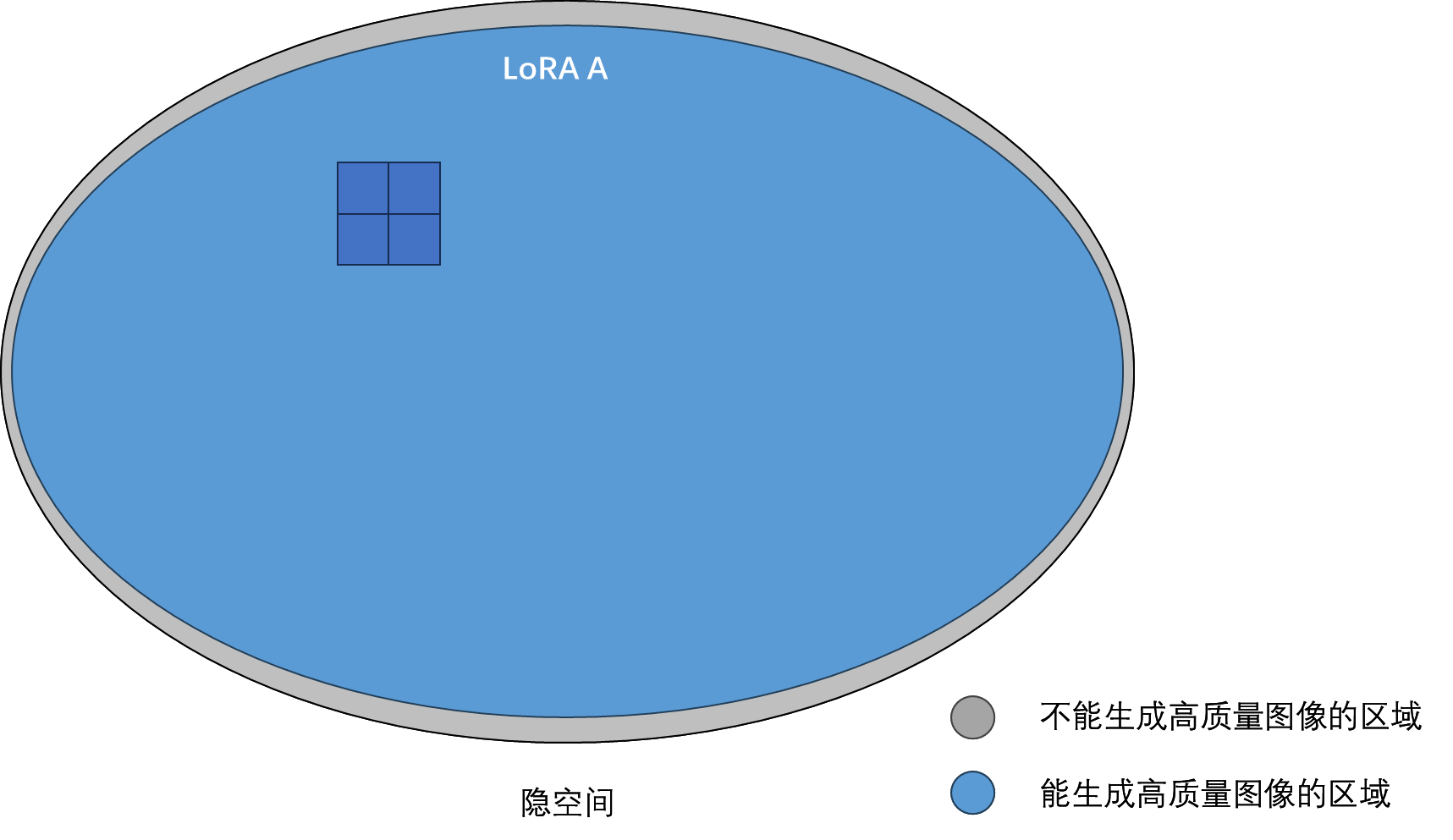
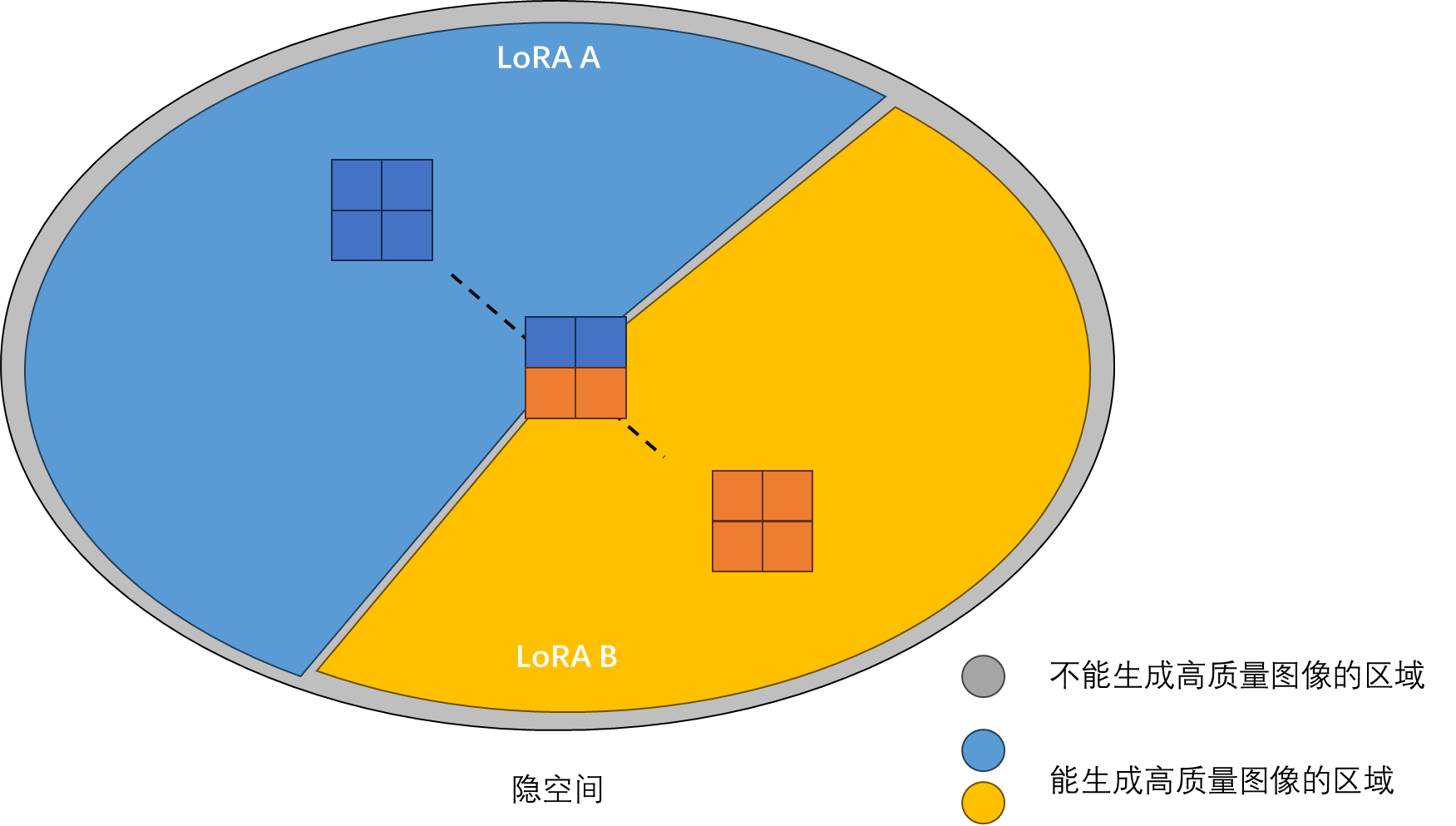
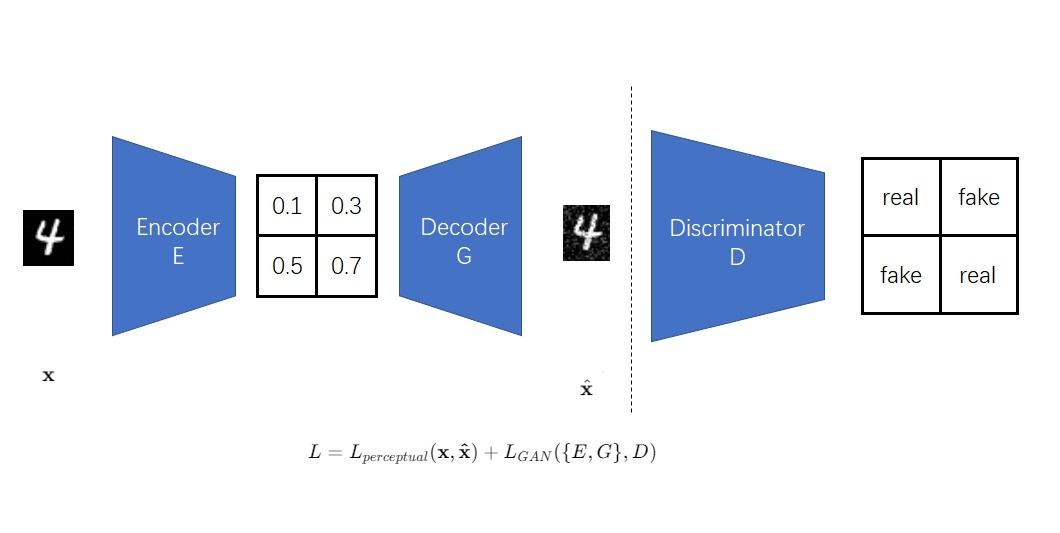
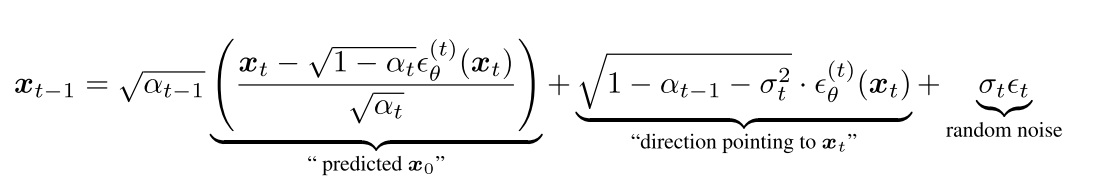from ..unet_3d_blocks import MidBlockTemporalDecoder, UpBlockTemporalDecoder ...
classUpBlockTemporalDecoder(nn.Module): def__init__(...): super().__init__() for i inrange(num_layers): ... resnets.append(SpatioTemporalResBlock(...))
