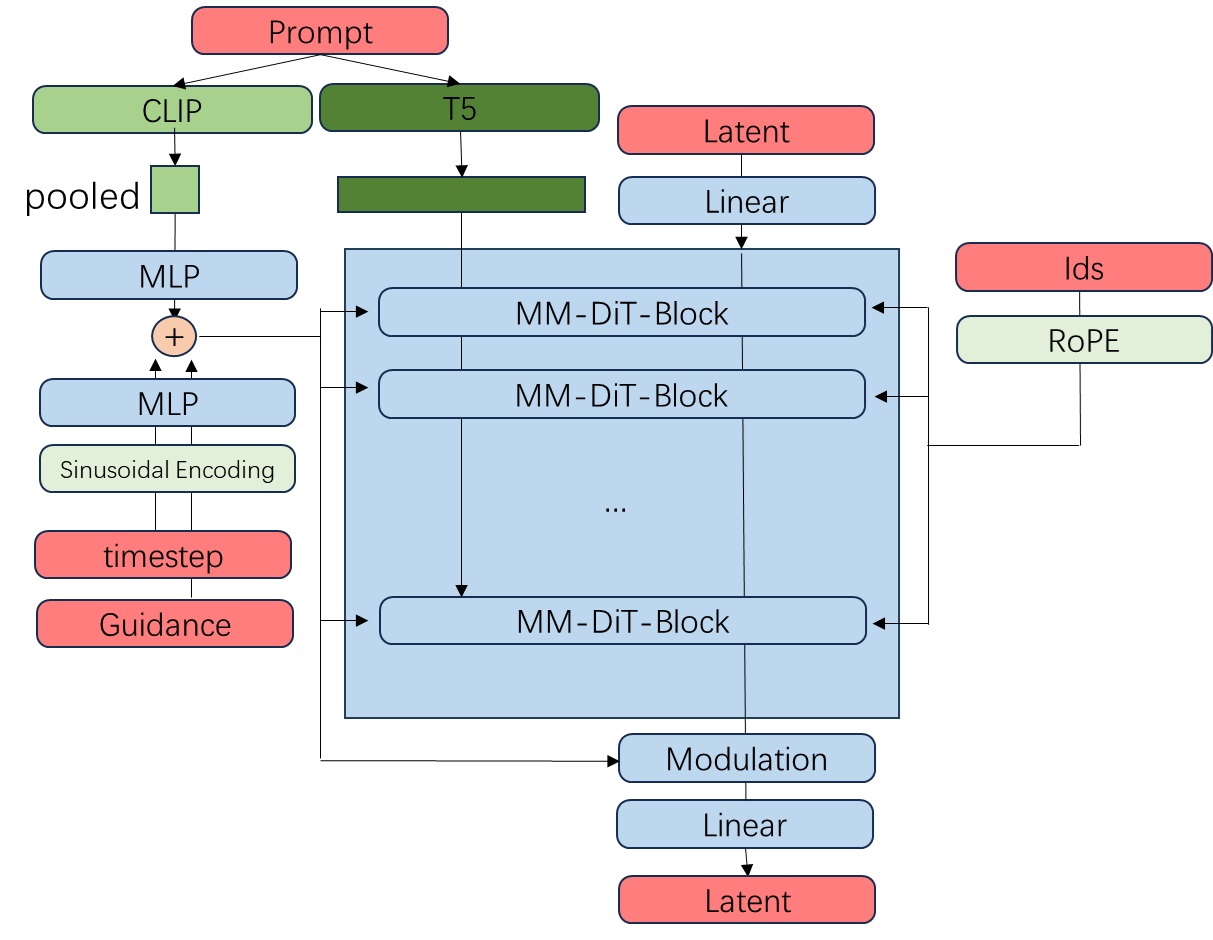
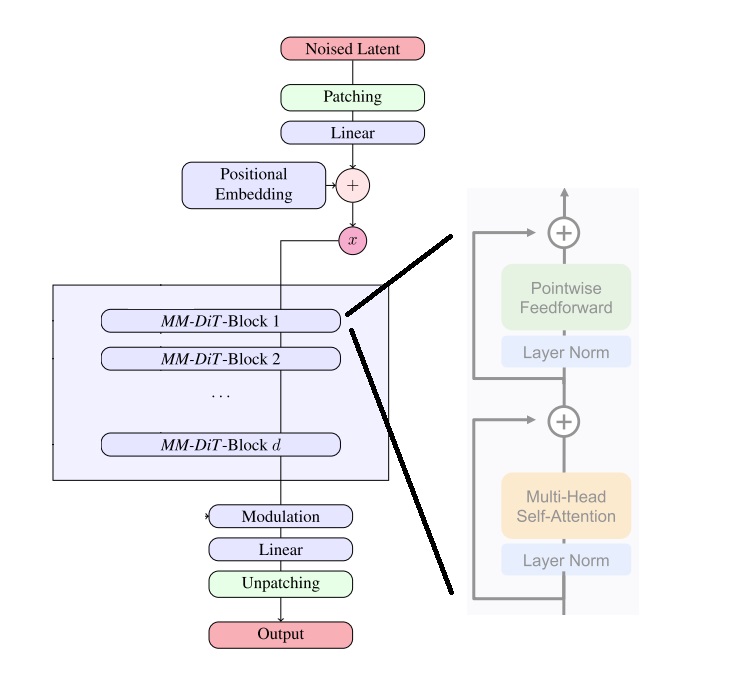
位置编码 image_rotary_emb 最后会传入双流注意力计算类 FluxAttnProcessor2_0 和单流注意力计算类 FluxSingleAttnProcessor2_0。由于位置编码在这两个类中的用法都相同,我们就找 FluxSingleAttnProcessor2_0 的代码来看一看。