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order self._num_timesteps = len(timesteps) with self.progress_bar(total=num_inference_steps) as progress_bar: for i, t inenumerate(timesteps):
# expand the latents if we are doing classifier free guidance latent_model_input = torch.cat([latents] * 2) if self.do_classifier_free_guidance else latents latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
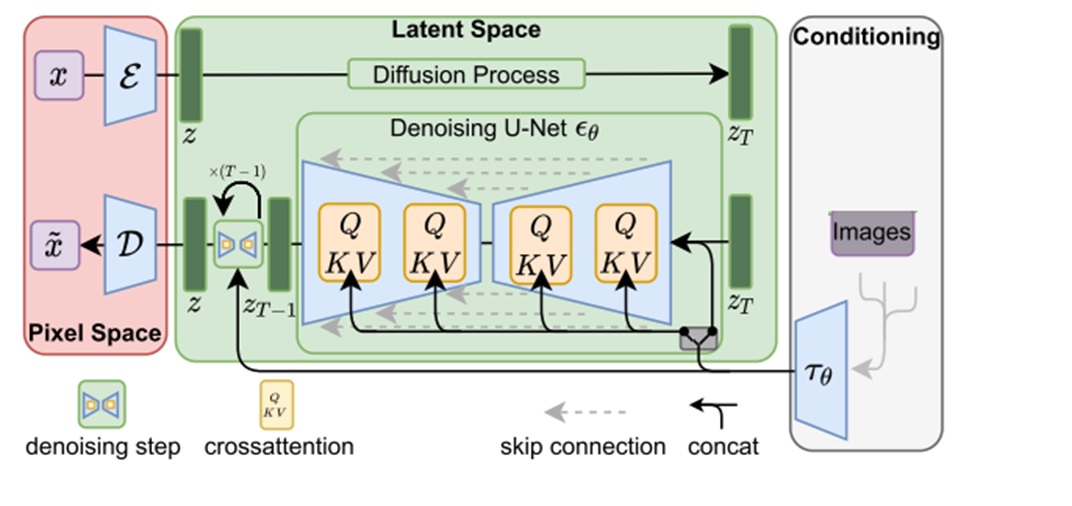
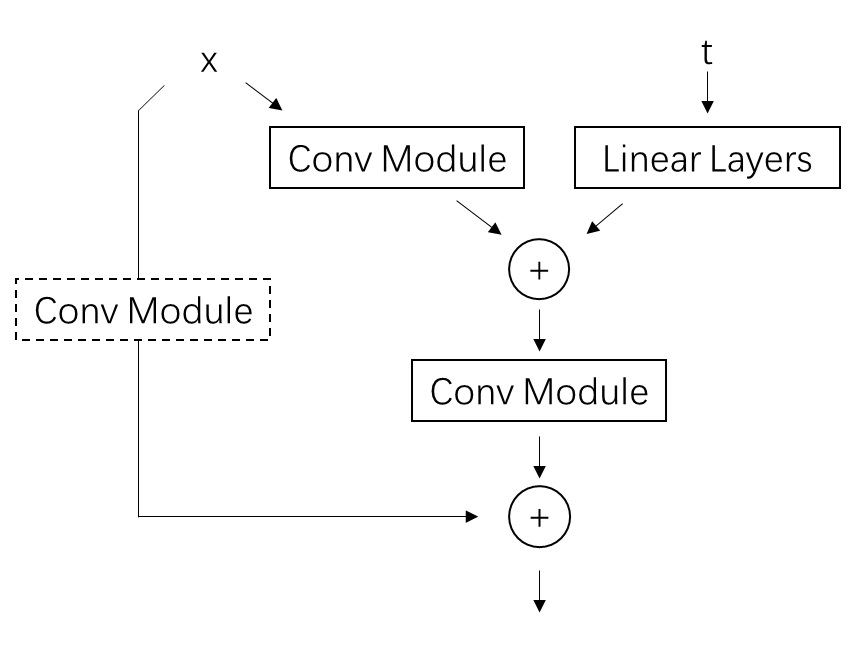
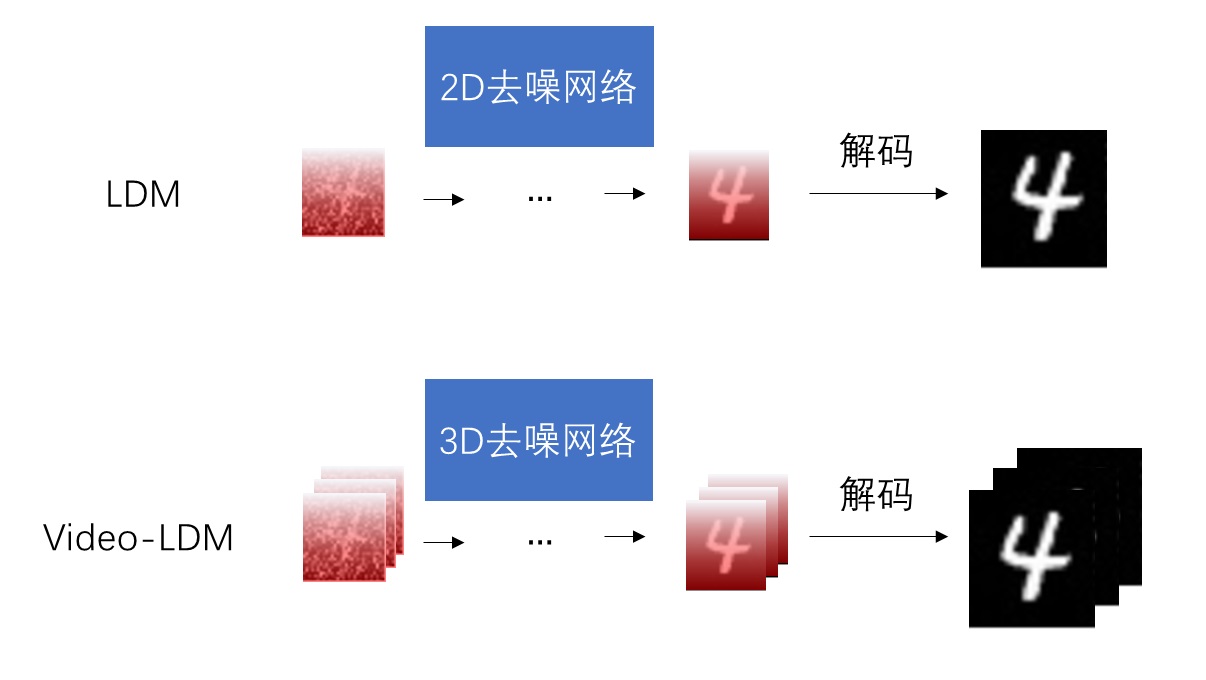
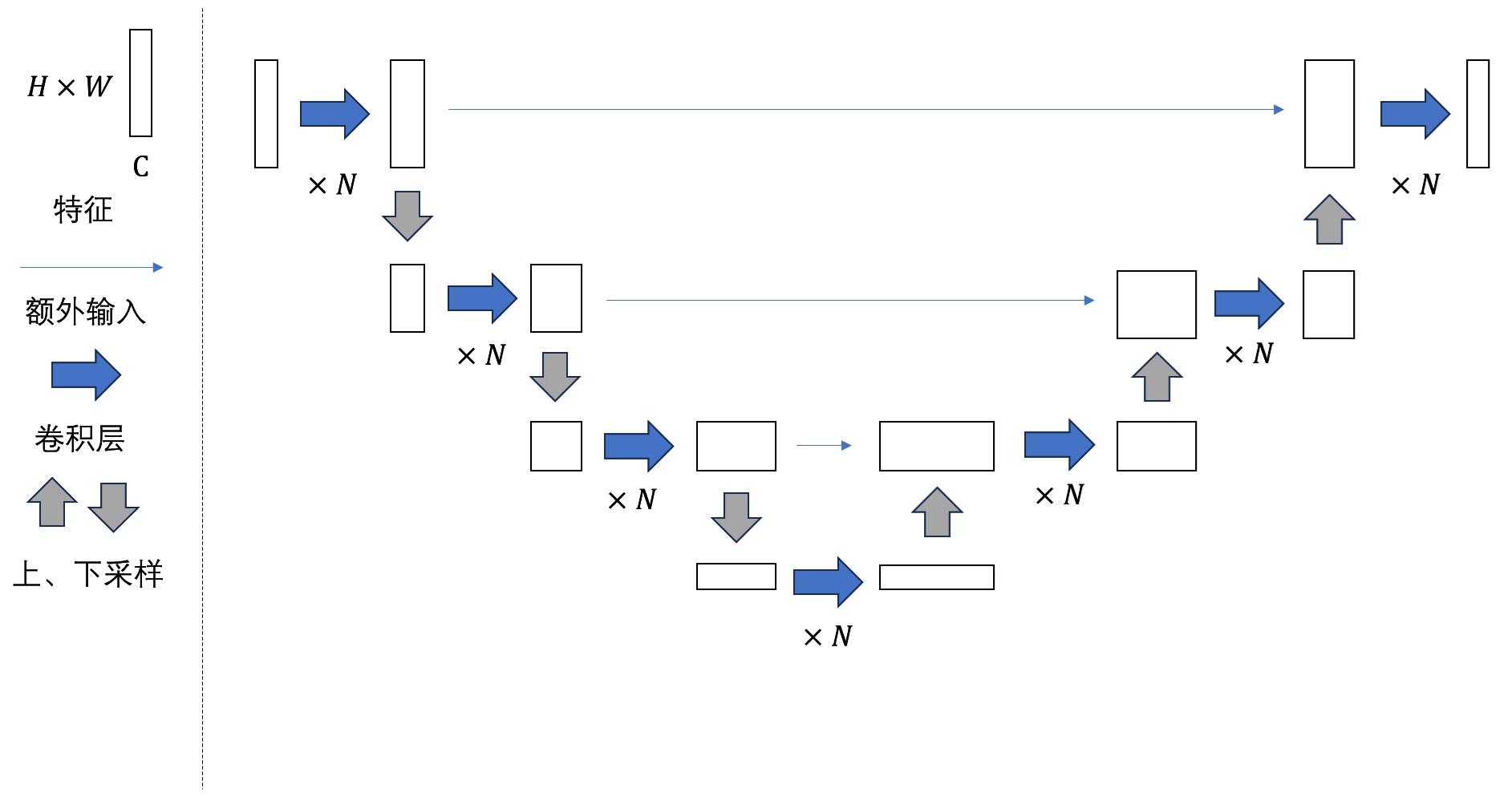
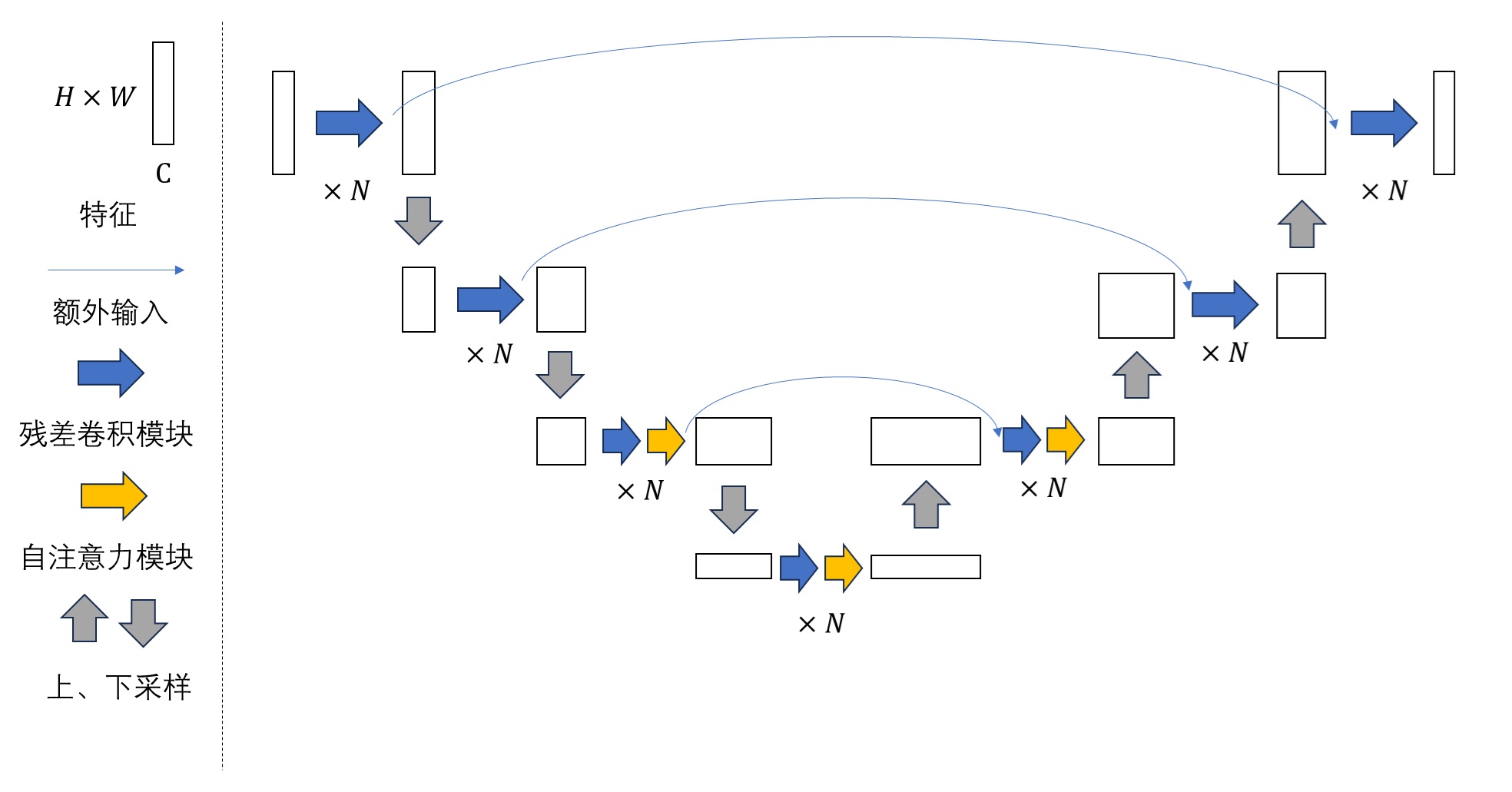
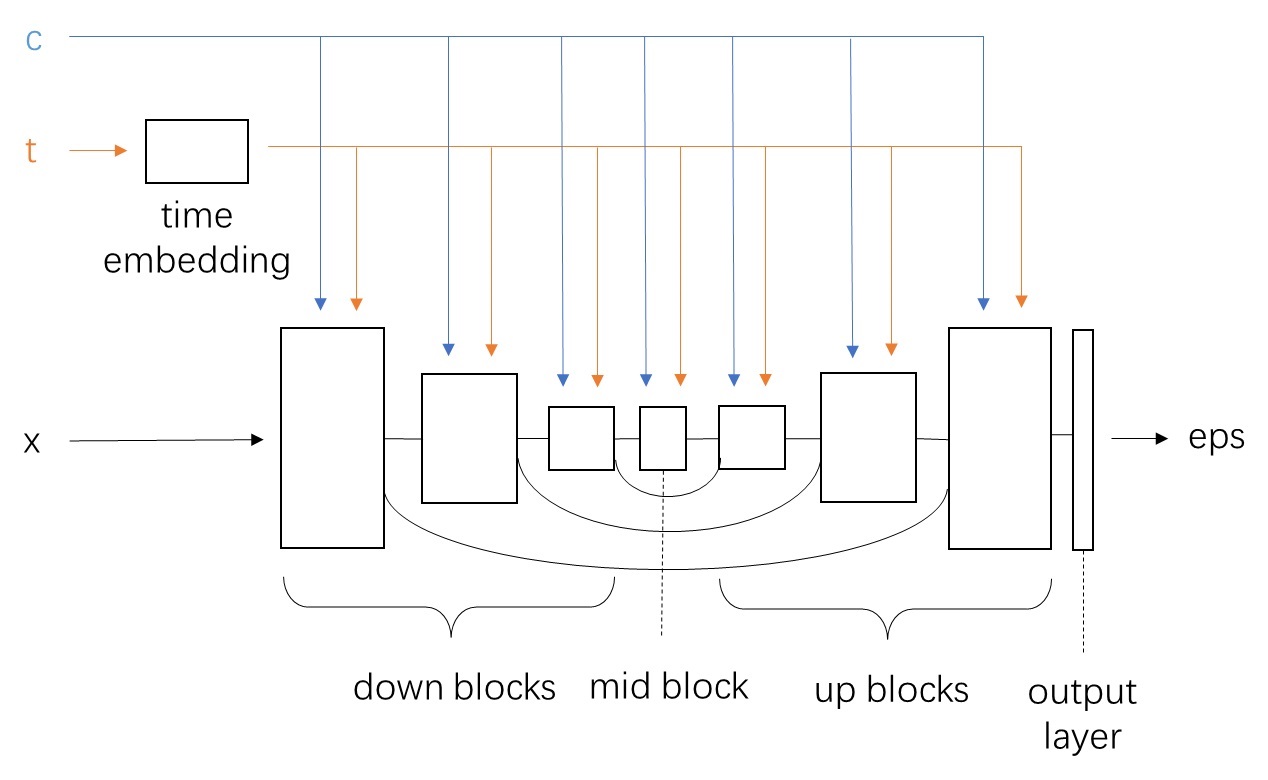
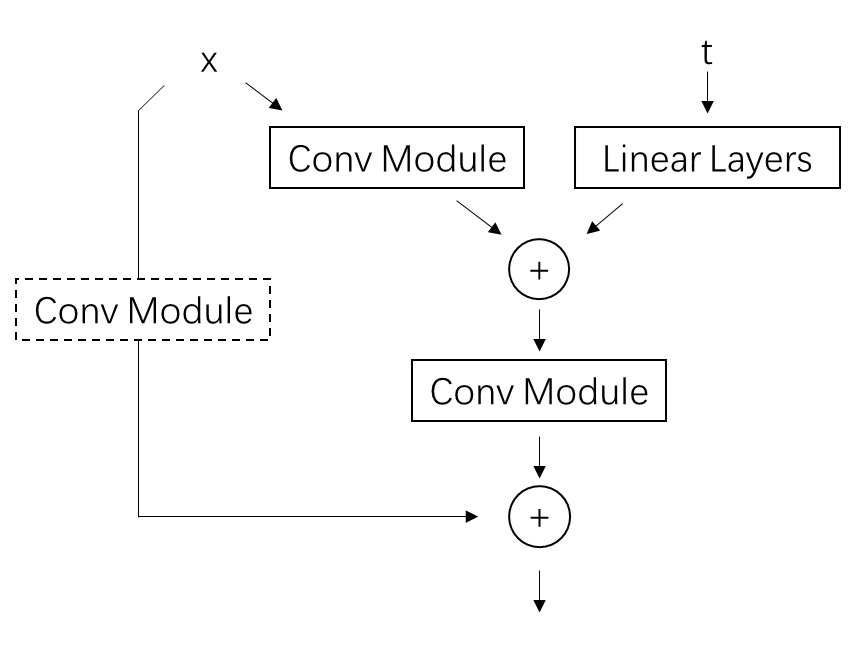
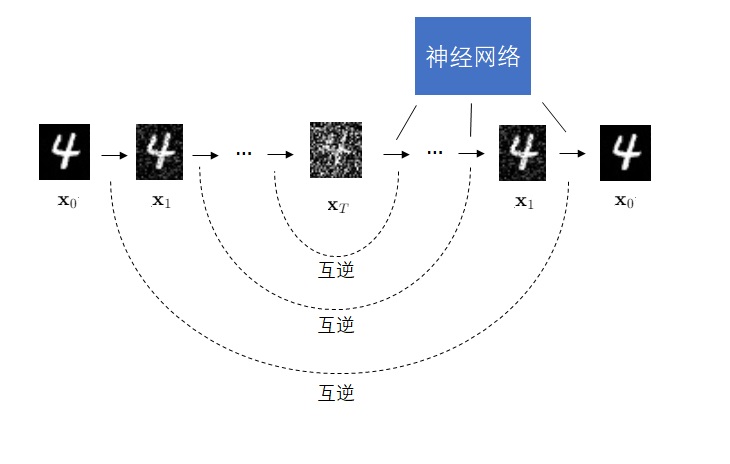
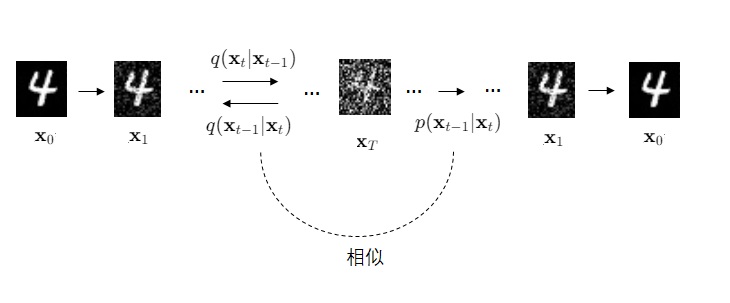
Video LDM 在 U-Net 中加入时序层的方法与多数同期方法相同,是在每个原来处理图像的空间层后面加上处理视频的时序层。Video LDM 加入的时序层包括 3D 卷积层与时序注意力层。这些新模块本身不难理解,但我们需要着重关注这些新模块是怎么与原模型兼容的。
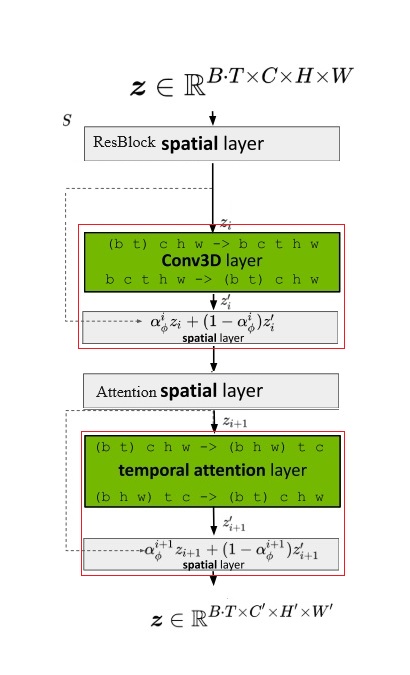
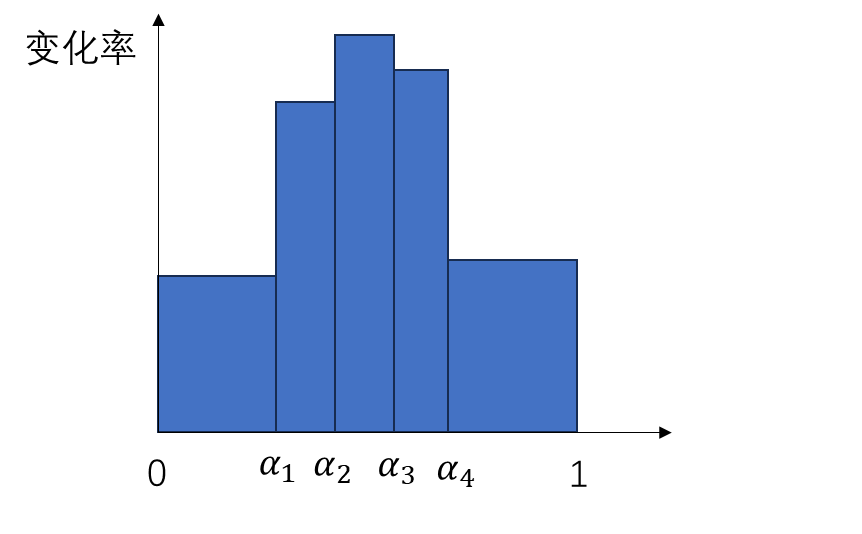
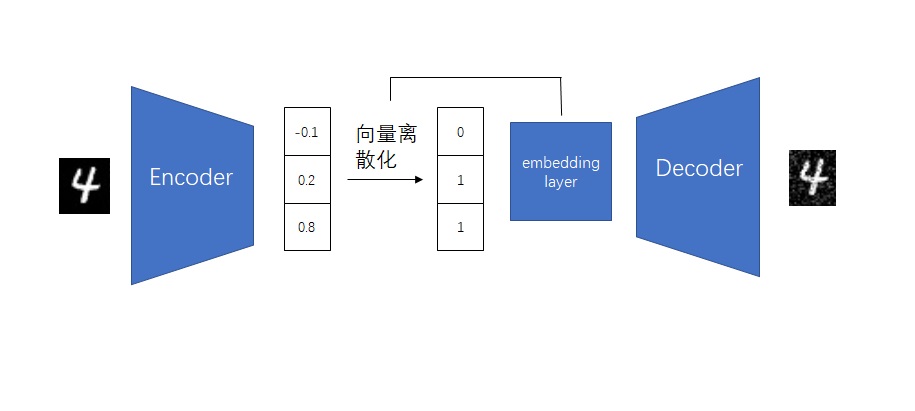
要兼容各个模块,其实就是要兼容数据的形状。本来,图像生成模型的 U-Net 的输入形状为 B C H W,分别表示图像数、通道数、高、宽。而视频数据的形状是 B T C H W,即视频数、视频长度、通道数、高、宽。要让视频数据复用之前的图像模型的结构,只要把数据前两维合并,变成 (B T) C H W 即可。这种做法就是把 B 组长度为 T 的视频看成了 $B \cdot T$ 张图片。
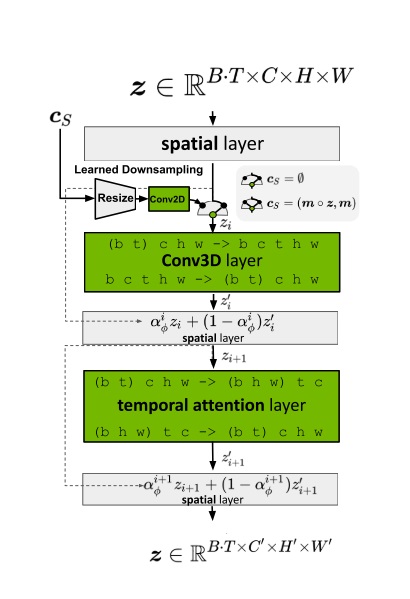
对于之前已有的空间层,只要把数据形状变成 (B T) C H W 就没问题了。而 SVD 又新加入了两种时序层:3D 卷积和时序注意力。我们来看一下数据是怎么经过这些新的时序层的。
2D 卷积会对 B C H W 的数据的后两个高、宽维度做卷积。类似地,3D 卷积会对数据最后三个时间、高、宽维度做卷积。所以,过 3D 卷积前,要把形状从 (B T) C H W 变成 B C T H W,做完卷积再还原。
接下来我们来看新的时序注意力。这个地方稍微有点难理解,我们从最简单的注意力开始一点一点学习。最早的 NLP 中的注意力层的输入形状为 B L C,表示数据数、token 长度、token 通道数。L 这一维最为重要,它表示了 L个 token 之间互相交换信息。如果把其拓展成图像空间注意力,则 token 表示图像的每一个像素。在这种注意力层中,L 是 (H W),B C H W 的数据会被转换成 B (H W) C 输入进注意力层。这表示同一组图像中,每个像素两两之间交换信息。而让视频数据过空间注意力层时,只需要把 B 换成 (B T) 即可,即把数据形状从 (B T) C H W 变为 (B T) (H W) C。这表示同一组、同一帧的图像的每个像素之间,两两交换信息。
在 SVD 新加入的时序注意力层中,token 依旧指代是某一组、某一帧上的一个像素。然而,这次我们不是让同一张图像的像素互相交换信息,而是让不同时刻的像素互相交换信息。因此,这次 token 长度 L 是 T,它表示要像素在时间维度上交换信息。这样,在视频数据过时序层里的自注意力层时,要把数据形状从 (B T) C H W 变成 (B H W) T C。这表示每一组、图像每一处的像素独立处理,它们仅与同一位置不同时间的像素进行信息交换。
此处如果你没有理解注意力层的形状变换也不要紧,它只是一个实现细节,不影响后面的阅读。如果感兴趣的话,可以回顾一下 Transformer 论文的代码,看一下注意力运算为什么是对 B L C 的数据做操作的。
微调 VAE 解码器
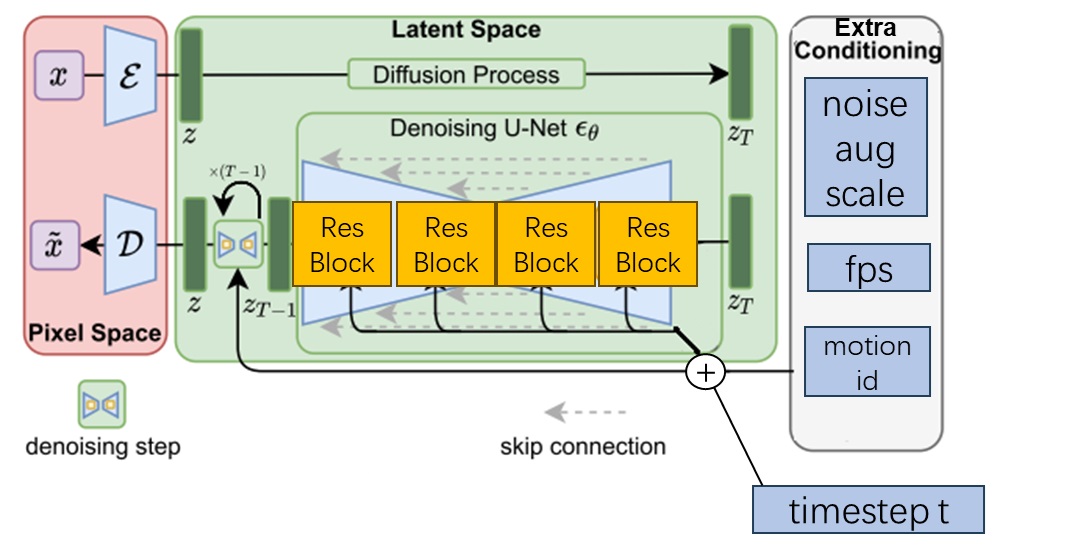
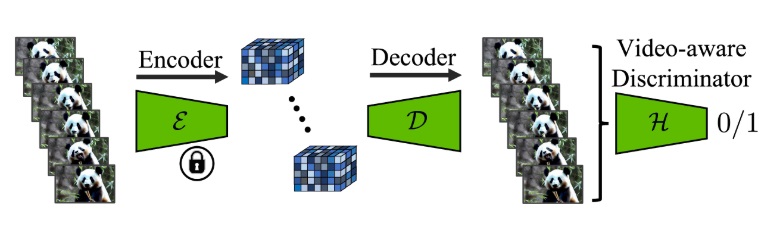
Video LDM 的另一项改动是修改了图像压缩模型 VAE 的解码器。具体来说,方法先在 VAE 的解码器中加入类似的时序层,并在 VAE 配套的 GAN 的判别器里也加入了时序层,随后开始微调。在微调时,编码器不变,仅训练解码器和判别器。
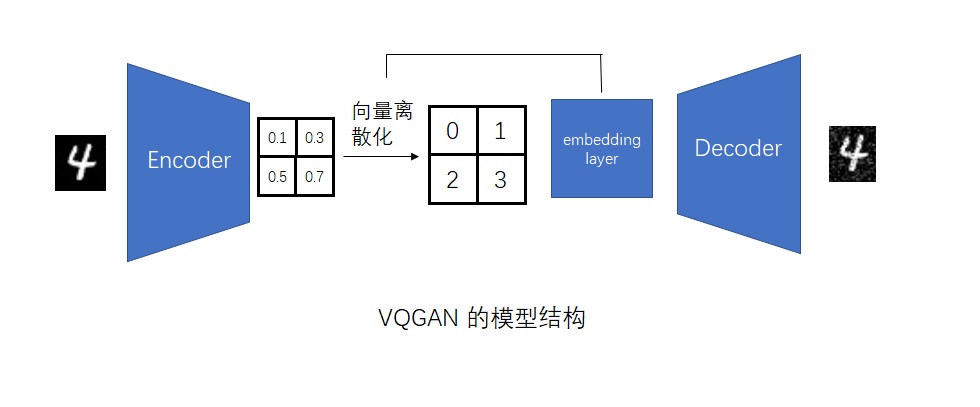
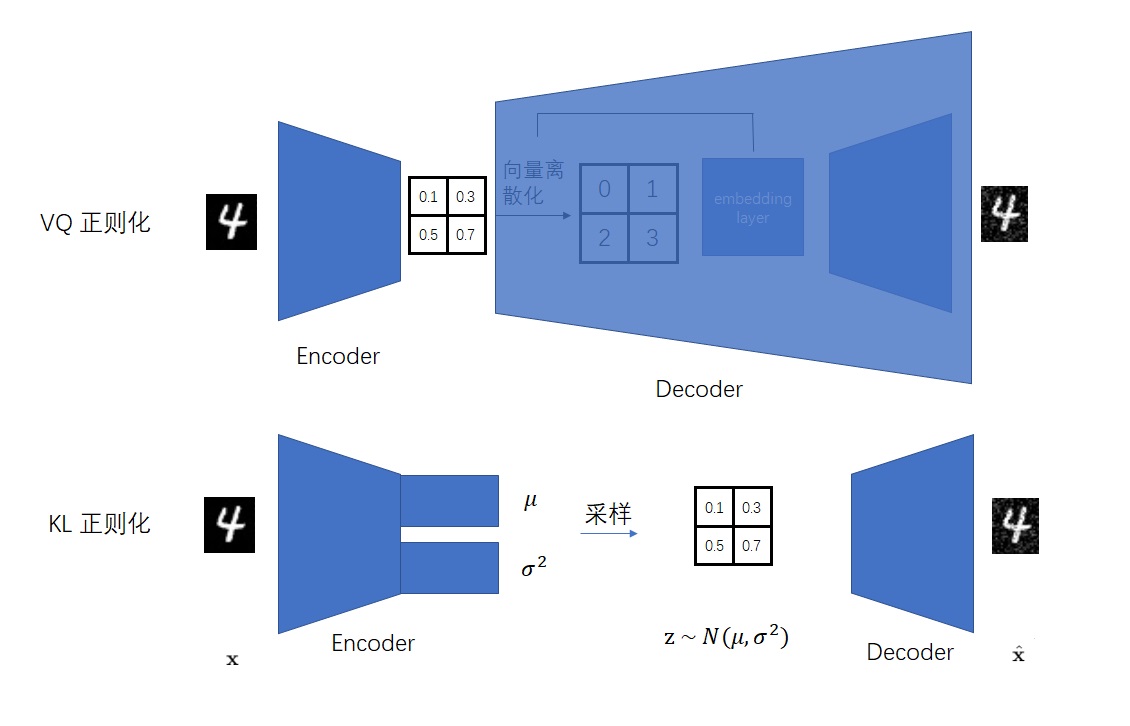
如果你没听过这套 VAE + GAN 的架构的话,请回顾 Stable Diffusion 论文及与其紧密相关的 VQGAN 论文。
以上就是 Video LDM 的模型结构。SVD 对其没有做任何更改,所以也没有在论文里对模型结构做详细介绍。稍有不同的是,Video LDM 仅微调了新加入的模块,而 SVD 在加入新模块后对模型的所有参数都进行了重新训练。
Video LDM 曾提出了一种把基础视频模型变成视频插帧模型方法。该方法以视频片段的首末帧为额外约束,在此新约束下把视频生成模型微调成了预测中间帧的视频预测模型。SVD 以同样方式实现了这一应用。
多视角生成
多视角生成是计算机视觉中另一类重要的任务:给定 3D 物体某个视角的图片,需要算法生成物体另外视角的图片,从而还原 3D 物体的原貌。而视频生成模型从数据中学到了物体的平滑变换规律,恰好能帮助到多视角生成任务。SVD 论文用不少篇幅介绍了如何在 3D 数据集上生成视频并微调基础模型,从而得到一个能生成环绕物体旋转的视频的模型。
结语
Stable Video Diffusion 是在文生图模型 Stable Diffusion 2.1 的基础上添加了和 Video LDM 相同的视频模块微调而成的一套视频生成模型。SVD 的论文主要介绍了其精制数据集的细节,并展示了几个微调基础模型能实现的应用。通过微调基础低分辨率文生视频模型,SVD 可以用于高分辨率文生视频、高分辨率图生视频、视频插帧、多视角生成。
模型输出不同,最容易想到的是模型权重不同。于是,我尝试交换使用二者的模型权重,再比较输出的 FID。两个库的模型定义不太一样,不能直接换模型文件名。我用强大的代码魔改实力强行让新权重分别都跑起来了。结果非常神奇,算上之前的两个 FID,我一共得到了 4 个不一样的 FID 结果。也就是说,A 库 A 模型、B 库 B 模型、A 库 B 模型,B 库 A 模型,结果均不一样。
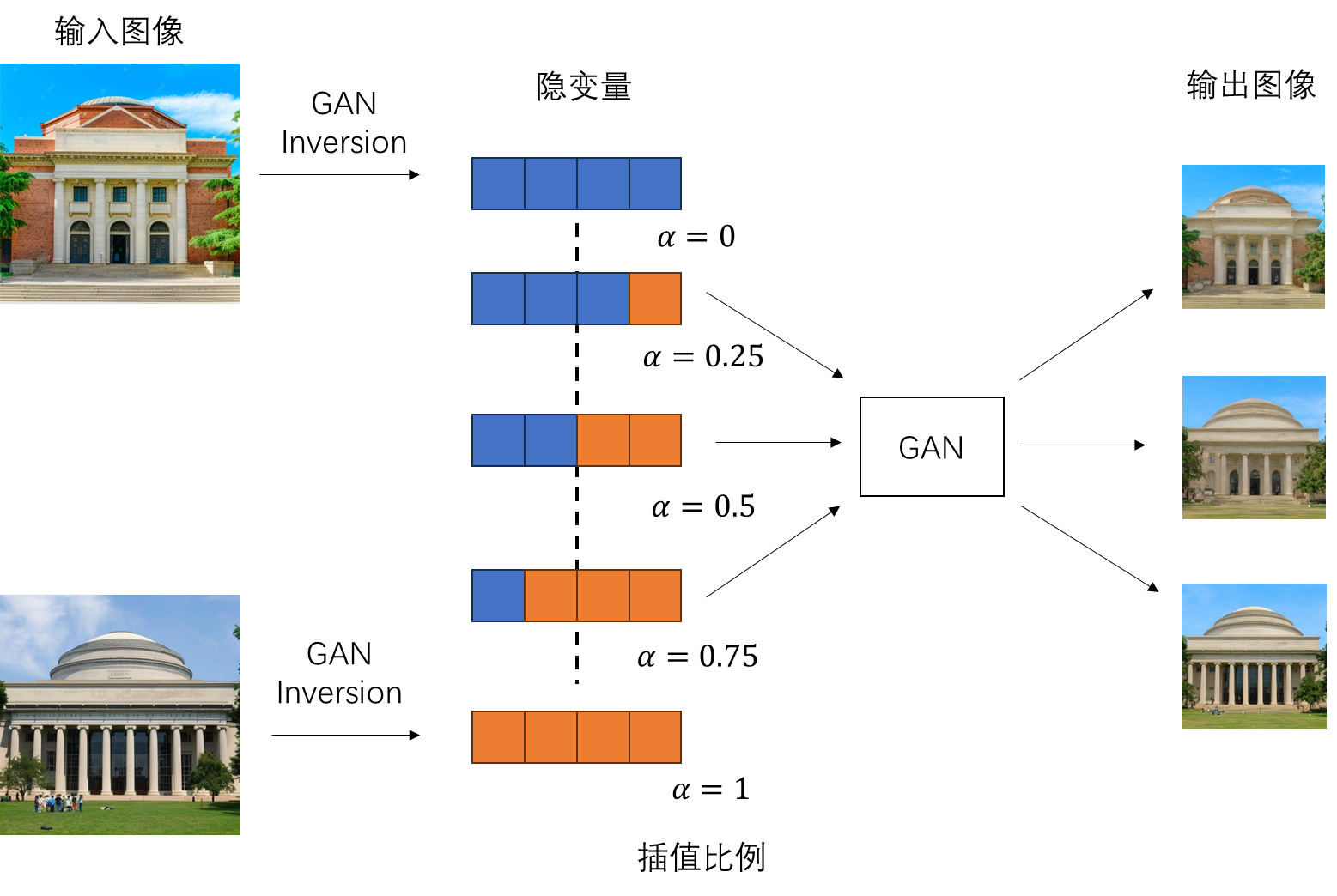
如前所述,图像变形任务在生成插值图像时不仅需要混合输入图像的内容,还需要补充生成一些内容。用预训练的图像生成模型来完成图像变形是再自然不过的想法了。前几年,已经有一些工作探究了如何用 GAN 来完成图像变形。使用 GAN 做图像变形的方法非常直接:在 GAN 中,每张被生成的图片都由一个高维隐变量决定。可以说,隐变量蕴含了生成一张图像所需的所有信息。那么,只要先使用 GAN 反演(inversion)把输入图片变成隐变量,再对隐变量做插值,就能用其生成两张输入图像的一系列中间过渡图像了。
对于隐变量,我们一般使用球面插值(slerp)而不是线性插值。
然而,GAN 生成的图像往往局限于某一类别,泛用性差。因此,用 GAN 做图像变形时,往往得不到高质量的图像插值结果。
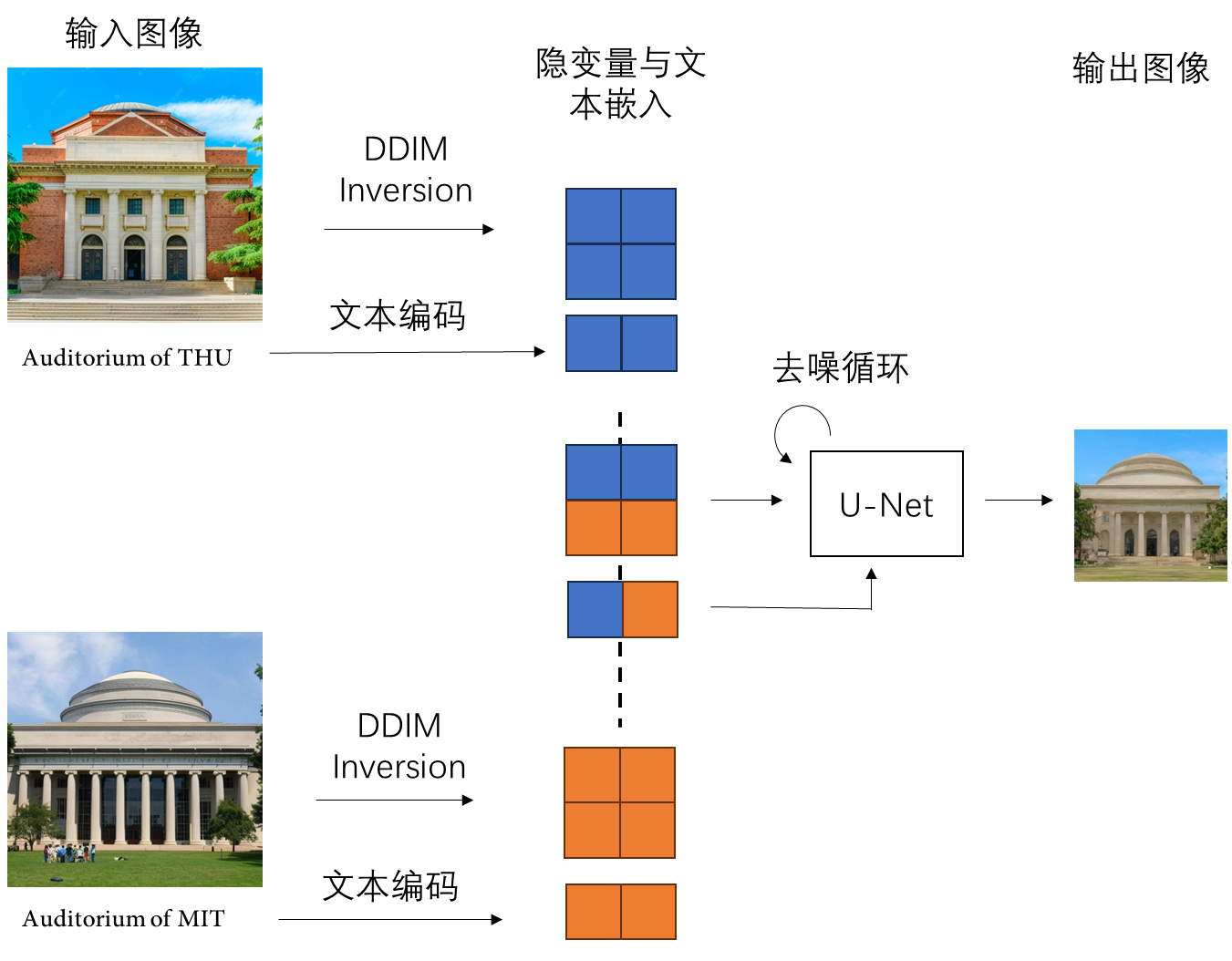
而以 Stable Diffusion(SD)为代表的图像生成扩散模型以能生成各式各样的图像而著称。我们可以在 SD 上也用类似的过程来实现图像插值。具体来说,我们需要对 DDIM 反演得到的纯噪声图像(隐变量)进行插值,并对输入文本的嵌入进行插值,最后根据插值结果生成图像。
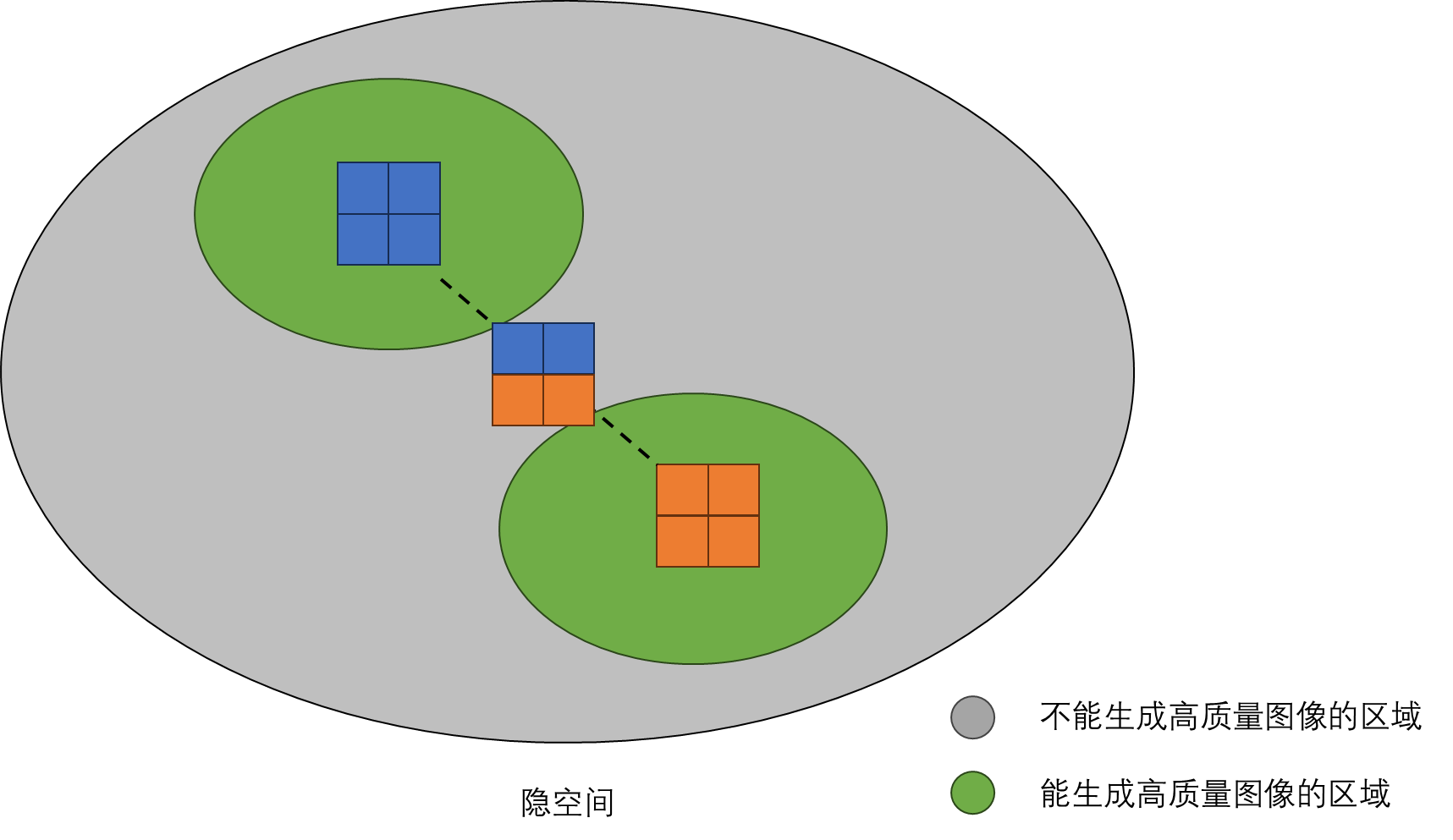
可是,扩散模型也存在缺陷:扩散模型的隐变量没有 GAN 的那么适合编辑。如下面的动图所示,如果仅使用简单的隐变量插值,会存在着两个问题:1)早期和晚期的中间帧和输入图像非常相近,而中期的中间帧又变化过快,图像的过渡非常突兀;2)中间帧的图像质量较低。这样的结果无法满足实际应用的要求。
git clone https://github.com/Kevin-thu/DiffMorpher.git cd DiffMorpher pip install -r requirements.txt
配置好了环境后,可以直接尝试仓库里自带的示例:
1 2 3 4 5
python main.py \ --image_path_0 ./assets/Trump.jpg --image_path_1 ./assets/Biden.jpg \ --prompt_0 "A photo of an American man" --prompt_1 "A photo of an American man" \ --output_path "./results/Trump_Biden" \ --use_adain --use_reschedule --save_inter
尽管 DiffMorpher 已经算是一个不错的图像变形工具了,该方法并没有从本质上提升扩散模型的可编辑性。相比 GAN 而言,逐渐对扩散模型的隐变量修改难以产生平滑的输出结果。比如在拖拽式编辑任务中,DragGAN 只需要优化 GAN 的隐变量就能产生合理的编辑效果,而扩散模型中的类似工具(如 DragDiffusion, DragonDiffusion)需要更多设计才能达到同样的结果。从本质上提升扩散模型的可编辑性依然是一个值得研究的问题。
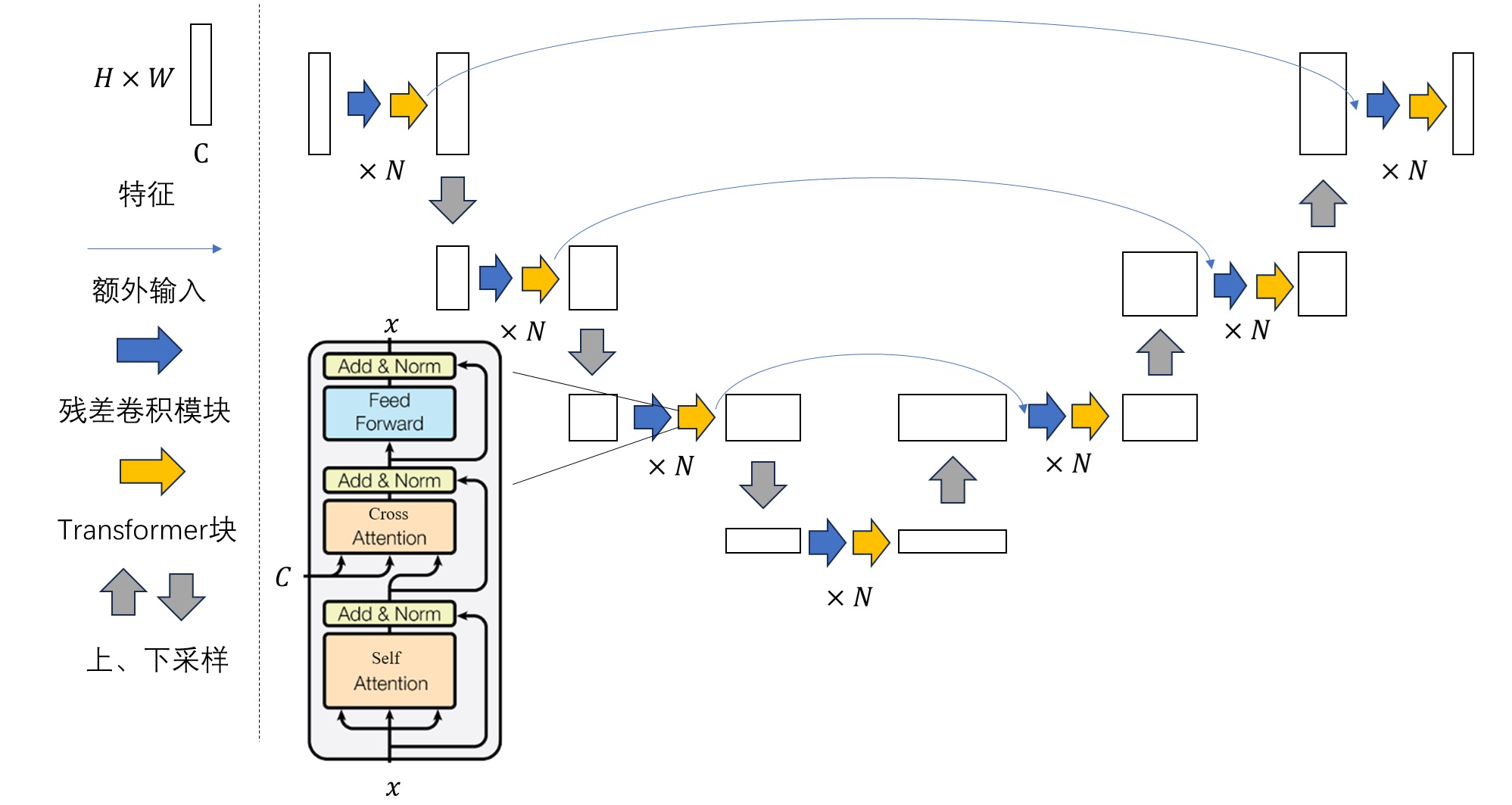
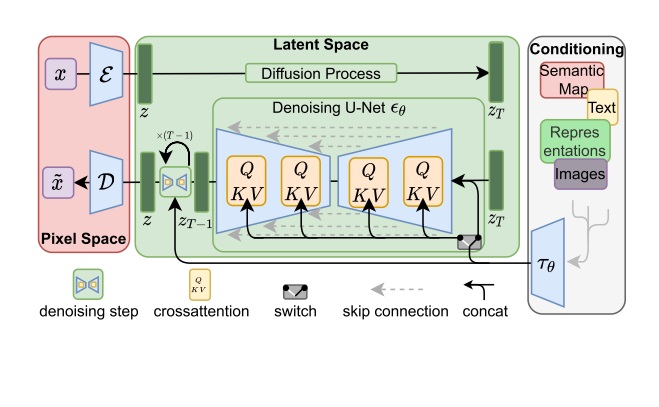
输入视频经过自编码器后,会被转换成一段空间和时间维度上都变小的压缩视频。这段压缩视频就是 Sora 的 DiT 的拟合对象。在处理视频数据时,DiT 较 U-Net 又有一些优势。
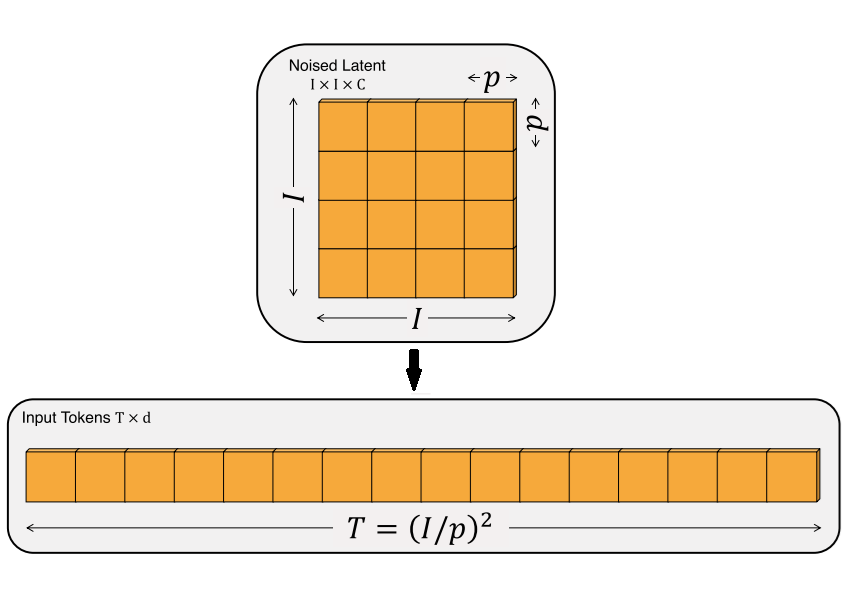
之前基于 U-Net 的去噪模型在处理视频数据时(如 [3]),都需要额外加入一些和时间维度有关的操作,比如时间维度上的卷积、自注意力。而 Sora 的 DiT 是一种完全基于图块的 Transformer 架构。要用 DiT 处理视频数据,不需要这种设计,只要把视频看成一个 3D 物体,再把 3D 物体分割成「图块」,并重组成一维数据输入进 DiT 即可。和原本图像 DiT 一样,假设视频边长为 $I$,时长也为 $I$,要切成边长为 $p$ 的图块,最后会得到 $(I/p)^3$ 个数据。
Sora 的这种性质还是得益于 Transformer 架构。前文提到,Transformer 的计算与输入顺序无关,必须用位置编码来指明每个数据的位置。尽管报告没有提及,我觉得 Sora 的 DiT 使用了类似于 $(x, y, t)$ 的位置编码来表示一个图块的时空位置。这样,不管输入的视频的大小如何,长度如何,只要给每个图块都分配一个位置编码,DiT 就能分清图块间的相对关系了。
报告结尾还是给出了一些失败的生成示例,比如玻璃杯在桌子上没有摔碎。这表明模型还不能完全学会某些物理性质。然而,我觉得现阶段 Sora 已经展示了足够强大的学习能力。想模拟现有视频中已经包含的物理现象,只需要增加数据就行了。
总结
Sora 是一个惊艳的视频生成模型,它以卓越的生成能力(高分辨率、长时间)与生成质量令一众同期的视频生成模型黯然失色。Sora 的技术报告非常简短,不过我们从中还是可以学到一些东西。从技术贡献上来看,Sora 的创新主要有两点:
让 LDM 的自编码器也在视频时间维度上压缩。
使用了一种不限制输入形状的 DiT
其中,第二点贡献是非常有启发性的。DiT 能支持不同形状的输入,大概率是因为它以视频的3D位置生成位置编码,打破了一维编码的分辨率限制。后续大家或许会逐渐从 U-Net 转向 DiT 来建模扩散模型的去噪模型。