在其 __call__ 方法中,可以看到,在做完了 Q, K 的投影变换、形状变换、归一化后,方法调用了 apply_rope 来执行旋转式位置编码的计算。而 apply_rope 会把 Q, K 特征向量的分量两两分组,根据之前的公式,模拟与位置编码的复数乘法运算。
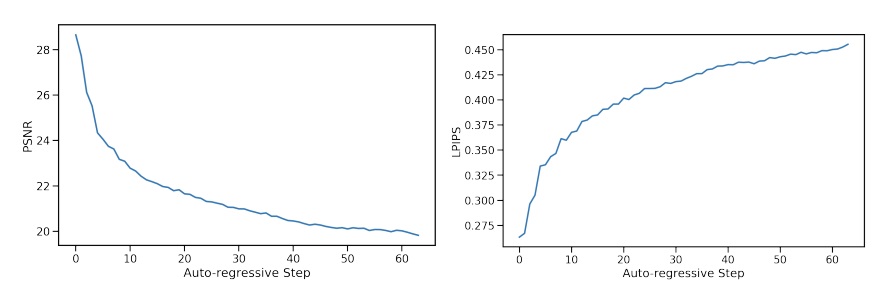
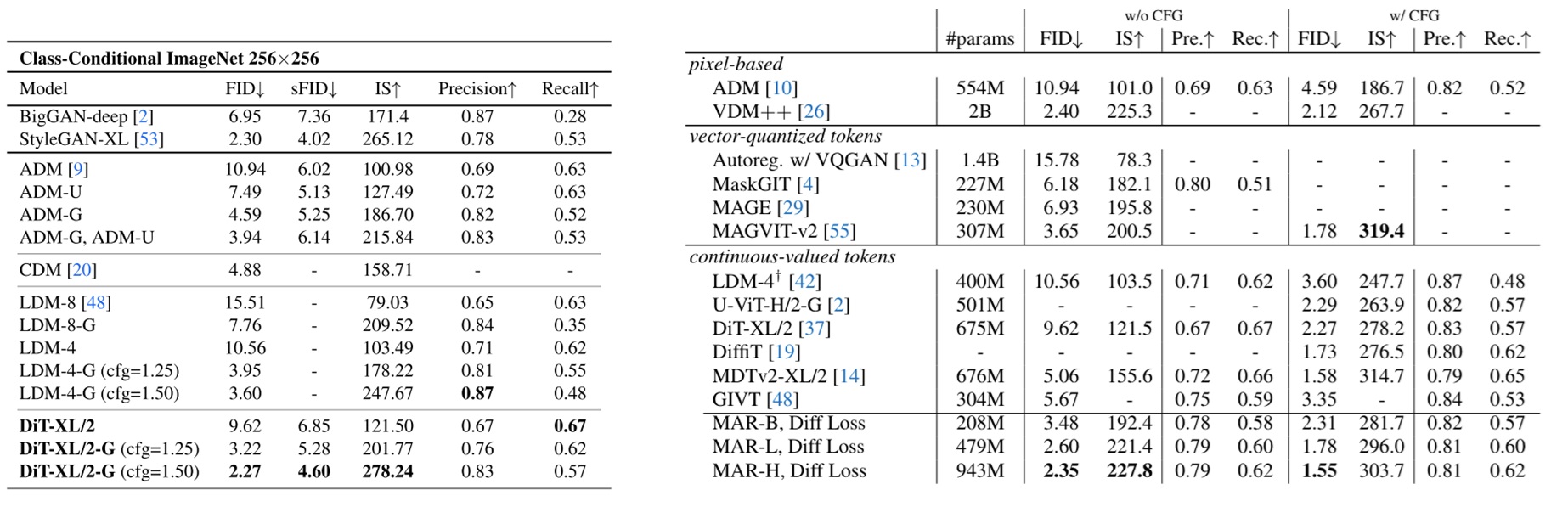
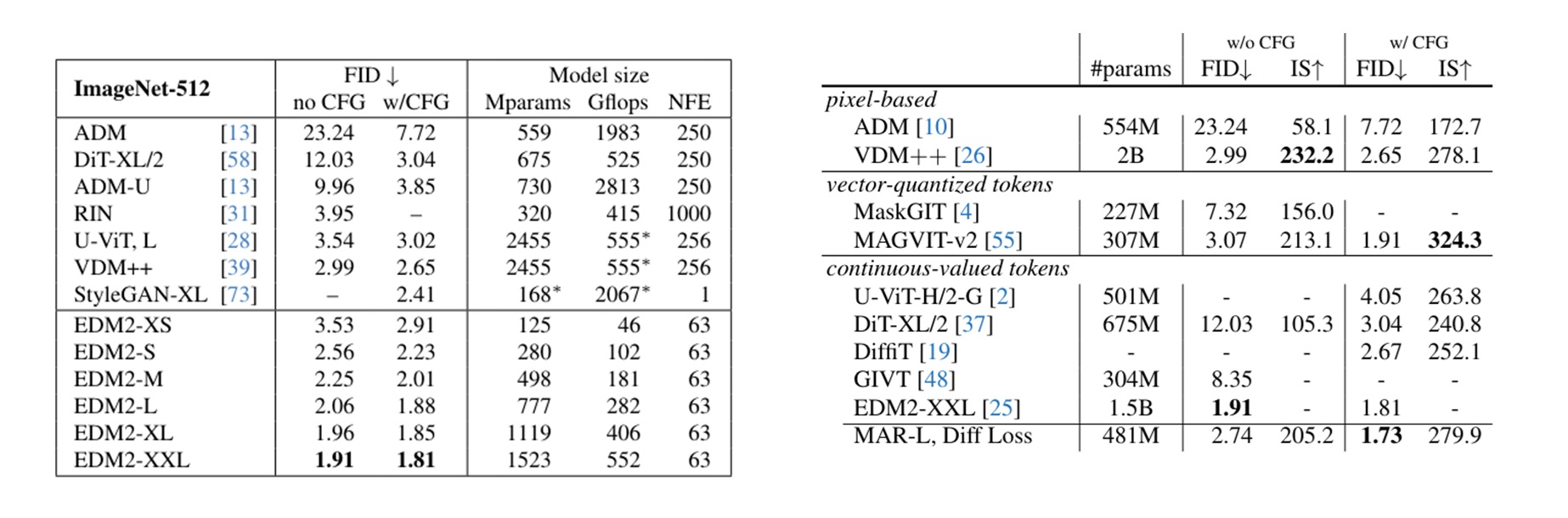
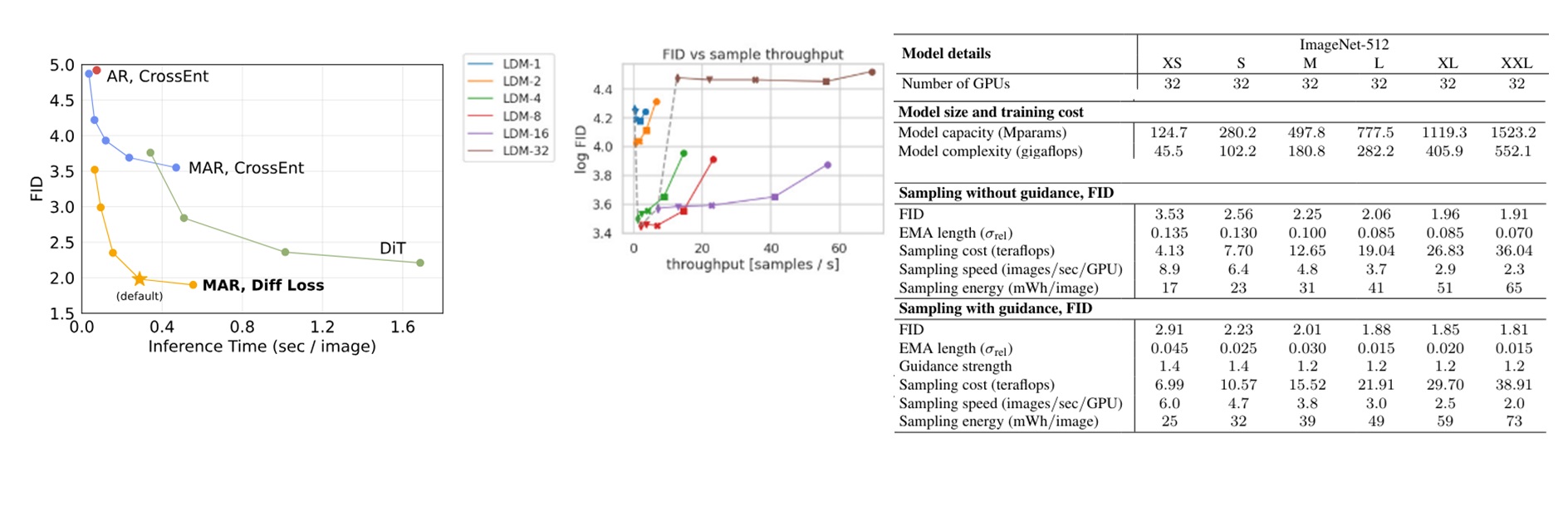
由于不同图表的采样速度指标不太一样,我们将指标统一成每秒生成的图像。从第一张图的对比可以看出,DiT 最快也是一秒 2.5 张图像左右,而 MAR 又快又好,默认(自回归步数 64)一秒生成 3 张图左右。同时,通过 MAR 和有 kv cache 加速的标准 AR 的对比,我们能发现 MAR 在默认自回归步数下还是比标准 AR 慢了不少。
我们再看中间 LDM 的速度。我们观察一下最常使用的 LDM-8。如果是令 DDIM 步数为 20 (第二快的结果)的话,LDM-8 的生成速度在一秒 16 张图像左右,还是比 MAR 快很多。DDIM 步数取 50 时也会比 MAR 快一些。
# `accelerate` 0.16.0 will have better support for customized saving if version.parse(accelerate.__version__) >= version.parse("0.16.0"): defsave_model_hook(models, weights, output_dir): ... defload_model_hook(models, input_dir): ...
跳过上面的代码,还是日志配置。
1 2 3 4 5 6 7 8 9 10 11 12 13
# Make one log on every process with the configuration for debugging. logging.basicConfig( format="%(asctime)s - %(levelname)s - %(name)s - %(message)s", datefmt="%m/%d/%Y %H:%M:%S", level=logging.INFO, ) logger.info(accelerator.state, main_process_only=False) if accelerator.is_local_main_process: datasets.utils.logging.set_verbosity_warning() diffusers.utils.logging.set_verbosity_info() else: datasets.utils.logging.set_verbosity_error() diffusers.utils.logging.set_verbosity_error()
之后其他版本的训练脚本会有一段设置随机种子的代码,我们给这份脚本补上。
1 2 3
# If passed along, set the training seed now. if args.seed isnotNone: set_seed(args.seed)
# Initialize the model if args.model_config_name_or_path isNone: model = UNet2DModel(...) else: config = UNet2DModel.load_config(args.model_config_name_or_path) model = UNet2DModel.from_config(config)
这份脚本还帮我们写好了维护 EMA(指数移动平均)模型的功能。EMA 模型用于存储模型可学习的参数的局部平均值。有时 EMA 模型的效果会比原模型要好。
1 2 3 4 5 6 7
# Create EMA for the model. if args.use_ema: ema_model = EMAModel( model.parameters(), model_cls=UNet2DModel, model_config=model.config, ...)
if args.resume_from_checkpoint: if args.resume_from_checkpoint != "latest": path = .. else: # Get the most recent checkpoint ...
if path isNone: ... else: accelerator.load_state(os.path.join(args.output_dir, path)) accelerator.print(f"Resuming from checkpoint {path}") ...
在每个 epoch 中,函数会重置进度条。接着,函数会进入每一个 batch 的训练迭代。
1 2 3 4 5 6 7
# Train! for epoch inrange(first_epoch, args.num_epochs): model.train() progress_bar = tqdm(total=num_update_steps_per_epoch, disable=not accelerator.is_local_main_process) progress_bar.set_description(f"Epoch {epoch}") for step, batch inenumerate(train_dataloader):
如果是继续训练的话,训练开始之前会更新当前的步数 step。
1 2 3 4 5
# Skip steps until we reach the resumed step if args.resume_from_checkpoint and epoch == first_epoch and step < resume_step: if step % args.gradient_accumulation_steps == 0: progress_bar.update(1) continue
接下来,函数会用去噪网络做前向传播。为了让模型能正确累计梯度,我们要用 with accelerator.accumulate(model): 把模型调用与反向传播的逻辑包起来。在这段代码中,我们会先得到模型的输出 model_output,再根据扩散模型得到损失函数 loss,最后用 accelerate 库的 API accelerator 代替原来 PyTorch API 来完成反向传播、梯度裁剪,并完成参数更新、学习率调度器更新、优化器更新。
1 2 3 4 5 6 7 8 9 10 11 12 13
with accelerator.accumulate(model): # Predict the noise residual model_output = model(noisy_images, timesteps).sample
loss = ...