我认为 Sora 的成功有三个原因。前两个原因对应两项创新。第一,由于在时间维度上也进行了压缩,Sora 最终能生成长达一分钟的视频;第二,使用 DiT 不仅去除了视频空间、时间长度上的限制,还充分利用了 Transformer 本身的可拓展性,使训练一个视频生成大模型变得可能。第三个原因来自于视频标注模型。之前 Stable Diffusion 能够成功,很大程度上是因为有一个能够关联图像与文本的 CLIP 模型,且有足够多的带标注图片。相比图像,视频训练本来就少,带标注的视频就更难获得了。一个能够理解视频内容,生成详细视频标注的标注器,一定是让视频生成模型理解复杂文本描述的关键。除了这几点原因外,剩下的就是砸钱、扩大模型、加数据了。
Sora 显然会对 AIGC 社区产生一定影响。对于 AIGC 爱好者而言,他们或许会多了一些生成创意视频的方法,比如给部分帧让 Sora 来根据文本补全剩余帧。当然,目前 Sora 依然不能取代视频创作者,长视频的质量依然有待观察。对于正在开发相似应用的公司,我觉得他们应该要连夜撤销之前的方案,转换为这套没有分辨率限制的 DiT 的方案。他们的压力应该会很大。对于相关科研人员而言,除了学习这种较为新颖的 DiT 用法外,也没有太多收获了。这份技术报告透露出一股「我绝对不会开源」的意思。没有开源模型,普通的研究者也就什么都做不了。新技术的诞生绝对不可能靠一家公司,一个模型就搞定。像之前的 Stable Diffusion,也是先开源了一个基础模型,科研者和爱好者再补充了各种丰富的应用。我呼吁各大公司尽快训练并开源一个这种不限分辨率的 DiT,这样科研界或许会抛开 U-Net,基于 DiT 开发出新的扩散模型应用。
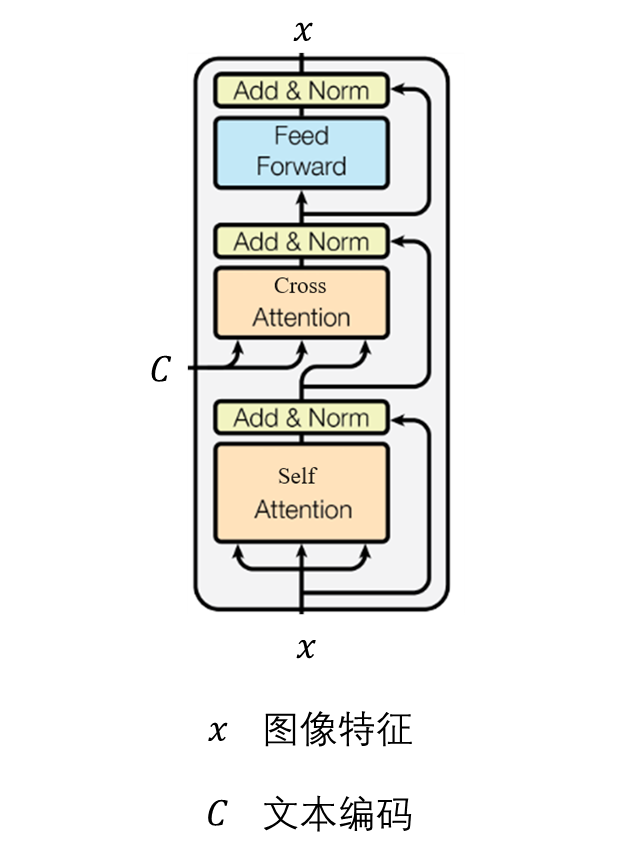
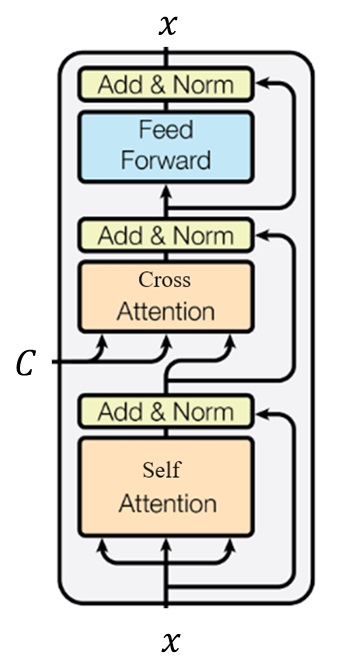
SD 的 U-Net 既用到了自注意力,也用到了交叉注意力。自注意力用于图像特征自己内部信息聚合。交叉注意力用于让生成图像对齐文本,其 Q 来自图像特征,K, V 来自文本编码。
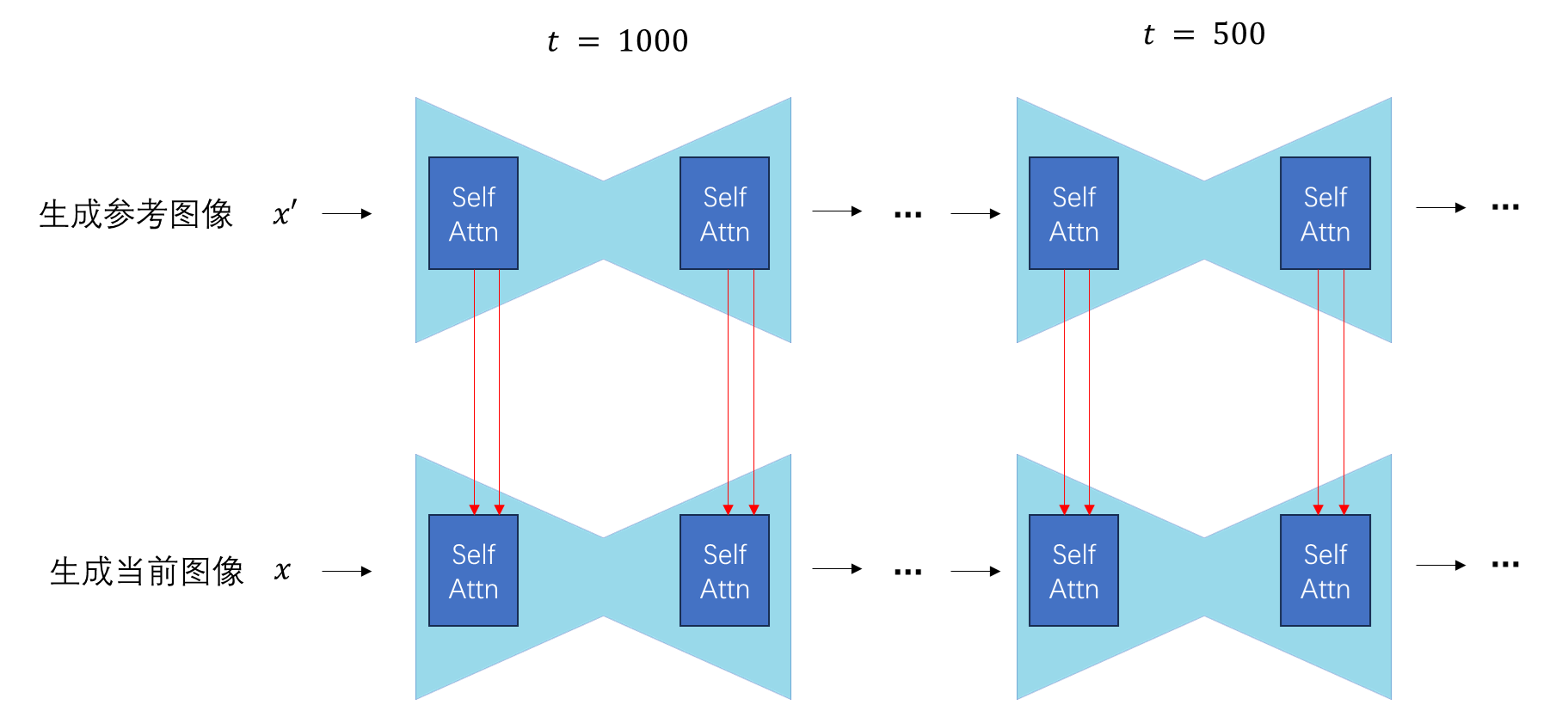
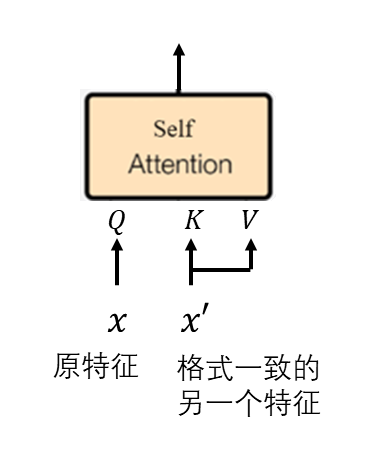
由于自注意力其实可以看成一种特殊的交叉注意力,我们可以把自注意力的 K, V 替换成来自另一幅参考图像的特征。这样,扩散模型的生成图片会既和原本要生成的图像相似,又和参考图像相似。当然,用来替换的特征必须和原来的特征「格式一致」,不然就生成不了有意义的结果了。
什么叫「格式一致」呢?我们知道,扩散模型在采样时有很多步,U-Net 中又有许多自注意力层。每一步时的每一个自注意力层的输入都有自己的「格式」。也就是说,如果你要把某时刻某自注意力层的 K, V 替换,就得先生成参考图像,用生成参考图像过程中此时刻此自注意力层的输入替换,而不能用其他时刻或者其他自注意力层的。
attn_processor_dict = {} for k in unet.attn_processors.keys(): if we_want_to_modify(k): attn_processor_dict[k] = MyAttnProcessor() else: attn_processor_dict[k] = AttnProcessor()
unet.set_attn_processor(attn_processor_dict)
实现帧间注意力处理类
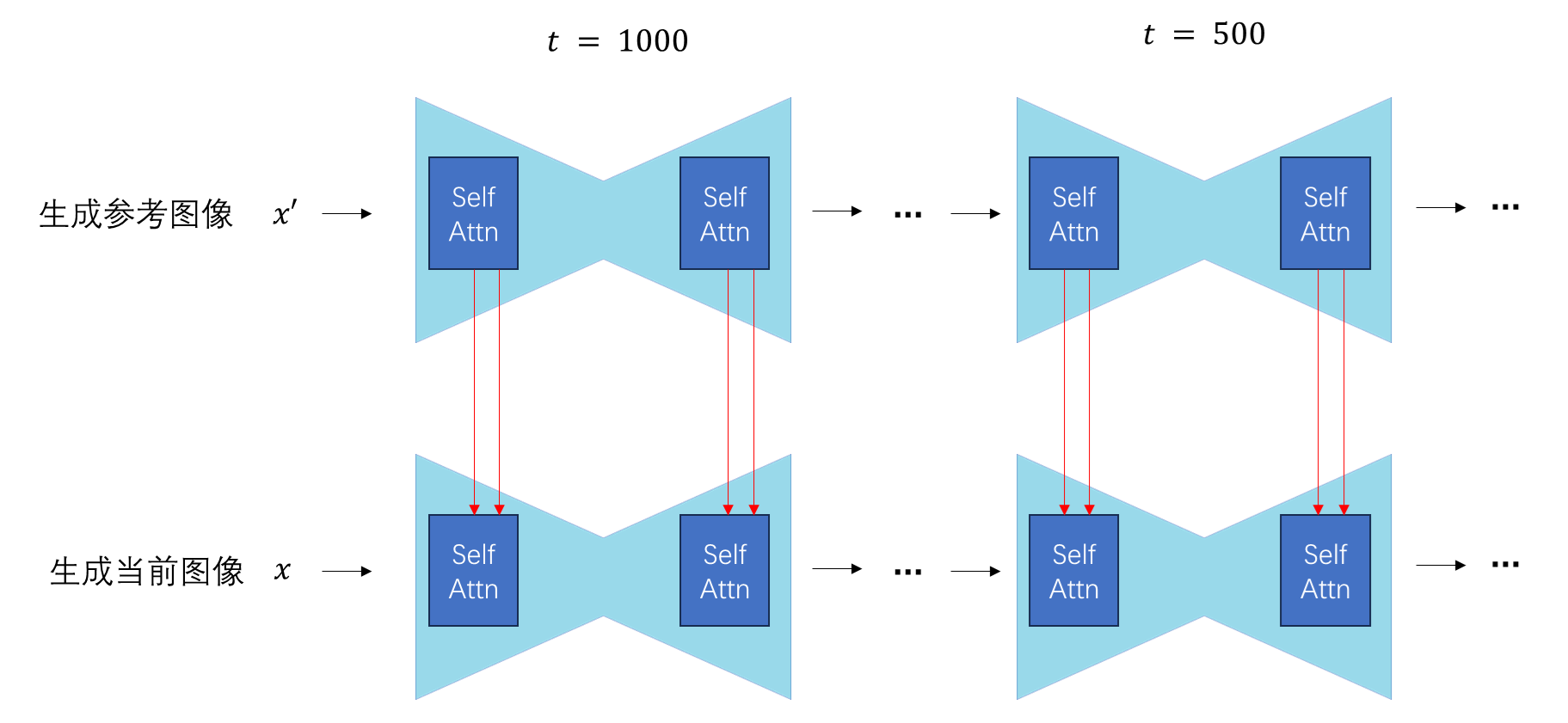
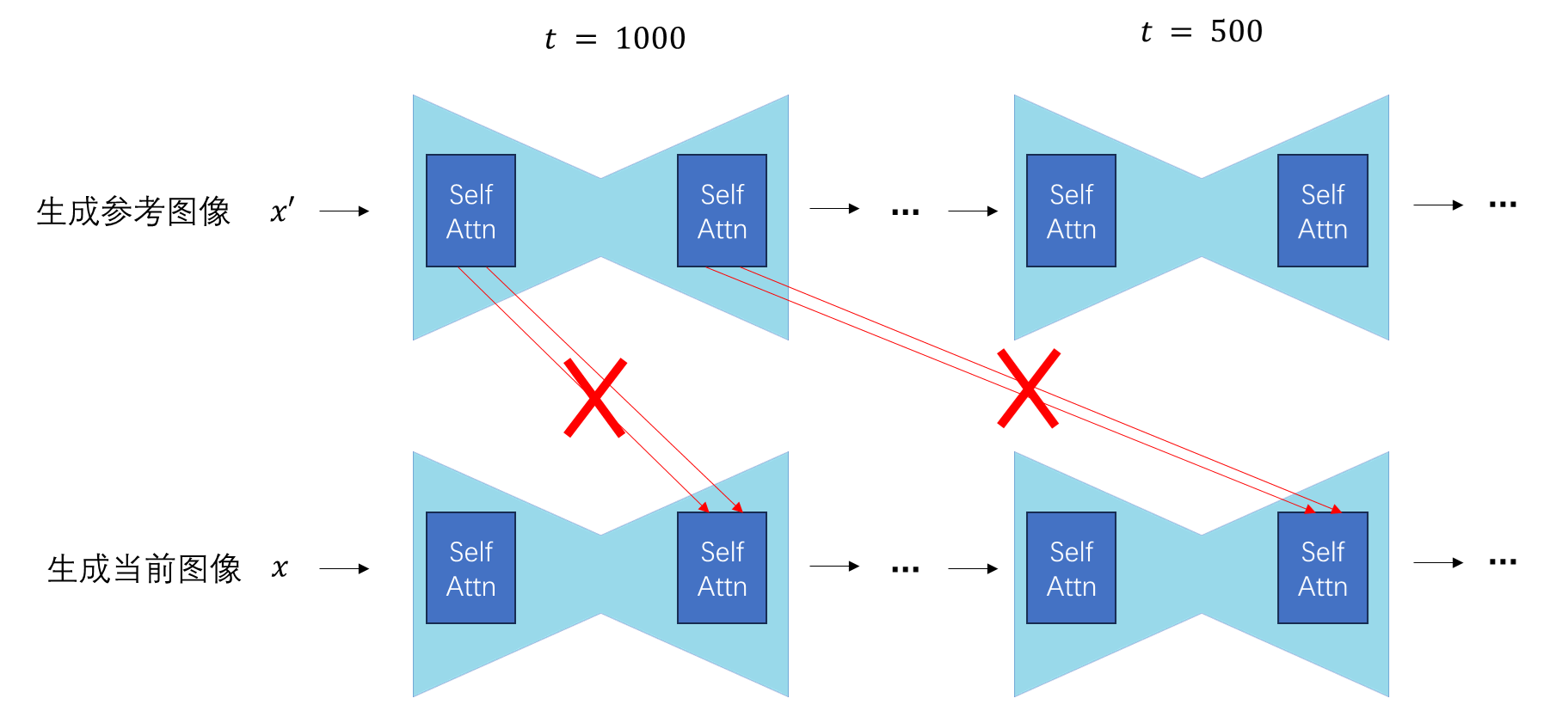
熟悉了 AttentionProcessor 类的相关内容,我们来编写自己的帧间注意力处理类。在处理第一帧时,该类的行为不变。对于之后的每一帧,该类的 K, V 输入会被替换成视频第一帧和上一帧的输入在序列长度维度上的拼接结果,即:
你是否会感到疑惑:为什么 K, V 的序列长度可以修改?别忘了,在注意力计算中,Q, K, V 的形状分别是:$Q \in \mathbb{R}^{a \times d_k}, K \in \mathbb{R}^{b \times d_k}, V \in \mathbb{R}^{b \times d_v}$。注意力计算只要求 K,V 的序列长度 $b$ 相同,并没有要求 Q, K 的序列长度相同。
self.attn_state = AttnState() attn_processor_dict = {} for k in unet.attn_processors.keys(): if k.startswith("up"): attn_processor_dict[k] = CrossFrameAttnProcessor( self.attn_state) else: attn_processor_dict[k] = AttnProcessor()
accelerator = Accelerator( gradient_accumulation_steps=args.gradient_accumulation_steps, mixed_precision=args.mixed_precision, log_with=args.report_to, project_config=accelerator_project_config, ) if args.report_to == "wandb": ifnot is_wandb_available(): raise ImportError("Make sure to install wandb if you want to use it for logging during training.") import wandb