accelerator.backward(loss)
if accelerator.sync_gradients: accelerator.clip_grad_norm_(model.parameters(), 1.0) optimizer.step() lr_scheduler.step() optimizer.zero_grad()
确保一步训练结束后,函数会更新和步数相关的变量。
1 2 3 4 5
if accelerator.sync_gradients: if args.use_ema: ema_model.step(model.parameters()) progress_bar.update(1) global_step += 1
f accelerator.is_main_process: if global_step % args.checkpointing_steps == 0: if args.checkpoints_total_limit isnotNone: checkpoints = os.listdir(args.output_dir) checkpoints = [ d for d in checkpoints if d.startswith("checkpoint")] checkpoints = sorted( checkpoints, key=lambda x: int(x.split("-")[1]))
defsave_model_hook(models, weights, output_dir): if accelerator.is_main_process: if args.use_ema: ema_model.save_pretrained( os.path.join(output_dir, "unet_ema"))
for i, model inenumerate(models): model.save_pretrained(os.path.join(output_dir, "unet"))
# make sure to pop weight so that corresponding model is not saved again weights.pop()
脚本默认的验证方法是随机生成图片,并用日志库保存图片。生成图片的方法是使用标准 Diffusers 采样流水线 DDPMPipeline。由于此时模型 model 可能被包裹成了一个用于多卡训练的 PyTorch 模块,需要用相关 API 把 model 解包成普通 PyTorch 模块 unet。如果使用了 EMA 模型,为了避免对 EMA 模型的干扰,此处需要先保存 EMA 模型参数,采样结束再还原参数。
generator = torch.Generator(device=pipeline.device).manual_seed(0) # run pipeline in inference (sample random noise and denoise) images = pipeline(...).images
if args.use_ema: ema_model.restore(unet.parameters())