# Make one log on every process with the configuration for debugging. logging.basicConfig( format="%(asctime)s - %(levelname)s - %(name)s - %(message)s", datefmt="%m/%d/%Y %H:%M:%S", level=logging.INFO, ) logger.info(accelerator.state, main_process_only=False) if accelerator.is_local_main_process: datasets.utils.logging.set_verbosity_warning() transformers.utils.logging.set_verbosity_warning() diffusers.utils.logging.set_verbosity_info() else: datasets.utils.logging.set_verbosity_error() transformers.utils.logging.set_verbosity_error() diffusers.utils.logging.set_verbosity_error()
随后的代码决定是否手动设置随机种子。保持默认即可。
1 2 3
# If passed along, set the training seed now. if args.seed isnotNone: set_seed(args.seed)
# freeze parameters of models to save more memory unet.requires_grad_(False) vae.requires_grad_(False) text_encoder.requires_grad_(False)
# Freeze the unet parameters before adding adapters for param in unet.parameters(): param.requires_grad_(False)
# For mixed precision training we cast all non-trainable weigths (vae, non-lora text_encoder and non-lora unet) to half-precision # as these weights are only used for inference, keeping weights in full precision is not required. weight_dtype = torch.float32 if accelerator.mixed_precision == "fp16": weight_dtype = torch.float16 elif accelerator.mixed_precision == "bf16": weight_dtype = torch.bfloat16
# Move unet, vae and text_encoder to device and cast to weight_dtype unet.to(accelerator.device, dtype=weight_dtype) vae.to(accelerator.device, dtype=weight_dtype) text_encoder.to(accelerator.device, dtype=weight_dtype)
unet.add_adapter(unet_lora_config) if args.mixed_precision == "fp16": for param in unet.parameters(): # only upcast trainable parameters (LoRA) into fp32 if param.requires_grad: param.data = param.to(torch.float32)
if args.enable_xformers_memory_efficient_attention: if is_xformers_available(): import xformers
xformers_version = version.parse(xformers.__version__) if xformers_version == version.parse("0.0.16"): logger.warn( ... ) unet.enable_xformers_memory_efficient_attention() else: raise ValueError("xformers is not available. Make sure it is installed correctly")
if args.gradient_checkpointing: unet.enable_gradient_checkpointing()
# Enable TF32 for faster training on Ampere GPUs, # cf https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices if args.allow_tf32: torch.backends.cuda.matmul.allow_tf32 = True
然后是优化器的选择。我们可以忽略其他逻辑,直接用 AdamW。
1 2 3 4 5 6 7 8 9 10 11 12
# Initialize the optimizer if args.use_8bit_adam: try: import bitsandbytes as bnb except ImportError: raise ImportError( "..." )
if args.dataset_name isnotNone: # Downloading and loading a dataset from the hub. dataset = load_dataset( args.dataset_name, args.dataset_config_name, cache_dir=args.cache_dir, data_dir=args.train_data_dir, ) else: data_files = {} if args.train_data_dir isnotNone: data_files["train"] = os.path.join(args.train_data_dir, "**") dataset = load_dataset( "imagefolder", data_files=data_files, cache_dir=args.cache_dir, ) # See more about loading custom images at # https://huggingface.co/docs/datasets/v2.4.0/en/image_load#imagefolder