# denormalize the images and save to tensorboard images_processed = (images * 255).round().astype("uint8")
if args.logger == "tensorboard": ... elif args.logger == "wandb": ...
在保存模型时,脚本同样会先用去噪模型 model 构建一个流水线,再调用流水线的保存方法 save_pretrained 将扩散模型的所有组件(去噪模型、噪声调度器)保存下来。
# old if cfg.model_config isNone: model = UNet2DModel(...) else: config = UNet2DModel.load_config(cfg.model_config) model = UNet2DModel.from_config(config)
# Create EMA for the model. if cfg.use_ema: ema_model = EMAModel(...) ...
# new trainer.init_modules(enable_xformers, cfg.gradient_checkpointing)
# The config must have a "base" key base_cfg_dict = data_dict.pop('base')
# The config must have one another model config assertlen(data_dict) == 1 model_key = next(iter(data_dict)) model_cfg_dict = data_dict[model_key] model_cfg_cls = __TYPE_CLS_DICT[model_key]
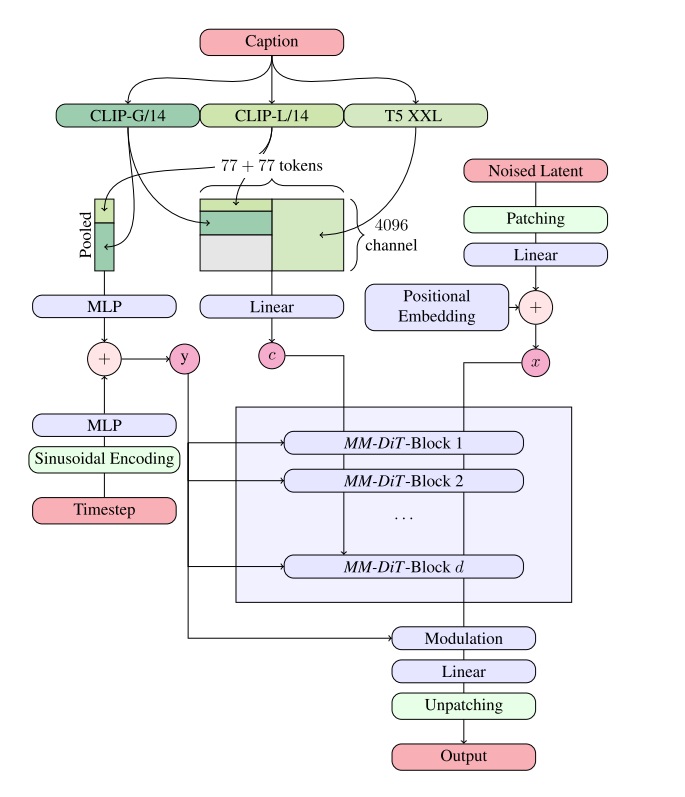
虽然整流模型是这样宣传的,但实际上 SD3 还是默认用了 28 步来生成图像。单看这篇文章,原整流论文里的很多设计并没有用上。对整流感兴趣的话,可以去阅读原论文 Flow straight and fast: Learning to generate and transfer data with rectified flow
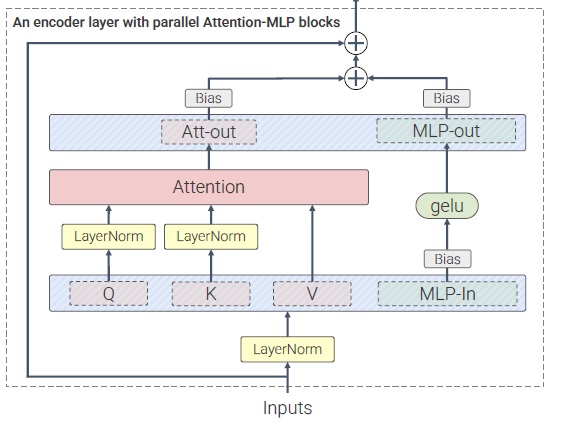
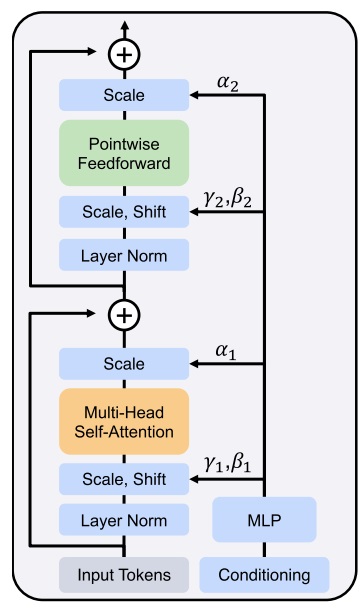
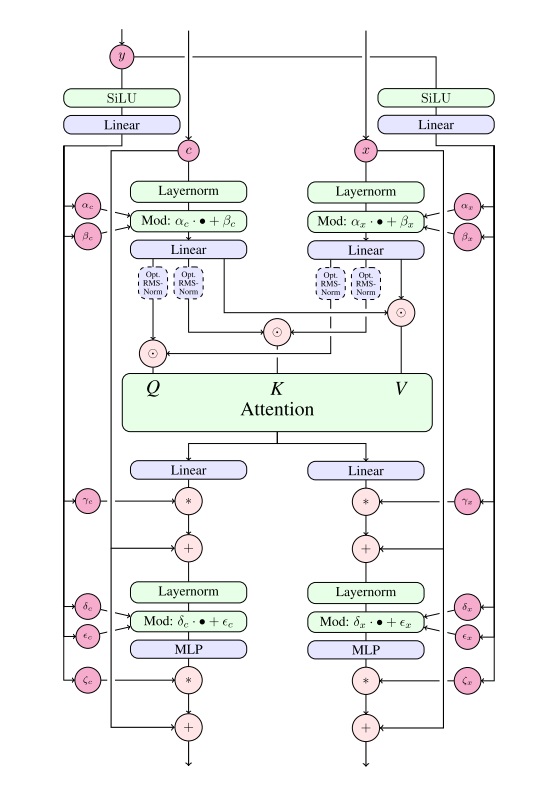
按照之前高分辨率文生图模型的训练方法,SD3 会先在 $256^2$ 的图片上训练,再在高分辨率图片上微调。然而,开发者发现,开始微调后,混合精度训练常常会训崩。根据之前工作的经验,这是由于注意力输入的熵会不受控制地增长。解决方法也很简单,只要在做注意力计算之前对 Q, K 做一次归一化就行,具体做计算的位置可以参考上文模块图中的 “RMSNorm”。不过,开发者也承认,这个技巧并不是一个长久之策,得具体问题具体分析。看来这种 DiT 模型在大规模训练时还是会碰到许多训练不稳定的问题,且这些问题没有一个通用解。