# Preprocessing the datasets. # We need to tokenize inputs and targets. column_names = dataset["train"].column_names
# 6. Get the column names for input/target. dataset_columns = DATASET_NAME_MAPPING.get(args.dataset_name, None) if args.image_column isNone: image_column = dataset_columns[0] if dataset_columns isnotNoneelse column_names[0] else: image_column = args.image_column if image_column notin column_names: raise ValueError( f"--image_column' value '{args.image_column}' needs to be one of: {', '.join(column_names)}" ) if args.caption_column isNone: caption_column = dataset_columns[1] if dataset_columns isnotNoneelse column_names[1] else: caption_column = args.caption_column if caption_column notin column_names: raise ValueError( f"--caption_column' value '{args.caption_column}' needs to be one of: {', '.join(column_names)}" )
准备好了数据集,接下来要定义数据预处理流程以创建 DataLoader。函数先定义了一个把文本标签预处理成 token ID 的 token 化函数。我们不需要修改它。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
deftokenize_captions(examples, is_train=True): captions = [] for caption in examples[caption_column]: ifisinstance(caption, str): captions.append(caption) elifisinstance(caption, (list, np.ndarray)): # take a random caption if there are multiple captions.append(random.choice(caption) if is_train else caption[0]) else: raise ValueError( f"Caption column `{caption_column}` should contain either strings or lists of strings." ) inputs = tokenizer( captions, max_length=tokenizer.model_max_length, padding="max_length", truncation=True, return_tensors="pt" ) return inputs.input_ids
# Preprocessing the datasets. train_transforms = transforms.Compose( [ transforms.Resize( args.resolution, interpolation=transforms.InterpolationMode.BILINEAR), transforms.CenterCrop( args.resolution) if args.center_crop else transforms.RandomCrop(args.resolution), transforms.RandomHorizontalFlip() if args.random_flip else transforms.Lambda(lambda x: x), transforms.ToTensor(), transforms.Normalize([0.5], [0.5]), ] )
定义了预处理流程后,函数对所有数据进行预处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
defpreprocess_train(examples): images = [image.convert("RGB") for image in examples[image_column]] examples["pixel_values"] = [ train_transforms(image) for image in images] examples["input_ids"] = tokenize_captions(examples) return examples
with accelerator.main_process_first(): if args.max_train_samples isnotNone: dataset["train"] = dataset["train"].shuffle( seed=args.seed).select(range(args.max_train_samples)) # Set the training transforms train_dataset = dataset["train"].with_transform(preprocess_train)
defcollate_fn(examples): pixel_values = torch.stack([example["pixel_values"] for example in examples]) pixel_values = pixel_values.to( memory_format=torch.contiguous_format).float() input_ids = torch.stack([example["input_ids"] for example in examples]) return {"pixel_values": pixel_values, "input_ids": input_ids}
# Scheduler and math around the number of training steps. overrode_max_train_steps = False num_update_steps_per_epoch = math.ceil( len(train_dataloader) / args.gradient_accumulation_steps) if args.max_train_steps isNone: args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch overrode_max_train_steps = True
# We need to recalculate our total training steps as the size of the training dataloader may have changed. num_update_steps_per_epoch = math.ceil( len(train_dataloader) / args.gradient_accumulation_steps) if overrode_max_train_steps: args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch # Afterwards we recalculate our number of training epochs args.num_train_epochs = math.ceil( args.max_train_steps / num_update_steps_per_epoch)
在准备工作的最后,函数会用 accelerate 库记录配置信息。
1 2
if accelerator.is_main_process: accelerator.init_trackers("text2image-fine-tune", config=vars(args))
# Potentially load in the weights and states from a previous save if args.resume_from_checkpoint: if args.resume_from_checkpoint != "latest": path = ... else: # Get the most recent checkpoint path = ...
progress_bar = tqdm( range(0, args.max_train_steps), initial=initial_global_step, desc="Steps", # Only show the progress bar once on each machine. disable=not accelerator.is_local_main_process, )
for epoch inrange(first_epoch, args.num_train_epochs): unet.train() train_loss = 0.0 for step, batch inenumerate(train_dataloader): with accelerator.accumulate(unet):
bsz = latents.shape[0] # Sample a random timestep for each image timesteps = torch.randint( 0, noise_scheduler.config.num_train_timesteps, (bsz,), device=latents.device) timesteps = timesteps.long()
时间戳和前面随机生成的噪声一起经 DDPM 的前向过程得到带噪图片 noisy_latents。
1 2 3 4
# Add noise to the latents according to the noise magnitude at each timestep # (this is the forward diffusion process) noisy_latents = noise_scheduler.add_noise( latents, noise, timesteps)
再把文本 batch["input_ids"] 编码,为之后的 U-Net 前向传播做准备。
1 2
# Get the text embedding for conditioning encoder_hidden_states = text_encoder(batch["input_ids"])[0]
# Get the target for loss depending on the prediction type if args.prediction_type isnotNone: # set prediction_type of scheduler if defined noise_scheduler.register_to_config( prediction_type=args.prediction_type)
if args.snr_gamma isNone: loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean") else: # Compute loss-weights as per Section 3.4 of https://arxiv.org/abs/2303.09556. ...
if global_step % args.checkpointing_steps == 0: if accelerator.is_main_process: # _before_ saving state, check if this save would set us over the `checkpoints_total_limit` if args.checkpoints_total_limit isnotNone: checkpoints = ...
import os import torch import numpy as np from omegaconf import OmegaConf from PIL import Image from tqdm import tqdm, trange from einops import rearrange from pytorch_lightning import seed_everything from torch import autocast from torchvision.utils import make_grid
from ldm.util import instantiate_from_config from ldm.models.diffusion.ddim import DDIMSampler
defload_model_from_config(config, ckpt, verbose=False): print(f"Loading model from {ckpt}") pl_sd = torch.load(ckpt, map_location="cpu") if"global_step"in pl_sd: print(f"Global Step: {pl_sd['global_step']}") sd = pl_sd["state_dict"] model = instantiate_from_config(config.model) m, u = model.load_state_dict(sd, strict=False) iflen(m) > 0and verbose: print("missing keys:") print(m) iflen(u) > 0and verbose: print("unexpected keys:") print(u)
model.cuda() model.eval() return model
defmain(): seed = 42 config = 'configs/stable-diffusion/v1-inference.yaml' ckpt = 'ckpt/v1-5-pruned.ckpt' outdir = 'tmp' n_samples = batch_size = 3 n_rows = batch_size n_iter = 2 prompt = 'a photograph of an astronaut riding a horse' data = [batch_size * [prompt]] scale = 7.5 C = 4 f = 8 H = W = 512 ddim_steps = 50 ddim_eta = 0.0
seed_everything(seed)
config = OmegaConf.load(config) model = load_model_from_config(config, ckpt)
device = torch.device( "cuda") if torch.cuda.is_available() else torch.device("cpu") model = model.to(device) sampler = DDIMSampler(model)
all_samples.append(x_samples_ddim) grid = torch.stack(all_samples, 0) grid = rearrange(grid, 'n b c h w -> (n b) c h w') grid = make_grid(grid, nrow=n_rows)
# to image grid = 255. * rearrange(grid, 'c h w -> h w c').cpu().numpy() img = Image.fromarray(grid.astype(np.uint8)) img.save(os.path.join(outpath, f'grid-{grid_count:04}.png')) grid_count += 1
print(f"Your samples are ready and waiting for you here: \n{outpath} \n" f" \nEnjoy.")
self.make_schedule(ddim_num_steps=S, ddim_eta=eta, verbose=verbose) # sampling C, H, W = shape size = (batch_size, C, H, W) print(f'Data shape for DDIM sampling is {size}, eta {eta}')
h = x.type(self.dtype) for module in self.input_blocks: h = module(h, emb, context) hs.append(h) h = self.middle_block(h, emb, context) for module in self.output_blocks: h = th.cat([h, hs.pop()], dim=1) h = module(h, emb, context) h = h.type(x.dtype) return self.out(h)
defforward(self, x, emb, context=None): for layer in self: ifisinstance(layer, TimestepBlock): x = layer(x, emb) elifisinstance(layer, SpatialTransformer): x = layer(x, context) else: x = layer(x) return x
for level, mult inenumerate(channel_mult): for _ inrange(num_res_blocks): layers = [ ResBlock(...)] ch = mult * model_channels if ds in attention_resolutions: layers.append( AttentionBlock(...) ifnot use_spatial_transformer else SpatialTransformer(...))
self.input_blocks.append(TimestepEmbedSequential(*layers)) if level != len(channel_mult) - 1: out_ch = ch self.input_blocks.append( TimestepEmbedSequential( ResBlock(...) if resblock_updown else Downsample(...) ) )
当然,标准Transformer是针对一维序列数据的。要把Transformer用到图像上,则需要把图像的宽高拼接到同一维,即对张量做形状变换n c h w -> n c (h * w)。做完这个变换后,就可以把数据直接输入进Transformer模块了。 这些图像数据与序列数据的适配都是在SpatialTransformer类里完成的。SpatialTransformer类并没有直接实现Transformer块的细节,仅仅是U-Net和Transformer块之间的一个过渡。Transformer块的实现在它的一个子模块里。我们来看它的实现代码。
defforward(self, x, context=None): b, c, h, w = x.shape x_in = x x = self.norm(x) x = self.proj_in(x) x = rearrange(x, 'b c h w -> b (h w) c') for block in self.transformer_blocks: x = block(x, context=context) x = rearrange(x, 'b (h w) c -> b c h w', h=h, w=w) x = self.proj_out(x) return x + x_in
defforward(self, x, context=None): x = self.attn1(self.norm1(x)) + x x = self.attn2(self.norm2(x), context=context) + x x = self.ff(self.norm3(x)) + x return x
for level, mult inenumerate(channel_mult): for _ inrange(num_res_blocks): layers = [ ResBlock(...)] ch = mult * model_channels if ds in attention_resolutions: layers.append( AttentionBlock(...) ifnot use_spatial_transformer else SpatialTransformer(...))
self.input_blocks.append(TimestepEmbedSequential(*layers)) if level != len(channel_mult) - 1: out_ch = ch self.input_blocks.append( TimestepEmbedSequential( ResBlock(...) if resblock_updown else Downsample(...) ) )
from diffusers import DiffusionPipeline import torch
pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16) pipeline.to("cuda") pipeline("An image of a squirrel in Picasso style").images[0].save('output.jpg')
from diffusers import DiffusionPipeline import torch
pipeline = DiffusionPipeline.from_pretrained("ckpt/sd15", torch_dtype=torch.float16) pipeline.to("cuda") pipeline("An image of a squirrel in Picasso style").images[0].save('output.jpg')
# 0. Default height and width to unet height = height or self.unet.config.sample_size * self.vae_scale_factor width = width or self.unet.config.sample_size * self.vae_scale_factor # to deal with lora scaling and other possible forward hooks
# 1. Check inputs. Raise error if not correct self.check_inputs(...)
# For classifier free guidance, we need to do two forward passes. # Here we concatenate the unconditional and text embeddings into a single batch # to avoid doing two forward passes if self.do_classifier_free_guidance: prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
# 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline ...
# 7. Denoising loop num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order self._num_timesteps = len(timesteps) with self.progress_bar(total=num_inference_steps) as progress_bar: for i, t inenumerate(timesteps): # expand the latents if we are doing classifier free guidance latent_model_input = torch.cat([latents] * 2) if self.do_classifier_free_guidance else latents latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0: # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale)
# call the callback, if provided if i == len(timesteps) - 1or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0): progress_bar.update()
with self.progress_bar(total=num_inference_steps) as progress_bar: for i, t inenumerate(timesteps): # eps = unet(zt, t, c)
# expand the latents if we are doing classifier free guidance latent_model_input = torch.cat([latents] * 2) if self.do_classifier_free_guidance else latents latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0: # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale)
classCrossAttnDownBlock2D(nn.Module): def__init__(...): for i inrange(num_layers): resnets.append(ResnetBlock2D(...)) ifnot dual_cross_attention: attentions.append(Transformer2DModel(...))
attn_processor_dict = {} for k in unet.attn_processors.keys(): if we_want_to_modify(k): attn_processor_dict[k] = MyAttnProcessor() else: attn_processor_dict[k] = AttnProcessor()
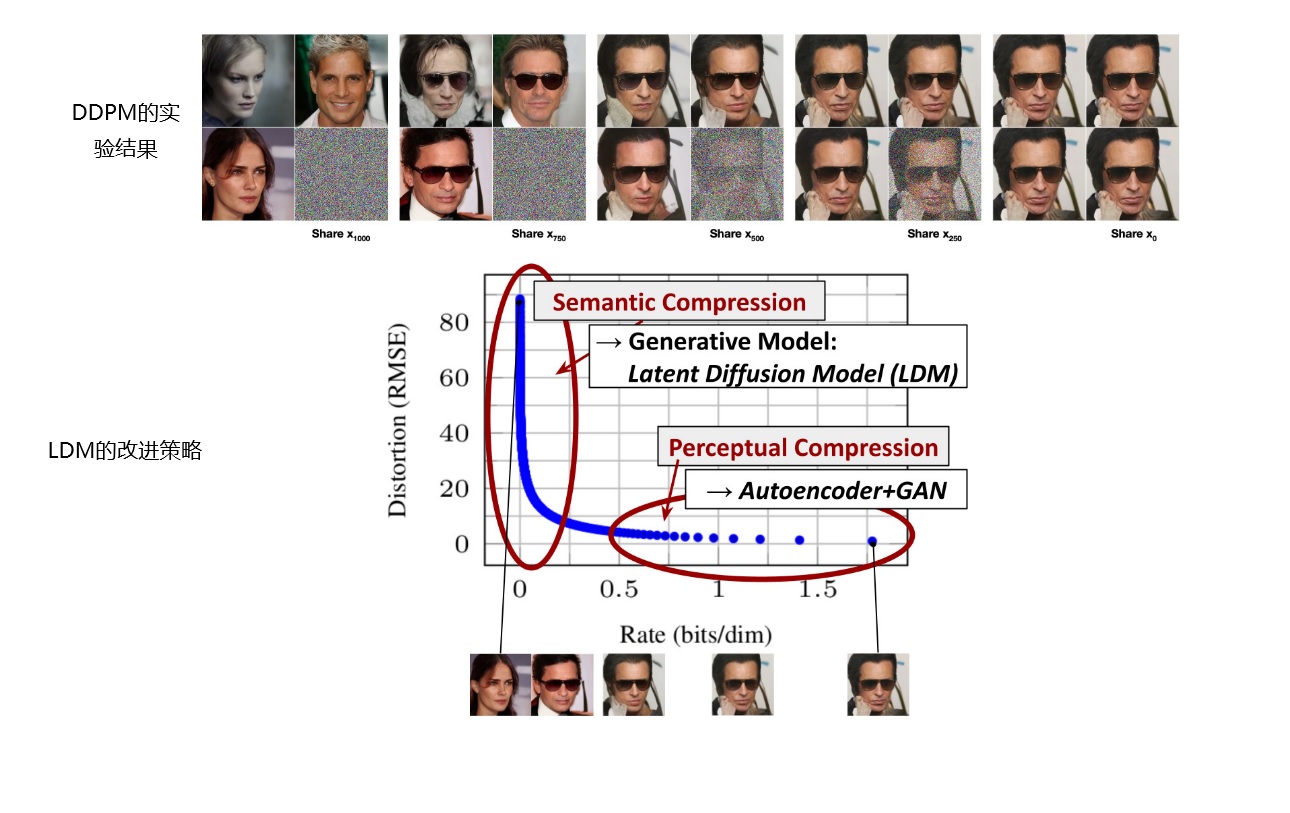
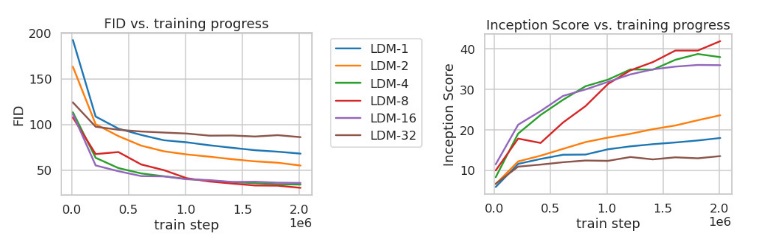
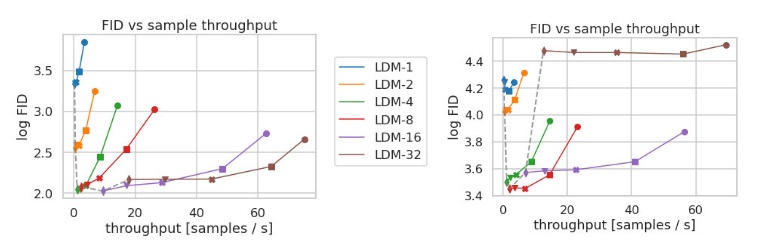
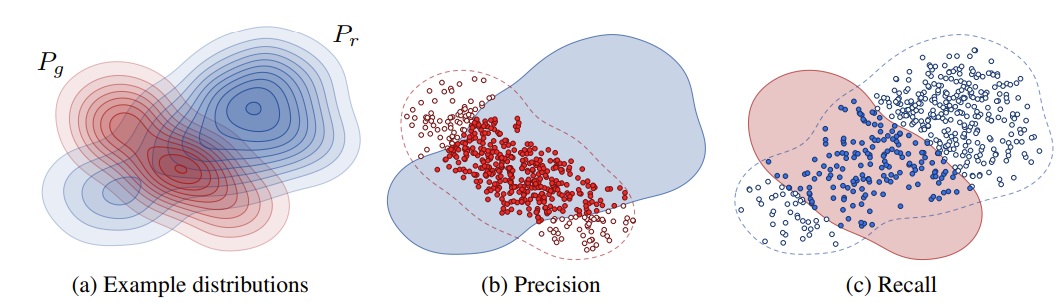
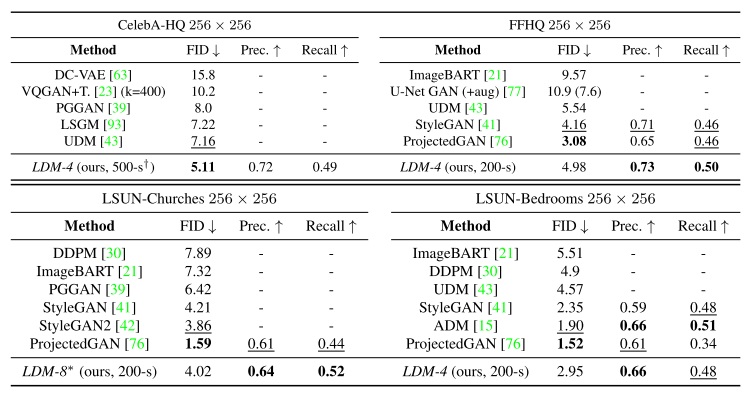
在介绍具体结果之前,先对这个不太常见的精确率及召回率指标做一个解释。精确率及召回率常用于分类等有确定答案的任务中,分别表示所有被分类为正的样本中有多少是分对了的、所有真值为正的样本中有多少是被成功分类成正的。而无约束图像生成中的精确率及召回率的解释可以参加论文Improved Precision and Recall Metric for Assessing Generative Models。如下图所示,设真实分布为蓝色,生成模型的分布为红色,则红色样本落在蓝色分布的比例为精确率,蓝色样本落在红色分布的比例为召回率。简单来说,精确率能描述采样质量,召回率能描述生成分布与真实分布的覆盖情况。
Deep Unsupervised Learning using Nonequilibrium Thermodynamics: https://arxiv.org/abs/1503.03585 DDPM的前作,首个提出扩散模型思想的文章。其核心原理和DDPM几乎完全一致,但是模型结构和优化目标不够先进,生成效果没有改进后的DDPM好。数学公式较多,不必细读,可以在学习DDPM时对比着阅读。